Abstract:
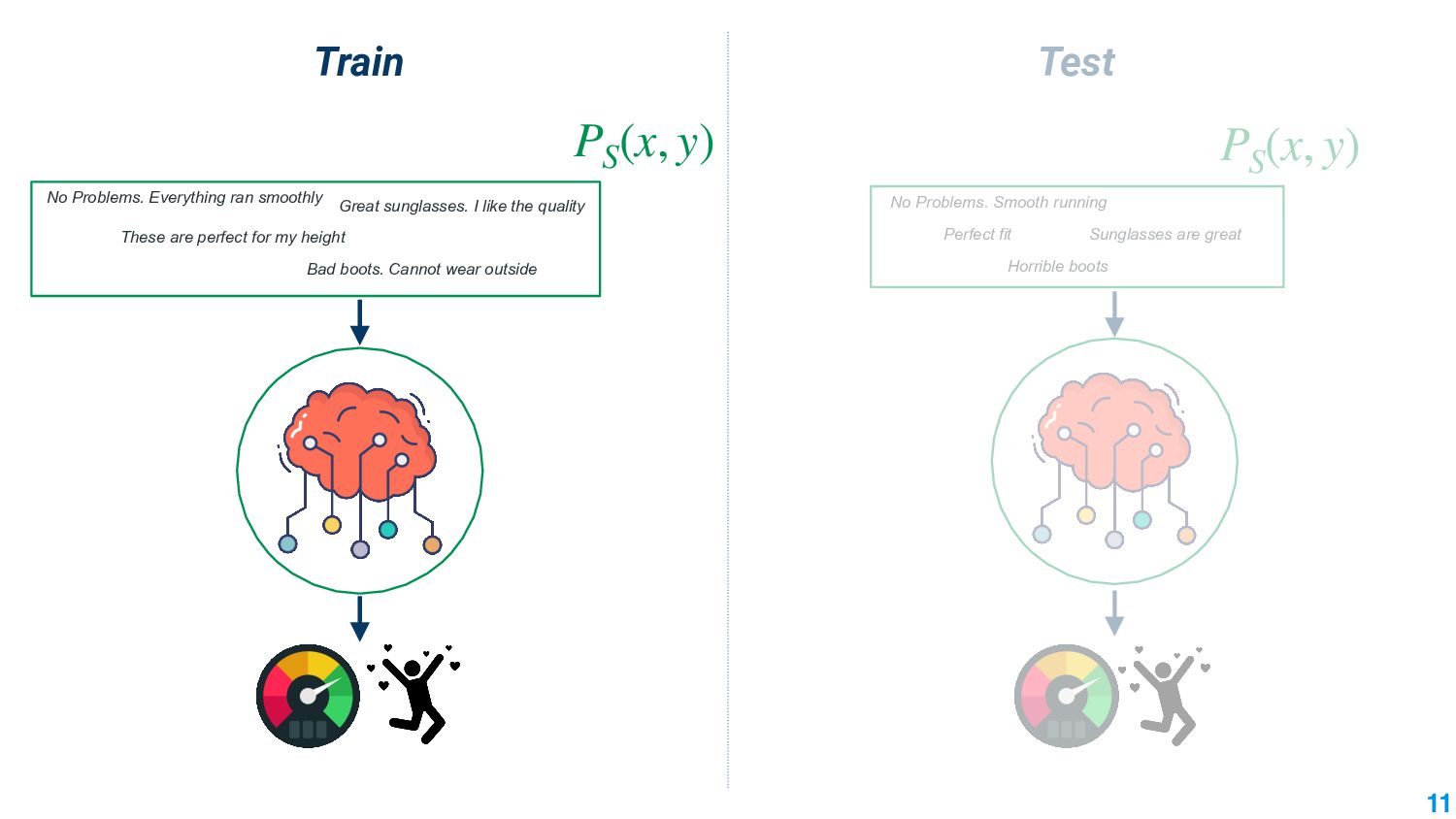
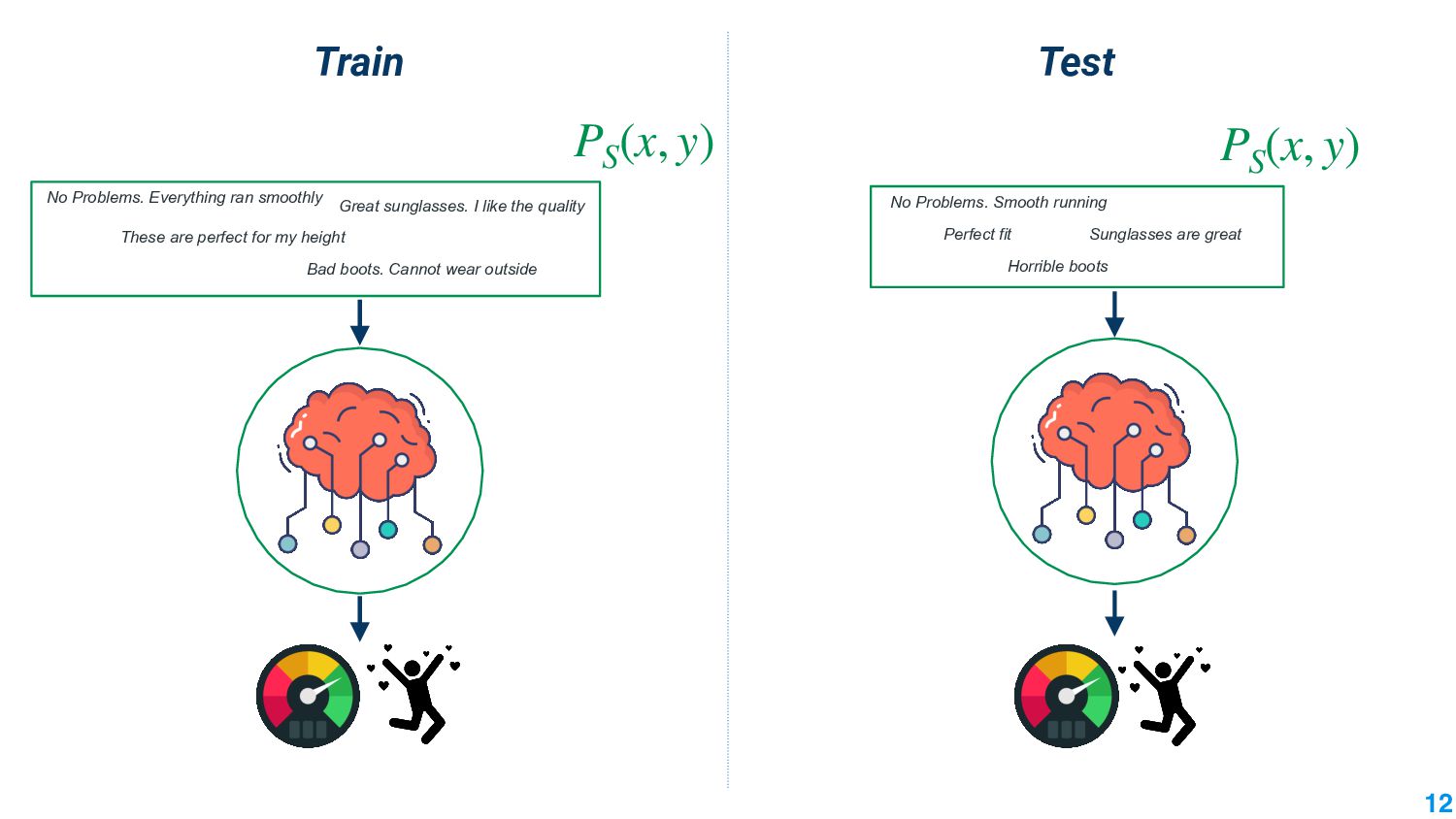
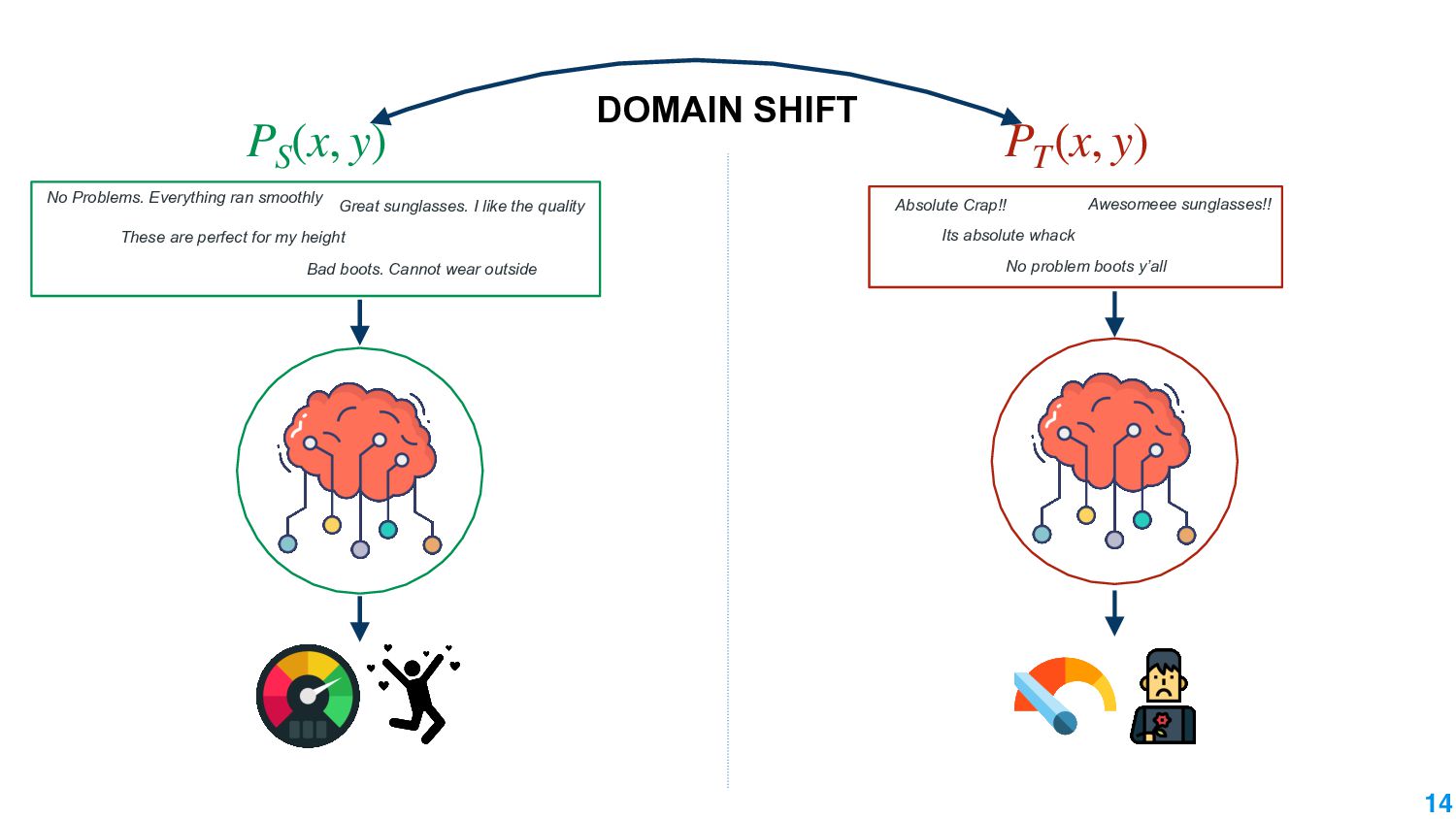
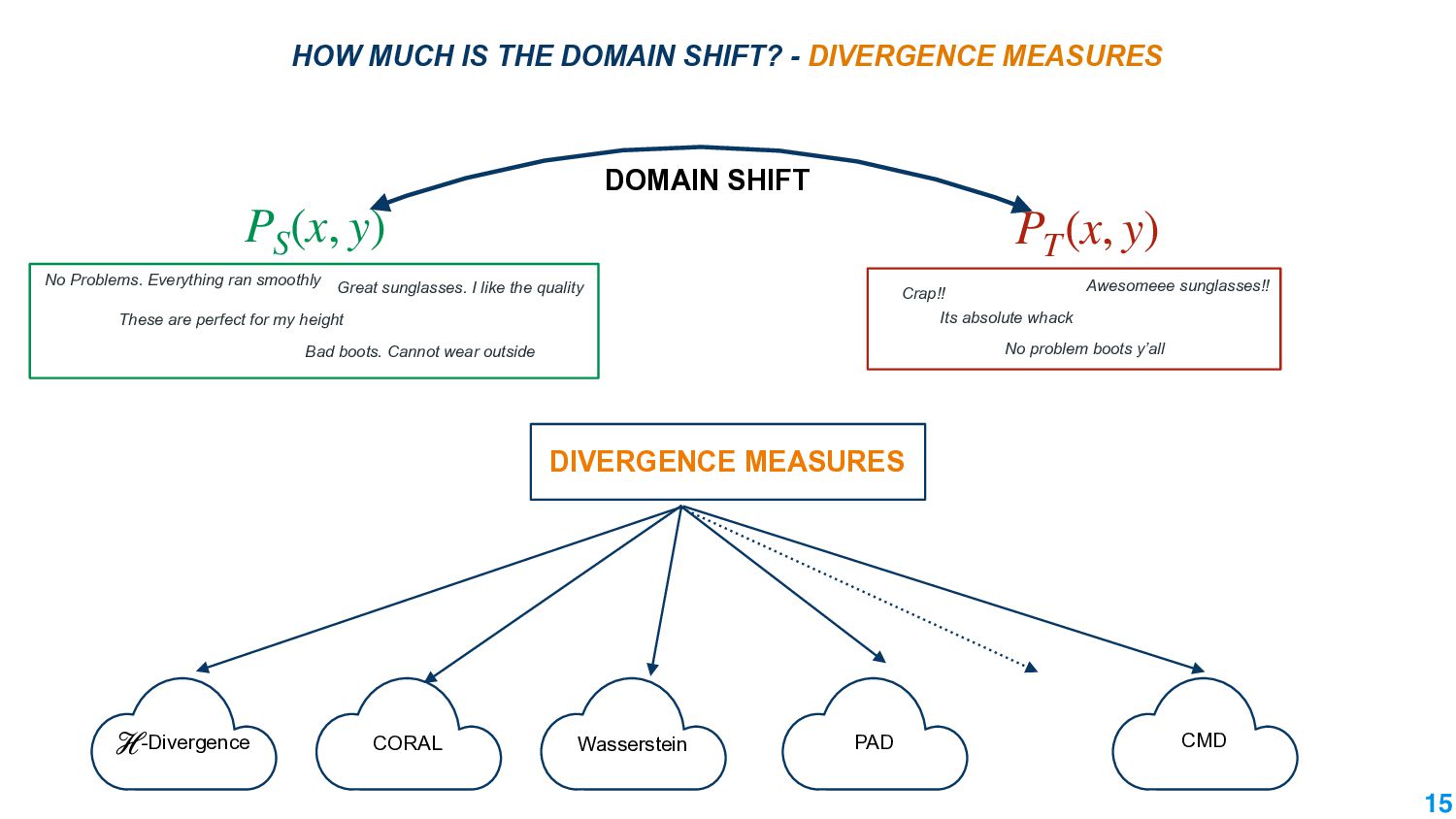
Machine learning models that work under different conditions are important for their deployment. The absence of robustness to varying conditions has adverse effects in the real world: increasing cases of autonomous cars crashing, making adverse legal decisions against minorities, working effectively only for only major languages in the world. The lack of robustness arises because machine learning models trained under certain input distributions are not guaranteed to work under a different distribution. An important aspect of making them work under different distributions is to measure how different these two distributions are. The mathematical tool of domain divergence helps quantify the difference. Applying divergence measures in novel ways is an important avenue to make machine learning models useful.
