Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Tensor Fusion Network for Multimodal Sentiment ...
Search
Yuto Kamiwaki
October 21, 2018
Research
280
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Tensor Fusion Network for Multimodal Sentiment Analysis
2018/10/22文献紹介の発表内容
Yuto Kamiwaki
October 21, 2018
More Decks by Yuto Kamiwaki
See All by Yuto Kamiwaki
Emo2Vec: Learning Generalized Emotion Representation by Multi-task Training
yuto_kamiwaki
0
120
Modeling Naive Psychology of Characters in Simple Commonsense Stories
yuto_kamiwaki
1
220
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
yuto_kamiwaki
0
120
Epita at SemEval-2018 Task 1: Sentiment Analysis Using Transfer Learning Approach
yuto_kamiwaki
0
140
Sentiment Analysis: It’s Complicated!
yuto_kamiwaki
0
93
ADAPT at IJCNLP-2017 Task 4: A Multinomial Naive Bayes Classification Approach for Customer Feedback Analysis task
yuto_kamiwaki
0
180
EmoWordNet: Automatic Expansion of Emotion Lexicon Using English WordNet
yuto_kamiwaki
0
120
ATTENTION-BASED LSTM FOR PSYCHOLOGICAL STRESS DETECTION FROM SPOKEN LANGUAGE USING DISTANT SUPERVISION
yuto_kamiwaki
0
160
BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs
yuto_kamiwaki
0
260
Other Decks in Research
See All in Research
Language and AI
ayaniwa
0
150
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
230
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
3.9k
事後確率分布の共分散について
koide3
0
150
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
1k
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
130
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
570
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
250
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
220
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
520
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
300
Featured
See All Featured
The Curse of the Amulet
leimatthew05
2
13k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
210
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Why Our Code Smells
bkeepers
PRO
340
58k
Utilizing Notion as your number one productivity tool
mfonobong
4
330
sira's awesome portfolio website redesign presentation
elsirapls
0
290
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
550
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
250
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
400
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
440
Transcript
Tensor Fusion Network for Multimodal Sentiment Analysis 長岡技術科学大学 自然言語処理研究室 上脇優人
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, Louis-Philippe Morency EMNLP2017, pages 1103–1114 10月文献紹介 ※各人の所属については,paperを参照
Abstract • マルチモーダル感情分析についての論文. • モーダル内及びモーダル間のダイナミクスをエンドツーエ ンドで学習するTensor Fusion Networkという新しい モデルを提案. •
提案されたアプローチは,オンラインビデオにおける音声 言語の揮発性と,付随するジェスチャと音声に合わせて調 整されている. • 提案モデルは,マルチモーダルとユニモーダルの両方の感 情分析のための最先端のアプローチよりも優れている. 2
Introduction • テキストベースの感情分析を一般化する. • 言語(テキスト),視覚(ジェスチャー),聴覚(音声) • SNSなどの分析などオピニオンマイニングと感情分析を扱う NLPタスクで非常に重要. • マルチモーダル感情分析の主な課題は,モダリティ間のダイ
ナミクスを表現することである. • つまり,表現された感情の認識を変える言語,視覚,および 音響の行動間の相互作用が重要. 3
4
CMU-MOSI Dataset •YouTubeムービーレビューからのビデオ意見の注釈付き データセット. •感情の注釈は,Stanford Sentiment Treebankのア ノテーションスキームに従っている. •感情はvery negativeからvery
positiveな7段階の スケールで注釈付けされます. •Stanford Sentiment Treebankは文で区切られてい るのに対し,CMU-MOSIデータセットは,文章の境界がテ キストほど明確ではない音声言語に対応するために,意見 発話によってセグメント化されている. 5
CMU-MOSI Dataset •CMU-MOSIの93人の話し手には2199件の意見発言 がある. •各動画に平均23.2の意見セグメントがある. •各動画の平均再生時間は4.2秒. •意見発話には合計26,295語がある. •これらの発話には,メカニカル・タークの5人の注 釈者が感情の注釈を付ける. 6
CMU-MOSI Dataset 7
Tensor Fusion Network • 提案するTFNは,3つの主要な要素で構成される. 1. モダリティ埋め込みサブネットワークは,入力とし てユニモーダルな特徴を取り込み,豊富なモダリテ ィ埋め込みを出力する. 2.
