Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第1回 Jubatusハンズオン
Search
Yuya Unno
February 18, 2013
Technology
15
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第1回 Jubatusハンズオン
Yuya Unno
February 18, 2013
More Decks by Yuya Unno
See All by Yuya Unno
深層学習で切り拓くパーソナルロボットの未来 @東京大学 先端技術セミナー 工学最前線
unnonouno
0
29
深層学習時代の自然言語処理ビジネス @DLLAB 言語・音声ナイト
unnonouno
0
53
ベンチャー企業で言葉を扱うロボットの研究開発をする @東京大学 電子情報学特論I
unnonouno
0
50
PFNにおけるセミナー活動 @NLP2018 言語処理研究者・技術者の育成と未来への連携WS
unnonouno
0
20
進化するChainer @JSAI2017
unnonouno
0
30
予測型戦略を知るための機械学習チュートリアル @BigData Conference 2017 Spring
unnonouno
0
29
深層学習フレームワーク Chainerとその進化
unnonouno
0
31
深層学習による機械とのコミュニケーション @DeNA TechCon 2017
unnonouno
0
43
最先端NLP勉強会 “Learning Language Games through Interaction” @第8回最先端NLP勉強会
unnonouno
0
25
Other Decks in Technology
See All in Technology
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
2
180
ADDF - ループエンジニアリングするフレームワークを作ったら/I Didn't Set Out to Build Loop Engineering, But ADDF Did
fruitriin
0
120
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
140
穢れた技術選定について
watany
6
490
AI時代の EM への処方箋
staka121
PRO
0
140
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.1k
