Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Sentiment Analysis: It’s Complicated!
Search
Yuto Kamiwaki
September 20, 2018
Research
93
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Sentiment Analysis: It’s Complicated!
2018/09/21文献紹介の発表内容
Yuto Kamiwaki
September 20, 2018
More Decks by Yuto Kamiwaki
See All by Yuto Kamiwaki
Emo2Vec: Learning Generalized Emotion Representation by Multi-task Training
yuto_kamiwaki
0
120
Modeling Naive Psychology of Characters in Simple Commonsense Stories
yuto_kamiwaki
1
220
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
yuto_kamiwaki
0
120
Epita at SemEval-2018 Task 1: Sentiment Analysis Using Transfer Learning Approach
yuto_kamiwaki
0
140
Tensor Fusion Network for Multimodal Sentiment Analysis
yuto_kamiwaki
0
280
ADAPT at IJCNLP-2017 Task 4: A Multinomial Naive Bayes Classification Approach for Customer Feedback Analysis task
yuto_kamiwaki
0
180
EmoWordNet: Automatic Expansion of Emotion Lexicon Using English WordNet
yuto_kamiwaki
0
120
ATTENTION-BASED LSTM FOR PSYCHOLOGICAL STRESS DETECTION FROM SPOKEN LANGUAGE USING DISTANT SUPERVISION
yuto_kamiwaki
0
160
BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs
yuto_kamiwaki
0
260
Other Decks in Research
See All in Research
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
1k
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
350
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
830
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
220
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
0
100
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
120
2026-01-30-MandSL-textbook-jp-cos-lod
yegusa
1
1.4k
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
120
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
320
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
3.9k
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
570
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
210
Featured
See All Featured
Speed Design
sergeychernyshev
33
1.9k
A better future with KSS
kneath
240
18k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
290
How to Ace a Technical Interview
jacobian
281
24k
Practical Orchestrator
shlominoach
191
11k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Believing is Seeing
oripsolob
1
150
Skip the Path - Find Your Career Trail
mkilby
1
150
Unsuck your backbone
ammeep
672
58k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.3k
The Curse of the Amulet
leimatthew05
2
13k
Transcript
Sentiment Analysis: It’s Complicated! 長岡技術科学大学 自然言語処理研究室 上脇優人 Kian Kenyon-Dean,Eisha Ahmed,Scott
Fujimoto, Jeremy Georges-Filteau,Christopher Glasz, Barleen Kaur,Auguste Lalande,Shruti Bhanderi, Robert Belfer,Nirmal Kanagasabai,Roman Sarrazingendron,Rohit Verma,2Derek Ruths McGill University, Department of Computer Science Proceedings of NAACL-HLT 2018, pages 1886–1895 9月文献紹介
Abstract • 感情分析のデータセットでは,適切なラベルに大きな不一致がある場合, 「ノイズの多い」または「複雑な」データを破棄することが一般的で す. • Twitter Sentiment Analysis(TSA)の目的で構築されたデータセ ットでは,上記の様なデータが,最初にアノテーションしたデータの
30%以上を構成している. • 上記の様なデータの削除は,短文のReal-time sentiment Classificationを実行するとき,自動化されたシステムがどのよう なサンプルが上記の様なカテゴリに入るかを事前に知ることができない ため,問題がある. • したがって,このようなテキストを分類するための「複雑な」クラスの 感情の概念を提案し,短文のSentiment analysisフレームワークに 含めることで,現実の設定で実装されるAutomatic sentiment analysis systemの品質が向上すると考えた. 2
Introduction • ツイートの感情を自動的に判断できるTSAモデルを構築す ることは,ここ数年で大きな注目を集めている. • しかし,最新のTSAモデルでは機械学習を使用してパラメ ータを調整しているため,実際の実装環境との関連性やパ フォーマンスは,訓練されたデータセットに大きく依存す る. •
残念ながら,TSAデータセットの構築には,TSAモデルの 設計よりも注意が払われていない. 3
4
Current Problems in TSA • TSAデータセットを構築するときに,多くのデータをフィ ルタリングしてしまっている. • 研究者は,もっと実世界の環境で使用することを想定して データセットを構築しないといけない.
