Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
BB_twtr at SemEval-2017 Task 4: Twitter Sentime...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Yuto Kamiwaki
May 29, 2018
Research
260
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs
2018/05/30文献紹介の発表内容
Yuto Kamiwaki
May 29, 2018
More Decks by Yuto Kamiwaki
See All by Yuto Kamiwaki
Emo2Vec: Learning Generalized Emotion Representation by Multi-task Training
yuto_kamiwaki
0
120
Modeling Naive Psychology of Characters in Simple Commonsense Stories
yuto_kamiwaki
1
220
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
yuto_kamiwaki
0
120
Epita at SemEval-2018 Task 1: Sentiment Analysis Using Transfer Learning Approach
yuto_kamiwaki
0
140
Tensor Fusion Network for Multimodal Sentiment Analysis
yuto_kamiwaki
0
280
Sentiment Analysis: It’s Complicated!
yuto_kamiwaki
0
93
ADAPT at IJCNLP-2017 Task 4: A Multinomial Naive Bayes Classification Approach for Customer Feedback Analysis task
yuto_kamiwaki
0
180
EmoWordNet: Automatic Expansion of Emotion Lexicon Using English WordNet
yuto_kamiwaki
0
120
ATTENTION-BASED LSTM FOR PSYCHOLOGICAL STRESS DETECTION FROM SPOKEN LANGUAGE USING DISTANT SUPERVISION
yuto_kamiwaki
0
160
Other Decks in Research
See All in Research
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
0
100
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
160
Data Visualization Tools in the Age of AI
flekschas
0
160
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
200
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
420
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
800
Claude Code × autoresearch 実践
mathbullet
0
170
LLM Compute Infrastructure Overview
karakurist
2
1.5k
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
300
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
130
Cross-Media Information Spaces and Architectures
signer
PRO
0
300
Featured
See All Featured
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
330
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Fireside Chat
paigeccino
42
4k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Accessibility Awareness
sabderemane
1
140
エンジニアに許された特別な時間の終わり
watany
107
250k
Producing Creativity
orderedlist
PRO
348
