Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
統計の基礎12 重回帰
Search
xjorv
February 03, 2021
Education
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
統計の基礎12 重回帰
統計の基礎12では、1つの従属変数を多数の説明変数で説明する場合の線形回帰の方法である、重回帰について説明します。
xjorv
February 03, 2021
More Decks by xjorv
See All by xjorv
コンパートメントモデル
xjorv
3
6k
コンパートメントモデルをStanで解く
xjorv
0
520
生物学的同等性試験 検出力の計算法
xjorv
0
3.7k
生物学的同等性試験ガイドライン 同等性パラメータの計算方法
xjorv
0
6.6k
粉体特性2
xjorv
0
2.6k
粉体特性1
xjorv
0
2.9k
皮膜5
xjorv
0
2.4k
皮膜4
xjorv
0
2.3k
皮膜3
xjorv
0
2.3k
Other Decks in Education
See All in Education
The Art & Science of Elearning
tmiket
1
230
モブ社員がモブエンジニアを名乗って得られたこと_20260413
masakiokuda
4
540
Throw Yourself In! - How I've learned English and What I'm Facing
georgeorge
1
160
コミュニティを通じた_キャリア設計のススメ_20260424.pdf
masakiokuda
0
340
2026年度春学期 統計学 第1回 イントロダクション ー 統計的なものの見方・考え方について (2026. 4. 9)
akiraasano
PRO
0
180
2026年度春学期 統計学 第2回 統計資料の収集と読み方 (2026. 4. 16)
akiraasano
PRO
0
200
Lectura 2 (PIT : Python Basico)
robintux
0
370
Data Management and Analytics Specialisation
signer
PRO
0
1.9k
Info Session MSc Computer Science & MSc Applied Informatics
signer
PRO
0
290
2026年度春学期 統計学 第7回 データの関係を知る(2)ー 回帰と決定係数 (2026. 5. 21)
akiraasano
PRO
0
160
Course Review - Lecture 13 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
2.3k
Data Physicalisation - Lecture 9 - Next Generation User Interfaces (4018166FNR)
signer
PRO
1
1.1k
Featured
See All Featured
The Curious Case for Waylosing
