Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Good for Misconceived Reasons: An Empirical Rev...
Search
tosho
September 09, 2021
Research
390
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Good for Misconceived Reasons: An Empirical Revisiting on the Need for Visual Context in Multimodal Machine Translation
第13回最先端NLP勉強会(SNLP2021)発表資料
tosho
September 09, 2021
More Decks by tosho
See All by tosho
LayerXにおけるセキュリティ管理の現在地と次の一手
tosho
0
360
Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation
tosho
0
330
Shaham and Levy, 2021. Neural Machine Translation without Embeddings. NAACL2021
tosho
0
140
Liu et al., 2021. Pay Attention to MLPs. arXiv
tosho
0
190
Huang et al. 2020 Unsupervised Multimodal Neural Machine Translation with Pseudo Visual Pivoting
tosho
0
500
Ive, Madhyastha, Specia_2019_EMNLP_Deep Copycat Networks for Text-to-Text Generation
tosho
0
170
Tan, Bansal_2019_EMNLP_LXMERT Learning Cross-Modality Encoder Representations from Transformers
tosho
0
280
Tsai et al._2019_ACL_Multimodal Transformer for Unaligned Multimodal Language Sequences
tosho
0
460
Zhou et al. 2019. Density Matching for Bilingual Word Embedding. NAACL
tosho
3
330
Other Decks in Research
See All in Research
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.5k
Ankylosing Spondylitis
ankh2054
0
180
量子コンピュータの紹介
oqtopus
0
360
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
280
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
340
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
10
8.4k
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
