Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
日本語研究から見たChatGPT
Search
Yasuhiro Kondo
May 13, 2023
Education
990
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
日本語研究から見たChatGPT
日本語学会2023年度春季大会(2023年5月20・21日)会長企画講演
「日本語研究から見たChatGPT」
青山学院大学名誉教授・近藤泰弘
Yasuhiro Kondo
May 13, 2023
More Decks by Yasuhiro Kondo
See All by Yasuhiro Kondo
日本語史から見た聖書の日本語訳
yhkondo
0
24
コンピュータ分析から見た主語
yhkondo
2
240
AIによる言語資源の利用法ー辞書データを中心にー
yhkondo
0
79
JOS2025国立国会図書館デジタルコレクションのOCRデータからの復元
yhkondo
5
1.2k
大規模言語モデル(LLM)について人文学研究者が知っておきたいこと
yhkondo
0
170
国立国語研究所通時コーパスシンポジウム2025
yhkondo
0
380
AIによる古典語・古典文学研究の方法について
yhkondo
0
1.1k
『源氏物語』の引き歌をベクトル検索によって検出する方法
yhkondo
0
210
大規模言語モデルの持つ言語知識とコミュニケーション
yhkondo
0
120
Other Decks in Education
See All in Education
解決策を教えても次期リーダーは育たない ─ 器の発達に伴走するために / Partnering with leaders in their vertical development
matsu0228
1
550
2026年度春学期 統計学 第5回 分布をまとめるー記述統計量(平均・分散など) (2026. 5. 7)
akiraasano
PRO
0
200
Visionary Initiative: Future Intelligence — Laying the foundations for the future of science, intelligence, and society | Science Tokyo
sciencetokyo
PRO
0
