Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
縮小推定のはなし.pdf
Search
Takayuki Uchiba
March 02, 2019
Science
2.8k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
縮小推定のはなし.pdf
Takayuki Uchiba
March 02, 2019
More Decks by Takayuki Uchiba
See All by Takayuki Uchiba
statistician_ja_lt5.pdf
utaka233
0
730
高次元データに対するL1正則化の有効性
utaka233
1
3.3k
Other Decks in Science
See All in Science
SpatialRDDパッケージによる空間回帰不連続デザイン
saltcooky12
0
280
Kritische evaluatie van GenAI-output voor literatuuronderzoek
voginip
0
200
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
240
「念のためのログ保存」を組織全体でやめるためのポリシーと仕組み作り
i2tsuki
4
320
明治薬科大学講義_ビッグデータ解析を支えるデータベース技術とクラウドコンピューティング
ktatsuya
1
140
Utiliser Bitcoin sans Internet
rlifchitz
0
310
Bear-safety-running
akirun_run
0
180
データベース06: SQL (3/3) 副問い合わせ
trycycle
PRO
1
1.1k
Snowflake HCLS Meet Upヘルスケアユーザー会紹介
ktatsuya
0
120
AI(人工知能)の過去・現在・未来 ~AIは人類を越えるのか~
tagtag
PRO
0
130
20260220 OpenIDファウンデーション・ジャパン ご紹介 / 20260220 OpenID Foundation Japan Intro
oidfj
0
380
機械学習 - 決定木からはじめる機械学習
trycycle
PRO
0
1.6k
Featured
See All Featured
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
440
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
230
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
4 Signs Your Business is Dying
shpigford
187
22k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
340
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
The World Runs on Bad Software
bkeepers
PRO
72
12k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
410
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
260
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
640
Paper Plane (Part 1)
katiecoart
PRO
1
9.9k
Transcript
縮小推定のはなし @utaka233 Tokyo.R #76, 03/02/2019
Table of Contents • 1. motivation • 2. 縮小推定とは •
3. 縮小推定の可能性
1. motivation 打者の生涯打率推定を例に
今回考える問題 • こんな問題を考えたい。 • web広告 : 各キャンペーンのCTRの推定 • セイバーメトリクス :
各打者の打率の推定 • 社会科学 : 各県の1世帯あたりの平均教育費の推定 campaign 1 campaign 2 campaign d 母CTR = ?% 母CTR = ?% 母CTR = ?% 母集団 4 clicks / 237 imps 8 clicks / 968 imps 2 clicks / 120 imps 標本 … …
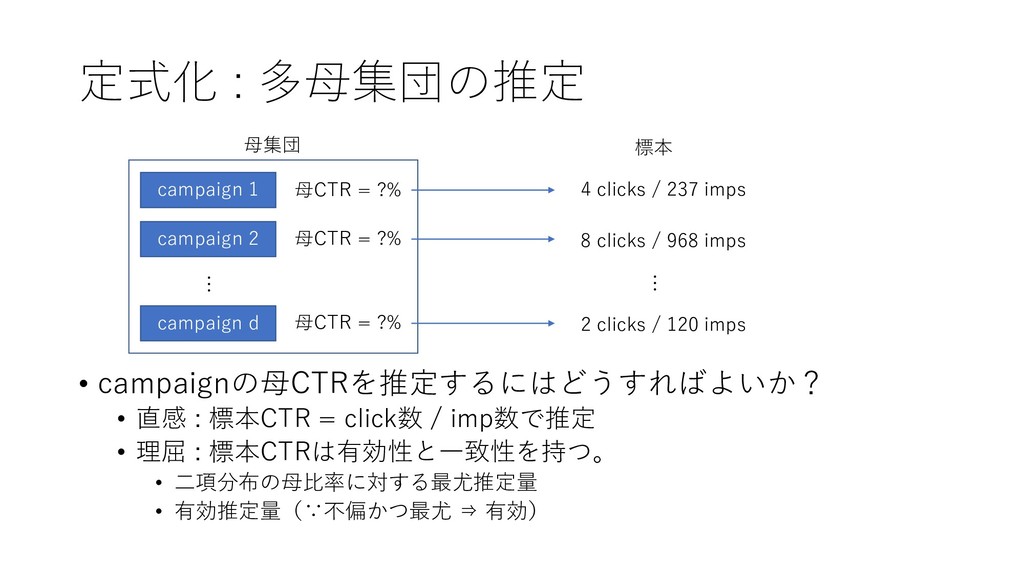
定式化 : 多母集団の推定 • campaignの母CTRを推定するにはどうすればよいか? • 直感 : 標本CTR =
click数 / imp数で推定 • 理屈 : 標本CTRは有効性と一致性を持つ。 • 二項分布の母比率に対する最尤推定量 • 有効推定量(∵不偏かつ最尤 ⇒ 有効) campaign 1 campaign 2 campaign d 母CTR = ?% 母CTR = ?% 母CTR = ?% 母集団 4 clicks / 237 imps 8 clicks / 968 imps 2 clicks / 120 imps 標本 … …
例 : 打者の生涯打率推定 • 打者の生涯打率推定 • 対象 : 通算で500打席以上に立った打者 •
デビューした年度の打率を用いて生涯打率を推定する。 • library(Lahman)のBattingデータセットを用いる。 標本抽出
例 : 推定量の比較 • 2つの推定量を比較してみよう。 • MLE : 手元のデータから計算できる打率(標本比率) •
mystery : 何者??
