Share
一橋大学「#経済学のための実践的データ分析」 2020春: 7/10回 7.テキスト分析をやってみよう 7.1.テキスト分析でできること 7.2.WordCloudを書いてみよう 7.3.Word2vecやTopicモデル 7.4.計量テキスト分析をやろ APPENDIX. 感情分析
一橋大学大学院経済学研究科 原泰史 [email protected]
{kind=link}
![今日の内容 • 13:00-13:15 • プレ講義 [録画なし] • 13:15-13:35 • 7.1テキスト分析でできること](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
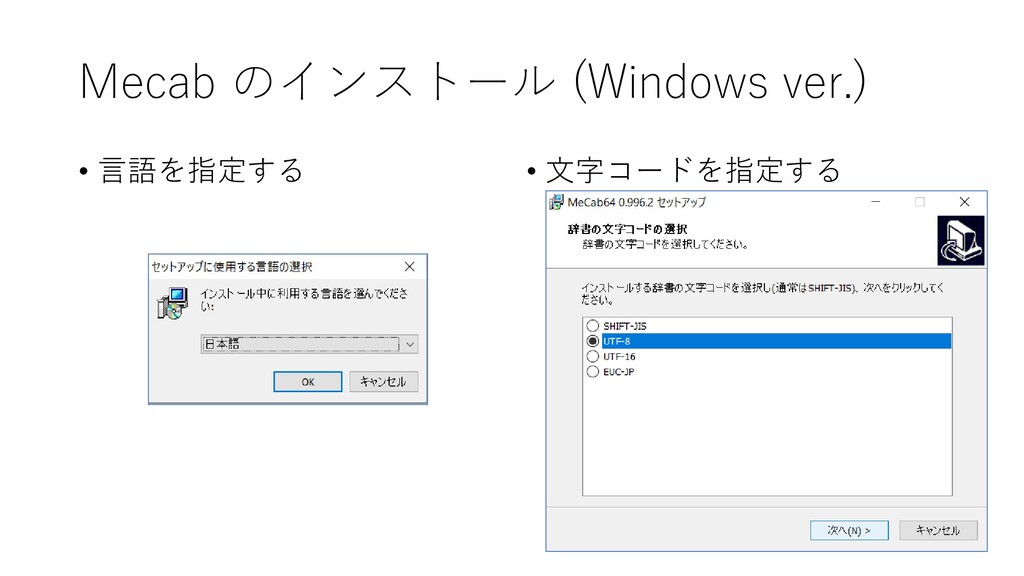{kind=link}
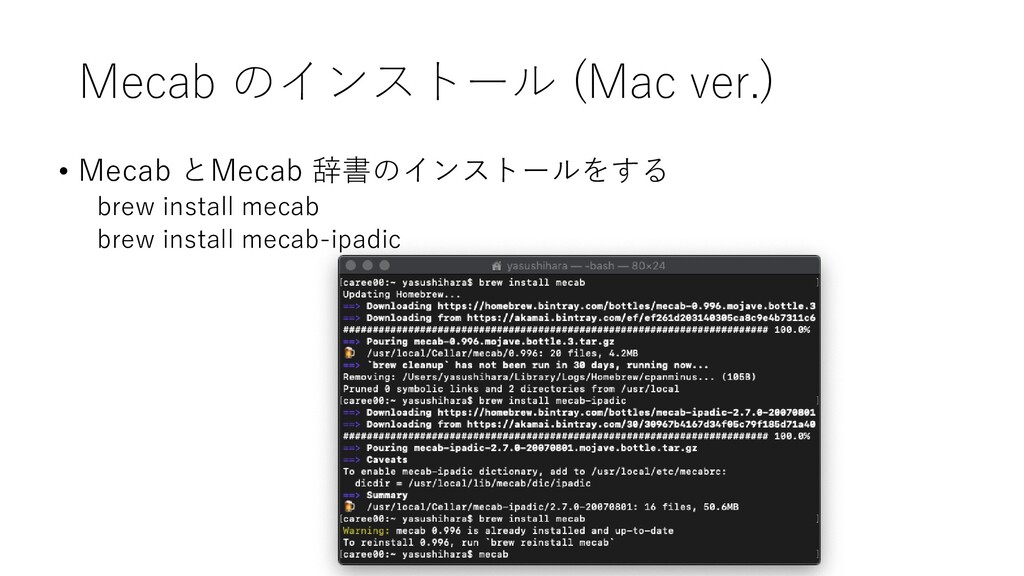{kind=link}
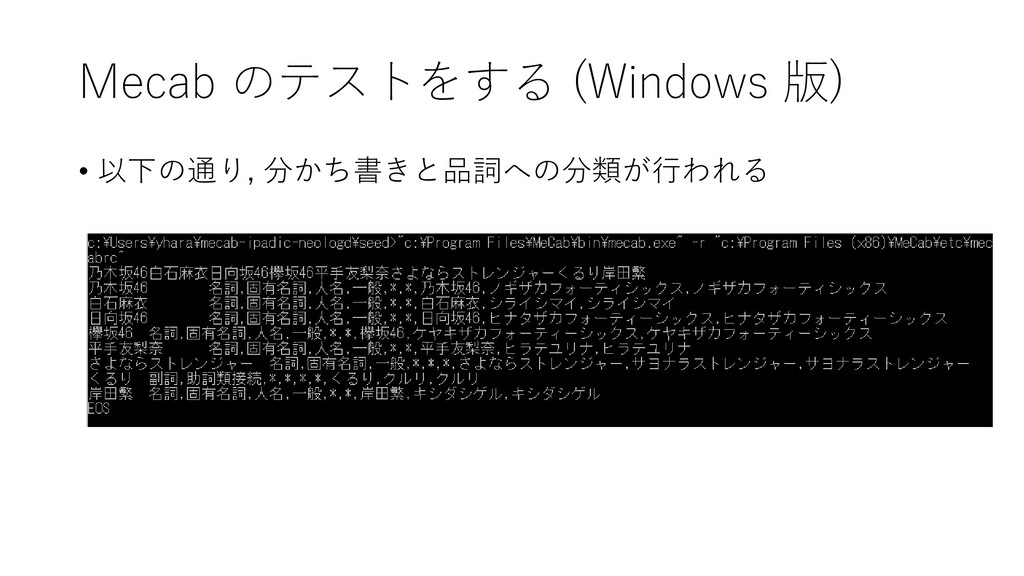{kind=link}
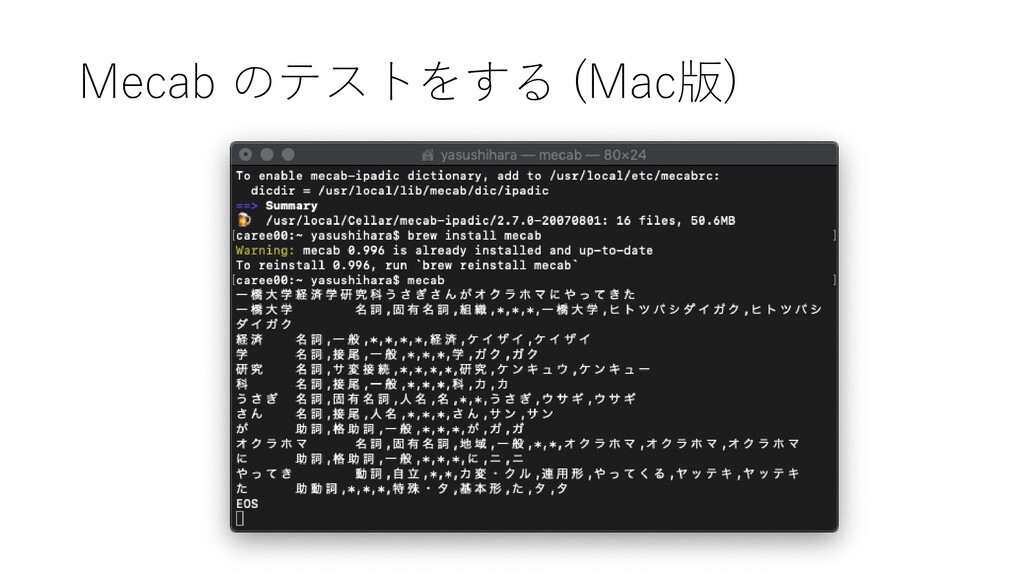{kind=link}
{kind=link}
{kind=link}
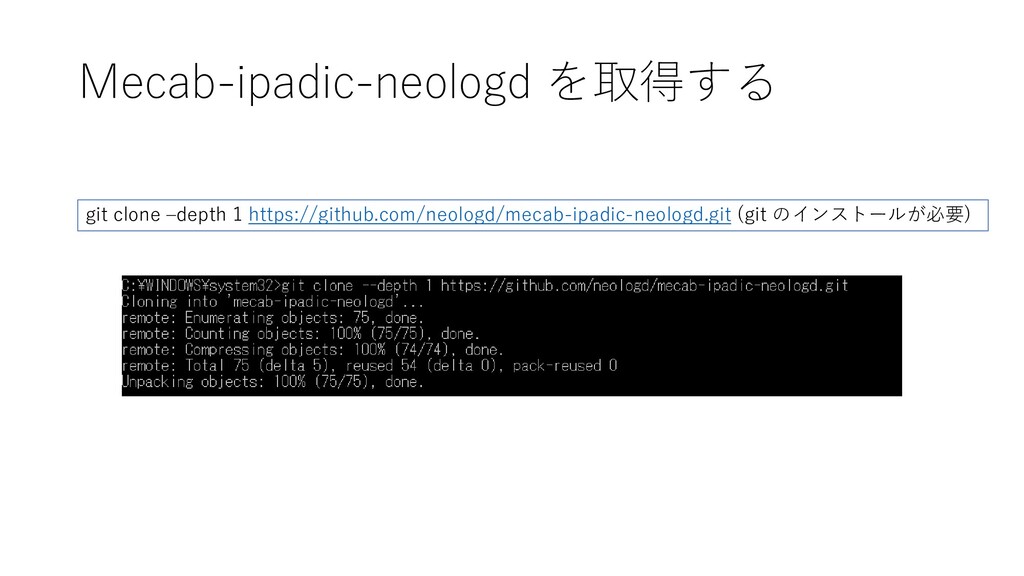{kind=link}