40k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
740
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.3k
We Have a Design System, Now What?
morganepeng
55
8.2k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
620
Transcript
BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs
and LSTMs 長岡技術科学大学 自然言語処理研究室 上脇優人 Mathieu Cliche Bloomberg SemEval-2017 pp573-580 5月文献紹介 ※sentiment=感情としています
Abstract •内容は,SoTAを達成したTwitterの感情分類 器(CNNとLSTM)について. •最終的なCNNとLSTMは,再度fine tuneした SemEval-2017 Twitter datasetでトレー ニングした. •パフォーマンスを向上させるためにいくつかの
CNNとLSTMを一緒に使う. •この手法は,40のチームの中で5つの英語のサ ブタスクで1位であった. 2
Introduction •Tweetの極性を決定するタスクは,タスクの 理解がしやすく,簡単な方法で良い結果を得る ことが可能. •SemEval-2017のコンペは,5つのサブタス ク. • (タスクの種類については,Rosenthal et al.,2017を参照)
•深層学習の手法は,いくつかのNLPタスクで従 来の手法を大幅に凌駕していて感情分析も例外 でない. •感情分析においても有用な深層学習のCNNと LSTMを用いて(組み合わせたりして)感情分 類器を構築する. 3
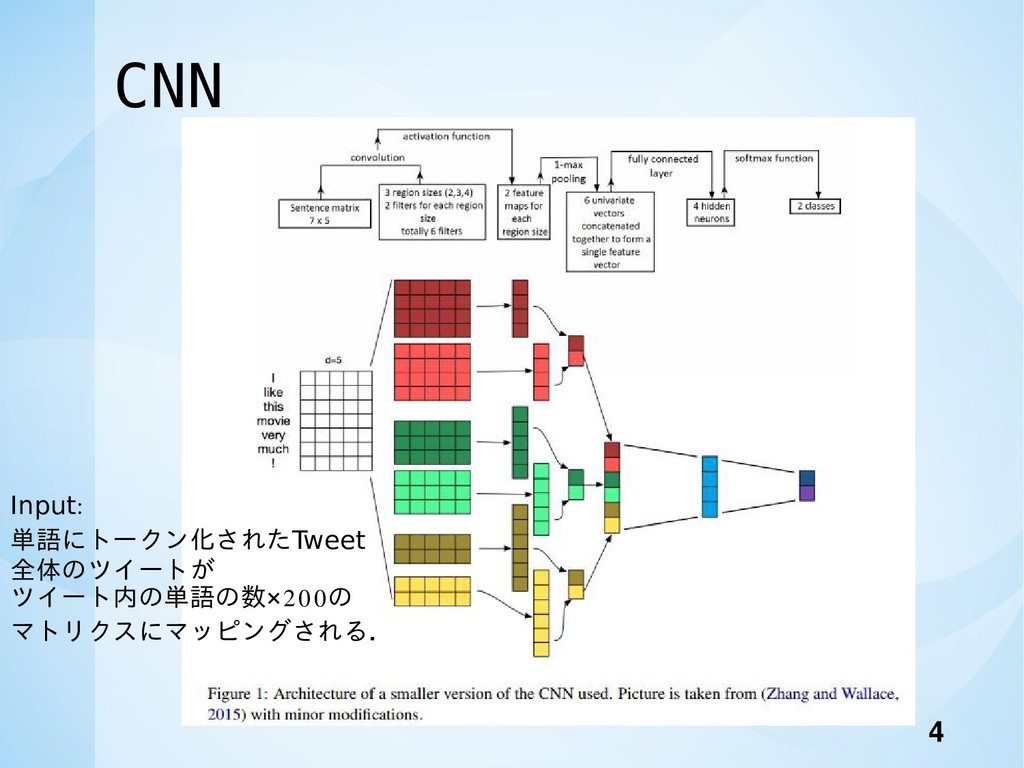
CNN 4 Input: 単語にトークン化されたTweet 全体のツイートが ツイート内の単語の数×200の マトリクスにマッピングされる.
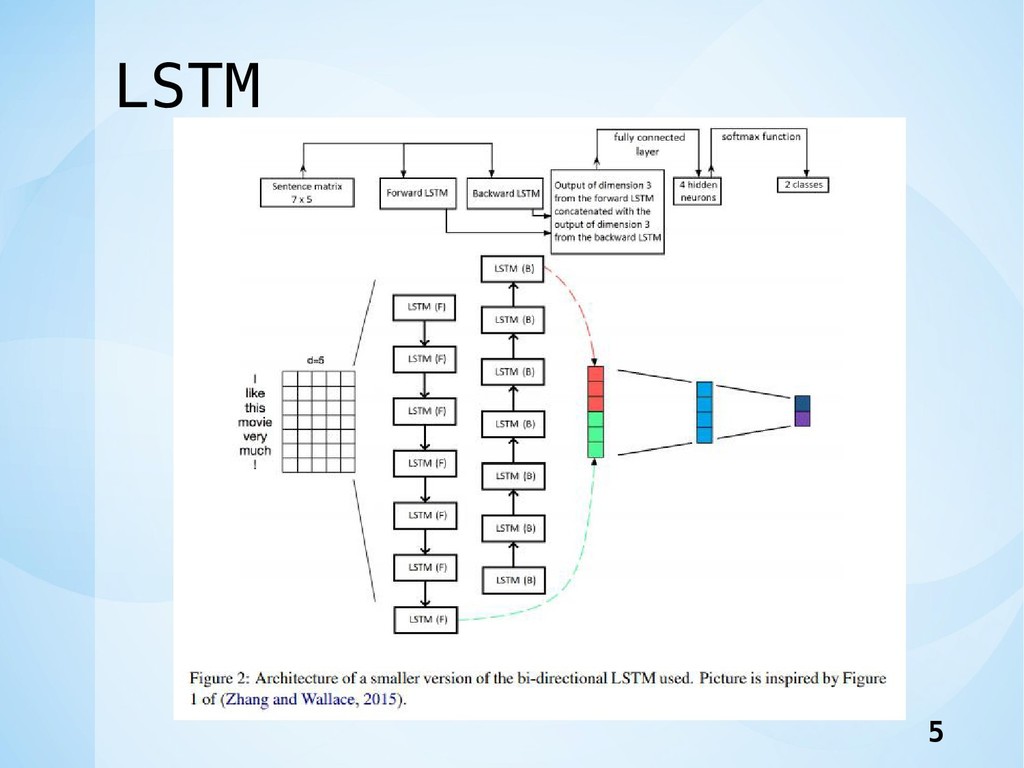
LSTM 5
Training •subtask A: • 49693 human labeled tweets •subtask C
