Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Experts, Errors, and Context: A Large-Scale St...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
tosho
September 25, 2022
Research
330
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation
第14回最先端NLP勉強会での発表資料。
元論文:
https://aclanthology.org/2021.tacl-1.87/
tosho
September 25, 2022
More Decks by tosho
See All by tosho
LayerXにおけるセキュリティ管理の現在地と次の一手
tosho
0
360
Good for Misconceived Reasons: An Empirical Revisiting on the Need for Visual Context in Multimodal Machine Translation
tosho
0
390
Shaham and Levy, 2021. Neural Machine Translation without Embeddings. NAACL2021
tosho
0
140
Liu et al., 2021. Pay Attention to MLPs. arXiv
tosho
0
190
Huang et al. 2020 Unsupervised Multimodal Neural Machine Translation with Pseudo Visual Pivoting
tosho
0
500
Ive, Madhyastha, Specia_2019_EMNLP_Deep Copycat Networks for Text-to-Text Generation
tosho
0
170
Tan, Bansal_2019_EMNLP_LXMERT Learning Cross-Modality Encoder Representations from Transformers
tosho
0
280
Tsai et al._2019_ACL_Multimodal Transformer for Unaligned Multimodal Language Sequences
tosho
0
460
Zhou et al. 2019. Density Matching for Bilingual Word Embedding. NAACL
tosho
3
330
Other Decks in Research
See All in Research
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
500
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.5k
明日から使える!研究効率化ツール入門
matsui_528
13
7.4k
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
590
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
110
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.2k
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
620
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
390
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
280
Featured
See All Featured
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
240
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
The Mindset for Success: Future Career Progression
greggifford
PRO
0
400
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
380
Product Roadmaps are Hard
