OF TECHNOLOGY • 2000 • Exchange Student in Malaysia • 2002-2009 • CLARAONLINE, INC. • ICT Hosting Company, nowadays called Cloud system supplier • 2009-2015 • Institute of Innovation Research, HITOTSUBASHI UNIVERSITY • 2015-2017 • Science for RE-Designing Science, Technology and Innovation Policy Center, National Graduate Institute for Policy Studies (GRIPS) / NISTEP / Hitotsubashi UNIVERSITY/MANAGEMENT INNOVATION CENTER • 2018-2019 • EHESS Paris – CEAFJP/Michelin Research Fellow • OECD Expert Advisory Group: Digital Science and Innovation Policy and Governance (DSIP) and STI Policy Monitoring and Analysis (REITER) project • 2019- • TDB Center for Advanced Empirical Research on Enterprise and Economy, Faculty of Economics, Hitotsubashi University
![イノベーション研究経済学の ための実践的データ分析 α. 回帰分析をやってみよう 11号館 801教室 経済学研究科 原泰史 [email protected]](https://files.speakerdeck.com/presentations/914a0fbc09184896800e7efbf7c4f13c/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
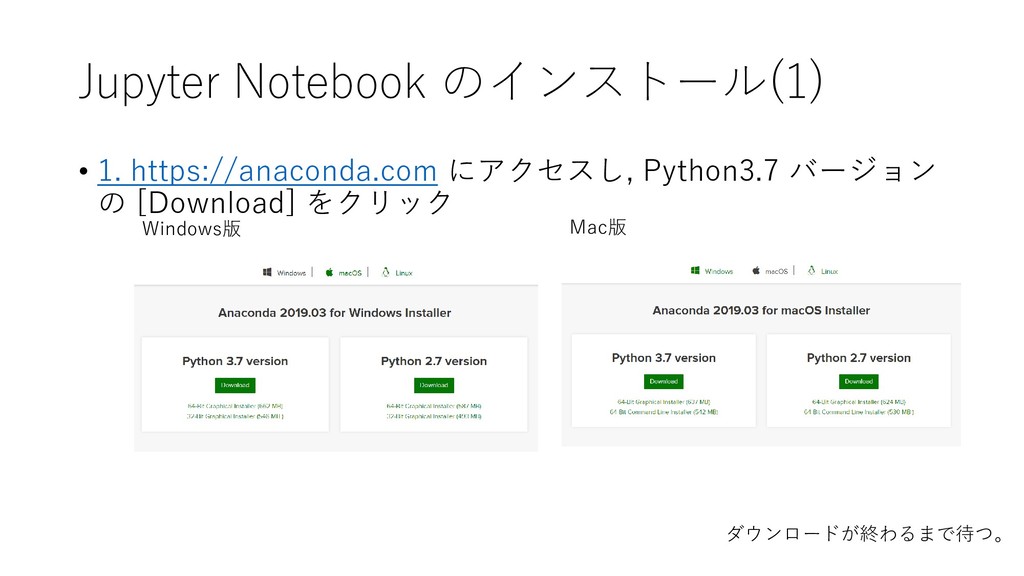
