Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Liu et al., 2021. Pay Attention to MLPs. arXiv
Search
tosho
May 27, 2021
Research
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Liu et al., 2021. Pay Attention to MLPs. arXiv
https://arxiv.org/abs/2105.08050
tosho
May 27, 2021
More Decks by tosho
See All by tosho
LayerXにおけるセキュリティ管理の現在地と次の一手
tosho
0
360
Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation
tosho
0
330
Good for Misconceived Reasons: An Empirical Revisiting on the Need for Visual Context in Multimodal Machine Translation
tosho
0
390
Shaham and Levy, 2021. Neural Machine Translation without Embeddings. NAACL2021
tosho
0
140
Huang et al. 2020 Unsupervised Multimodal Neural Machine Translation with Pseudo Visual Pivoting
tosho
0
500
Ive, Madhyastha, Specia_2019_EMNLP_Deep Copycat Networks for Text-to-Text Generation
tosho
0
170
Tan, Bansal_2019_EMNLP_LXMERT Learning Cross-Modality Encoder Representations from Transformers
tosho
0
280
Tsai et al._2019_ACL_Multimodal Transformer for Unaligned Multimodal Language Sequences
tosho
0
460
Zhou et al. 2019. Density Matching for Bilingual Word Embedding. NAACL
tosho
3
330
Other Decks in Research
See All in Research
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
140
PGDM: Physically Guided Diffusion Model for L Downscaling
satai
3
330
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
