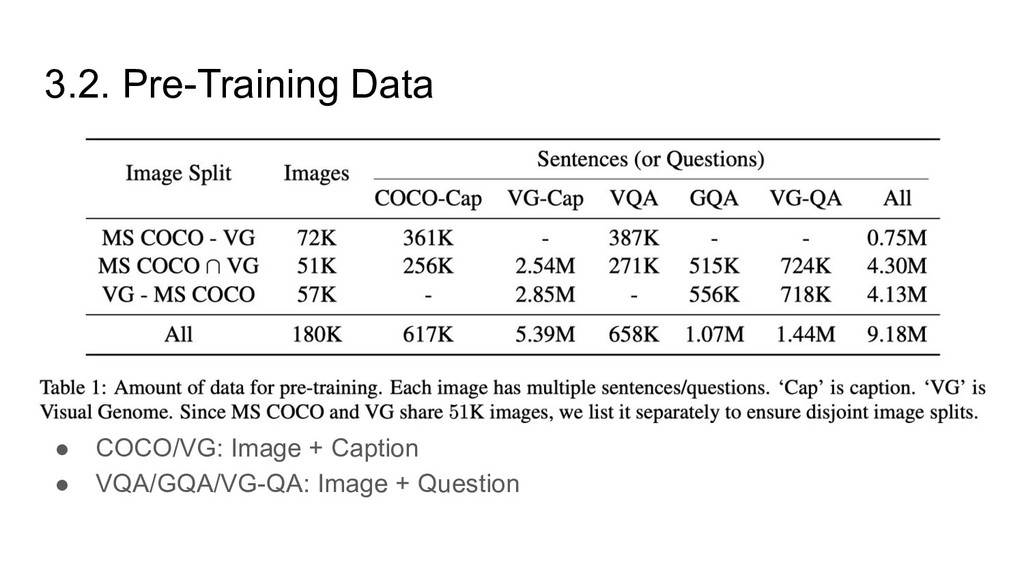
Transformer for language ◦ Transformer for vision ◦ Transformer for cross-modality • Effectively learn language/vision/cross-modality relationship • Achieve SOTA in 3 tasks ◦ Visual Question Answering (VQA) ◦ Compositional Question Answering (GQA) ◦ Natural Language for Visual Reasoning for Real (NLVR2)
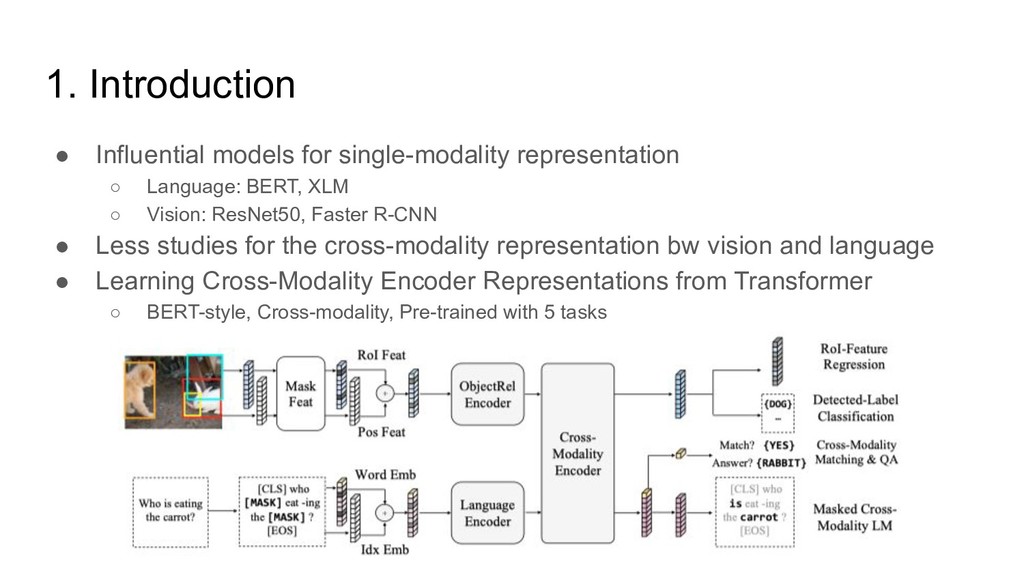
BERT, XLM ◦ Vision: ResNet50, Faster R-CNN • Less studies for the cross-modality representation bw vision and language • Learning Cross-Modality Encoder Representations from Transformer ◦ BERT-style, Cross-modality, Pre-trained with 5 tasks
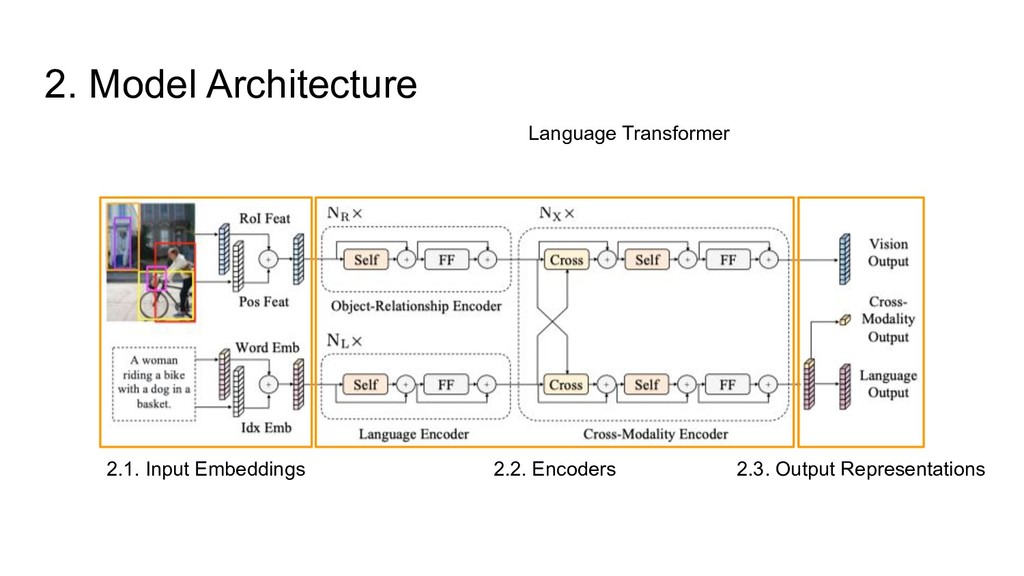
cross-modality encoder for language • Visual output ◦ Output of the cross-modality encoder for vision • Cross-modal output ◦ Output of the cross-modality encoder for [CLS] [CLS]
