In a distributed system with multiple moving parts, which is the case of Microservices, we can’t allow that a single complement downtime breaks down the entire system. Dealing with stateless code is easy, but it gets much harder when we have to deal with persistent state. In this scenario, zero downtime migrations are paramount to guarantee integrity and consistency.
Within all the Microservices characteristics, undoubtedly the one that creates more perplexity is the “one database per Microservice”. However, very few teams have the privilege of starting something from scratch: most of the times they have a legacy database that will survive any new implementation.
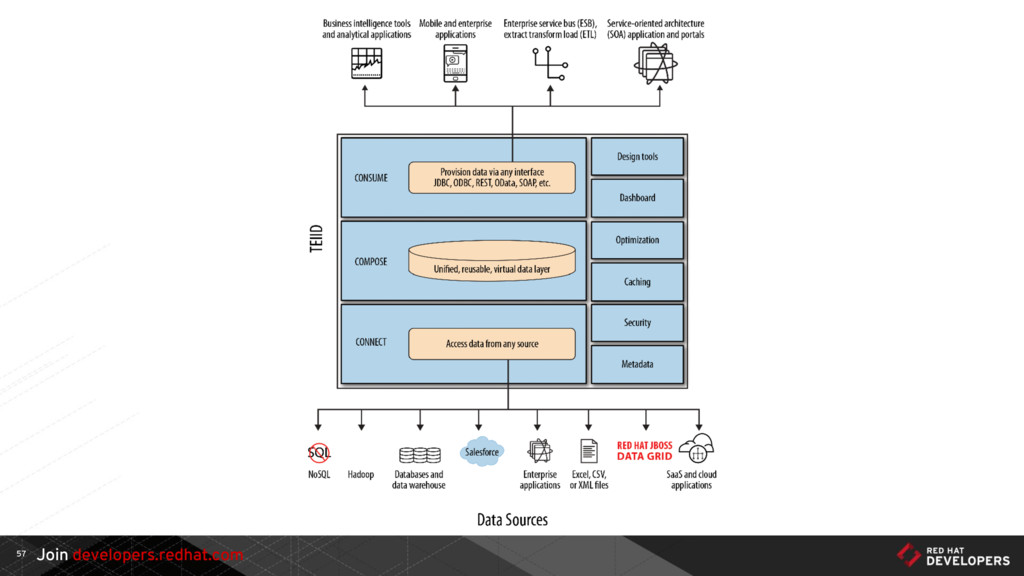
In legacy systems you traditionally have a model that adopts transactions, strong consistency, and CRUD. In order to guarantee integrity and consistency with zero downtime, we must reassess some of these concepts. In this talk we’ll discuss strong and eventual consistency, CRUD and CQRS, Event Sourcing, and how these techniques relate to each other in many different integration and evolution strategies for relational databases. We’ll explore Views, Materialized Views, Mirror Tables, Event Sourcing/Streaming, Data Virtualization, Change Data Capture, and how these strategies enable you to build up a Microservices architecture from a legacy monolithic relational database.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}