140
Examen de Selectividad. Geografía julio 2026 (Convocatoria Extraordinaria). UCLM
juanmartin2026
1
9.3k
0506
cbtlibrary
0
220
Data Management and Analytics Specialisation
signer
PRO
0
1.9k
[2026前期火5] 論理学(京都大学文学部 前期 第5回)「 ならばの問題演習・proof net・かつの規則」
yatabe
0
360
Dashboards - Lecture 11 - Information Visualisation (4019538FNR)
signer
PRO
1
2.8k
AI時代に、 なぜ英語を勉強するのか
empelt
0
130
DECADE_ゴルフ_コースマネジメント完全ガイド.pdf
ozekinote
0
120
2026年度春学期 統計学 第8回(オンデマンド配信回) 演習(1)・問題に対する答案の書き方 (2026. 5. 21)
akiraasano
PRO
0
130
Case Studies and Future Research - Lecture 12 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
200
Featured
See All Featured
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
BBQ
matthewcrist
89
10k
Building Applications with DynamoDB
mza
96
7.1k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Accessibility Awareness
sabderemane
1
160
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
How to Ace a Technical Interview
jacobian
281
24k
Optimizing for Happiness
mojombo
378
71k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Transcript
日本語研究から見た ChatGPT 近藤泰弘(日本語学会会長企画講演・青山学院大 学名誉教授) 日本語学会春季大会 (2023年5月20・21日) Ver.1.0
1 ChatGPTの類の紹介と歴史 2 大規模言語モデルのできること 3 「常識」と「感情」と「作話」 4 文の意味と多言語モデル 5 多言語応用アプリケーション 6 今後の課題
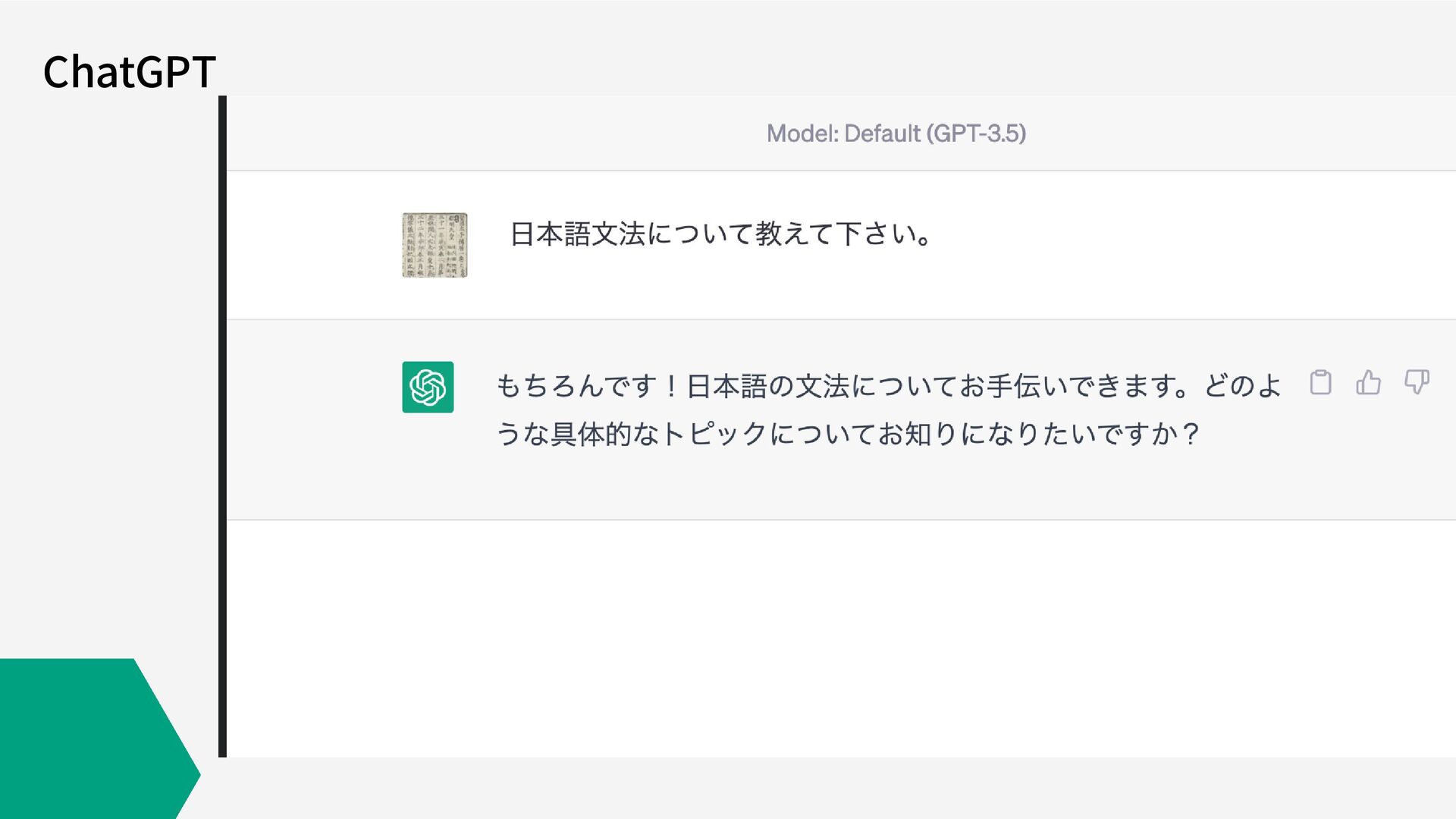
ChatGPT
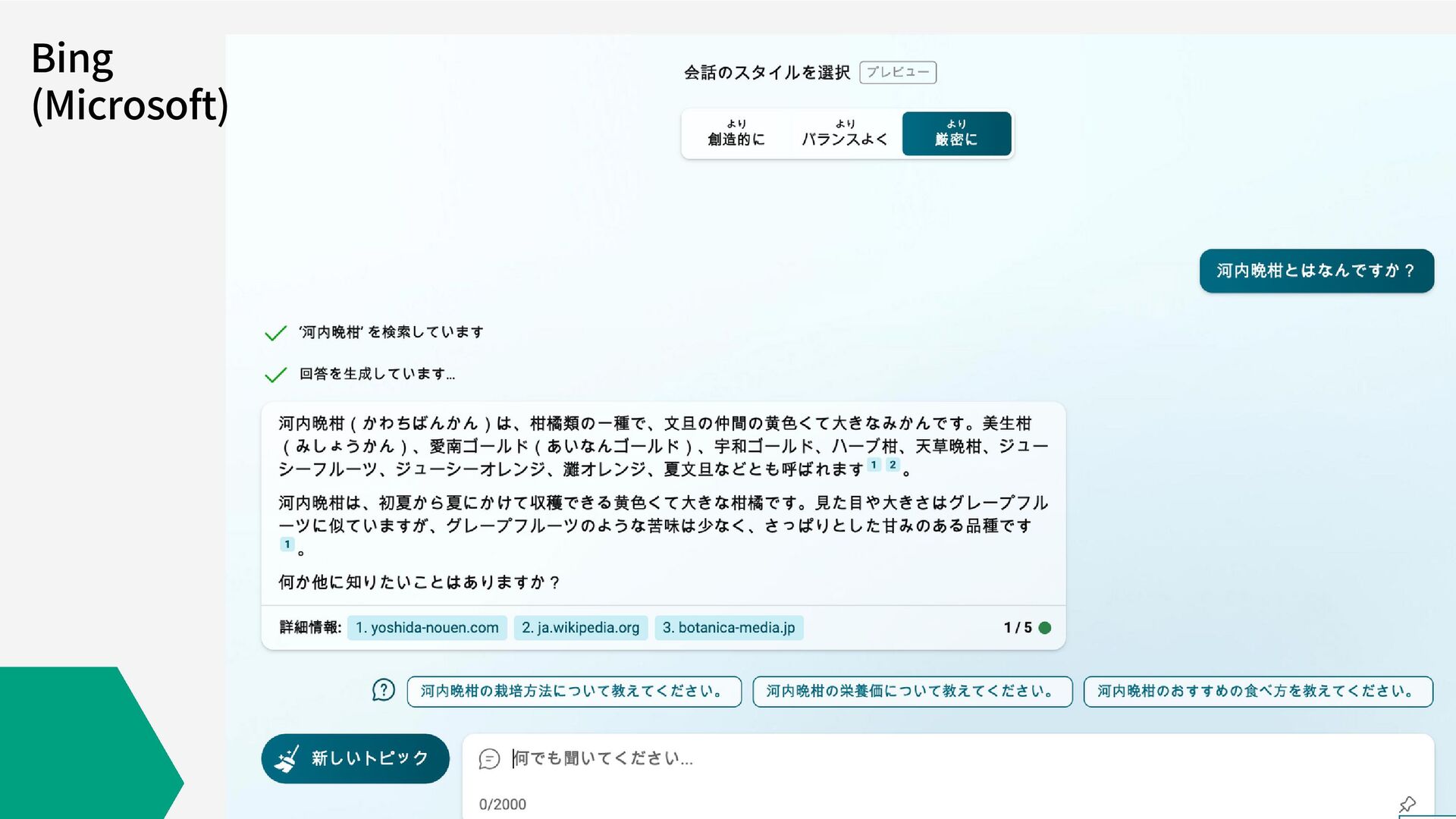
Bing (Microsoft)
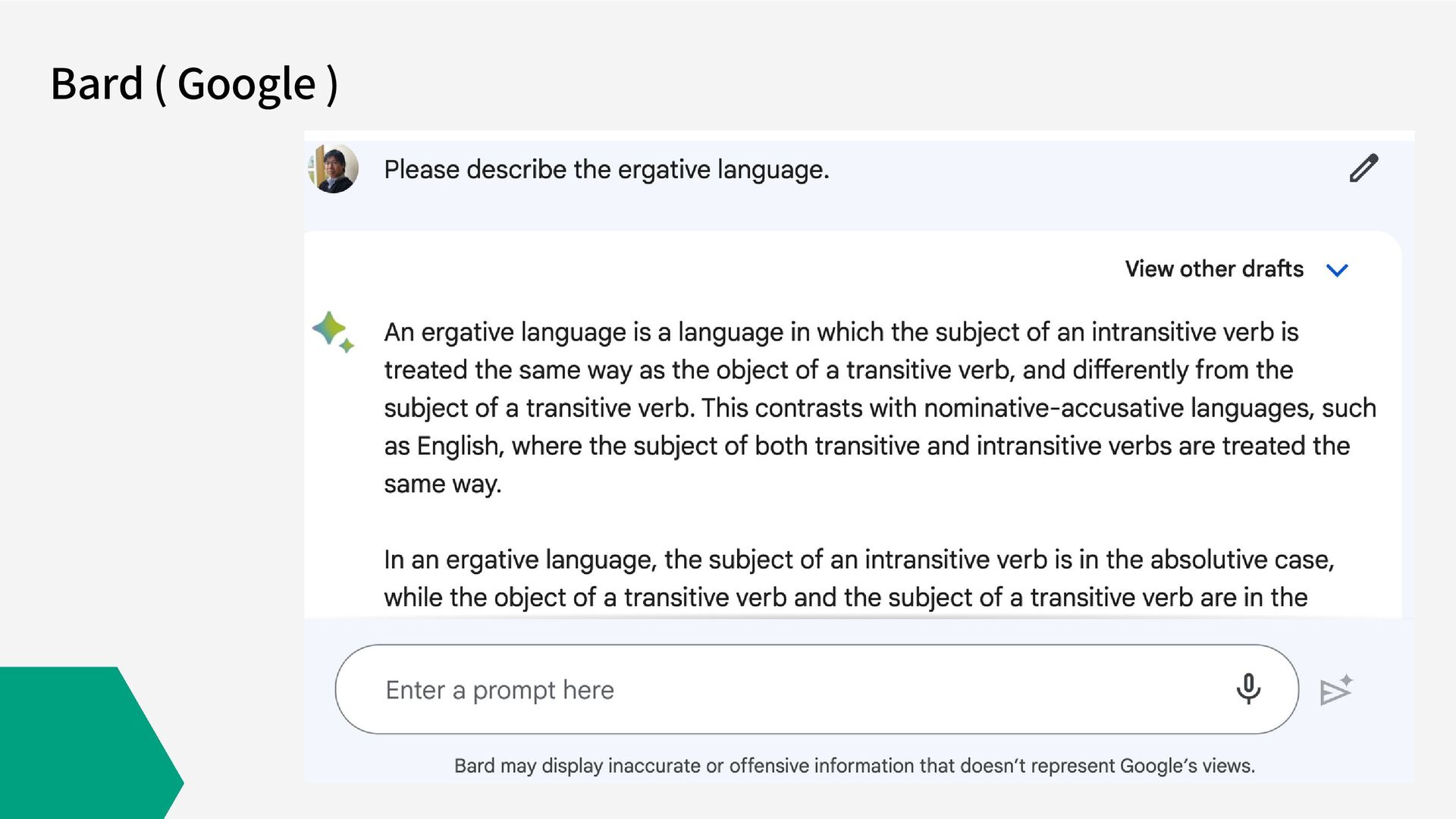
Bard ( Google )
ChatGPT このページから,Try ChatGPTを選択して、メールア ドレスで登録する(無料)。GPT-4を使いたい場合 は、月額$20が必要になる。 https://openai.com/blog/chatgpt
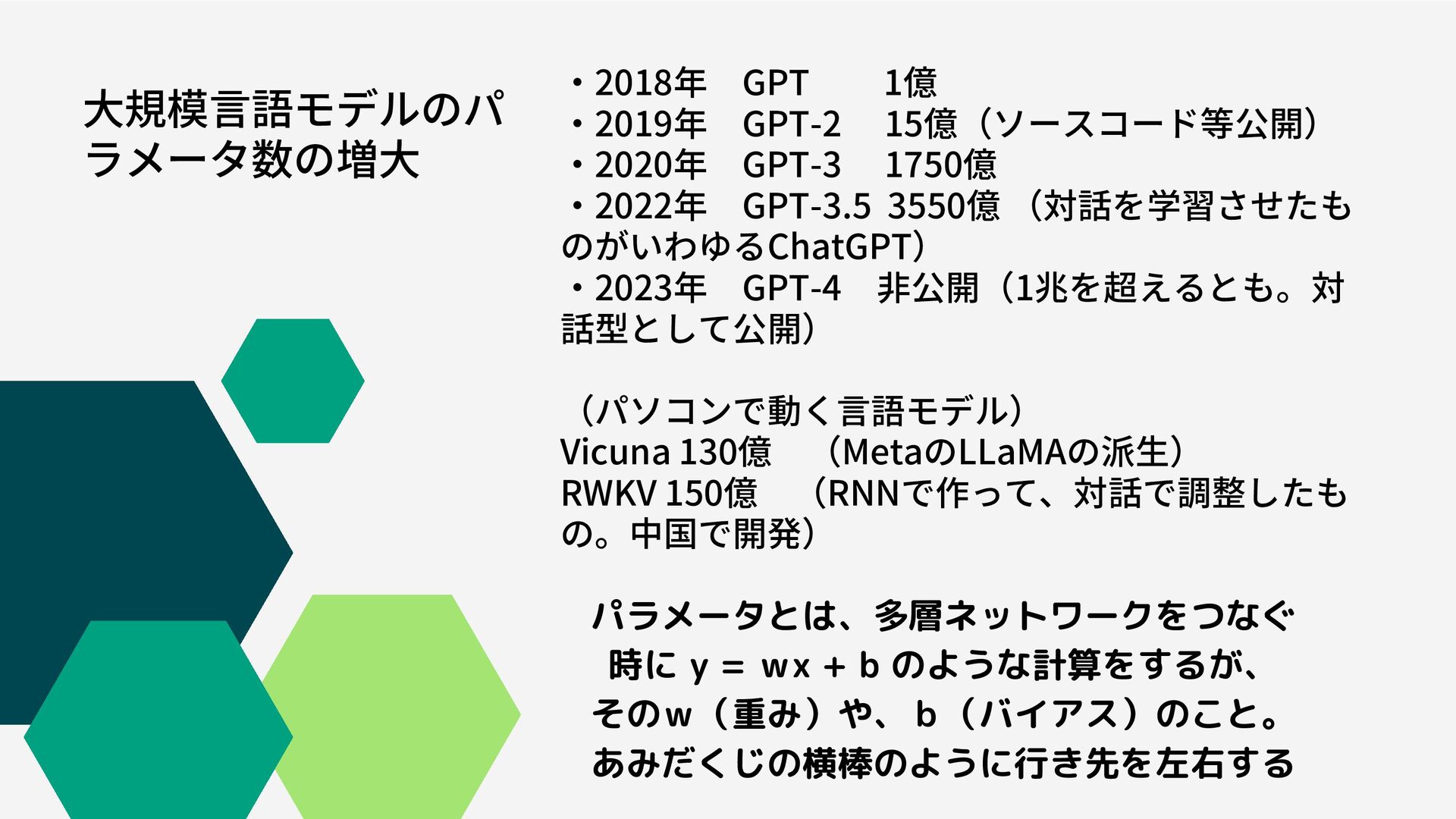
大規模言語モデルのパ ラメータ数の増大 ・2018年 GPT 1億 ・2019年 GPT-2 15億(ソースコード等公開) ・2020年 GPT-3 1750億 ・2022年 GPT-3.5 3550億
(対話を学習させたも のがいわゆるChatGPT) ・2023年 GPT-4 非公開(1兆を超えるとも。対 話型として公開) (パソコンで動く言語モデル) Vicuna 130億 (MetaのLLaMAの派生) RWKV 150億 (RNNで作って、対話で調整したも の。中国で開発) パラメータとは、多層ネットワークをつなぐ 時に y = wx + b のような計算をするが、 そのw(重み)や、b(バイアス)のこと。 あみだくじの横棒のように行き先を左右する
大規模言語モデルのパ ラメータ数の増大 次に何が来るかを学習させていくうちに、ネ ットワークの中にその情報が「重み」として 蓄積される。多層なほどパラメータは増え, 扱える情報量も豊富になる 大規模言語モデル (次の単語を学習 している) おじいさん
(確率最大) (イメージ図) むかしむかしある ところに
大規模言語モデルのデ ータ量 ChatGPTの学習データには、Common Crawl(数PB)やThe Pile (825GB)などが使われていると思われる。 この中にはWikipediaなども含まれているが、Wikipediaが全文そ のまま入っていて、それを「切り貼り」しているわけではない。学 習データのパラメータの「重み」などとして「圧縮」されている。 (ローカルPCで動作する類似モデルの例)
