Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Jubatusにおける機械学習のテスト @Machine Learning Casual Talks
Search
Yuya Unno
June 06, 2014
Technology
21
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Jubatusにおける機械学習のテスト @Machine Learning Casual Talks
Yuya Unno
June 06, 2014
More Decks by Yuya Unno
See All by Yuya Unno
深層学習で切り拓くパーソナルロボットの未来 @東京大学 先端技術セミナー 工学最前線
unnonouno
0
29
深層学習時代の自然言語処理ビジネス @DLLAB 言語・音声ナイト
unnonouno
0
53
ベンチャー企業で言葉を扱うロボットの研究開発をする @東京大学 電子情報学特論I
unnonouno
0
50
PFNにおけるセミナー活動 @NLP2018 言語処理研究者・技術者の育成と未来への連携WS
unnonouno
0
20
進化するChainer @JSAI2017
unnonouno
0
30
予測型戦略を知るための機械学習チュートリアル @BigData Conference 2017 Spring
unnonouno
0
29
深層学習フレームワーク Chainerとその進化
unnonouno
0
31
深層学習による機械とのコミュニケーション @DeNA TechCon 2017
unnonouno
0
43
最先端NLP勉強会 “Learning Language Games through Interaction” @第8回最先端NLP勉強会
unnonouno
0
24
Other Decks in Technology
See All in Technology
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
Zoom2Youtube.Claude
kawaguti
PRO
3
490
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
220
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
160
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
3
200
スタートアップにおけるアジャイルの実践について #shibuyagile
murabayashi
3
2.2k
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
0
120
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
130
依頼文化をやめる日 EM視点で語るPlatform EngineeringとInclusive SRE / Discussing Platform Engineering and Inclusive SRE from an EM's Perspective
