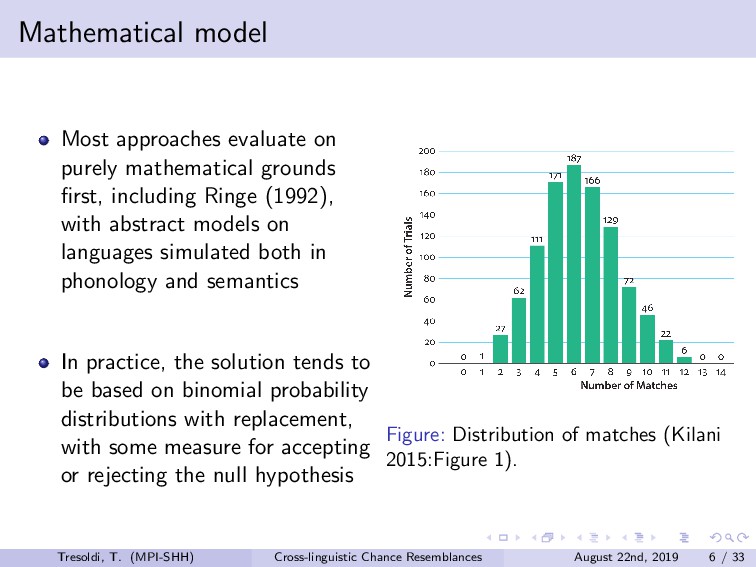
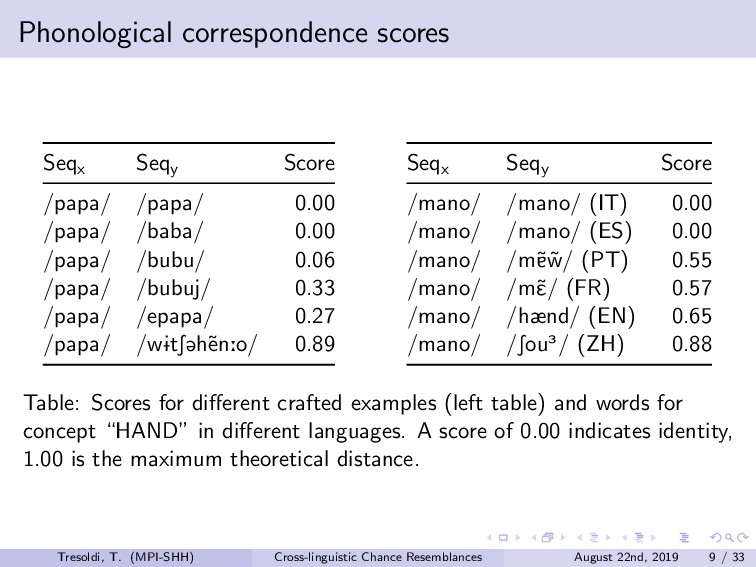
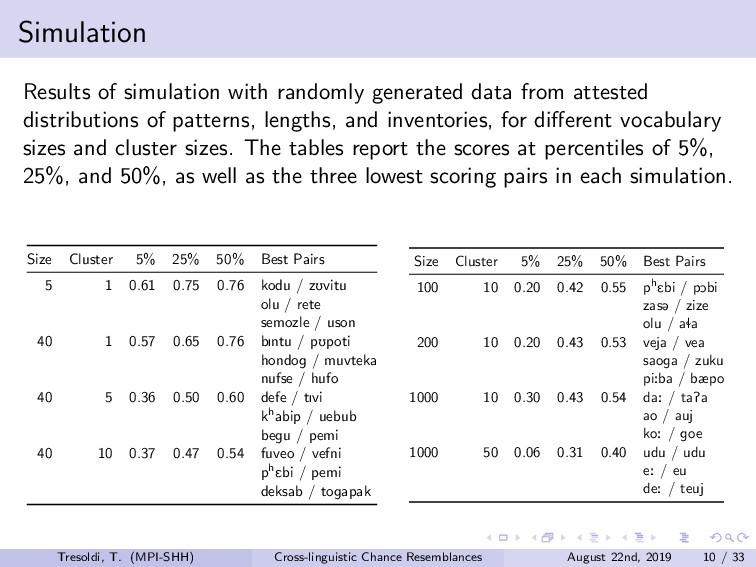
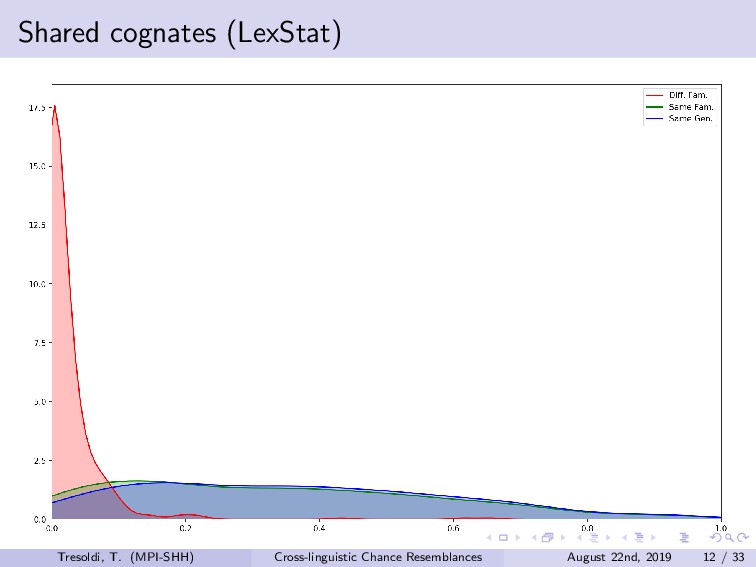
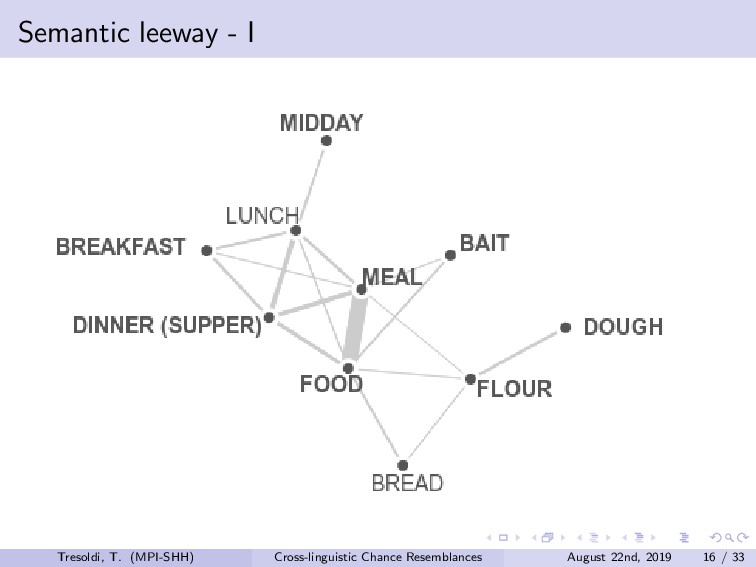
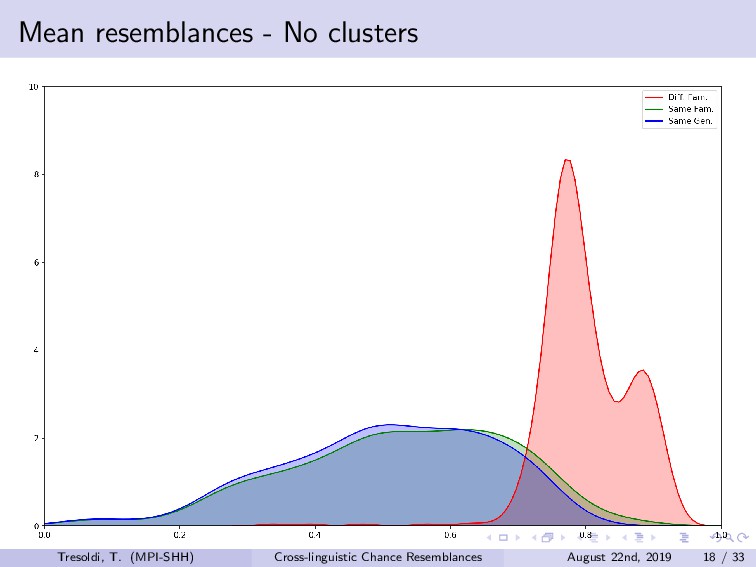
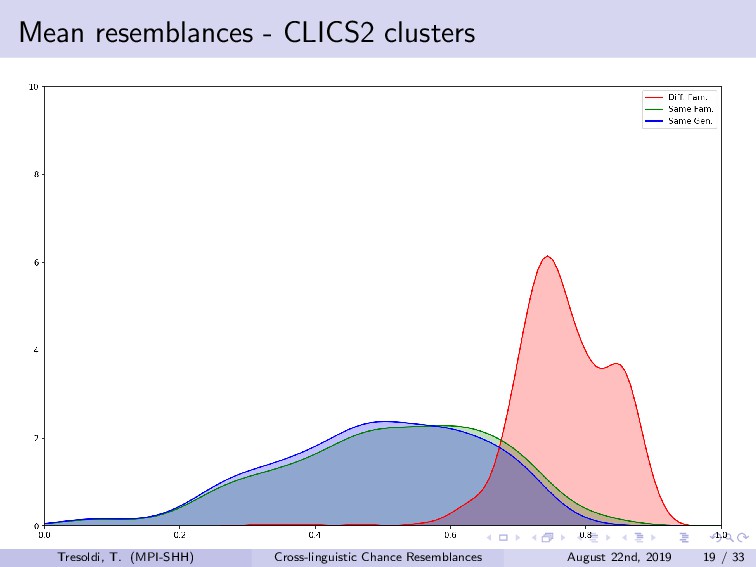
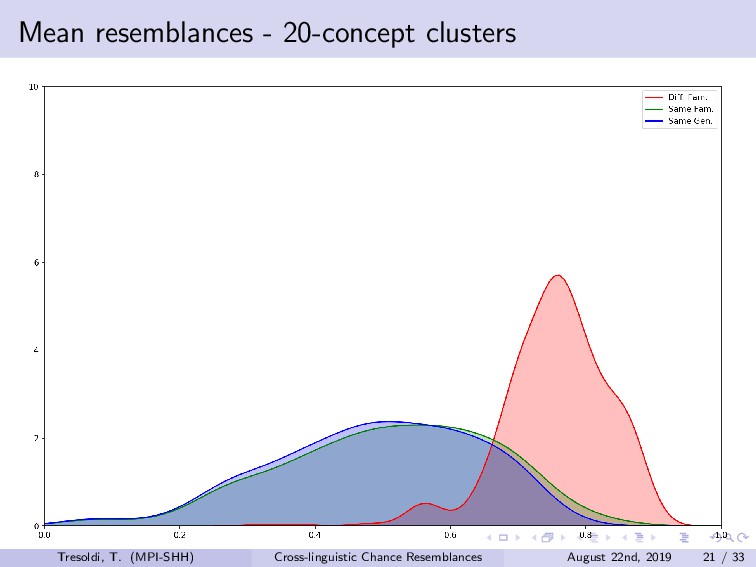
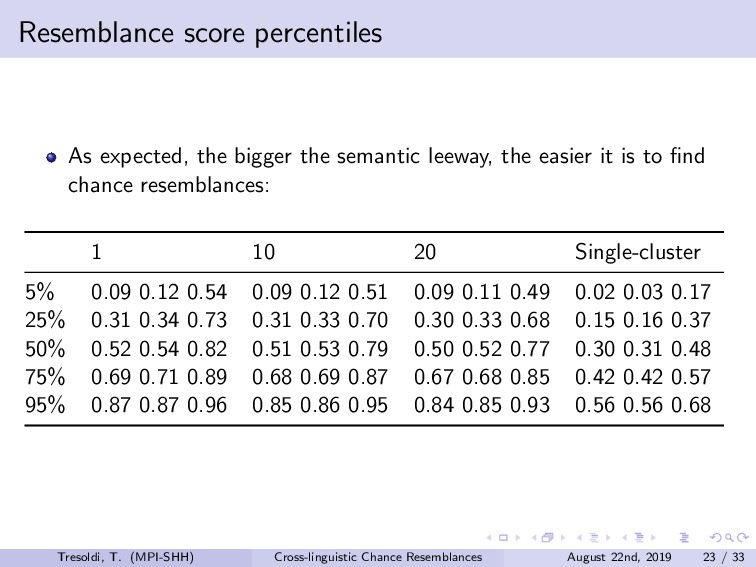
Chance resemblances can be an anathema in linguistics, given the difficulties in identifying them, and, occasionally, their usage as evidence against the comparative method. Conversely, they also tend to be among the objections towards computational approaches, as only expert knowledge and supplementary evidences would be able to confidently distinguish among vertical transmission, horizontal transmission, and chance resemblance. Limitations of this kind have been advanced since the beginnings of the comparative method, such in the frequently cited false correspondence between Latin *deus* and Ancient Greek *θεός* (both meaning “god”). The reduction, or rather expansion, *ad absurdum* of such difficulty is demonstrated both by the long tradition of folk etymologies, motivated by the assumption that surface similarities are too strong to be due to chance, and by the recurrent claims