Multimodal machine translation is an attractive application of neural machine translation (NMT). It helps computers to deeply understand visual objects and their relations with natural languages. However, multimodal NMT systems suffer from a shortage of available training data, resulting in poor performance for translating rare words. In NMT, pretrained word embeddings have been shown to improve NMT of low-resource domains, and a search-based approach is proposed to address the rare word problem. In this study, we effectively combine these two approaches in the context of multimodal NMT and explore how we can take full advantage of pretrained word embeddings to better translate rare words. We report overall performance improvements of 1.24 METEOR and 2.49 BLEU and achieve an improvement of 7.67 F-score for rare word translation.
{kind=link}
{kind=link}
![Issue of MMT • Multi30k [Elliott et al., 2016] has](https://files.speakerdeck.com/presentations/4ba0b7cab59b4000a3c5ccf70ac5d325/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Baseline: IMAGINATION [Elliot and Kádáar, 2017] 6/11/19 NAACL SRW 2019,](https://files.speakerdeck.com/presentations/4ba0b7cab59b4000a3c5ccf70ac5d325/slide_6.jpg){kind=link}
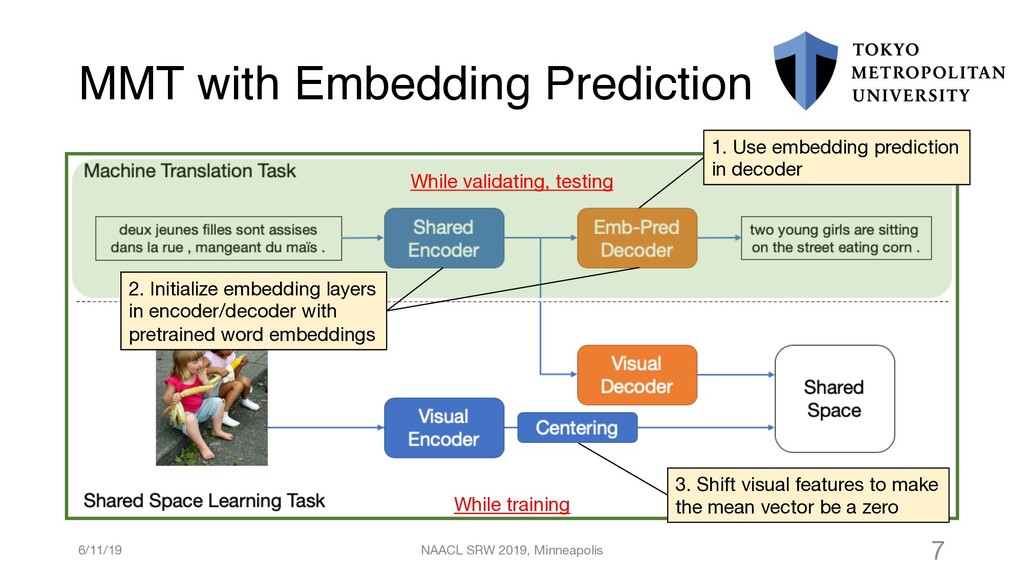{kind=link}
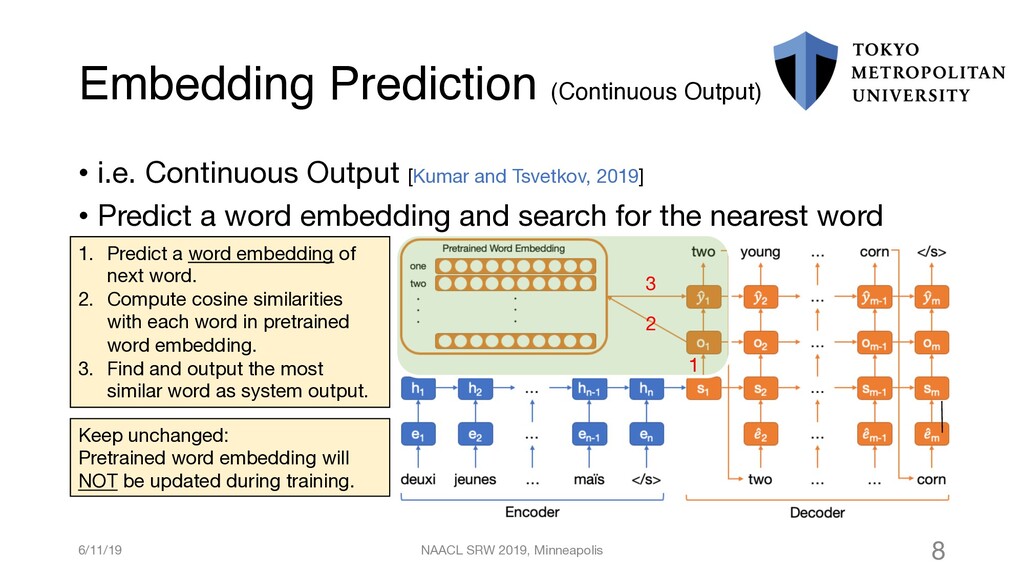{kind=link}
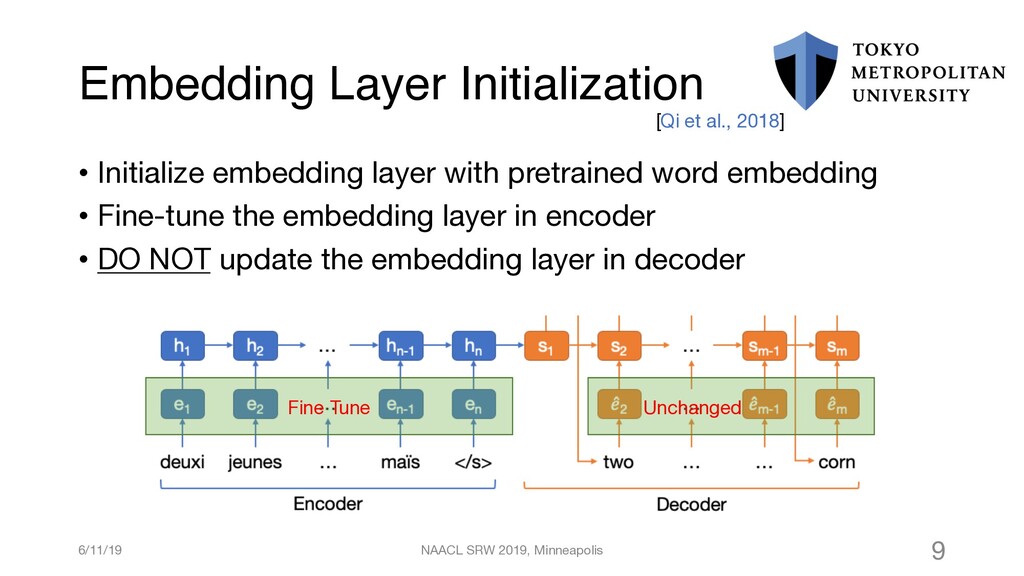{kind=link}
{kind=link}
{kind=link}
![Hubness Problem [Lazaridou et al., 2015] • Certain words (hubs)](https://files.speakerdeck.com/presentations/4ba0b7cab59b4000a3c5ccf70ac5d325/slide_12.jpg){kind=link}
![All-but-the-Top [Mu and Viswanath, 2018] • Address hubness problem in](https://files.speakerdeck.com/presentations/4ba0b7cab59b4000a3c5ccf70ac5d325/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
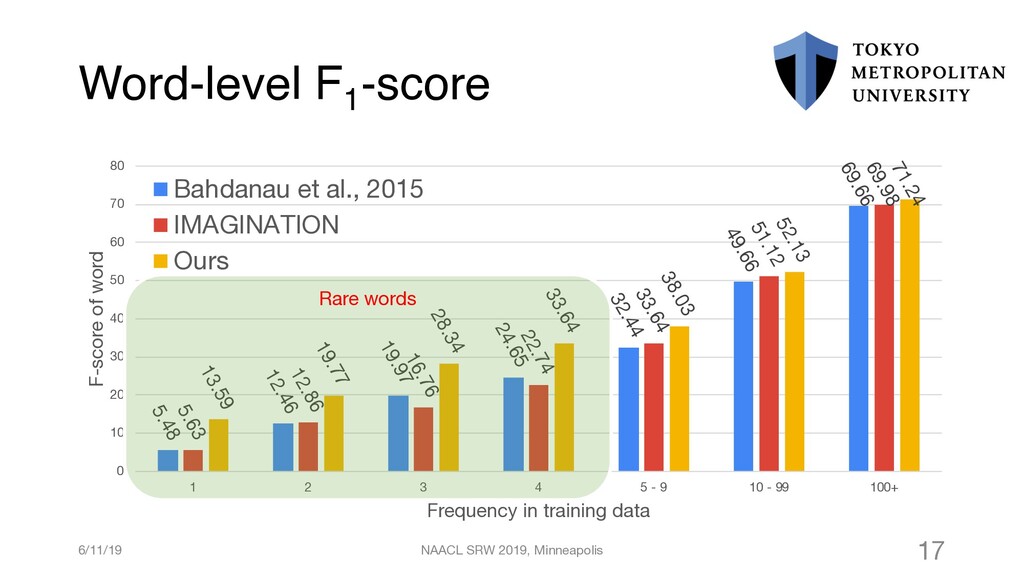{kind=link}
{kind=link}
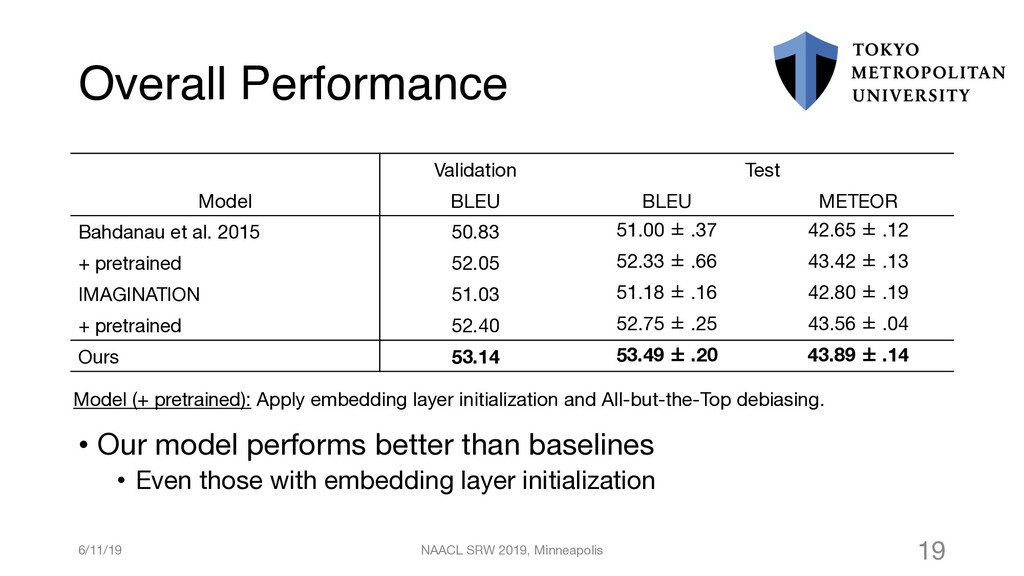{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}