iamctodd
55
12k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
A designer walks into a library…
pauljervisheath
211
24k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Transcript
論文紹介 Experts, Errors, and Context: A Large-Scale Study of Human
Evaluation for Machine Translation Markus Freitag, George Foster, David Grangier, Viresh Ratnakar, Qijun Tan, Wolfgang Macherey TACL, Volume 9 (2021) 読み手:平澤 寅庄 東京都立大学小町研究室 D2 2022/9/27 第14回最先端NLP勉強会
論文 (TACL) : https://aclanthology.org/2021.tacl-1.87/ (8/2021) 論文 (arXiv) : https://arxiv.org/abs/2104.14478 (4/2021)
データセット : https://github.com/google/wmt-mqm-human-evaluation MQM Viewer : https://github.com/google-research/google-research/tree/master/mqm_viewer 注釈のない図表は論文から引用されたものです 2
この論文の... 問題設定 • 正しく機械翻訳を評価できているか キモとなる技術や手法 • Professional translators による MQM
評価をプラチナとする • MQM 評価との相関で各評価手法の良し悪しを評価する 分かったこと • 人手翻訳(HT)は依然として機械翻訳(MT)よりも品質がよい • 自動評価は Crowd-worker による人手評価よりも、MQM との相関が高い 3
(機械)翻訳の評価手法 自動評価 • BLEU, COMET, chrF, YiSi, etc Crowd-sourcing による人手評価
