framework ◦ Based on transformer network ◦ Do not use coverage penalty • Better performance wrt ◦ novel n-gram generation rate (higher is better) ◦ repetition rate (lower is better) • Dual-source setting: Automatic post-editing task ◦ Conditioned on two inputs and copy from either of them ▪ Source language ▪ Original machine translation
et al., 2017] ◦ Reinforcement learning ▪ ROUGE and maximum likelihood [Paulus et al., 2017] ▪ Global quality estimator [Li et al., 2018] ◦ Content selection [Gehrmann et al., 2018] • Automatic Post-Editing (APE) ◦ Machine translation [Simard and Foster, 2013] ◦ Multi-source transformer architectures [Junczys-Dowmunt and Grundkiewicz, 2018] ◦ Requires large-scale dataset: unrealistic scenarios ◦ SOTA APE models modify ~30% of inputs [Chatterjee et al., 2018] ▪ Only 50% of modification are positive changes
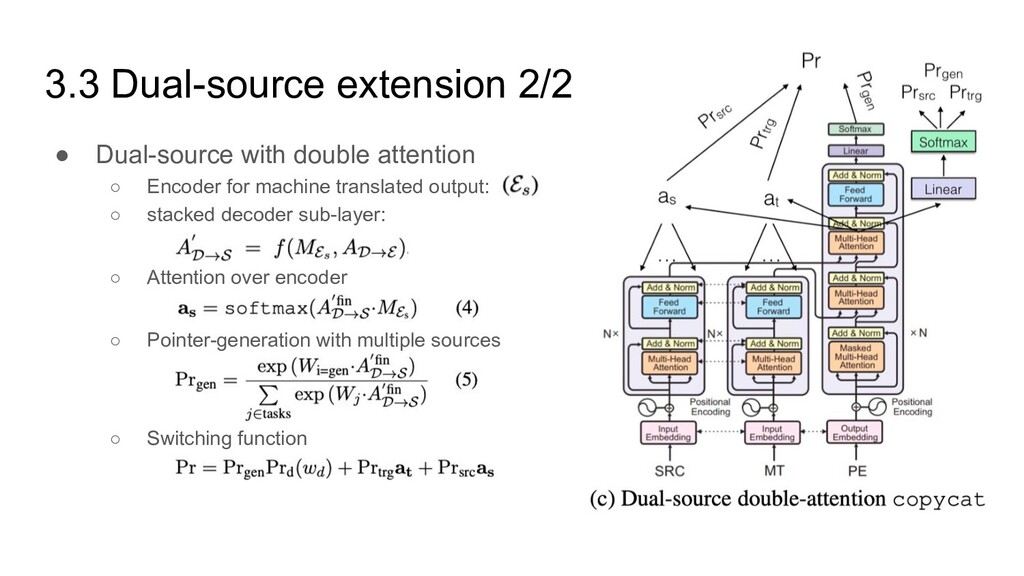
• Attention over encoder ◦ Dot product attention ◦ States of last decoder layer, just before Norm. layer • Generation probability ◦ sigmoid function ◦ States of last decoder layer, just before Norm. layer ◦ Interpolation of decoder’s probability and copy probability
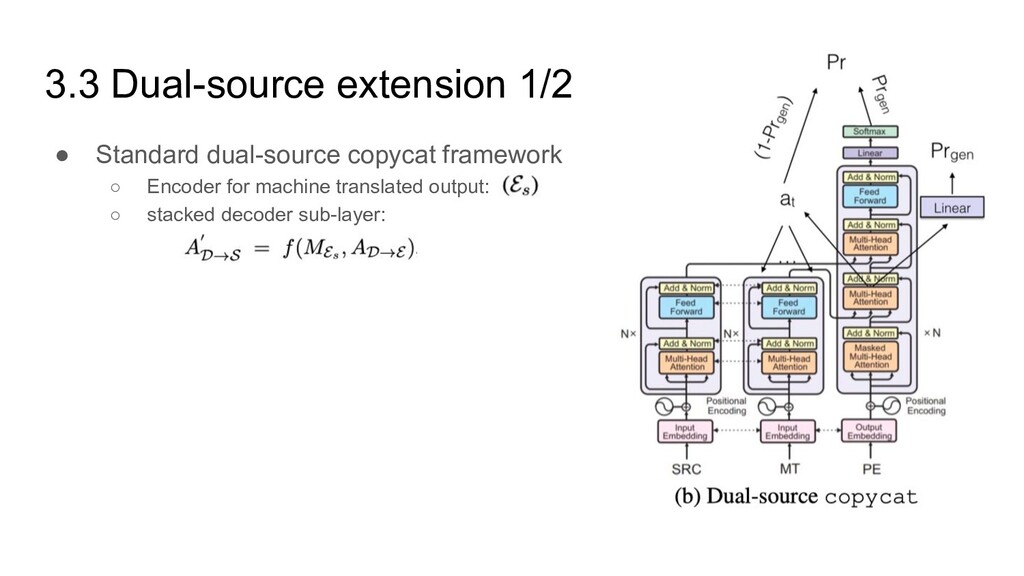
Encoder for machine translated output: ◦ stacked decoder sub-layer: a ◦ Attention over encoder a ◦ Pointer-generation with multiple sources a ◦ Switching function
dataset [Hermann et al., 2015; Nallapati et al., 2016] ◦ Online news articles (800 tokens on average) and their abstracts (60 tokens on average) ◦ 300k for training, 13k for validation, 11k for test ◦ BPE with 32k, truncate articles to 400 subwords • APE: two variants ◦ English-German (En-De): WMT18/WMT19 APE shared task (IT domain) ▪ translated by a NMT system (45.8 BLEU) ▪ 13k for training, 1k for validation, 1k for test ◦ English-Latvian (En-Lv): life sciences domain [Specia et al., 2018] ▪ Translated by a NMT system (38.4 BLEU) ▪ 13k for training, 1k for validation, 1k for test
