Shaojie Bai, Paul Pu Liang, J. Zico Kolter, Louis-Philippe Morency, Ruslan Salakhutdinov Carnegie Mellon University ACL 2019 紹介者:平澤 寅庄(TMU, M1, 小町研) 28 October, 2019 @小町研
2,199 short monologue video clips • Label: -3 (strongly negative) to 3 (strongly positive) CMU-MOSEI: sentiment and emotion analysis dataset • 23,454 movie review video clips • Label: -3 (strongly negative) to 3 (strongly positive) IEMOCAP: human emotion analysis (Busso et al., 2008) • 10K videos • Label: happy, sad, angry and neutral (multilabel) (Zadeh et al., 2018) (Zadeh et al., 2016) 13
{kind=link}
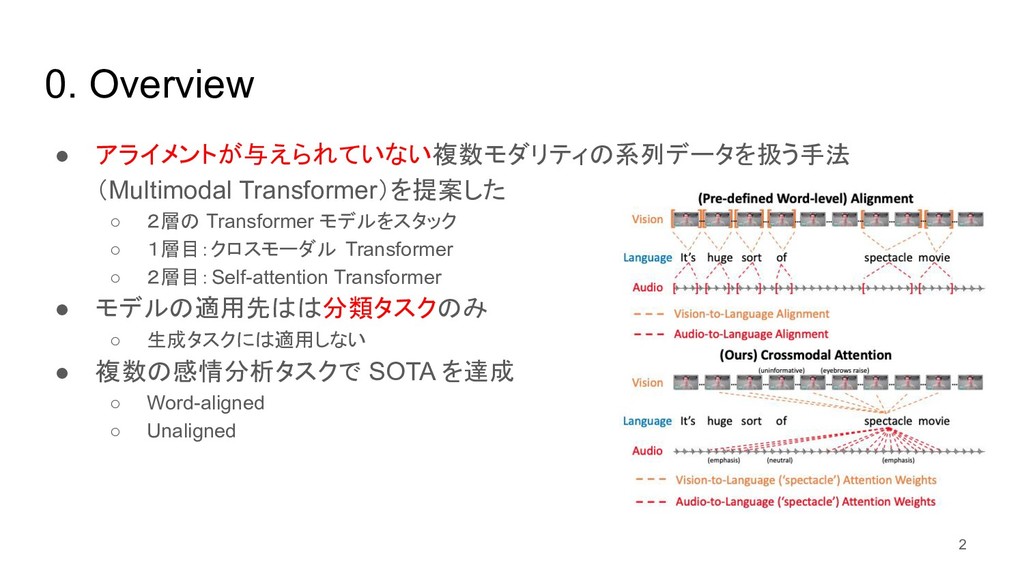{kind=link}
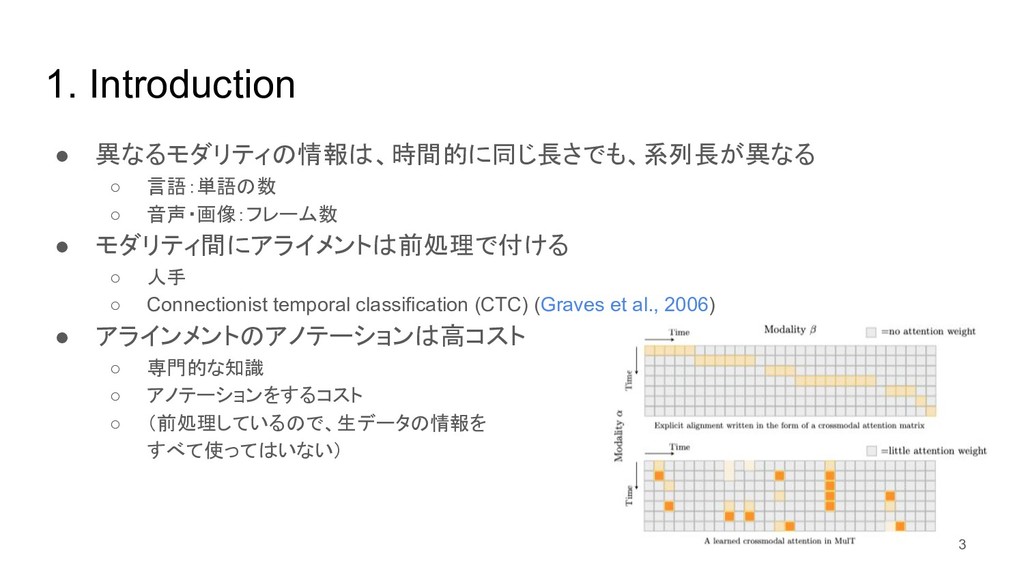{kind=link}
{kind=link}
{kind=link}
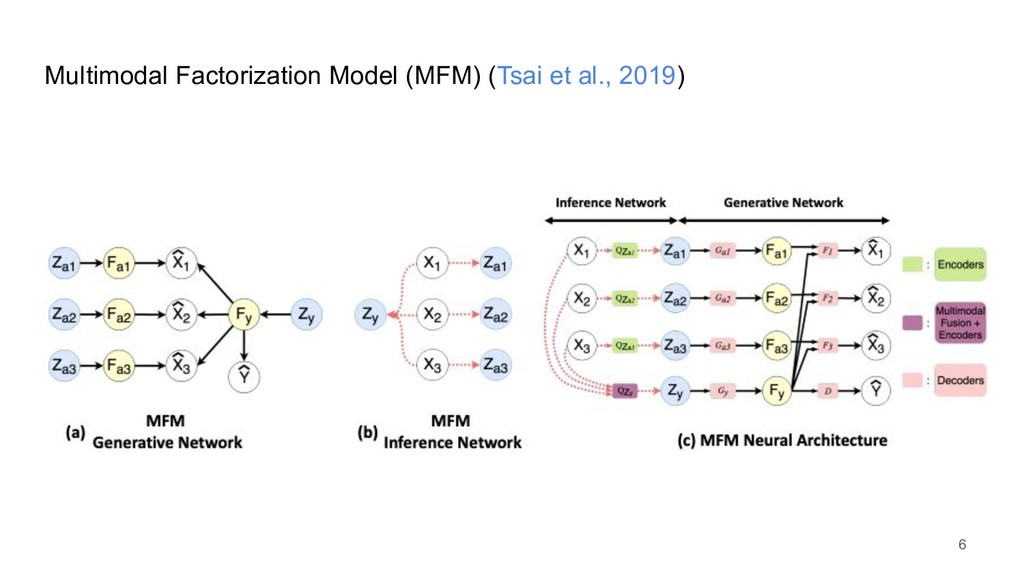{kind=link}
{kind=link}
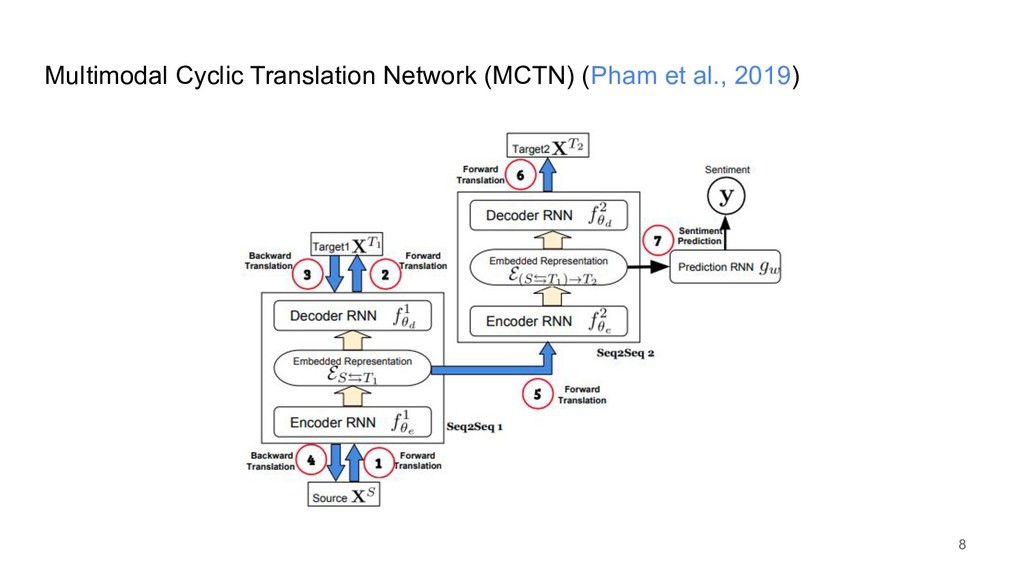{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
