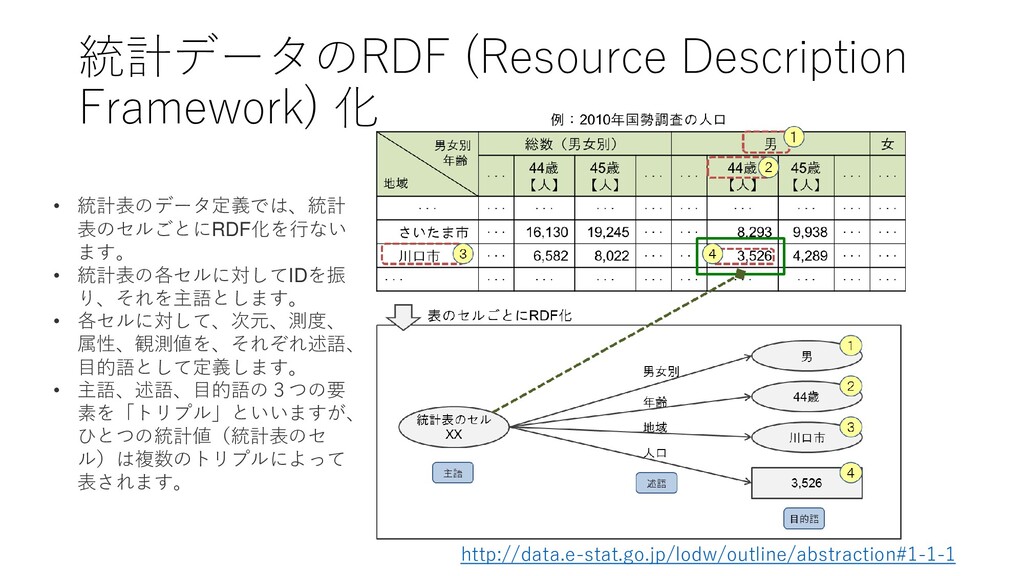
format) but with an open licence, to be Open Data ★★ Available as machine-readable structured data (e.g. excel instead of image scan of a table) ★★★ as (2) plus non-proprietary format (e.g. CSV instead of excel) ★★★★ All the above plus, Use open standards from W3C (RDF and SPARQL) to identify things, so that people can point at your stuff ★★★★★ All the above, plus: Link your data to other people’s data to provide context https://www.w3.org/DesignIssues/LinkedData.html https://5stardata.info/ja/
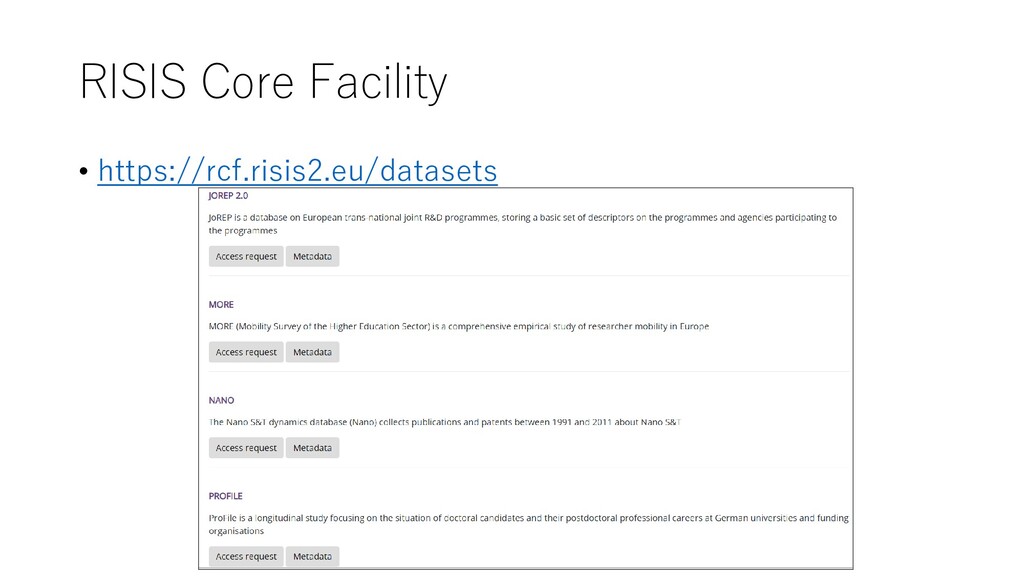
RISIS CORE FACILITY (RCF), is organised around 3 major dimensions and activities: • 1. A front end, focusing on users, the ways they access RISIS, work within RISIS and build RISIS user communities. At the core is the RISIS Core facility (WP4). The core facility supports virtual transnational access (WP8) and is accompanied by all the efforts we do to raise awareness, train researchers and interact with them (WP2) and to help them build active user communities (mobilising D4Science VRE, WP7). • 2. A service layer that helps