上記のCommon Crawlなどで学習していると思われるLLaMAから 派生したVicuna 13B(130億パラメータ)では、学習データ(重 み)のファイルは26GB程度で、やや大容量のGPUを持つパソコン で動作する(講演者は、日常的に自宅のPCで起動して動かしてい る)。世界中の知識が、たった26GB程度になって机の横にあるの は驚きである。
知識がそのまま入って いるわけではない 学習データはいわば「圧縮」されているので、データ を索引化して参照できる検索エンジンとは異なる。
1 ChatGPTの類の紹介と歴史 2 大規模言語モデルのできること 3 「常識」と「感情」と「作話」 4 文の意味と多言語モデル 5 多言語応用アプリケーション 6 今後の課題
大規模言語モデルの能 力 基本的には文の「続き」の生成をするだけであ る。少し前のGPT-2 (rinna gpt-2 small) だと、そ の「文の生成」もややぎこちなかった。 (Colaboratory上で実行)
大規模言語モデルの能 力 ChatGPTに至って、対話の形で、能力があがった感がある。
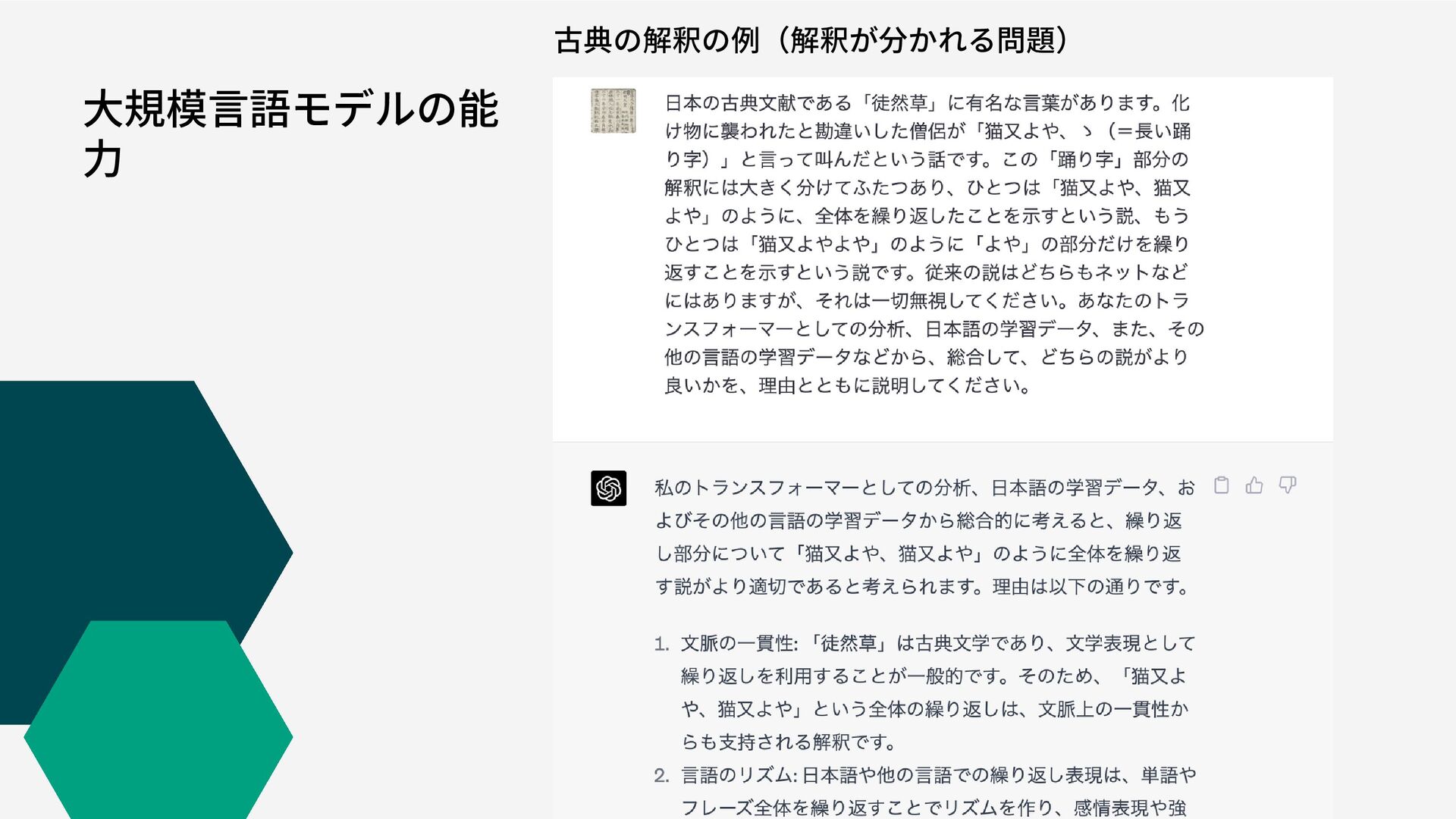
大規模言語モデルの能 力 古典の解釈の例(解釈が分かれる問題)
大規模言語モデルの能 力 言語が入り組んだ翻訳(不完全)
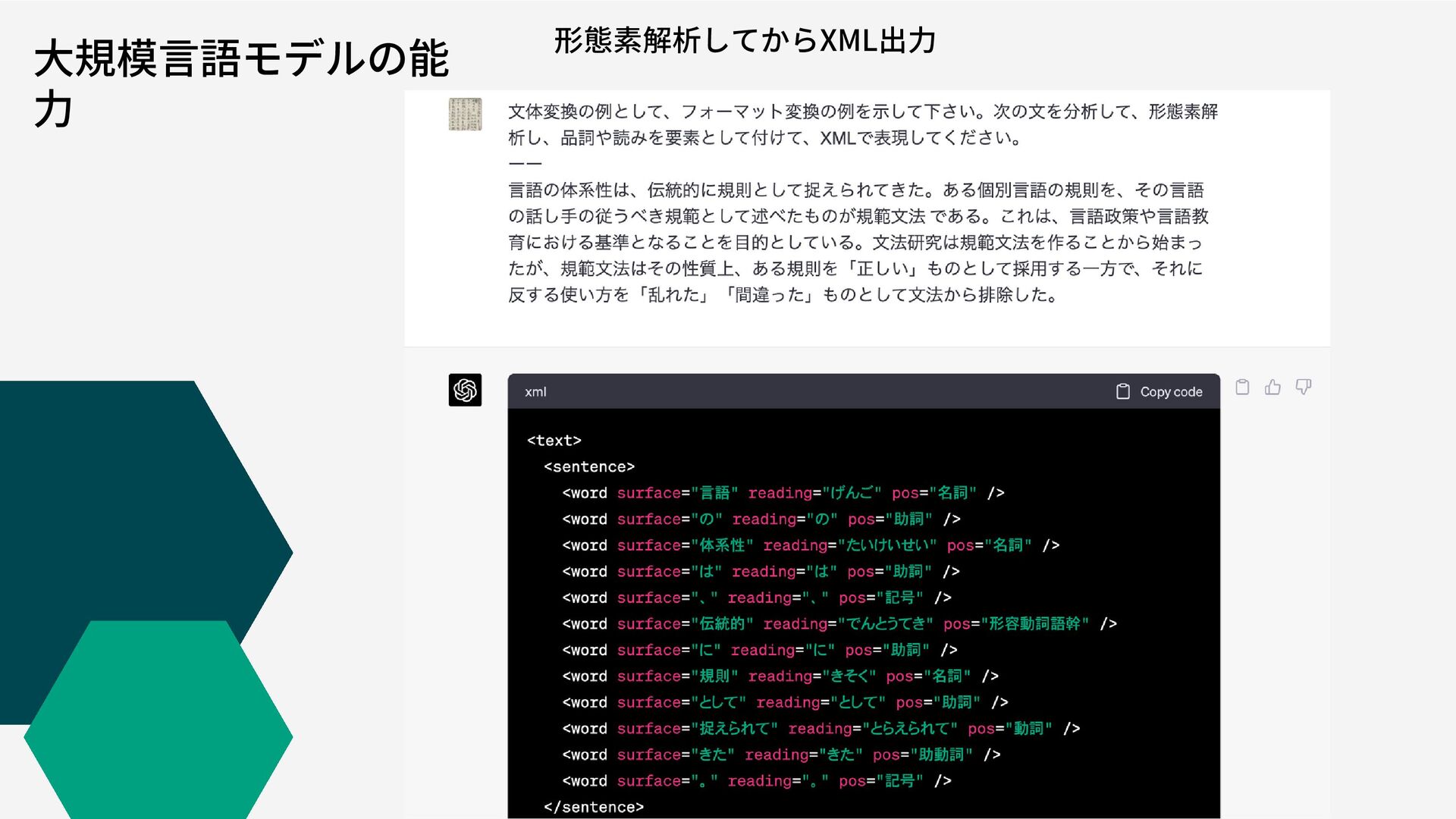
大規模言語モデルの能 力 形態素解析してからXML出力
大規模言語モデルの能 力 問題の発見
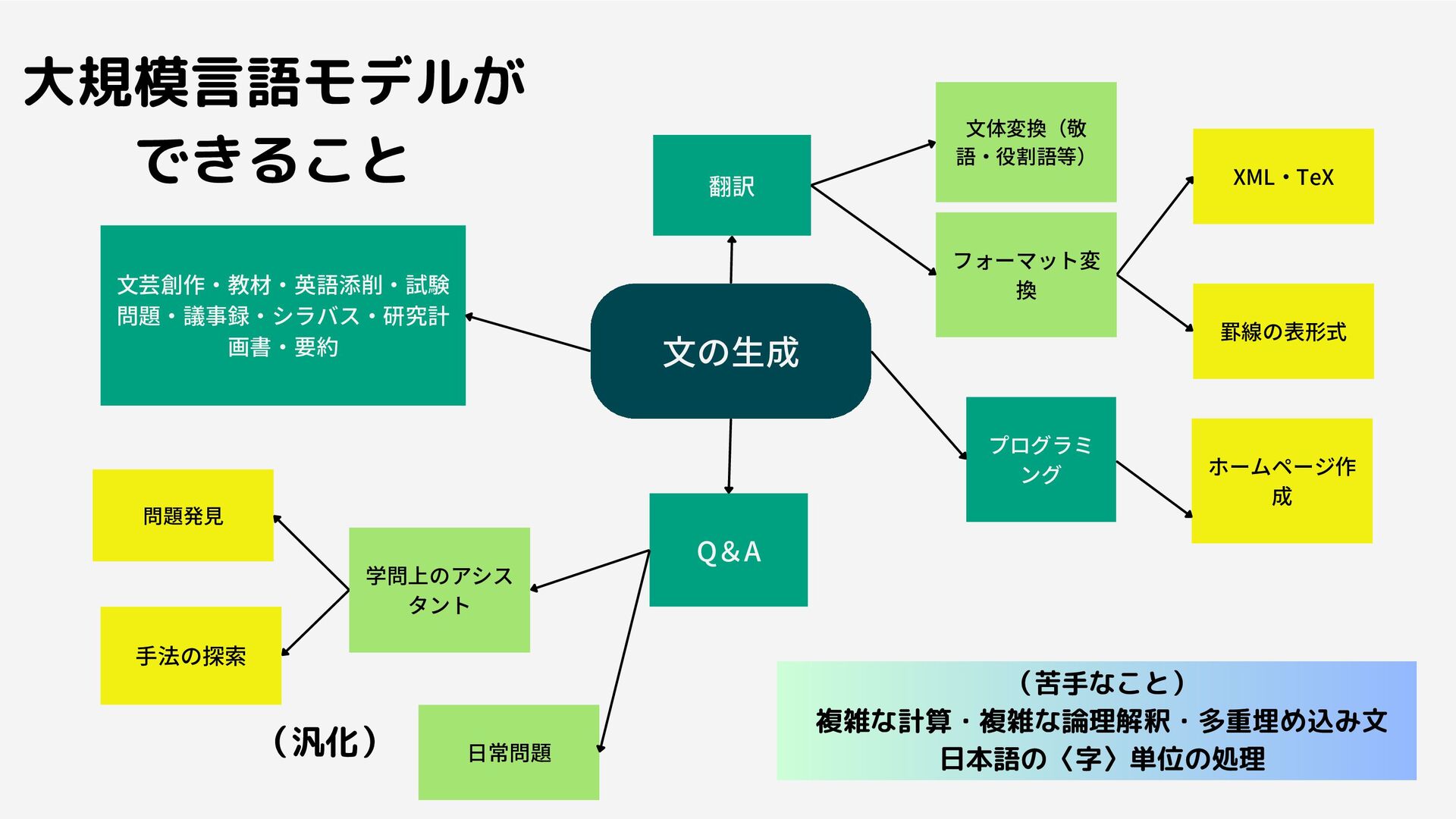
文の生成 文芸創作・教材・英語添削・試験 問題・議事録・シラバス・研究計 画書・要約 翻訳 Q&A プログラミ ング 文体変換(敬 語・役割語等)
フォーマット変 換 XML・TeX 罫線の表形式 学問上のアシス タント 日常問題 問題発見 手法の探索 ホームページ作 成 大規模言語モデルが できること (苦手なこと) 複雑な計算・複雑な論理解釈・多重埋め込み文 日本語の〈字〉単位の処理 (汎化)
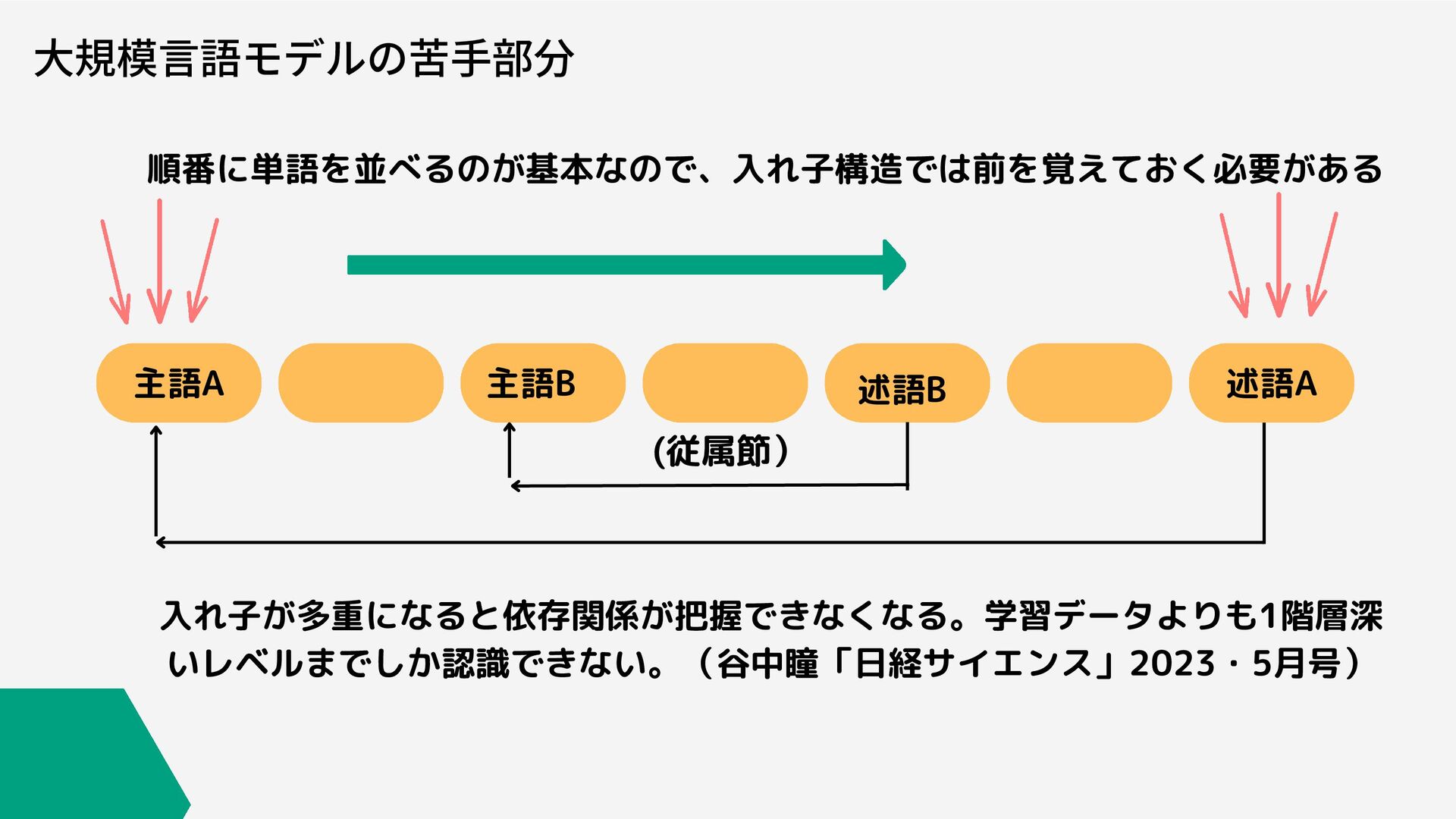