![Jupyter Notebook のインストール(1) • 2. [Download] をクリックする](https://files.speakerdeck.com/presentations/914a0fbc09184896800e7efbf7c4f13c/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
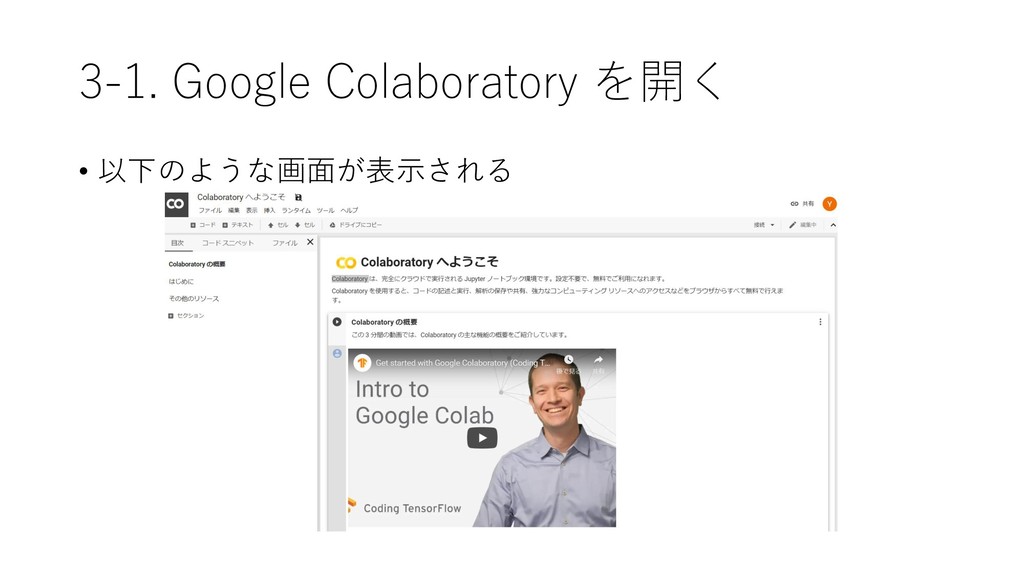{kind=link}
![3-2. 新しいnotebook を作成する • [ファイル]-[python3 の新しいノートブック] を選択する](https://files.speakerdeck.com/presentations/914a0fbc09184896800e7efbf7c4f13c/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