• 例えば,ツイートがSTRONGLY NEGATIVEを2つ, STRONGGLY POSITIVEを2つ,NEUTRALのラベルを1つ受 け取った場合,結果のラベルはNEUTRALになります。 • しかし,ツイートは確かに「ニュートラル」ではないだろ うが,ニュートラルのラベリングに関する全会一致でツイ ートと質的に異なる. 5
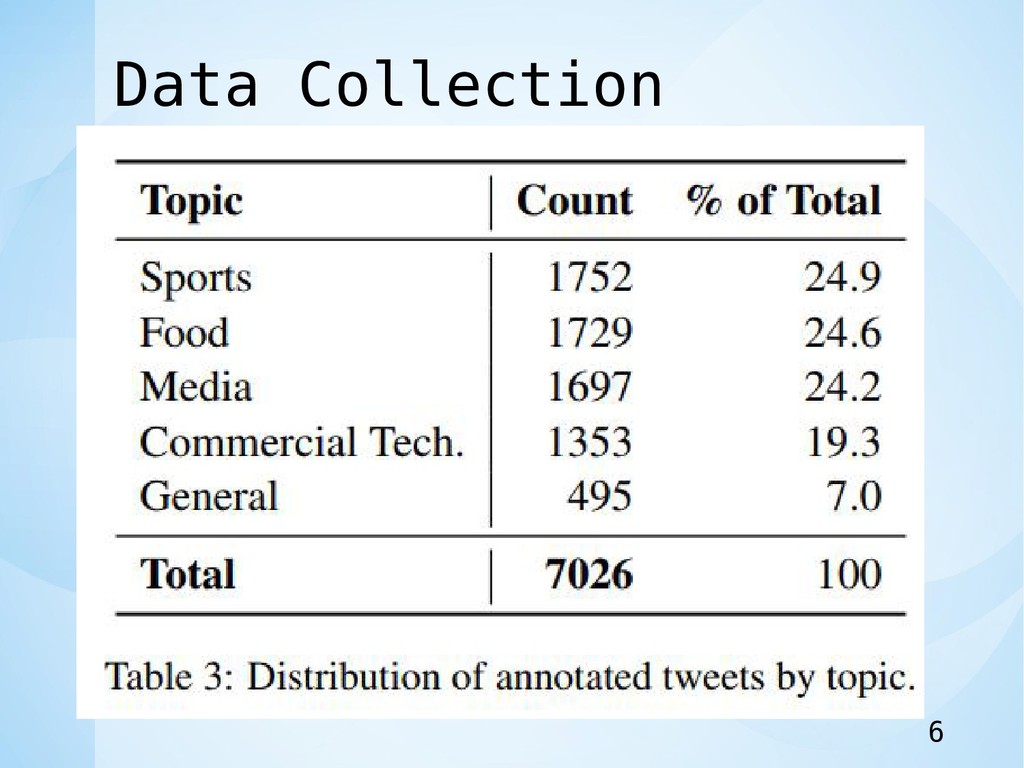
Data Collection 6
Data Annotation • データのアノテーションには,CrowdFlowerプラットフ ォームを使用した. • 指示書では,ツイートに表現された感情があいまいである か,混在しているか,または肯定的/否定的なものとして 解釈される可能性がある場合に,COMPLICATEDが好まし い選択肢として提示された。
• 181人の信頼できる投稿者によって合計35,926件のタス クが完了し,7,026個の注釈付きツイートを作成. 7
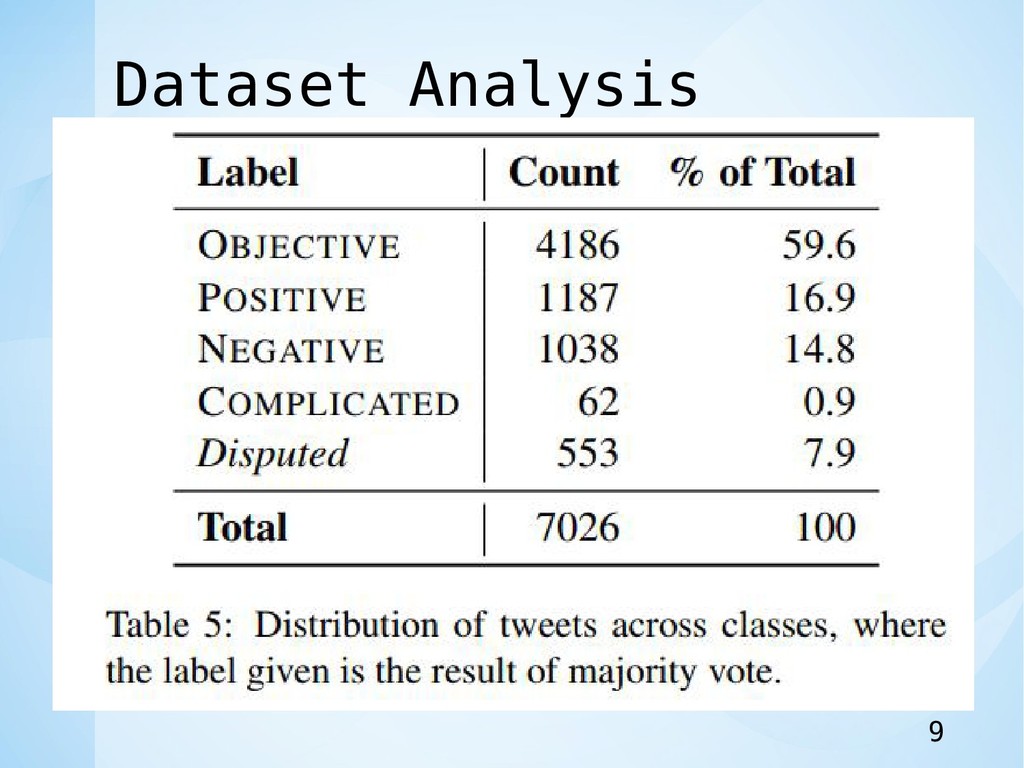
