Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ATTENTION-BASED LSTM FOR PSYCHOLOGICAL STRESS D...
Search
Yuto Kamiwaki
June 27, 2018
Research
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ATTENTION-BASED LSTM FOR PSYCHOLOGICAL STRESS DETECTION FROM SPOKEN LANGUAGE USING DISTANT SUPERVISION
2018/06/28文献紹介の発表内容
Yuto Kamiwaki
June 27, 2018
More Decks by Yuto Kamiwaki
See All by Yuto Kamiwaki
Emo2Vec: Learning Generalized Emotion Representation by Multi-task Training
yuto_kamiwaki
0
120
Modeling Naive Psychology of Characters in Simple Commonsense Stories
yuto_kamiwaki
1
220
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
yuto_kamiwaki
0
120
Epita at SemEval-2018 Task 1: Sentiment Analysis Using Transfer Learning Approach
yuto_kamiwaki
0
140
Tensor Fusion Network for Multimodal Sentiment Analysis
yuto_kamiwaki
0
280
Sentiment Analysis: It’s Complicated!
yuto_kamiwaki
0
93
ADAPT at IJCNLP-2017 Task 4: A Multinomial Naive Bayes Classification Approach for Customer Feedback Analysis task
yuto_kamiwaki
0
180
EmoWordNet: Automatic Expansion of Emotion Lexicon Using English WordNet
yuto_kamiwaki
0
120
BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs
yuto_kamiwaki
0
260
Other Decks in Research
See All in Research
世界モデルにおける分布外データ対応の方法論
koukyo1994
7
2.2k
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.4k
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
130
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
650
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
3.9k
Data Visualization Tools in the Age of AI
flekschas
0
160
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
320
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
140
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
120
論文紹介:HalluCitation Matters
wasyro
0
110
typst の使い方:言語学を研究する学生のために
