The Blavatnik School of Computer Science, Tel Aviv University ♠ Facebook AI Research NAACL 2021 紹介者: Tosho Hirasawa (小町研D1) 2021/07/05 @小町研 EACL/NAACL 2021 論文読み会
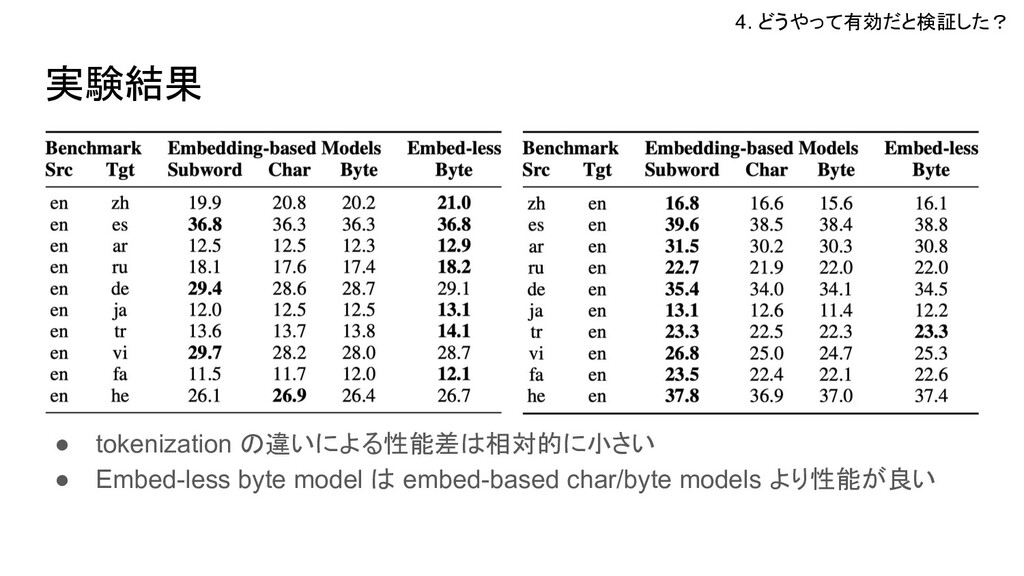
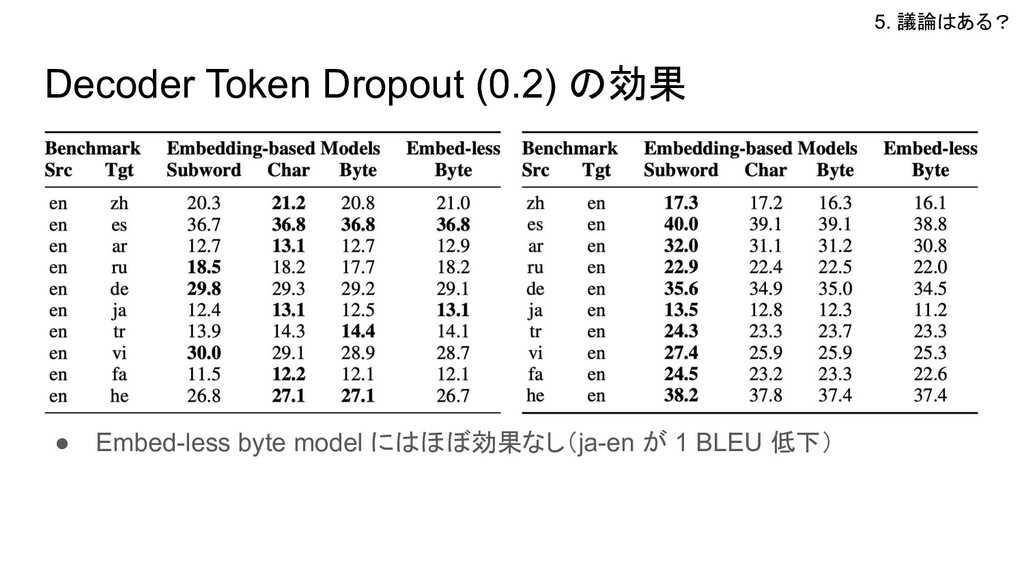
= zh, es, ar, ru, de, ja, tr, vi, fa, he) ベースライン: 3 Transformer models (Fairseq, 6 layers, 4 heads, 512d, 1024d ffn) • BPE-based model (10k merge operations) • character-based model • byte-based model w/ embedding Training: Adam, 4k warmup steps, 5e-4 lr, (0.2 or 0.3 dropout?,) batch of 64k byte average top 5 checkpoints in 50k steps Evaluation: SacreBLEU (case-sensitive), use the raw text as the reference 4. どうやって有効だと検証した?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}