of amateur linguists on impossible relationships such as, for example, between Ainu and Etruscan.Among the sources for such difficulties is the fact that we have no clear definition on chance similarity, in general loosely defined as “words that sound similar”, particularly when there is a limited semantic leeway and preferably when judged as such with the support of the phonotactics of the languages involved. The uncertainties in terms of definition translate into limited sets of concrete examples, leading to the absence of baselines.In this talk, we investigate the question of how to create a baseline for expected probability of chance resemblance according to different typological parameters. As such, we will present the results of a cross-linguistic and computational inquiry on chance resemblances, following three different experiments. In the first, developing on Rosenfelder (2002), is a purely mathematical modeling that calculates the probability of random correspondences on a set of linguistic models of very simplified phonological and semantic assumptions. The second applies state-of-the-art algorithms for automatic cognate detection (List et al., 2018b) on languages randomly generated from phonological and semantic parameters collected from real languages of different typologies, in a massive comparison that allows to highlight which factors contribute the more to the perception of similarity; in fact, we will also explore the possibility of later re-using the dataset to collect resemblance judgements according to experts. The third and most important experiment uses actual linguistic data from a cross-linguistic database, Lexibank (forthcoming), by applying the same methods to languages pairs of varying phylogenetic relationships (Hammarström et al., 2018), which, combined with semantic information linked to Concepticon (List et al., 2018a) and CLICS (List et al., 2018c). Our results support the hypothesis that chance resemblances, even across unrelated languages, are common and indeed expected even with minor leeway, and that chance resemblances need to judged on a per-language pair and not per-potential cognate pair basis. This should allow to orient future experiment setup, besides offering a preliminary baseline on the expectancy of chance resemblance according to given sets of parameters, including language proximity in terms of lineage, possibly being incorporated into future work on automatic borrowing detection.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}