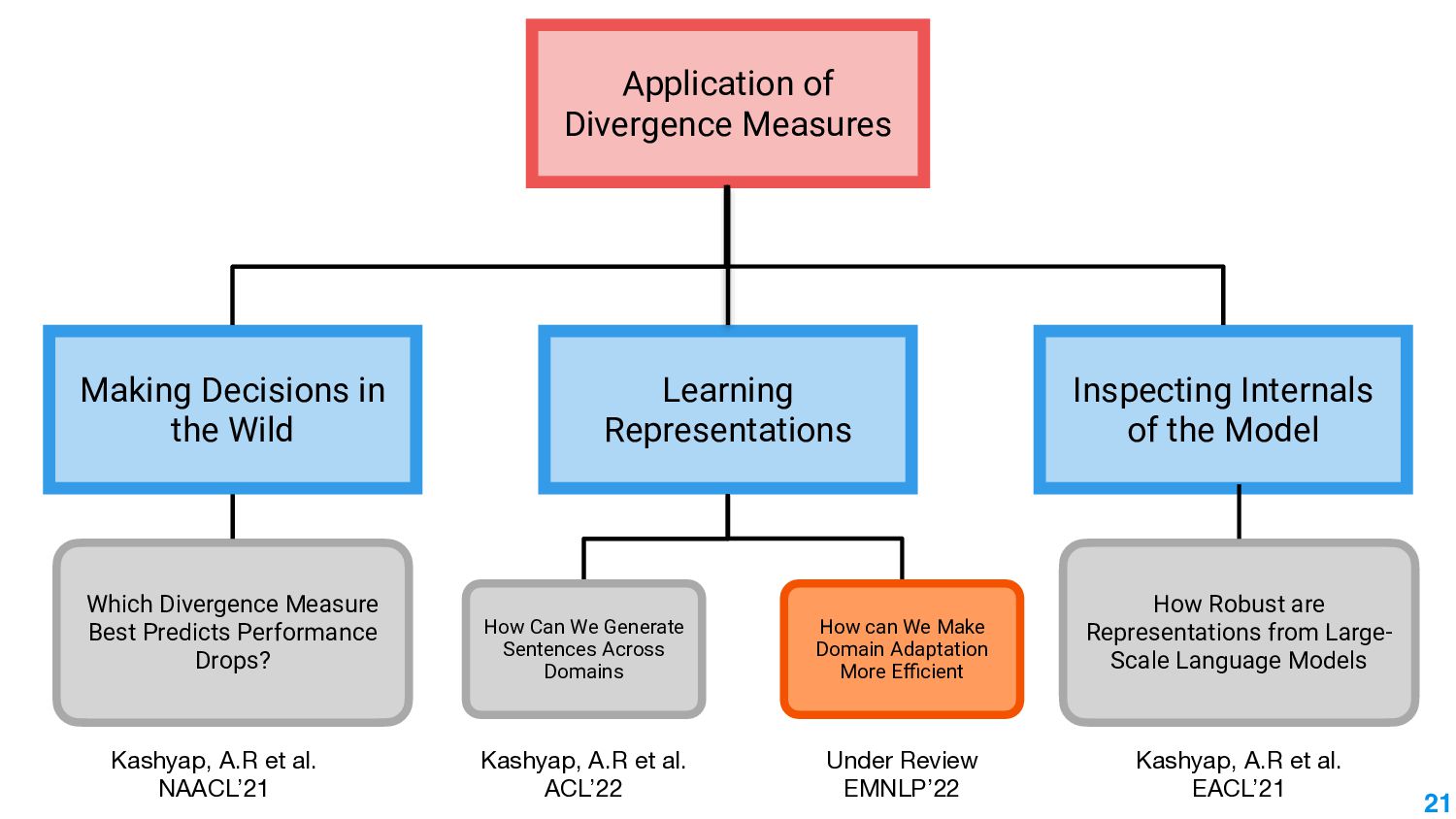
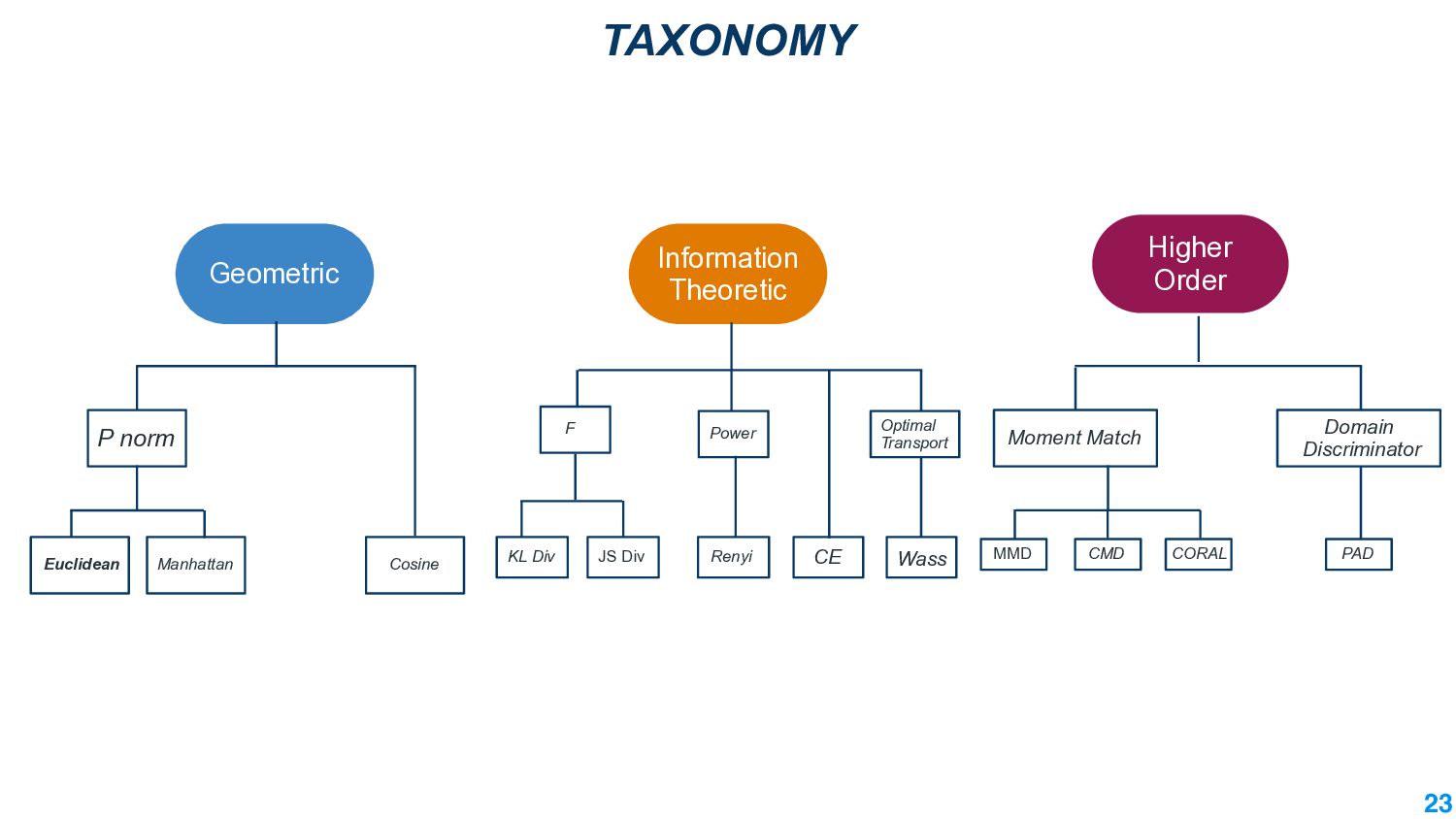
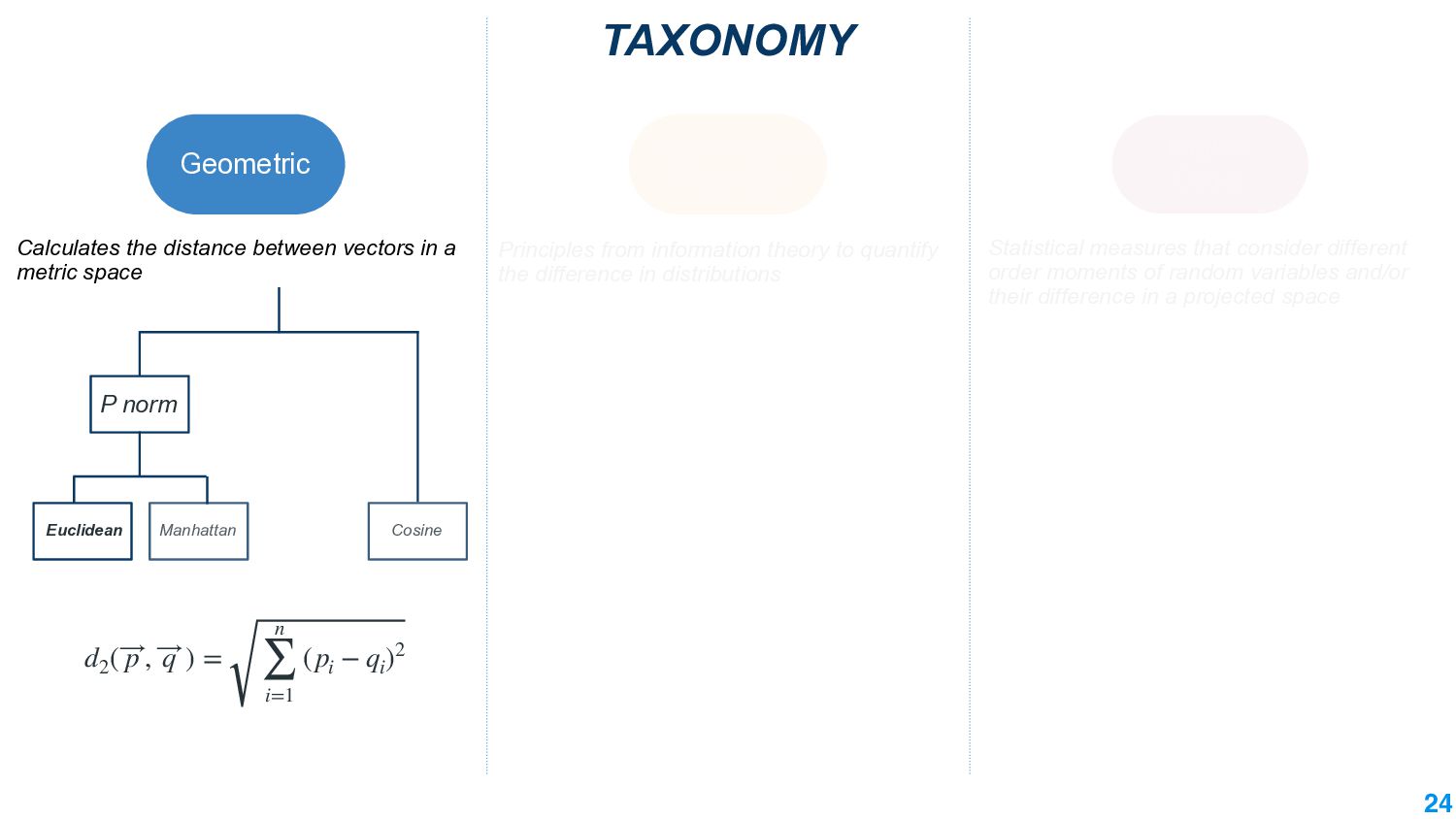
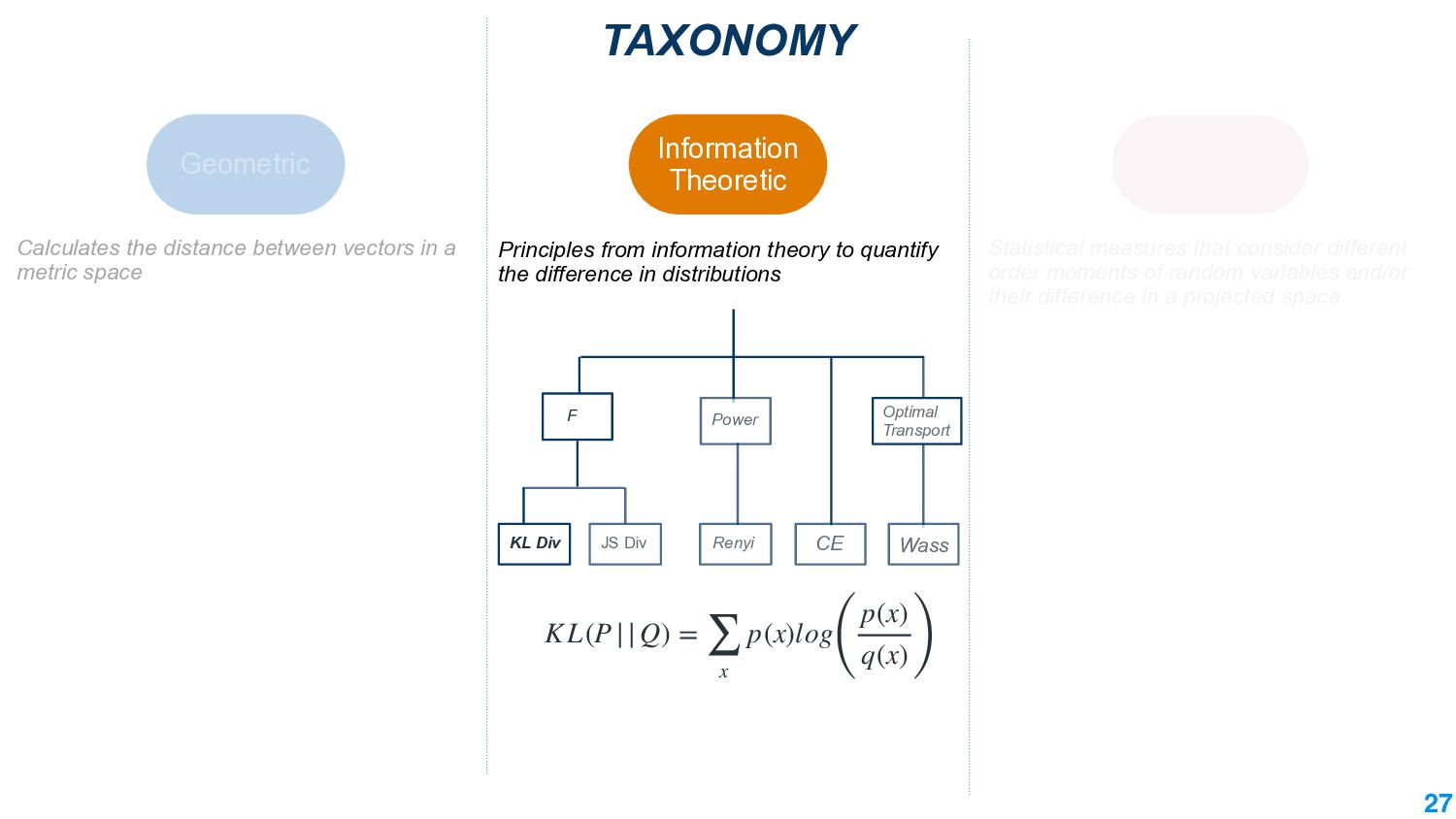
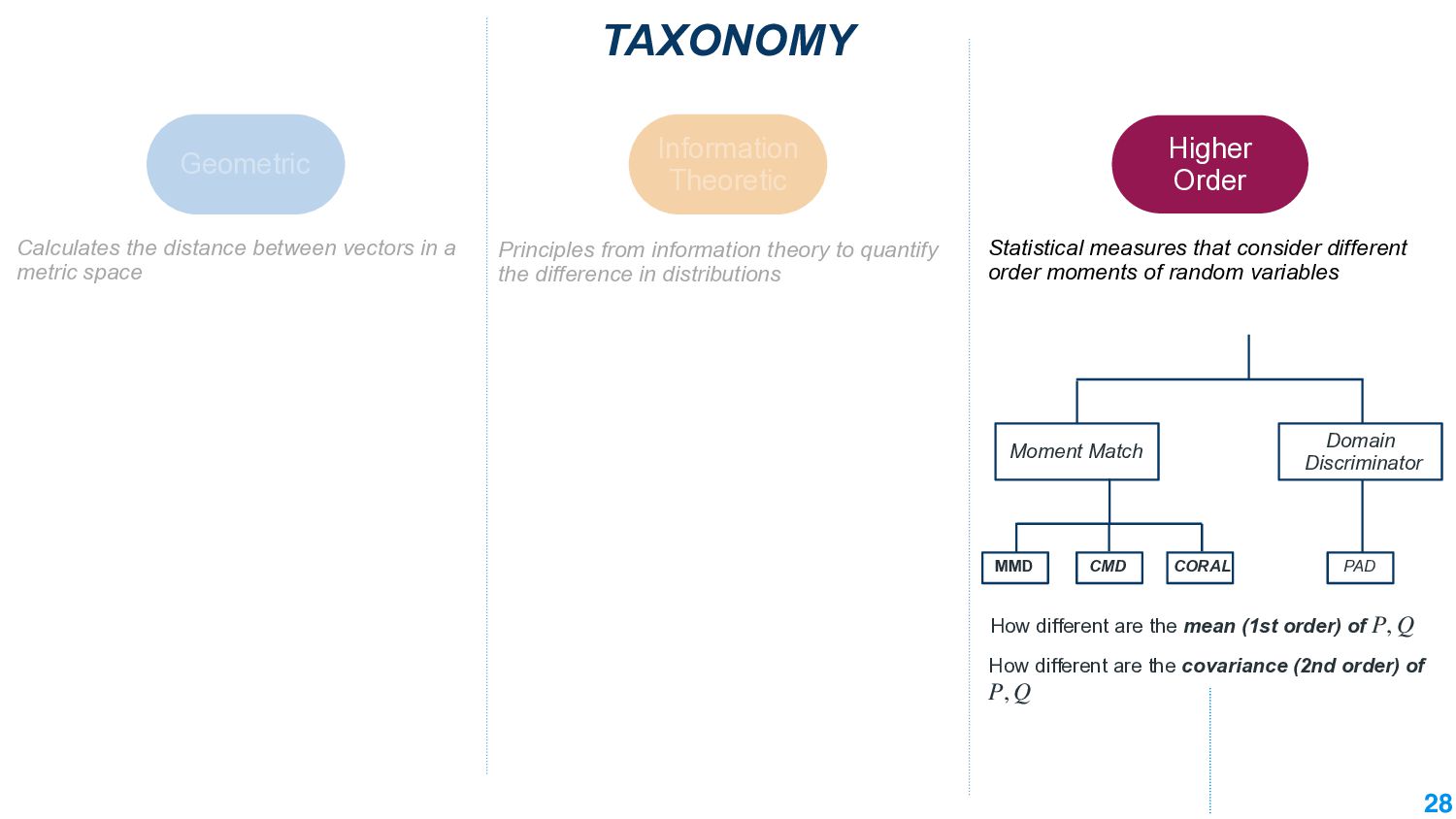
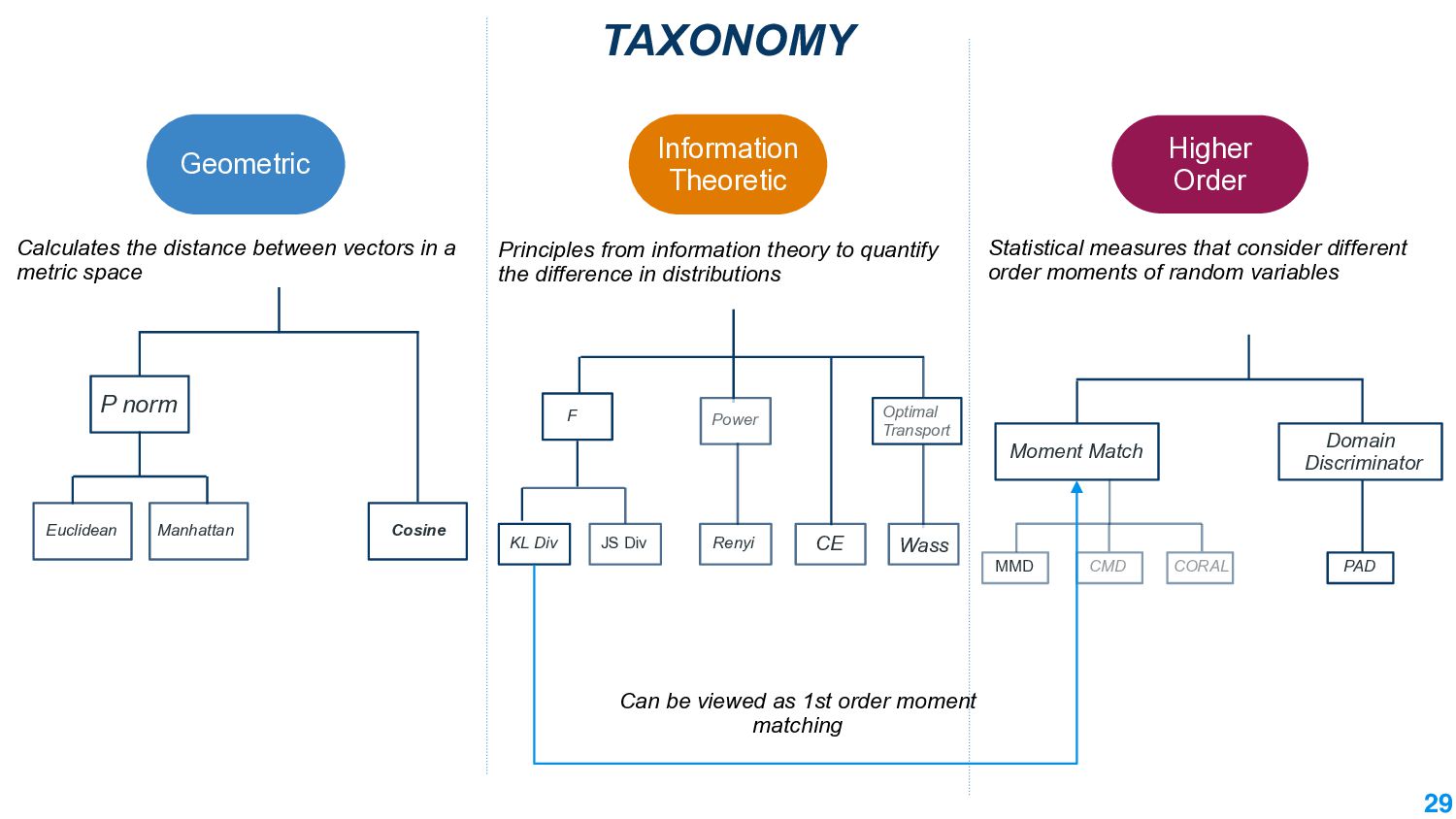
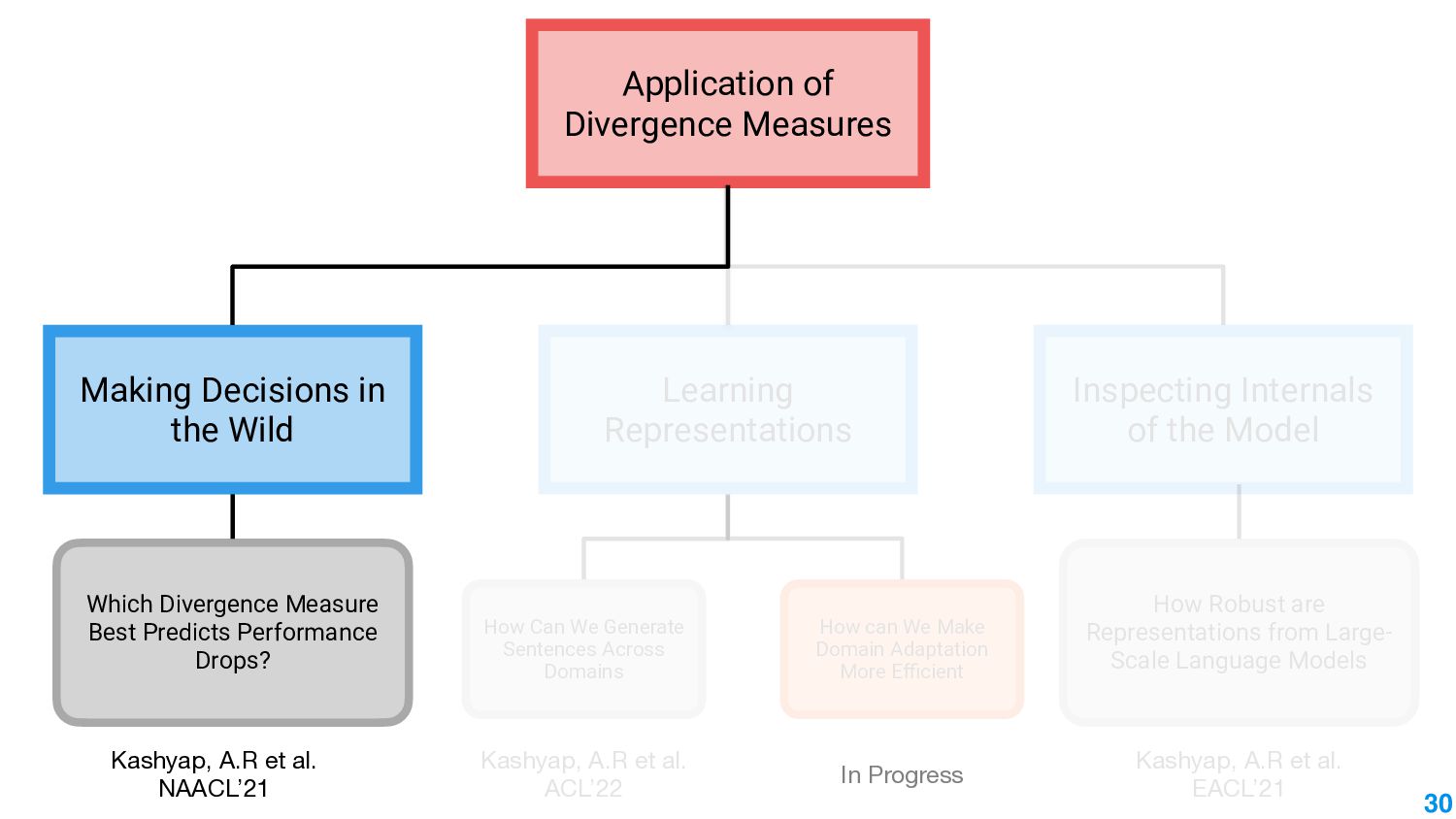
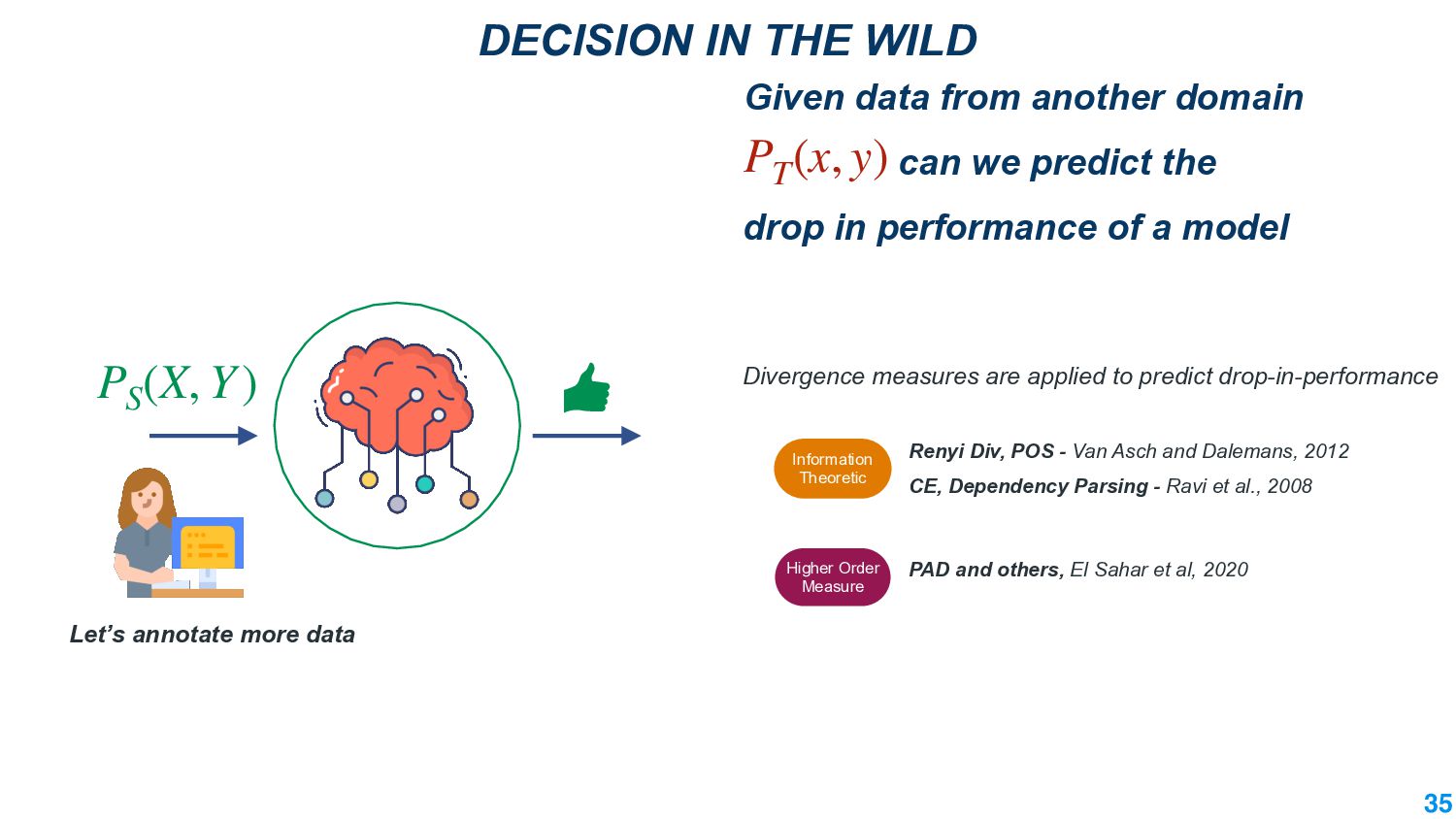
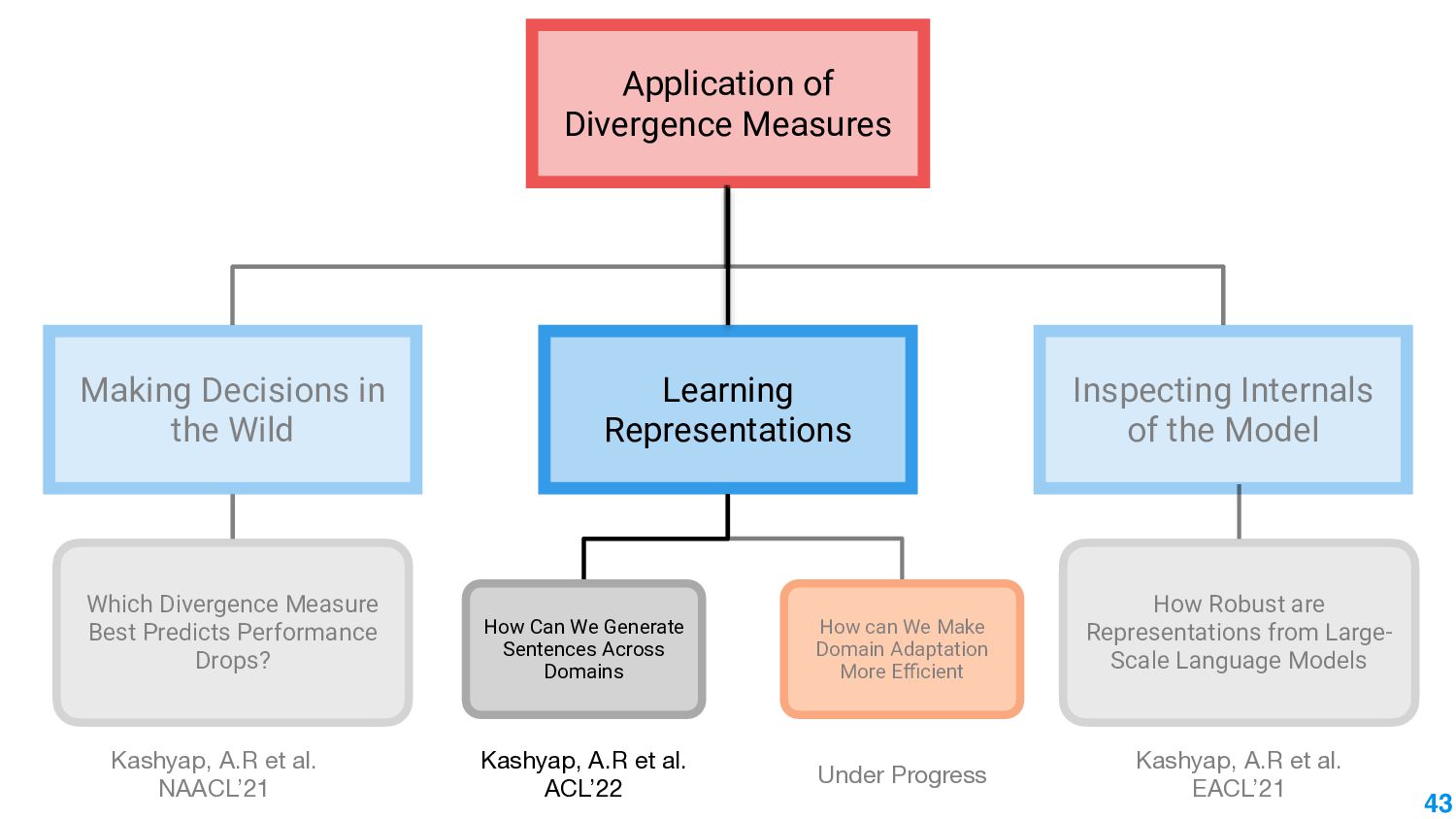
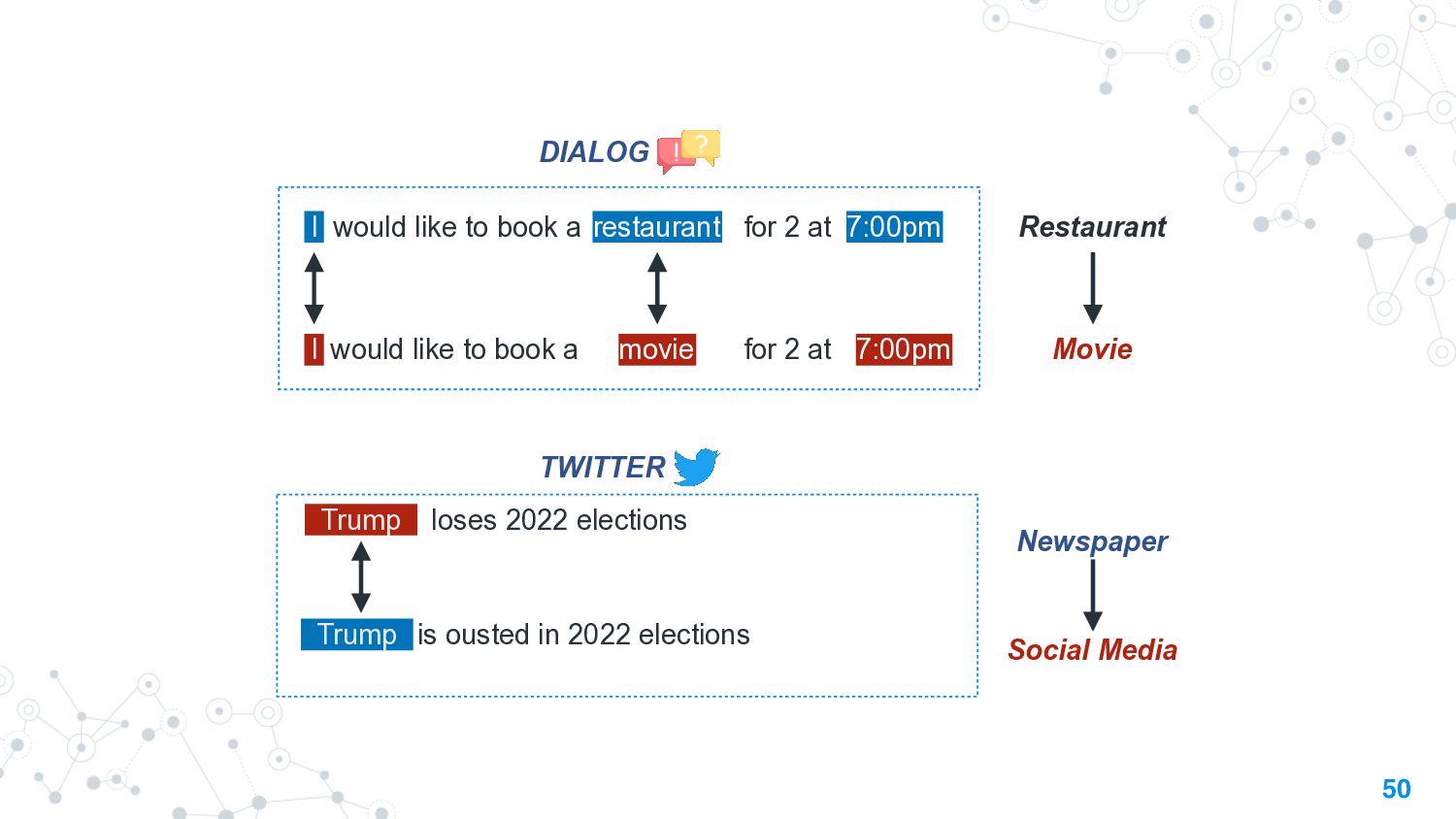
In this talk, we take the journey to explore the different applications of divergence measures, with a special interest in adapting NLP models to new inputs that arise naturally. We first identify the different divergence measures