and E: • 30849 human labeled tweets •subtask B and D: • 18948 human labeled tweets •上記のデータの他に1億の英語のツイートを取 得し,500万のポジティブツイートと500万の ネガティブツイートのデータ抽出. ※:)等はポジティブになっている 6
Unsupervised training •取得した1億のラベルなしデータを使用. •学習に使用したモデルは,下記3種類のアルゴ リズム. • Word2vec • FastText •
GloVe •全てのアルゴリズムにおいて論文著者が提供す るコードをデフォルトで使用. 7
Distant training •極性情報を追加するためにDistant training. •Distant trainingには、CNNを使用し,初 期値は教師なしフェーズで学習した embeddingを使用. •次に,抽出した500万のポジティブツイートと 500万のネガティブツイートのデータを用いて
CNNをtrainingしてノイズを分類. 8
Supervised training •このtrainingでは,SemEval-2017から提 供されるhuman labeled tweetsを使用す る. •CNNとLSTMのembeddingの初期値は,前のフ ェーズでfine tuneされた
embedding.(epoch:1~5) •モデルはTensorFlowで実装され、実験は GeForce GTX Titan X GPUで実行. •分散を軽減し、精度を向上させるために、10 のCNNと10のLSTMを統合. 9
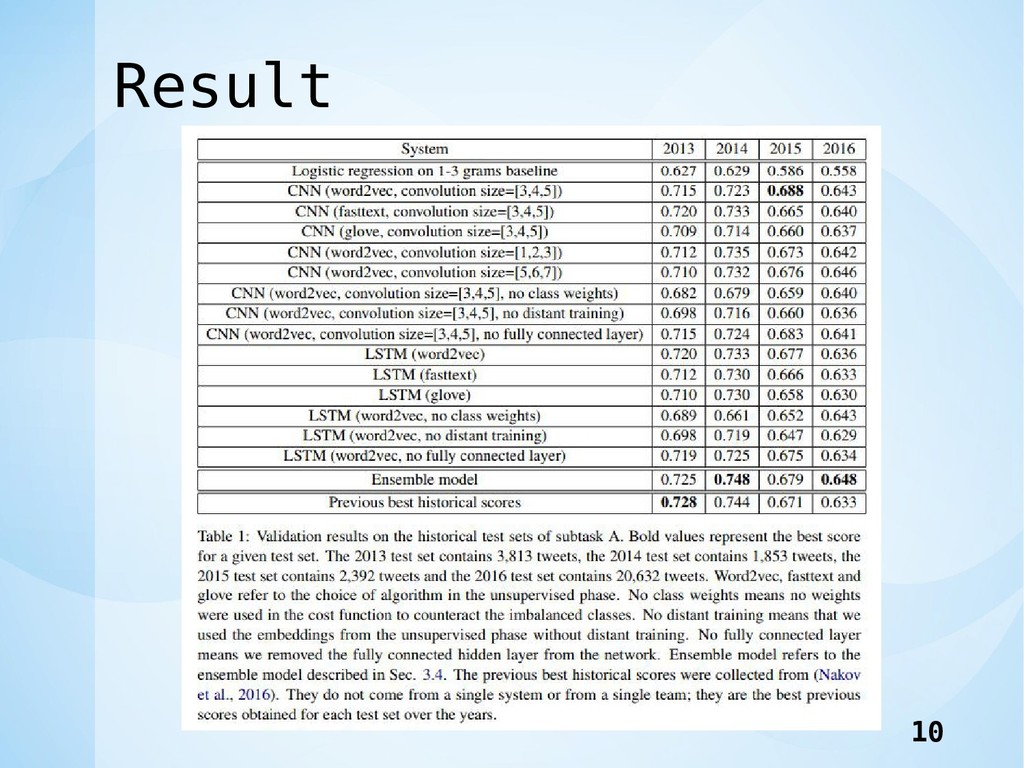
Result 10
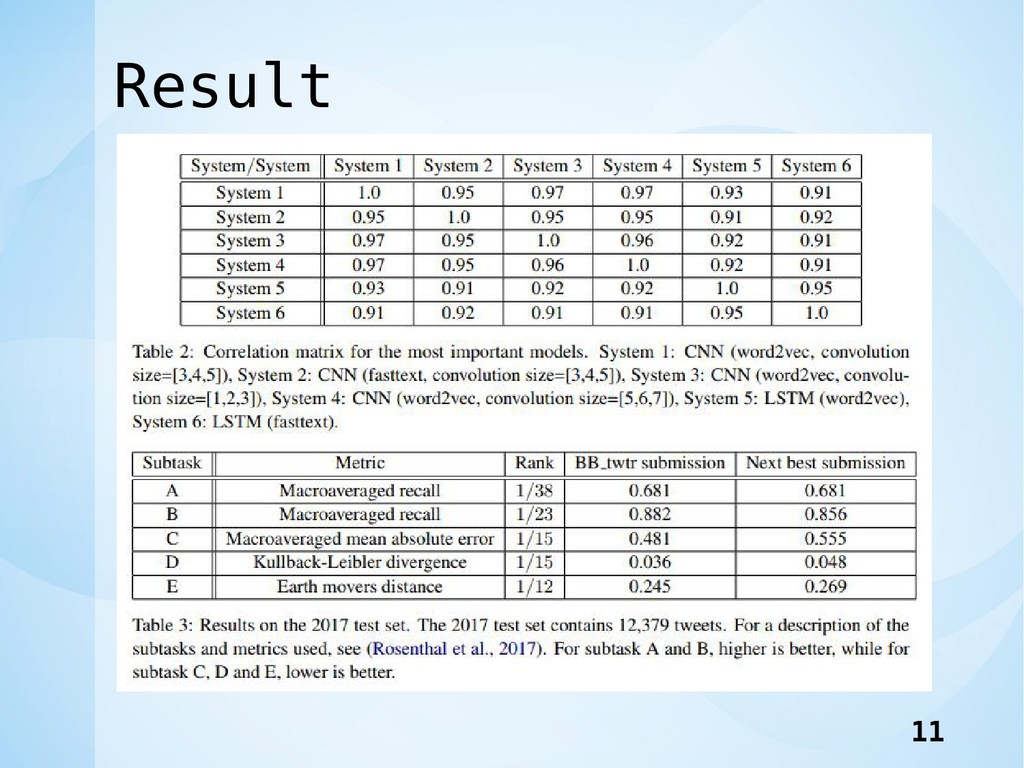
Result 11
Conclusion •SemEval-2017 Twitter sentiment analysis competitionのpaper. •Tweetの分類器を現代のtraining法に加えて 深層学習のモデルで実験した. •最後のモデルは,10のCNNと10のLSTMを用い た.(異なるハイパーパラメータ・トレーニン
グ). •参加したタスク全てで1位だった. 12
Future work •CNNとLSTMを組み合わせたモデルの探求 •unlabeled dataとdistant dataの量によ るモデルのパフォーマンスの変化の調査 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}