110
Featured
See All Featured
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
First, design no harm
axbom
PRO
2
1.2k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
The Limits of Empathy - UXLibs8
cassininazir
1
390
YesSQL, Process and Tooling at Scale
rocio
174
15k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
The untapped power of vector embeddings
frankvandijk
2
1.8k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Facilitating Awesome Meetings
lara
57
7k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Transcript
論文紹介: Good for Misconceived Reasons: An Empirical Revisiting on the
Need for Visual Context in Multimodal Machine Translation Zhiyong Wu, Lingpeng Kong, Wei Bi, Xiang Li, Ben Kao ACL 2021, https://aclanthology.org/2021.acl-long.480/ 発表者:平澤 寅庄(ひらさわ とうしょう) 東京都立大学小町研究室 D1 2021/9/16 第13回最先端NLP勉強会
注釈のない図表は論文から引用されたものです 2
この論文について 読んだ理由 • Multimodality のうれしみを評価する手法を知っておくのは重要 • 視覚情報の効果を同定しているが、その過程に興味があった 3
どんな論文か? タスク:マルチモーダル機械翻訳(言語+画像、言語+動画、etc) 分かったこと: • マルチモーダルな入力を使うことで正則化の効果を得られる • 既存のデータセットで訓練したモデルは視覚情報を無視する • 入力文がマスクされていると、モデルは視覚情報を活用する 4
関連研究:マルチモーダル機械翻訳 言語+画像 言語+動画 5 図は Barrault et al., 2018. Findings
of the Third Shared Task on Multimodal Machine Translation. WMT より引用 図は Wang et al., 2019. VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research. ICCV より引用
Adversarial Evaluation [Elliott, 2018] 問題点 • 直感的ではない • 正規化、データバイアスなどの影響が明らかでない モデルの
image awareness を評価 • 正しい (congruent) 画像を使用した性能と 正しくない (incongruent) 画像を使用した 性能の差を評価 • モデルの学習は congruent な画像を使用 関連研究:モデルは“マルチモーダル”なのか? 6 図は Elliott, 2018. Adversarial Evaluation of Multimodal Machine Translation. EMNLP より引用