that are used within Natural Language Processing (NLP) and provide a taxonomy. Further, we identify applications of divergences and make contributions along them: 1) \textit{Making Decisions in the Wild} -- help practitioners predict the performance drop of a model under a new distribution 2) \textit{Learning Representations} -- aligning source and target domain representations for novel applications 3) \textit{Inspecting the Internals of a model} - understand the inherent robustness of models under new distributions.
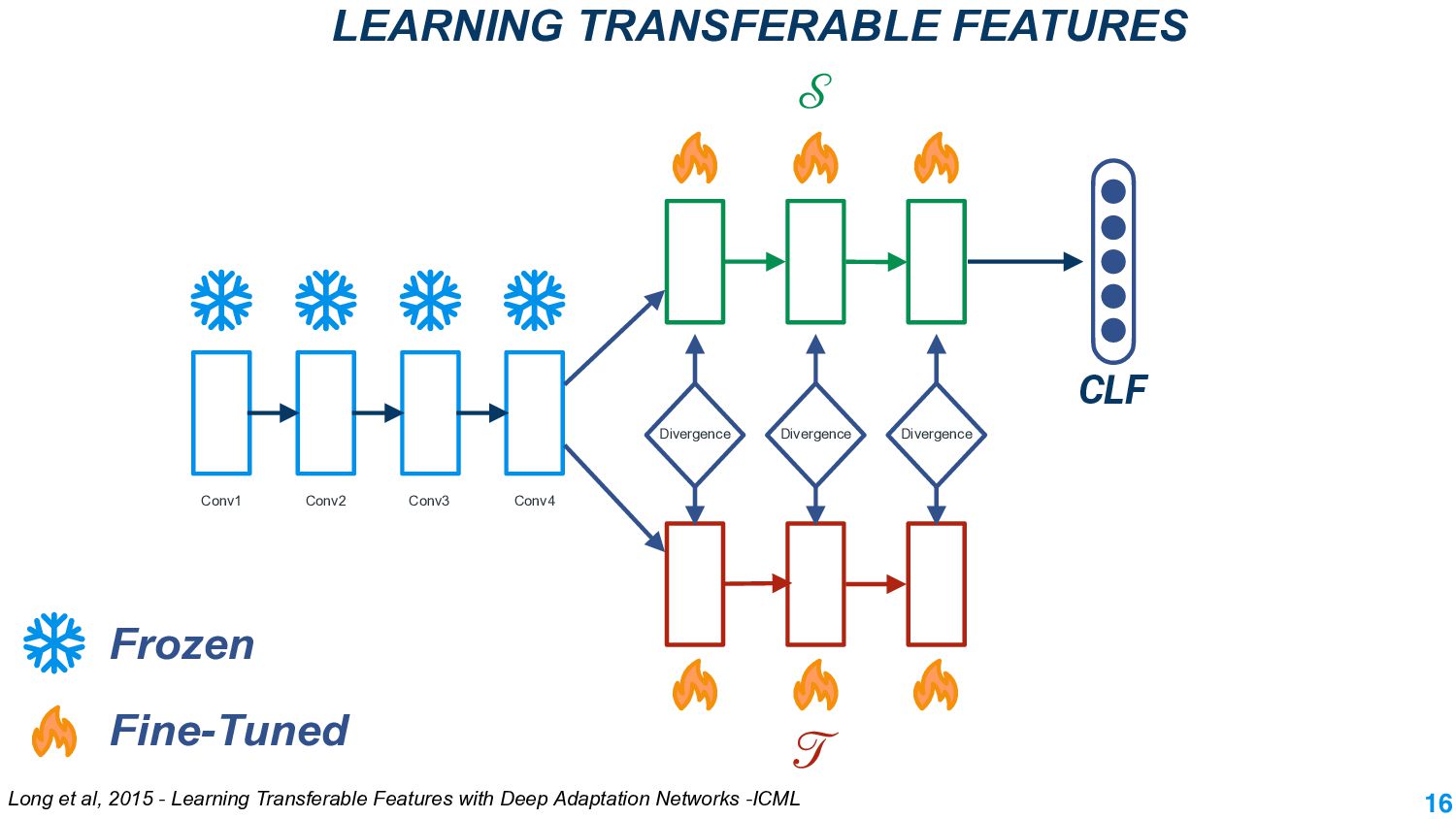
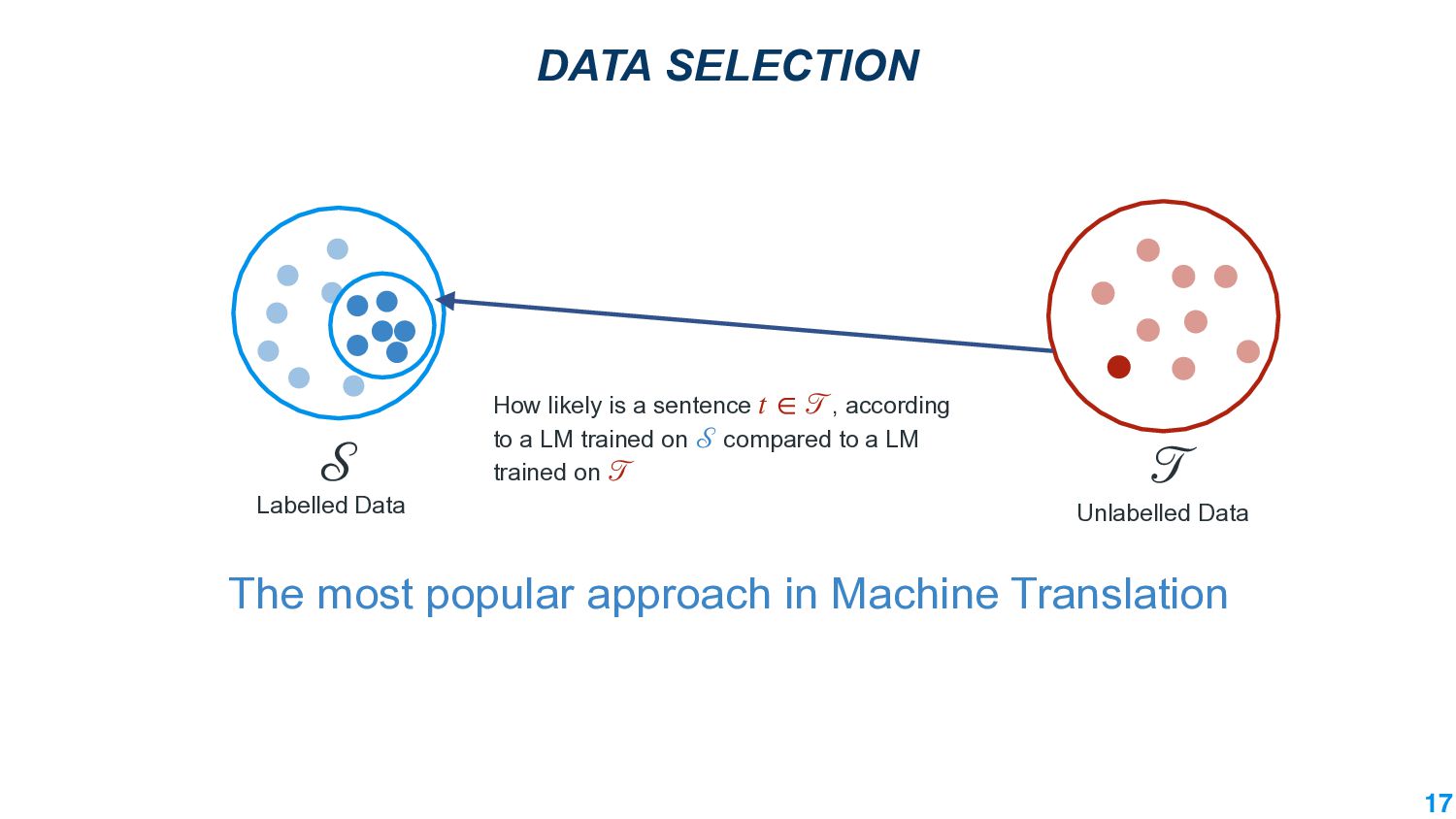
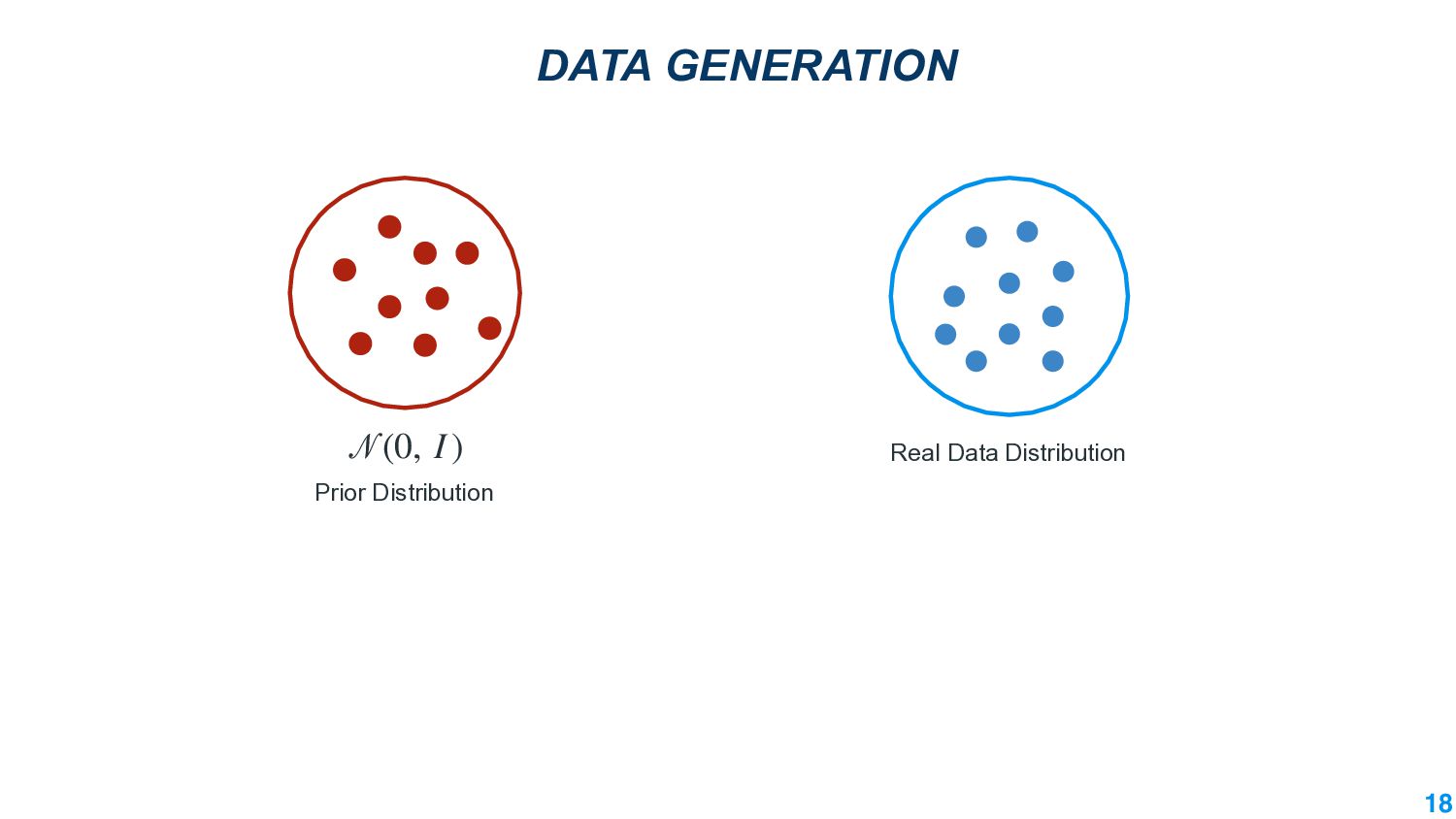