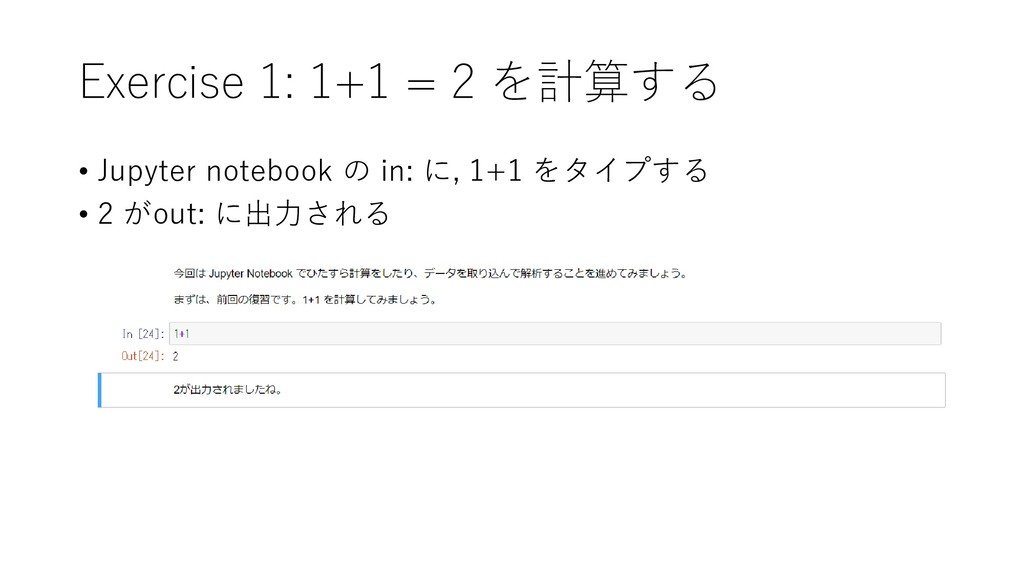{kind=link}
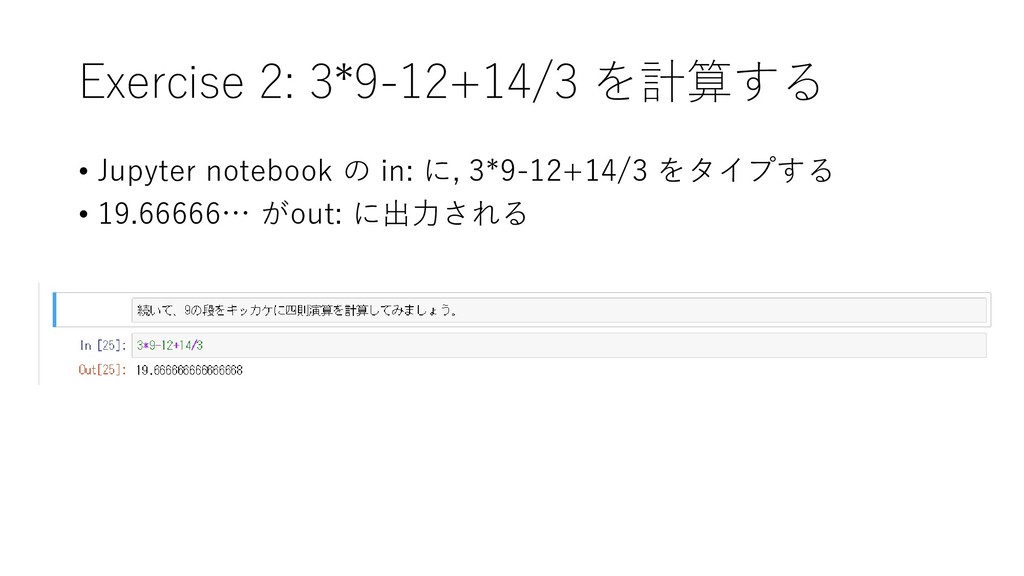{kind=link}
{kind=link}
{kind=link}
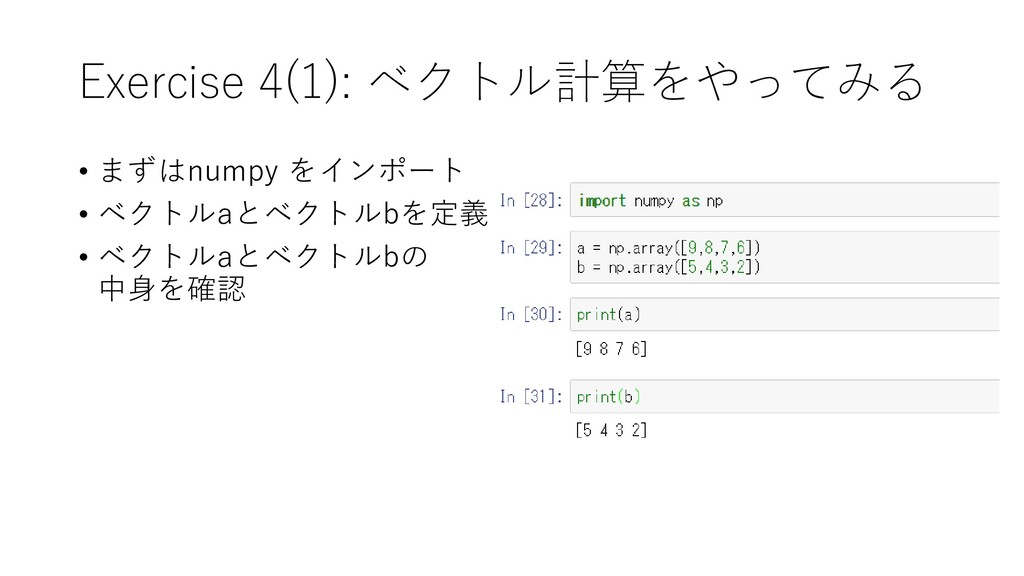{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
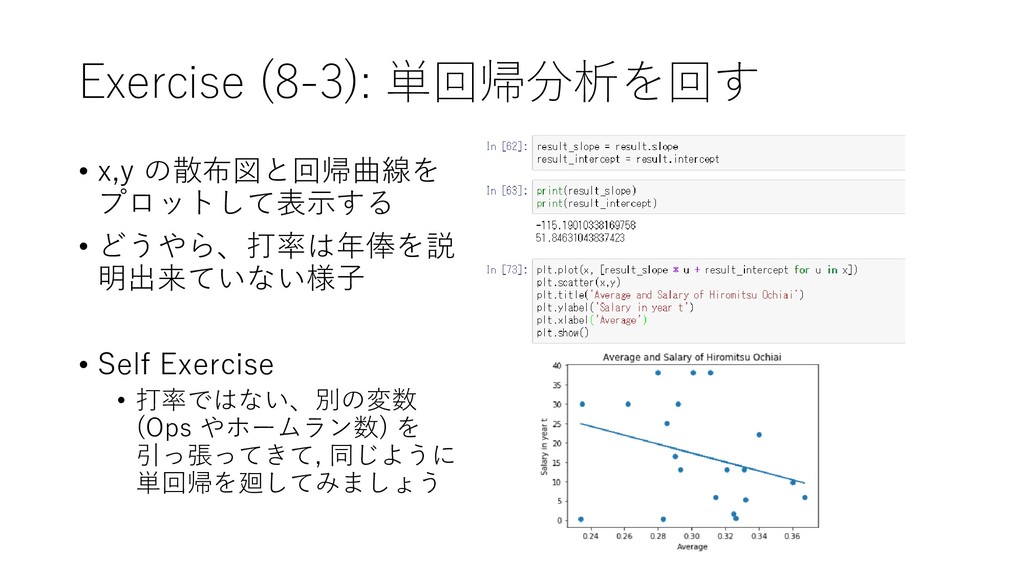{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