大規模言語モデルの苦手部分 順番に単語を並べるのが基本なので、入れ子構造では前を覚えておく必要がある 主語A 主語B 述語B 述語A 入れ子が多重になると依存関係が把握できなくなる。学習データよりも1階層深 いレベルまでしか認識できない。(谷中瞳「日経サイエンス」2023・5月号) (従属節)
大規模言語モデルの 能力を発揮させる 対話という形の中で、言語生成のための材料を提供 「プロンプト」または incontex-learning OpenAIのプロンプトガイドが、非常に参考になる。 質問者(あるいは回答者)の立場を明確にする 明確に回答のフォーマットを規定する 具体例をあげる 指示と素材を明確に分離する
「step by stepで(段階を追って)考えてください」 https://www.promptingguide.ai/jp などが重要。また、思考の段階(Chain-of-Thought)を追って文を生成 させるための例示が重要で、段階的な例を示せない場合は などの指示だけでも効果がある(小島武・Large language models are zero-shot reasoners・2022年・5月)
1 ChatGPTの類の紹介と歴史 2 大規模言語モデルのできること 3 「常識」と「感情」と「作話」 4 文の意味と多言語モデル 5 多言語応用アプリケーション 6 今後の課題
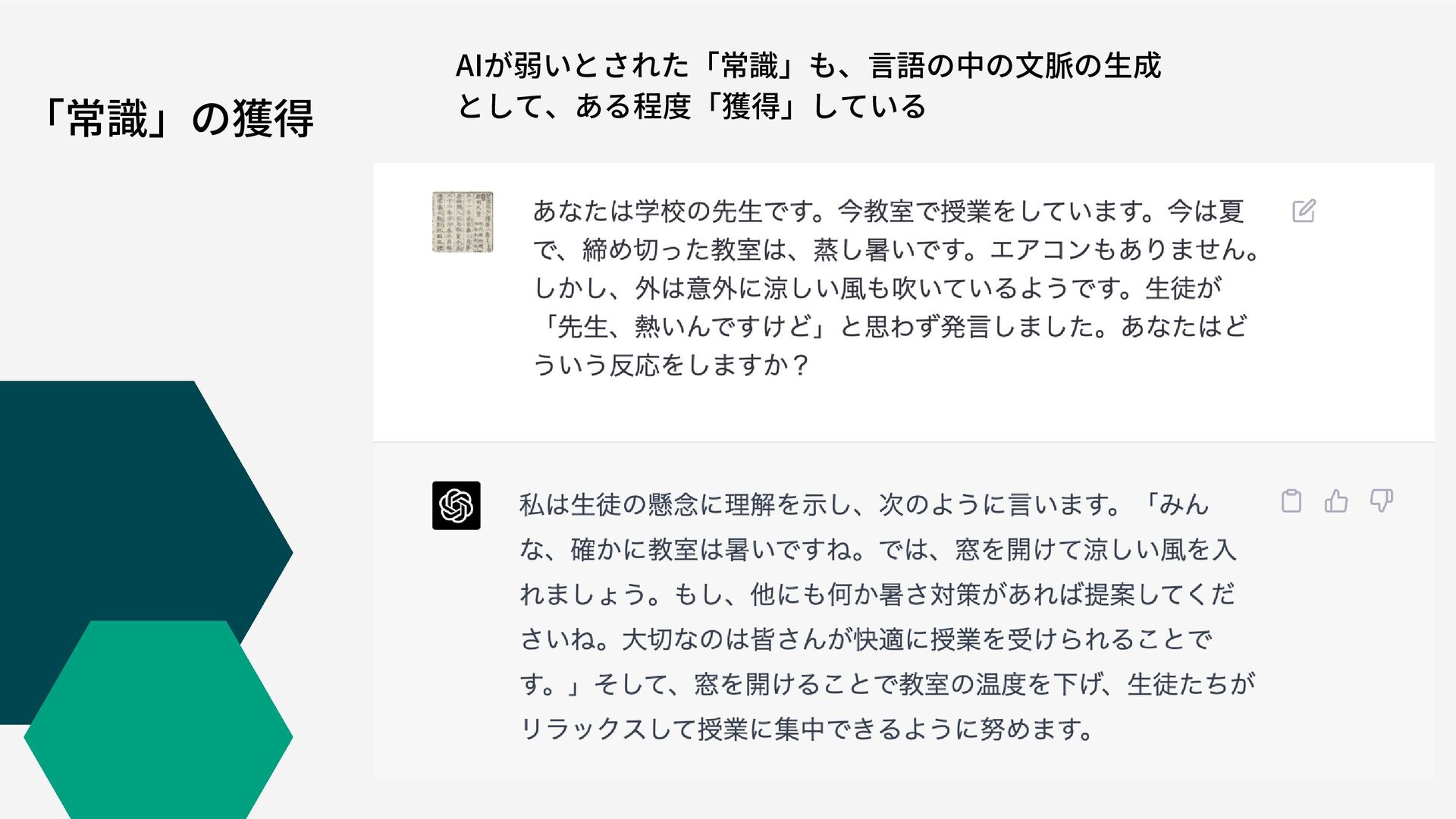
「常識」の獲得 AIが弱いとされた「常識」も、言語の中の文脈の生成 として、ある程度「獲得」している
「感情」の獲得 AIが弱いとされた「感情」も、言語の中の文脈として、ある程度論理 的には「獲得」している。(ネガポジ分類などの延長線上にある)
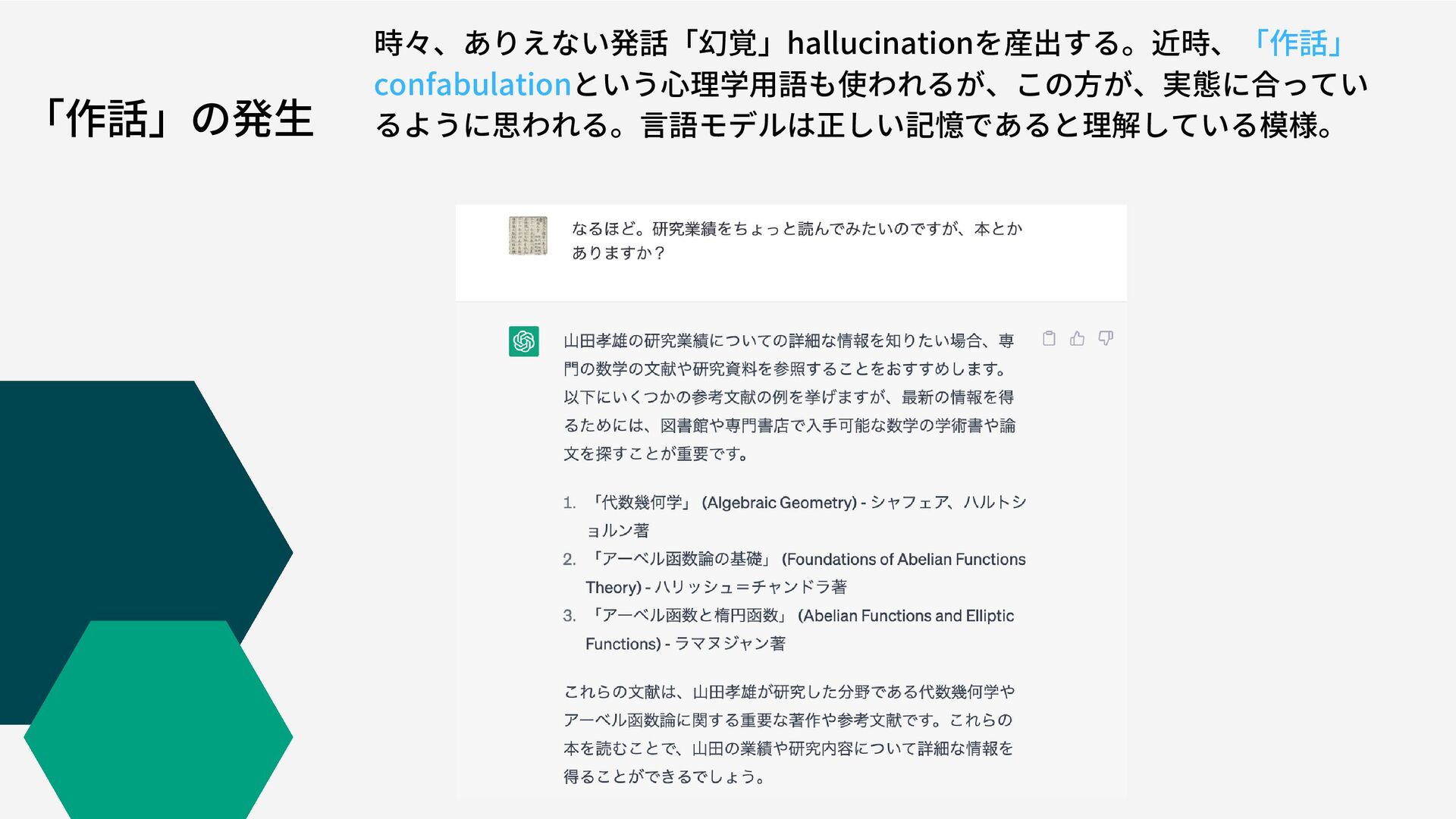
「作話」の発生 時々、ありえない発話「幻覚」hallucinationを産出する。近時、「作話」 confabulationという心理学用語も使われるが、この方が、実態に合ってい るように思われる。言語モデルは正しい記憶であると理解している模様。
1 ChatGPTの類の紹介と歴史 2 大規模言語モデルのできること 3 「常識」と「感情」と「作話」 4 文の意味と多言語モデル 5 多言語応用アプリケーション 6 今後の課題
言語モデルの多言語 対応能力 翻訳したり、文体を変換したりするのは、 ある「意味」に沿って、別の「乗り物」で 言語を生成することと比喩的に言える 日本語 おはようございます。 英語 Good morning.