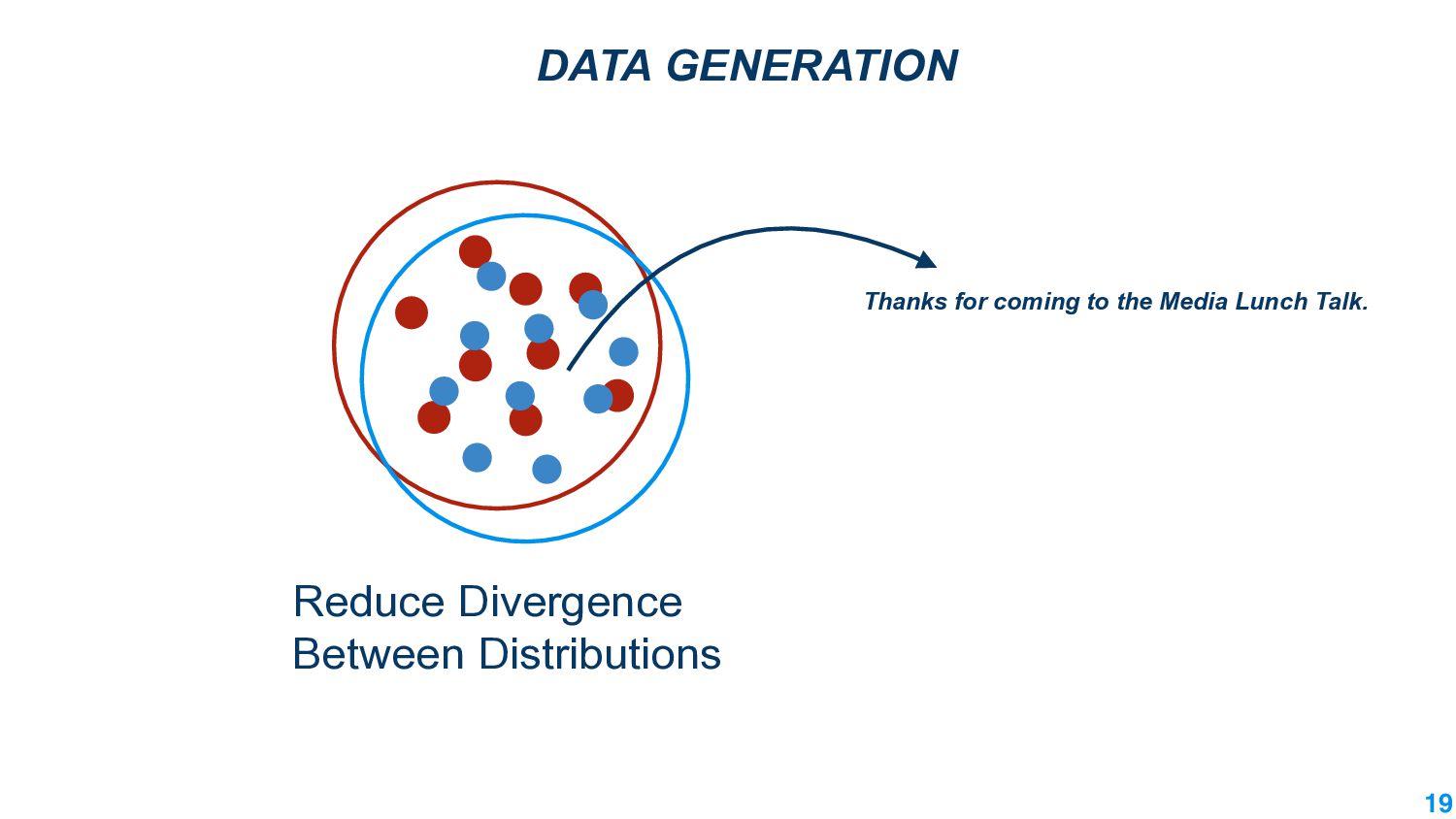
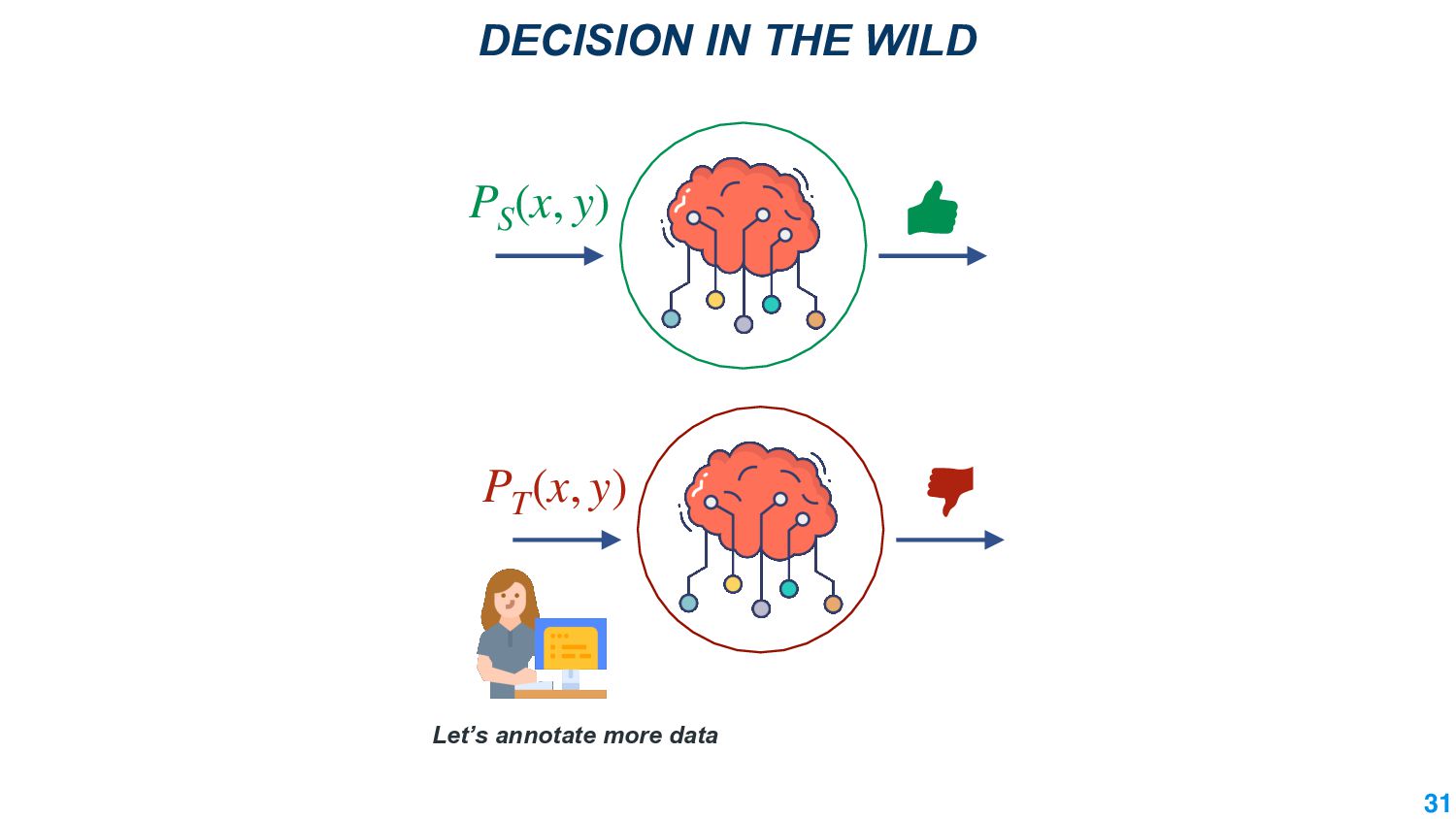
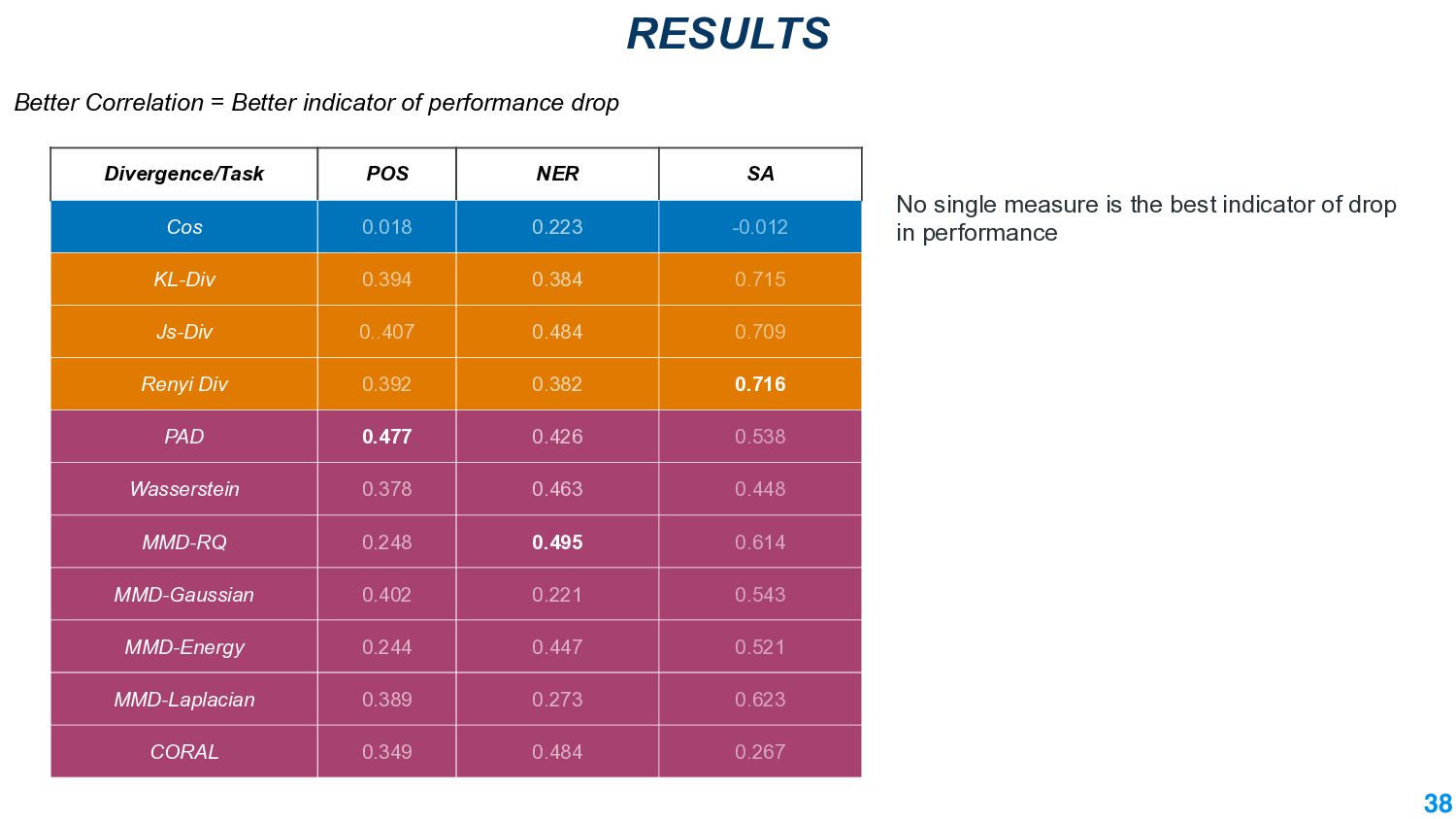
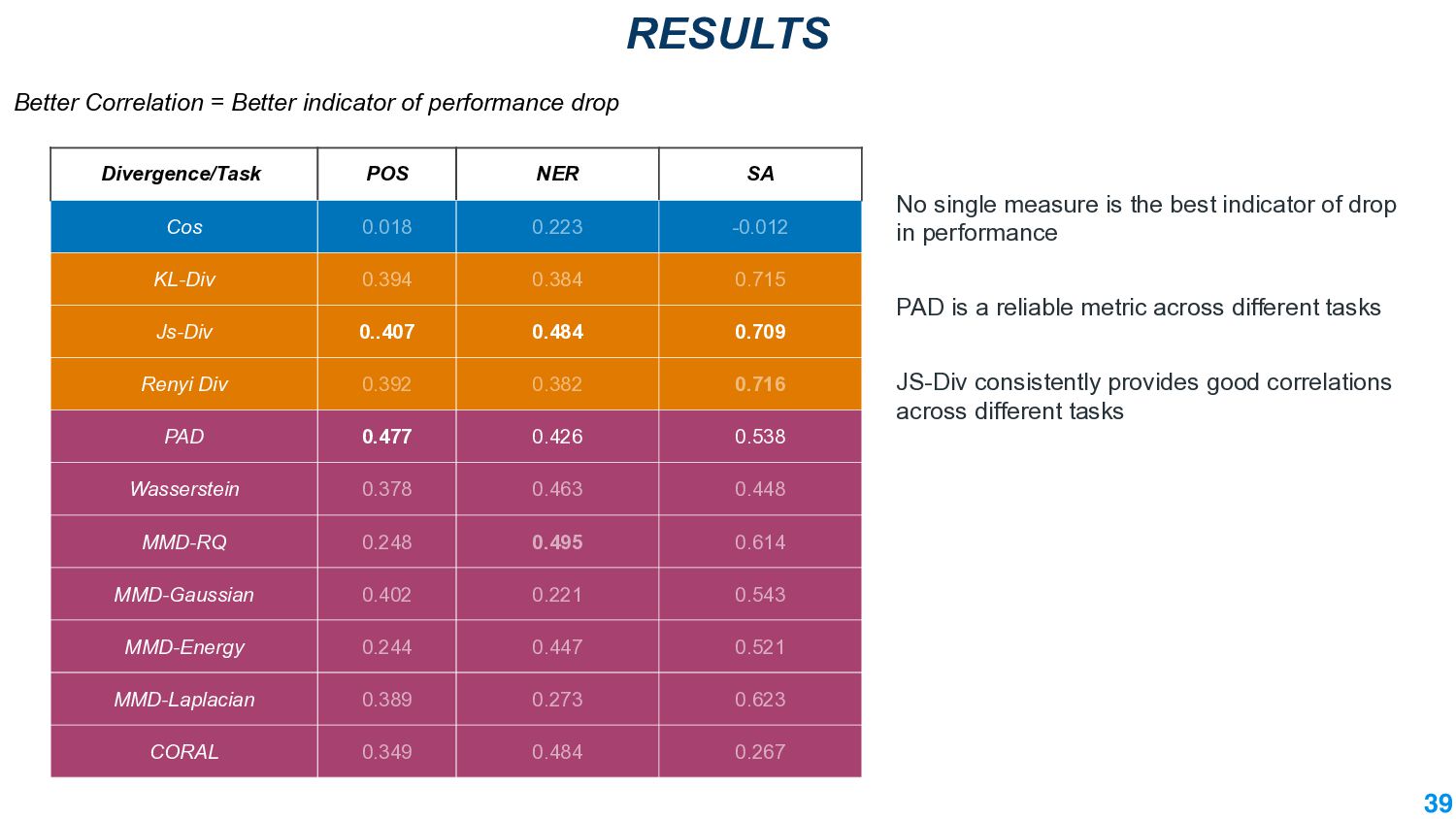
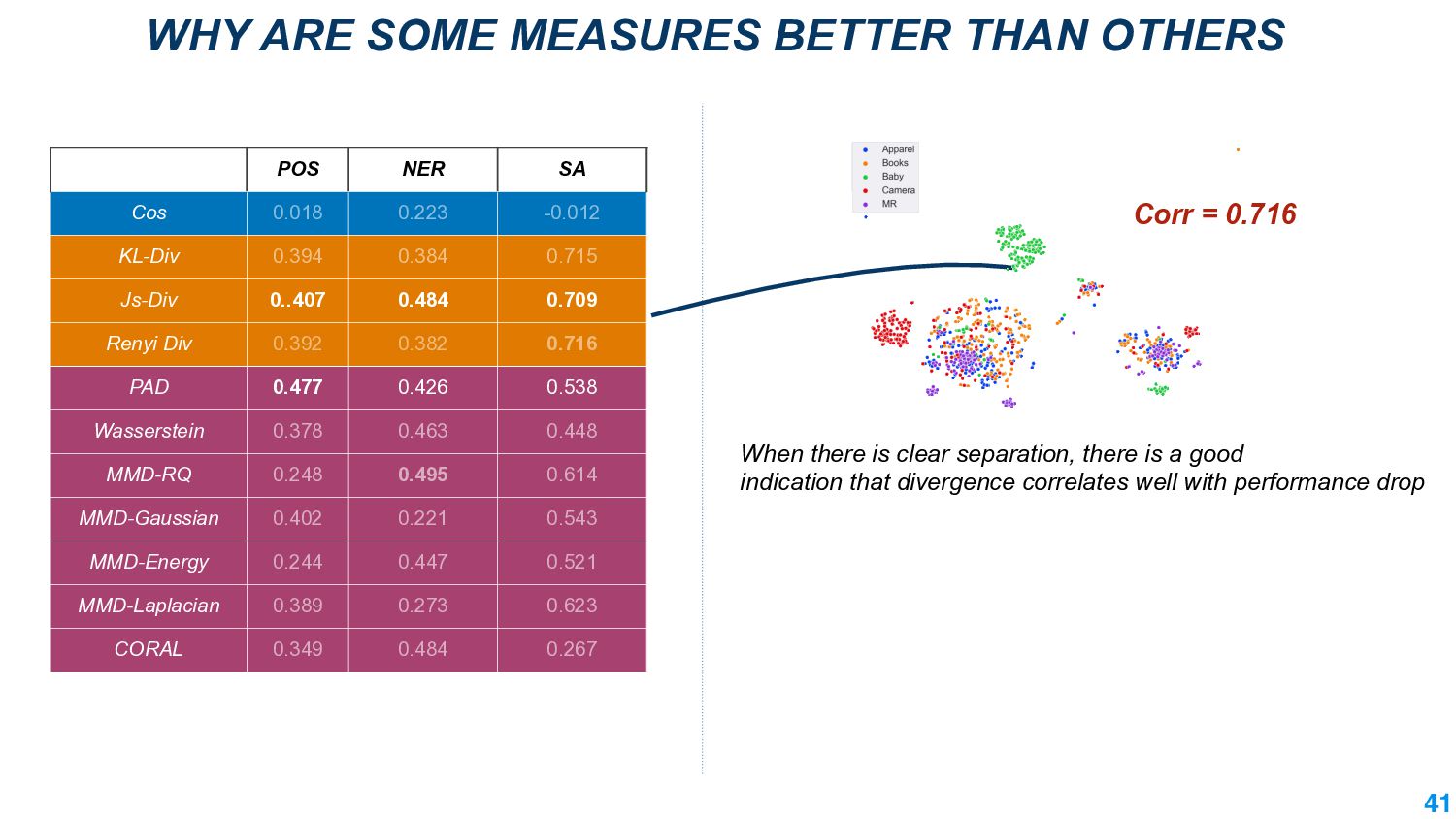
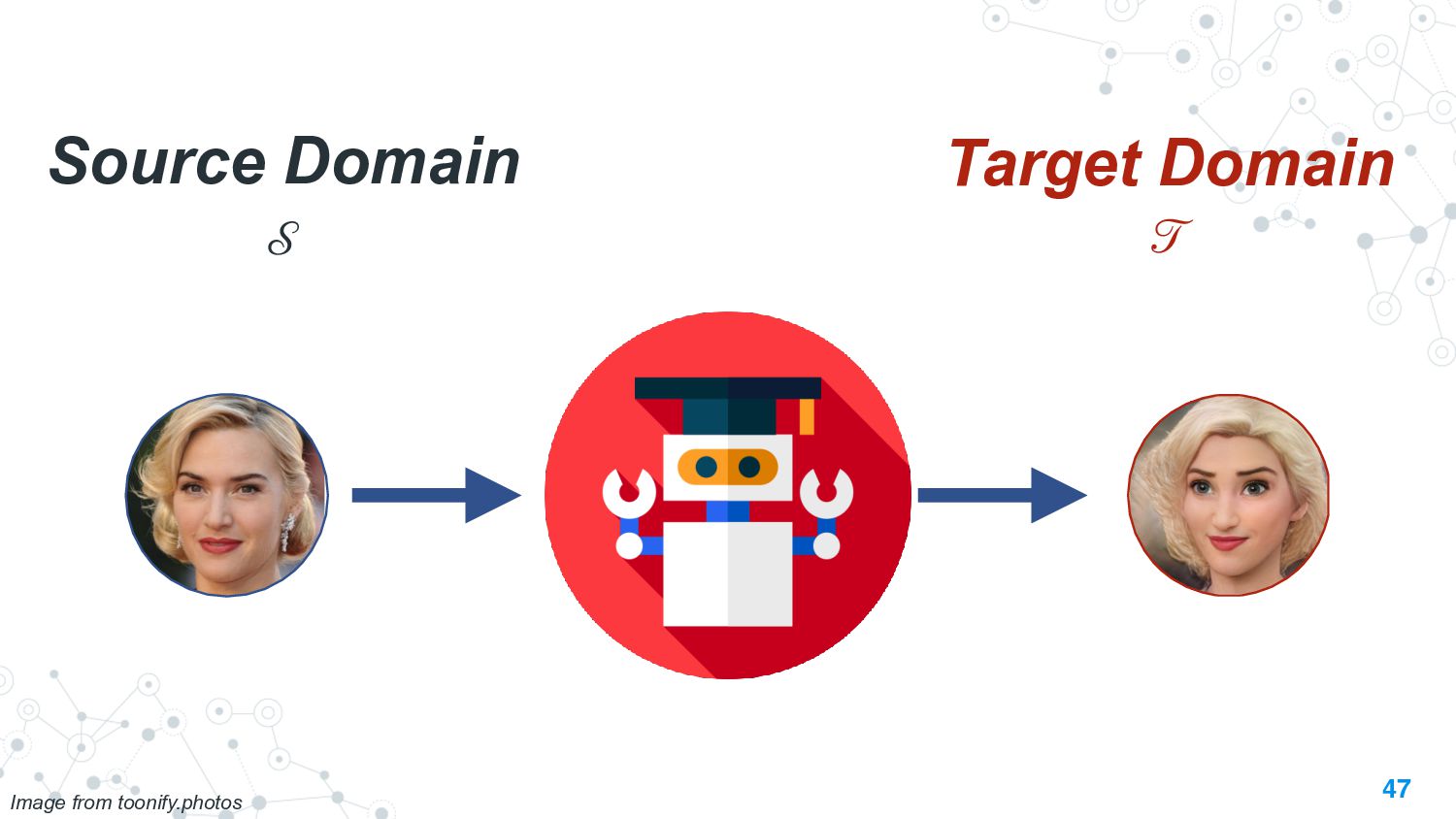
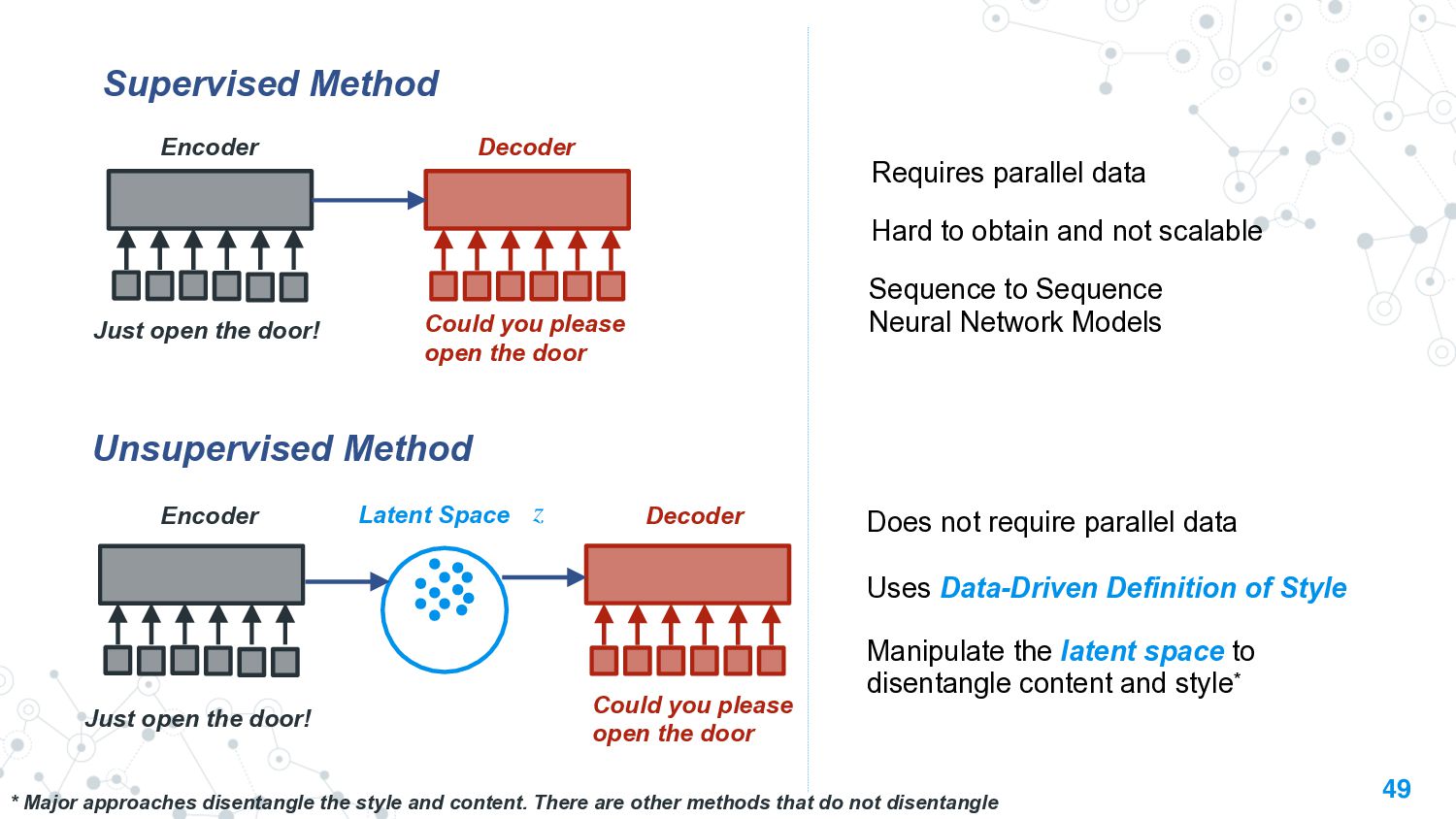
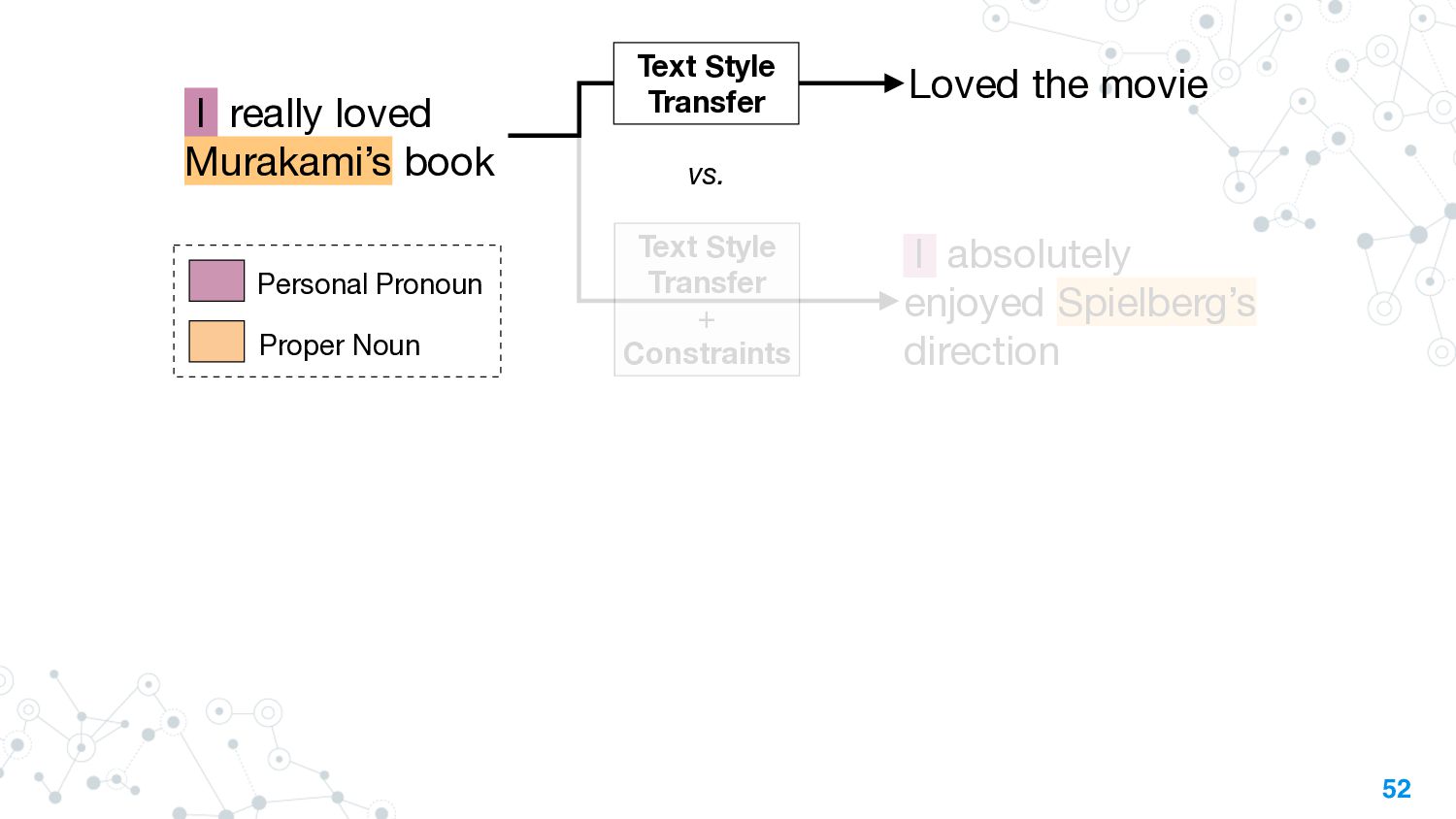
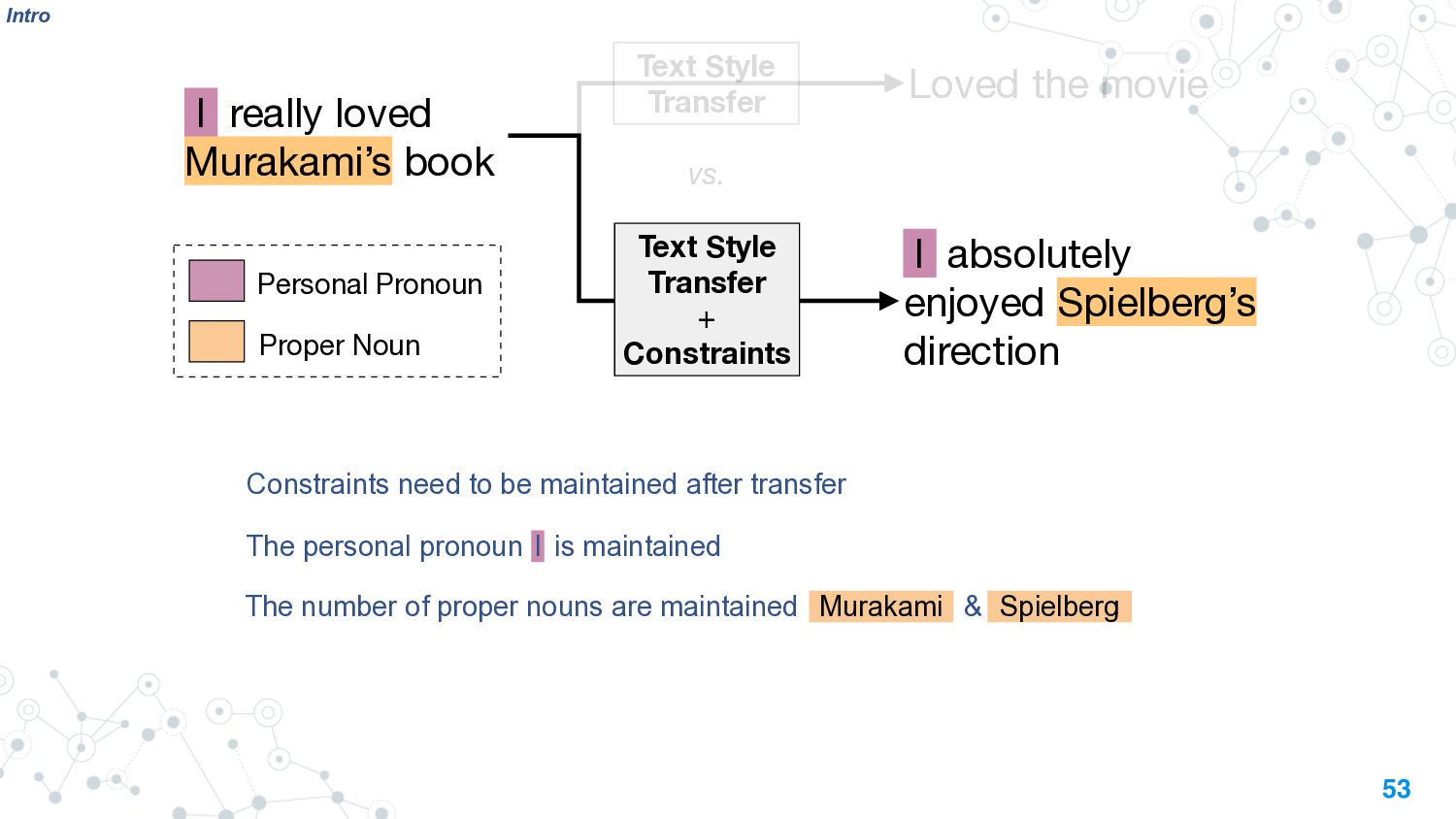
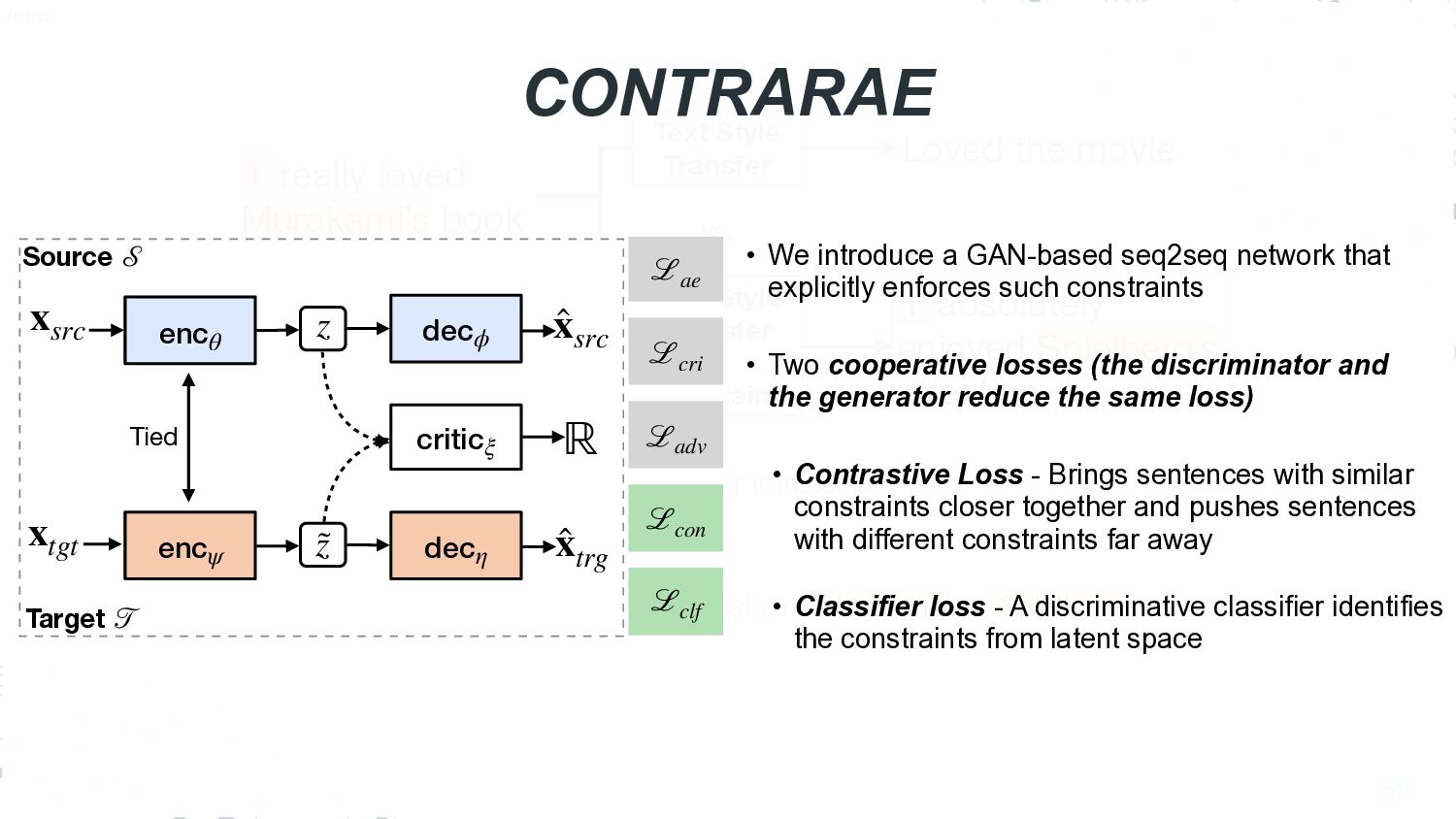
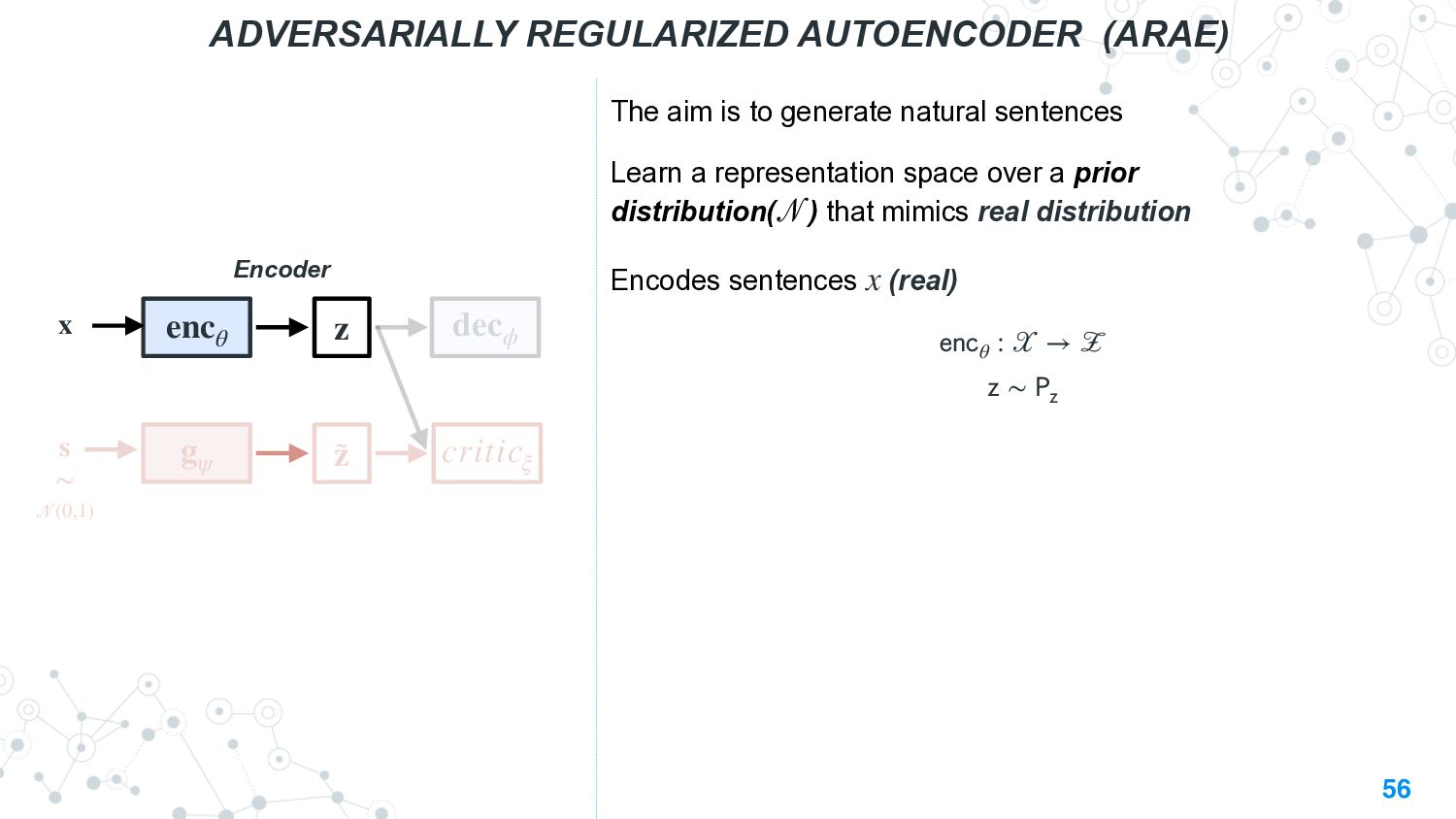
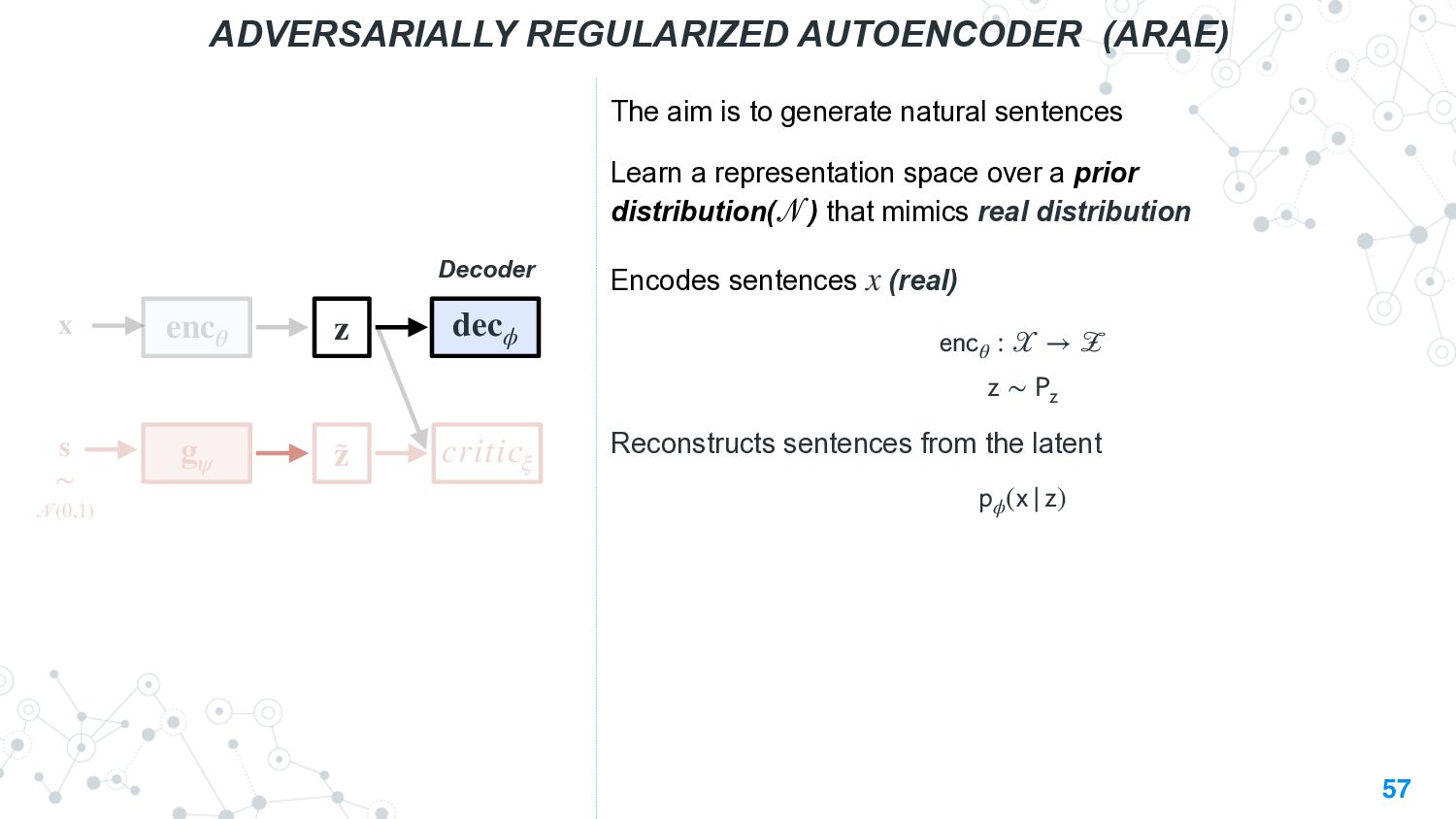
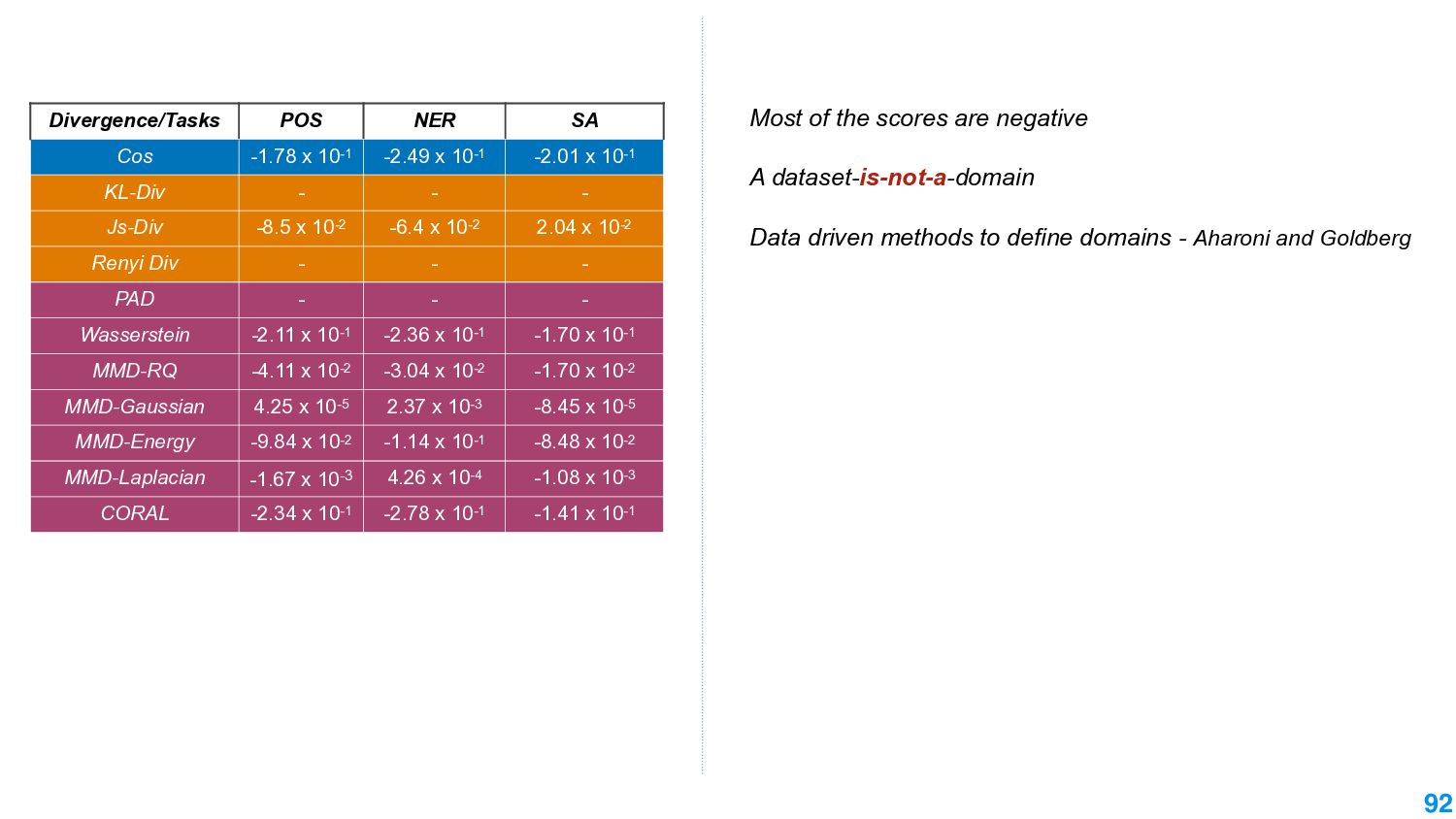
This talk will present a brief overview of two of these applications. For the first application, we performed