Tensor Fusion Layerは,モダリティ埋め込みか らの3倍デカルト積を使用して,ユニモーダルからト リモーダルまでの相互作用を明示的にモデル化す る. 3. センチメント推論サブネットワークは,Tensor Fusion Layerの出力を条件とし,感情推論を行う ネットワークである. • セクション3のタスクに応じて,バイナリ分類,5クラス 分類または回帰に対応するようにネットワーク出力が変更 される. • TFNへの入力は,言語,視覚,聴覚の3つのモダリティを 含む意見発話である. 8
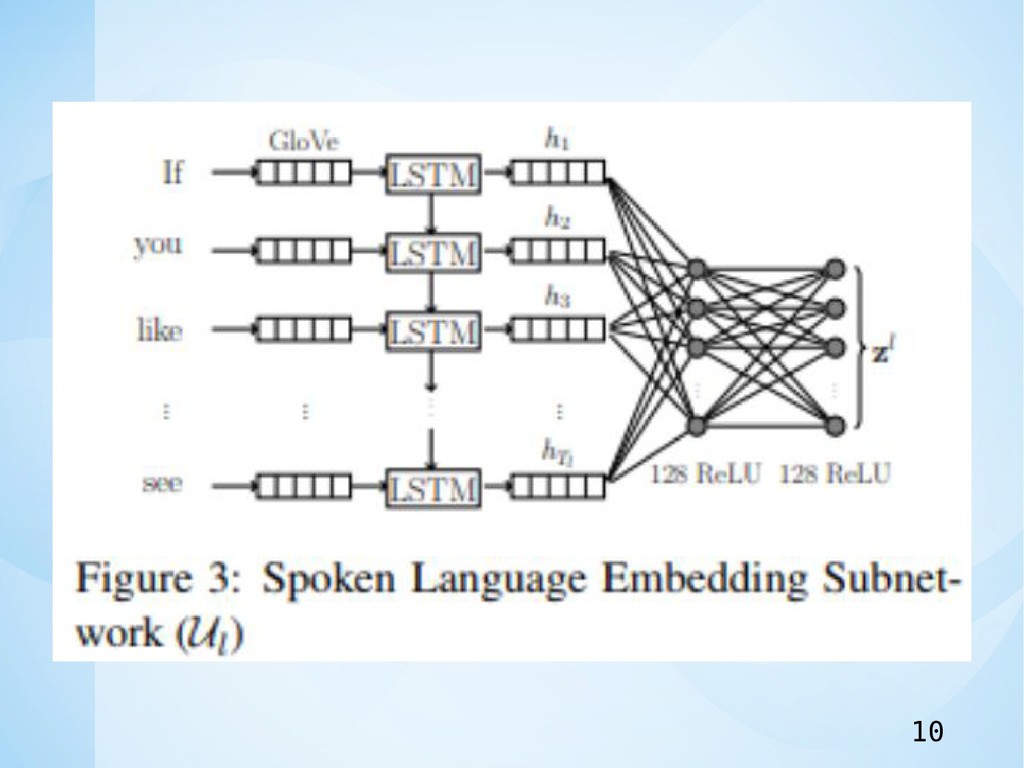
Modality Embedding Subnetworks: Spoken Language Embedding Subnetwork • 音声テキストは,レビュー等とは異なる. 例:“I think
it was alright...Hmmm...let me think...yeah...no...ok yeah” • 最初の部分は実際のメッセージを伝え,残りは最終的に最 初の部分に賛同するような形になっている. • 音声言語の揮発性の性質の課題に対処するために提案され ているアプローチは,各単語区間での話し言葉の豊かな表 現を学び,それを完全に接続されたDeep Networkへの 入力として使用するものである. 9
10
Modality Embedding Subnetworks: Visual Embedding Subnetwork, Acoustic Embedding Subnetwork • 表情の情報が視覚情報の最も重要なソースである.