• Scalar Quality Metric (cSQM) Professional translator による人手評価 • Scalar Quality Metric (pSQM) • Multidimensional Quality Metrics (MQM) 4
(機械)翻訳の評価手法 自動評価 • BLEU, COMET, chrF, YiSi, etc Crowd-sourcing による人手評価
• Scalar Quality Metric (cSQM) Professional translator による人手評価 • Scalar Quality Metric (pSQM) • Multidimensional Quality Metrics (MQM) 低 高 低 高 精度 コスト 5
(機械)翻訳の評価手法 自動評価 • BLEU, COMET, chrF, YiSi, etc Crowd-sourcing による人手評価
• Scalar Quality Metric (cSQM) Professional translator による人手評価 • Scalar Quality Metric (pSQM) • Multidimensional Quality Metrics (MQM) 低 高 低 高 精度 コスト 6 WMT Direct Assessment
WMT Direct Assessment (or WMT) • 文(segment)ごとに 0 - 100
でスコアを付ける • 評価時は文脈(原文を含む文書)が提示される Translations out of English (X → English) • 原文のみで評価 • researchers / translators Translation into English (English → X) • 参照訳のみで評価 • crowd workers 7
Scalar Quality Metric (SQM) • 文(segment)ごとに 0 - 6 でスコアを付ける
• 評価時は原文・参照訳・文脈(原文を含む文書)が提示される cSQM • crowd worker による評価 • proficiency test に合格した rater のみで行う pSQM • professional translator による評価 8