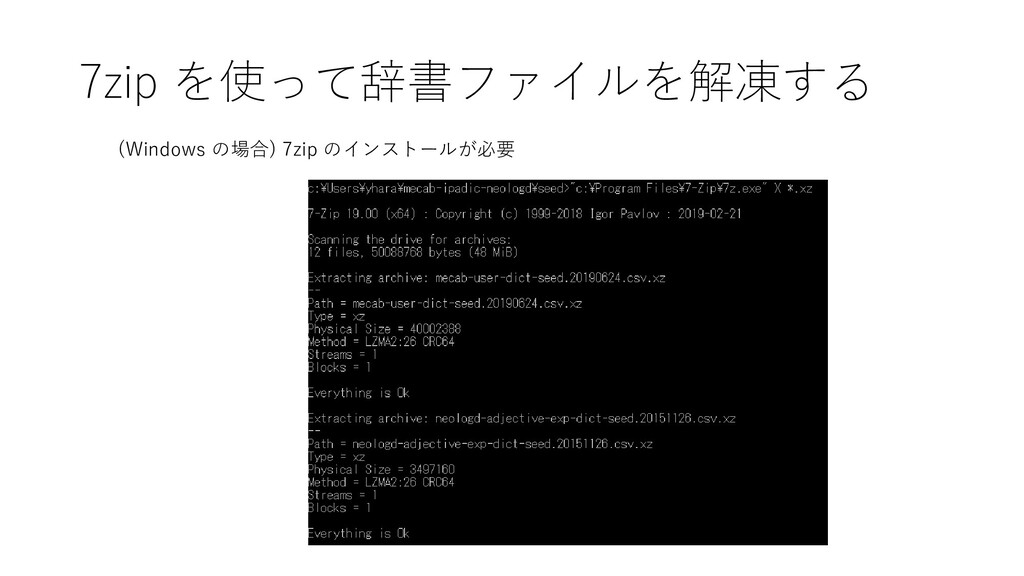{kind=link}
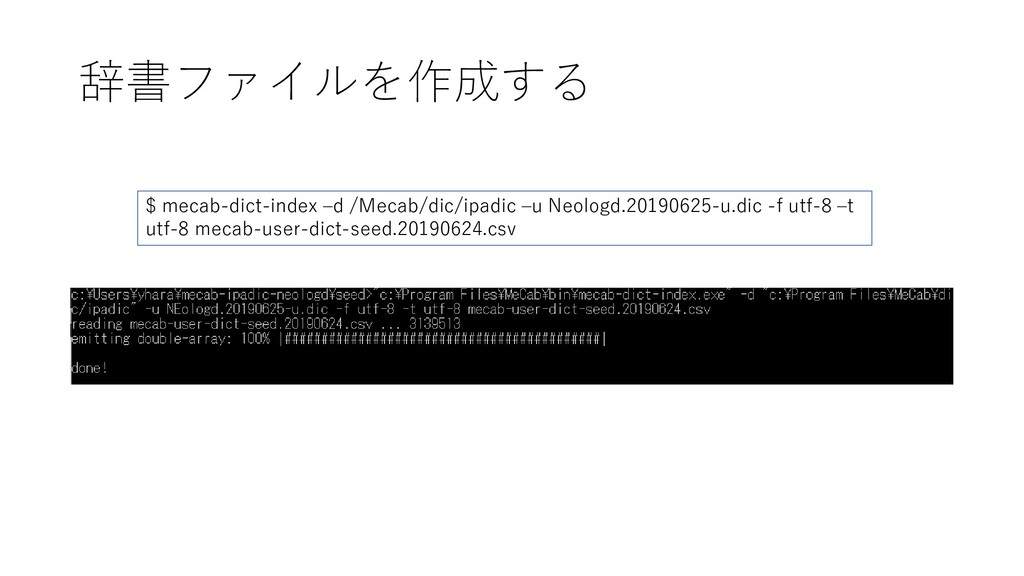{kind=link}
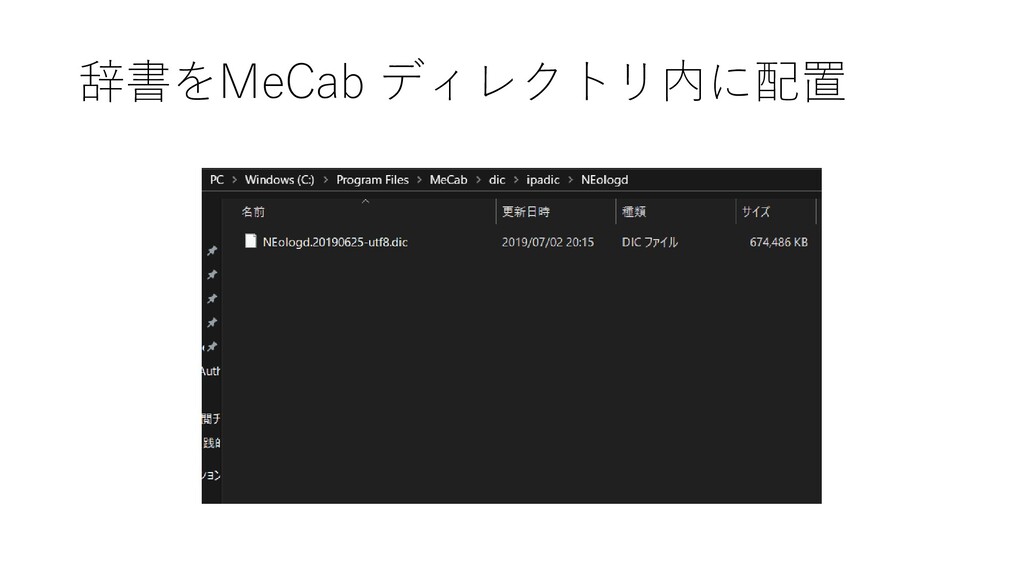{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
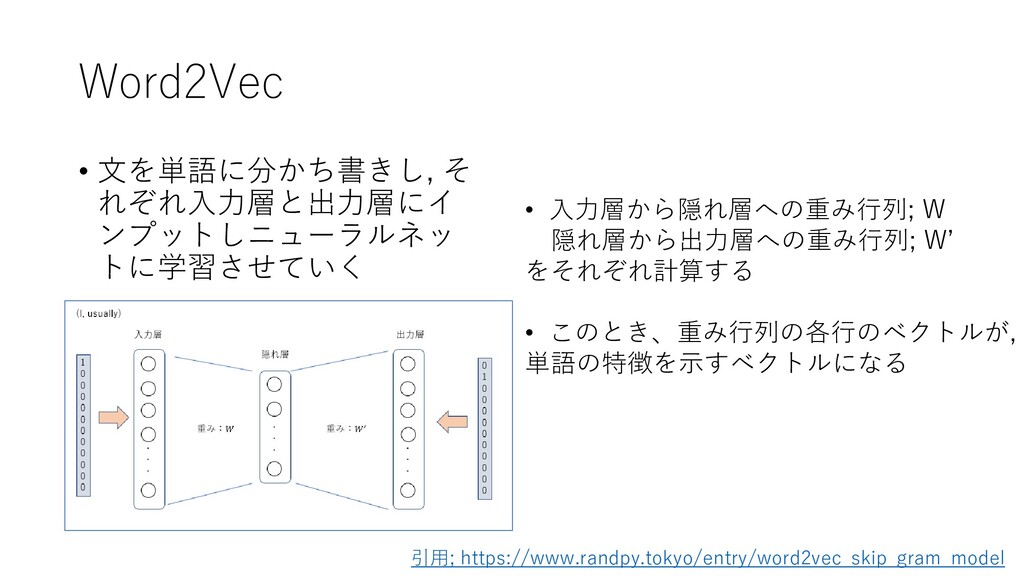{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
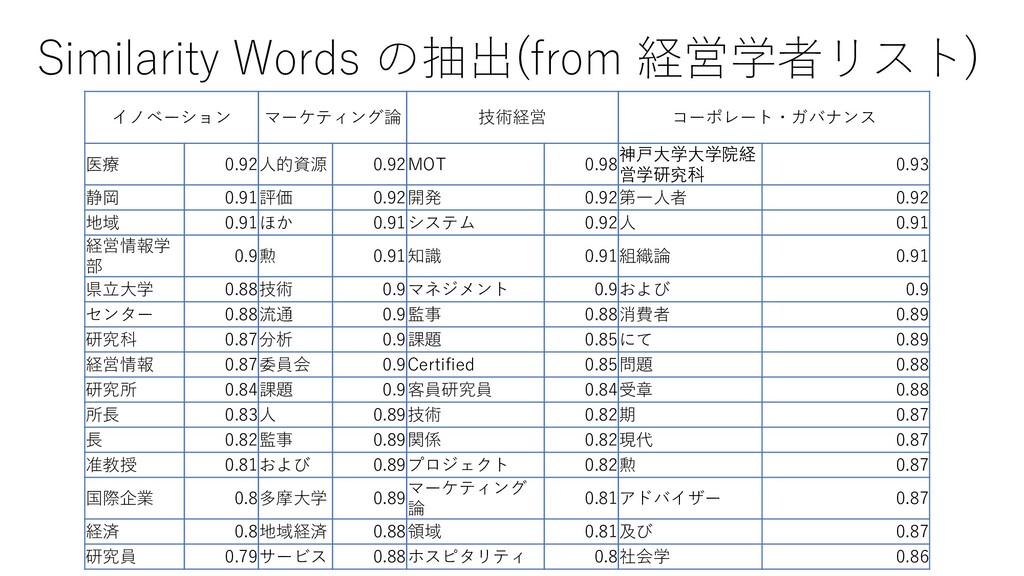{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
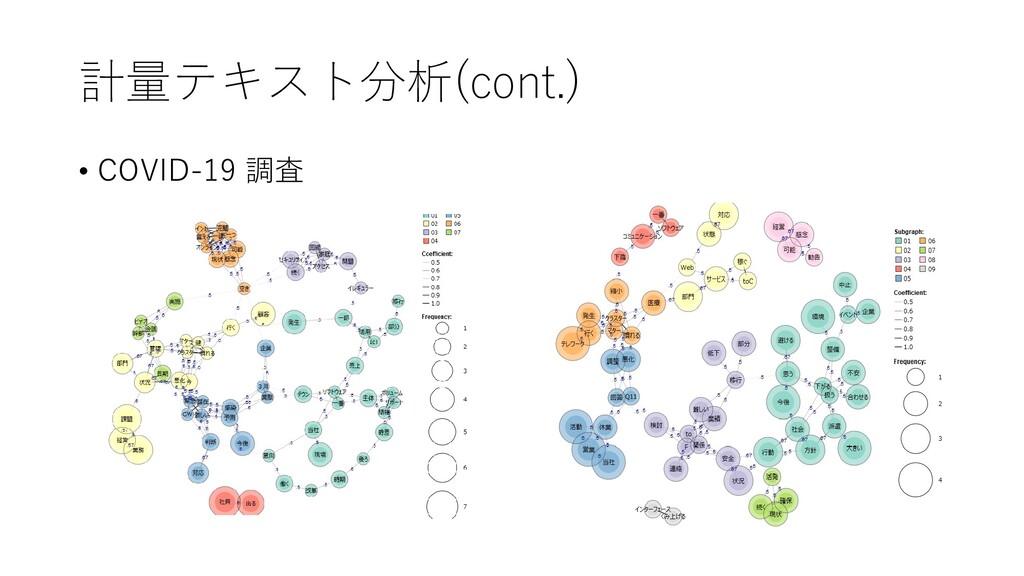{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
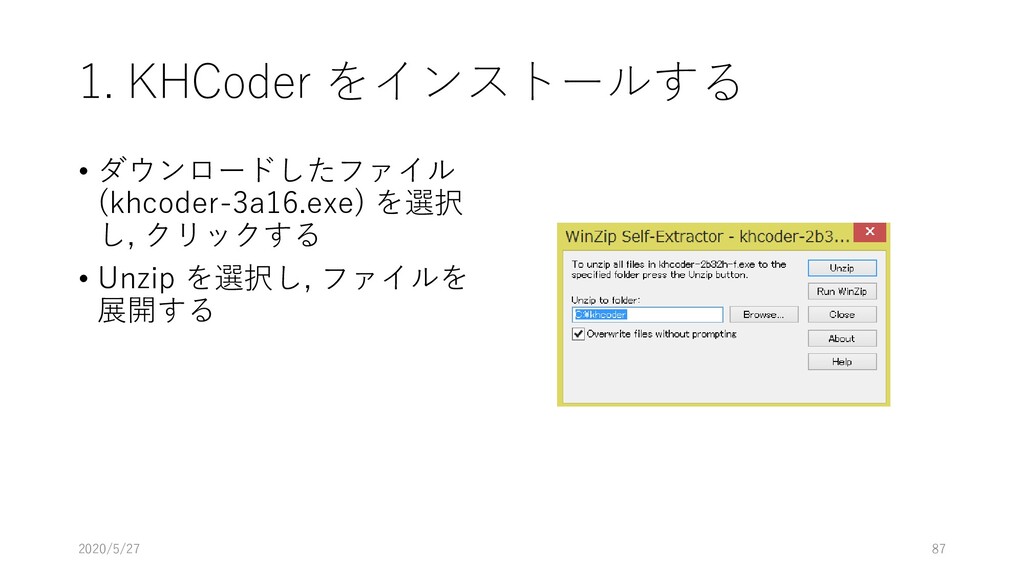{kind=link}
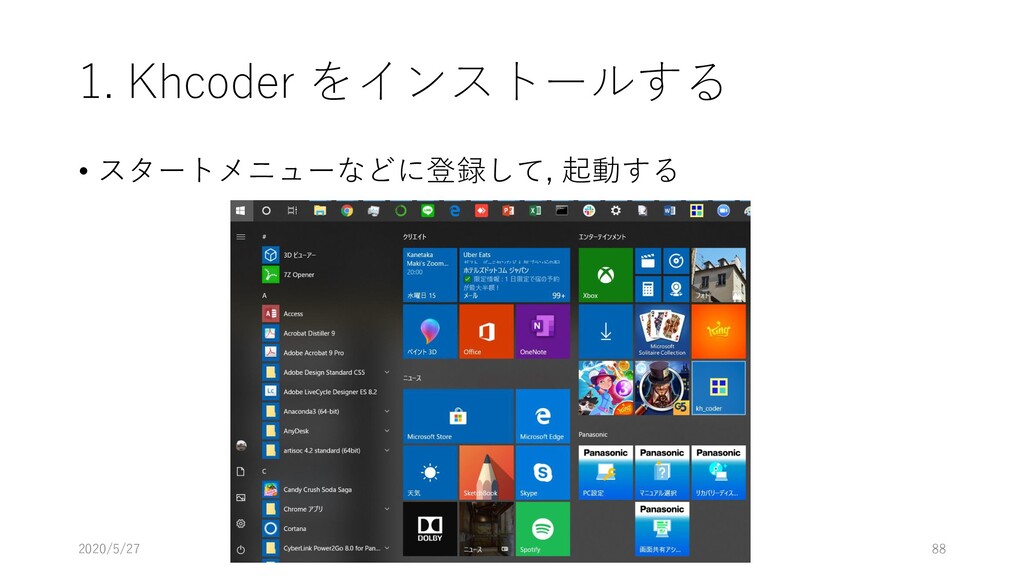{kind=link}