SRE Lounge Hiroshimaへの招待
grimoh
0
640
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
0
120
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
3
1k
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
3.5k
貴方はどのエンジニアリングを磨くのか
hatyibei
0
130
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
1
110
Featured
See All Featured
GitHub's CSS Performance
jonrohan
1033
470k
Bash Introduction
62gerente
615
220k
Thoughts on Productivity
jonyablonski
76
5.2k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
We Are The Robots
honzajavorek
0
280
Building AI with AI
inesmontani
PRO
1
1.1k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Ruling the World: When Life Gets Gamed
codingconduct
0
280
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Transcript
第1回 Jubatusハンズオン 2013年年 2⽉月18⽇日(⽉月) Jubatus Team
⾃自⼰己紹介 l 海野 裕也 (Yuya Unno) l Twitter: @unnonouno l 株式会社Preferred
Infrastructure l 専⾨門 l ⾃自然⾔言語処理理 l テキストマイニング 2
今⽇日の⽬目標 l 初めて機械学習を使ってみる⼈人も対象です l 機械学習の初歩から説明します l ⾼高校数学くらいの知識識があればOK l 詳しい⼈人にとっては少し退屈かもしれません 3
Jubatusを使って機械学習に触れてみる
アジェンダ l イントロダクション l Jubatusを使ってみる l 設定を変更更してみる 4