a large-scale correlational study of different divergence measures with a decrease in model performance. We compare whether divergence measures based on traditional word-level distributions are more reliable than those based on contextual word representations from pretrained language models. Based on our study, we make appropriate recommendations for divergence measures that best predict performance drop. In the second application, we employ machine learning models that reduce divergence between two domains to enable us to generate sentences between domains. Further, we make enhancements to the model to produce sentences that satisfy certain linguistic constraints with downstream applications to domain adaptation in Natural Language Processing.
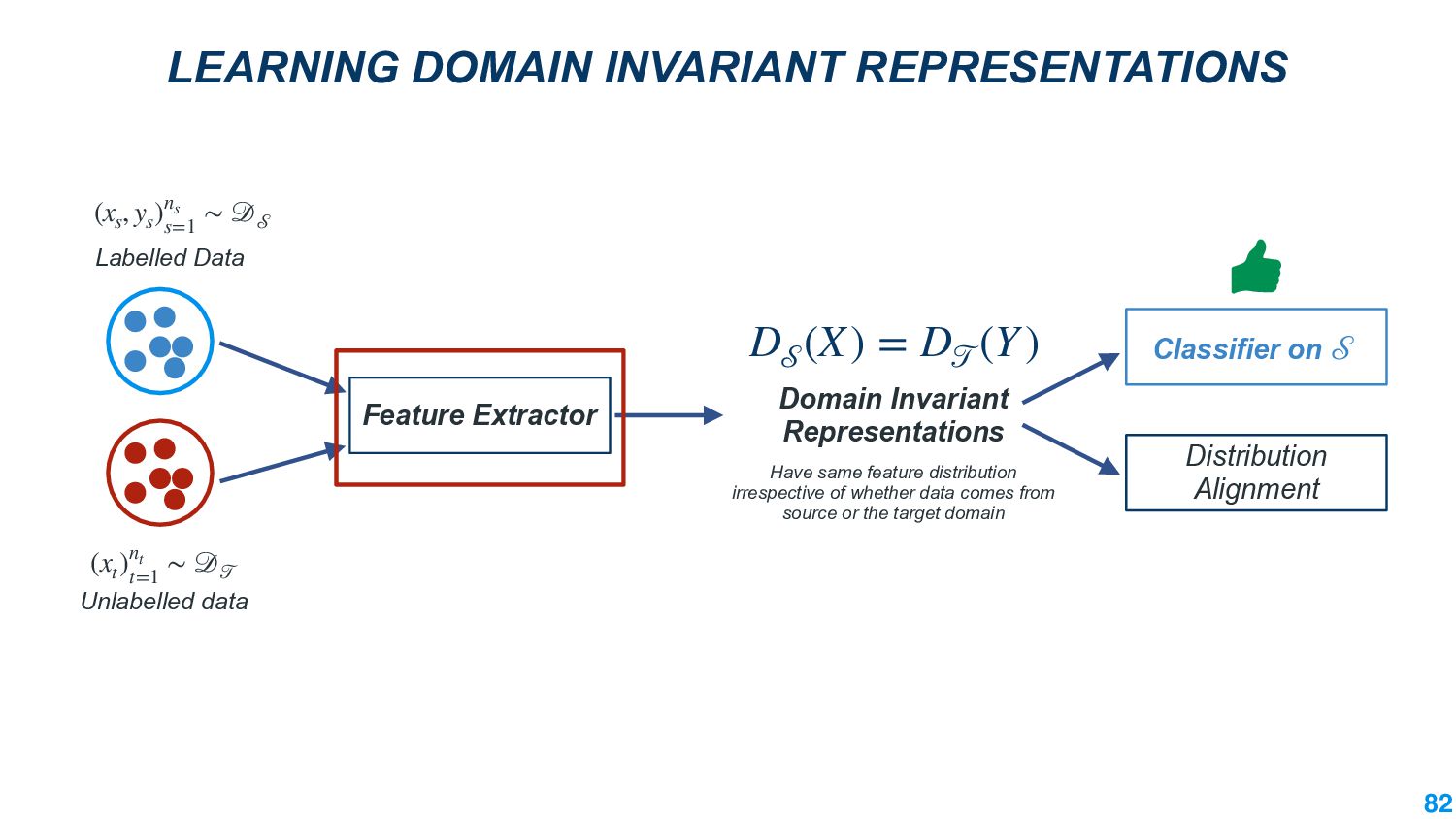
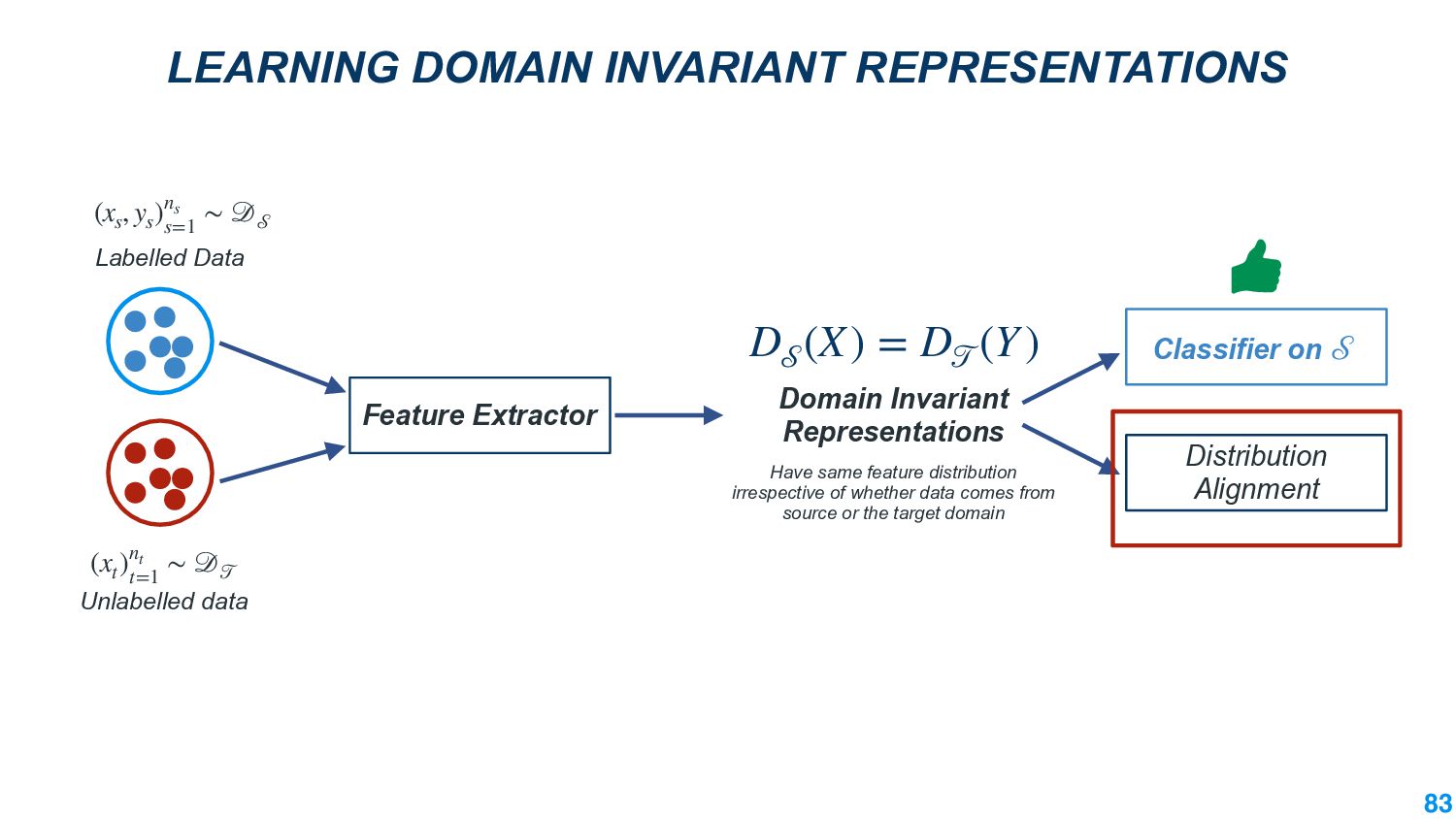
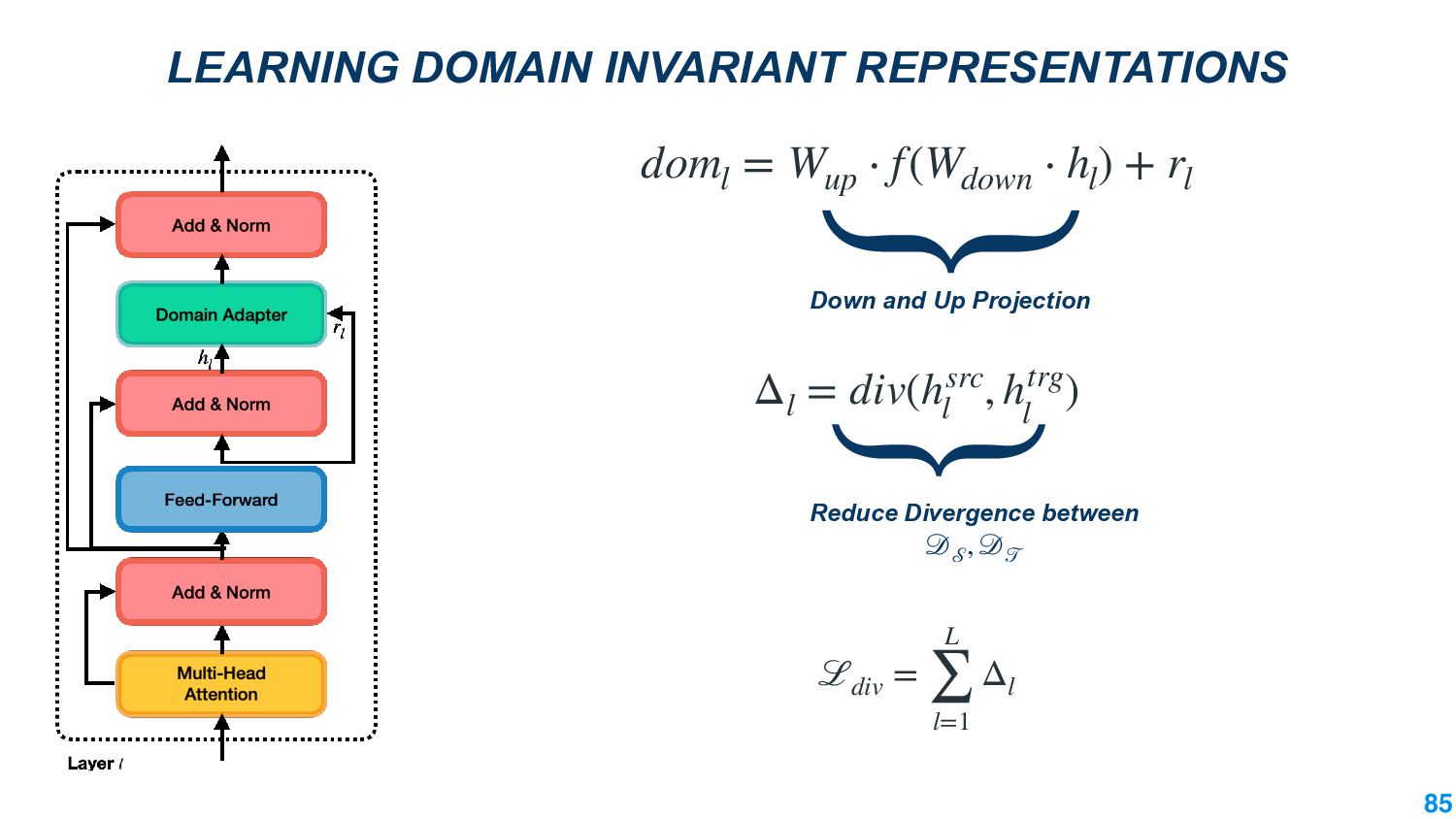
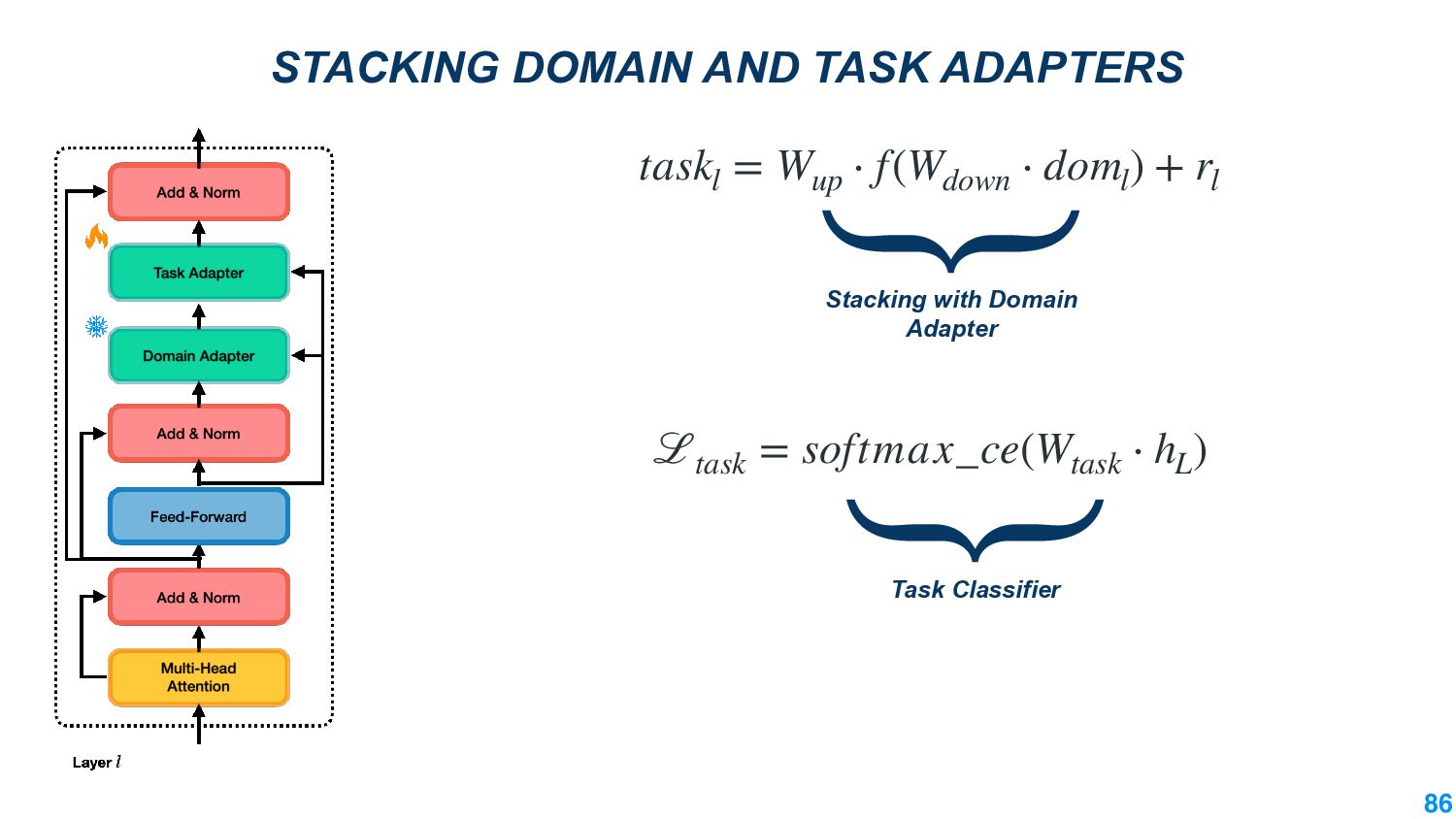
We also present an ongoing work that applies divergence methods in a parameter-efficient manner for domain adaptation in NLP. Our method follows a two-step process of first extracting domain-invariant representation by reducing divergence measures between two domains and then reducing task-specific loss on labeled data in the source domain and achieve this using adapters. We provide some future directions for domain adaptation in NLP.