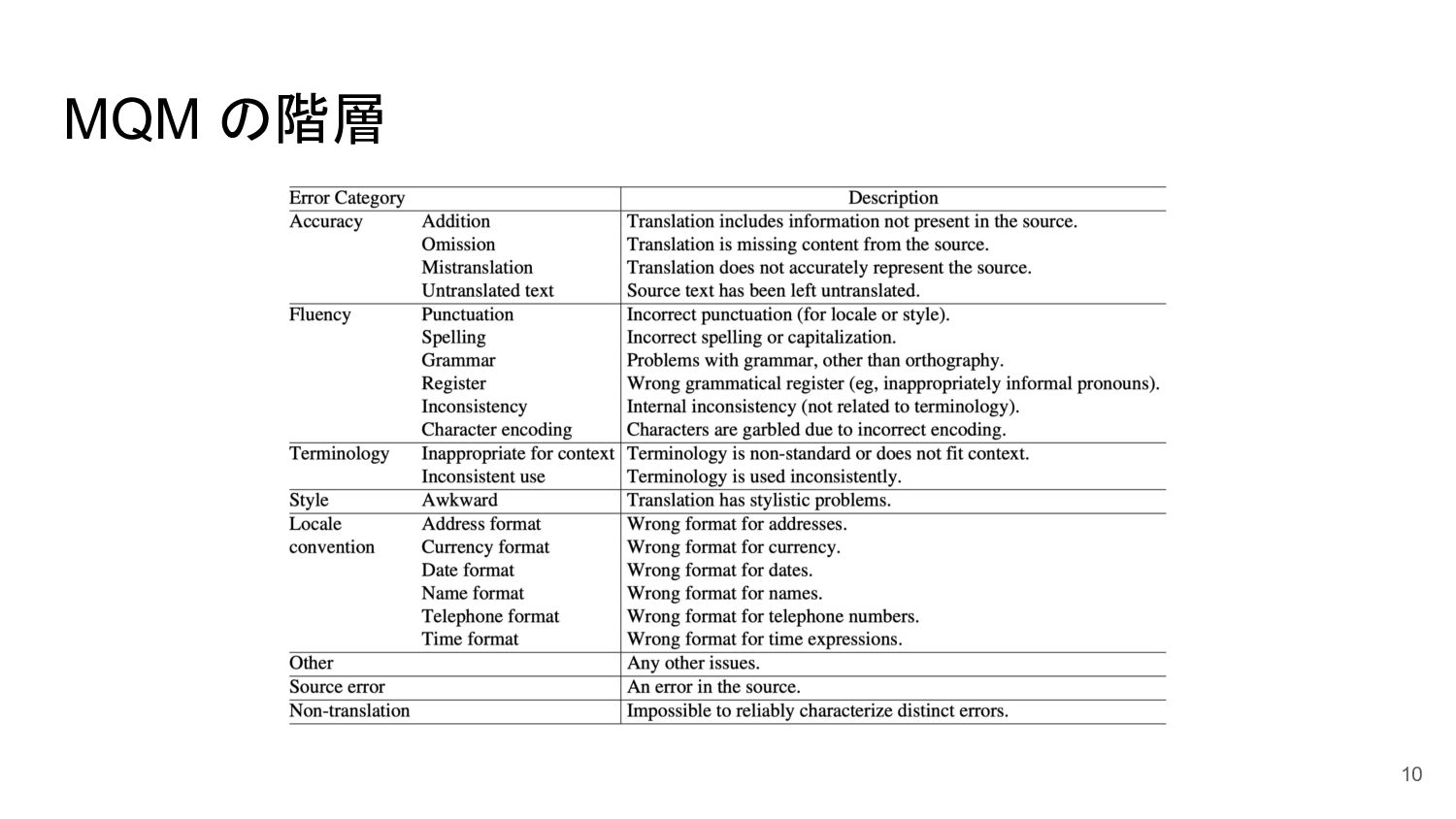
Multidimensional Quality Metrics (MQM) • 階層化された誤りカテゴリを用いて評価を行う ◦ Accuracy / Fluency
/ Terminology / Style / Locale convention / Other • それぞれの誤りは重大度(severity)が付けられる ◦ Major: 意味的もしくは文法的な誤り ◦ Minor: より小さな不完全さ ◦ Neutral: 評価者の主観によるもの ◦ MQM でよく使われる Critical は Major と主観的な違いしかないため、廃止した • 2つの追加の誤り ◦ Source error: 入力文の誤り ◦ Non-translation: 個別の誤りとは分類できない翻訳 ◦ これらの誤りは重大度を持たず、階層化された誤りカテゴリとは区別されて付与される。 9
MQM の階層 10
Accuracy の例 Mistranslation Omission Addition 11
Fluency の例 Grammer Punctuation 12
Style の例 Awkward 13
Non-translation の例 14
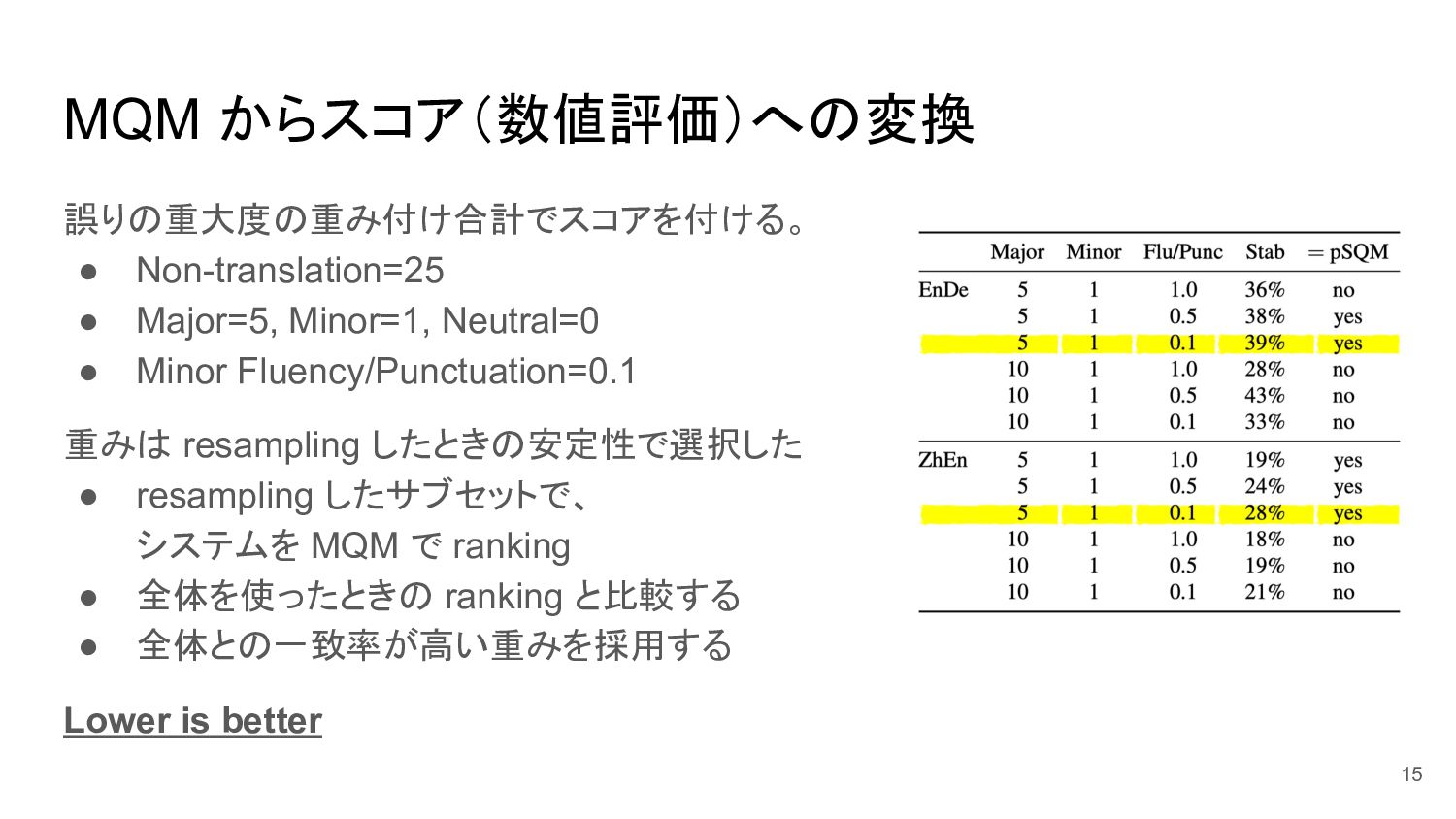
MQM からスコア(数値評価)への変換 誤りの重大度の重み付け合計でスコアを付ける。 • Non-translation=25 • Major=5, Minor=1, Neutral=0 •
Minor Fluency/Punctuation=0.1 重みは resampling したときの安定性で選択した • resampling したサブセットで、 システムを MQM で ranking • 全体を使ったときの ranking と比較する • 全体との一致率が高い重みを採用する Lower is better 15
実験 データ:WMT 2020/2021 test sets, TED test set 言語対:English→German /