shin1988
4
5.1k
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
1
100
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
160
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
470
Featured
See All Featured
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
460
The SEO Collaboration Effect
kristinabergwall1
1
500
Designing for Performance
lara
611
70k
A Tale of Four Properties
chriscoyier
163
24k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
Tell your own story through comics
letsgokoyo
1
990
Design in an AI World
tapps
1
260
Transcript
Jubatusにおける機械学習の テスト 株式会社Preferred Infrastructure 海野 裕也 (@unnonouno) 2014/06/06 Machine Learning Casual
Talks@Cookpad
⾃自⼰己紹介 海野 裕也(@unnonouno) l (株) Preferred Infrastructure l Jubatus開発者 l 専⾨門:⾃自然⾔言語処理理、テキストマイニング
l クックパッドプレミアム会員 2
l 今⽇日はJubatusがどのようなテストをしている のかを話します l 別の⾔言い⽅方をすると、今までのJubatusのバグ の歴史を紹介します 3
Jubatus (http://jubat.us/) l 分散オンライン学習のフレームワーク l 分類・回帰・レコメンド・グラフ・近傍探索索・異異常検 知・クラスタリング l 特徴抽出エンジンも備えているので、⽣生データも扱える l
全て分散環境かつオンラインで動く 4
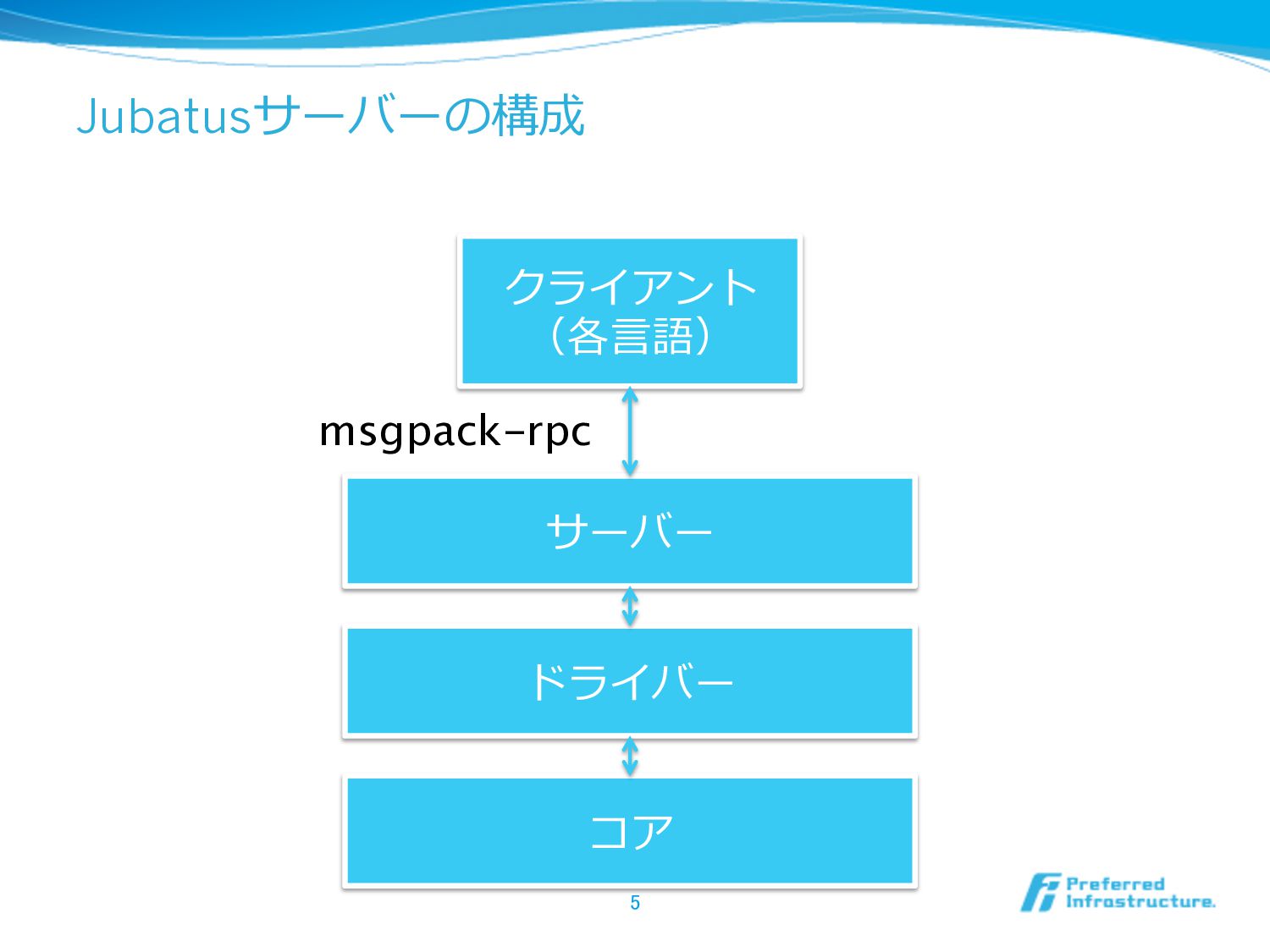
Jubatusサーバーの構成 5 サーバー クライアント (各⾔言語) msgpack-rpc ドライバー コア
各モジュールの役割 l サーバー・クライアント l msgpack-rpcサーバー・クライアントとして振る舞る l だいたい⾃自動⽣生成される l ドライバー l
⽣生データ(⽂文書など)を処理理する層 l 特徴抽出、重み付け、学習を結びつける役割 l コア l ベクトルを受け取る⽣生の学習器 l ベクトルを⽣生成する⽣生の特徴抽出器 l 最近リポジトリを分離離した(jubatus_core) 6
各レイヤーのテスト l サーバー・クライアント l 正しくクライアントのリクエスト受けつけて、処理理をドライ バーに投げられるか l ドライバー l ⽣生データを正しくそれぞれのモジュールに引き渡しているか