l イントロダクション l Jubatusを使ってみる l 設定を変更更してみる 5
JubatusはOSSの機械学習フレームワークです 6 リアルタイム ストリーム 分散並列列 深い解析 l NTT SIC*とPreferred Infrastructureによる共同開発
l 2011年年10⽉月よりOSSで公開 http://jubat.us/ * NTT SIC: NTT研究所 サイバーコミュニケーション研究所 ソフトウェアイノベーションセンタ
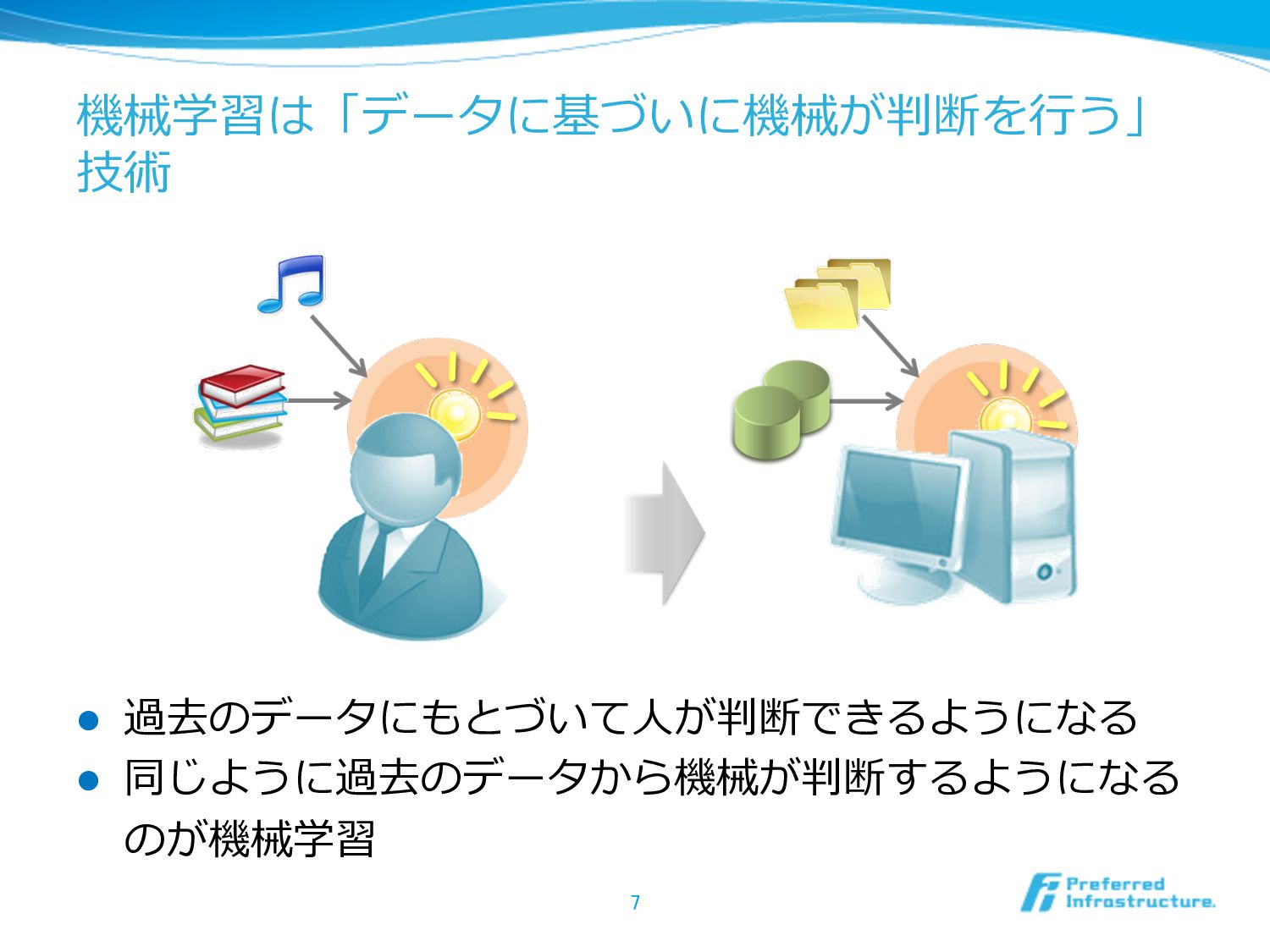
機械学習は「データに基づいに機械が判断を⾏行行う」 技術 l 過去のデータにもとづいて⼈人が判断できるようになる l 同じように過去のデータから機械が判断するようになる のが機械学習 7
複数の選択肢から1つ選ぶのが「多値分類問題」 l ⼊入⼒力力xに対する出⼒力力yを予想するのが多値分類問題 l 機械学習の⼀一番基本的な問題設定 l ⼊入出⼒力力の組みをたくさん教えこむ 8 分類器 (classifier)
文書 画像 スポーツ記事 芸能記事 or ⼈人物画像 動物画像 or
l イントロダクション l Jubatusを使ってみる l 設定を変更更してみる 9
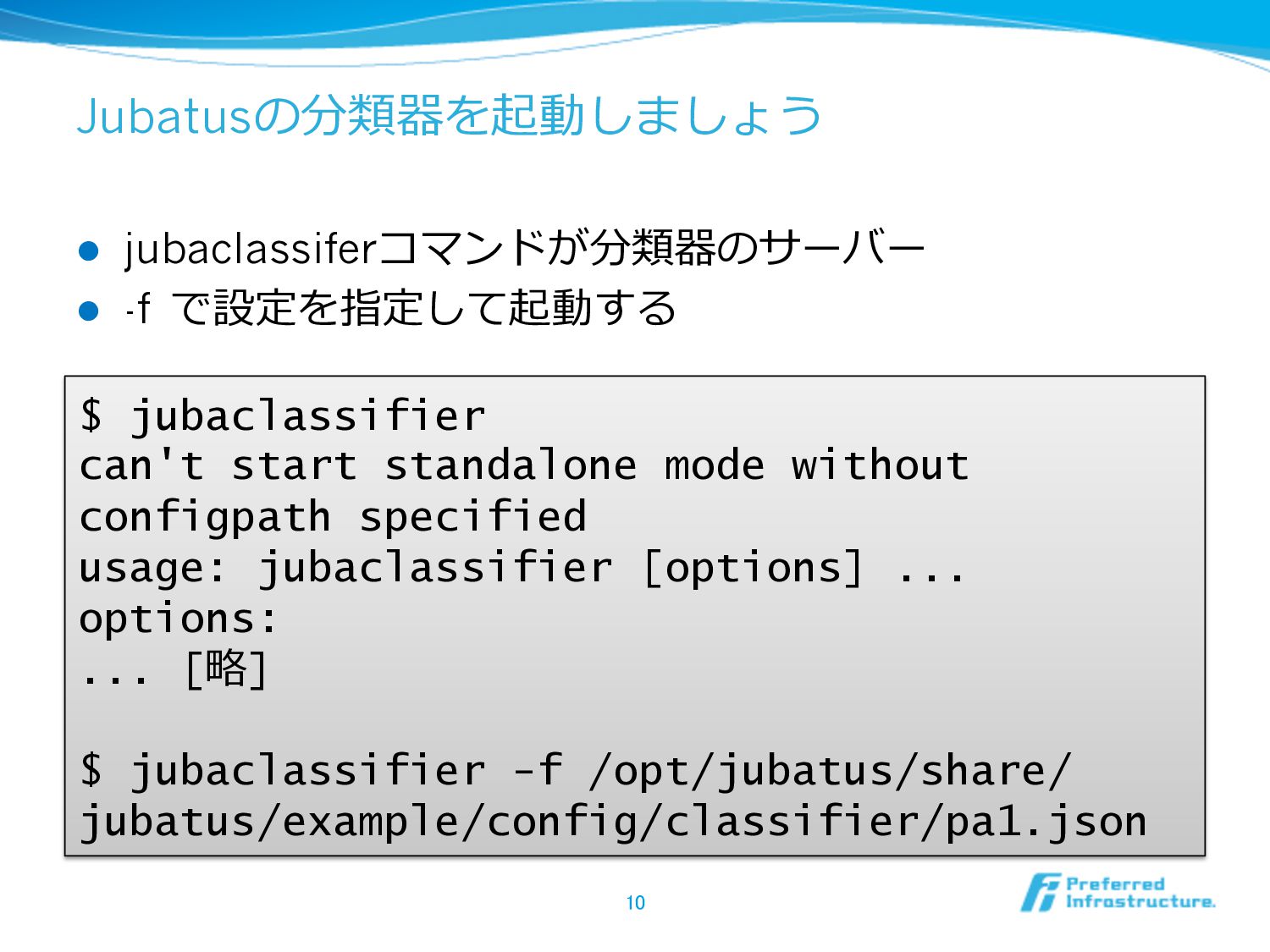
Jubatusの分類器を起動しましょう l jubaclassiferコマンドが分類器のサーバー l -f で設定を指定して起動する 10 $ jubaclassifier can't
start standalone mode without configpath specified usage: jubaclassifier [options] ... options: ... [略略] $ jubaclassifier -f /opt/jubatus/share/ jubatus/example/config/classifier/pa1.json
今⽇日は分散の話はしません l 今⽇日は単体で実⾏行行させます l 分散させません 11
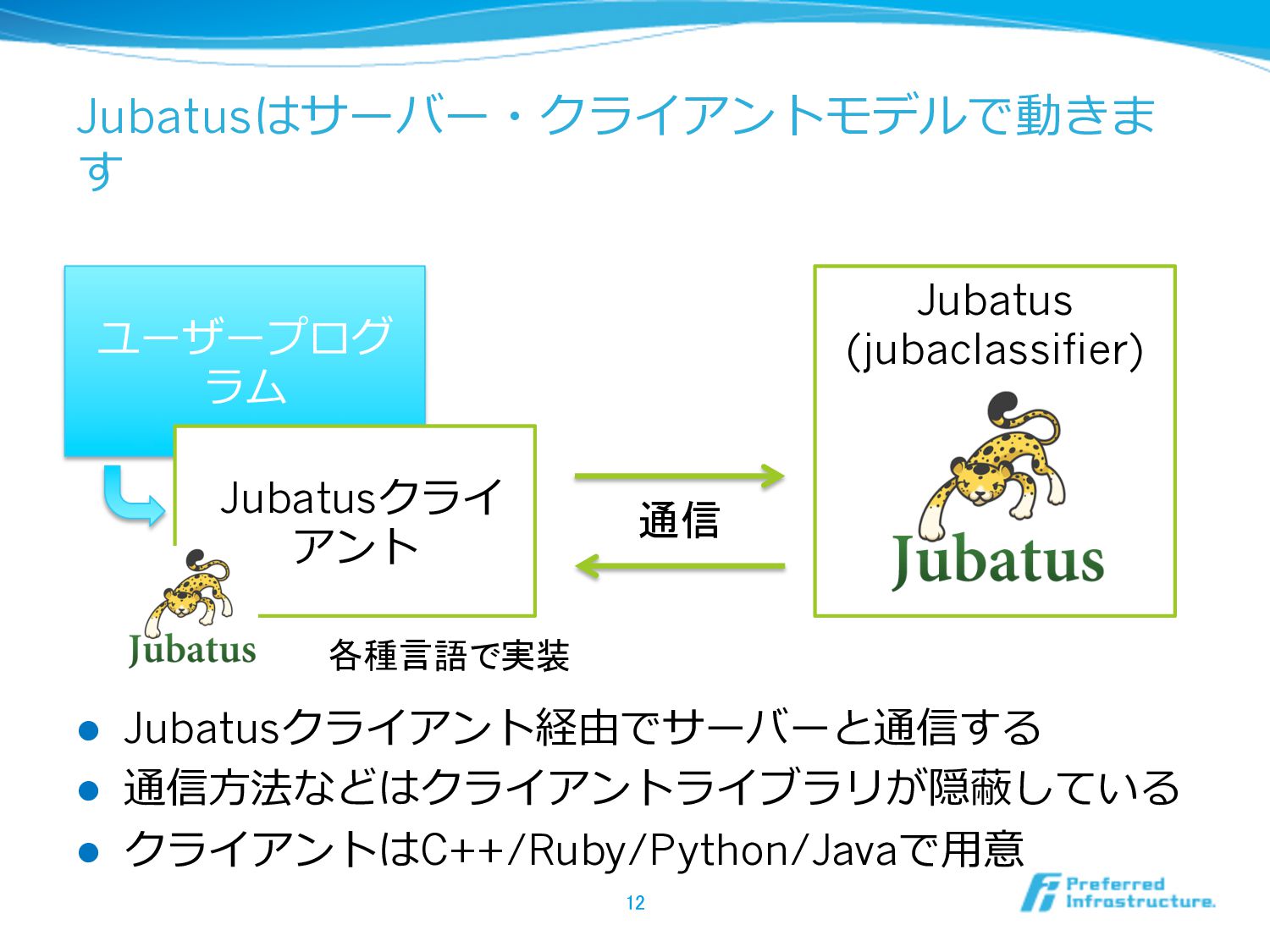
Jubatusはサーバー・クライアントモデルで動きま す l Jubatusクライアント経由でサーバーと通信する l 通信⽅方法などはクライアントライブラリが隠蔽している l クライアントはC++/Ruby/Python/Javaで⽤用意 12 ユーザープログ
ラム Jubatus (jubaclassifier) Jubatusクライ アント 通信 各種言語で実装