Dataset Analysis • 注釈付きのツイートは,満場一致(5つのうち5つがラベル で合意),コンセンサス(5つのうち4つが合意),多数 (5つのうち3つが合意),またはそれ以外. 8
Dataset Analysis 9
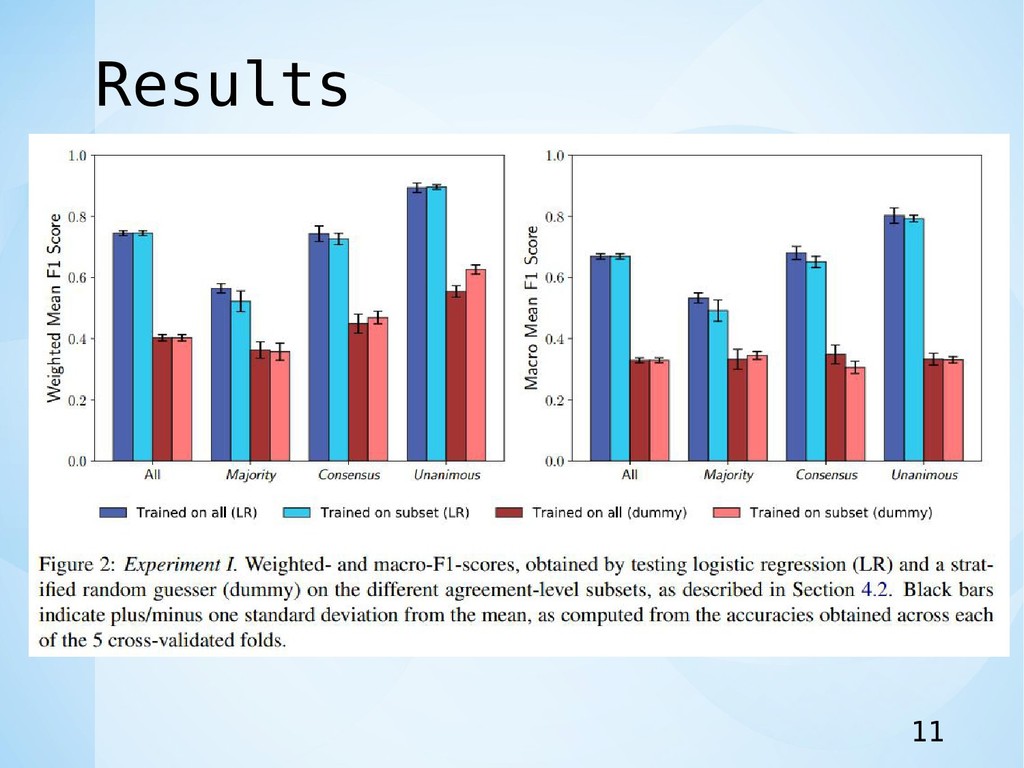
Experiment • 目的は,最適精度で最先端の分類器を構築することではな く,アノテータの不一致に基づいてツイートサブセットを 含むか除外するかが分類精度にどのように影響するかを理 解. • 実験1 • 従来通り,アノテータの不一致ツイートを削除(3クラス分類
問題) • 実験2 • アノテータの不一致ツイートを含める(4クラス分類問題) 10
Results 11
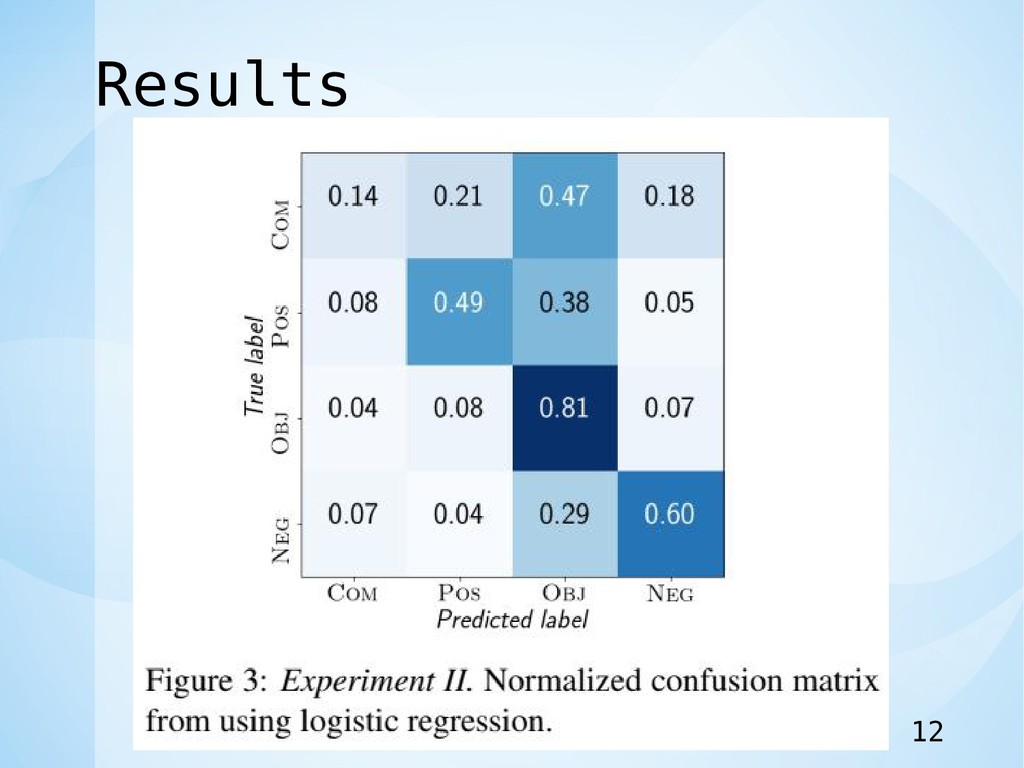
Results 12
Discussion • 我々の結果は、注釈の不一致は単に人間の誤りに起因する ものではないことを示している。 • 短いテキストの感情分析の分野を進めるためには、データ セットの設計と開発における共通のプラクティスを変更す る必要があります。 • 将来のデータセットは,アノテートされたデータを破棄す
ることなく,生の注釈ラベルの割り当てと共に公開される べきである. 13
Conclusions • McGill Twitter Sentiment Analysis(MTSA)デ ータセットを作成することによって,人間が実際に短文の Sentiment analysisデータセット構築において,デー タに注釈を付ける方法をよりよく理解する必要性を強調し
た. 14
Future work • 生の人間の注釈を利用してSentiment analysis分類子 を改善し,注釈の不一致を引き起こすこれらのサンプルの 「複雑な」特性をよりよく検出し理解する方法を見つける ことが必要. • さらに,研究者は,教師なし,レキシコンベース,および
ルールベースの方法を含む短文Sentiment analysisの ための他の方法の開発にMTSAを使用することを推奨す る. 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}