l コア l ちゃんと学習するか 7
各レイヤーのテスト l サーバー・クライアント l 正しくクライアントのリクエスト受けつけて、処理理をドライ バーに投げられるか l ドライバー l ⽣生データを正しくそれぞれのモジュールに引き渡しているか
l コア l ちゃんと学習するか 8 割りと一般的なテスト
各レイヤーのテスト l サーバー・クライアント l 正しくクライアントのリクエスト受けつけて、処理理をドライ バーに投げられるか l ドライバー l ⽣生データを正しくそれぞれのモジュールに引き渡しているか
l コア l ちゃんと学習するか 9 今日の話はこっち
「ちゃんと」って? 10
3つの「ちゃんと」の話をします l 「ちゃんと」問題が解けるか l 「ちゃんと」論論⽂文通りか l 「ちゃんと」使えるか 11
「ちゃんと」問題を解けるか どう考えても解けるだろうという擬似問題を解かせる 12 (1, 1)と(-1, -1)を原点、分散1の正規分布からそれ ぞれ正例例と負例例をサンプリングして分類器に投げ て学習する 例:分類器の場合
テストを書いてみた・・ l Perceptron l 正解率率率:95% l Passive Aggressive l 正解率率率:97%
l Confidence Weighted l 正解率率率:98% l AROW l 正解率率率:98% l NHERD l 正解率率率:70% 13
??? 14
何か変だ・・ 15 流流⽯石に精度度低くないですかね? ハイパーパラメータ チューニングしてないし、 不不安定な⼿手法なのかもね ナルホド、タシカニ
落落ち着いて考えよう しかし、2以上も離離れている点を中⼼心にして分散 1ってことは、もうほとんど線形分類可能だろう どんな適当なことしても70%ってことはなくない か・・・??? 16
Crammer系⼿手法のおさらい 17 initialize w, ∑" for (x, y) in data:"
#m = y (x・w)" #if m < e:" # #w := w + αy∑x" # #update ∑" l ベースのアルゴリズムはシンプル l 各⼿手法は、上記のe, α, ∑だけが違う
とはいえ、予想以上にグチャグチャ 式が極めて⻑⾧長いということはないが、正しく写経 できているか確認しづらい 18
雰囲気だけ・・・ 19 void normal_herd::update( const common::sfv_t& sfv, float margin, float
variance, const string& pos_label, const string& neg_label) { for (common::sfv_t::const_iterator it = sfv.begin(); it != sfv.end(); ++it) { // 中略略 storage_->set2(feature, pos_label, storage::val2_t(pos_val.v1 + (1.f - margin) * val_covariance_pos / (val_covariance_pos * val + 1.f / C), 1.f / ((1.f / pos_val.v2) + (2 * C + C * C * variance) * val * val))); if (neg_label != "") { storage_->set2(feature, neg_label, storage::val2_t(neg_val.v1 + (1.f - margin) * val_covariance_neg / (val_covariance_neg * val + 1.f / C), 1.f / ((1.f / neg_val.v2) + (2 * C + C * C * variance) * val * val))); } } } この中に⼀一箇所だけ+と−を間違えています
結局、何が起こっていたか l 1箇所だけ正負を間違えていた l 何度度も何度度も⾒見見返してようやく発⾒見見した l 数式とコードのギャップは深い l 発散するでもなく、完全にランダムでもなく、 妙に精度度が低かった
l 精度度が思ったよりも悪かったら、疑うべき(あ たりまえだけど) 20
「ちゃんと」論論⽂文の書いてある通りに実装されてい るか l 「精度度が出ない」ことがわかるのなら、頑張っ て原因を探せば良良い l 「精度度が出ていた」ら、正しく実装できている のか? 細部が異異なっていても「割と期待通りに」 動いてしまうことは多い
21
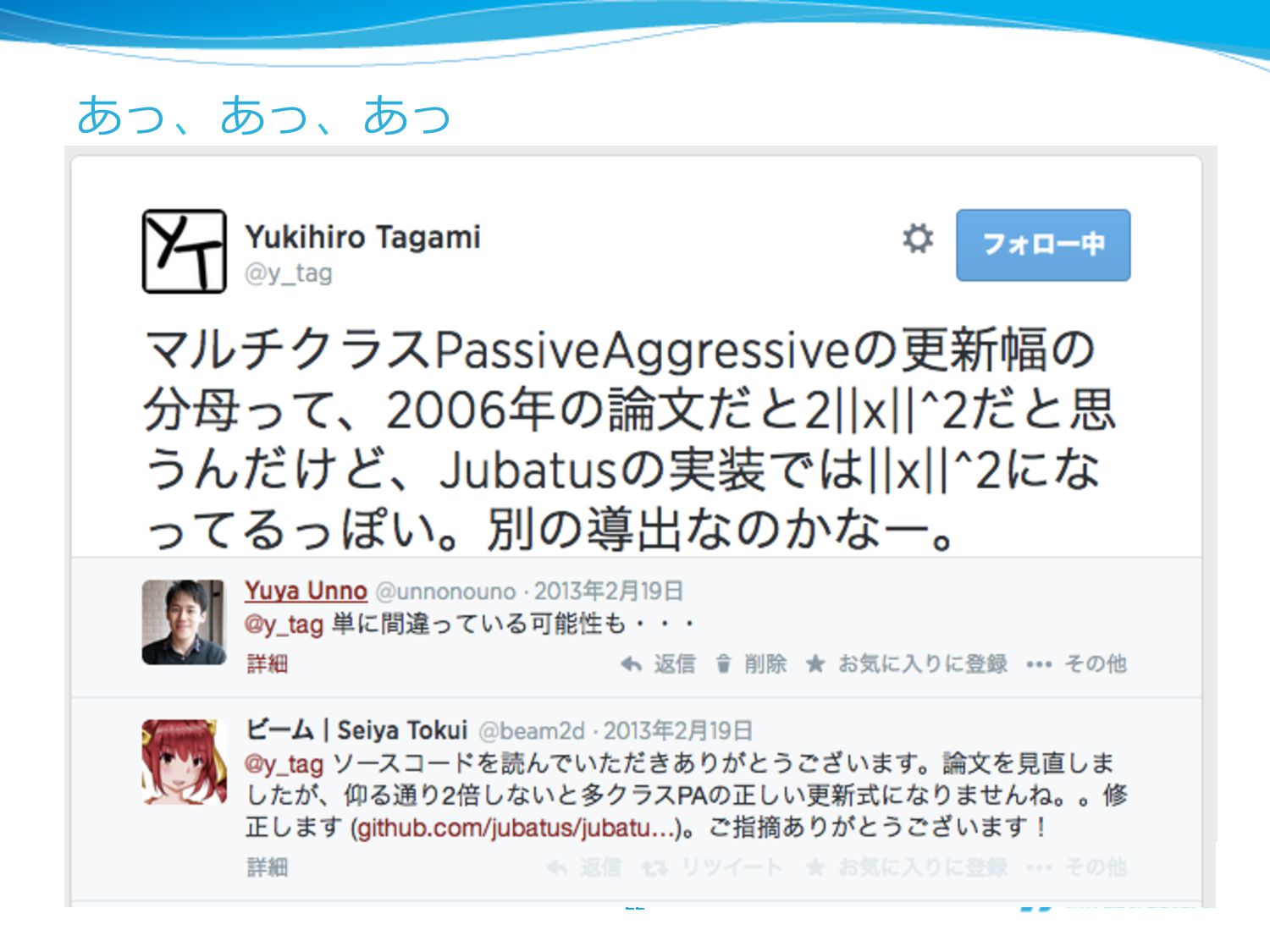
あっ、あっ、あっ 22
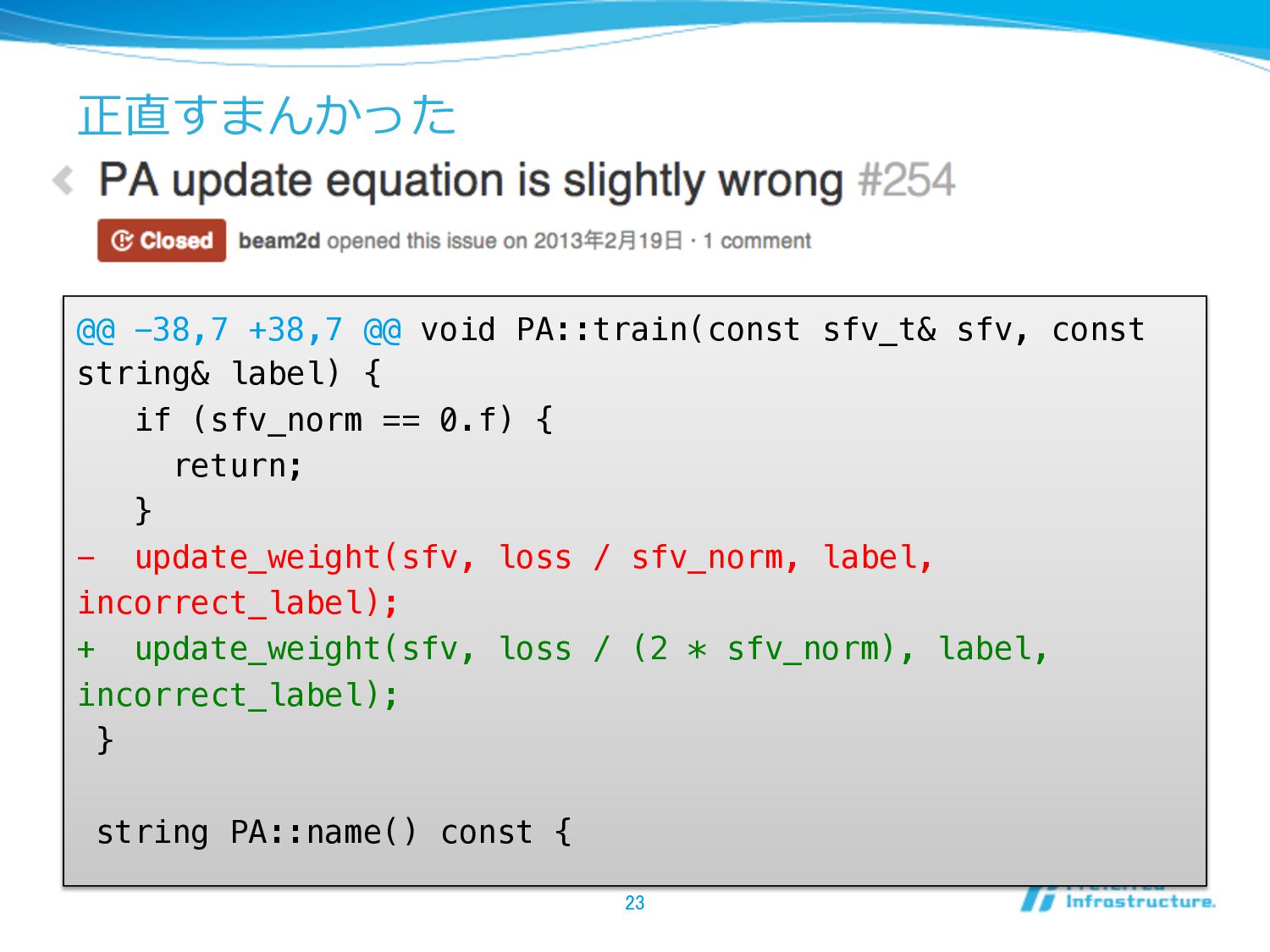
正直すまんかった @@ -38,7 +38,7 @@ void PA::train(const sfv_t& sfv, const
string& label) {" if (sfv_norm == 0.f) {" return;" }" - update_weight(sfv, loss / sfv_norm, label, incorrect_label);" + update_weight(sfv, loss / (2 * sfv_norm), label, incorrect_label);" }" " string PA::name() const { 23
結局、どうなったのか l そこらにあるテストセット(news20など)を利利 ⽤用して精度度の変化を試したが、ほとんど変わら なかった l 何故か間違った実装のほうが精度度が出た l 意図した実装でないことは事実、しかし発⾒見見は 極めて困難
l テストだけでは発⾒見見出来ない 24
「ちゃんと」利利⽤用者に使い⽅方がわかるか l 実装のテストというか仕様のテスト? l どういう設定をするどどうなるのかが利利⽤用者に とってわかりやすくなっているか l もっと⾔言えば、望まない結果が得られた時にど う対処すればよいかわかるようにできているか 25
みんな⼤大好き-cオプション l 「Cいくつにした?」と聞かれる l 正則化項と損失の⽐比率率率を調整する重みのこと 26 % svm-train" Usage: svm-train
[options] training_set_file [model_file]" options:" ..." -c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)" ...