Bio:
Abhinav Ramesh Kashyap is a fourth-year Ph.D. student advised by Prof Min-Yen Kan. His research is on Natural Language Processing. Specifically, he focuses on making NLP models robust under different domains, also called Domain Adaptation. He is also interested in Scholarly Document Processing which helps extract information from scholarly articles.
Seminar page: https://wing-nus.github.io/nlp-seminar/speaker-abhinav
YouTube Video recording: https://youtu.be/ycdG5bozFT0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![48 [1]: Di Jin et al, Deep Learning For Text](https://files.speakerdeck.com/presentations/12c0834a3d974c22868ebf03ebdf5c26/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
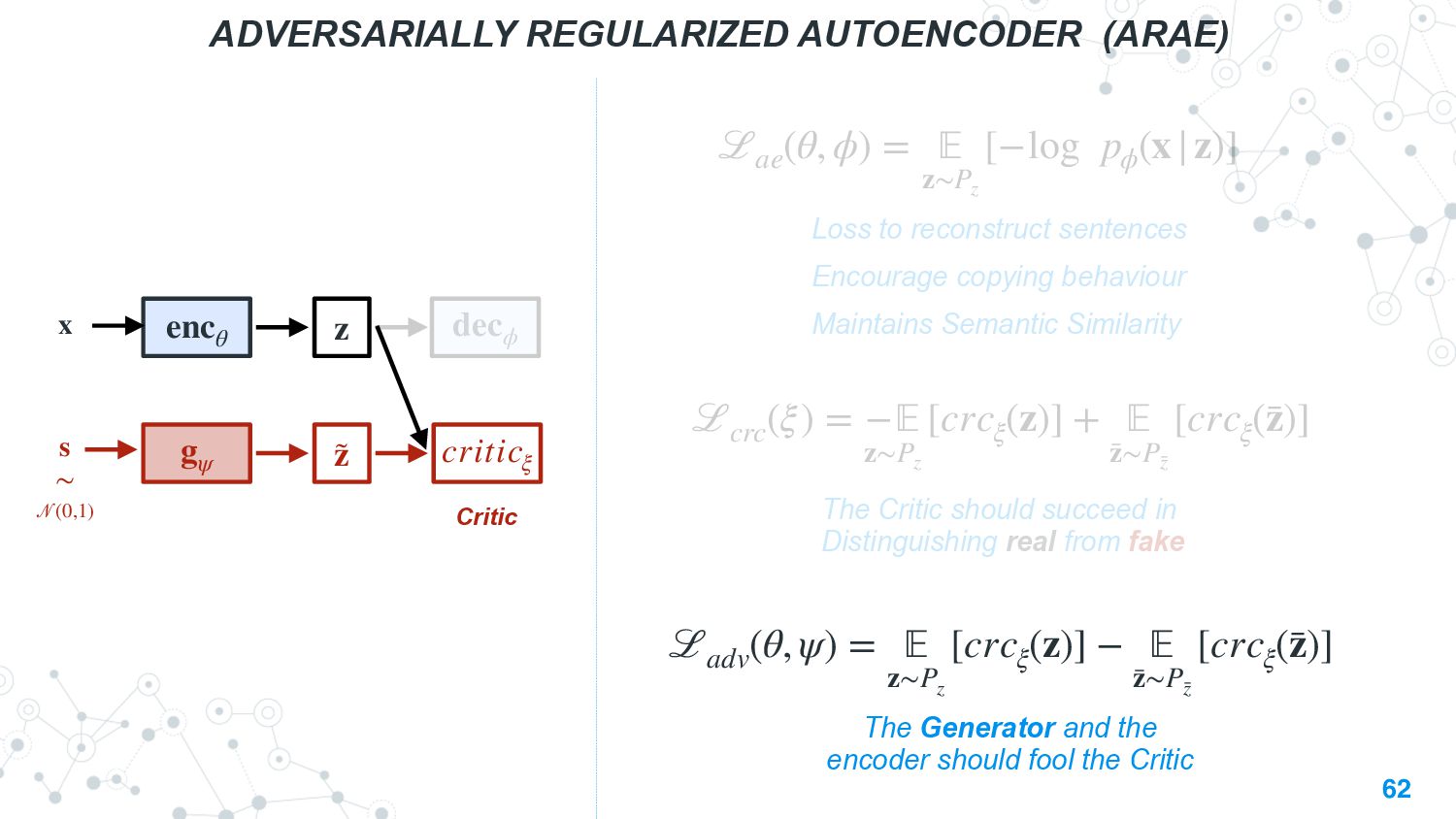{kind=link}
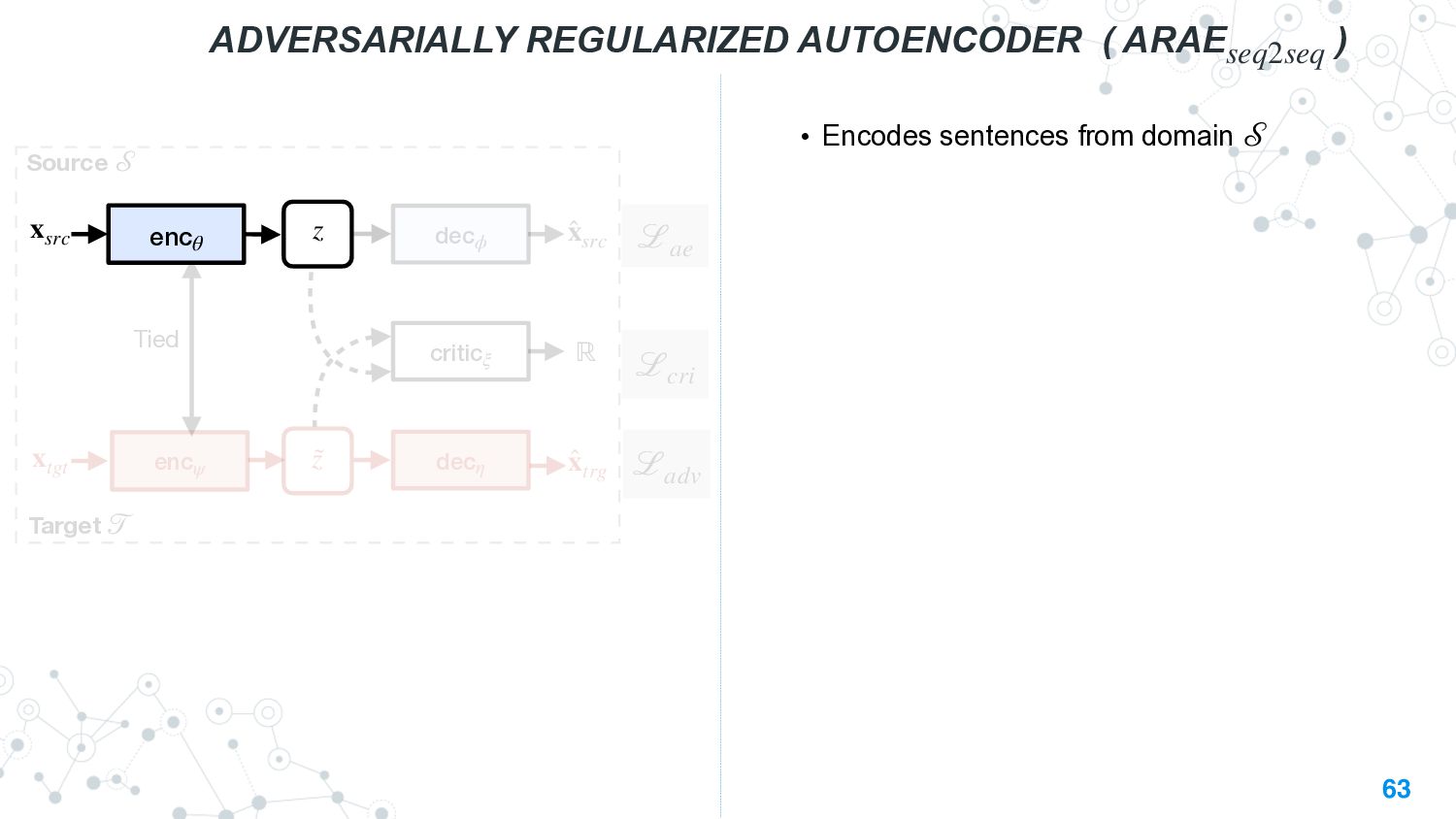{kind=link}
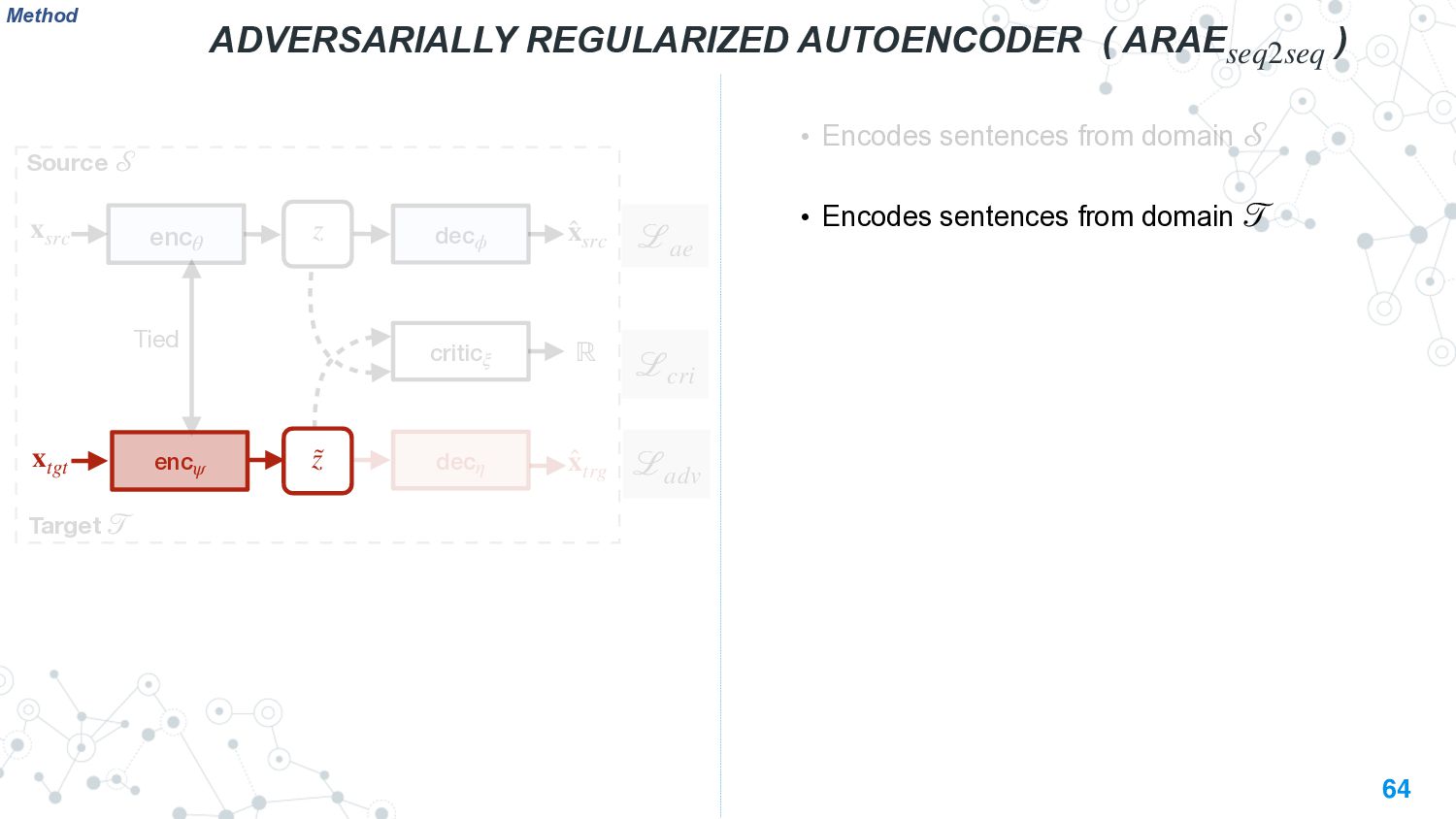{kind=link}
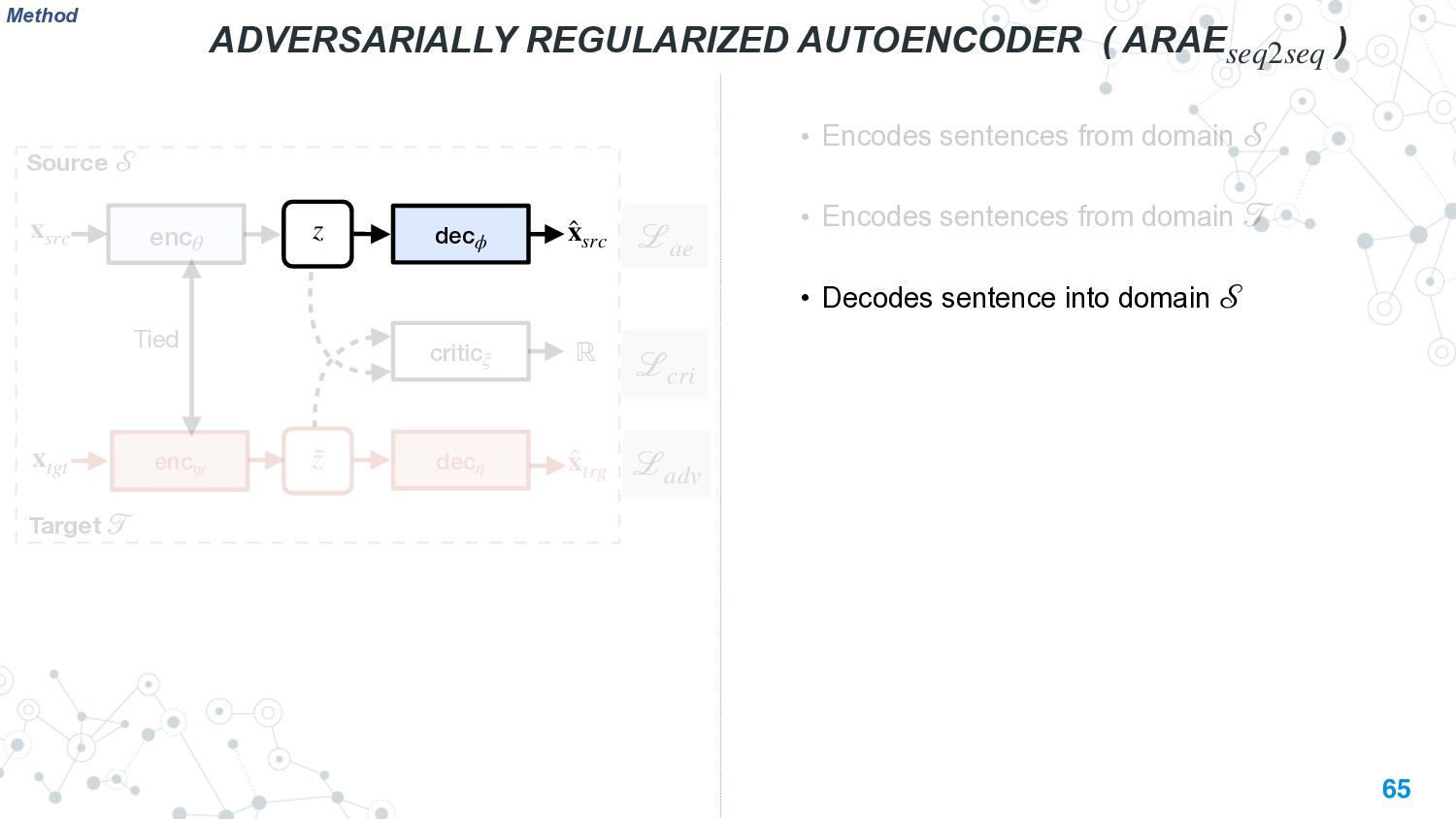{kind=link}
{kind=link}
{kind=link}
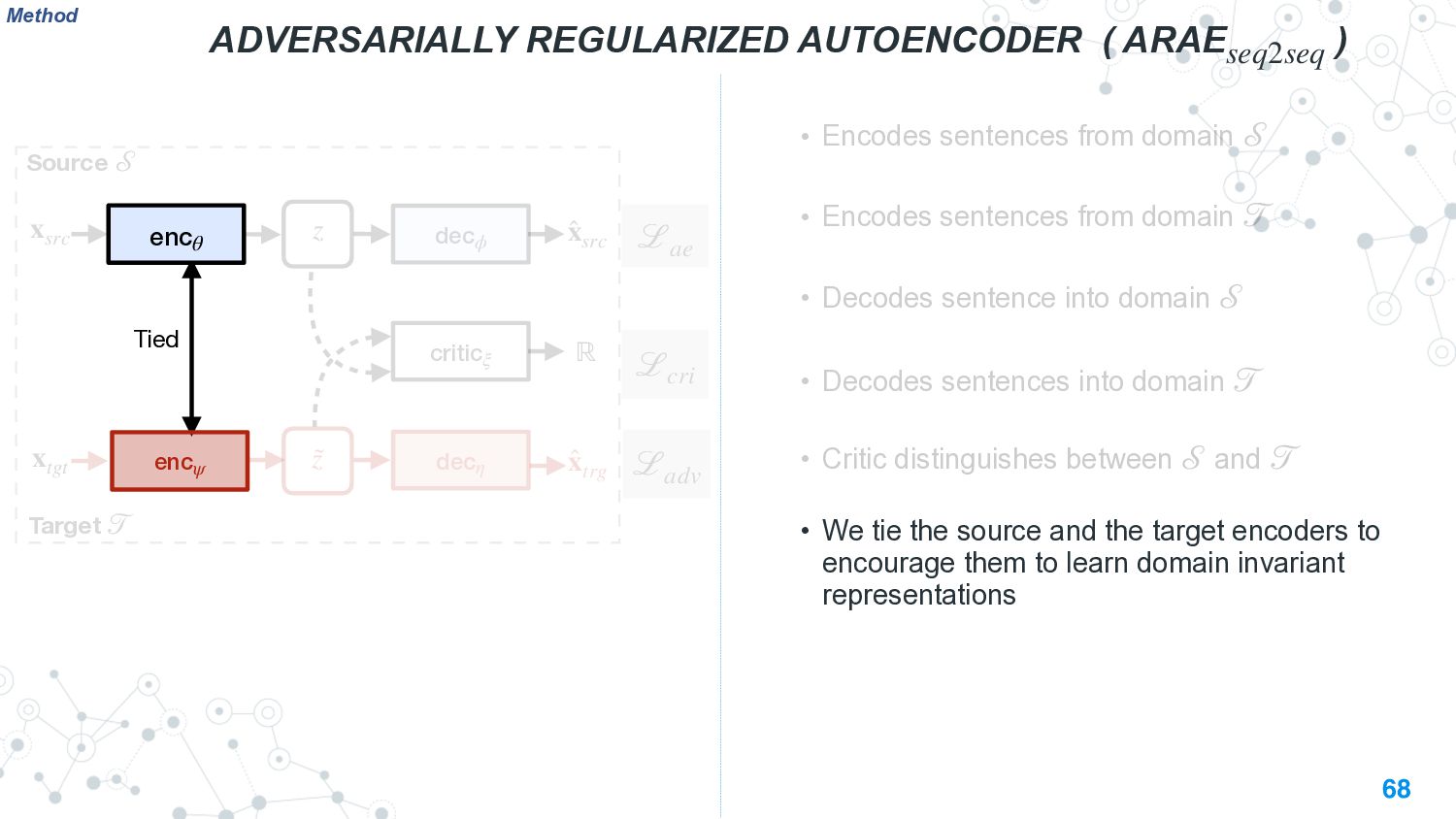{kind=link}
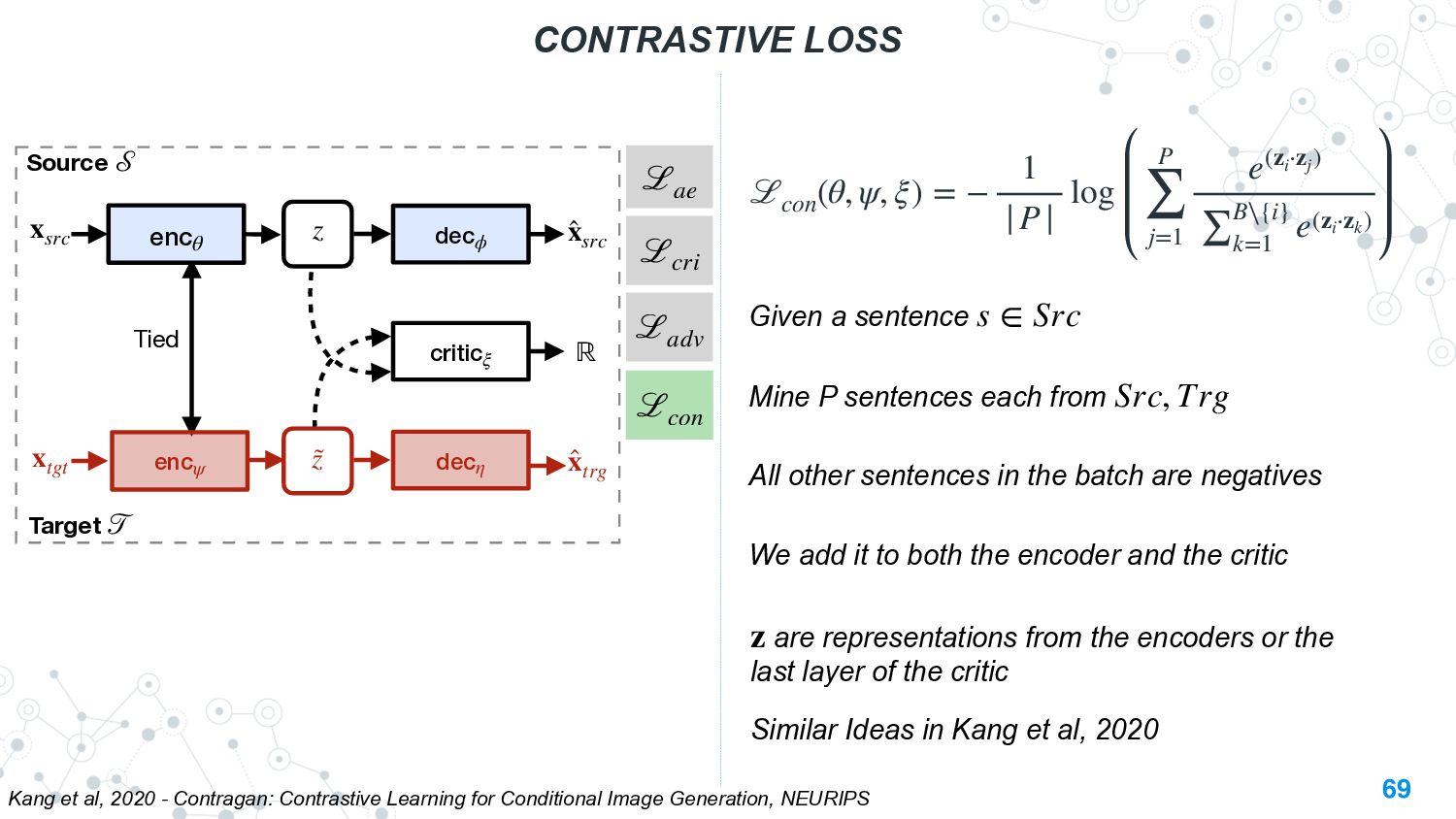{kind=link}
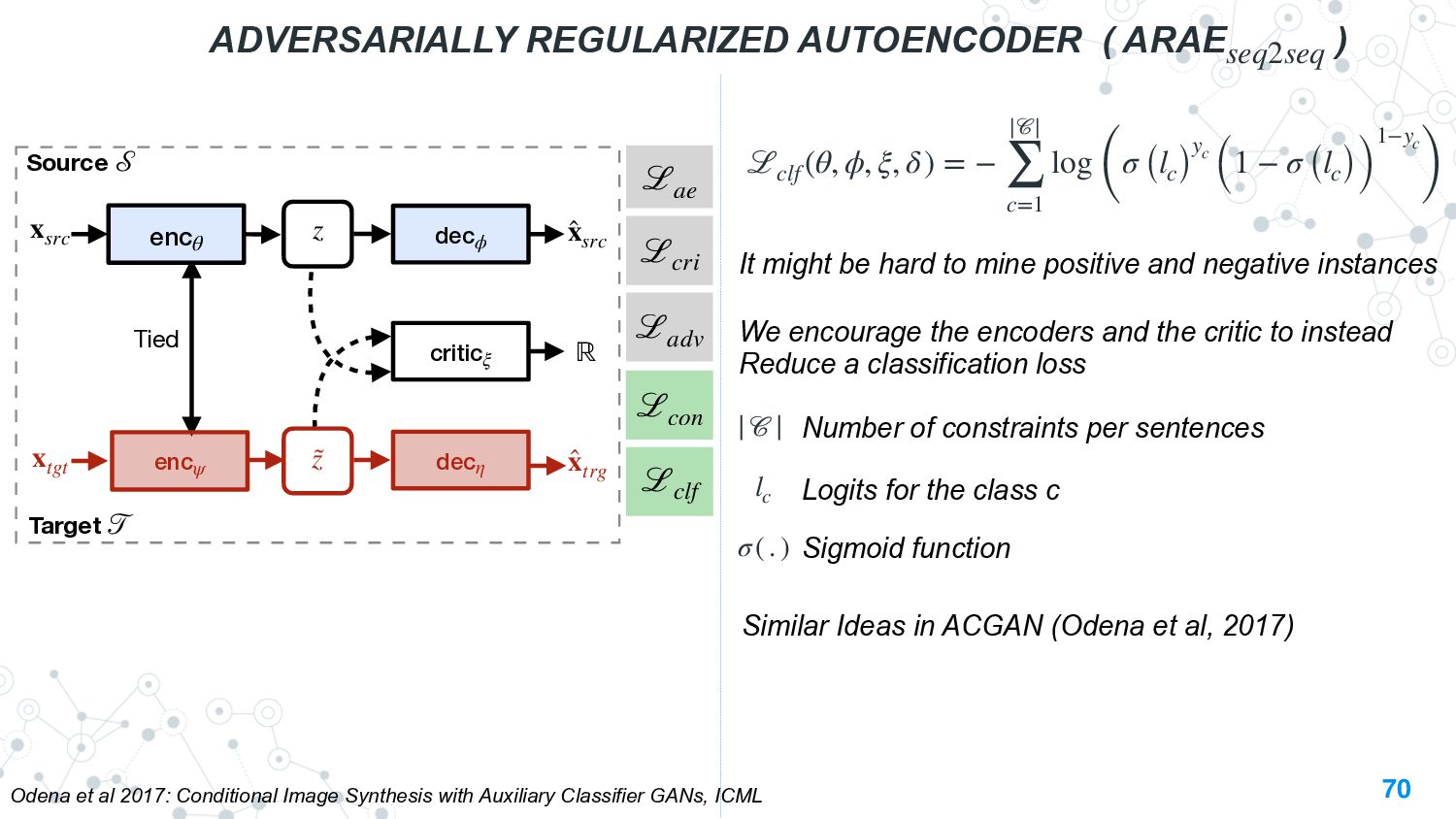{kind=link}
{kind=link}
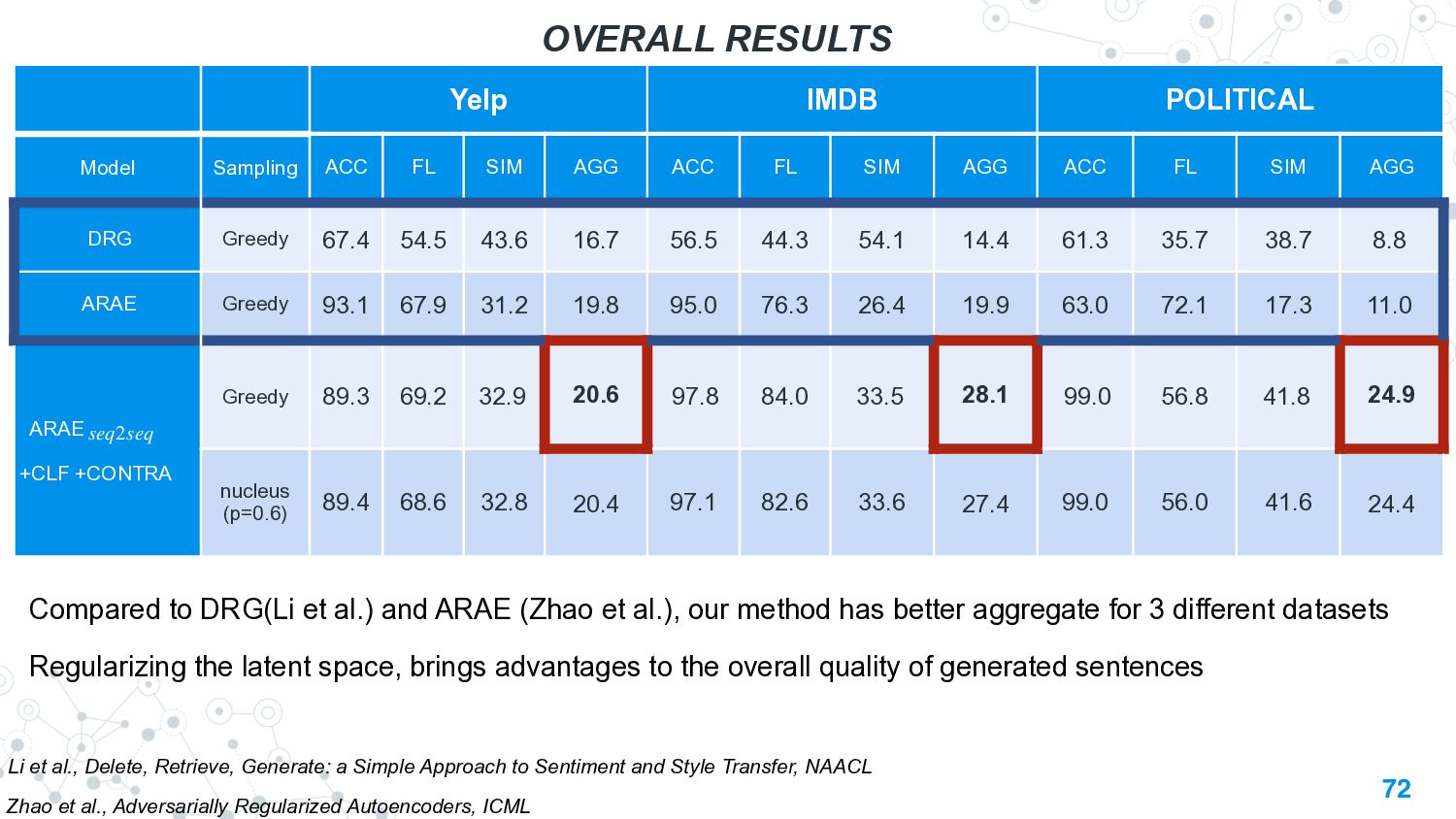{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}