590
論文紹介:HalluCitation Matters
wasyro
0
120
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
10
8.4k
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
620
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
180
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
470
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
事後確率分布の共分散について
koide3
0
170
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
320
Featured
See All Featured
The Curse of the Amulet
leimatthew05
2
13k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
630
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
340
How to make the Groovebox
asonas
2
2.3k
Git: the NoSQL Database
bkeepers
PRO
432
67k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
AI: The stuff that nobody shows you
jnunemaker
PRO
8
770
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
480
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
380
The Invisible Side of Design
smashingmag
301
52k
Google's AI Overviews - The New Search
badams
0
1.1k
A Soul's Torment
seathinner
6
3k
Transcript
Pay Attention to MLPs Hanxiao Liu, Zihang Dai, David R.
So, Quoc V. Le 紹介者:平澤 寅庄 東京都立大学大学院 小町研究室 D1 2021年5月27日 @論文読み会
Make MLPs Great Again! 『ステート・オブ・AI ガイド』より引用 https://ja.stateofaiguides.com/20210524-beginning-of-mlp-era/ 2
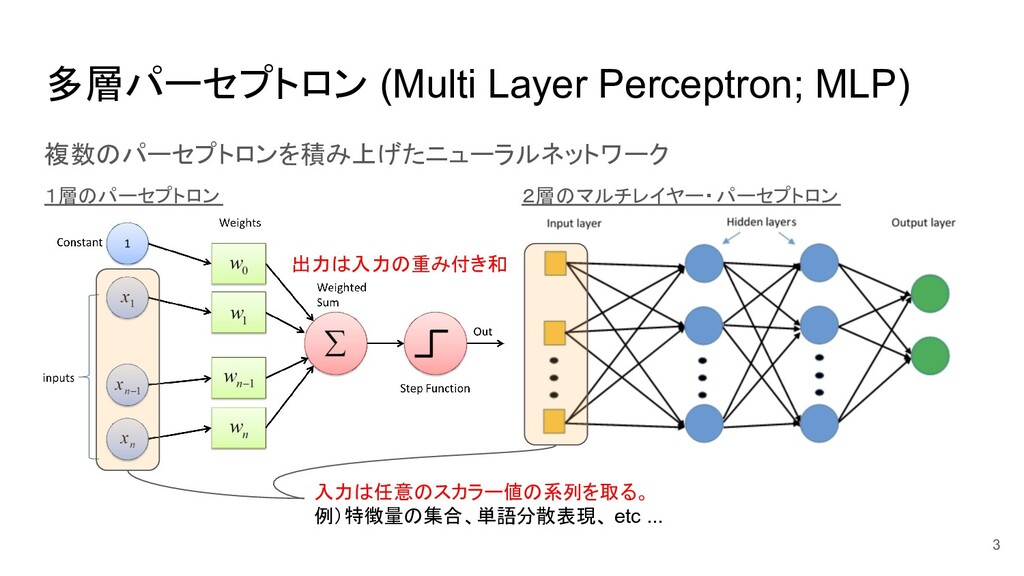