サンプルを⽤用意したので実⾏行行してみましょう l jubaclassifierを起動した状態でサンプルを実⾏行行 l 以下の様な結果が出れば成功 13 https://github.com/jubatus/jubatus-example $ cd jubatus-example/gender/python
$ ./gender.py female 0.473417669535 male 0.388551652431 female 2.79595327377 male -2.36301612854 ラベルごとのスコア
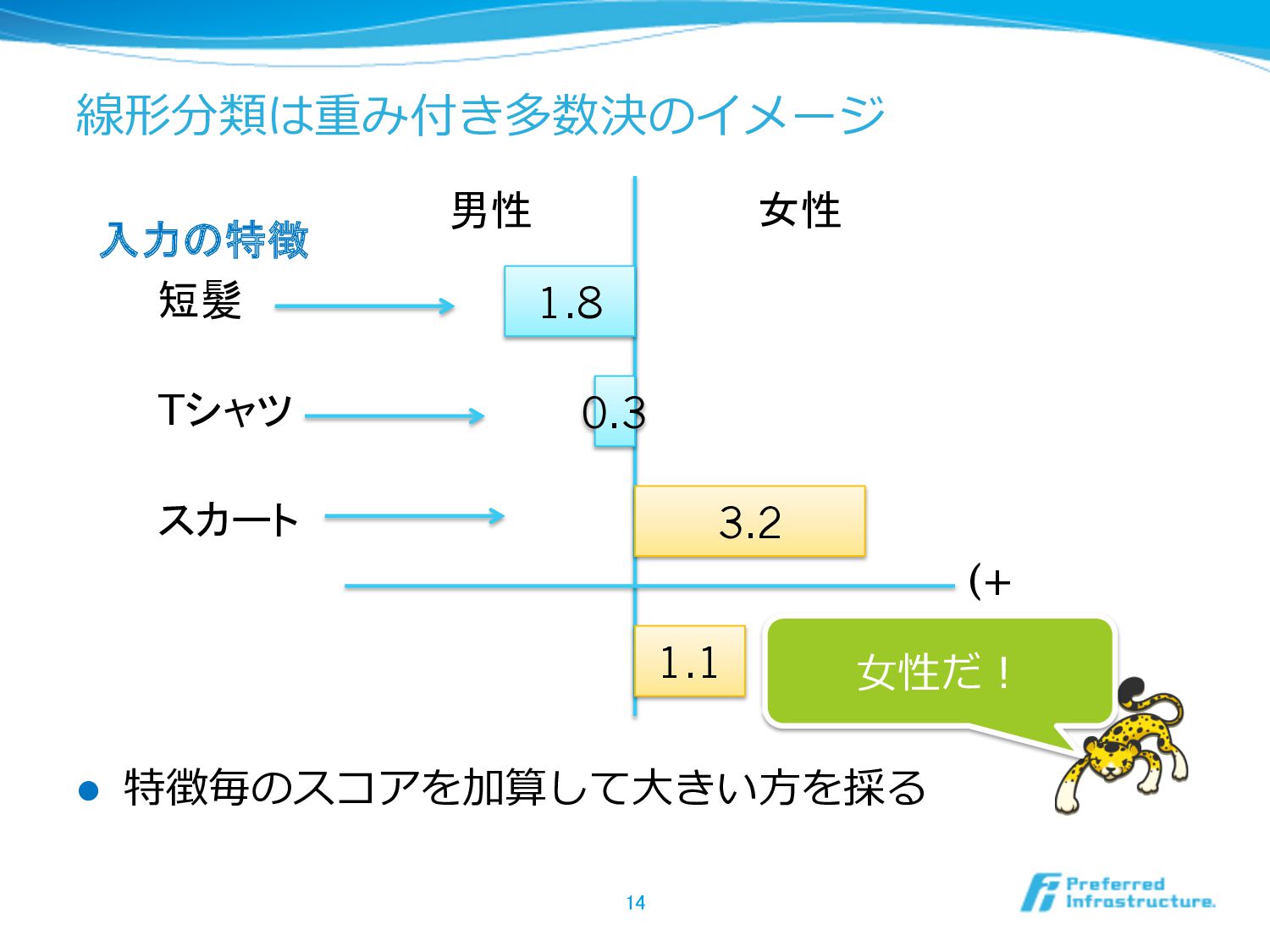
線形分類は重み付き多数決のイメージ l 特徴毎のスコアを加算して⼤大きい⽅方を採る 14 短髪 男性 女性 0.3 3.2 (+
1.1 1.8 Tシャツ スカート ⼥女女性だ! 入力の特徴
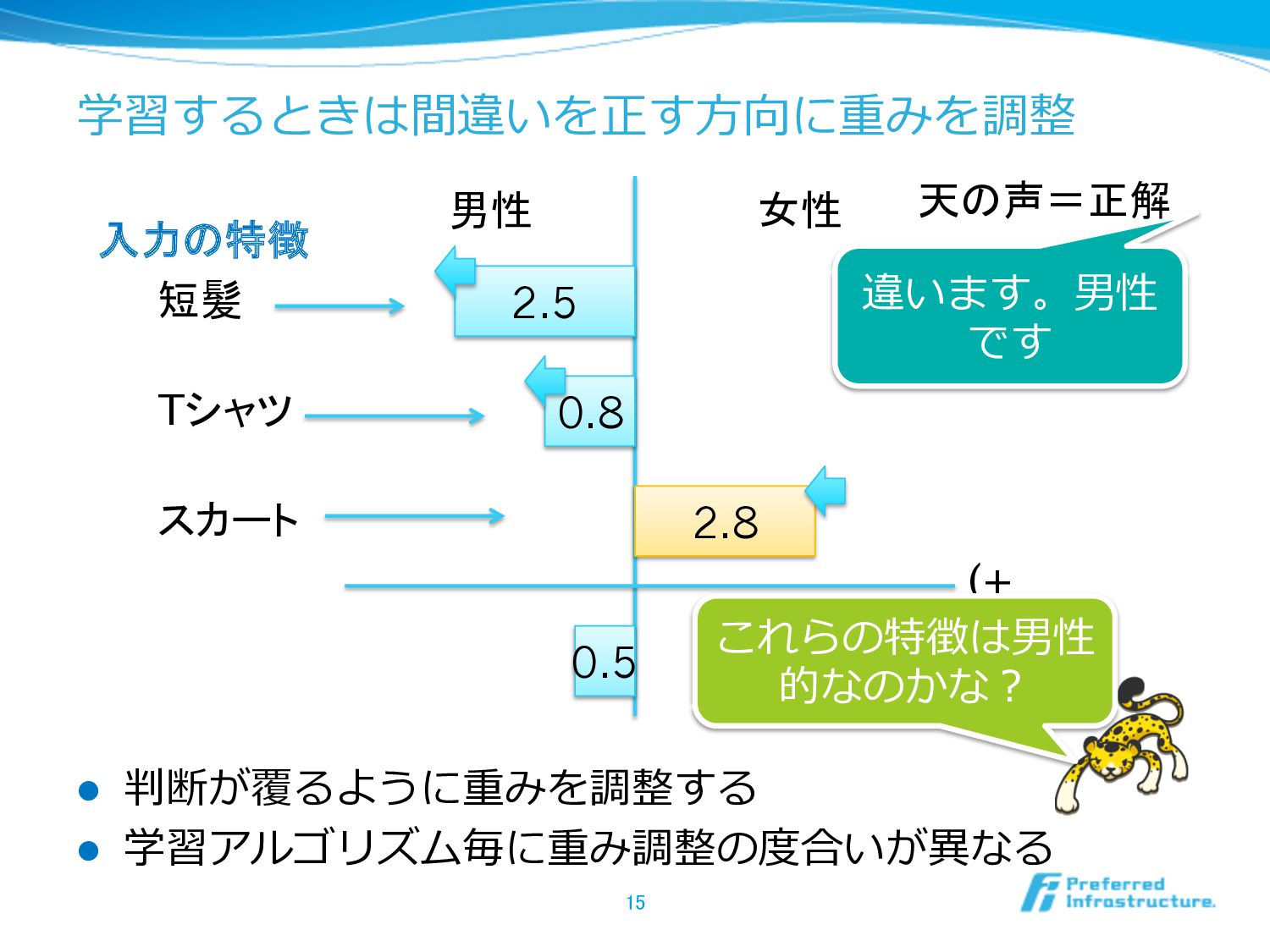
学習するときは間違いを正す⽅方向に重みを調整 l 判断が覆るように重みを調整する l 学習アルゴリズム毎に重み調整の度度合いが異異なる 15 短髪 男性 女性 0.8
2.8 (+ 2.5 Tシャツ スカート これらの特徴は男性 的なのかな? 入力の特徴 違います。男性 です 天の声=正解 0.5
サンプルを読んでみよう l sample.pyの中は⼤大雑把には以下のとおり 16 #(前略略) client = jubatus.Classifier(host, port) train_data
= [ ... ] client.train(name, train_data) test_data = [ ... ] results = client.classify(name, test_data) #(後略略)
Jubatusはクライアントオブジェクト経由で使う l 最初にクライアントオブジェクトを⽣生成する l クライアントオブジェクト経由で操作する 17 #(前略略) client = jubatus.Classifier(host,
port) train_data = [ ... ] client.train(name, train_data) test_data = [ ... ] results = client.classify(name, test_data) #(後略略)
正解のわかっているデータを使って学習(train)を⾏行行 う l 最初にクライアントオブジェクトを⽣生成する l クライアントオブジェクト経由で操作する 18 client = jubatus.Classifier(host,