例 : 平均2乗誤差による評価 • MSE(平均2乗誤差)の比較 • MSEとは : • どうやらmysteryはMLE(標本比率)より良い推定量らしい。
• efficiency = mysteryのMSE / MLEのMSE • MLEよりmysteryのほうが、全体的にはground truthに近い値をとっている。
例 : たまたまでは? • もう一度やってみる。たまたまでは? 単なる偶然ではなさそう…?
mysteryは何者? • mysteryの正体 • 平均方向に縮小する推定量 • 他の打者の情報をつかって推定効率を良くする。そんなことができるのか? • James-Stein型推定量という。
試してみてください。 • GitHubにスクリプトを貼っておいたので、試してみてください。 • URL : https://github.com/utaka233/tokyor76/tree/master • stein.R :
例に掲げた計算を行うためのスクリプト
2. 縮小推定とは 原点や平均方向への縮小がもたらす平均2乗誤差の効率性
良く用いられる推定量の良さとは • 不偏性と標準誤差 • MSEのバイアス・バリアンス分解 • 第1項:バイアス, 第2項:推定量の標準誤差 • 不偏推定量
= バイアスのない推定量 • 平均2乗誤差が最小の推定量を見つけるのは困難。不偏推定量はそこまででもない。 • 標準誤差が最小の不偏推定量を求めればよい。→ 一様最小分散不偏推定量 • Cramer-Rao下限(達成できる場合、有効性を持つという。) • 例:母平均に対する標本平均, 母分散に対する不偏分散, …
平均2乗誤差最小推定量 • 平均2乗誤差最小推定量 ≠ 一様最小分散不偏推定量 • 代表例:正規分布の母分散の推定 • バイアスを許してしまう。 •
その代わりに標準誤差を小さくする。 N(0, 100)から25個の標本をとる。
2つの推定量の比較 • 一様最小分散不偏推定量 • 各推定時に期待される値は真のパラメータの値そのもの。 • 推定ごとに得られる値はやや不安定。 • 平均2乗誤差最小推定量 •
各推定時に期待される値は真のパラメータより少しズレている。 • 推定ごとに得られる値は安定。 • 要するに、真のパラメータより少しズレた値ではあろうけれど、言うて近い値を 安定して得ることが出来る。
Stein現象 • 問題設定 • 3群以上の正規母集団を考えてください。 • 母平均は未知とします。 • 母分散は既知、すべての群で等しいとしてよいことにします。 •
各群からサイズ1の標本をひとつずつ抽出しましょう。 • 各群の母平均を推定してください。 直感的には、各群の標本の値そのもので推定するしかない。 しかし、もっと良い推定量がある。 James-Stein推定量, Stein (1956)
James-Stein推定量 • James-Stein推定量 • 原点への縮小 • 標本の値をそのまま推定に使うより、少し0に近づけた値を使っている。 • 不偏推定量ではない。要するにbiasを許している。 •