for APE ◦ HTER [Snover et al., 2009] ▪ The minimum number of edits (substitution, insertion, deletion and shift) ▪ 0.15 HTER for En-De, 0.29 HTER for En-Lv on average ◦ BLEU [Papineni et al., 2002] ▪ n-gram precision between MT hypotheses and post-edits • Hyperparameters ◦ Shared embedding with enc./dec. ◦ beam search of size 5 (Summarisation), 10 (APE) ◦ Adam optimizer ▪ initial learning rate of 0.044, 4k warmup steps (Summarisation) ▪ initial learning rate of 0.050, 8k warmup steps (APE) ◦ Batch size of 50 ◦ Early stopping: patience of 10 epochs based on ROUGE-L (Summarisation) and BLEU (APE)
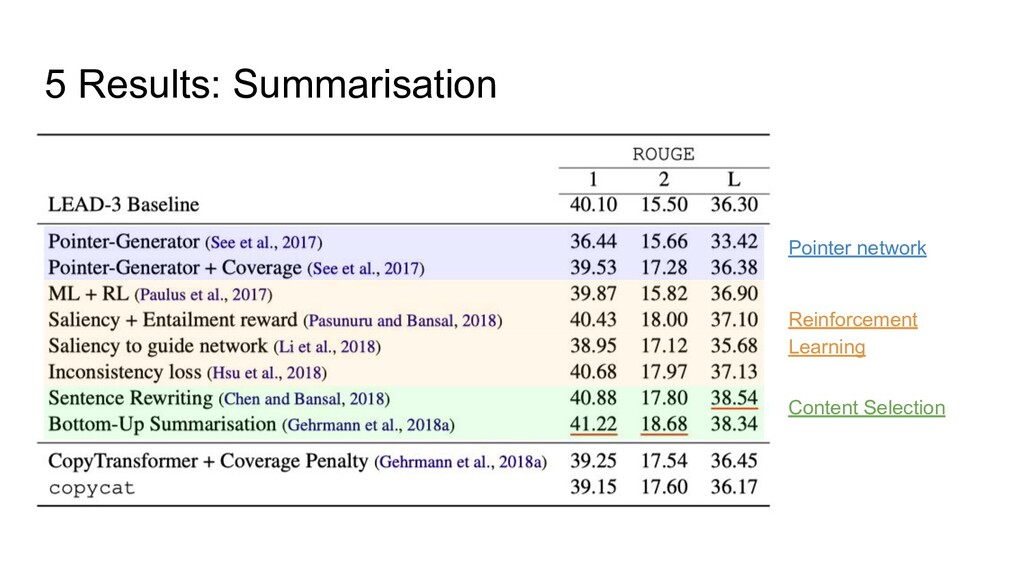
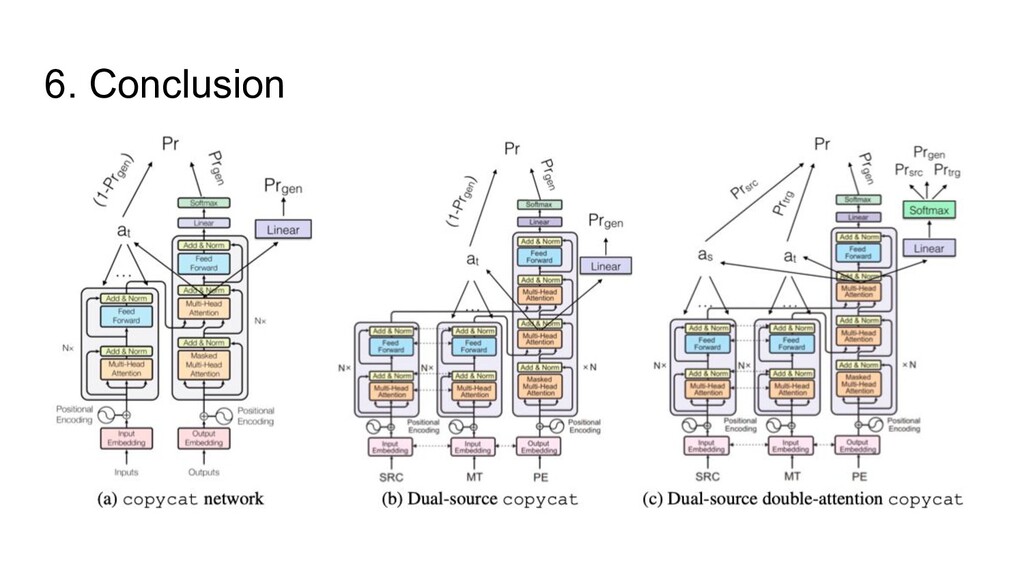
PNT-TRG: copycat with attention over the MT • PNT-TRG+SRC: copycat with double attention • Pre-training model is mandatory ◦ Pre-train models on synthetic data by randomly deletion, insertion, shift, substitution target side sentence in parallel corpus wrt HTER score in APE dataset ◦ eSCAPE corpus (En-De) ◦ Europarl and EMEA corpora (En-Lv) ◦ Fine-tuning with learning rate of 0.001 • The performance of copycat systems depends on the difficulty of the task ◦ Minor improvement for German • Major post-edits ◦ punctuation (e.g., deletion of a comma) ◦ auxiliary words (e.g., insertion/deletion of prepositions or articles) eSCAPE: a Large-scale Synthetic Corpus for Automatic Post-Editing EMEA: European Medicines Agency
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pointer-Generator Network [See et al., 2017]](https://files.speakerdeck.com/presentations/8a1e57c7d2584c8691fea0a86e38963d/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}