port) train_data = [ ('male’, datum([('hair', 'short’), ...), ... ] client.train(name, train_data) test_data = [ ... ] results = client.classify(name, test_data)
学習したら未分類のデータを分類(classify)する l 最初にクライアントオブジェクトを⽣生成する l クライアントオブジェクト経由で操作する 19 client = jubatus.Classifier(host, port)
train_data = [ ... ] client.train(name, train_data) test_data = [ datum([('hair', 'short'), ... ), ... ] results = client.classify(name, test_data)
単体のデータを表すdatumクラスの構造に注意 l ⽂文字列列情報と数値情報のリストを別々に指定する l それぞれは、キーと値のペアのリストになっている l 下のデータは、”hair”が”short”、“top”が”T shirt”、”height”が 1.81と読む 20
datum( [('hair', 'short'), ('top', 'T shirt’),], [('height', 1.81)] )
データを追加してみよう l 学習⽤用のデータを増やすと⼀一般的に分類性能が良良くなる l 無限に増やしても、全て当たるようになるわけではない 21 client = jubatus.Classifier(host, port)
train_data = [ ('male’, datum([('hair', 'short’), ...), ... # ここにデータを追加 ] client.train(name, train_data) test_data = [ ... ] results = client.classify(name, test_data)
ラベルを追加してみよう l ラベルを細かくすると分類も細かくできる l 粒粒度度を細かくするとそれだけ正解率率率は落落ちるので注意 22 client = jubatus.Classifier(host, port)
