Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Using millions of emoji occurrences to learn an...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Yuto Kamiwaki
December 16, 2018
Research
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
2018/12/17 文献紹介の発表内容
Yuto Kamiwaki
December 16, 2018
More Decks by Yuto Kamiwaki
See All by Yuto Kamiwaki
Emo2Vec: Learning Generalized Emotion Representation by Multi-task Training
yuto_kamiwaki
0
120
Modeling Naive Psychology of Characters in Simple Commonsense Stories
yuto_kamiwaki
1
220
Epita at SemEval-2018 Task 1: Sentiment Analysis Using Transfer Learning Approach
yuto_kamiwaki
0
140
Tensor Fusion Network for Multimodal Sentiment Analysis
yuto_kamiwaki
0
280
Sentiment Analysis: It’s Complicated!
yuto_kamiwaki
0
93
ADAPT at IJCNLP-2017 Task 4: A Multinomial Naive Bayes Classification Approach for Customer Feedback Analysis task
yuto_kamiwaki
0
180
EmoWordNet: Automatic Expansion of Emotion Lexicon Using English WordNet
yuto_kamiwaki
0
120
ATTENTION-BASED LSTM FOR PSYCHOLOGICAL STRESS DETECTION FROM SPOKEN LANGUAGE USING DISTANT SUPERVISION
yuto_kamiwaki
0
160
BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs
yuto_kamiwaki
0
260
Other Decks in Research
See All in Research
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
550
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
120
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
650
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
160
第66回コンピュータビジョン勉強会@関東 Epona: Autoregressive Diffusion World Model for Autonomous Driving
kentosasaki
0
640
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
140
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
200
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
160
Ankylosing Spondylitis
ankh2054
0
180
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
310
Harness Engineering and Al Agent
kzinmr
3
1.7k
Featured
See All Featured
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.3k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
370
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
370
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.1k
Accessibility Awareness
sabderemane
1
140
Bash Introduction
62gerente
615