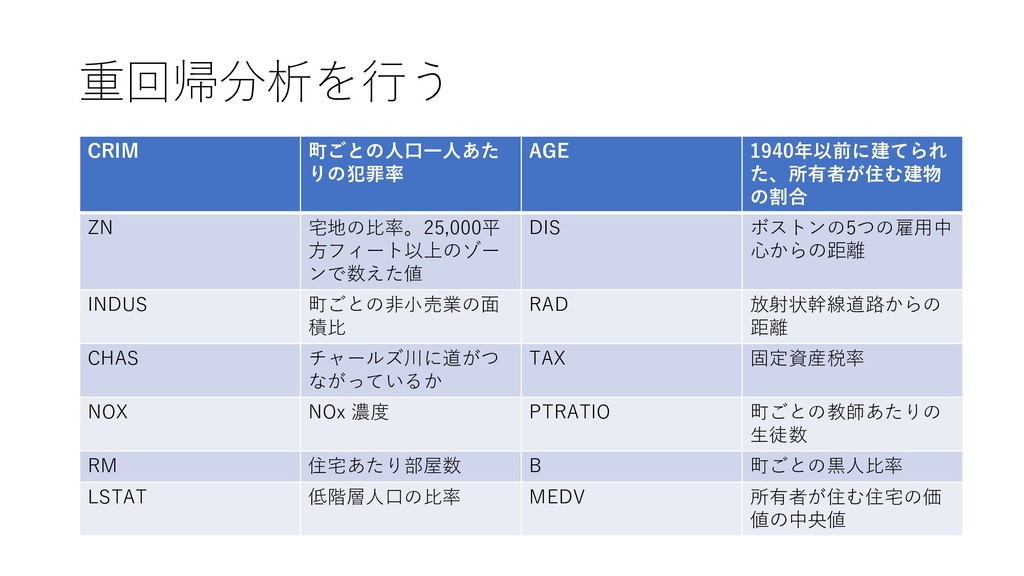{kind=link}
{kind=link}
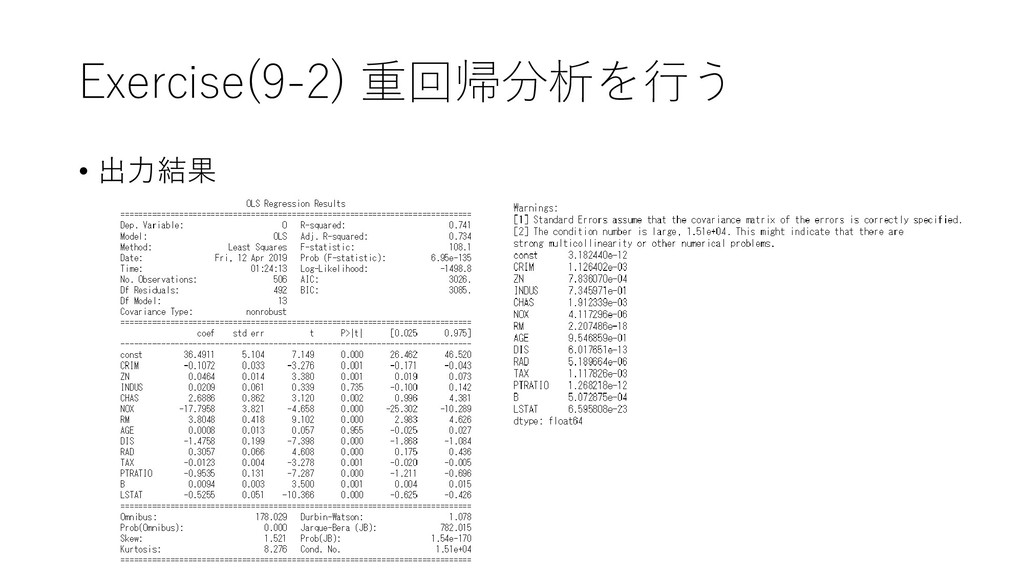{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
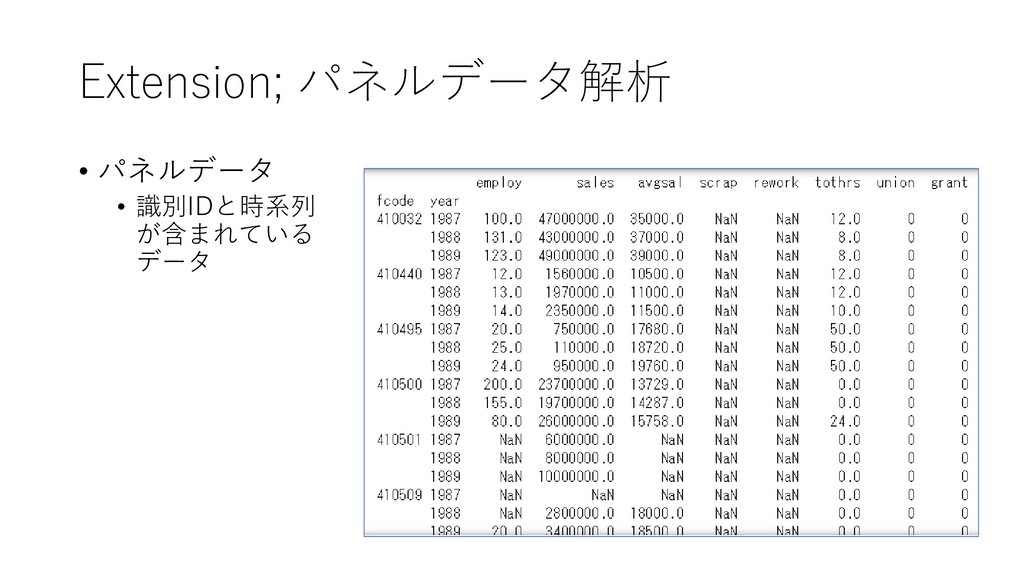{kind=link}
{kind=link}
{kind=link}
{kind=link}
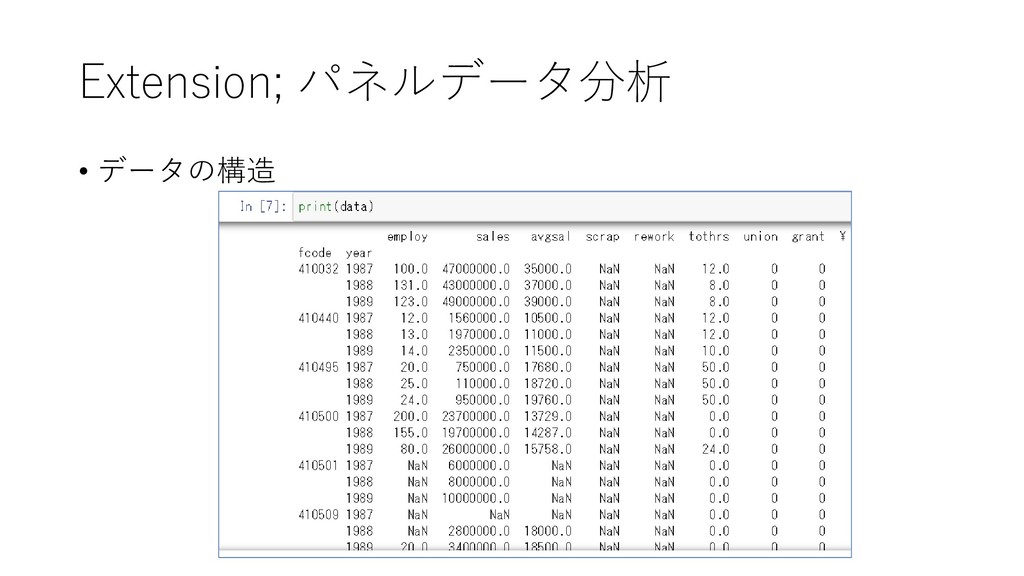{kind=link}