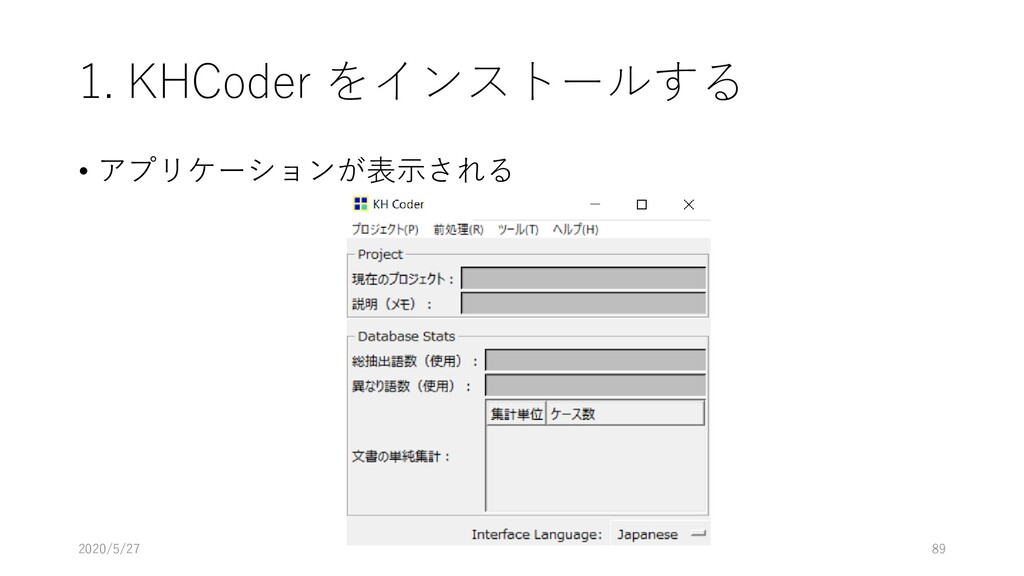{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![3. KHCoder に定点調査の自由記述データ を読み込む • KHCoder を開く • [プロジェクト] –[新規]](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_96.jpg){kind=link}
![3. KHCoder にデータを読み込む • [参照]をクリックして, 分析対 象ファイルを選ぶ • 分析対象とする列について[詳 細]](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_97.jpg){kind=link}
![4. データ分析前の処理をする • [前処理] – [テキストのチェッ ク]をクリックする • OKをクリックする 2020/5/27](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_98.jpg){kind=link}
![4. データ分析前の処理をする • 修正が必要である旨メッセージが表示される • [画面に表示] をクリックして, 問題点をチェックする • “テキストの自動修正”](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_99.jpg){kind=link}