Chinese→English • 1,418 / 2,000 segments, 130 / 155 documents MT systems:10 システム • うち、3 / 2 システムは参照訳 • pSQM, MQM では1つのドキュメントを3名の評価者で評価する 評価方法:WMT, cSQM, pSQM, MQM 16
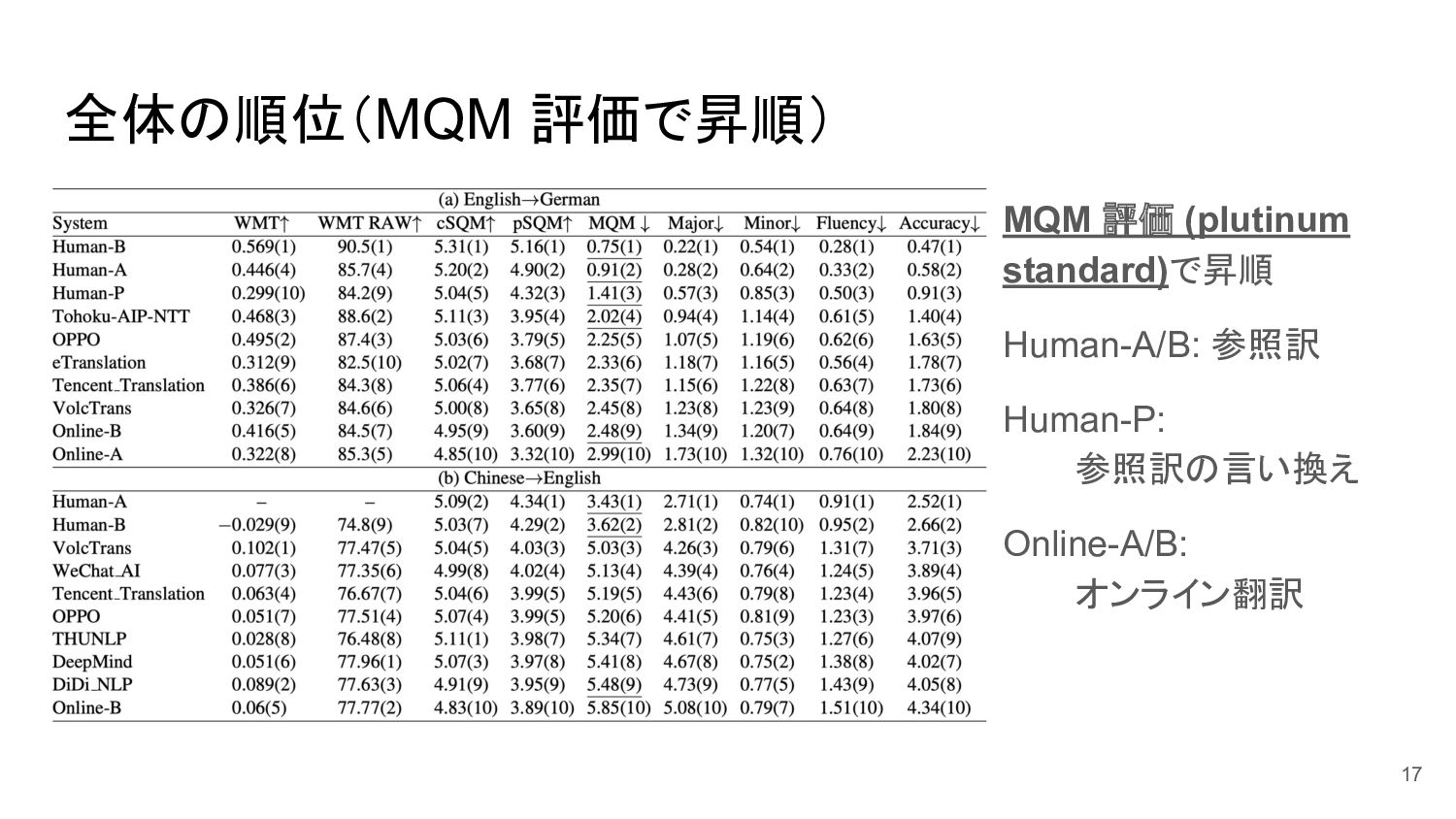
全体の順位(MQM 評価で昇順) MQM 評価 (plutinum standard)で昇順 Human-A/B: 参照訳 Human-P: 参照訳の言い換え
Online-A/B: オンライン翻訳 17
Crowd worker は人手翻訳 (HT) を過小評価している 翻訳者 (pSQM / MQM)が HT
を上位にランク している一方、crowd worker は中位〜下位 にランクすることがある。 pSQM / MQM の評価だと、HT と MT の品質 には依然として大きな差がある。 crowd worker は表面的な・簡単に評価できる 翻訳を好む • Human-P は参照訳の言い換えで、原文と 用語や構造が違うことが多い 18
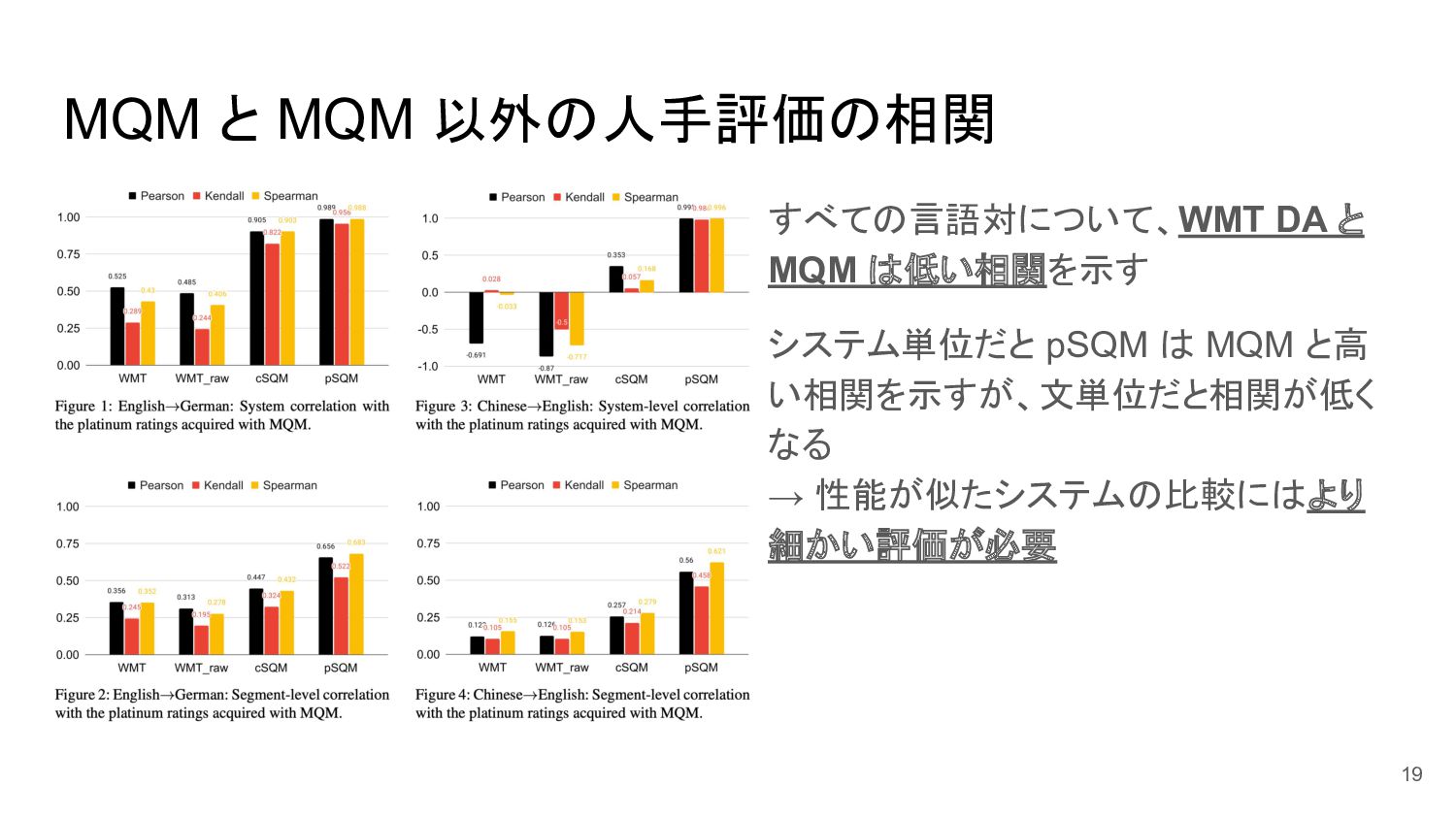
MQM と MQM 以外の人手評価の相関 すべての言語対について、WMT DA と MQM は低い相関を示す システム単位だと
pSQM は MQM と高 い相関を示すが、文単位だと相関が低く なる → 性能が似たシステムの比較にはより 細かい評価が必要 19
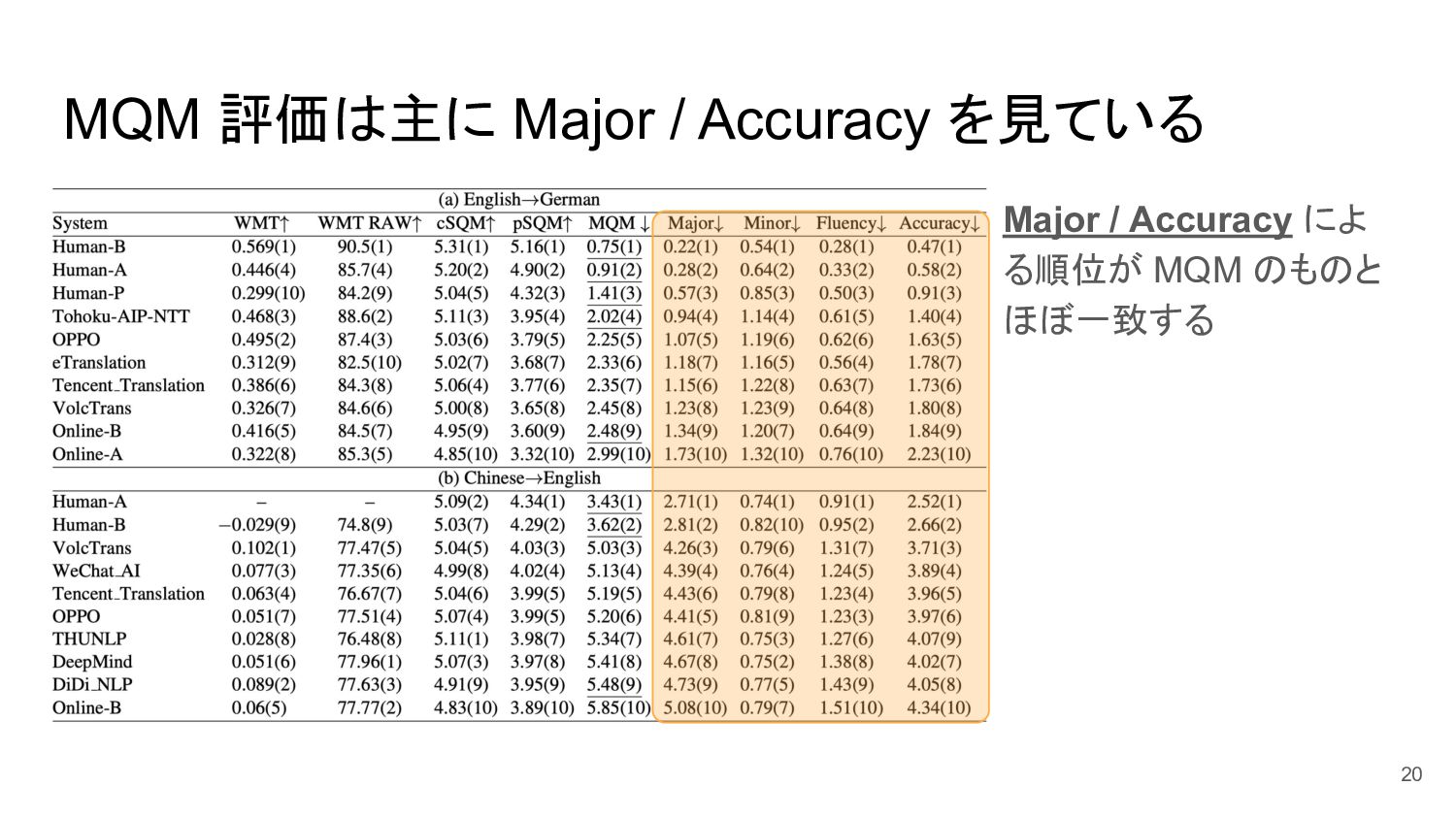
MQM 評価は主に Major / Accuracy を見ている Major / Accuracy によ
る順位が MQM のものと ほぼ一致する 20
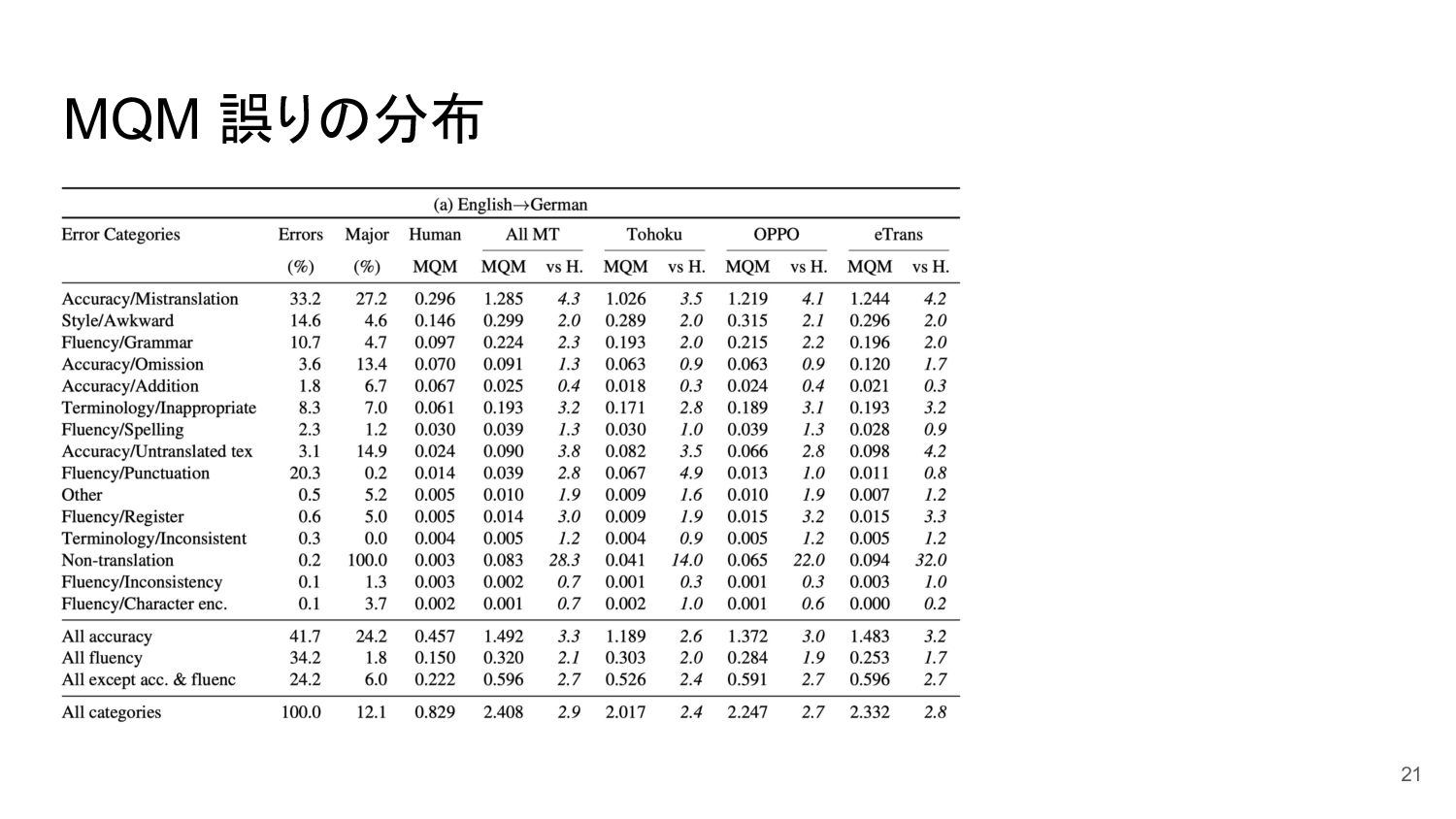
MQM 誤りの分布 21
MT の主な誤りは Mistranslation HT と比べ 4+ 倍 MQM スコアの半分を占め る
22
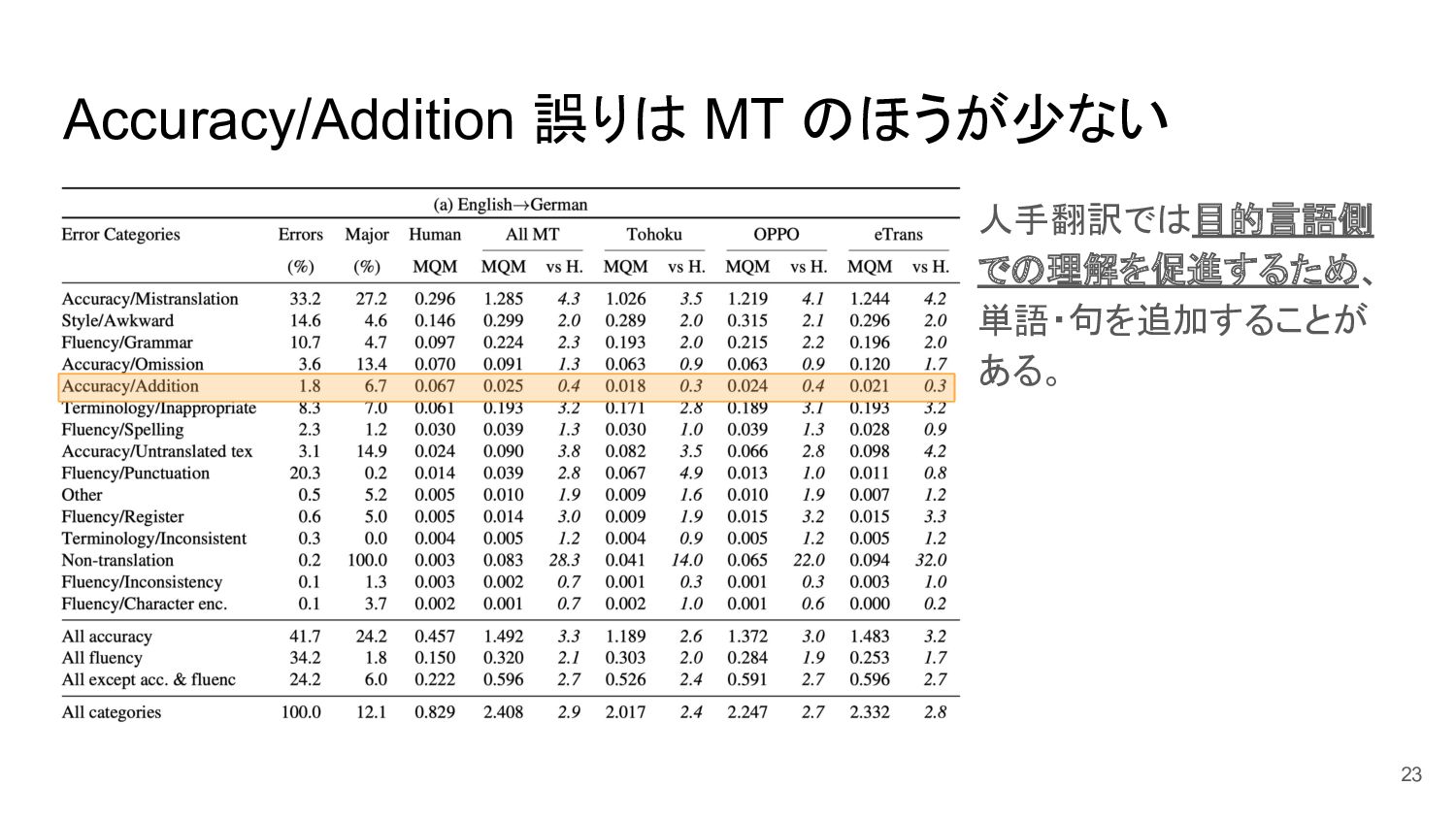
Accuracy/Addition 誤りは MT のほうが少ない 人手翻訳では目的言語側 での理解を促進するため、 単語・句を追加することが ある。 23
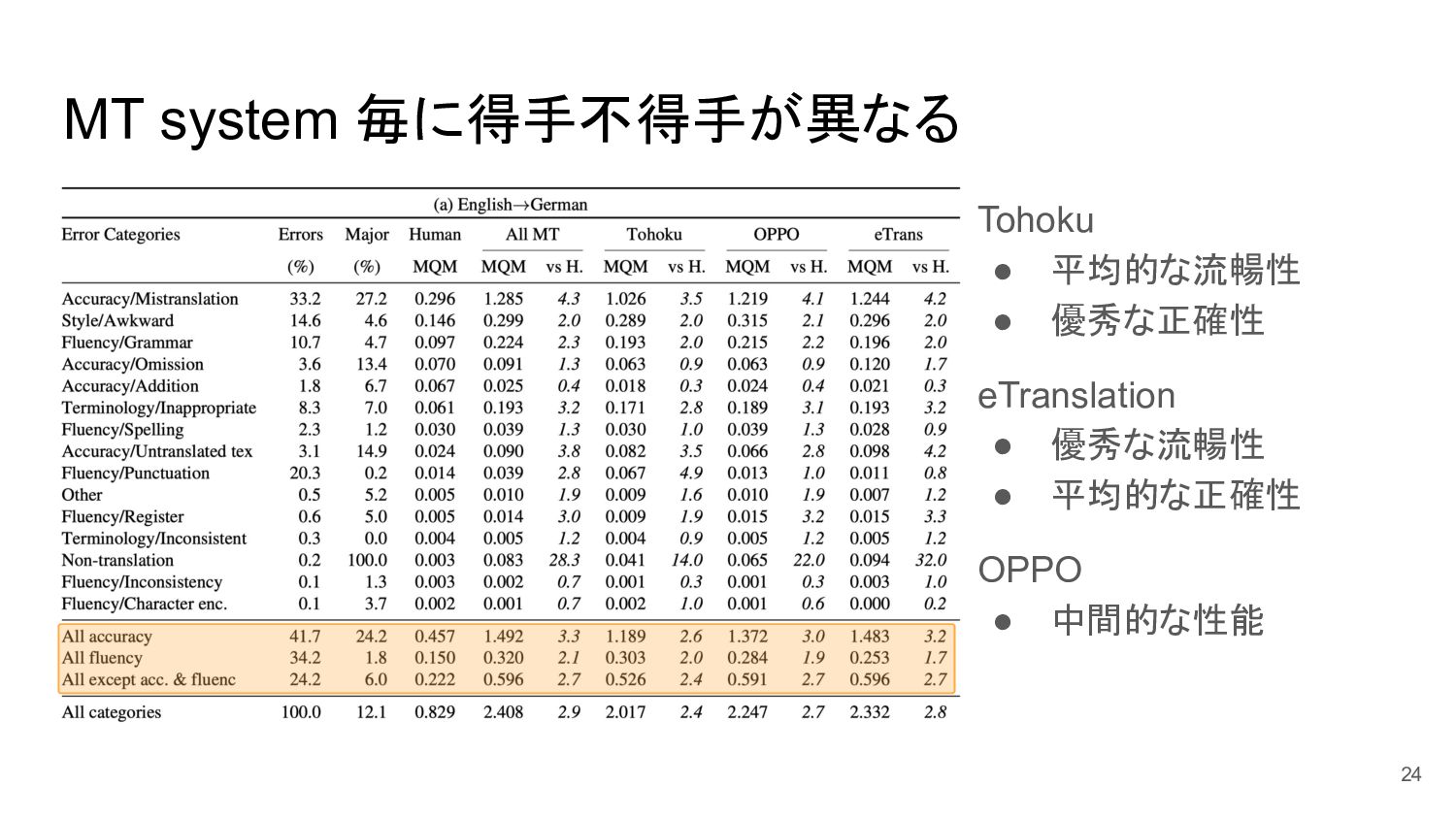