その代わり、平均2乗誤差は一様最小分散不偏推定量より小さい。 • 要するに標準誤差が小さい。
なぜ他の群の情報が役立つ? • 経験ベイズ推定量による解釈 • 実はJames-Stein推定量は、経験ベイズ推定量と一致している。 • 以下、母分散を1として証明のoutlineを説明します。 • 母平均パラメータの事前分布を正規分布とします。 •
期待値を0, 分散をAとしましょう。 • 分散Aはmoment法で推定してしまう。(経験ベイズ) • ベイズ更新により以下の事後分布を得る。あとはEAPを考えればよい。
平均への縮小 • 平均への縮小 • 群が4以上の場合には、全体平均へ縮小する推定量がある。 二項分布の正規近似
注:母比率の場合の経験ベイズ推定量 • 母比率の(経験)ベイズ推定 • beta-二項モデル : 事前分布はbeta分布、母集団モデルは二項分布。 • library(ebbr) •
beta-二項モデルの経験ベイズ推定を行うパッケージ
3. 縮小推定の可能性 縮小推定が活躍する場面とは
縮小推定のプライオリティ • 多母集団における標準誤差の改善 • ドメイン知識が存在する場合 • 広告のCTRは基本的に0に近い値を取るなど。 • 原点や平均値など任意の値に対して推定量を縮小できる。 •
小地域推定 • 各母集団ごとに推定すると、各群で標本サイズが違う場合と標本サイズが小さい 群のほうが大きい群より標準誤差が高くなってしまう。
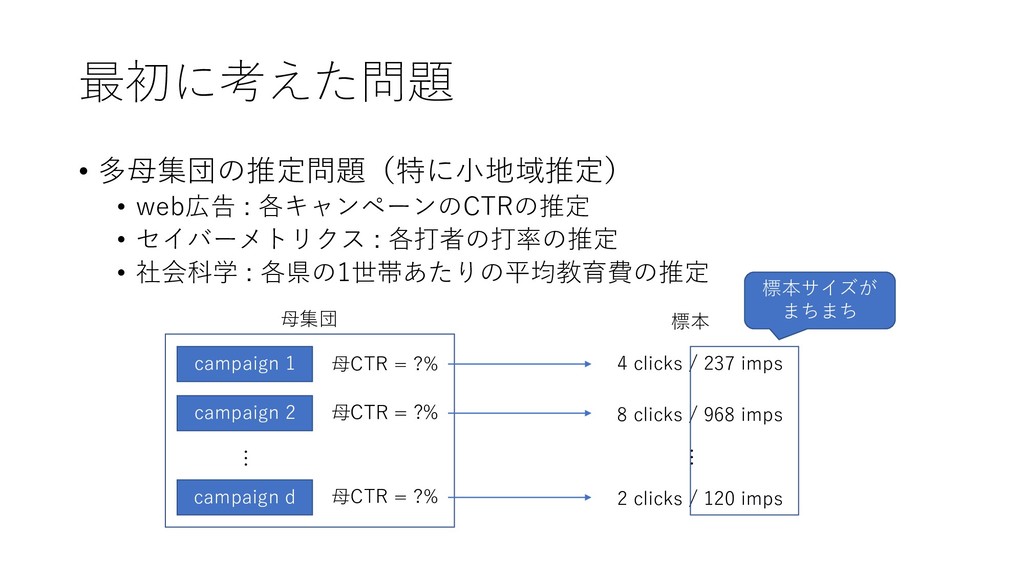
最初に考えた問題 • 多母集団の推定問題(特に小地域推定) • web広告 : 各キャンペーンのCTRの推定 • セイバーメトリクス :
各打者の打率の推定 • 社会科学 : 各県の1世帯あたりの平均教育費の推定 campaign 1 campaign 2 campaign d 母CTR = ?% 母CTR = ?% 母CTR = ?% 母集団 4 clicks / 237 imps 8 clicks / 968 imps 2 clicks / 120 imps 標本 … … 標本サイズが まちまち
4. おわりに 自己紹介とか…。
自己紹介 • お仕事 • 2014-現在 : 株式会社すうがくぶんか(現在 : 教務部 部長)
• 2015-現在 : 株式会社オモロワークス データサイエンティスト • 2018-現在 : 株式会社スカイディスク 技術顧問 • 経歴 • 2015年 : 修士(理学, 早稲田大学)代数幾何学専攻 • 2015年 : 統計検定1級, 人文科学優秀者A
We Are Hiring ! マーベリックでは機械学習エンジニアを募集しています。 機械学習を活用し、広告配信システムの 機能開発を行いませんか? 実務経験のある方、実務未経験だけど意欲のある方、 ぜひお声がけください!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}