users organise problem based integration of RISIS datasets (with possibilities to complement with their own datasets) – this entails the data integration and analysis services (WP5) and methodological support for advanced quantitative methods (WP6). • 3. A data layer that gathers the core RISIS datasets that we maintain (WP5) and enlarge (WP9), the datasets of interest for which we insure reliability and harmonisation for integration (WP4), and the new datasets that we develop and will progressively open (WP10). https://www.risis2.eu/project-description/
Data is such a dataset that is openly available for anyone to use for non-commercial research. The data was produced as a joint effort by the Institute for Geoinformatics, University of Muenster, Germany and the National Institute for Space Research (INPE) in Brazil. • The data can be accessed in a Linked Data fashion via a SPARQL-endpoint, and via dereferenciable URIs. The data consists of 8250 cells—each of size of 25 km * 25 km—capturing the observations of deforestation in the Brazilian Amazon Rainforest and a number of related and relevant variables. This spatiotemporal deforestation data was created using a number of aggregation methods from different sources. The data covers the whole Brazilian Amazon Rainforest. http://linkedscience.org/data/linked-brazilian-amazon-rainforest/
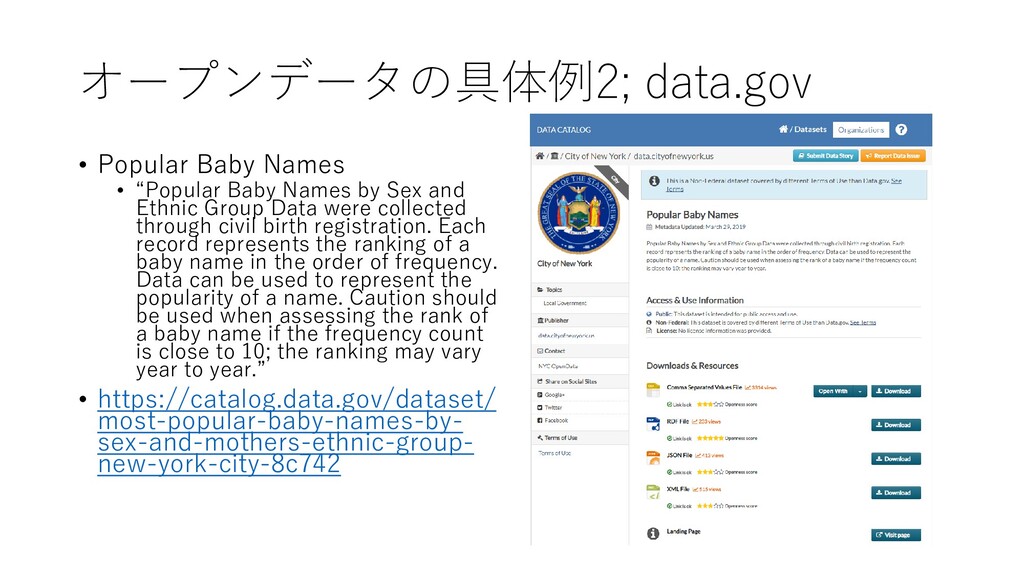
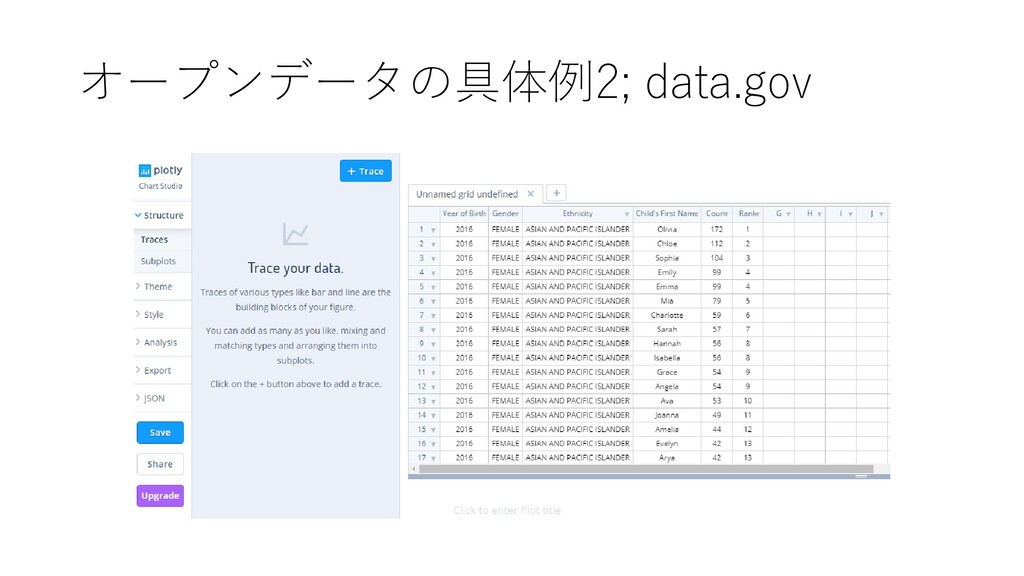
by Sex and Ethnic Group Data were collected through civil birth registration. Each record represents the ranking of a baby name in the order of frequency. Data can be used to represent the popularity of a name. Caution should be used when assessing the rank of a baby name if the frequency count is close to 10; the ranking may vary year to year.” • https://catalog.data.gov/dataset/ most-popular-baby-names-by- sex-and-mothers-ethnic-group- new-york-city-8c742
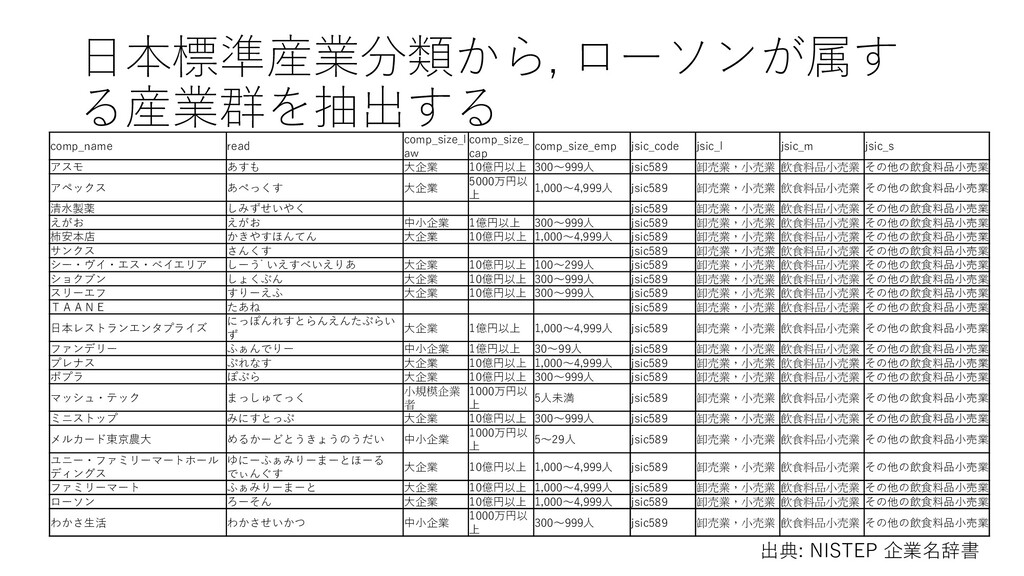
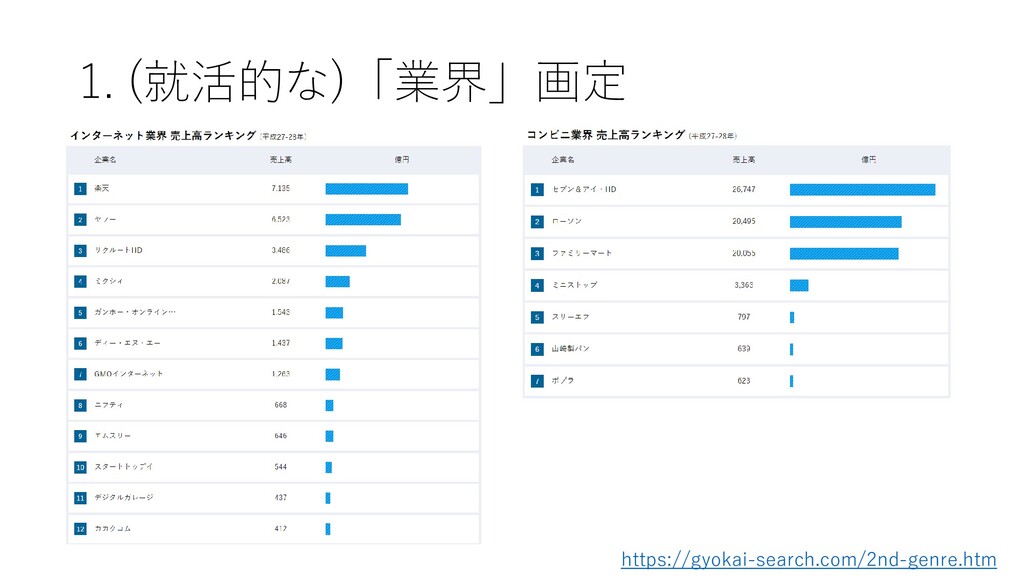
• D. 建設業 • E. 製造業 • F. 電気・ガス・熱供給・水道業 • G. 情報通信業 • H. 運輸業,郵便業 • I. 卸売業,小売業 • J. 金融業,保険業 • K. 不動産業,物品賃貸業 • L. 学術研究,専門・技術サービス業 • M. 宿泊業,飲食サービス業 • N. 生活関連サービス業,娯楽業 • O. 教育,学習支援業 • P. 医療,福祉 • Q. 複合サービス事業 • R. サービス業(他に分類されないもの) • S. 公務(他に分類されるものを除く) • T. 分類不能の産業 http://www.soumu.go.jp/toukei_toukatsu/index/seido/ sangyo/02toukatsu01_03000022.html