視覚情報の関わりを明らかにするために 実験の方針 1. 入力文と視覚情報の特徴量を Gate する機構を持つ、2つのマルチモーダル 機械翻訳モデルを訓練する ◦ Gated fusion
multimodal machine translation (MMT) model ◦ Retrieval-Augmented MMT 2. 正則化を働きをする手法を同じモデルに適用し、同様に訓練する 3. Gate の動きを比較する 7
モデル1:Gated Fusion MMT Language encoder の出力に、線形変換した視覚特徴量を重み付きで加える 8 画像
モデル2:Retrieval-Augmented MMT (RMMT) 入力文をクエリに検索した視覚情報を入力に使うモデル 1. 入力に関連する画像を検索し top-K (K=5) を取得する (
Z ) 2. f_θ(∗)を用いて、抽出した Z をベクトル表現に変換する ◦ max-pooling over elements を使用 3. 変換した特徴量を用いて Gated fusion NMT と同様に計算する 9 画像 set max-pooling
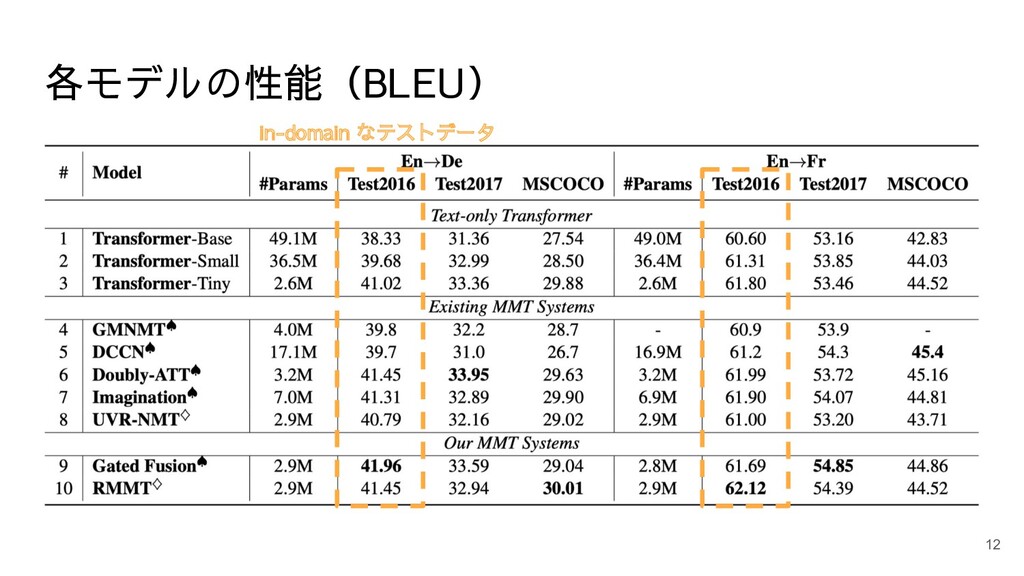
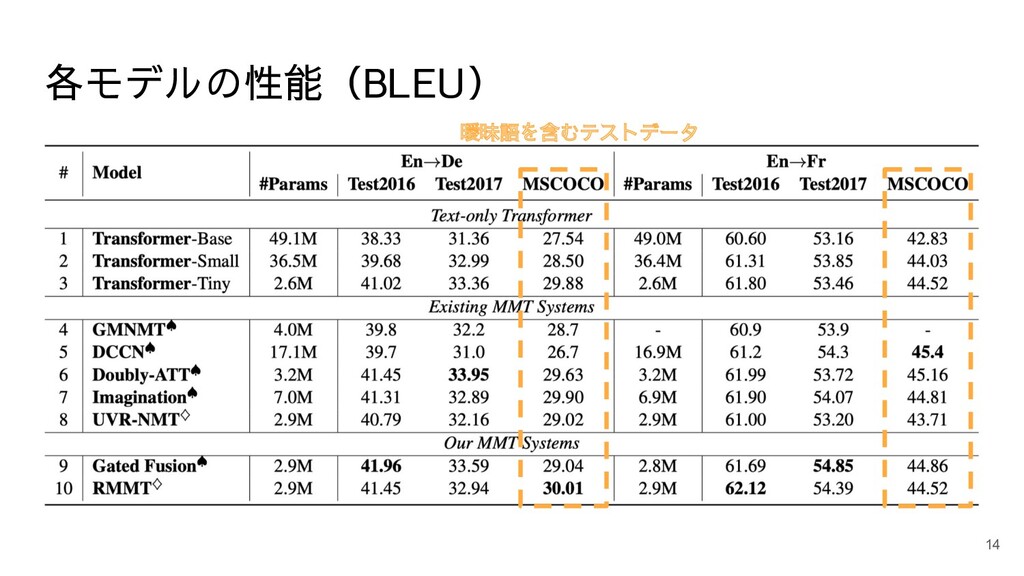
実験設定 データセット:Multi30k, MSCOCO test set(曖昧語を含むテストセット) 画像検索モデル:Flickr30k で学習 ベースライン: • Transformer
(base, small, tiny) • Conventional MMT models (Doubly-ATT, Imagination) • Retrieval-based MMT model (UVR-NMT) • Graph-based MMT model (GMNMT) • Dynamic context-guided capsule network (DCCN) 10
各モデルの性能(BLEU) 11
各モデルの性能(BLEU) 12 in-domain なテストデータ
各モデルの性能(BLEU) 13 少し domain shift したテストデータ
各モデルの性能(BLEU) 14 曖昧語を含むテストデータ
各モデルの性能(BLEU) 15
MMTモデルは画像を見ているのか? Gate の重み (Λ) のマイクロ平均を計算 入力文・トークン毎の重みを平均 • 大きい → 視覚情報を使う
• 小さい → 視覚情報を使わない Gated Fusion / RMMT の両モデル で非常に小さな値になる • 1e-10 より大きい重みはなし 結論: モデルは推論時に視覚情報を使って いない 16
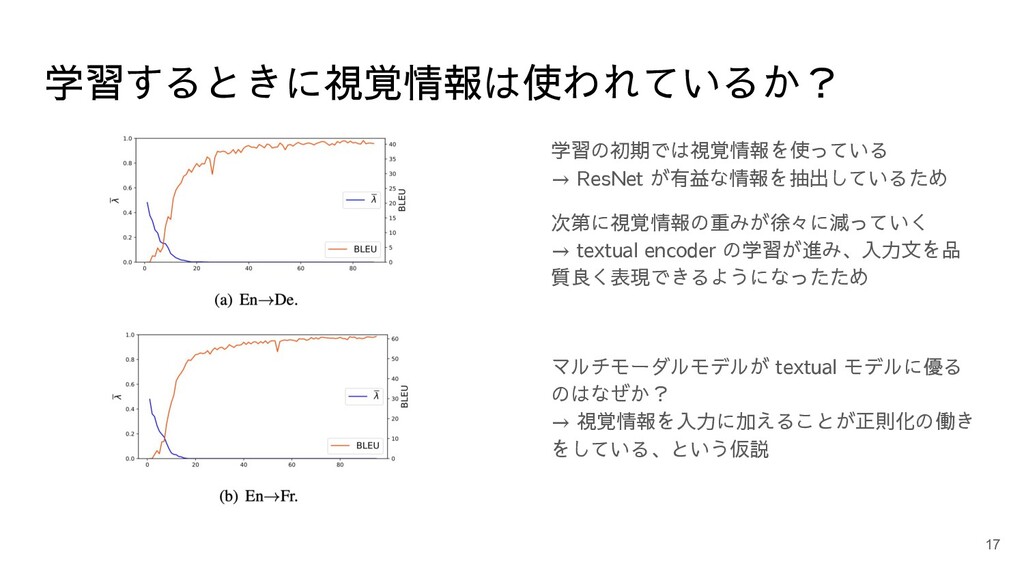
学習するときに視覚情報は使われているか? 学習の初期では視覚情報を使っている → ResNet が有益な情報を抽出しているため 次第に視覚情報の重みが徐々に減っていく → textual encoder の学習が進み、入力文を品
質良く表現できるようになったため マルチモーダルモデルが textual モデルに優る のはなぜか? → 視覚情報を入力に加えることが正則化の働き をしている、という仮説 17