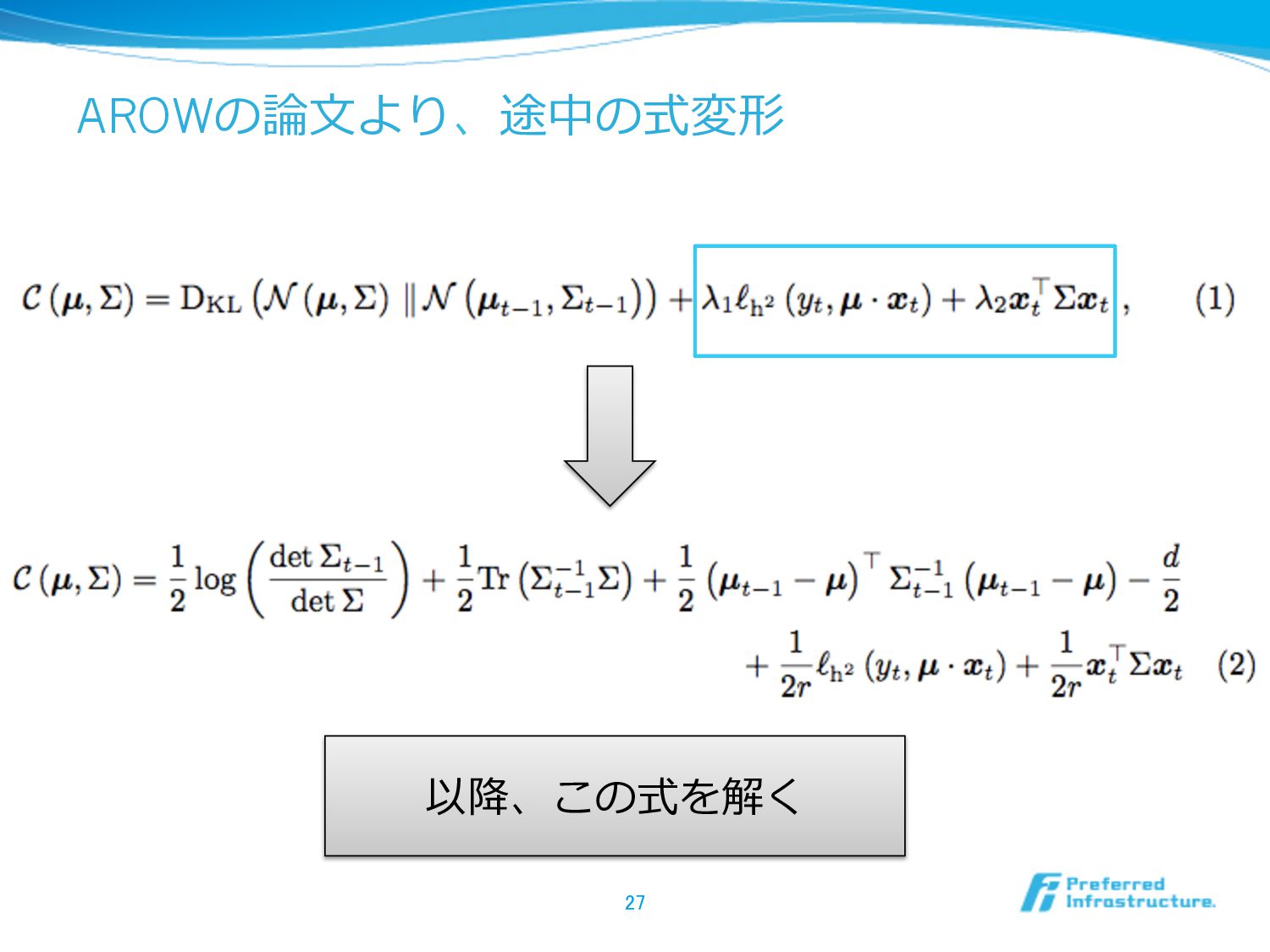
AROWの論論⽂文より、途中の式変形 27 以降降、この式を解く
λ1 とλ2 どこ⾏行行った? 28
AROWの論論⽂文より 29
AROWの論論⽂文より 30
r、お前誰? 31
よく⾒見見ると・・・ l 本質的には r と λ の役割は同じ l ところが⼤大⼩小関係が逆なので、⼤大きくしたり⼩小 さくした時の挙動が他のアルゴリズムと逆にな
る 32
ハイパーパラメータは所詮ハイパーパラメータ l λ が正しいか 1/r が正しいかの議論論は不不⽑毛 l いずれにせよ、ハイパーパラメータチューニン グで最適化するものであるから、いずれかが間 違いとは⾔言えない
l 利利⽤用者側の観点でみると、考えるべきは論論⽂文と の整合性よりも使い勝⼿手(⼀一貫性) 33
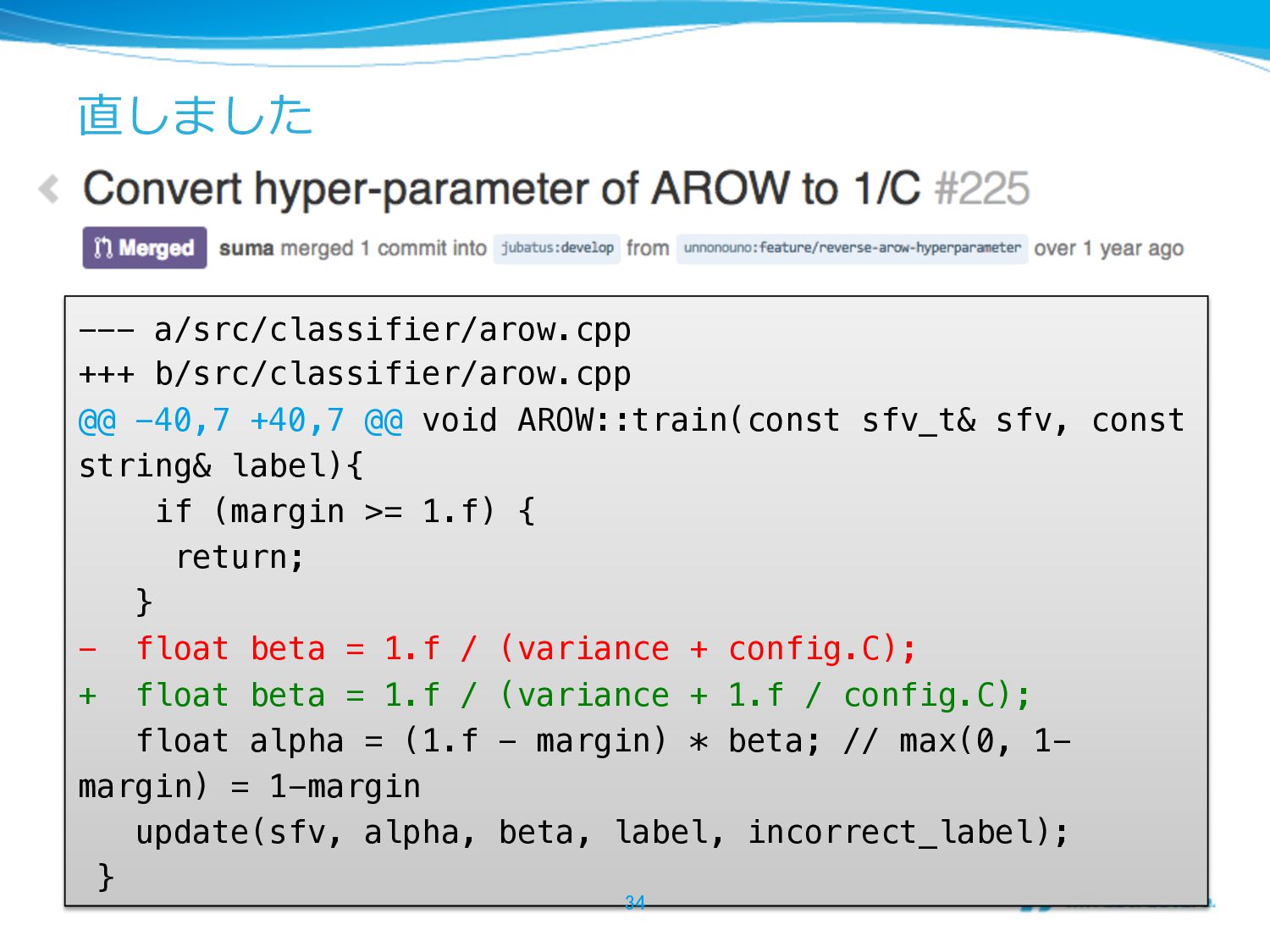
直しました --- a/src/classifier/arow.cpp" +++ b/src/classifier/arow.cpp" @@ -40,7 +40,7 @@ void