![4. データ分析前の処理をする • 問題点が修正される. • [閉じる]をクリックする. 2020/5/27 101](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_100.jpg){kind=link}
![4. データ分析前の処理をする • [前処理] – [前処理の実行] を選択する • OKをクリックする 2020/5/27](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_101.jpg){kind=link}
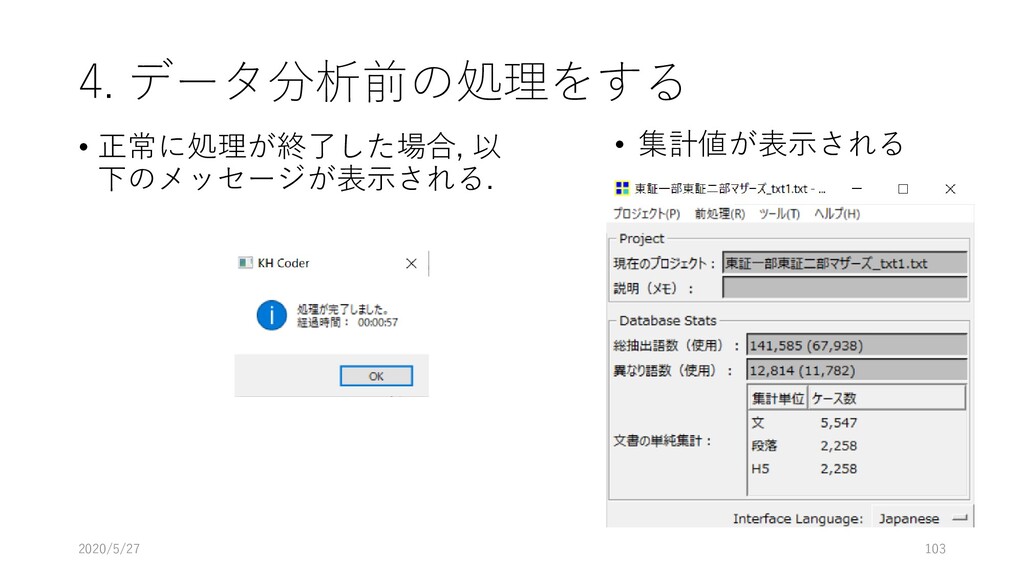{kind=link}
![4. データ分析前の処理をする • 複合語の検出を行う • [前処理]-[複合語の検出]-[茶筌 を利用]をクリックする](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_103.jpg){kind=link}
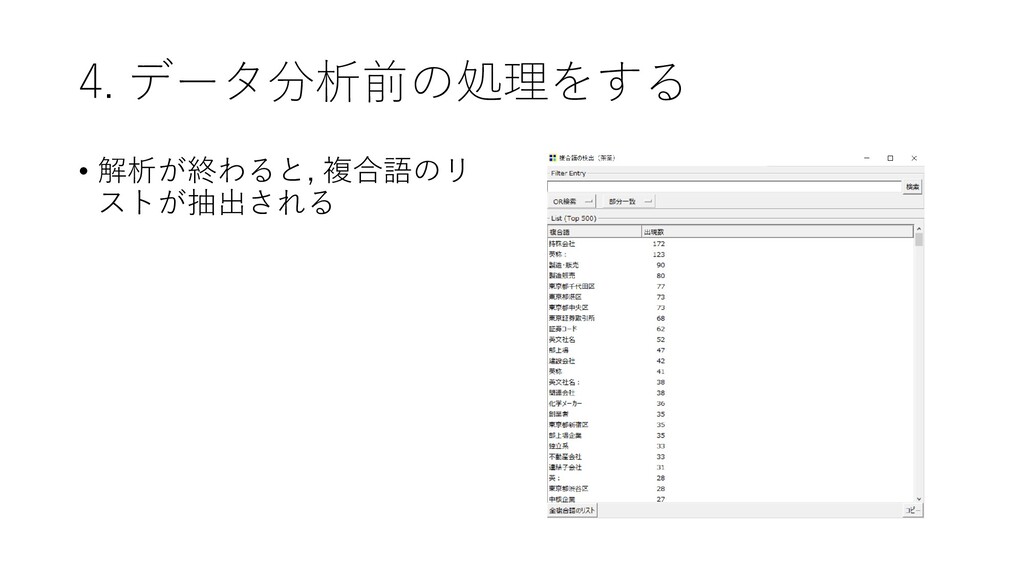{kind=link}
![5. 頻出語の取り出しを行う • [ツール]-[抽出語]-[抽出語 リスト(Excel)]を選択する 2020/5/27 106](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_105.jpg){kind=link}