gitomochang
0
470
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
250
Featured
See All Featured
HDC tutorial
michielstock
2
720
The Cost Of JavaScript in 2023
addyosmani
55
10k
The browser strikes back
jonoalderson
0
1.3k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
790
Done Done
chrislema
186
16k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
400
A better future with KSS
kneath
240
18k
Making the Leap to Tech Lead
cromwellryan
135
9.9k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.8k
Un-Boring Meetings
codingconduct
0
320
Odyssey Design
rkendrick25
PRO
2
710
Transcript
ATTENTION-BASED LSTM FOR PSYCHOLOGICAL STRESS DETECTION FROM SPOKEN LANGUAGE USING
DISTANT SUPERVISION 長岡技術科学大学 自然言語処理研究室 上脇優人 Genta Indra Winata, Onno Pepijn Kampman, Pascale Fung Hong Kong University of Science and Technology, Clear Water Bay, Hong Kong ICASSP 2018 6月文献紹介
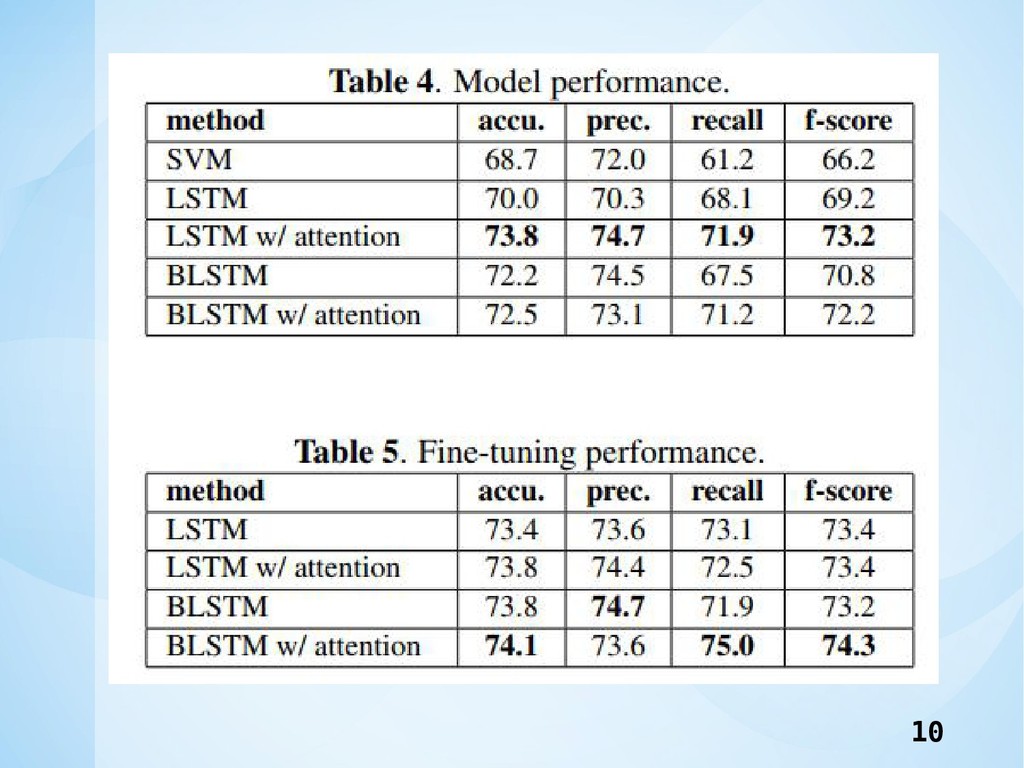
Abstruct •自己導出型の書き起こしからの心理的ストレスを分類す るためのattentionメカニズムを備えたLSTMを提案. •コーパスのサイズを補完して拡張するハッシュタグの内 容に基づいて,ツイートを自動的にラベル付けすること によってdistant supervisionを適用. •biLSTMモデルは,accuracy 74.1%とF値 74.3%の
点で最高のモデルである. •distant supervisionの微調整により,accuracy 1.6%,F値 2.1%向上. 2
Introduction •心理的ストレスは,人の話し方や言葉の選択に影 響する. •言語学的研究では,言語選択にストレスと精神的 健康のレベルへの指針が含まれていることが示さ れている. •うつ病の発生を予測するためのソーシャルメディ アとTwitterからのテキストデータの可能性も実 証されている. •文章レベルのストレス検出に関する研究は,主に,
マイクロブログなどのソーシャルメディアから収 集されたテキストに焦点を当てている. 3
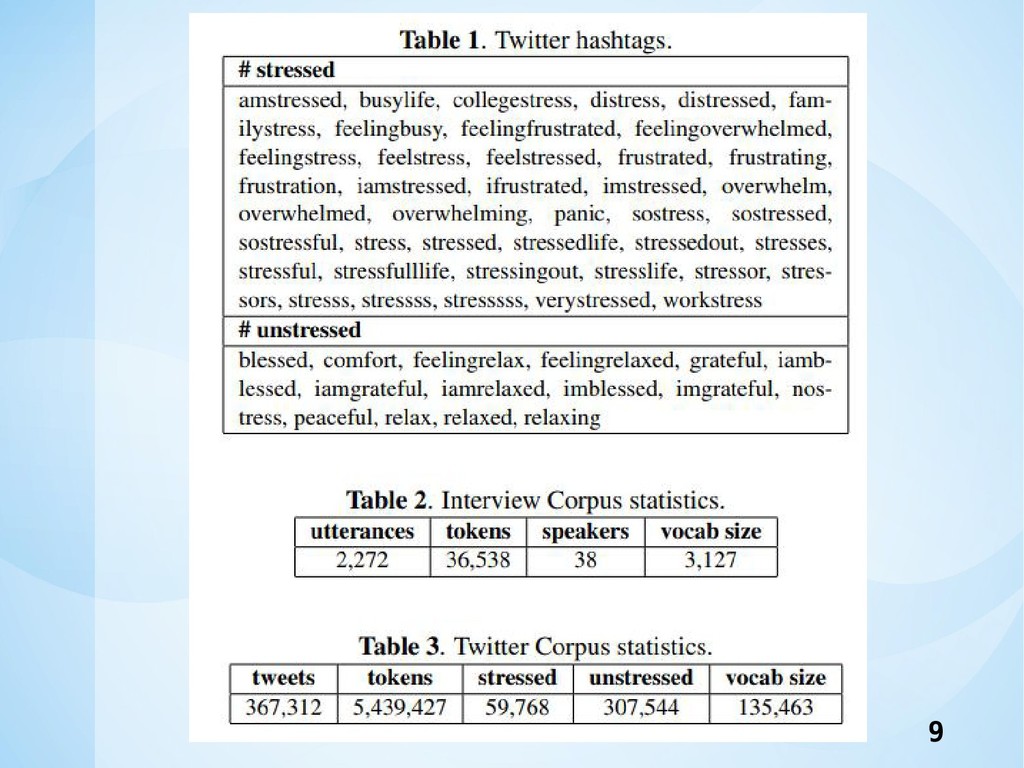
Introduction •本研究では,面接転写から文章レベルでの心理的ストレ スを検出するための単語埋め込み型attention based LSTMモデルを構築することを提案. •本ケースでは,著者の心の強調または非ストレス状態を 示すハッシュタグを手動で選択し,ストレス(正のラベ ル)とストレスのない(負のラベル)つぶやきをスクラ ップするのに使用. •インタビューコーパスは比較的小さく,主にアカデミア
に関連する限られた数の話題しかカバーしていないため, トレーニング中にデータを追加する必要がある. 4 この論文の主な貢献は、Twitterから収集されたラベルのないデータ が,本研究のインタビュー転記コーパスの分類パフォーマンスを向上 させることができることを示し,attention mechanismを適用すると モデルが重要な単語を効果的に選択するのに役立つ.