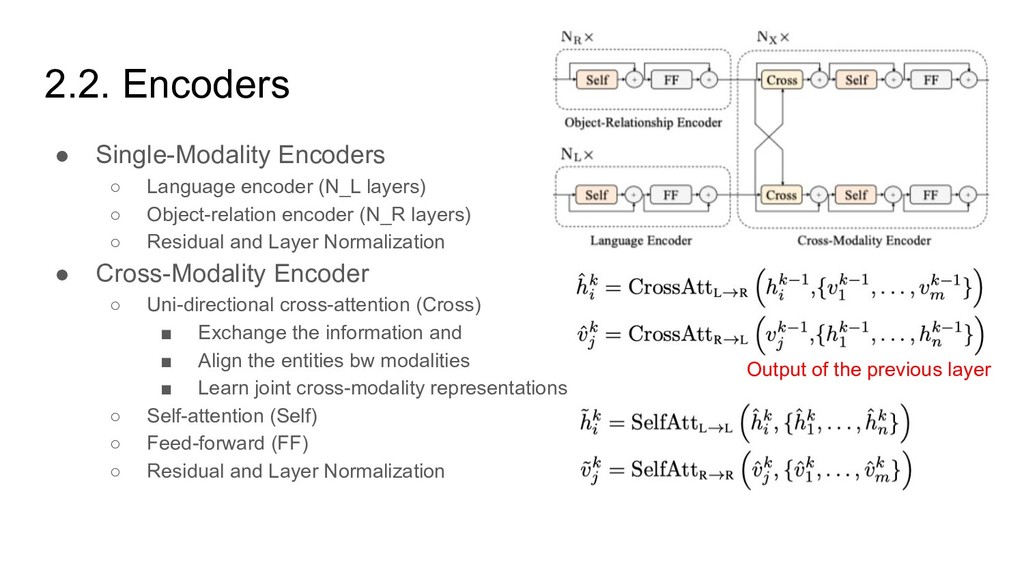
the non-masked words in the language modality • Randomly mask words with a probability of 0.15 • Pros: Good at resolving ambiguity • Cons: Cannot load pre-trained BERT parameters
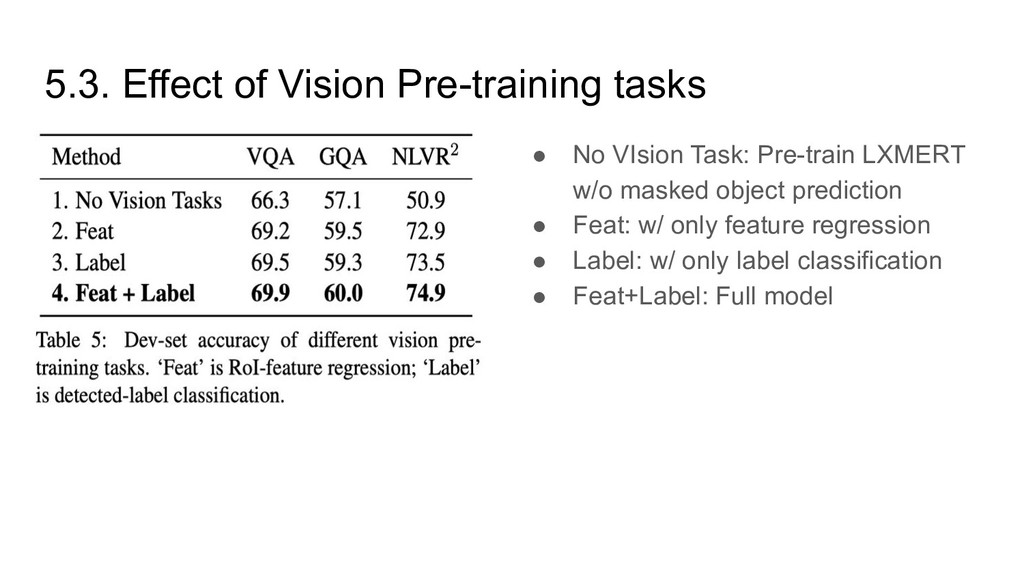
non-masked object in the vision modality • Randomly mask objects with a probability of 0.15 • RoI-Feature Regression => Predict the object RoI feature with L2 loss • Detected-Label Classification => Predict the object label detected by Faster R-CNN • Pros: Learning object relationship • Pros: Learning cross-modality alignment