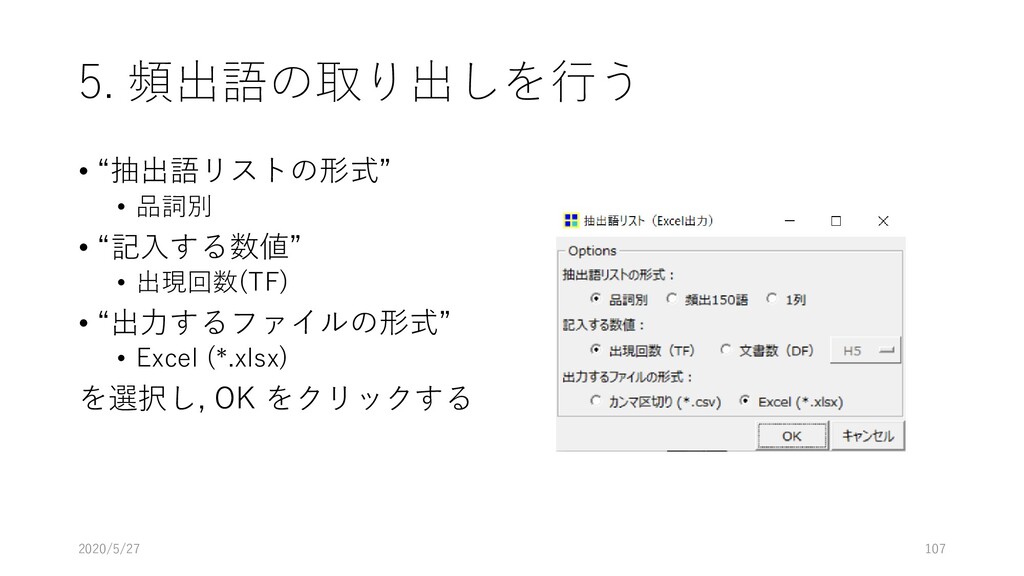{kind=link}
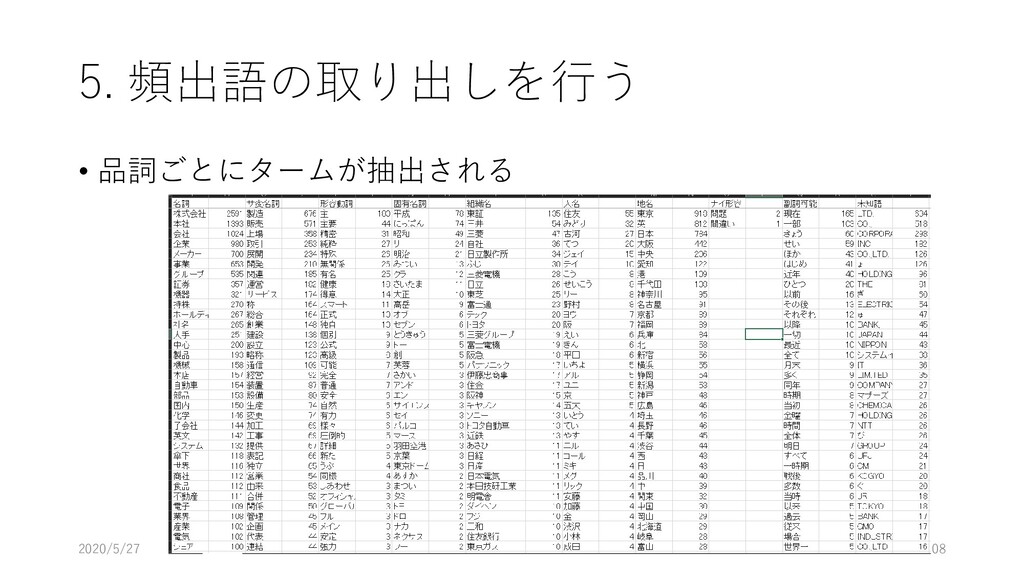{kind=link}
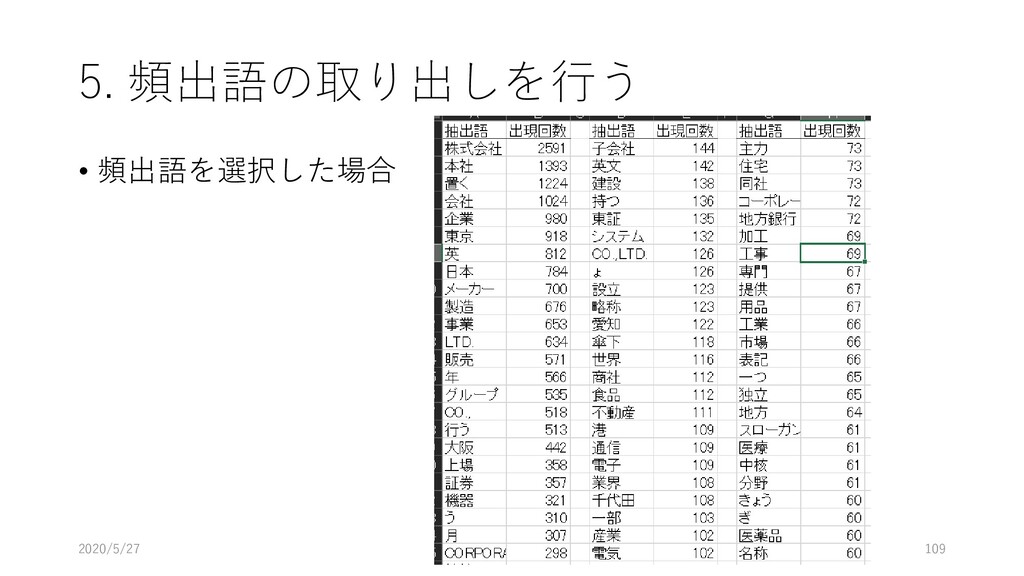{kind=link}
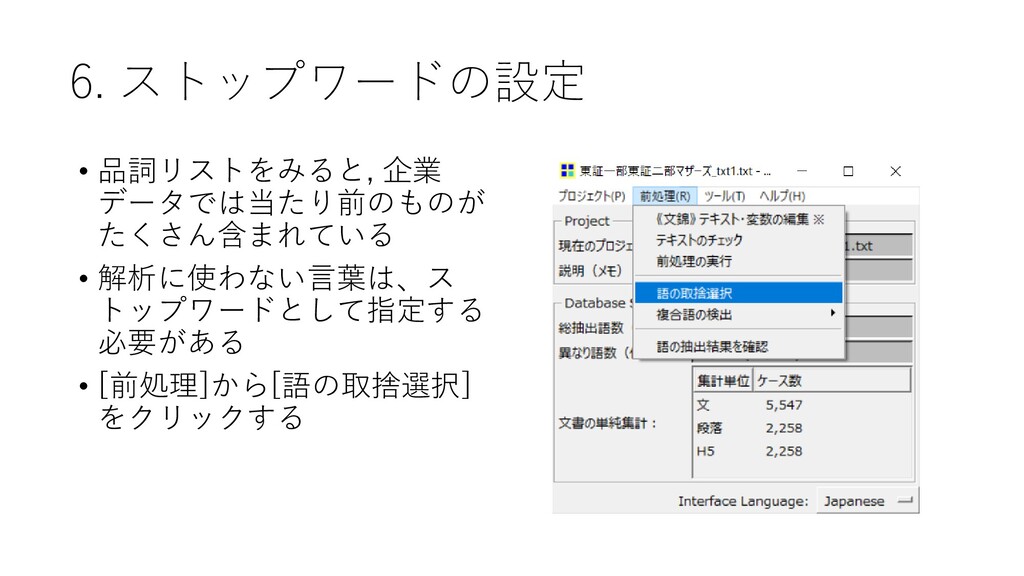{kind=link}
{kind=link}
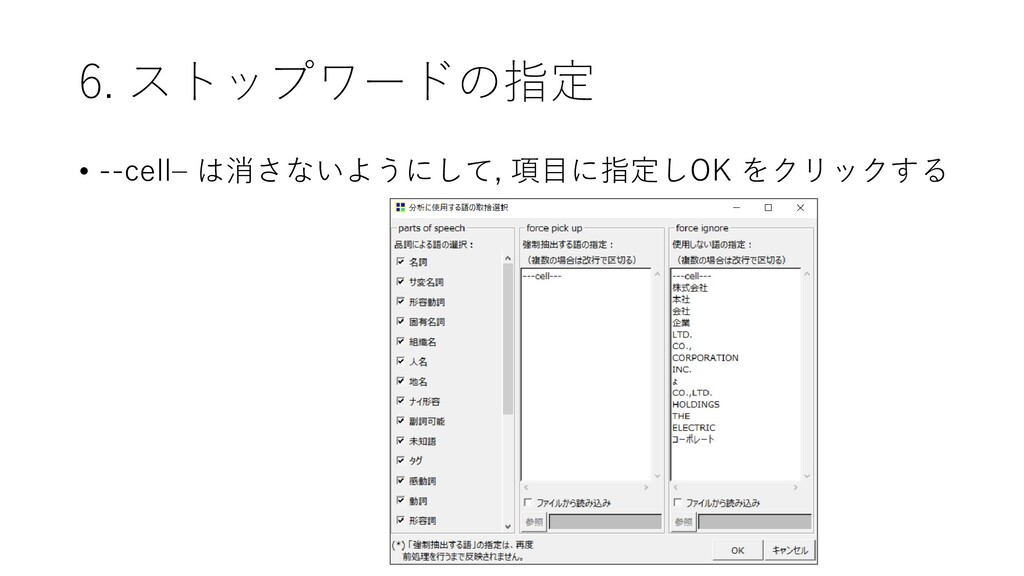{kind=link}
![6. 共起ネットワークを書く • [ツール]-[抽出語]-[共起 ネットワーク]を選択する 2020/5/27 113](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_112.jpg){kind=link}
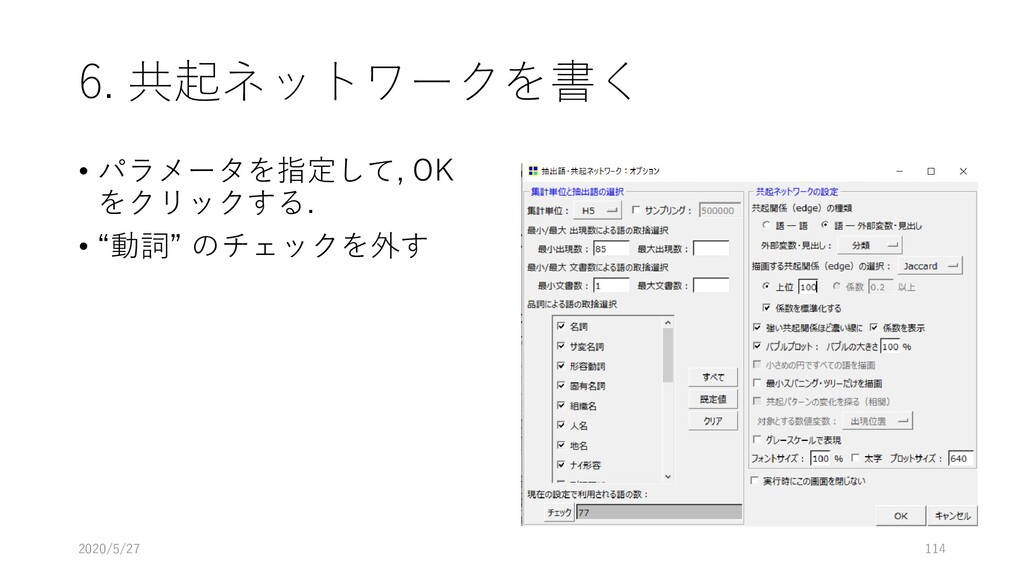{kind=link}
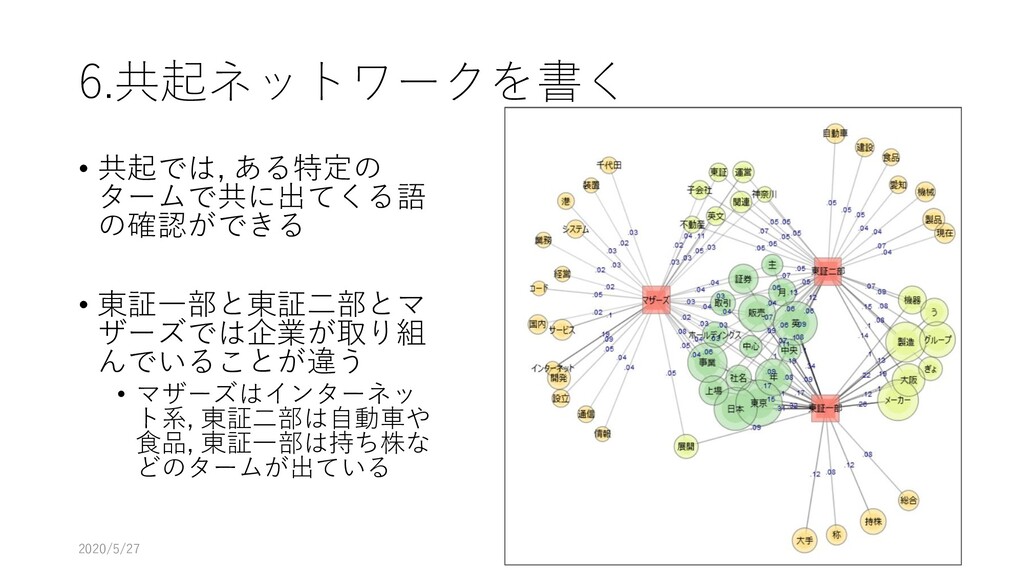{kind=link}
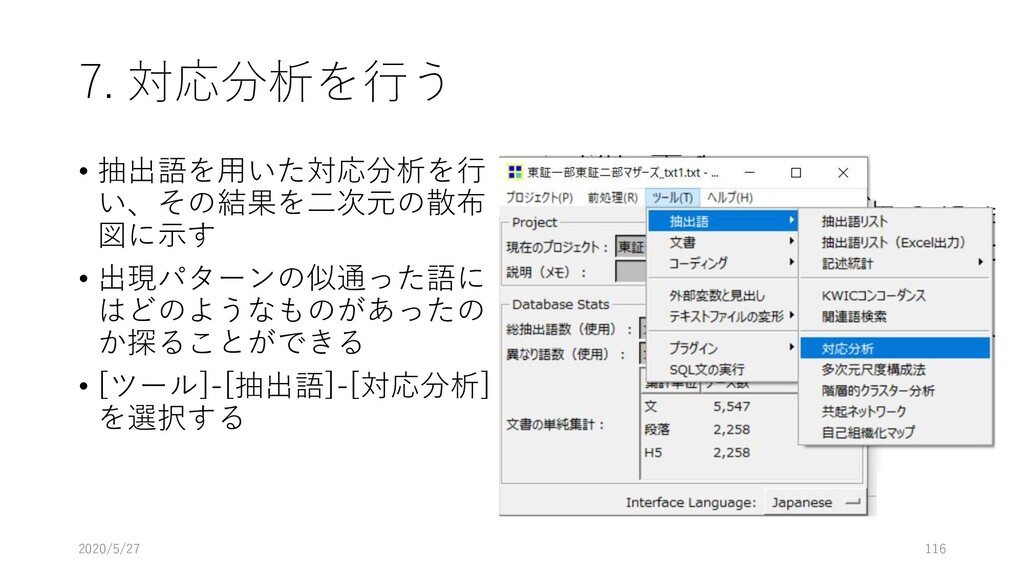{kind=link}
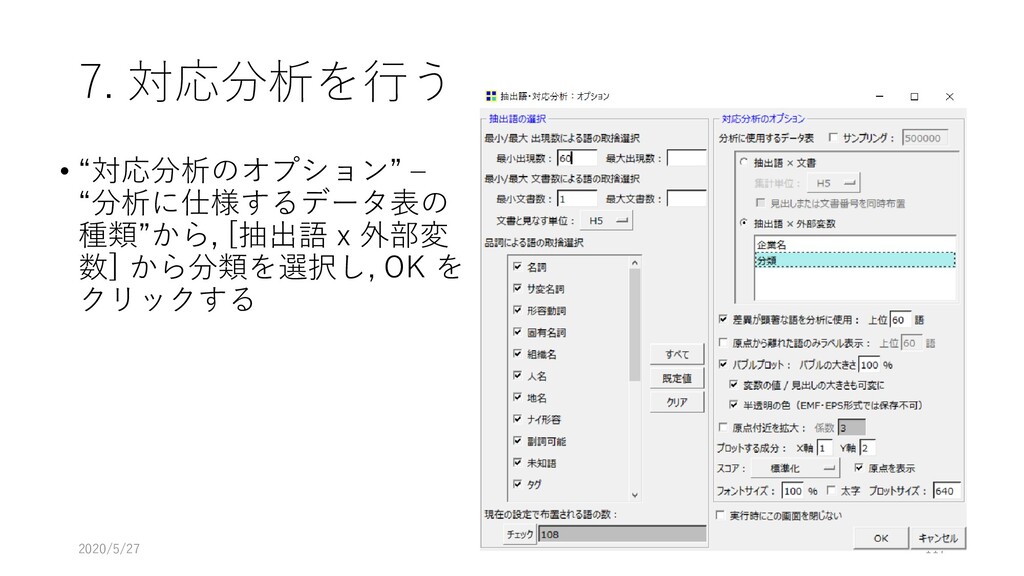{kind=link}