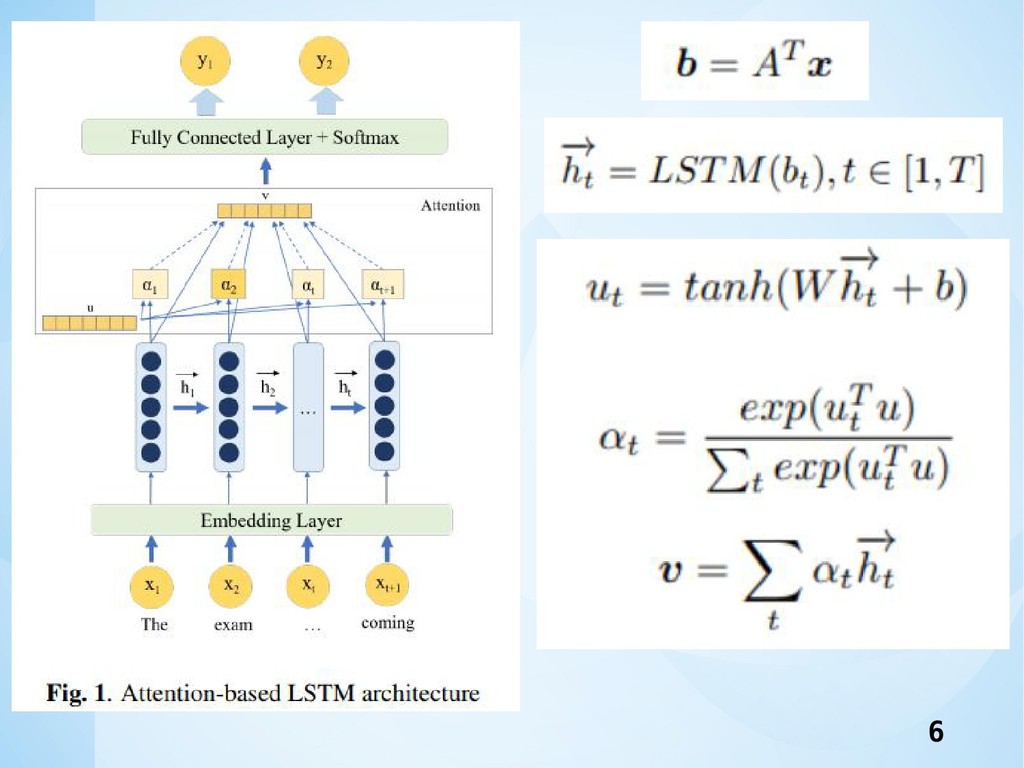
Models •本研究の目的は,入力として発話があれば,誰か がストレスを受けているかどうかを判断可能とす ることである. •いくつかの異なるモデルを探索した. •LSTM及びBiLSTMモデルでは,最終的にストレス 及びストレスのない用語集を形成するために訓練 可能な埋め込み層を使用した. •LSTMは,文中の単語の時間的ダイナミクスを捕 捉することが可能.
5
6
7
SVM •ベースラインとして,Radial Basis Function(RBF)カーネルを用いてSVMを構築 した. •与えられた文中の単語ごとにword2vecのワード エンベディングを抽出した. •埋め込みの次元数はkは300で,Googleニュース のデータで事前に訓練されている(約1000億語 でユニークワードは約300万語).
•SVMの場合,入力はN個の発話ベクトルからなる 入力行列として表されます. 8
9
10
11
12
Conclusion •面接記録から面接者のストレスレベルを分類する 方法を提示した. •biLSTMのモデルが最高性能であった. •ドメイン外ストレスツイートデータセットを使用 した2段階トレーニング方法は,学習のパフォー マンスを向上させる. 13
Future work •言語的および音響的特徴を用いたマルチモーダル 学習をする. •transfer learningのために文法的に正しい文 章を取得する. •今回のモデルを仮想セラピストのプラットフォー ムに組み込んで自動音声出力をさせる. •これにより、システムはユーザーのストレスを認
識し,適切なストレスマネジメントのアドバイス とエクササイズで対応する. 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}