cassininazir
1
410
Building Applications with DynamoDB
mza
96
7.1k
Faster Mobile Websites
deanohume
310
32k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
870
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Site-Speed That Sticks
csswizardry
13
1.2k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
450
The Curse of the Amulet
leimatthew05
2
13k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
180
Ethics towards AI in product and experience design
skipperchong
2
320
Statistics for Hackers
jakevdp
799
230k
Transcript
統計の基礎12 重回帰 2021/1/13 Ver. 1.0
重回帰とは? 2つ以上の説明変数により、従属変数が説明される回帰のこと 血圧 年齢 体重 身長 160 54 88 177
119 30 61 169 122 41 60 184 143 54 58 174 139 34 85 174 127 46 60 183 119 17 80 177 141 45 72 147 177 62 96 169 110 29 71 166 171 58 92 160 142 68 63 174 146 42 79 170 131 47 57 160 169 56 89 165 139 25 91 180 163 58 81 165 128 48 53 176 154 56 73 173 128 43 55 161 • 血圧が年齢、体重、身長で説明できるか どうか調べる • 血圧が従属変数 • 年齢・体重・身長が説明変数
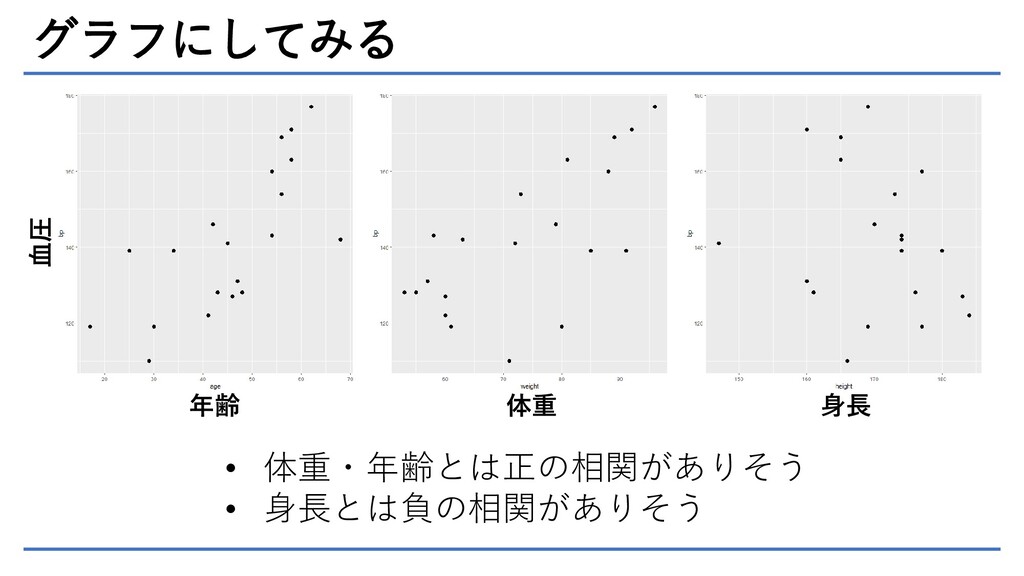
グラフにしてみる 血圧 年齢 体重 身長 • 体重・年齢とは正の相関がありそう • 身長とは負の相関がありそう
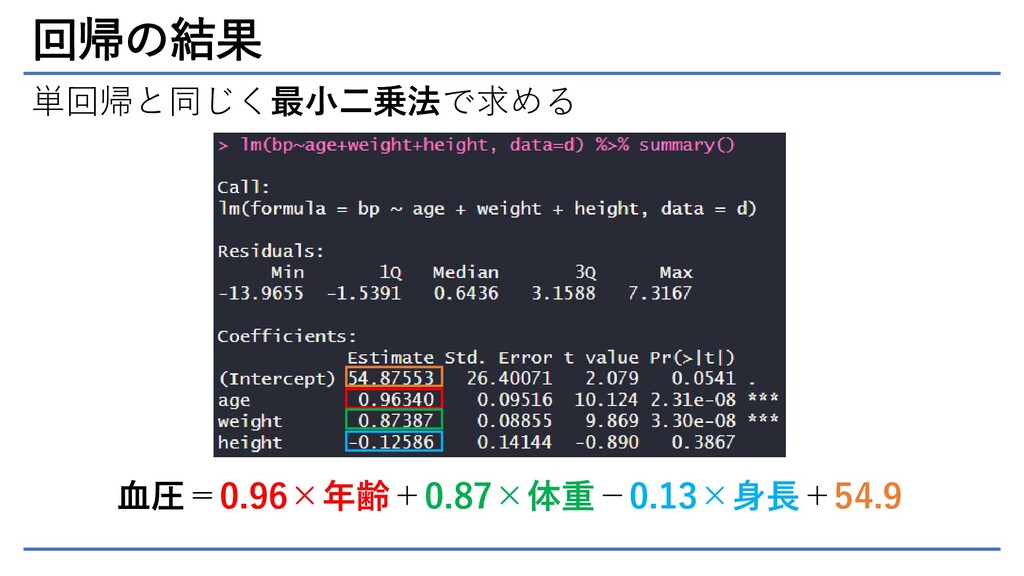
回帰の結果 単回帰と同じく最小二乗法で求める 血圧=0.96×年齢+0.87×体重-0.13×身長+54.9
p値の意味 単回帰と同じく、傾きが0とみなせる確率を示す • 年齢と体重の傾きは0ではない • 身長の傾きは0でないとは言えない • 計算方法はt検定
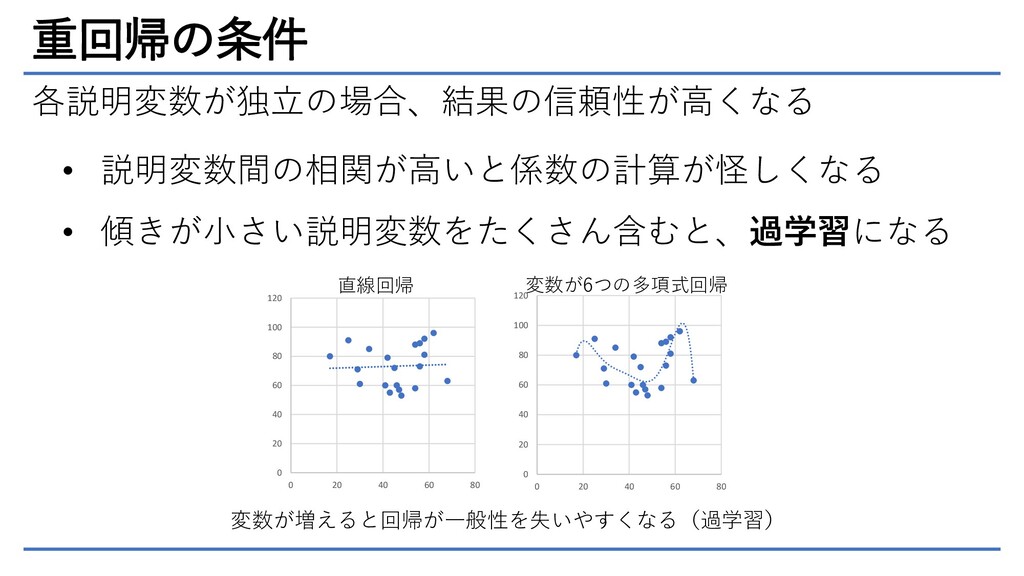
重回帰の条件 各説明変数が独立の場合、結果の信頼性が高くなる • 説明変数間の相関が高いと係数の計算が怪しくなる • 傾きが小さい説明変数をたくさん含むと、過学習になる 0 20 40 60
80 100 120 0 20 40 60 80 0 20 40 60 80 100 120 0 20 40 60 80 直線回帰 変数が6つの多項式回帰 変数が増えると回帰が一般性を失いやすくなる(過学習)