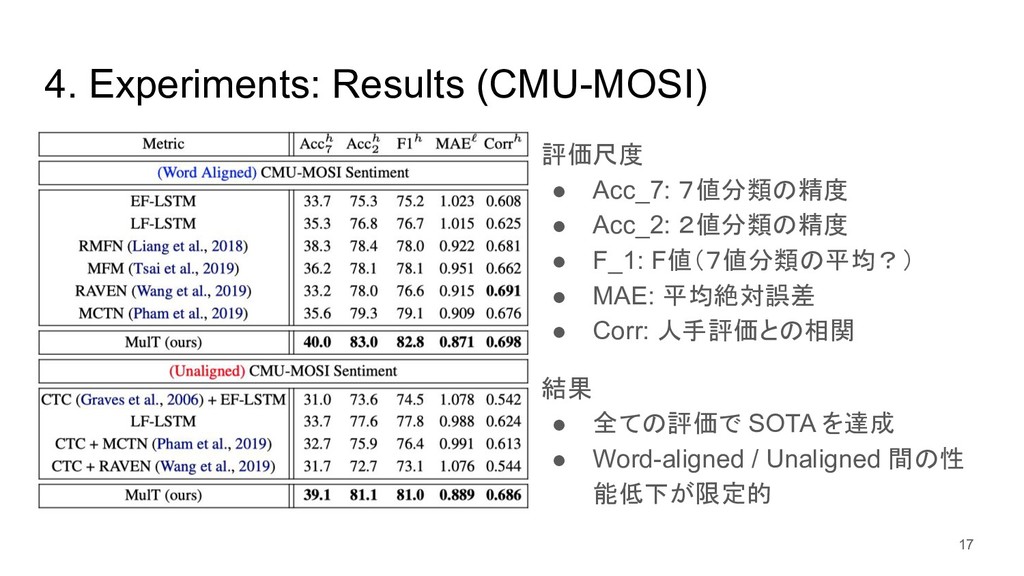{kind=link}
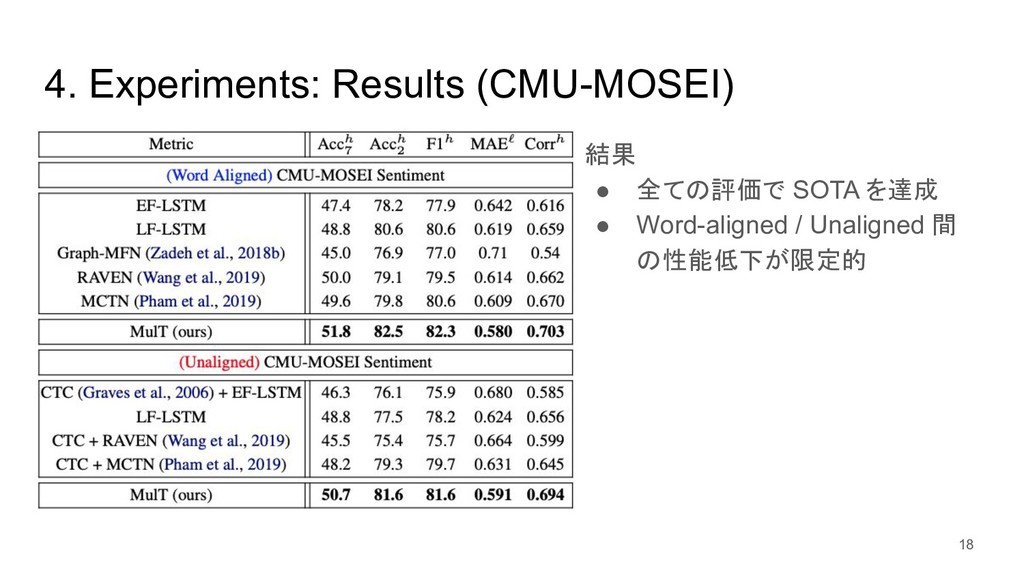{kind=link}
{kind=link}
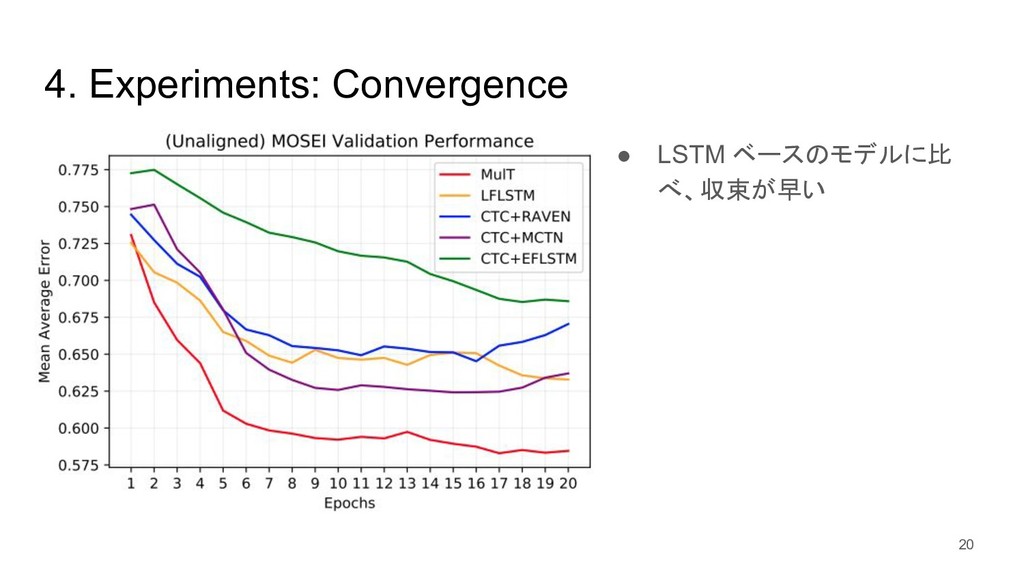{kind=link}
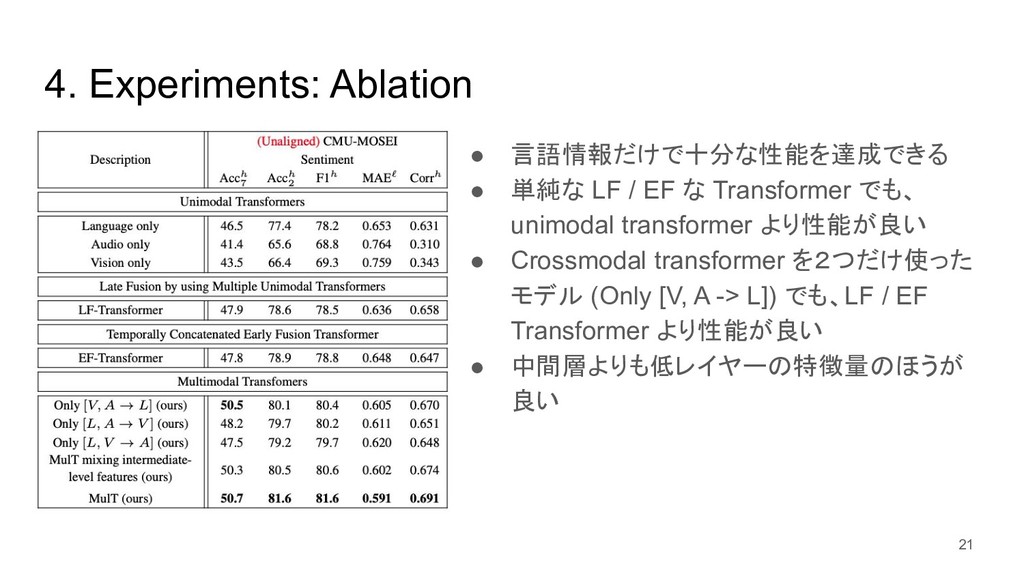{kind=link}
{kind=link}
{kind=link}