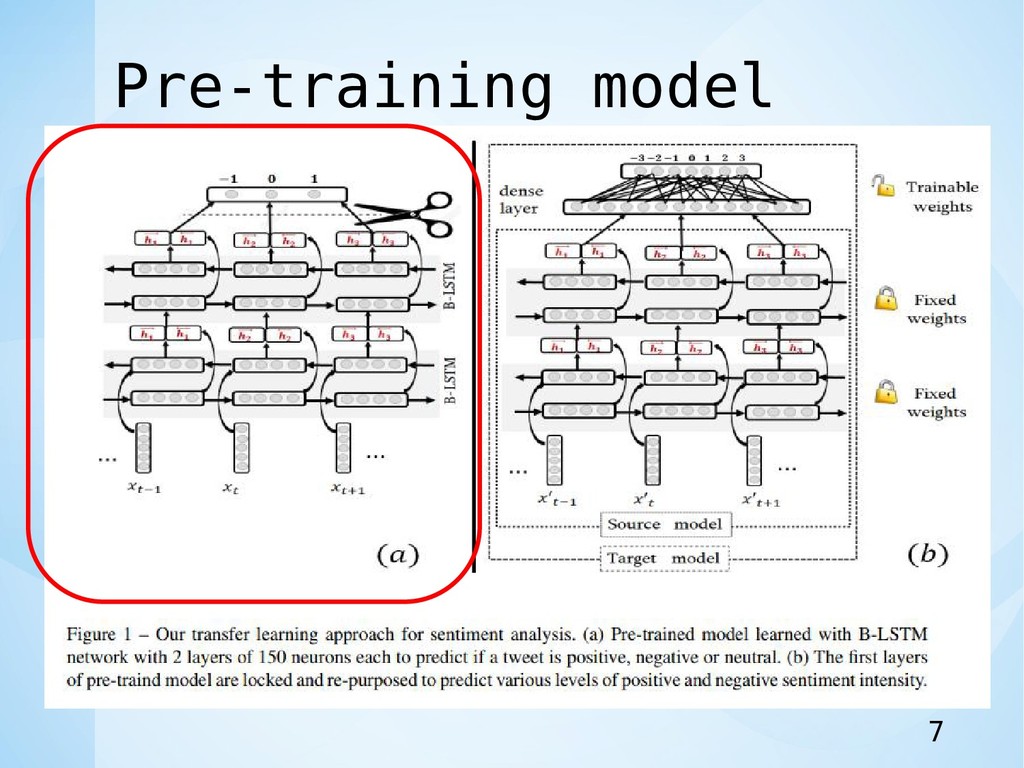
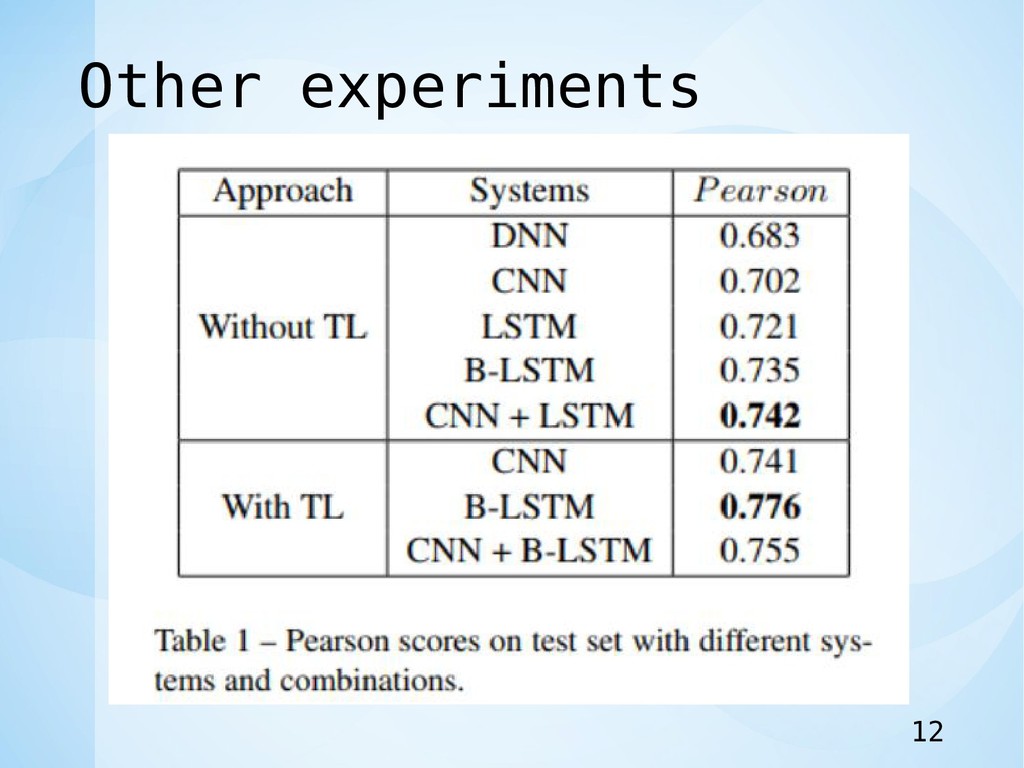
(300 for B-LSTM), 2 layers of B-LSTM, with a dropout of 0.3 and 0.5 for embedding and LSTM layers respectively. • Gaussian noise with σ of 0.3 • L2 regularization of 0.0001. • over 18 epochs • learning rate of 0.01 • batch size of 128 sequences. • モデルを外部データで訓練したが,評価のためにタスクで提供された training & development setを適合させた. • さまざまなレベルの肯定的な感情が同じクラスで再編成された. • さまざまなレベルの否定的な感情についても同じことが言える. • モデルは69.4%の精度を達成. 10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}