train_data = [ ('male (adult)’, datum([('hair', 'short’), ...), ... ] client.train(name, train_data) test_data = [ ... ] results = client.classify(name, test_data)
l イントロダクション l Jubatusを使ってみる l 設定を変更更してみる 23
設定を⾒見見てみよう 24 { "converter" : { ... }, "parameter" :
{ "regularization_weight" : 1.0 }, "method" : "PA1" } 特徴抽出の設定 学習⽅方法のパラメータ 学習の⽅方法
学習アルゴリズムを変えてみよう l “method” は学習アルゴリズムを指定する l “PA1” から ”AROW” に変えてみる l
利利⽤用できるアルゴリズムはドキュメント参照 25 { "converter" : { ... }, "parameter" : { ... }, "method" : ”AROW" }
パラメータを変えてみよう l parameter はどのように学習するかの調整に使われる l 学習で調整されるパラメータとは区別する意味で、ハイ パーパラメータと呼ばれる l よい値はデータやアプリケーションによって異異なる 26
{ "converter" : { ... }, "parameter" : { "regularization_weight" : 10.0 }, "method" : "PA1" }
残りの設定は特徴抽出の設定です l converter は⽣生のデータをどう扱うかの、特徴抽出に関 する設定 l 設定のしどころであり、学習がうまくいくかの重要な部 分 27 {
"converter" : { ... }, “parameter” : { ... }, "method" : "PA1" }
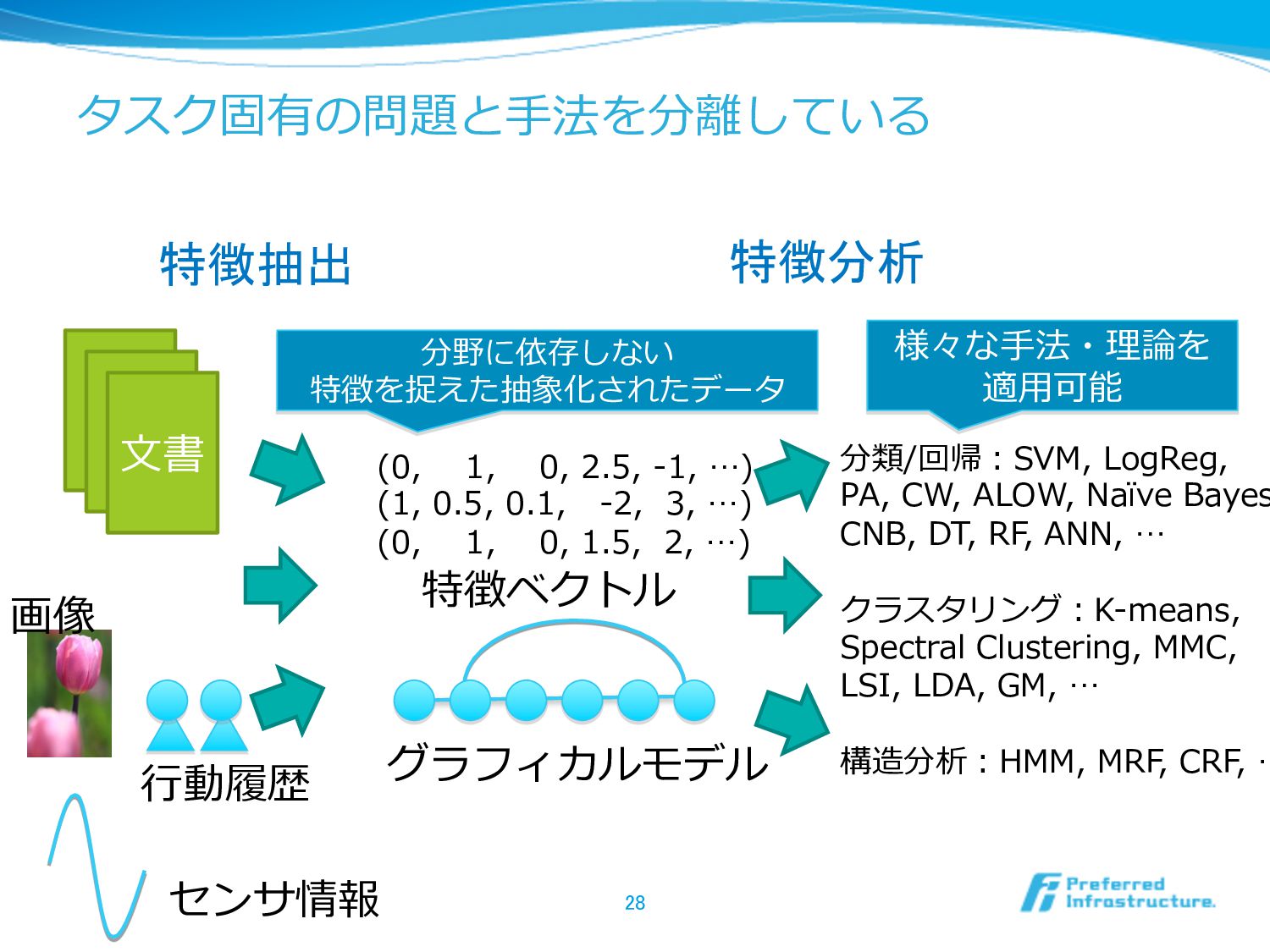
タスク固有の問題と⼿手法を分離離している 28 ⽂文書 (0, 1, 0, 2.5, -‐‑‒1, …) (1,
0.5, 0.1, -‐‑‒2, 3, …) (0, 1, 0, 1.5, 2, …) 特徴ベクトル グラフィカルモデル 分類/回帰:SVM, LogReg, PA, CW, ALOW, Naïve Bayes CNB, DT, RF, ANN, … クラスタリング:K-‐‑‒means, Spectral Clustering, MMC, LSI, LDA, GM, … 構造分析:HMM, MRF, CRF, … 画像 センサ情報 ⾏行行動履履歴 分野に依存しない 特徴を捉えた抽象化されたデータ 様々な⼿手法・理理論論を 適⽤用可能 特徴抽出 特徴分析