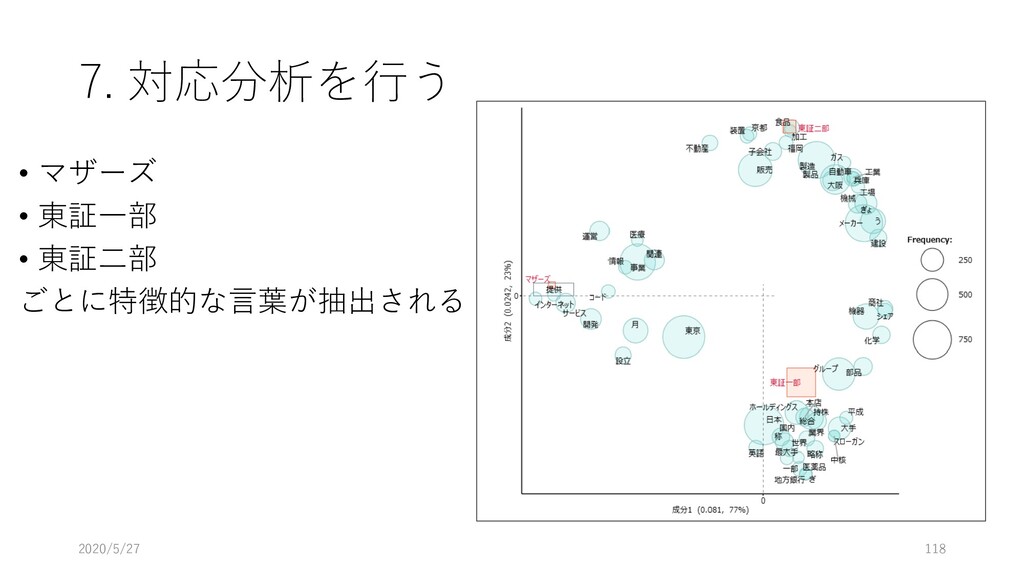{kind=link}
![8. 多次元尺度構成法で解析する • 近接している語のパターンを 解析できる • [ツール]-[抽出語]-[多次元尺 度構成法]を選択する](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_118.jpg){kind=link}
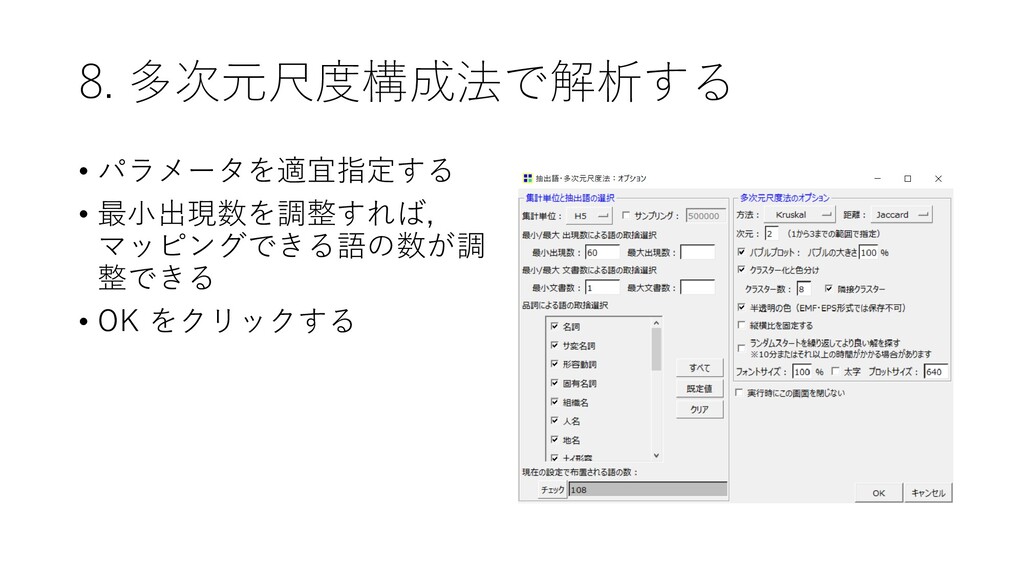{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10. コーディングルールに基づき単純推 計する • [ツール]-[コーディング]-[単 純推計] をクリックする](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_123.jpg){kind=link}
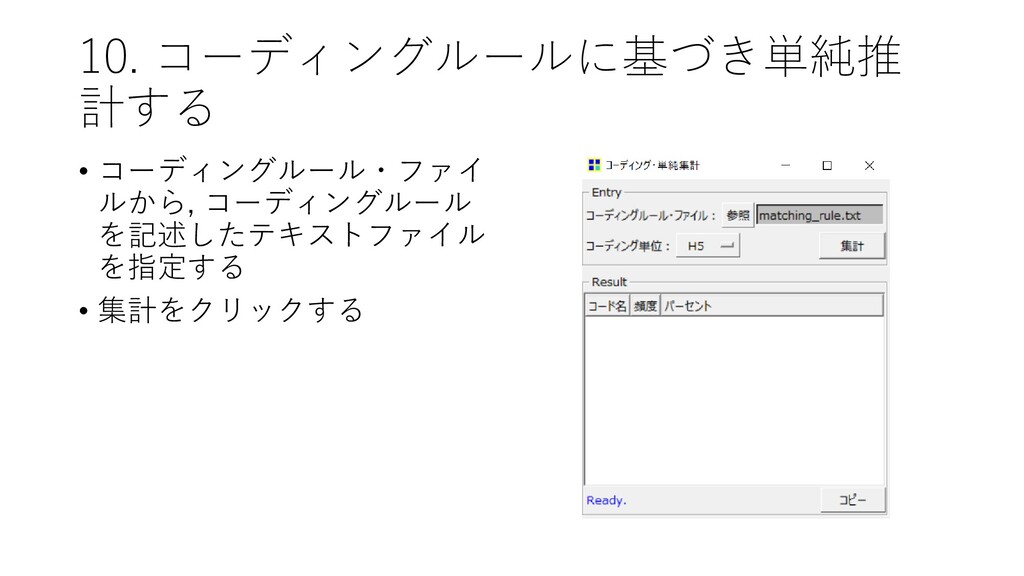{kind=link}
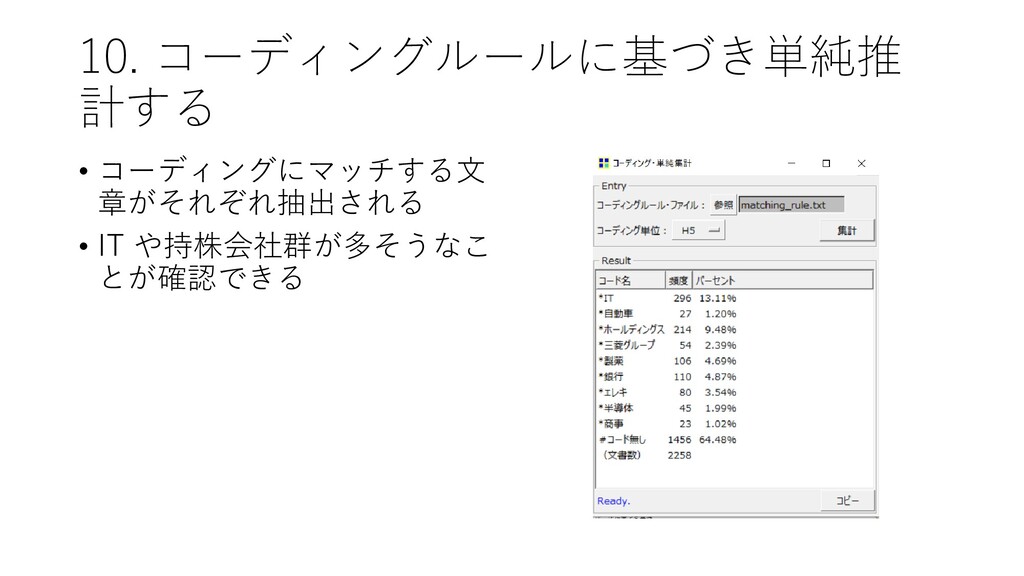{kind=link}
![11. コーディングルールに基づきクロス 集計する • [ツール]-[コーディング]-[ク ロス集計] をクリックする](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_126.jpg){kind=link}