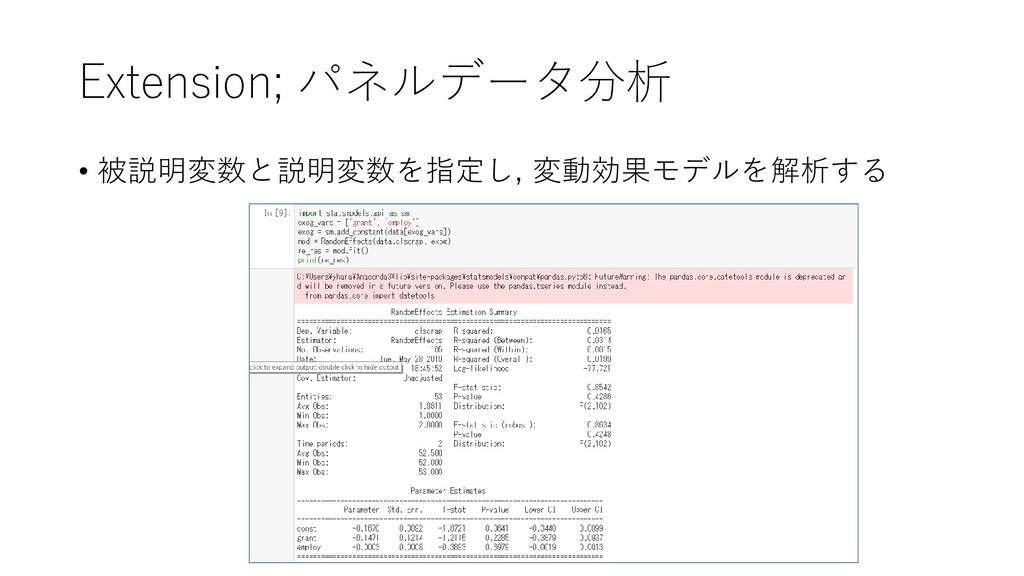{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
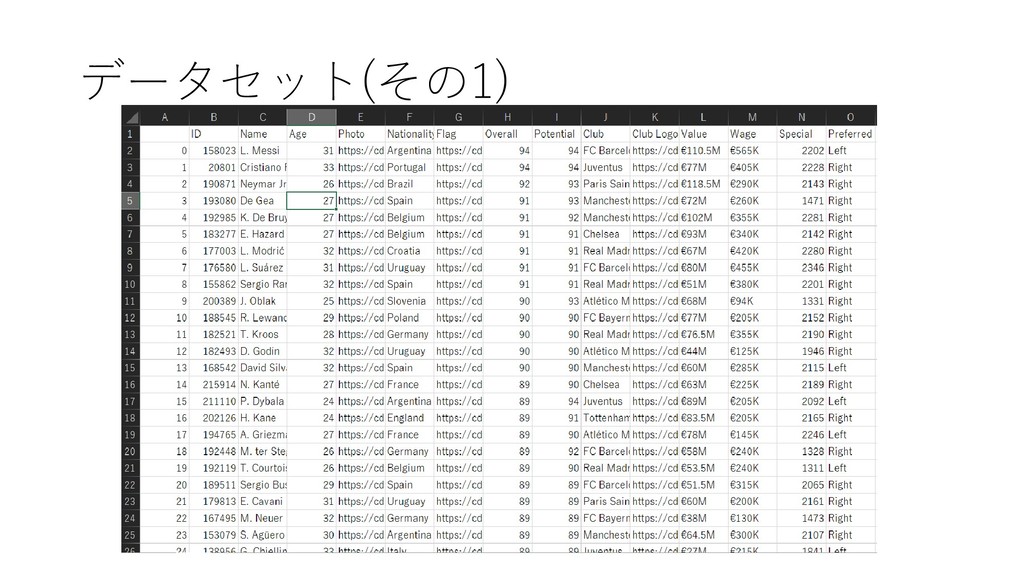{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Notebook の解説 やっていること ・説明変数と被説明変数をそれぞれの列か ら取り出す (.iloc [行, 列]で, 行を指定せず 列のみを指定する)](https://files.speakerdeck.com/presentations/914a0fbc09184896800e7efbf7c4f13c/slide_69.jpg){kind=link}