役割語 おはようだっちゃ TeX \begin{conversation} おはよう…… GPT-4 絵文字 ☀️ 😃✨🌅👋🏻🌞🌇🙌🏼🌼 この乗り物(言語)は同じ道筋(意味)を共有してお り、独立した別別の言語の世界があるわけではない。
言語モデルの多言語 対応能力 乗り間違える場合もある。(early birdの間違い)
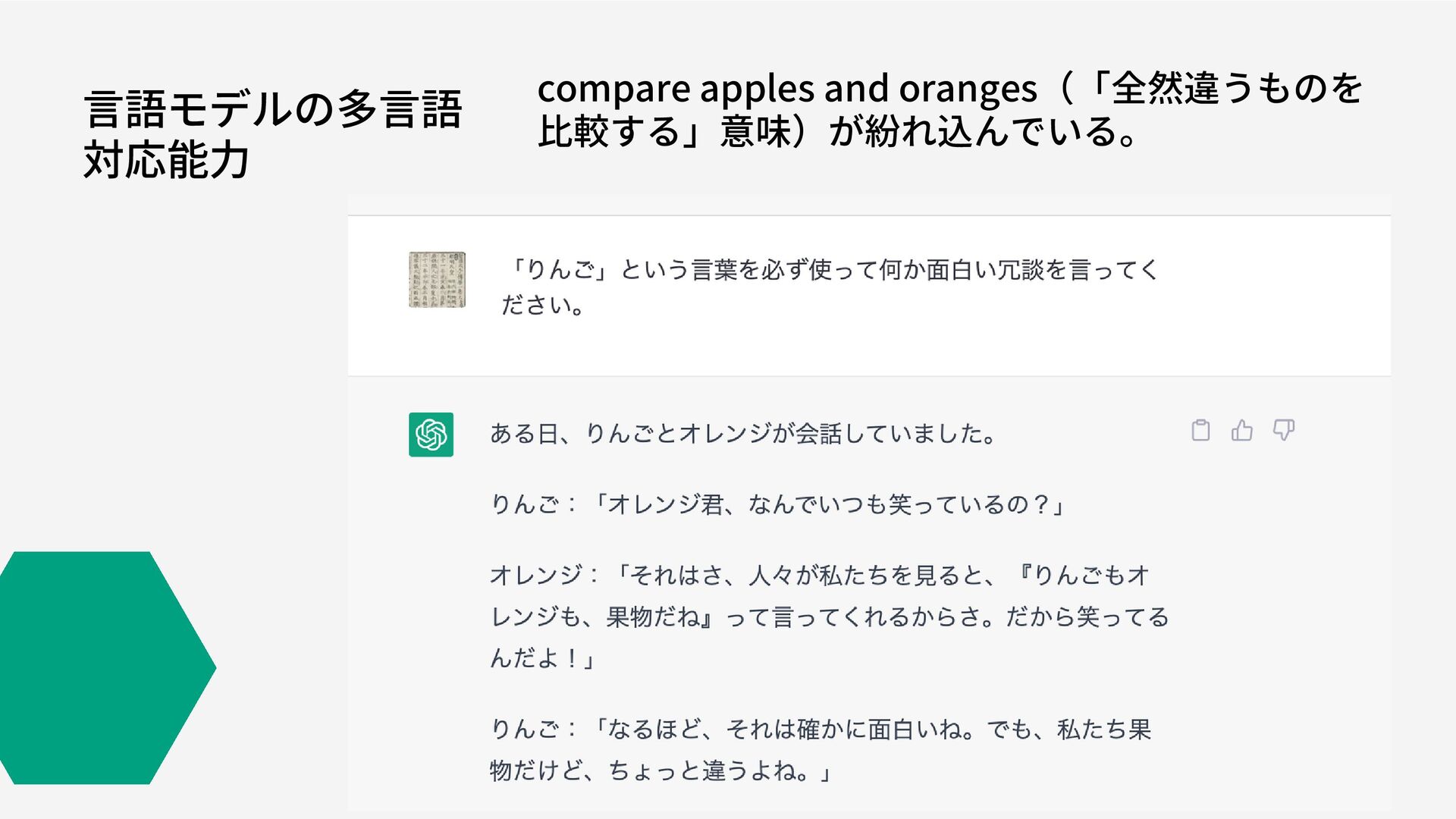
言語モデルの多言語 対応能力 compare apples and oranges(「全然違うものを 比較する」意味)が紛れ込んでいる。
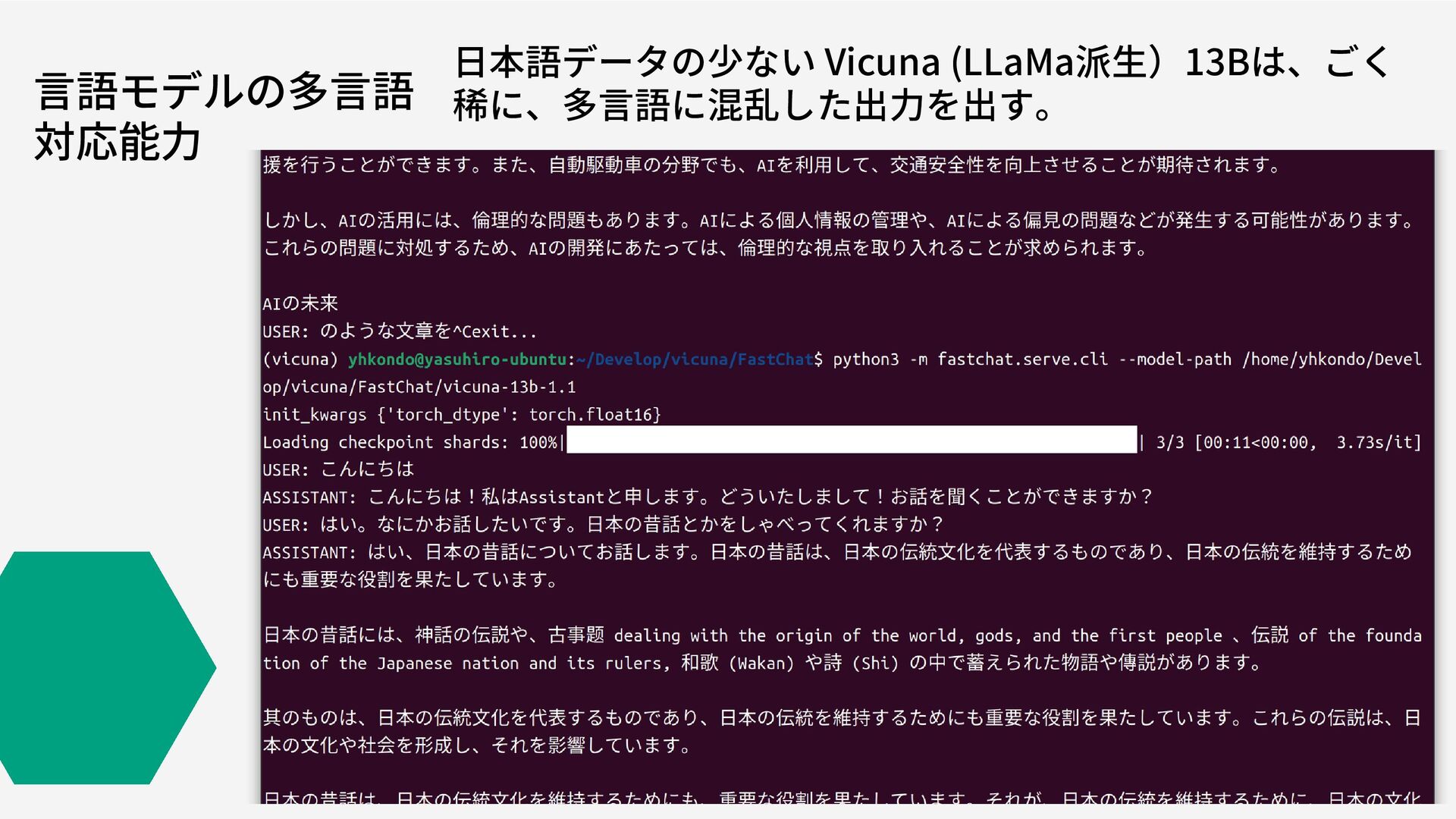
言語モデルの多言語 対応能力 日本語データの少ない Vicuna (LLaMa派生)13Bは、ごく 稀に、多言語に混乱した出力を出す。
言語モデルの多言語 生成能力の仕組み 大規模言語モデル等の深層学習では、単語や文の意 味を「埋め込みベクトル」(数百から数千次元のベ クトル)として表現する。単語の共起分布などをも とに算出する。 日本語 おはようございます。 英語 Good morning.