• 話者の表情は,30Hzでサンプリングされたフレームごと に検出され,7つの基本感情(怒り,軽蔑,嫌悪感,恐怖, 喜び,悲しみ,驚き)と2つの高度な感情(欲求不満と混 乱)(Ekman,1992)をFACET表情解析フレームワーク1 を用いて抽出する. • 顔の詳細な筋肉の動きを示す20個の顔面アクションユニ ット(Ekman et al.,1980)のセットも,FACETを使 用して抽出する. • 音声についてもフレームワークを用いて特徴を抽出し た.抽出された特徴は,人間の声の様々な特徴を捕捉し, 感情に関連することが示されている. 11
Tensor Fusion Layer 12
Sentiment Inference Subnetwork •Tensor Fusion層の後,各意見発声は,マルチモ ーダルテンソルzmとして表すことができる. •我々は,zm上で条件付けされた重みWs を有する感情 推論サブネットワークUs と呼ばれる完全に接続され
たDeep Neural Networkを使用する. •ネットワークのアーキテクチャは,決定レイヤに接 続された128個のReLUアクティベーションユニット の2つのレイヤーで構成される. 13
Sentiment Inference Subnetwork •センチメント推論サブネットワークの尤度関数は,以下 のように定義される.ここで,φはセンチメント予測で ある.ここで,φmax(φm)は,我々のネットワーク. •第1のネットワークは,バイナリのクロスエントロピ ー損失を使用する単一のシグモイド出力ニューロンを 用いて,バイナリセンチメント分類のために訓練され る.