多層パーセプトロン (Multi Layer Perceptron; MLP) 複数のパーセプトロンを積み上げたニューラルネットワーク 1層のパーセプトロン 2層のマルチレイヤー・パーセプトロン 入力は任意のスカラー値の系列を取る。 例)特徴量の集合、単語分散表現、
etc ... 出力は入力の重み付き和 3
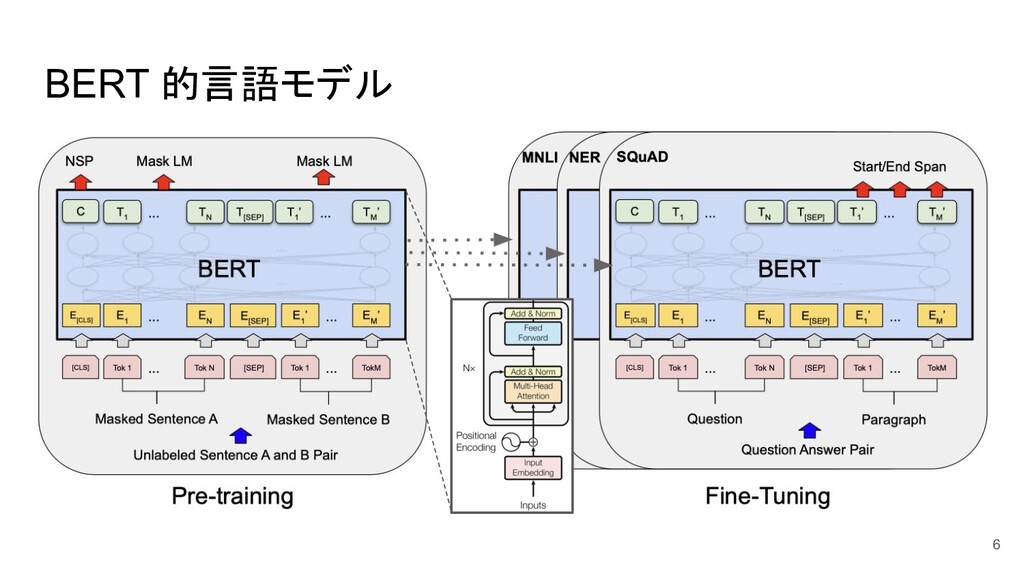
トランスフォーマー(Transformer) Vaswani et al., 2017 が提案した Encoder-Decoder 系列変換モデル • Multi-Head
Attention を導入することで、 全トークンの状態を並列で計算すること ができるようになった ◦ 各位置の状態は入力されるベクトル列の 重み付き和(重み=Attention)で計算する ◦ それまで主流だった RNN(再帰ニューラル ネットワーク)は順番にトークンごとの 状態を計算する必要があった • Positional Encoding でトークンの位置情報を組み込む • BERT的言語モデルは Encoder 側のみを使う Encoder Decoder 重みを計算 4
画像認識 画像に写っているのもを識別する技術 粒度により様々なタスクがある cat Image Localization Object Detection Instance Segmentation
画像認識で最も有名なデータセット • 1400 万枚の画像を 22,000 のクラスに分類 ◦ WordNet に基づいてラベルを設定 • コンペでは 1000 クラス分類(ImageNet-1K) cat Image Classification 5