タスク固有の問題と⼿手法の分離離(続) l 特徴抽出と特徴分析を分離離することが重要 l データの種類、ドメイン、利利⽤用⽬目的に依存せず、様々な 分析を利利⽤用可能なしくみを作ることができる l 利利点 l システム開発・専⾨門家教育のコストを⼤大きく下げることができ
る l 特徴抽出では各問題ドメインに専念念 l 特徴分析では各分析⼿手法に専念念 29
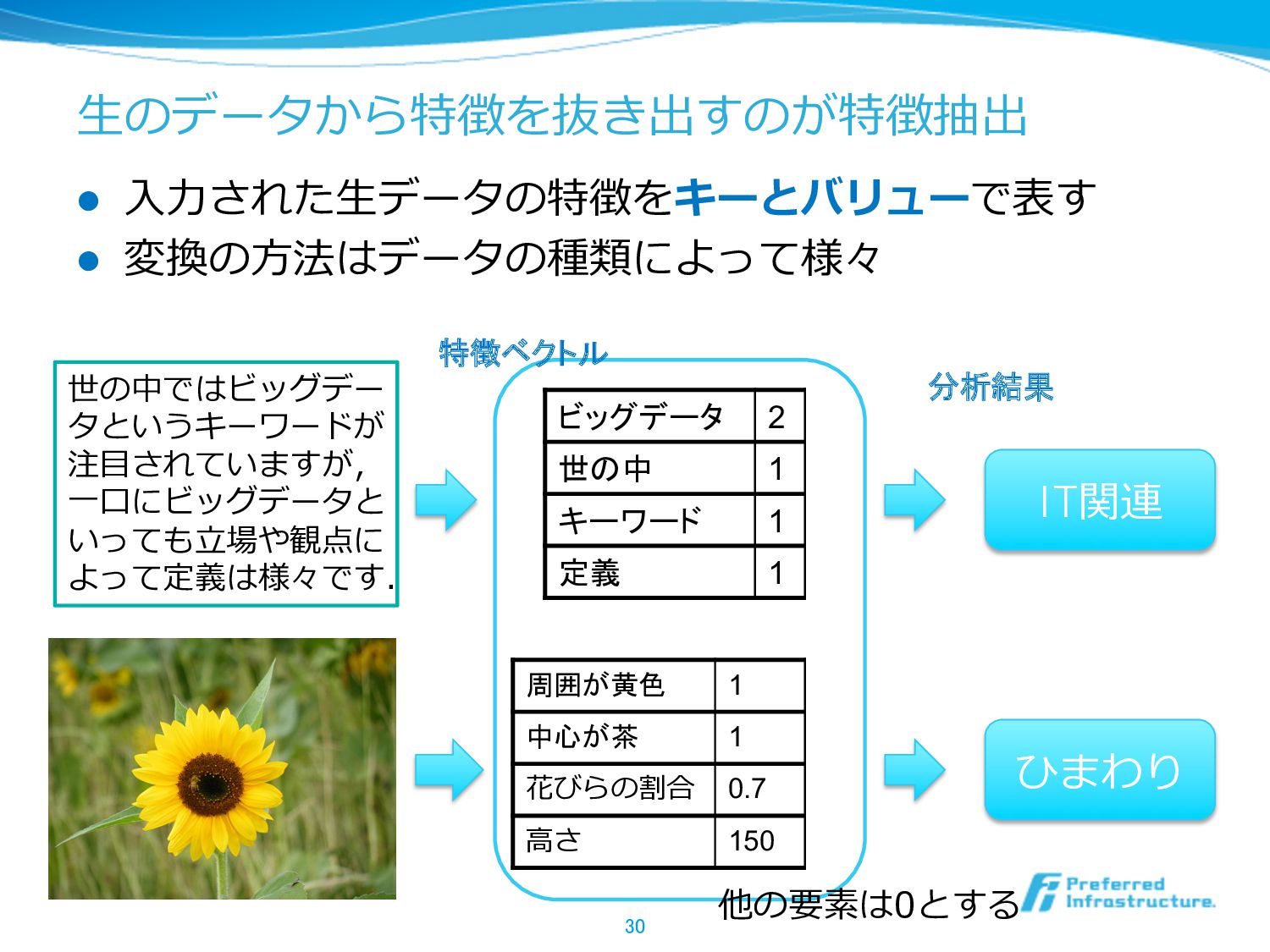
⽣生のデータから特徴を抜き出すのが特徴抽出 l ⼊入⼒力力された⽣生データの特徴をキーとバリューで表す l 変換の⽅方法はデータの種類によって様々 30 周囲が黄色 1 中心が茶 1
花びらの割合 0.7 ⾼高さ 150 世の中ではビッグデー タというキーワードが 注⽬目されていますが, ⼀一⼝口にビッグデータと いっても⽴立立場や観点に よって定義は様々です. 他の要素は0とする ビッグデータ 2 世の中 1 キーワード 1 定義 1 IT関連 ひまわり 特徴ベクトル 分析結果
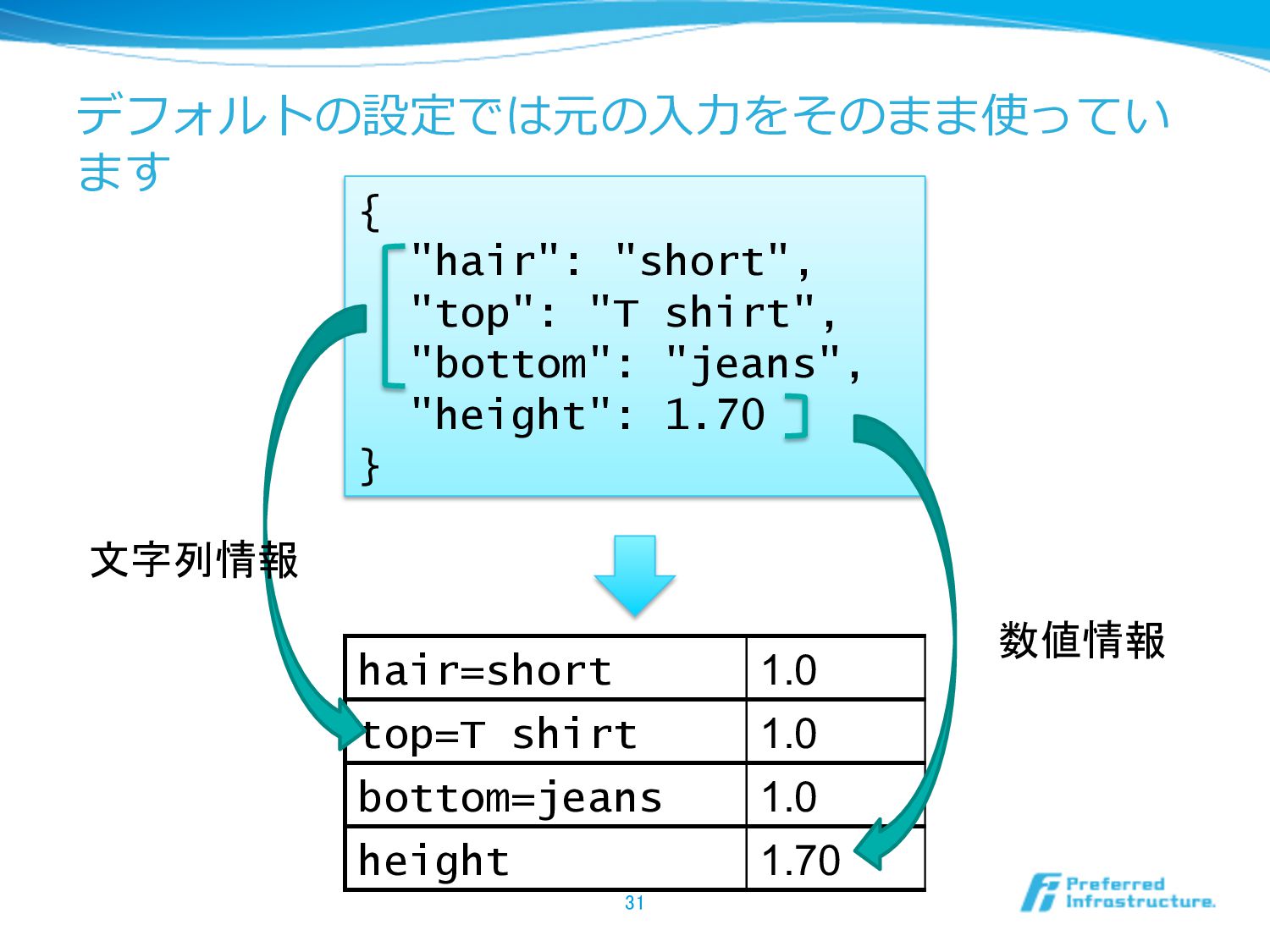
デフォルトの設定では元の⼊入⼒力力をそのまま使ってい ます 31 { "hair": "short", "top": "T shirt", "bottom":
"jeans", "height": 1.70 } hair=short 1.0 top=T shirt 1.0 bottom=jeans 1.0 height 1.70 文字列情報 数値情報
⽂文字列列に対する処理理 32 { "hair": "short", "top": "T shirt", "bottom": "jeans",
"height": 1.70 } hair=short 1.0 top=T shirt 1.0 bottom=jeans 1.0 height 1.70 l キーと値の組み合わ せで、1つの特徴に なるようにする l 値は1.0で固定
string_rulesに⽂文字列列データの変換規則を書きます l key: * 全てのデータに対して、 l type: str 値をそのまま使う l
sample_weight, global_weight: 重み付けは1.0 33 ... "string_rules" : [ { "key" : "*”, "type" : "str", "sample_weight" : "bin”, "global_weight" : "bin" } ], ...