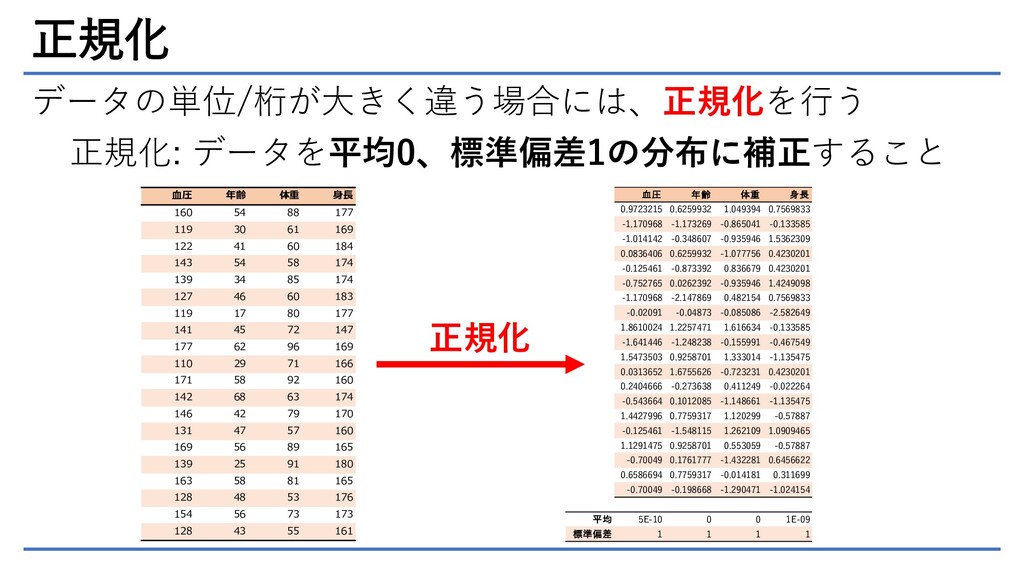
正規化 データの単位/桁が大きく違う場合には、正規化を行う 正規化: データを平均0、標準偏差1の分布に補正すること 血圧 年齢 体重 身長 0.9723215 0.6259932
1.049394 0.7569833 -1.170968 -1.173269 -0.865041 -0.133585 -1.014142 -0.348607 -0.935946 1.5362309 0.0836406 0.6259932 -1.077756 0.4230201 -0.125461 -0.873392 0.836679 0.4230201 -0.752765 0.0262392 -0.935946 1.4249098 -1.170968 -2.147869 0.482154 0.7569833 -0.02091 -0.04873 -0.085086 -2.582649 1.8610024 1.2257471 1.616634 -0.133585 -1.641446 -1.248238 -0.155991 -0.467549 1.5473503 0.9258701 1.333014 -1.135475 0.0313652 1.6755626 -0.723231 0.4230201 0.2404666 -0.273638 0.411249 -0.022264 -0.543664 0.1012085 -1.148661 -1.135475 1.4427996 0.7759317 1.120299 -0.57887 -0.125461 -1.548115 1.262109 1.0909465 1.1291475 0.9258701 0.553059 -0.57887 -0.70049 0.1761777 -1.432281 0.6456622 0.6586694 0.7759317 -0.014181 0.311699 -0.70049 -0.198668 -1.290471 -1.024154 平均 5E-10 0 0 1E-09 標準偏差 1 1 1 1 血圧 年齢 体重 身長 160 54 88 177 119 30 61 169 122 41 60 184 143 54 58 174 139 34 85 174 127 46 60 183 119 17 80 177 141 45 72 147 177 62 96 169 110 29 71 166 171 58 92 160 142 68 63 174 146 42 79 170 131 47 57 160 169 56 89 165 139 25 91 180 163 58 81 165 128 48 53 176 154 56 73 173 128 43 55 161 正規化
まとめ • 1つの従属変数を多数の説明変数で説明するモデルを重回帰 と呼ぶ • 重回帰は単回帰と同じく、最小二乗法で計算する • 重回帰の傾きにはt検定が適用される • 説明変数が多すぎると、過学習が起きる
• データの単位や桁によっては、データの正規化を行う
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}