正則化であることを検証するために 正則化で使われる2つの手法を使った場合の結果と比較する • Random noise injection → Gaussian でランダムな視覚特徴量を生成 •
Weight decay 18
実験結果(Random noise injection) Gate の重み (Λ):ResNet=97.7, Random Noise=95.2 → Random
noise は視覚特徴量の結果が類似している → 視覚情報は random noise と同様の働き(=正則化)をしている 19 (カッコ内は画像特徴量を使った場合からの差分)
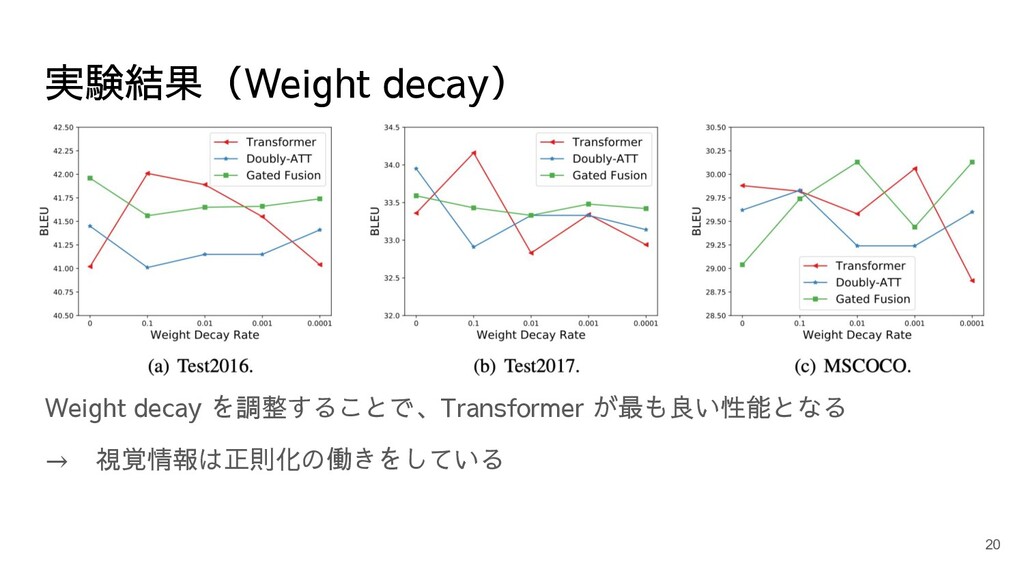
実験結果(Weight decay) Weight decay を調整することで、Transformer が最も良い性能となる → 視覚情報は正則化の働きをしている 20
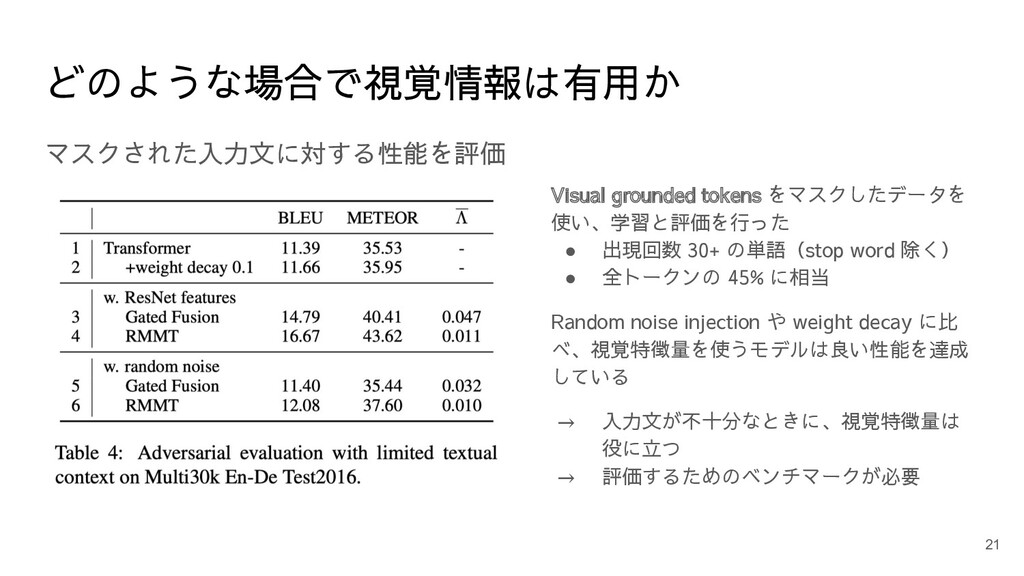
どのような場合で視覚情報は有用か マスクされた入力文に対する性能を評価 Visual grounded tokens をマスクしたデータを 使い、学習と評価を行った • 出現回数 30+
の単語(stop word 除く) • 全トークンの 45% に相当 Random noise injection や weight decay に比 べ、視覚特徴量を使うモデルは良い性能を達成 している → 入力文が不十分なときに、視覚特徴量は 役に立つ → 評価するためのベンチマークが必要 21
議論 1.新しいベンチマークが必要である • Multi30k は翻訳として簡単なデータセットである 2.提案手法は新しいベンチマークの verification に使用できる 3.視覚特徴量抽出器の選択は重要である •
抽出器の精度は町モーダル機械翻訳モデルの性能に大きく影響する 22
まとめ • マルチモーダルな入力を使うことで正則化の効果を得られる • 既存のデータセットで訓練したモデルは視覚情報を無視する • 入力文がマスクされていると、モデルは視覚情報を活用する 今後は • 視覚情報が必要とされるようなベンチマークが必要
23
読んだ感想 • 現在のベンチマーク(Multi30k)では、十分にモデルのマルチモダール性を 評価できない、というのは納得感がある • 視覚情報を使うことの効果が、正則化であることがまだつながらない ◦ 正則化であるなら、Test2016 での性能向上よりも、domain shift
した Test2017 や曖昧語を 含む MSCOCO での性能向上が顕著に現れても良さそうだが、そうではない • モデルの特性とデータセットの特性をどうやって切り分けるのだろうか? ◦ 現在のベンチマークで multimodality を活用できないのは、データセットが原因なのか、 それとも、(単純化された)モデルが原因なのか? ◦ 先行研究で Doubly-Att は高い image awareness を持つことは示されている 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Adversarial Evaluation [Elliott, 2018] 問題点 • 直感的ではない • 正規化、データバイアスなどの影響が明らかでない モデルの](https://files.speakerdeck.com/presentations/907d5f57b59140848975bd0014e81e54/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}