L’objectif de la création de ce groupe est de découvrir et partager les meilleures recettes à utiliser dans les compétitions de Machine Learning organisées par Kaggle: Feature engineering, hyper paramètres, cross validation, stacking, ensemble, blending ainsi que la star des algo sur Kaggle 'eXtreme Gradient Boosting' seront quelques uns des sujets abordés.
Sommaire :
• Présentation & règles des compétitions Kaggle
• REX
• Présentation des compétitions actuelles
• Discussion ouverte sur le fonctionnement / mode d’organisation des prochaines rencontres
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
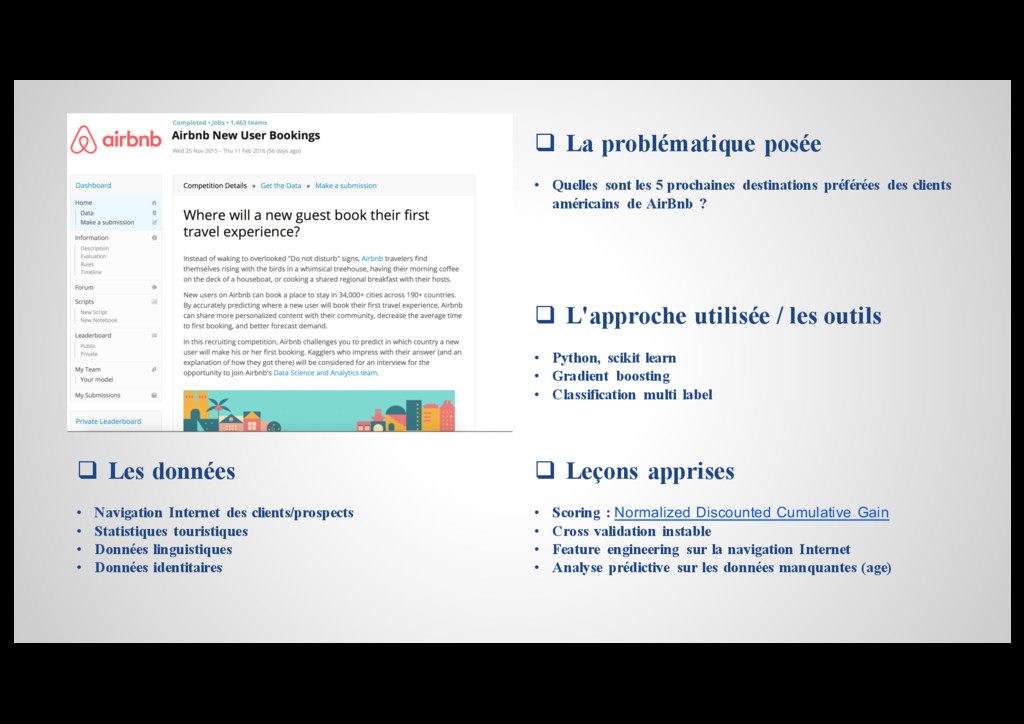{kind=link}
{kind=link}
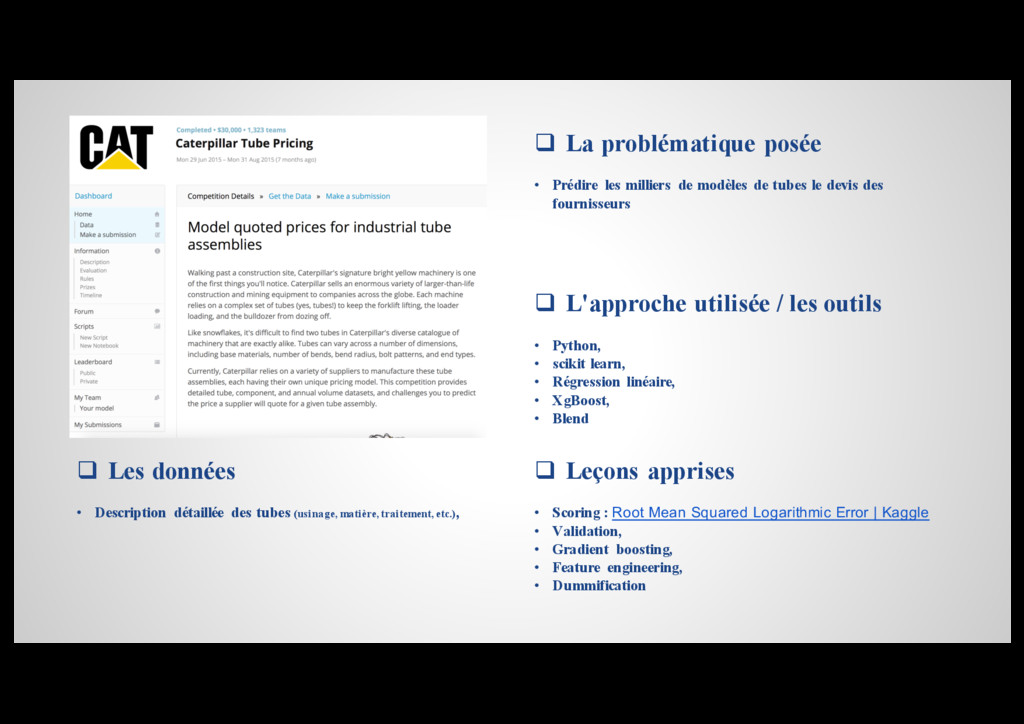{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}