some families, especially IE • Still emphasis on the tree model and reconstruction of proto-forms • Sometimes more an art than a science – No set of formal guidelines leading to reproducible results, more principles – No standard for data – Good art is better than bad science!
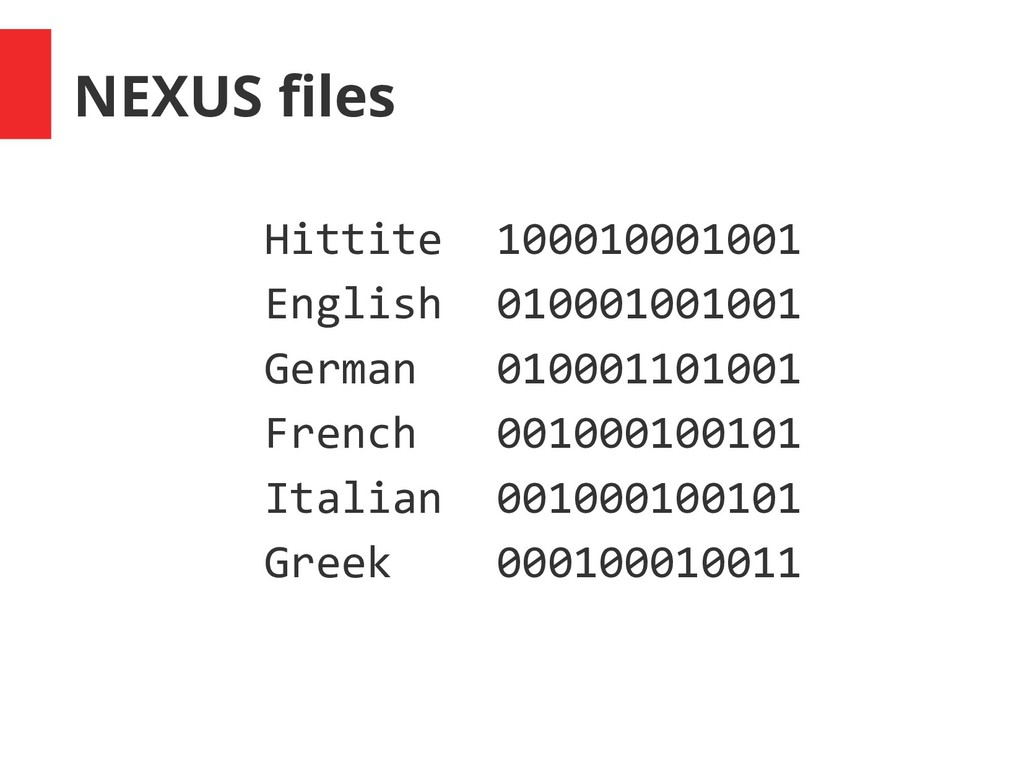
watar kuwapi English all sea water when German alle see, meer wasser wann French tout mer eau quand Italian tutto mare acqua quando Greek pant thalasa nero pote
aruna (B1) watar (C1) kuwapi (D1) English all (A2) sea (B2) water (C1) when (D1) German alle (A2) see (B2), meer (B3) wasser (C1) wann (D1) French tout (A3) mer (B3) eau (C2) quand (D1) Italian tutto (A3) mare (B3) acqua (C2) quando (D1) Greek pant (A4) thalasa (B4) nero (C3) pote (D1)
not mean increase in data for historical linguistics • Preparing datasets for large-scale historical and typological language comparison is difficult • Scholars don’t tend to adhere to standards when (and if!) preparing datasets • Field divided in traditional and computational approaches
for the sake of reconstructing proto-forms • The discipline should inform and be informed by other areas of language research • It should also inform and be informed by other fields of the science of human history • We need computer-assisted, not computer- performed research
to make an analysis involving data? • What do (modeled) linguists do, if they want to make an analysis involving data? • Main alternatives for cross-linguistic comparison: parse some on-line data, few limited source (Wiktionary), ASJP
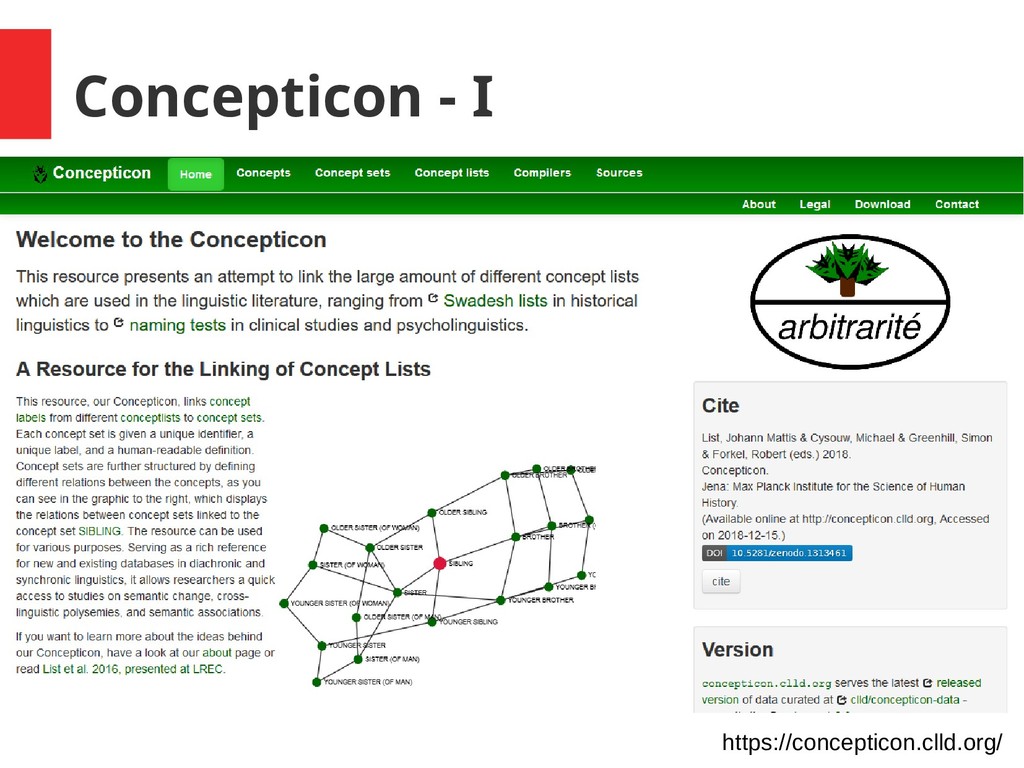
set “MOTHER” (#1216) is linked to 112 different concepts, including – “ 母亲” in Allen (2007) – “mother, older female relative” in Bengtson (1994) – “his mother” in Davies (1985) – “мать” in a Russian translation of Swadesh (1964)
translated in Chinese as 钝 (dùn, “blunt”), sometimes as 笨 (bèn, “stupid”) – In Concepticon, data collected as 钝 is mapped to concept BLUNT, data collect as 笨 to concept STUPID
must be human- and machine-readable – Interfaces must be lightweight – Software should produce transparent results • Empirical, cross-linguistic priors • Levels of confidence • History of languages as part of human histories – We should like reticulation!
Simon Greenhill, Harald Hammarström, Cormac Anderson, Mary Walworth, Thiago Chacon, Russell Gray • DFG Center for Advanced Studies “Words, Bones, Genes, Tools” (Universität Tübingen) • ERC #206320 • http://calc.digling.org/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}