BERT 的言語モデル 6
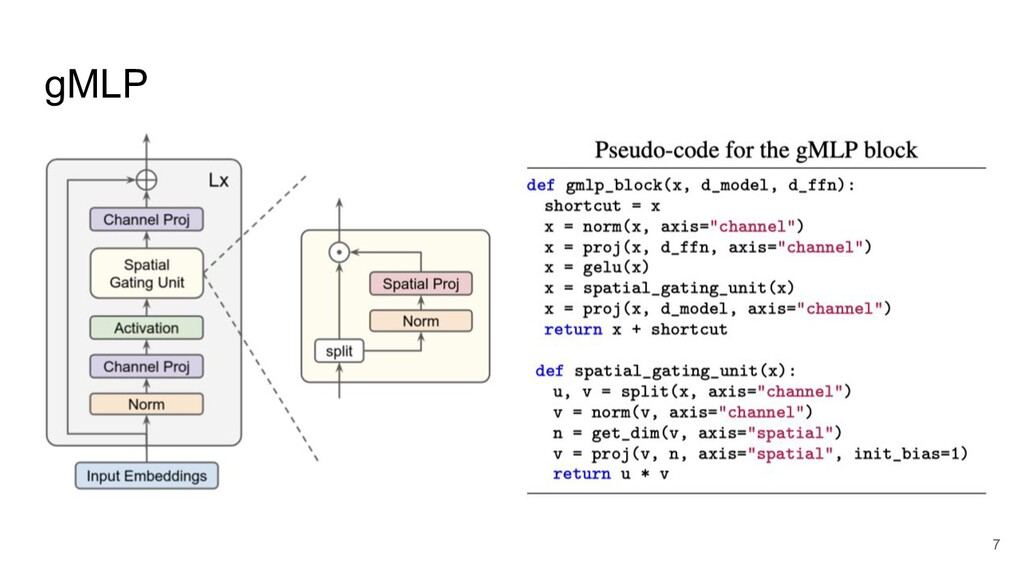
gMLP 7
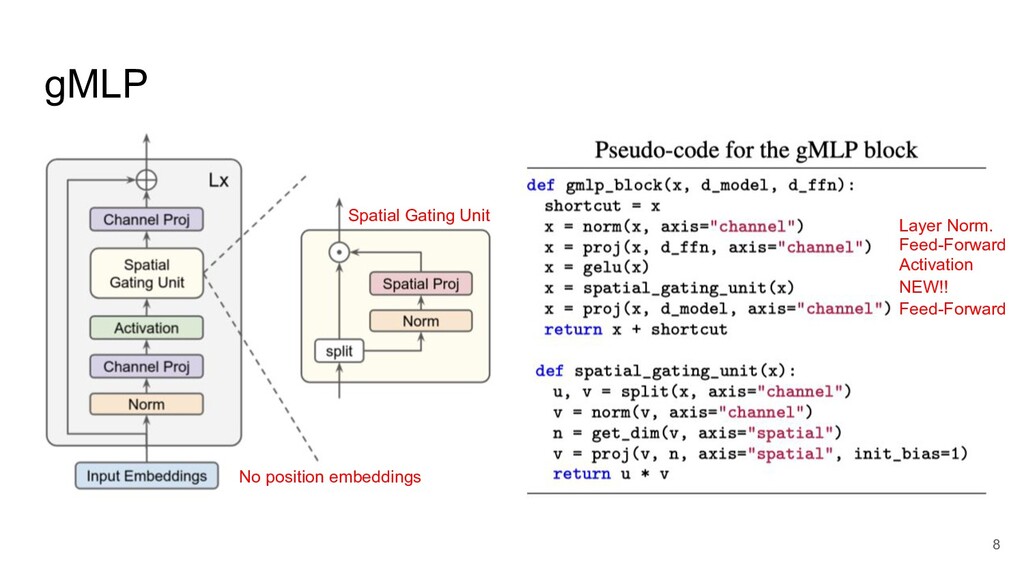
gMLP Layer Norm. Feed-Forward Activation NEW!! Feed-Forward Spatial Gating Unit
No position embeddings 8
Spatial Gating Unit トークン間インタラクションを担うモジュール 入力を分割 {する|しない} パーセプトロン(系列方向) 要素積 x1 x2
x3 x4 u1 u2 u3 u4 v1 v2 v3 v4 v1 v2 v3 v4 s1 s2 s3 s4 ⊙ W Gate 9
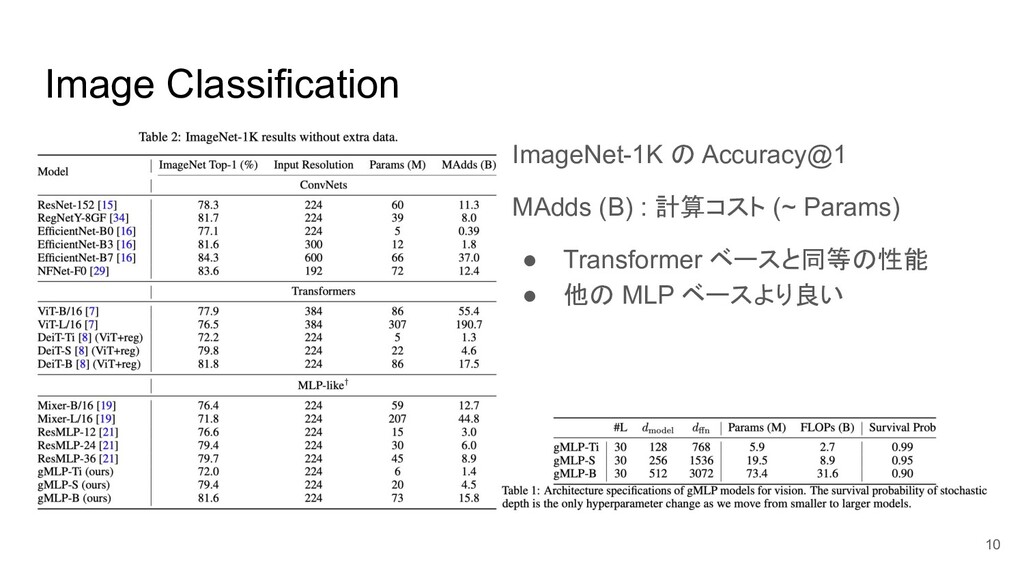
Image Classification ImageNet-1K の Accuracy@1 MAdds (B) : 計算コスト (~
Params) • Transformer ベースと同等の性能 • 他の MLP ベースより良い 10
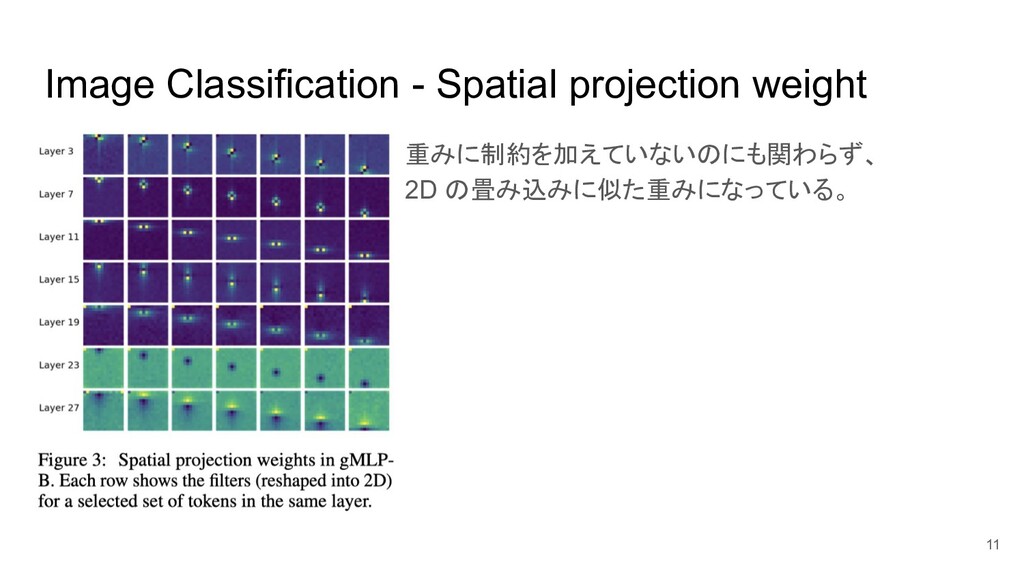
Image Classification - Spatial projection weight 重みに制約を加えていないのにも関わらず、 2D の畳み込みに似た重みになっている。 11