mismatched one with a probability of 0.5 • Predict whether an image and a sentence match each other • Equivalent of “Next Sentence Prediction” in BERT Image Question Answering • Predict the answer for image-question data • 9,500 answers (~90%) • Pros: Enlarge dataset (⅓ sentences in entire dataset)
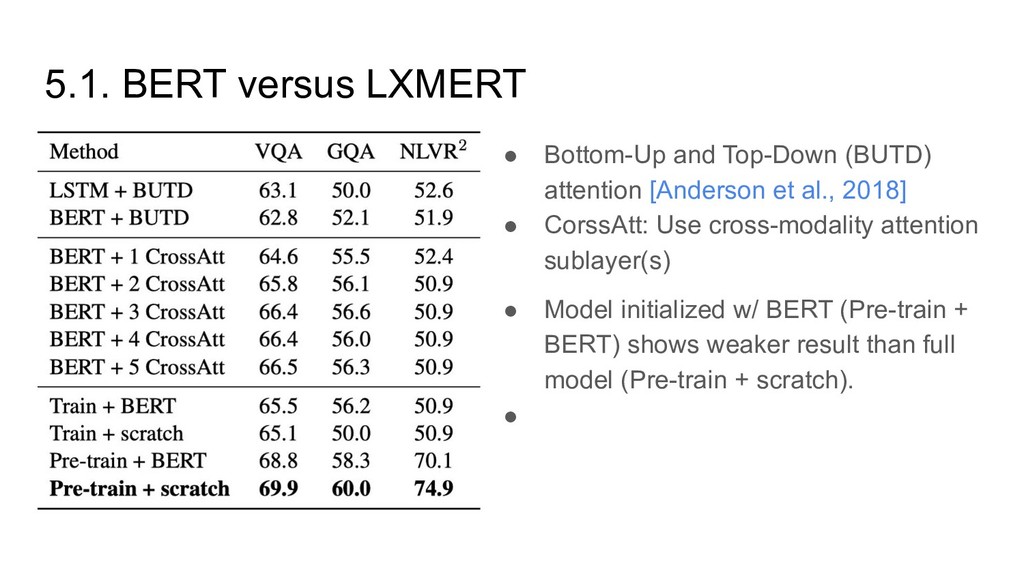
[Anderson et al., 2018] • CorssAtt: Use cross-modality attention sublayer(s) • Model initialized w/ BERT (Pre-train + BERT) shows weaker result than full model (Pre-train + scratch). •
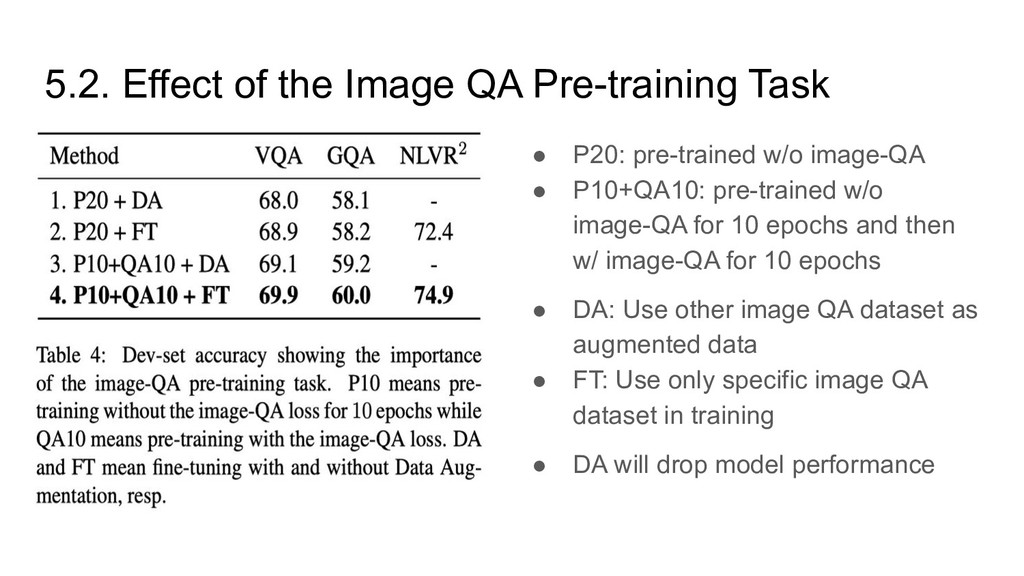
pre-trained w/o image-QA • P10+QA10: pre-trained w/o image-QA for 10 epochs and then w/ image-QA for 10 epochs • DA: Use other image QA dataset as augmented data • FT: Use only specific image QA dataset in training • DA will drop model performance
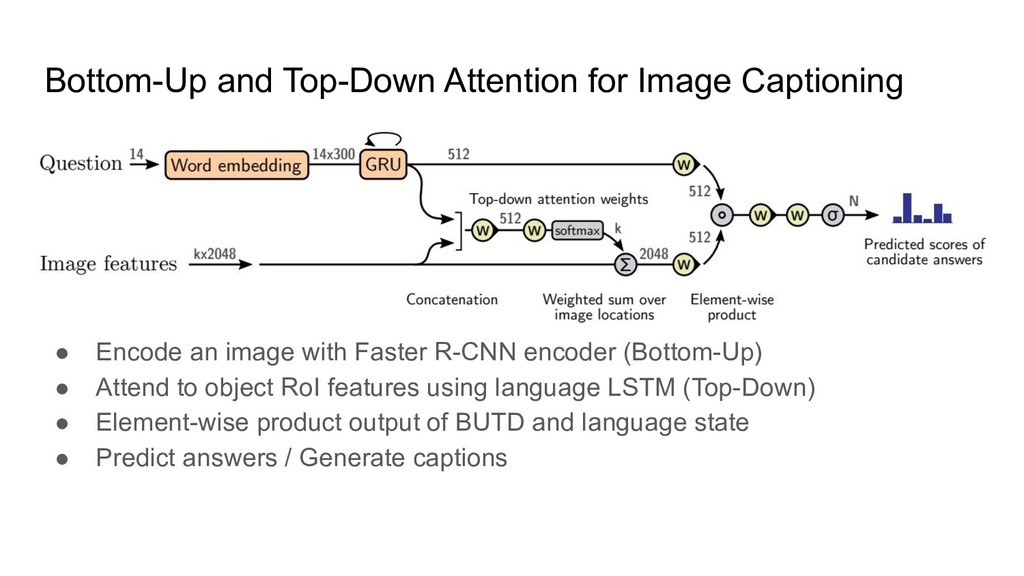
image with Faster R-CNN encoder (Bottom-Up) • Attend to object RoI features using language LSTM (Top-Down) • Element-wise product output of BUTD and language state • Predict answers / Generate captions
BERT-style ◦ Code/Pre-trained model available online • Learn representations for language/vision/cross-modality effectively ◦ Especially in NLVR2 • SOTA results on VGA/GQA/NLVR2 tasks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ViLBERT [Lu et al., 2019] • Co-TRM: Co-attentional TRansforMer layers](https://files.speakerdeck.com/presentations/1c9bd85341394c8eb6cdcd3dac1579f7/slide_21.jpg){kind=link}
![Visual-BERT [Li et al., 2019]](https://files.speakerdeck.com/presentations/1c9bd85341394c8eb6cdcd3dac1579f7/slide_22.jpg){kind=link}
{kind=link}