Research Data contains the output of much of the data analysis work used in Google Patents (patents.google.com), including machine translations of titles and abstracts from Google Translate, embedding vectors, extracted top terms, similar documents, and forward references.”
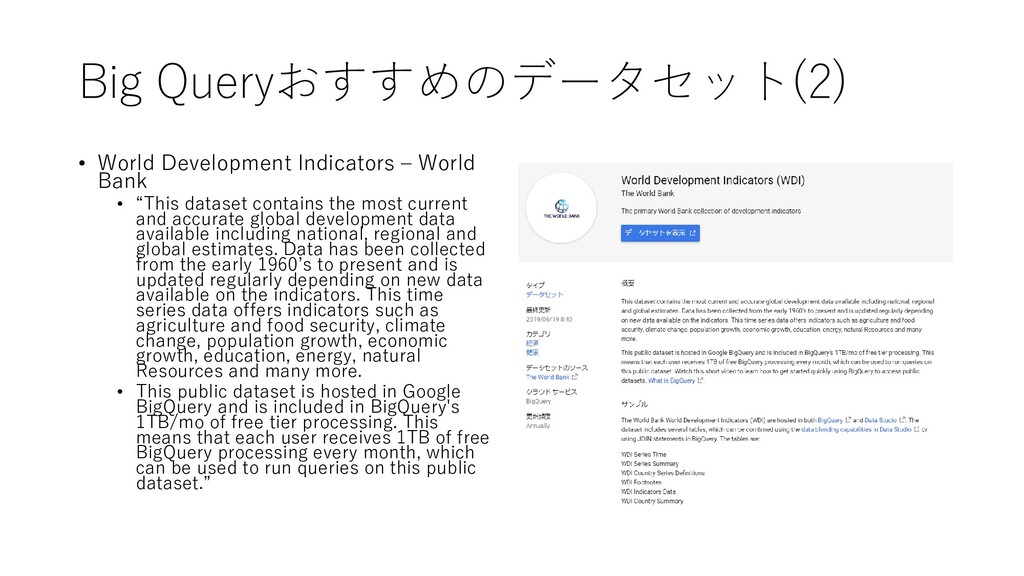
“This dataset contains the most current and accurate global development data available including national, regional and global estimates. Data has been collected from the early 1960’s to present and is updated regularly depending on new data available on the indicators. This time series data offers indicators such as agriculture and food security, climate change, population growth, economic growth, education, energy, natural Resources and many more. • This public dataset is hosted in Google BigQuery and is included in BigQuery's 1TB/mo of free tier processing. This means that each user receives 1TB of free BigQuery processing every month, which can be used to run queries on this public dataset.”