MT system 毎に得手不得手が異なる Tohoku • 平均的な流暢性 • 優秀な正確性 eTranslation •
優秀な流暢性 • 平均的な正確性 OPPO • 中間的な性能 24
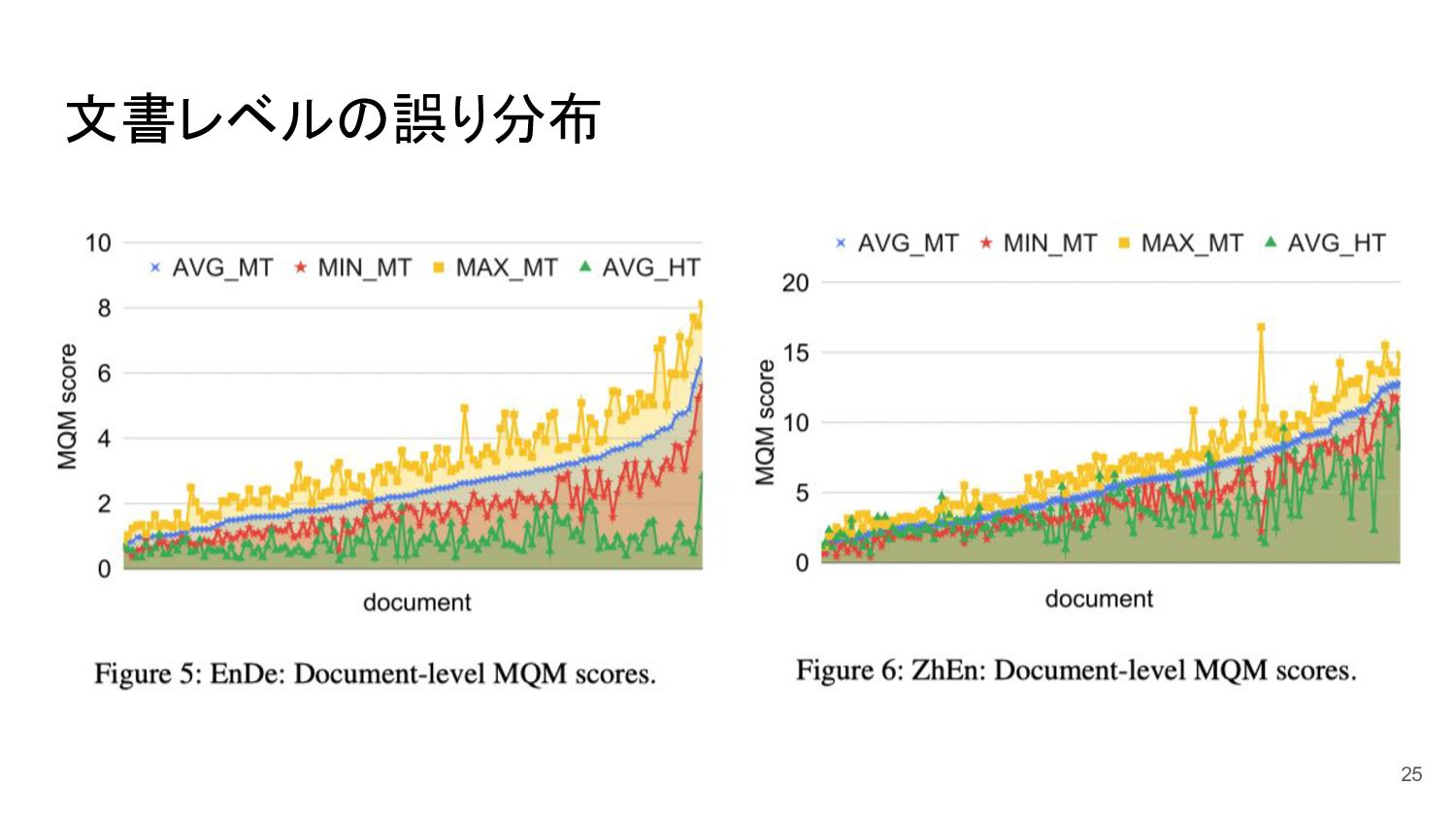
文書レベルの誤り分布 25
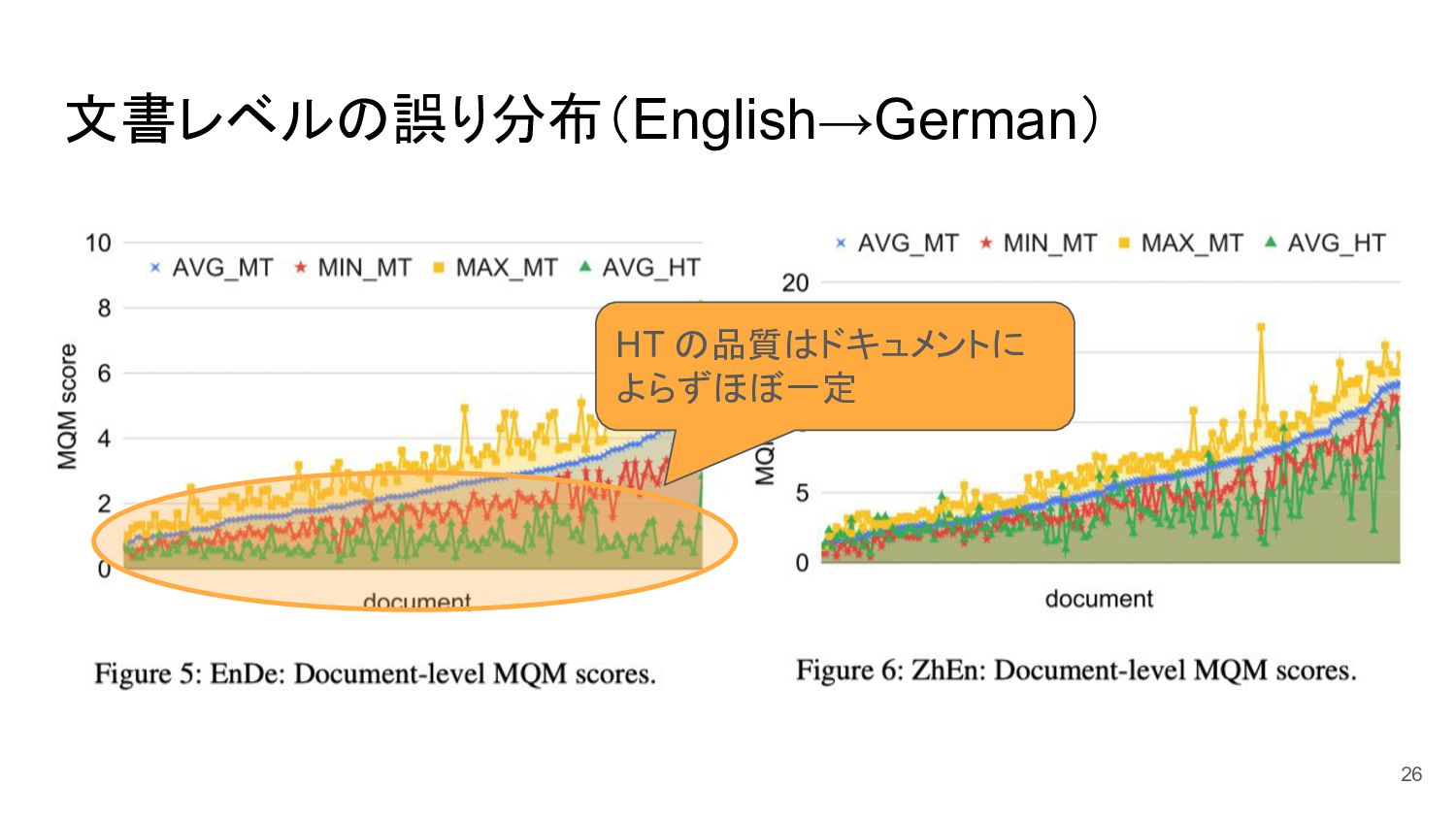
文書レベルの誤り分布(English→German) 26 HT の品質はドキュメントに よらずほぼ一定
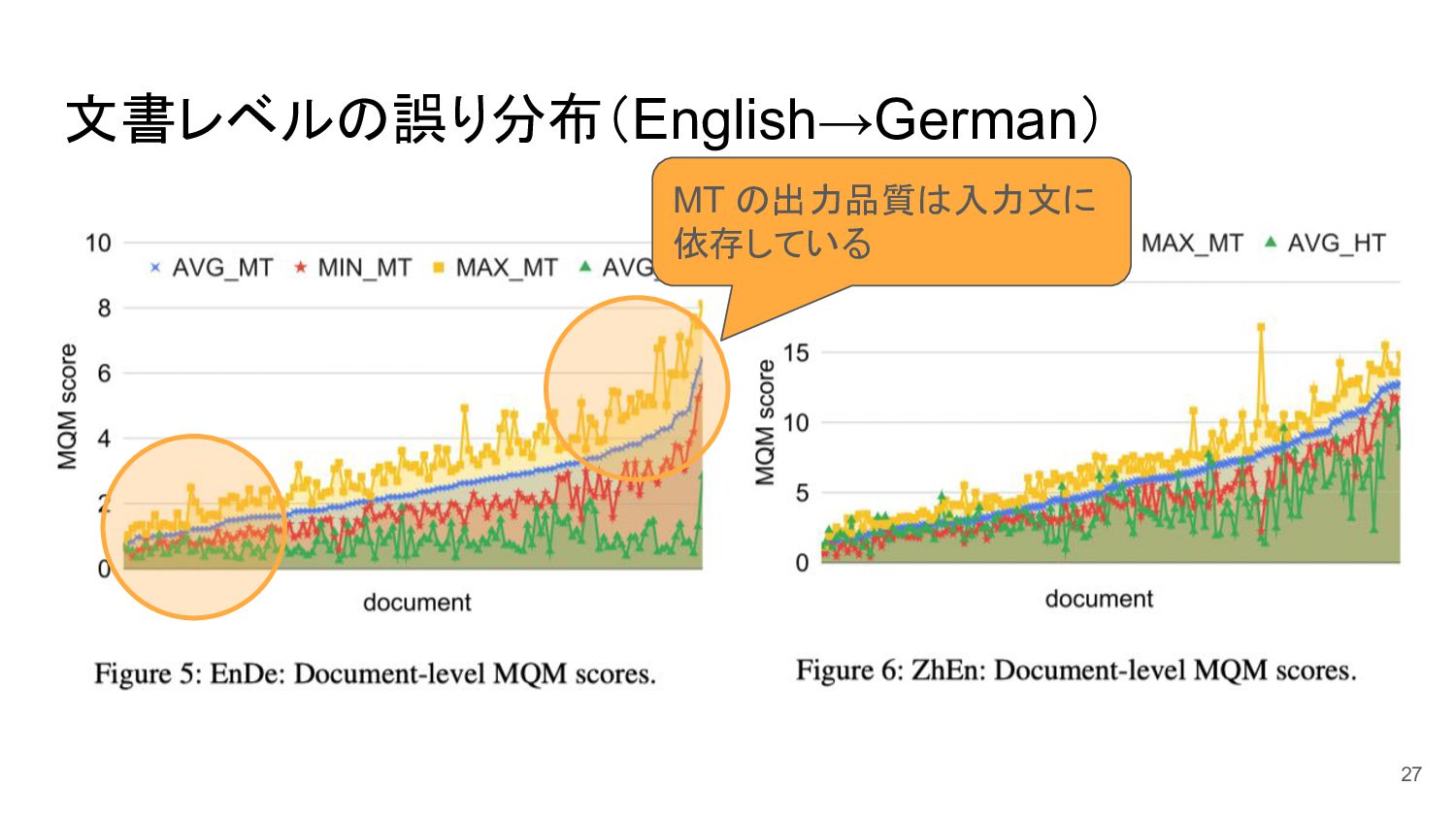
文書レベルの誤り分布(English→German) 27 MT の出力品質は入力文に 依存している
文書レベルの誤り分布(Chinese→English) 28 HT と MT の誤り分布が似 ている • 言語が遠いから? •
原文が政府系新聞の 記事でスタイルが翻訳 しにくい?
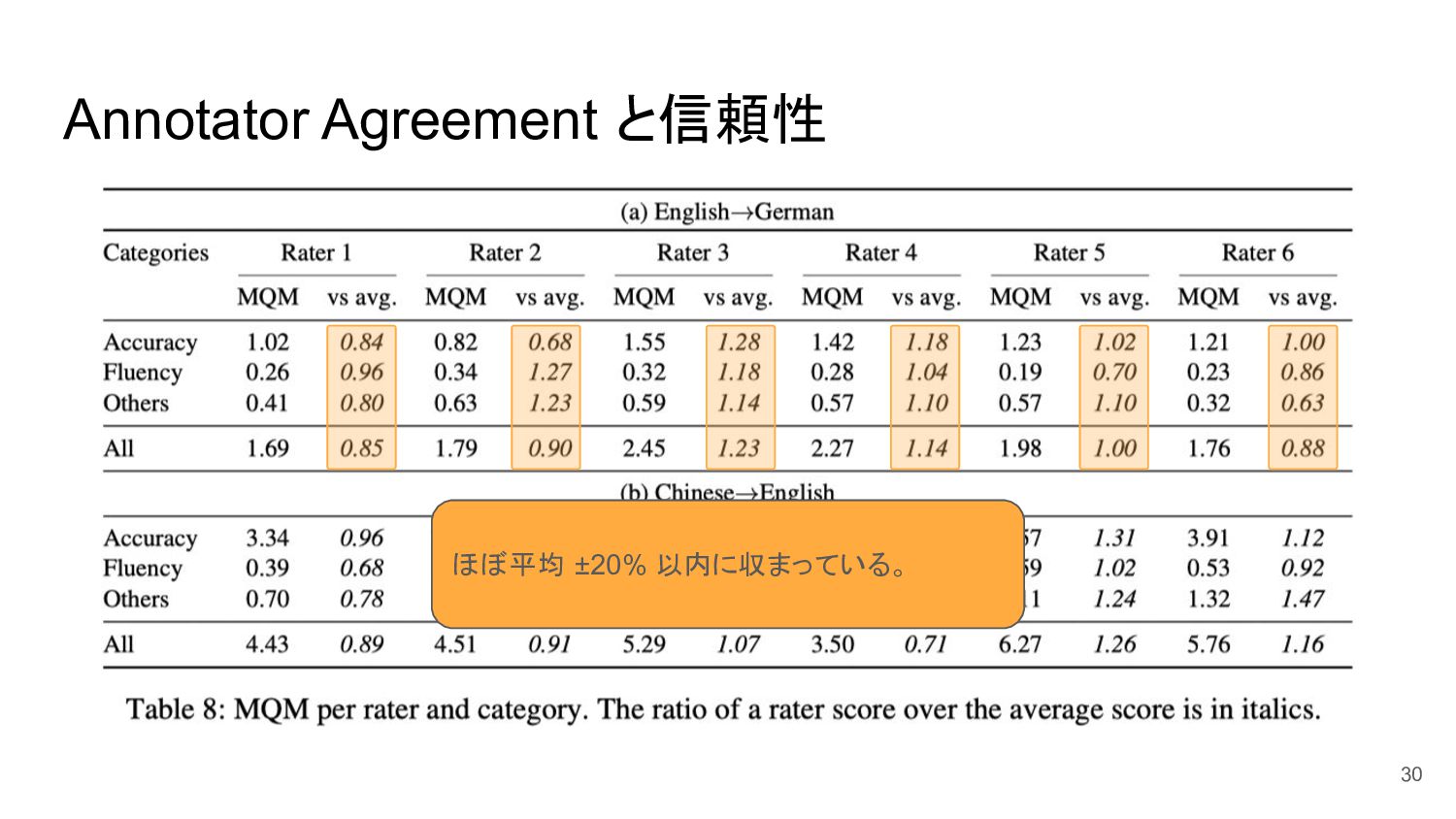
Annotator Agreement と信頼性 29
Annotator Agreement と信頼性 30 ほぼ平均 ±20% 以内に収まっている。
Annotator Agreement と信頼性 31 Annotator 間のスコア差は存在するが、 annotation models を使うことで訂正すること ができる。
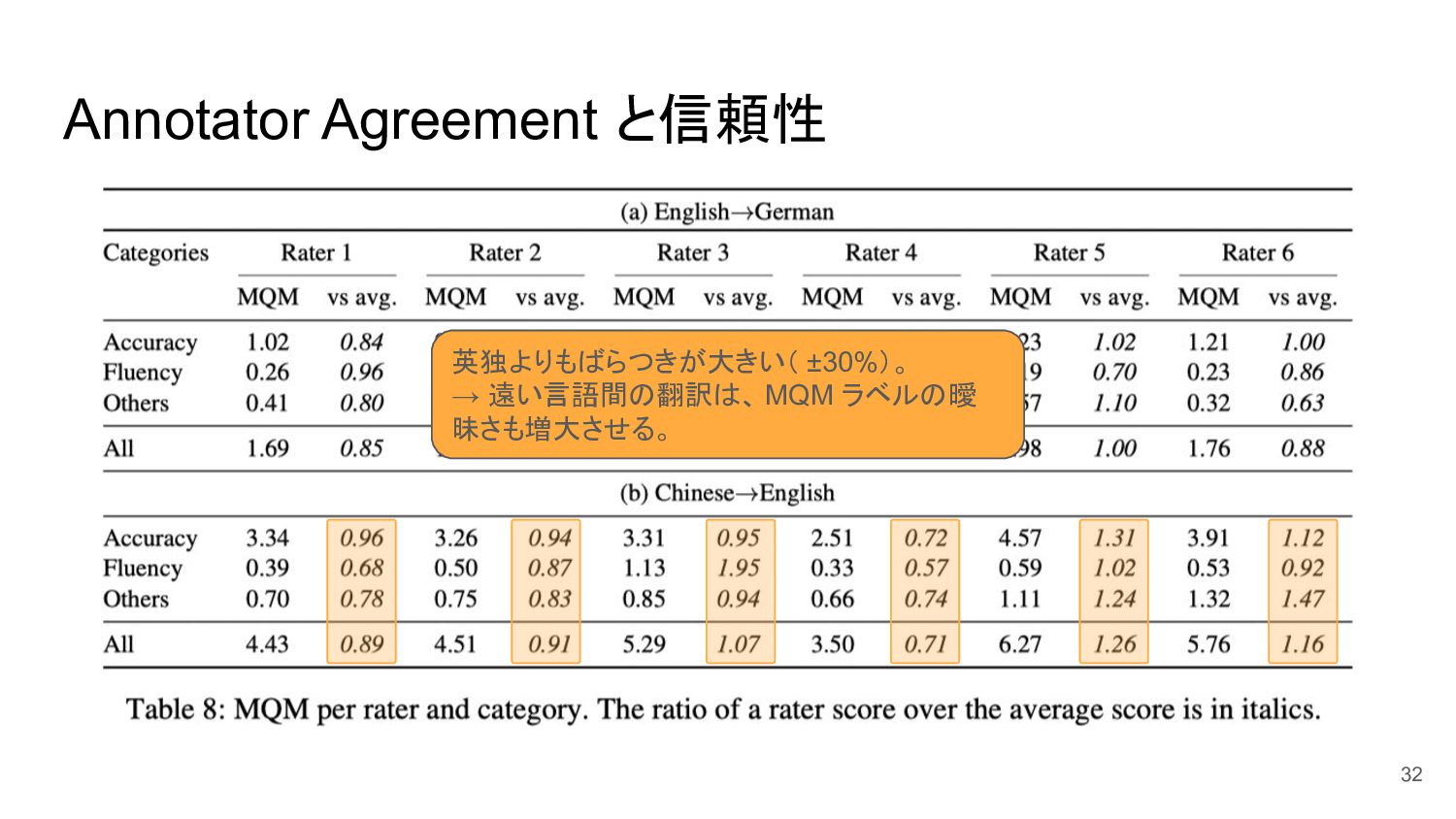
Annotator Agreement と信頼性 32 英独よりもばらつきが大きい( ±30%)。 → 遠い言語間の翻訳は、 MQM ラベルの曖
昧さも増大させる。
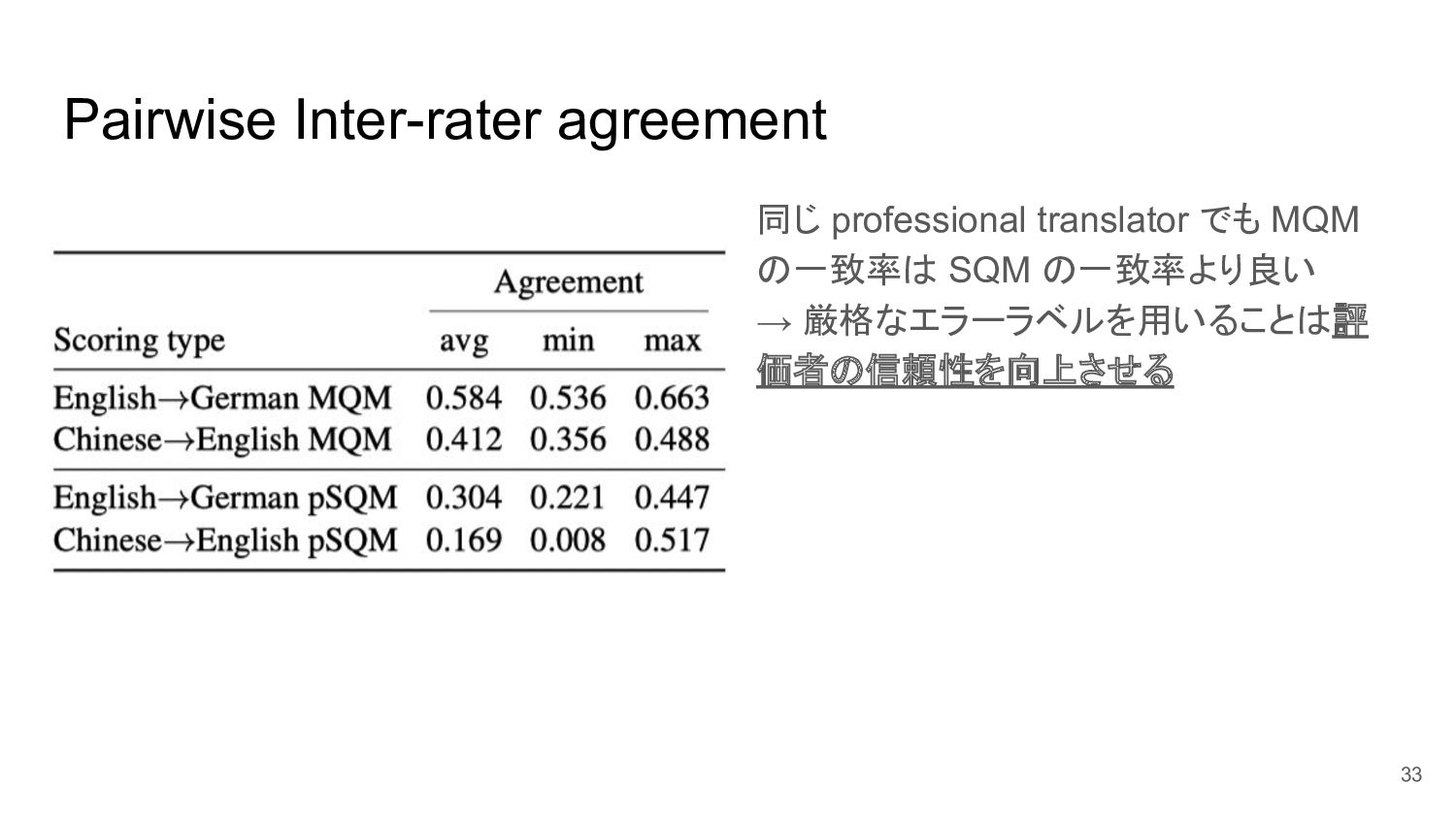
Pairwise Inter-rater agreement 同じ professional translator でも MQM の一致率は SQM
の一致率より良い → 厳格なエラーラベルを用いることは評 価者の信頼性を向上させる 33
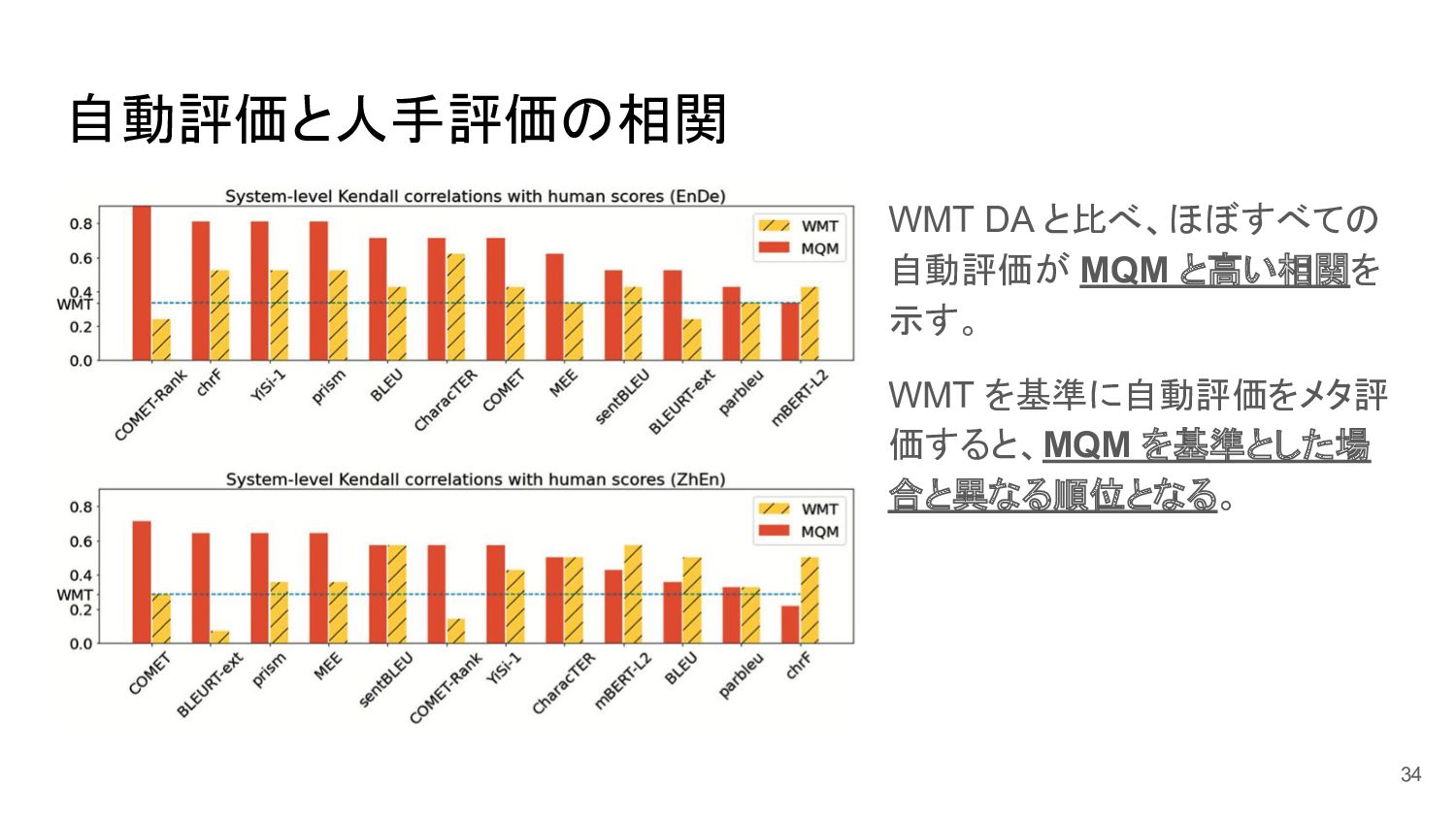
自動評価と人手評価の相関 WMT DA と比べ、ほぼすべての 自動評価が MQM と高い相関を 示す。 WMT を基準に自動評価をメタ評