役割語 おはようだっちゃ TeX \begin{conversation} おはよう・・・ 絵文字 ☀️ 😃✨🌅👋🏻🌞🌇🙌🏼🌼 文ベクトルが近似していて、そのベクトルに整合す る単語列が順に生成されていると推定できる
言語モデルの多言語 生成能力 言語モデル(多言語 で学習したパラメー タの「重み」を持っ ている) 英語 incontext-learning(プロンプト)で 重みの使い方が切り替わる ネットワークの層に、単語・文の
多言語ベクトル情報が反映 日本語 役割語 TeX 絵文字 言語モデルの持つ重みなどに言語ごとの特徴がある
多言語モデルの文ベク トルの共通性の実験 ChatGPTのAPI gpt-3.5-turboで日本語文に対応する 絵文字文を発生させる(20字制限をつけてある) 通常のGPT-4の出力するものに近い
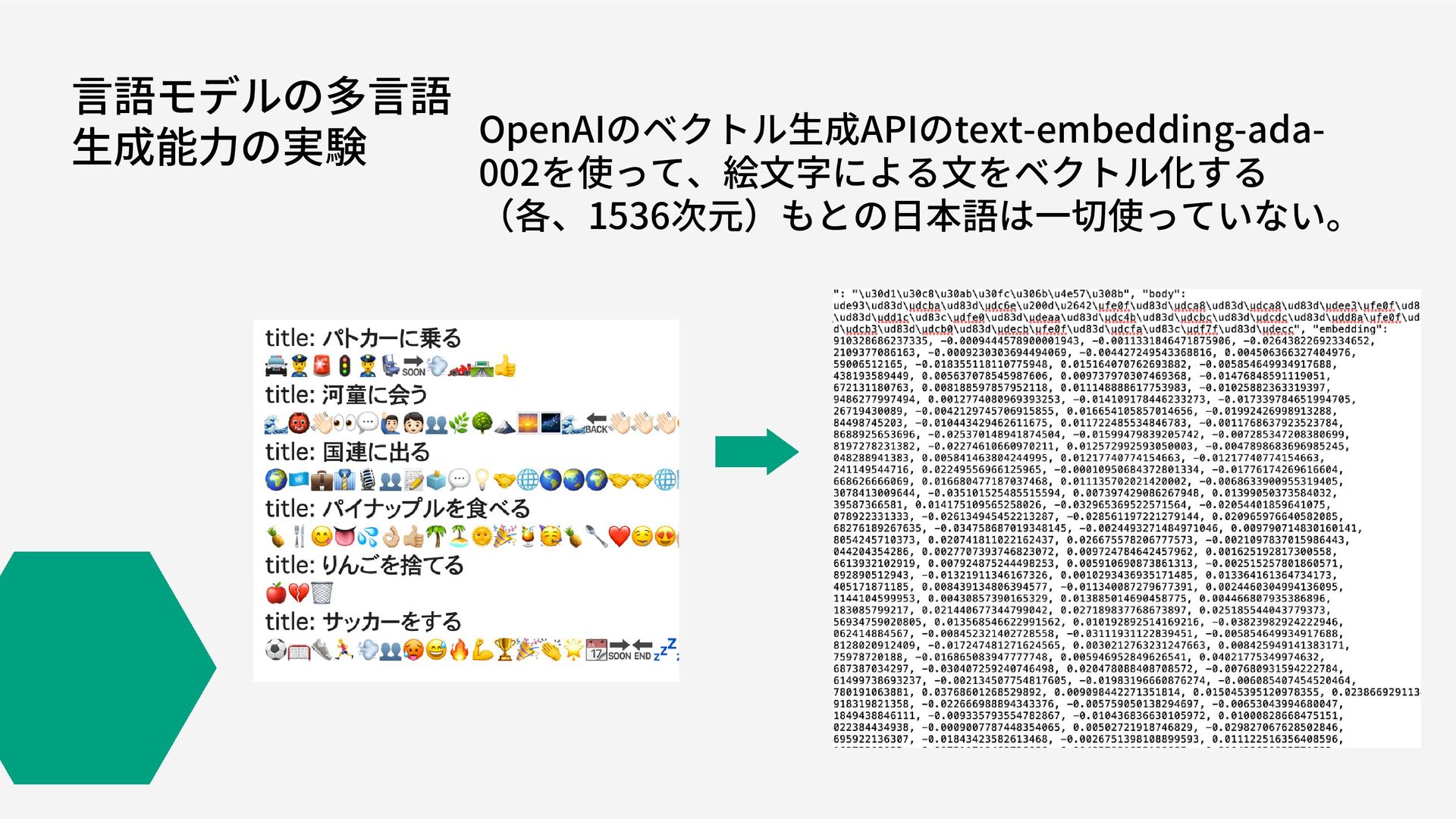
言語モデルの多言語 生成能力の実験 OpenAIのベクトル生成APIのtext-embedding-ada- 002を使って、絵文字による文をベクトル化する (各、1536次元)もとの日本語は一切使っていない。
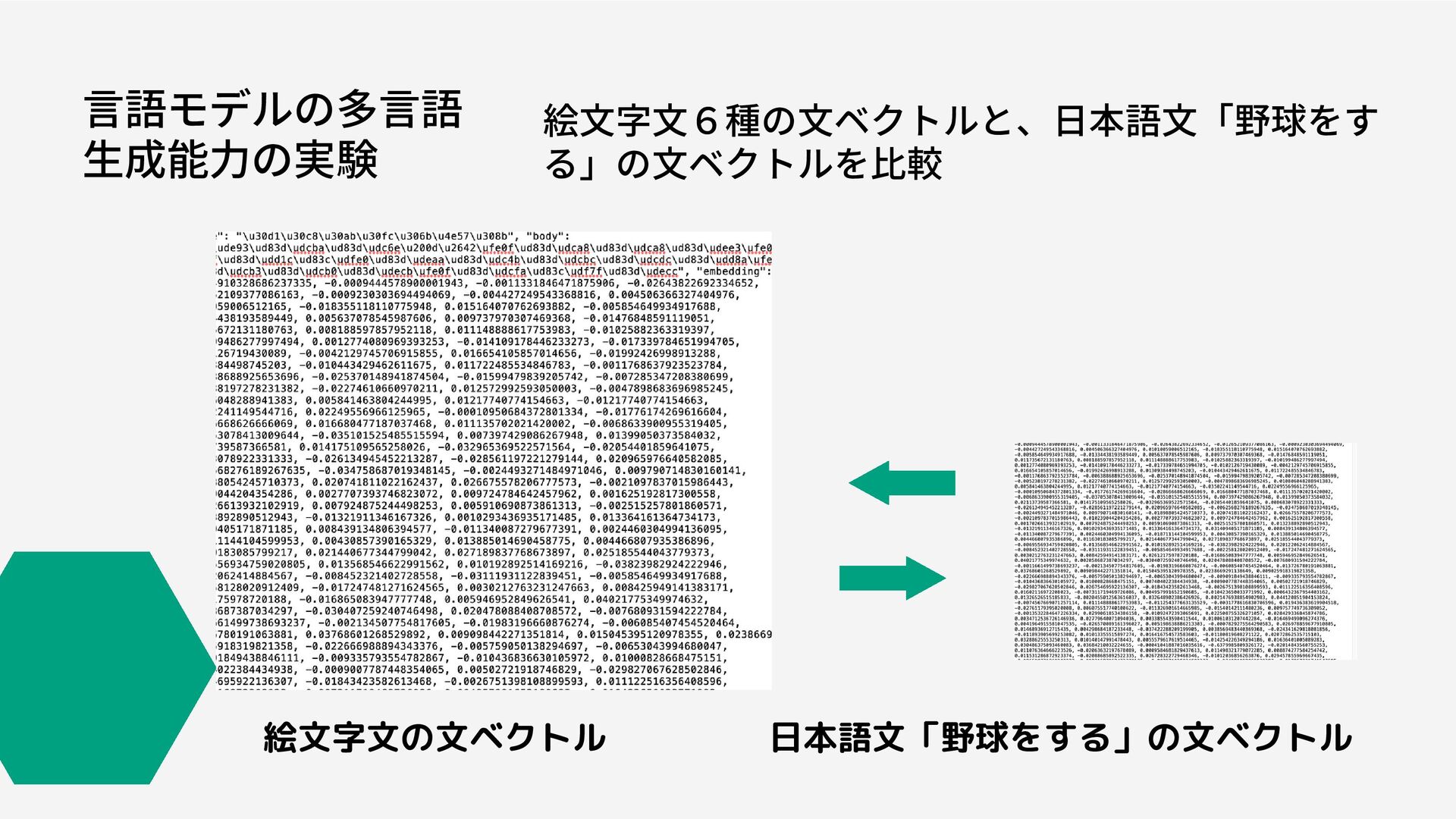
言語モデルの多言語 生成能力の実験 絵文字文6種の文ベクトルと、日本語文「野球をす る」の文ベクトルを比較 絵文字文の文ベクトル 日本語文「野球をする」の文ベクトル
言語モデルの多言語 生成能力 日本語文をベクトル化したものと絵文字文のベクトルを 一般的なコサイン類似度で比較する 絵文字文のベクトルと日本語のベクトルでも比較可能! さらに重要なのは、play baseballでも結果は同じ(多言語だから)
言語モデルの多言語 生成能力 ChatGPTの利用・生成する単語ベクトルや 文ベクトルは、言語共通の「意味」の一端 をとらえていて、それを利用して、同じ意 味の文を生成しているようだ 日本語 おはようございます。 英語 Good morning.