Masked Language Mode with BERT C4 データセットを使い、MLM で学習する。 • BERT
BERT モデル • + rel pos Positional encoding ➜ Relative positional encoding • + rel pos - attn MHA の content-dependent term を削除 Attention の計算 • Transformer ベースのモデルと同等の性能( ppl)を達成した • Spatial Gate Unit は Split + Multiplicative がよい 12
MLM with BERT - Spatial filter analysis 13
MLM with BERT - Spatial filter analysis • 基本的には近いところしか見ていない。 v1
v2 v3 v4 Gate を計算するときにどの要素を 見ているかを表している。 14
MLM with BERT - Spatial filter analysis • 基本的には近いところしか見ていない。 15
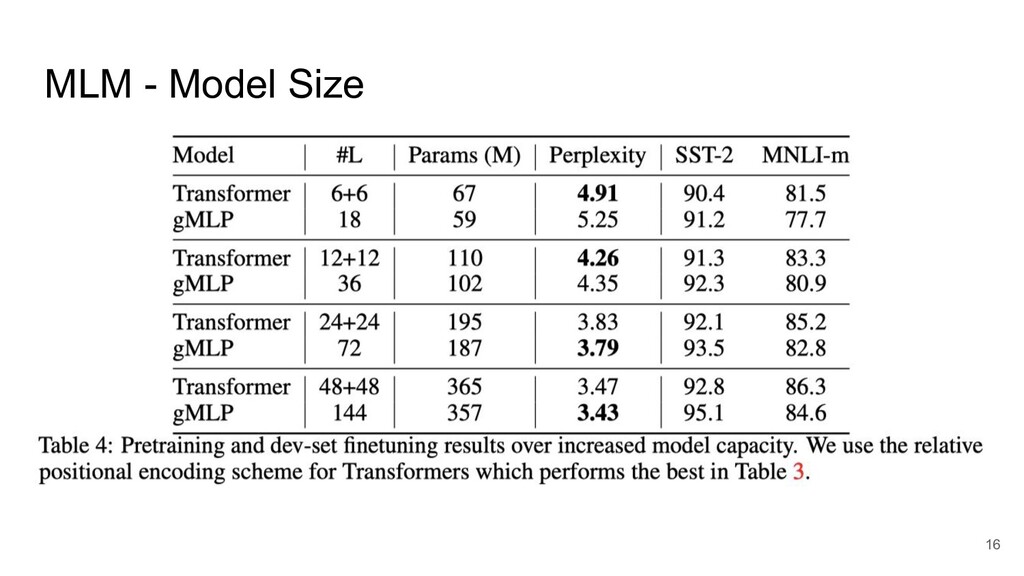
MLM - Model Size 16
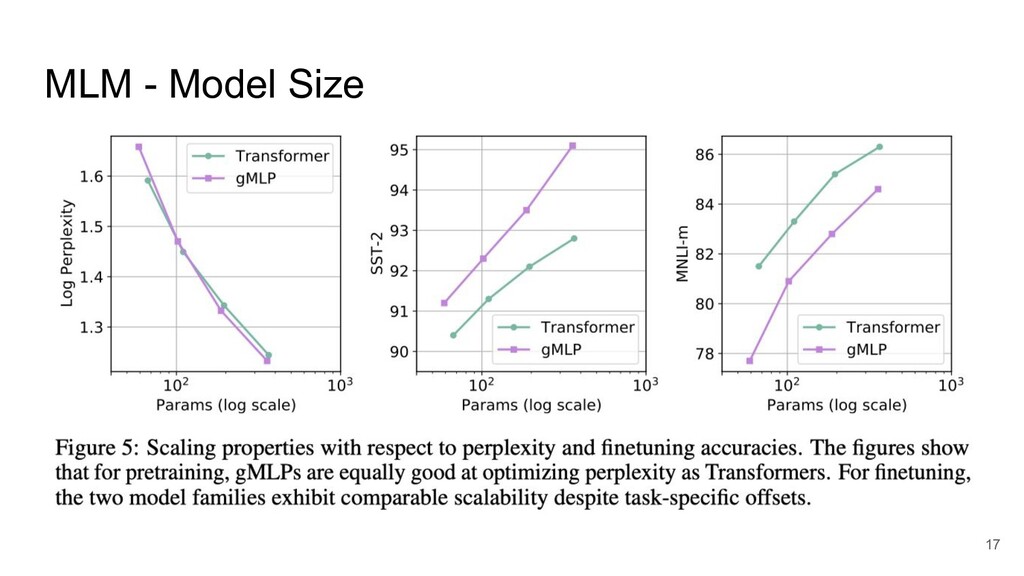
MLM - Model Size 17
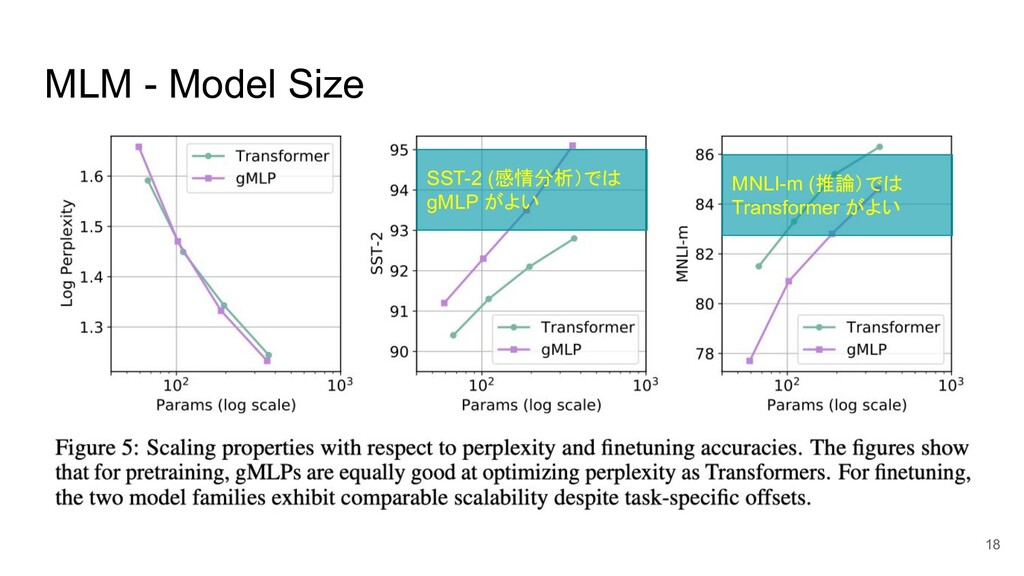