AROW::train(const sfv_t& sfv, const string& label){" if (margin >= 1.f) {" return;" }" - float beta = 1.f / (variance + config.C);" + float beta = 1.f / (variance + 1.f / config.C);" float alpha = (1.f - margin) * beta; // max(0, 1- margin) = 1-margin" update(sfv, alpha, beta, label, incorrect_label);" } 34
直しました 35
設定の与え⽅方を気をつける l 式中のハイパーパラメータを外から設定できる ようにしたいが、パラメータに名前をつけるの は難しい l 仮に「元論論⽂文(2)式中のrです」と書いても、適 切切な値は探索索しないとわからない l 上下したときの影響がわかりやすく、⼀一貫性が
取れるようにする 36
ハイパーパラメータが1つだけだと思うなよ l 分類器なら正則化パラメータや学習率率率程度度だっ た l 教師無しになるほど何かしらの過程を置く l ◯◯分布を仮定する l ◯◯個のトピック、クラスタを仮定する
37 ハイパーパラメータの数が爆発
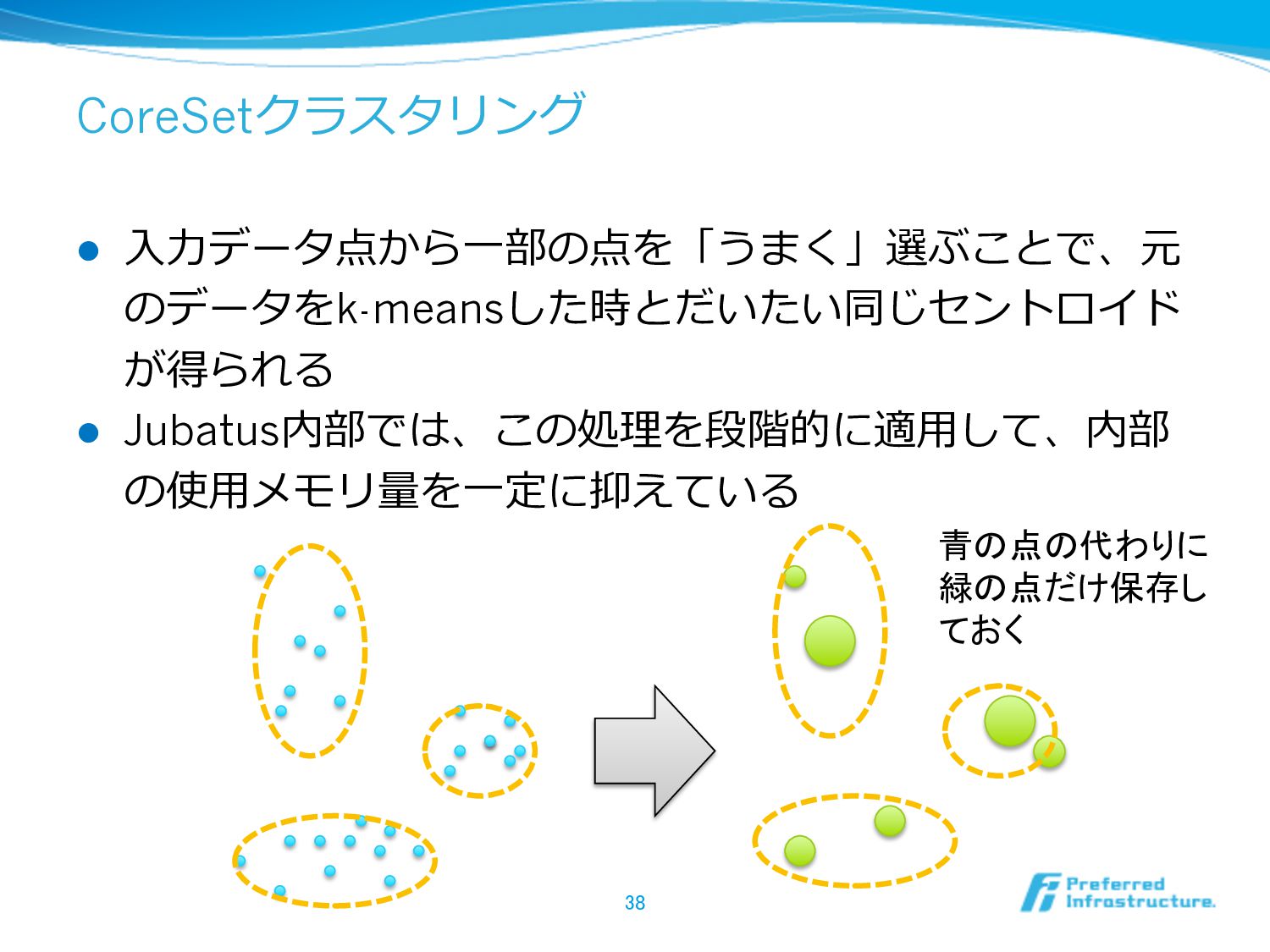
CoreSetクラスタリング l ⼊入⼒力力データ点から⼀一部の点を「うまく」選ぶことで、元 のデータをk-meansした時とだいたい同じセントロイド が得られる l Jubatus内部では、この処理理を段階的に適⽤用して、内部 の使⽤用メモリ量量を⼀一定に抑えている 38 青の点の代わりに
緑の点だけ保存し ておく
お、おう・・・ l クラスタ数K以外に、 ハイパーパラメータ が沢⼭山 39 設定値は6個ある
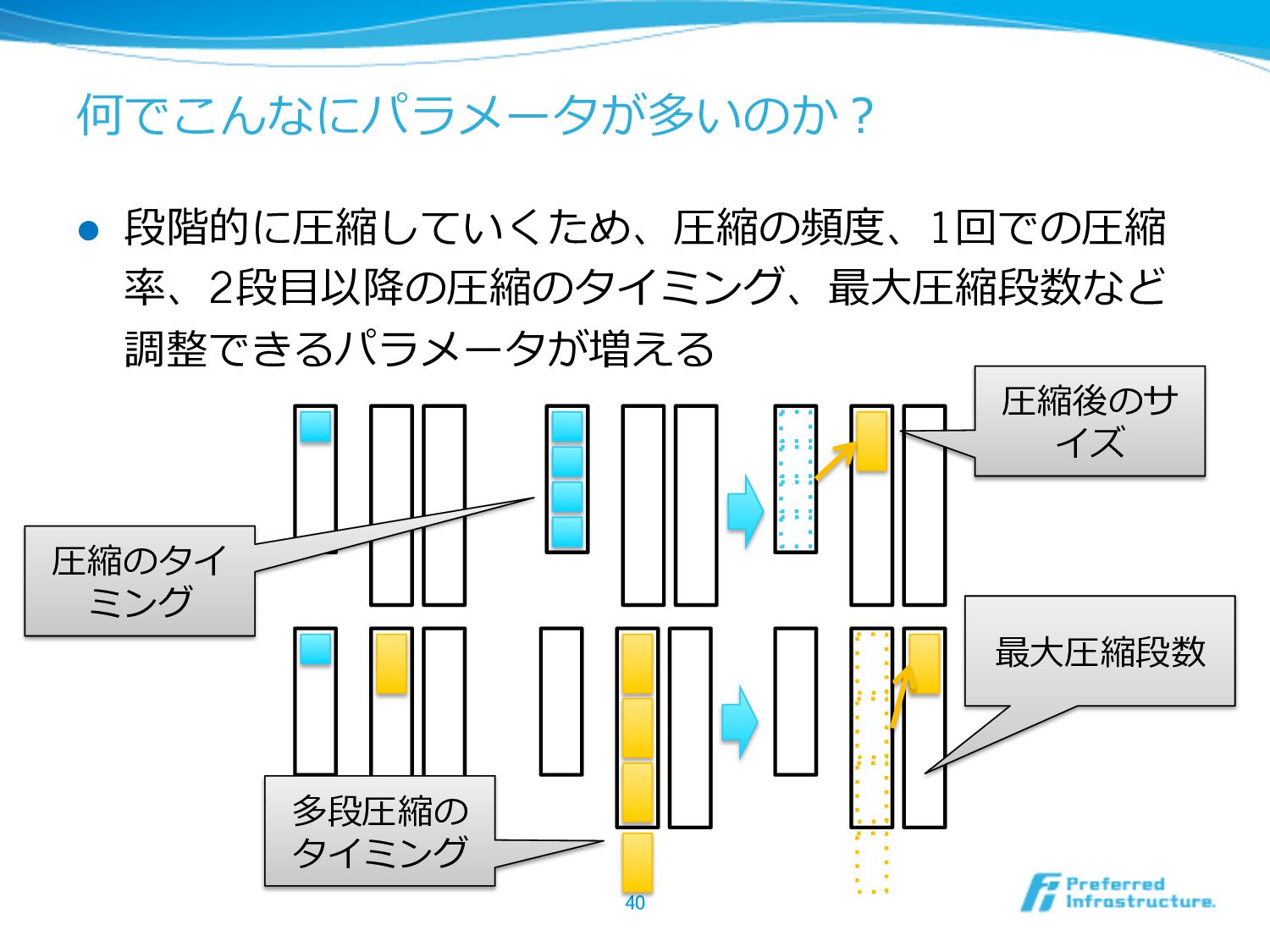
何でこんなにパラメータが多いのか? l 段階的に圧縮していくため、圧縮の頻度度、1回での圧縮 率率率、2段⽬目以降降の圧縮のタイミング、最⼤大圧縮段数など 調整できるパラメータが増える 40 圧縮のタイ ミング 圧縮後のサ イズ
多段圧縮の タイミング 最⼤大圧縮段数
最近思っていること パラメータによる影響範囲がなるべく限定的にし、 複数の変化が起きにくくするのがよい l メモリ消費量量 l イテレーションの時間 l スループット l
直近のデータへの感度度・過去データの忘却の程 度度 41 1つのパラメータで3つ以上変化 すると制御は難しい
まとめ l 「ちゃんと」問題が解けるか l 解けそうな問題を解けるか l 簡単な問題にヒドイ間違いをしないか l 「ちゃんと」論論⽂文通りか l
数式はちゃんと写しているか l 確認する⽅方法は・・・頑張れ・・・ l 「ちゃんと」使えるか l 設定は⼗十分意味が伝わり、⼀一貫性が有るか l 挙動を制御しやすいか 42
次回 「機械学習のデバック術」 乞うご期待 43
ご静聴ありがとうございました 44
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}