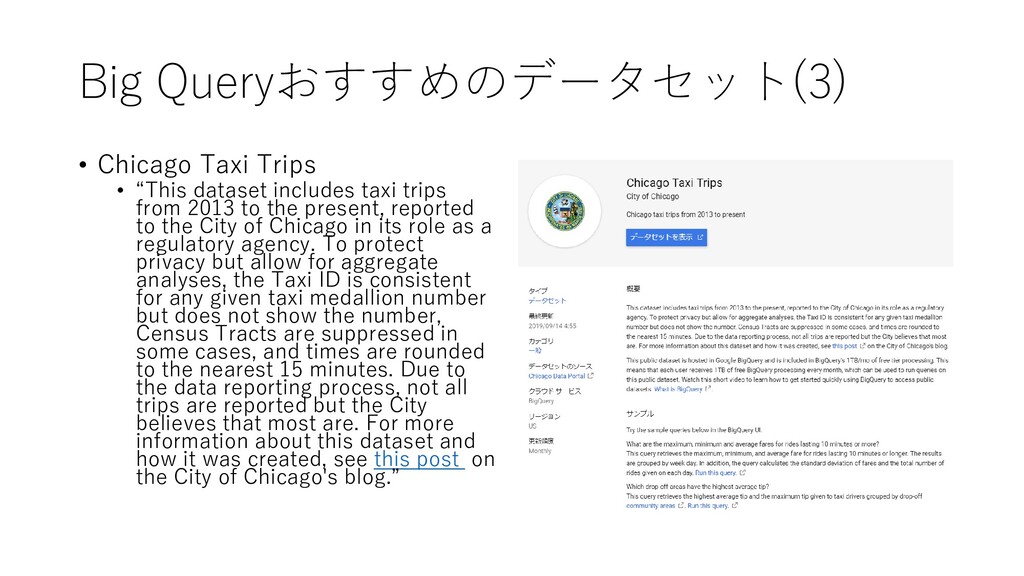
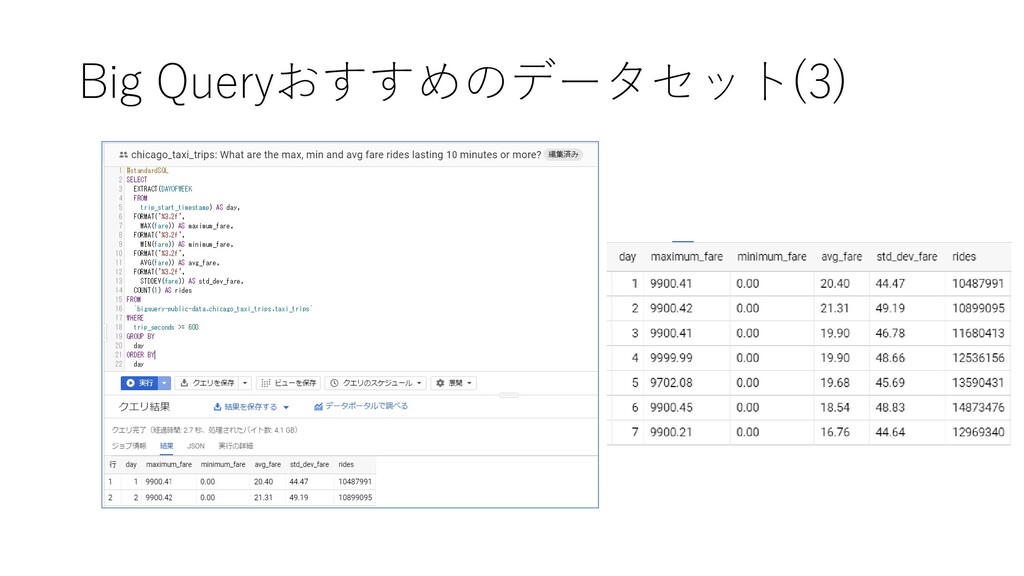
taxi trips from 2013 to the present, reported to the City of Chicago in its role as a regulatory agency. To protect privacy but allow for aggregate analyses, the Taxi ID is consistent for any given taxi medallion number but does not show the number, Census Tracts are suppressed in some cases, and times are rounded to the nearest 15 minutes. Due to the data reporting process, not all trips are reported but the City believes that most are. For more information about this dataset and how it was created, see this post on the City of Chicago's blog.”
{kind=link}
{kind=link}
{kind=link}
![今日の内容; Open Linked Data の活用 (RDF, RISIS などの事例紹介および試用) [座学、実 習]](https://files.speakerdeck.com/presentations/15fc9991c9b3414eb5d727c6033e8952/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/15fc9991c9b3414eb5d727c6033e8952/slide_120.jpg){kind=link}