価すると、MQM を基準とした場 合と異なる順位となる。 34
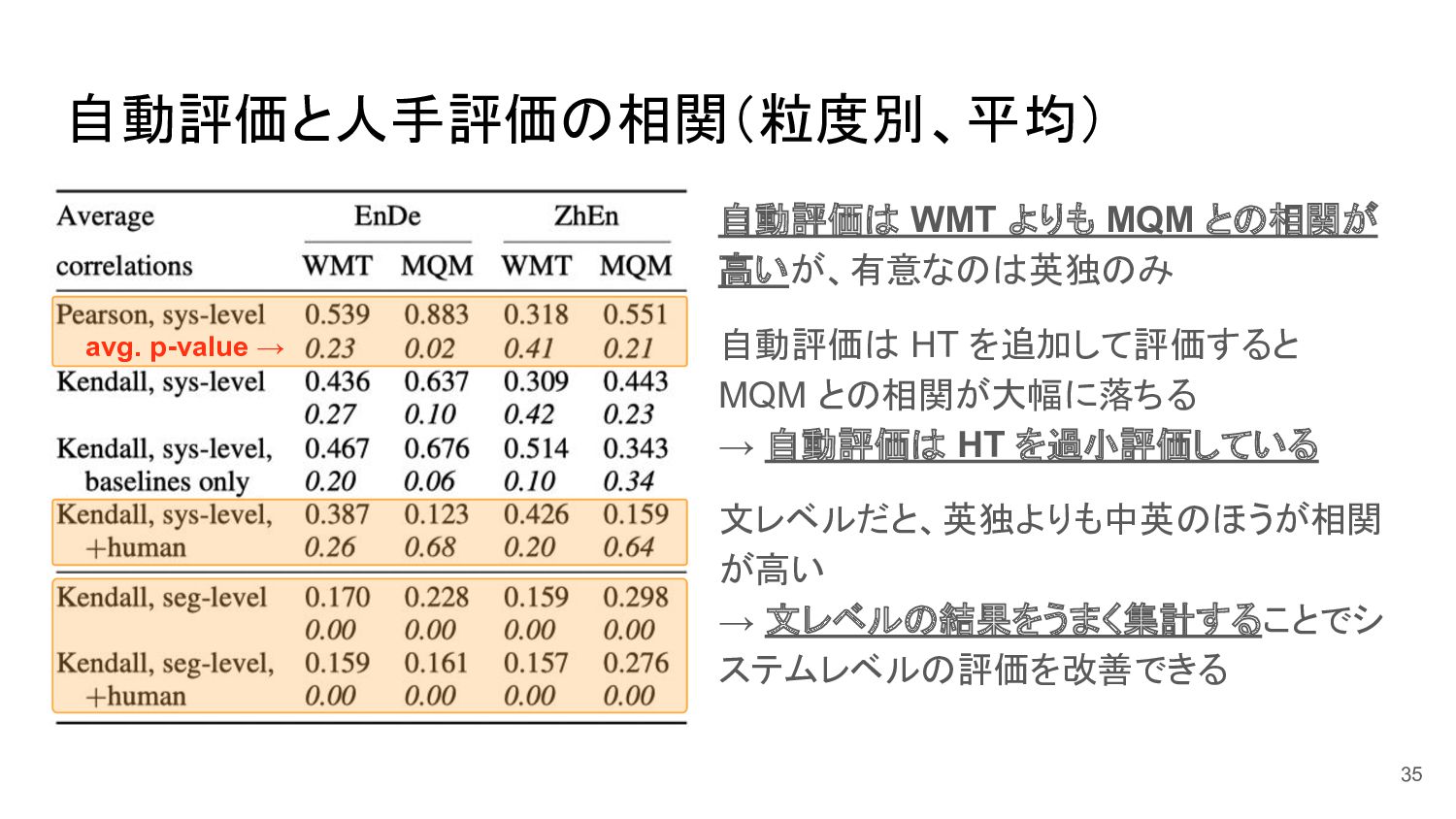
自動評価と人手評価の相関(粒度別、平均) 自動評価は WMT よりも MQM との相関が 高いが、有意なのは英独のみ 自動評価は HT を追加して評価すると
MQM との相関が大幅に落ちる → 自動評価は HT を過小評価している 文レベルだと、英独よりも中英のほうが相関 が高い → 文レベルの結果をうまく集計することでシ ステムレベルの評価を改善できる 35 avg. p-value →
結論 問題設定 • 正しく機械翻訳を評価できているか キモとなる技術や手法 • Professional translators による MQM
評価をプラチナとする • MQM 評価との相関で各評価手法の良し悪しを評価する 分かったこと • 人手翻訳(HT)は依然として機械翻訳(MT)よりも品質がよい • 自動評価は Crowd-worker による人手評価よりも、MQM との相関が高い 36
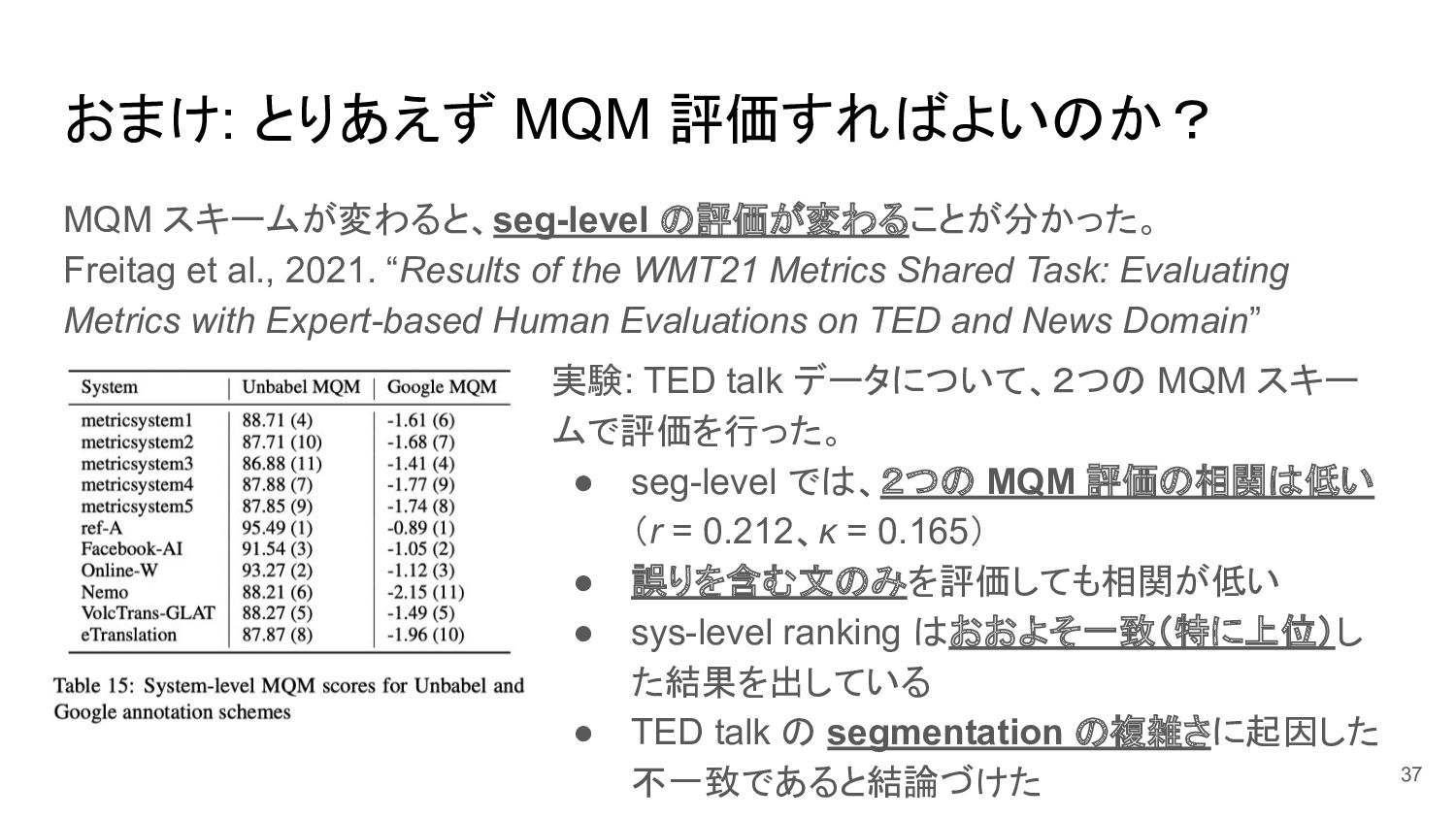
おまけ: とりあえず MQM 評価すればよいのか? MQM スキームが変わると、seg-level の評価が変わることが分かった。 Freitag et al.,
2021. “Results of the WMT21 Metrics Shared Task: Evaluating Metrics with Expert-based Human Evaluations on TED and News Domain” 実験: TED talk データについて、2つの MQM スキー ムで評価を行った。 • seg-level では、2つの MQM 評価の相関は低い (r = 0.212、κ = 0.165) • 誤りを含む文のみを評価しても相関が低い • sys-level ranking はおおよそ一致(特に上位)し た結果を出している • TED talk の segmentation の複雑さに起因した 不一致であると結論づけた 37
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}