![11. コーディングルールに基づきクロス 集計する • クロス集計[分類]を選択した上で, [集計] をクリックする • マザーズはITの割合が高いことが確認できる](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_127.jpg){kind=link}
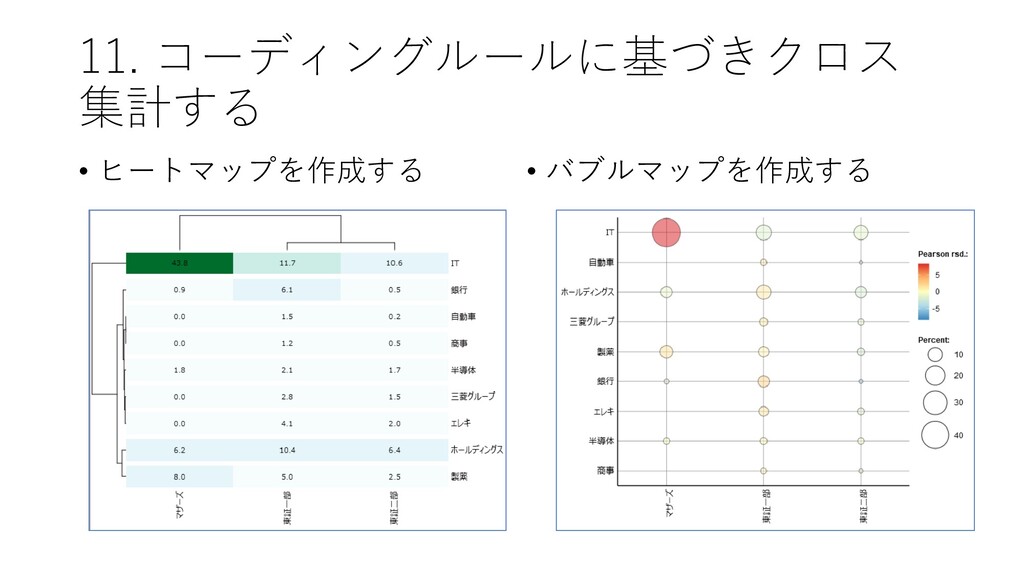{kind=link}
![12. Jacaard 係数に基づき類似度行列を導 出する • [ツール]-[コーディング]-[類 似度行列]をクリックする](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_129.jpg){kind=link}
![13. コーディングルールに基づき対応分 析を行う • [ツール]-[コーディング]-[対 応分析]をクリックする](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_130.jpg){kind=link}
{kind=link}
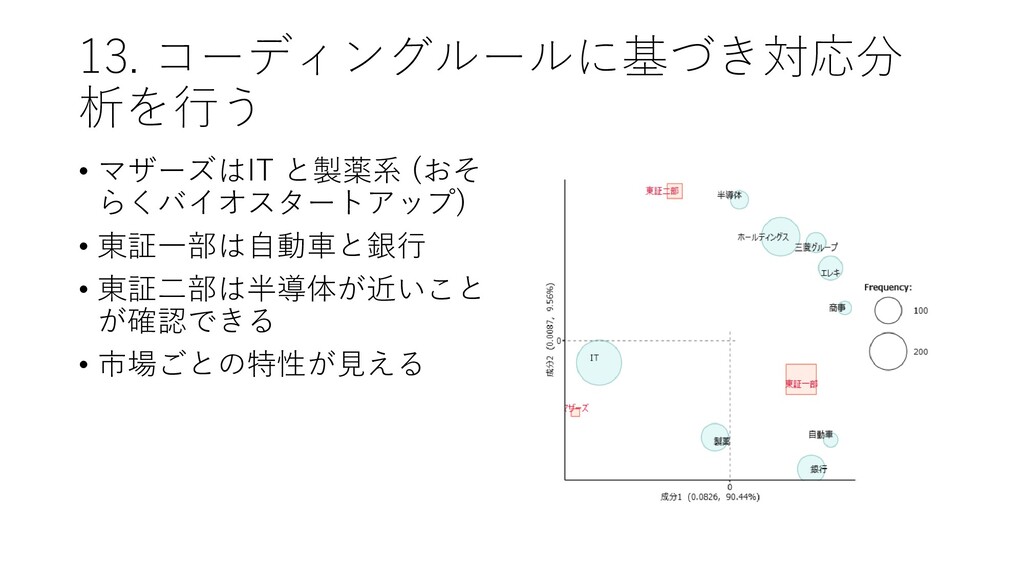{kind=link}