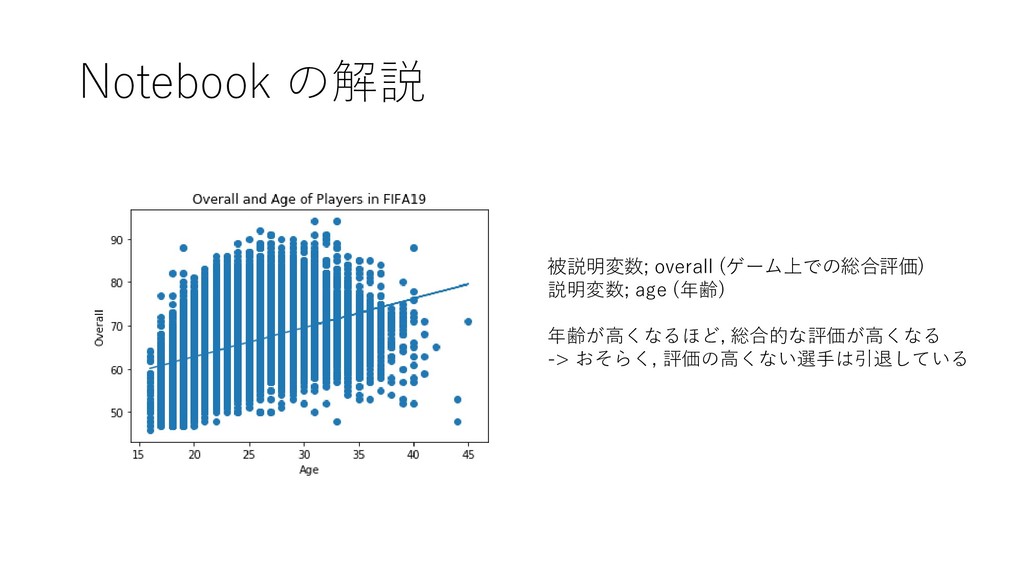{kind=link}
{kind=link}
{kind=link}
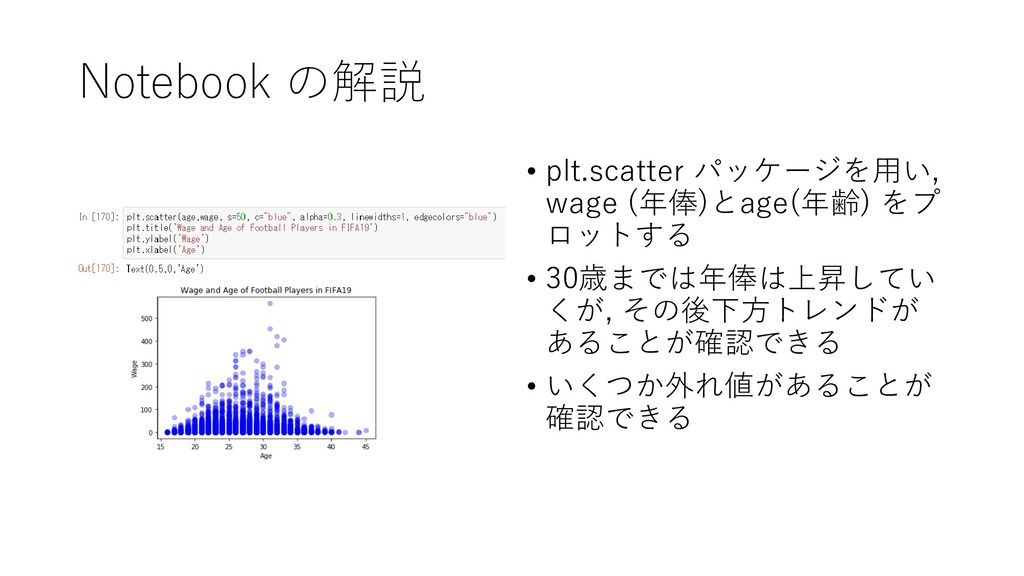{kind=link}
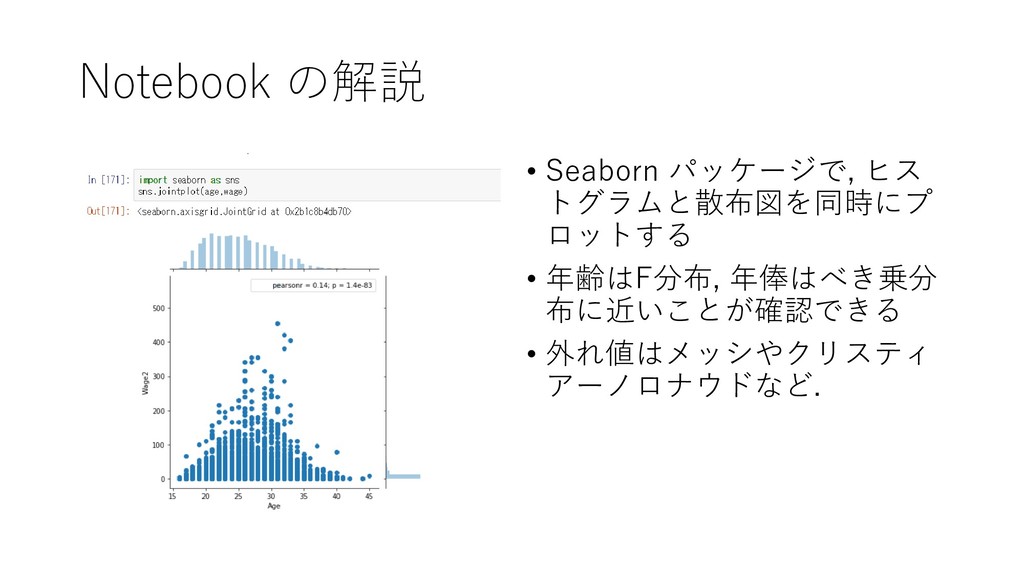{kind=link}
{kind=link}
{kind=link}
{kind=link}
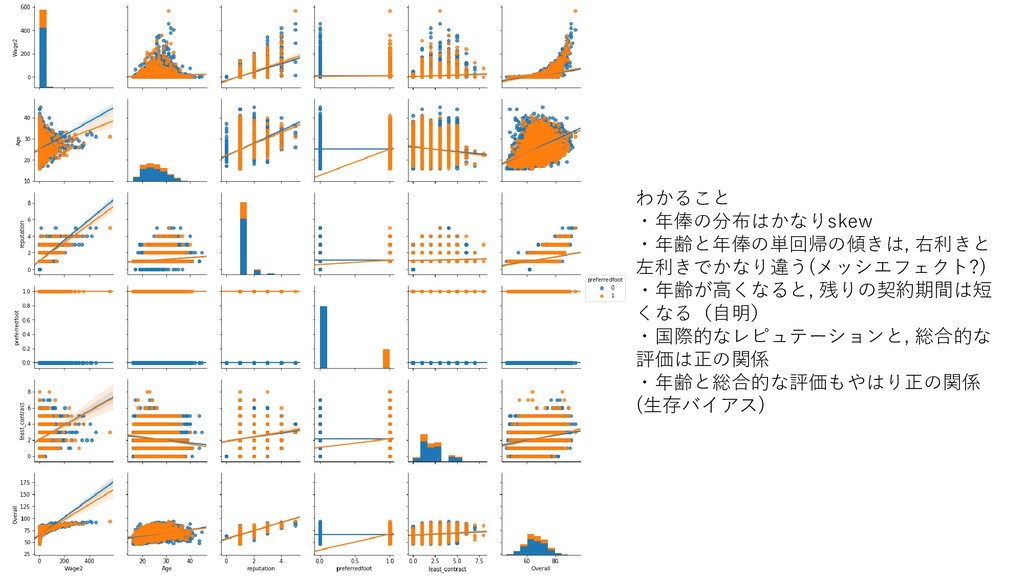{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/914a0fbc09184896800e7efbf7c4f13c/slide_82.jpg){kind=link}