数値に対する処理理 34 { "hair": "short", "top": "T shirt", "bottom": "jeans",
"height": 1.70 } hair=short 1.0 top=T shirt 1.0 bottom=jeans 1.0 height 1.70 l キーと値をそのまま 特徴の値となるよう にする
num_rulesに数値データの変換規則を書きます l key: * 全てのデータに対して l type: num 数値をそのまま使う 35
... ”num_rules" : [ { "key" : "*”, "type" : ”num” } ], ...
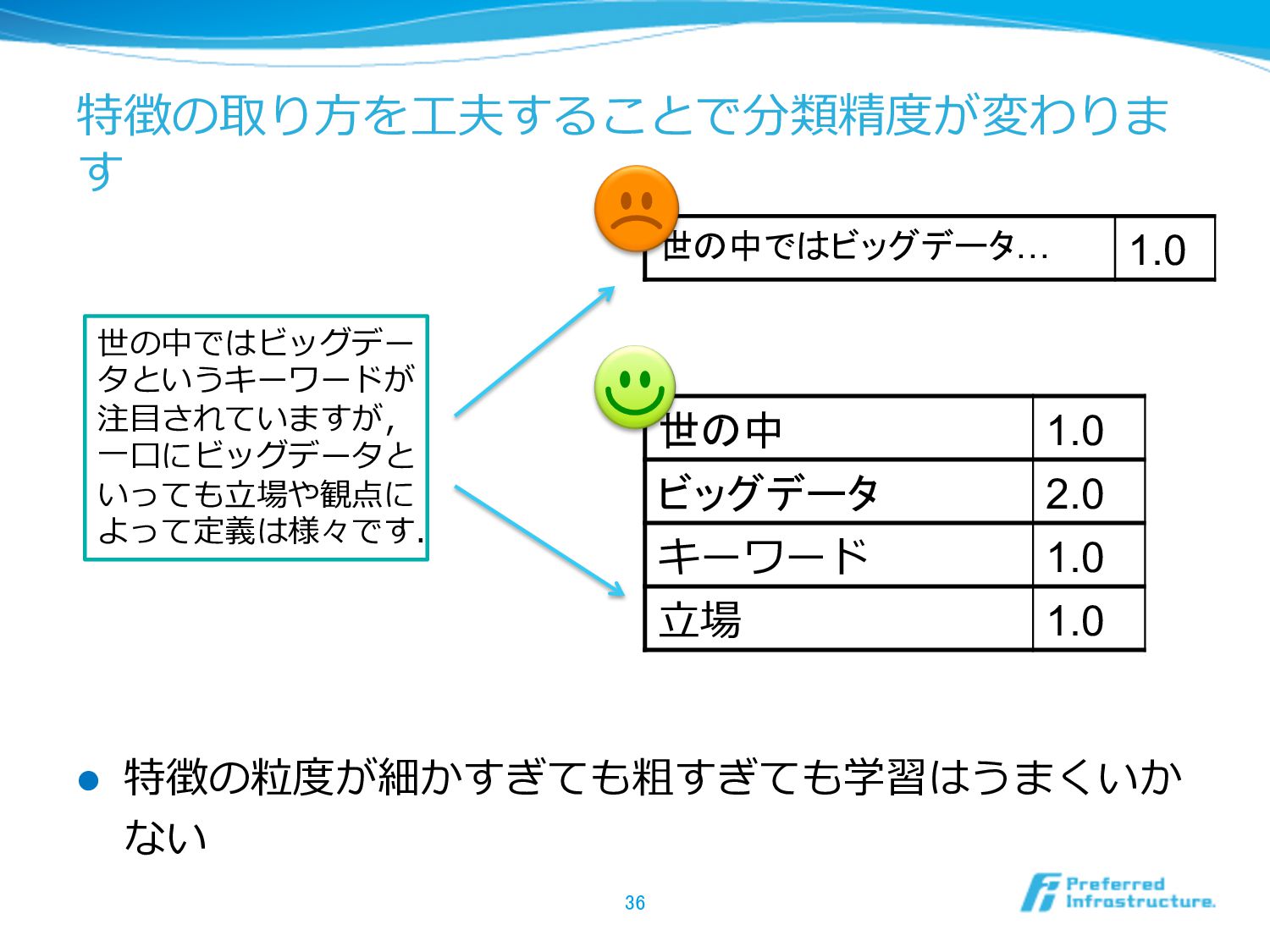
特徴の取り⽅方を⼯工夫することで分類精度度が変わりま す l 特徴の粒粒度度が細かすぎても粗すぎても学習はうまくいか ない 36 世の中ではビッグデー タというキーワードが 注⽬目されていますが, ⼀一⼝口にビッグデータと
いっても⽴立立場や観点に よって定義は様々です. 世の中ではビッグデータ… 1.0 世の中 1.0 ビッグデータ 2.0 キーワード 1.0 ⽴立立場 1.0
スペース区切切りで特徴をとってみましょう l スペース区切切りを使う場合はtypeにspaceを使う l 他にも特徴の取り⽅方は設定で簡単に変えられるので、ド キュメントを参照 37 ... "string_rules" :
[ { "key" : "*”, "type" : “space", "sample_weight" : "bin”, "global_weight" : "bin" } ], ...
その他の情報源 l ドキュメント l http://jubat.us/ja/ l 特徴抽出や設定周りもひと通り書いてある l メーリングリスト l
http://groups.google.com/group/jubatus l ソースとバグ報告 l https://github.com/jubatus/jubatus 38
⾃自由に改変してみましょう l jubatus-example以下に、⾊色々サンプルがあるので試し てみる l 分類以外のサンプルもあるが、記述⾔言語が限られている l よく知られたデータセットを利利⽤用してみる l http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets
l news20で検索索 l Enjoy! 39
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}