MLM - Model Size SST-2 (感情分析)では gMLP がよい MNLI-m (推論)では
Transformer がよい 18
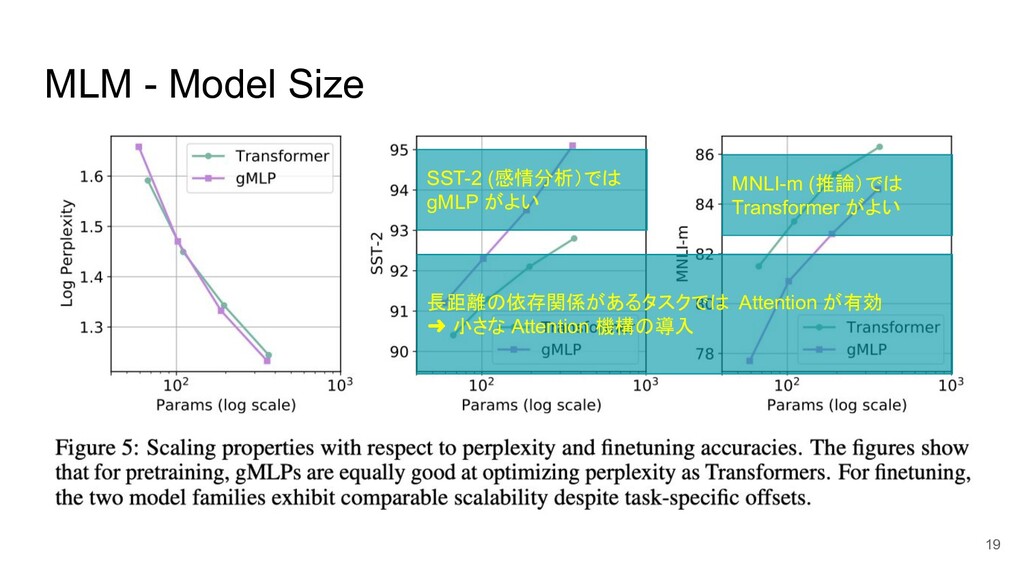
MLM - Model Size SST-2 (感情分析)では gMLP がよい MNLI-m (推論)では
Transformer がよい 長距離の依存関係があるタスクでは Attention が有効 ➜ 小さな Attention 機構の導入 19
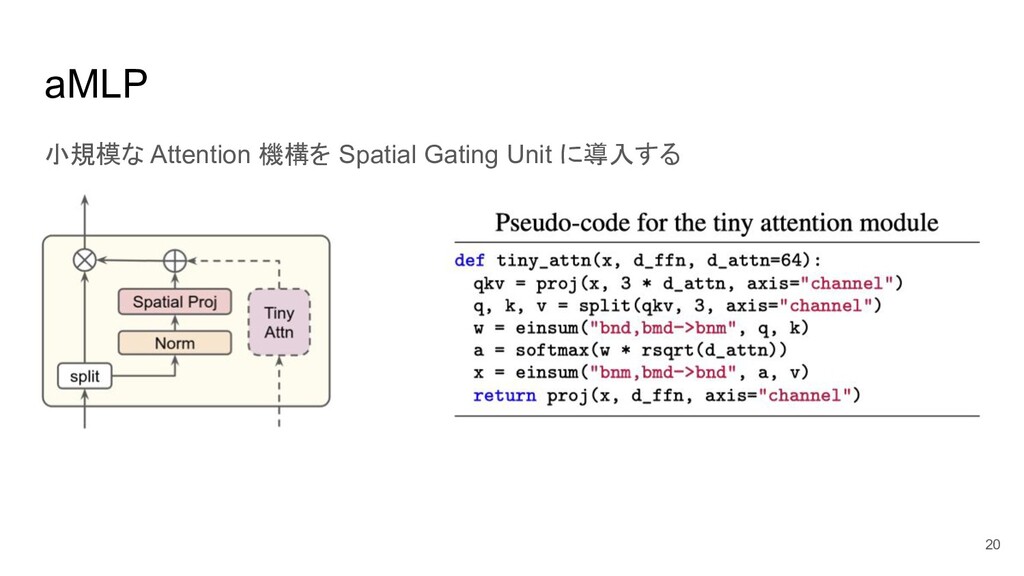
aMLP 小規模な Attention 機構を Spatial Gating Unit に導入する 20
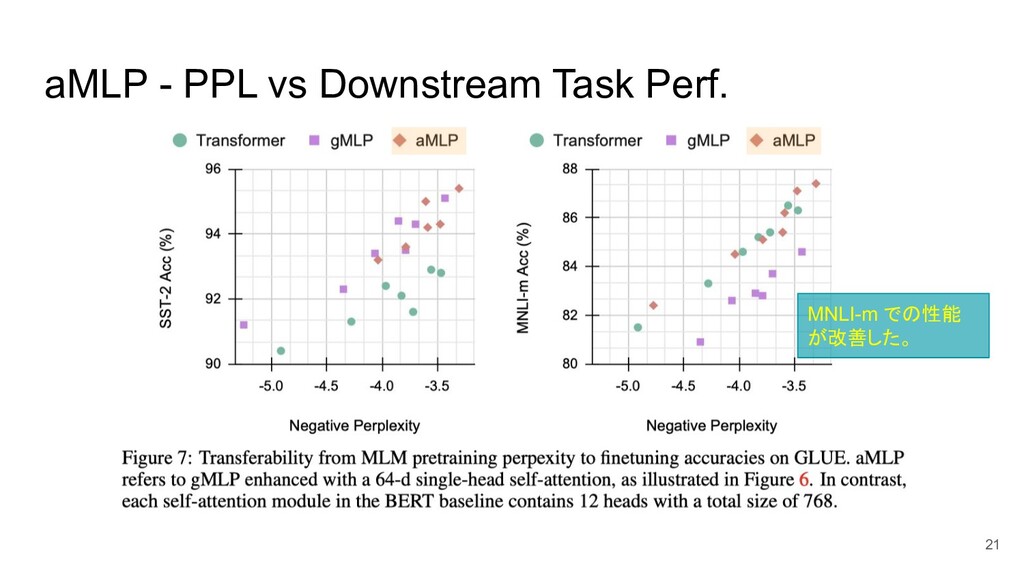
aMLP - PPL vs Downstream Task Perf. MNLI-m での性能 が改善した。
21
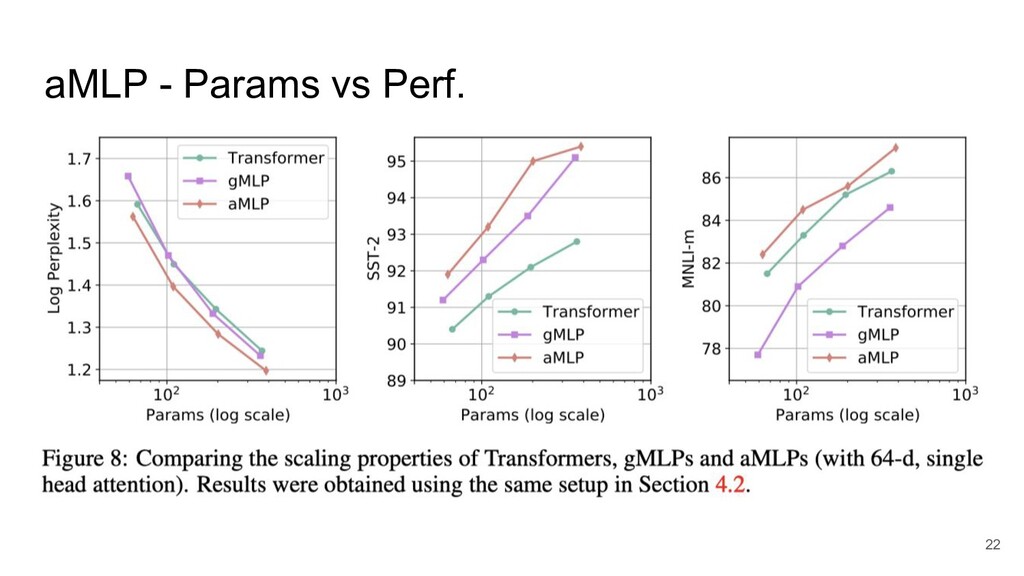
aMLP - Params vs Perf. 22
MLM - Main results 23
Conclusion • Attention は小規模なもので十分で、タスクによっては不要である • ゲート付き MLP(gMLP)でも、Transformer に匹敵する性能がある • 文間の関係を捉えることが重要なタスクでは、attention
が重要な働きをする 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}