![14. コーディングルールに基づき共起 ネットワーク分析を行う • [ツール]-[コーディング]-[共 起ネットワーク] をクリック する](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_133.jpg){kind=link}
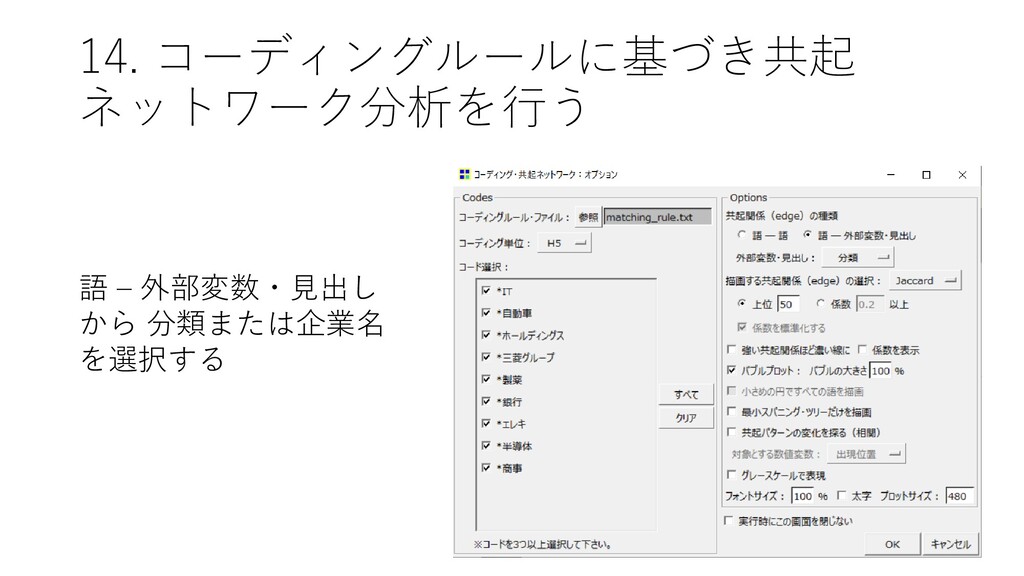{kind=link}
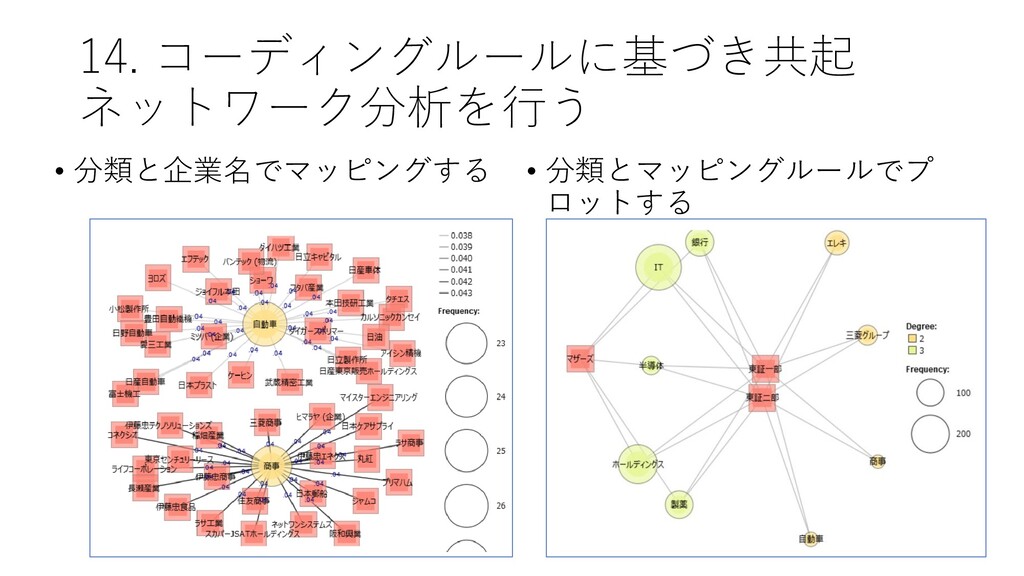{kind=link}
{kind=link}
{kind=link}
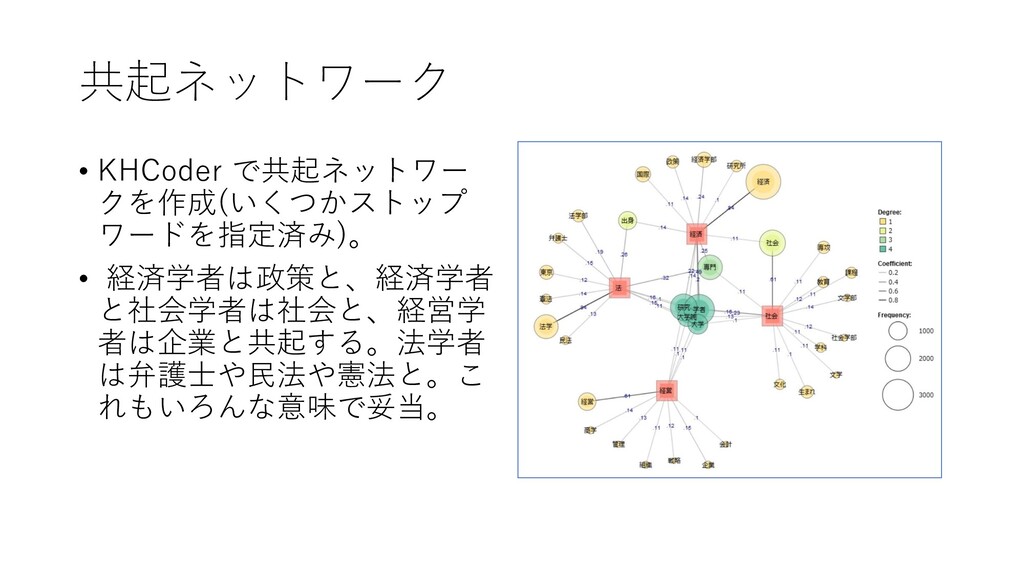{kind=link}
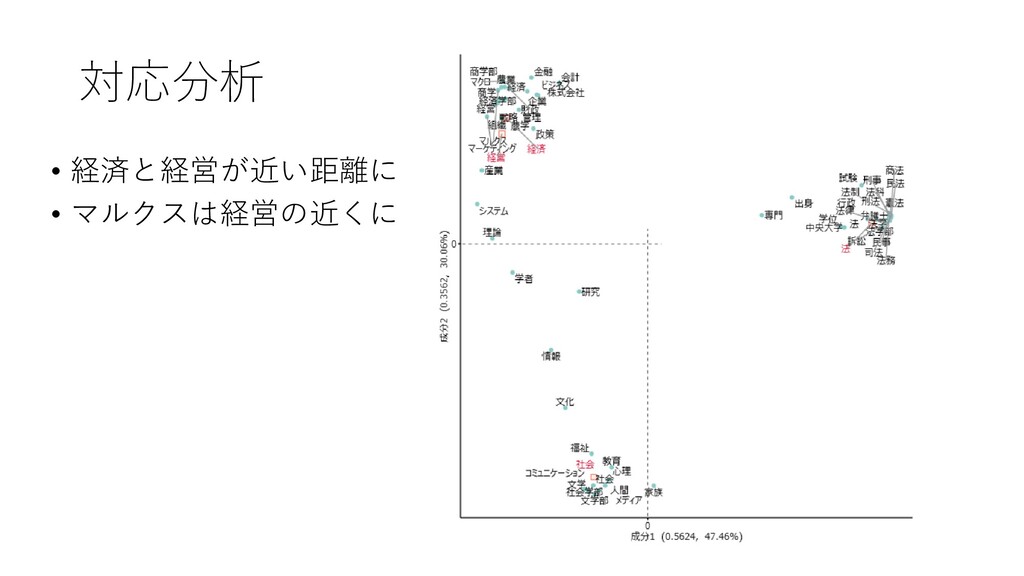{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/d983ca95477942ed9e071fa33dc27b1d/slide_141.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
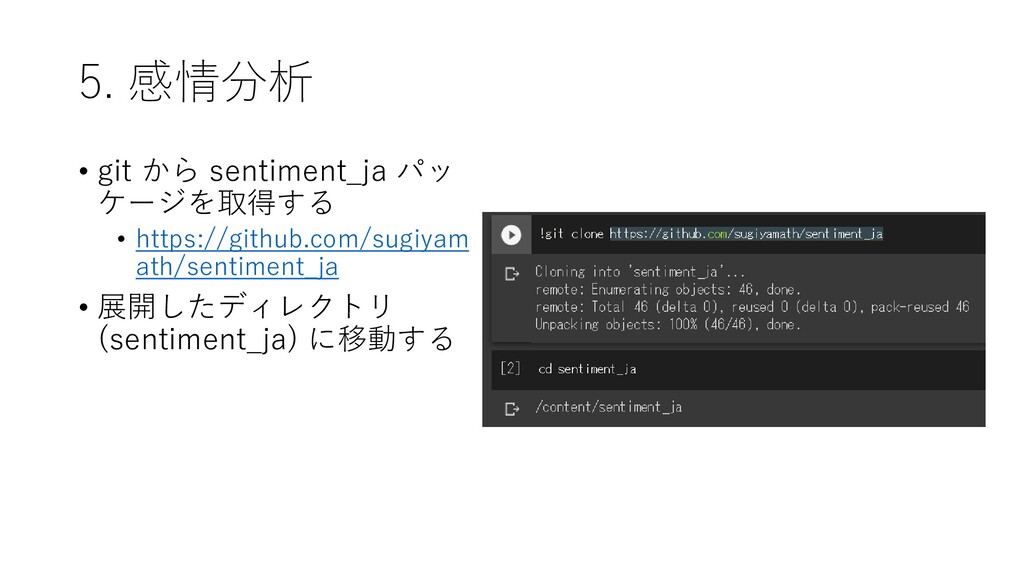{kind=link}
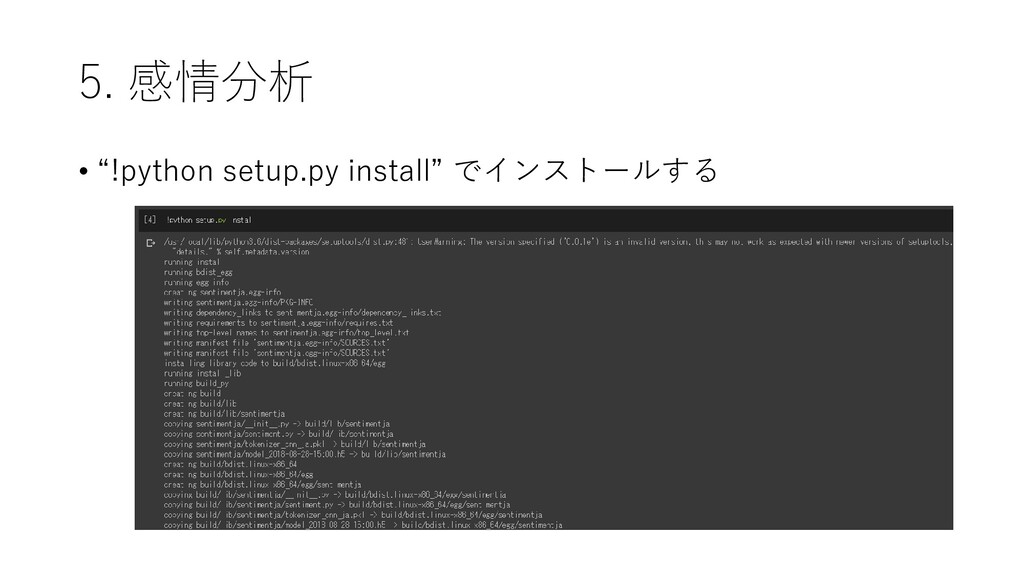{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}