(usually, no image overlap) • Test: L1-Img-L2 • Introduce three new loss from: • Multilingual visual-semantic embedding • Pivoted Captioning for Back-Translation • Povited Captioning for Paired-Translation • SOTA for unsupervised multimodal MT on Multi30K 1
of the source and target languages by using visual as pivot • VSE objective: Max-margin loss w/ negative sampling • Compute similarity of two sequences 6
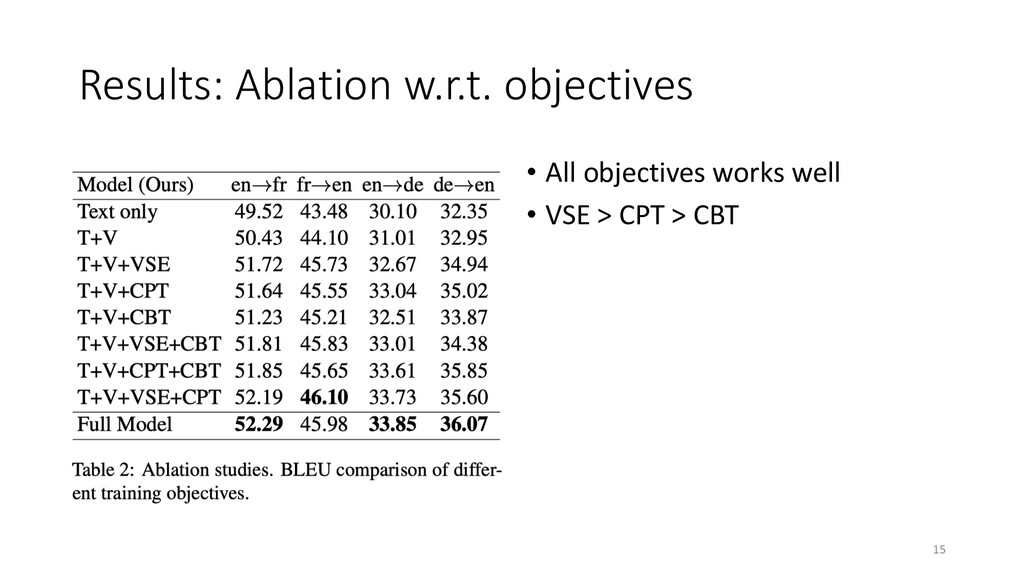
weight for each loss • BUT, loss for CPT will decrease according to a scheduler • Decrease weight from 1.0 to 0.1 at 10-th epoch • Avoid training on noisy captions in laterstage of training 9
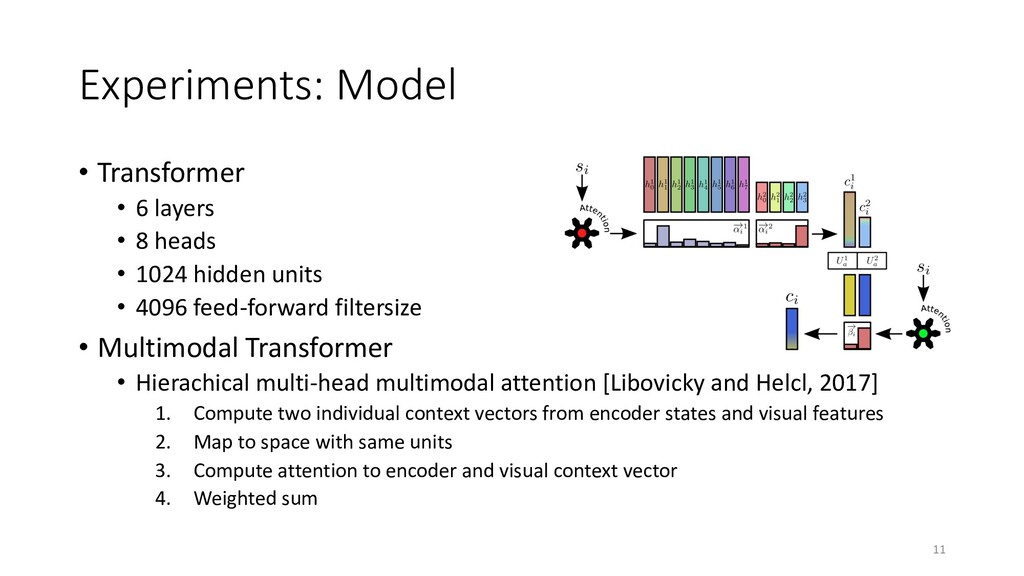
• 1024 hidden units • 4096 feed-forward filtersize • Multimodal Transformer • Hierachical multi-head multimodal attention [Libovicky and Helcl, 2017] 1. Compute two individual context vectors from encoder states and visual features 2. Map to space with same units 3. Compute attention to encoder and visual context vector 4. Weighted sum 11
Crawl from 2007 to 2017 • 10M data for English/German/French • Objective: Masked seq-to-seq objective • Pre-train captioning model • Dtaset: MS-COCO • 56,643 images and 283,215 captions for English • Use Google Translate to generate German/French translations • Objective: 12
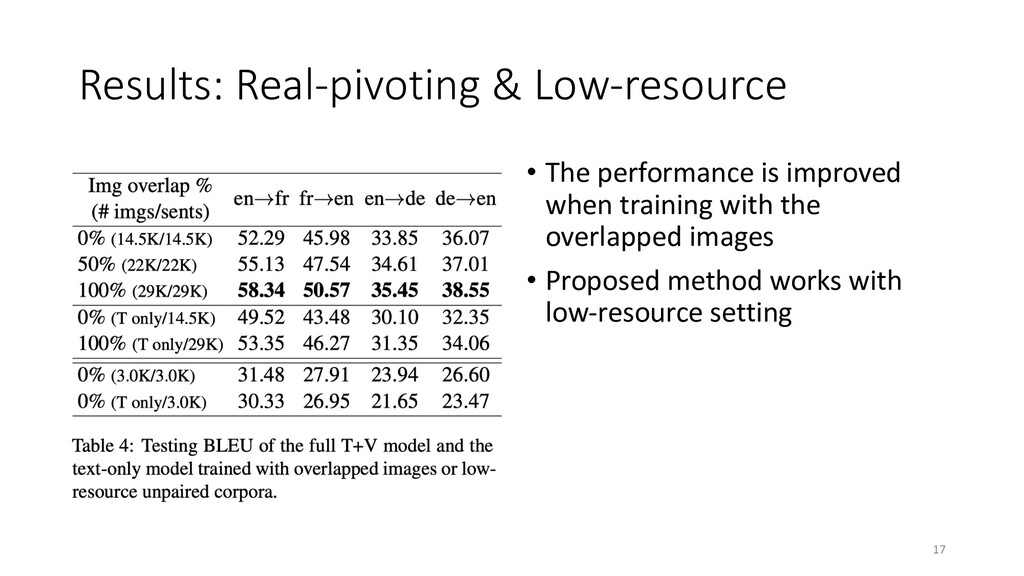
VSE is the key component to use visual information • Full model is more sensitive with images (-0.65 BLEU) than model w/o VSE (-0.25 BLEU) 16 Results with images:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}