220k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Done Done
chrislema
186
16k
Typedesign – Prime Four
hannesfritz
42
3.1k
Transcript
Using millions of emoji occurrences to learn any-domain representations for
detecting sentiment, emotion and sarcasm Nagaoka University of Technology Yuto Kamiwaki Literature Review
Literature • Using millions of emoji occurrences to learn any-domain
representations for detecting sentiment, emotion and sarcasm • Bjarke Felbo, Alan Mislove, Anders Søgaard, Iyad Rahwan, Sune Lehmann • EMNLP 2017 2
Abstract • sentiment analysis, emotion analysis and sarcasm classificationにおける8つのbenchmarkでSoTA達成 •
感情ラベルの多様性が以前のdistant supervisonのアプ ローチよりもパフォーマンスの向上をもたらすことを確認 3
Introduction • NLPのタスクでは,アノテーション済み(感情が付与された)の データは少ない. • Distant supervisionを用いてSoTAを達成している研究があ る. Distant supervision
: (http://web.stanford.edu/~jurafsky/mintz.pdf) ラベル付きデータの情報を手がかりに全く別のラベルなしデータからラベル付きの学 習データを生成し、モデルを学習する手法 4
Related work • Ekman, Plutchikなどの感情の理論を用いて手作業によって 分類 ◦ 感情の理解が難しく,時間がかかる. • official
emoji tables (Eisner et al., 2016)からembeddingす る手法 ◦ emojiの使われ方を考慮しない. • マルチタスク学習 ◦ データストレージの観点から問題あり. 5
Pretraining • 2013年1月から2017年6月までのTweet data(emojiあり) • Only English tweets without URL’s
are used for the pretraining dataset. • All tweets are tokenized on a word-by-word basis. 6
Model 7
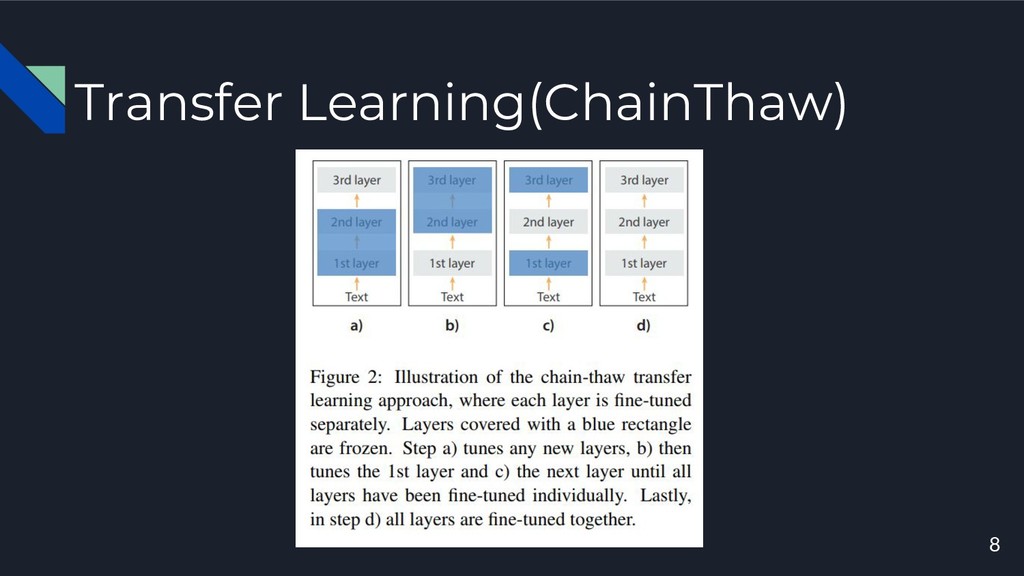
Transfer Learning(ChainThaw) 8
Emoji Prediction 9
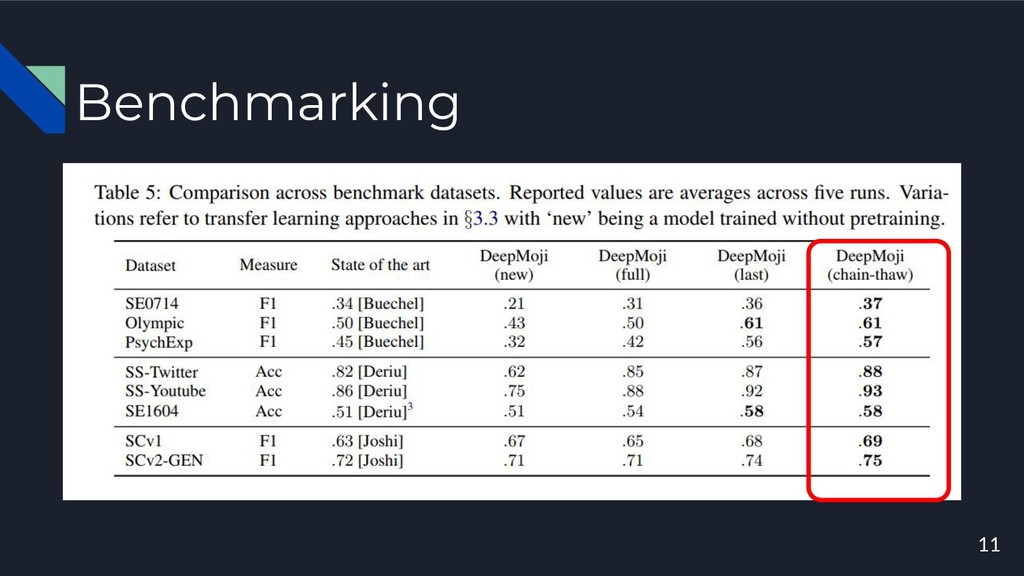
Benchmarking 10 8 Benchmarks(3tasks,5domains)
Benchmarking 11
Importance of emoji diversity 12 Pos/Neg Emoji:8 types DeepMoji:64 types
感情ラベルの多様性が重要 64種類のemojiの細かい ニュアンスを学習できている. (次ページの図を参照)
Importance of emoji diversity 13
Model architecture 14 Pretraining時点では,差がない benchmark時点では,Attention ありの方が精度が高い 低層の特徴へのアクセスが簡単 勾配消失がなく,学習可能
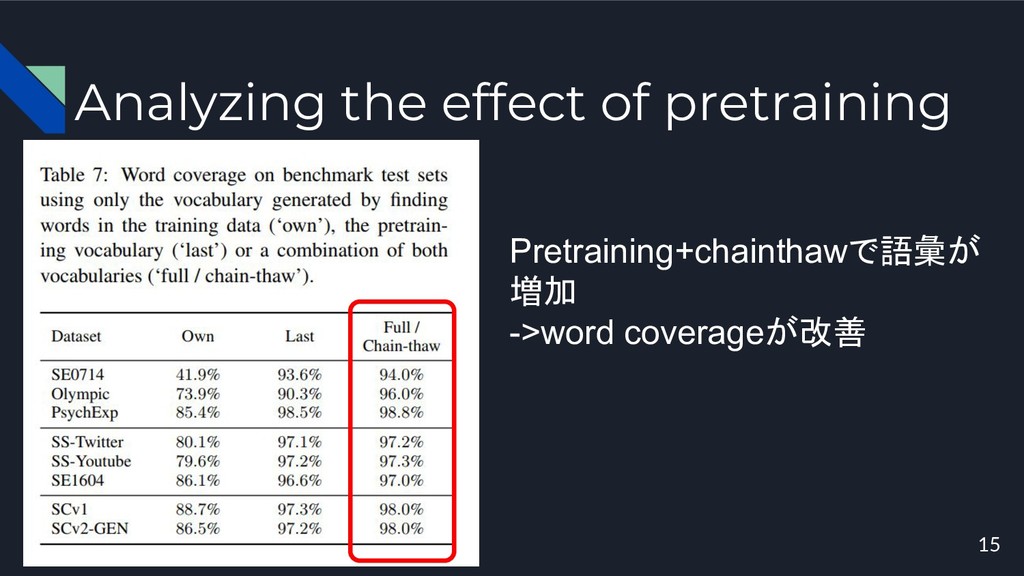
Analyzing the effect of pretraining 15 Pretraining+chainthawで語彙が 増加 ->word coverageが改善
Comparing with human-level agreement 16 Human:76.1% Deepmoji:82.4% Deepmojiの方が,精度 が高い (実験内容については,論文
を参照)
Conclusion • sentiment analysis, emotion analysis and sarcasm classificationにおける8つのbenchmarkでSoTA達成 •
感情ラベルの多様性が以前のdistant supervisonのアプ ローチよりもパフォーマンスの向上をもたらすことを確認 • Pretraining済みモデルを公開 ◦ (Demo : https://deepmoji.mit.edu/) 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}