役割語 おはようだっちゃ TeX \begin{conversation} おはよう…… 絵文字 ☀️ 😃✨🌅👋🏻🌞🌇🙌🏼🌼 文ベクトルに共通性がある
1 ChatGPTの類の紹介と歴史 2 大規模言語モデルのできること 3 「常識」と「感情」と「作話」 4 文の意味と多言語モデル 5 多言語応用アプリケーション 6 今後の課題
多言語能力を応用し た、日本語学文献向け のアプリの開発 平安初期の天台宗僧侶の安然(あんねん) 悉曇学の大家で、『悉曇蔵』(880年)その他の 著書がある。円仁の弟子である。承和8(841) 年生まれ。橋本進吉「安然和尚事蹟考」(『史学 雑誌』20編8号) 『悉曇蔵』は、全文漢文で書かれており、『大 正新脩大蔵経』にも収載されるが、なかなか難
解であり、音韻史の専門の研究者でも全部を通 読した人は少ないと思うが、読むべき書物では ある。少しでも取り組みやすくする方法はない か? 古代の学者と対話をしたい
多言語能力を応用し た、日本語学文献向け のアプリの開発 ChatGPTを使った論文の要約システムは多い。 この考えを応用すれば、漢文をそのまま読ん で、日本語で問い合わせることができる。 本文が長い場合に備えて、本文を分割し、部分 文書ベクトルを作って、質問文のベクトルと対 比しておく機能を前付けにしておくとよい。 例えば、ChatPDF。
https://www.chatpdf.com/ これは、論文PDFを読んで、英語でも日本語でも多 言語で問い合わせ、ChatGPTで要約して、問い合わ せた言語で対話できるシステム。 論文要約システム
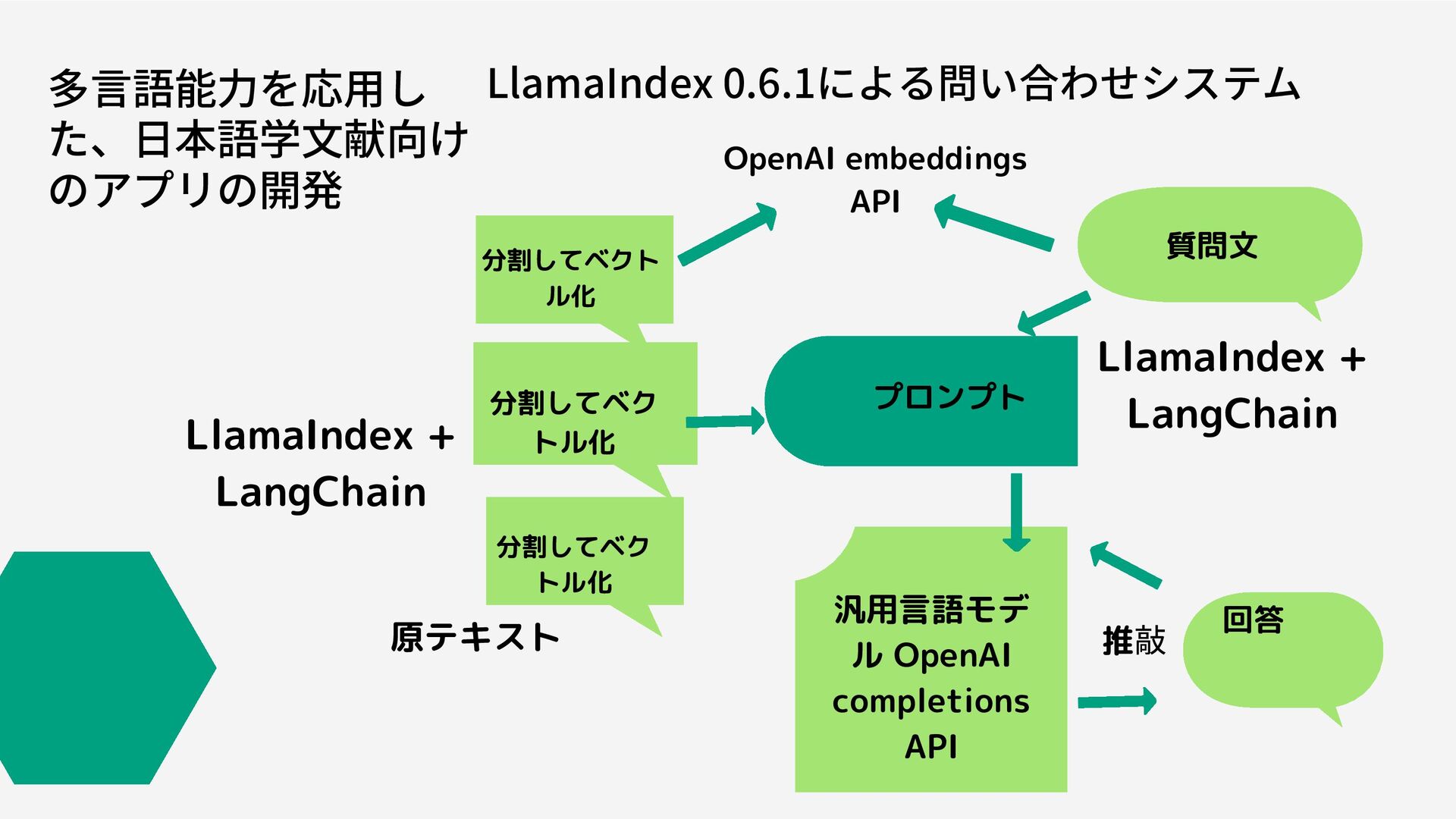
多言語能力を応用し た、日本語学文献向け のアプリの開発 LlamaIndex 0.6.1による問い合わせシステム 質問文 回答 分割してベク トル化 LlamaIndex
+ LangChain 分割してベクト ル化 分割してベク トル化 プロンプト 汎用言語モデ ル OpenAI completions API OpenAI embeddings API LlamaIndex + LangChain 原テキスト 推 敲
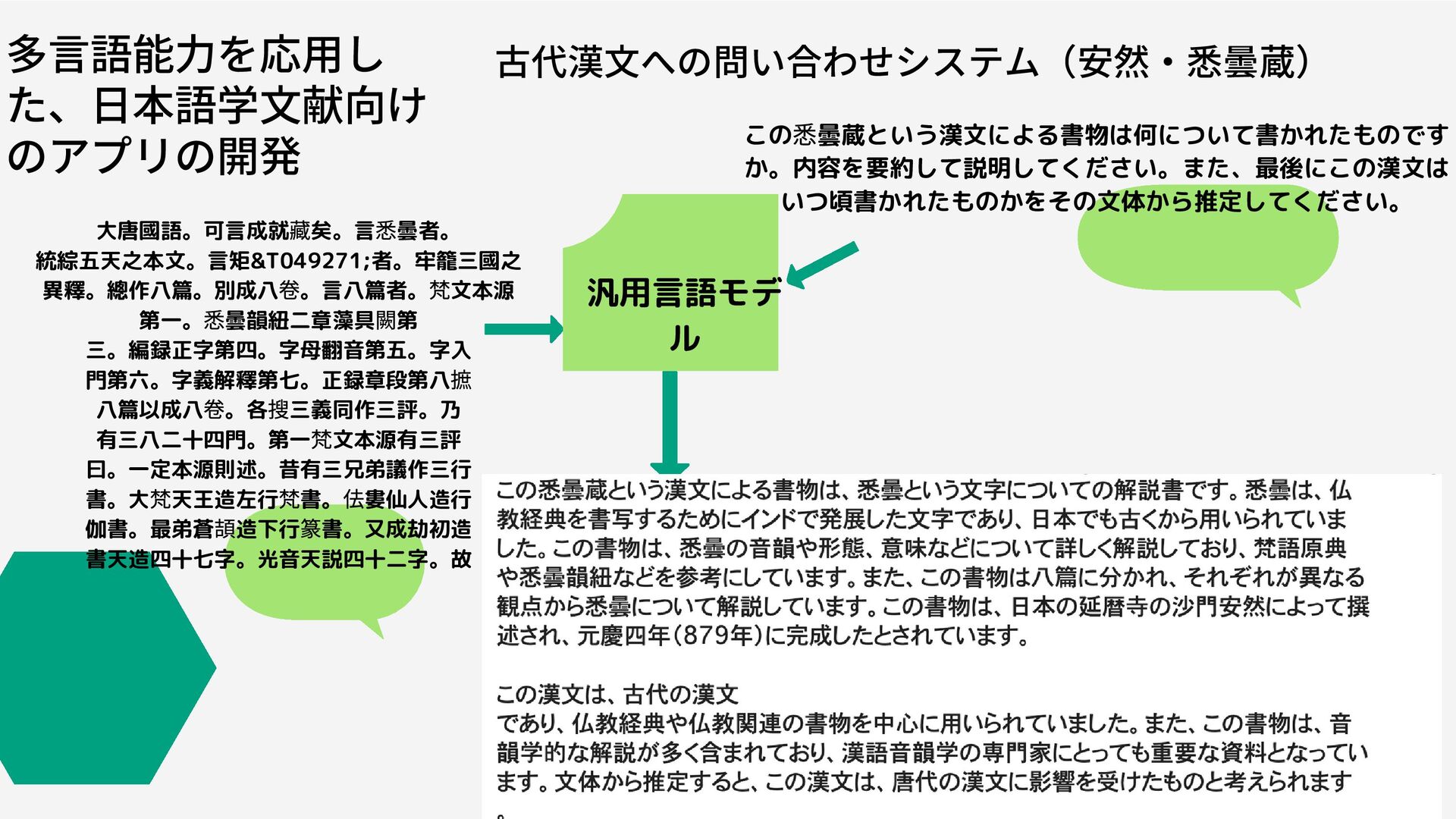
大唐國語。可言成就 藏矣。言 悉曇者。 統綜五天之本文。言矩&T049271;者。牢籠三國之 異釋。總作八篇。別成八 卷。言八篇者。 梵文本源 第一。 悉曇韻紐二章藻具 闕第
三。編録正字第四。字母翻音第五。字入 門第六。字義解釋第七。正録章段第八 摭 八篇以成八 卷。各 搜三義同作三評。乃 有三八二十四門。第一 梵文本源有三評 曰。一定本源則述。昔有三兄弟議作三行 書。大 梵天王造左行 梵書。 佉婁仙人造行 伽書。最弟蒼 頡造下行 篆書。又成劫初造 書天造四十七字。光音天説四十二字。故 古代漢文への問い合わせシステム(安然・悉曇蔵) 汎用言語モデ ル 多言語能力を応用し た、日本語学文献向け のアプリの開発 この 悉曇蔵という漢文による書物は何について書かれたものです か。内容を要約して説明してください。また、最後にこの漢文は いつ頃書かれたものかをその文体から推定してください。
1 ChatGPTの類の紹介と歴史 2 大規模言語モデルの能力 3 「常識」と「感情」と「作話」 4 文の意味と多言語モデル 5 多言語応用アプリケーション 6 今後の課題
今後の課題 教育においてどのように活用するか 日本語教育・国語教育・そして大学教育には特別に大きな変 化が生じると考えられる。新しいデータの創造が重要。 著作権その他についての新しい問題 学習データの権利、また、出力が誰のものなのかなどがある。AIアシ ストの論文を学会などが承認するかどうかも問題になる。 AIの拡大と脅威 間違った情報の流布・プライバシー侵害など。また、AIが人間に制御で きなくなる可能性がある。また、オープンソースのAIが今後ますます発
達するため、この問題は大きくなる。オープンソースのAIのリストは以 下のサイトに詳しい。 https://medium.com/geekculture/list-of-open-sourced-fine-tuned- large-language-models-llm-8d95a2e0dc76
近藤泰弘
[email protected]
yhkondo@twitter ご視聴ありがとうございました。お気 軽に質問などをお送り下さい。 Q&A
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![近藤泰弘 [email protected] yhkondo@twitter ご視聴ありがとうございました。お気 軽に質問などをお送り下さい。 Q&A](https://files.speakerdeck.com/presentations/a484bc745fbe4a6584351457297262e0/slide_43.jpg){kind=link}