•第2のネットワークは,5クラスのセンチメント分類 のために設計され,カテゴリクロスエントロピー損失 を使用するソフトマックス確率関数を使用する. •第3のネットワークは,単一のシグモイド出力を使用 して,平均誤差除去を使用して感情回帰を実行する. 14
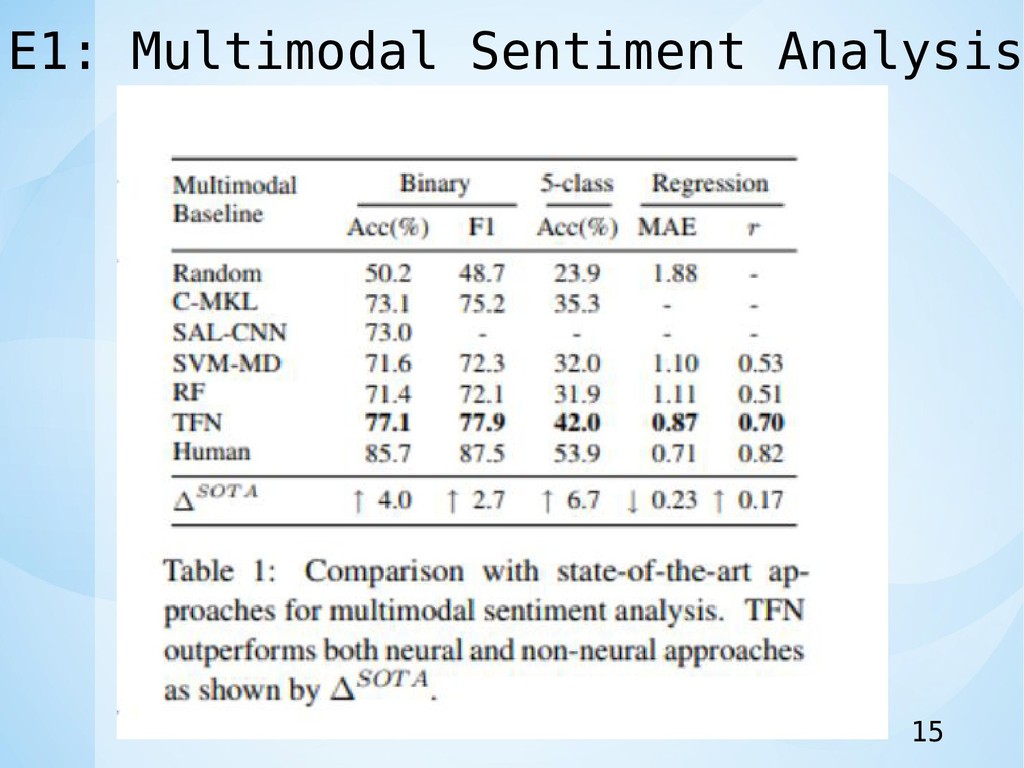
E1: Multimodal Sentiment Analysis 15
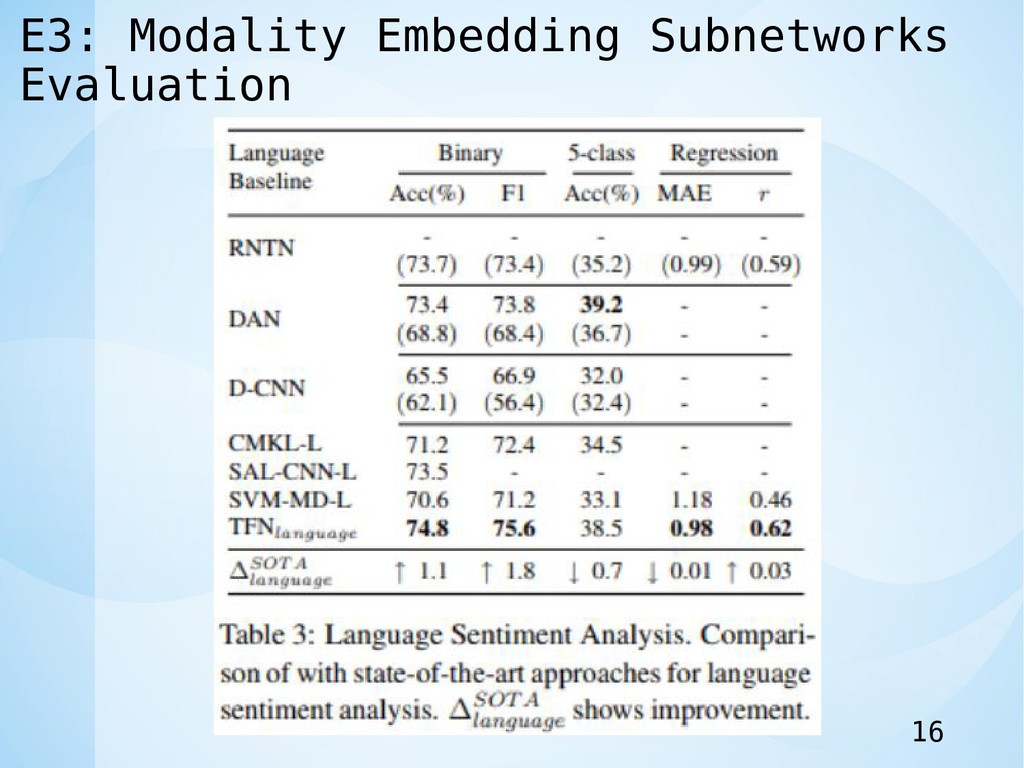
E3: Modality Embedding Subnetworks Evaluation 16
Qualitative Analysis 17
Conclusions •Tensor Fusion Networkを提案した. •公に利用可能なCMU-MOSIデータセットに関す る本実験は,他のマルチモーダルアプローチと 比較して最先端のパフォーマンスであった. 18
Methodology •すべてのモデルは,CMUMOSIによって提案され た5-fold cross-validationを使用してテ ストされる. •最適なハイパーパラメータは,バリデーション セットのモデル性能に基づいたグリッド検索を 使用して選択される. •TFNモデルは,学習率5e4のAdamオプティマイ ザを使用して訓練される.
•Uv とUa ,Us サブネットワークはp = 0.15とL2 ノルム係数0.01ですべての隠れ層でドロップア ウトを使用して正則化される. •train, test and validationは,すべて のベースラインでまったく同じである. 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}