Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Whisperに耳をすませば
Search
Henry Cui
October 30, 2022
Technology
290
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Whisperに耳をすませば
Henry Cui
October 30, 2022
More Decks by Henry Cui
See All by Henry Cui
プロダクション言語モデルの情報を盗む攻撃 / Stealing Part of a Production Language Model
zchenry
1
260
Direct Preference Optimization
zchenry
0
470
Diffusion Model with Perceptual Loss
zchenry
0
530
レンズの下のLLM / LLM under the Lens
zchenry
0
240
Go with the Prompt Flow
zchenry
0
230
Mojo Dojo
zchenry
0
270
ことのはの力で画像の異常検知 / Anomaly Detection by Language
zchenry
0
740
驚愕の事実!LangChainが抱える問題 / Problems of LangChain
zchenry
0
330
MLOps初心者がMLflowを触る / MLflow Brief Introduction
zchenry
0
220
Other Decks in Technology
See All in Technology
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
720
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
400
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
370
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.1k
reFACToring
moznion
0
180
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
25
11k
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
480
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
1
480
[Droidcon Orlando '26] The Android Lens: Applying Mobile Forensics to AI Performance
amanda_hinchman
1
110
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
1
160
Featured
See All Featured
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Building an army of robots
kneath
306
46k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
Practical Orchestrator
shlominoach
191
11k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Between Models and Reality
mayunak
4
380
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
WCS-LA-2024
lcolladotor
0
750
Transcript
Whisperに耳をすませば 機械学習の社会実装勉強会第16回 Henry 2022/10/30
自己紹介 ▪ 東京大学理学部情報科学科 ▪ 同大学大学院情報理工学系研究科コンピュター科学専攻 ▪ 博士(情報理工学)取得 • ICMLなどの国際・国内学会・ジャーナルに論文発表 •
学振DC2・理研AIPセンター研究パートタイマー • AIPチャレンジなどの競争的研究費取得・外国大学への訪問 ▪ 在学中に株式会社パンハウスを共同創業 2
内容 ▪ Whisperとは ▪ 誰でも試せるデモ ▪ Whisperを使ったアプリケーション 3
Whisperは音声認識モデル Whisperは最近OpenAIがオープンソースした音声認識モデル で、学習済み重みも公開されている 特徴は以下三つ ▪ シンプルなEnd-to-end Transformerベースのモデル ▪ 膨大な教師つき学習データ ▪
多タスクで訓練されて、多タスクを遂行できる 4
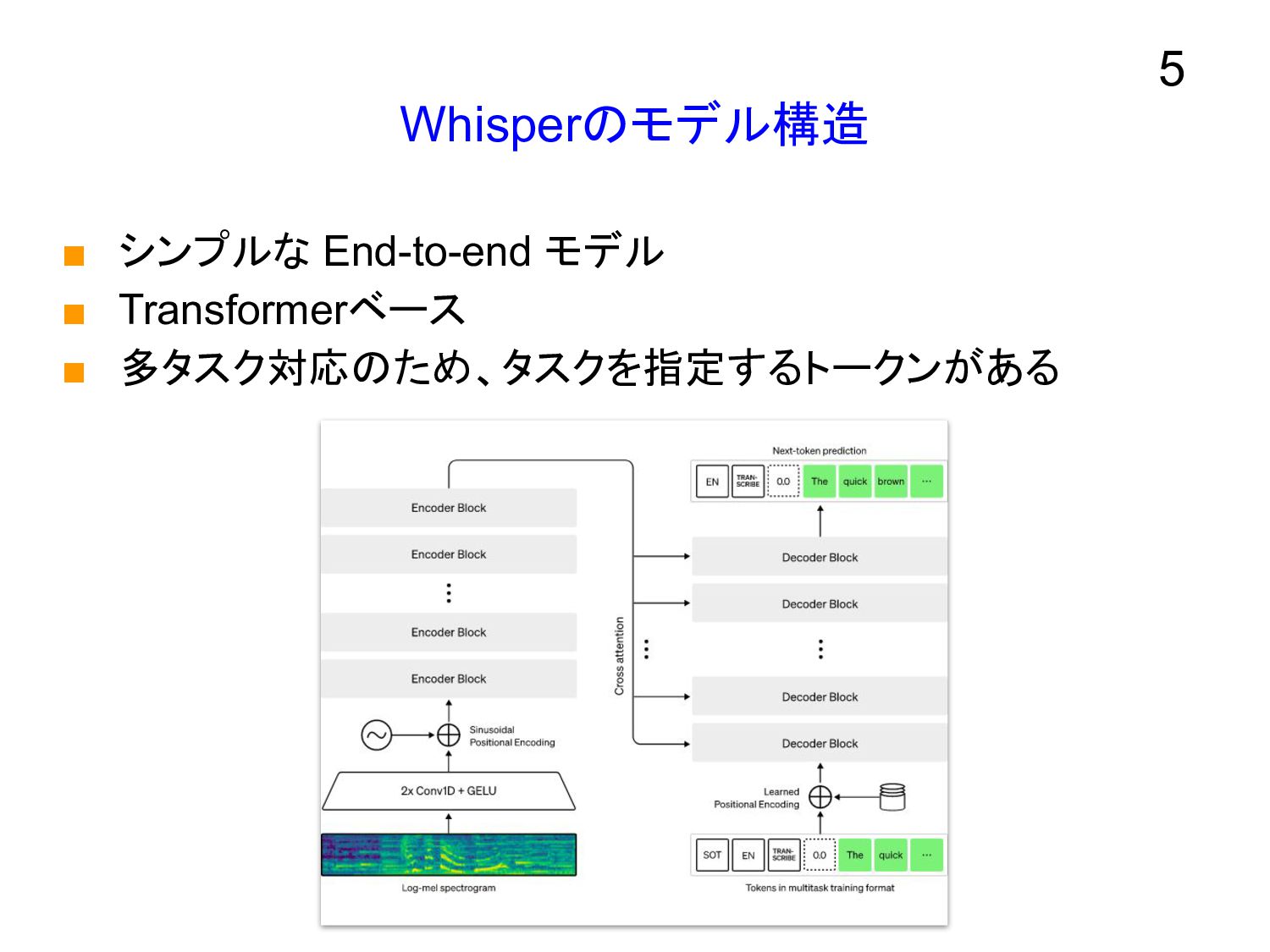
Whisperのモデル構造 ▪ シンプルな End-to-end モデル ▪ Transformerベース ▪ 多タスク対応のため、タスクを指定するトークンがある 5
Whisperが学習したデータ ▪ 膨大かつ教師つきのデータセットを使うのは初 • 既存手法は、少ない教師つきデータか、膨大な教師なしデータでしか 学習できていない ▪ 総計68万時間(約78年)になる • 従来使われる教師つきデータのおよそ10倍のサイズ
• データ増しによる性能改善の余地はまだある(scaling law) ▪ 三分の一が非英語 • 公式ブログではスペイン語・韓国語の認識例が挙げられている • もちろん日本語音声も認識可能 • 99言語に対応との紹介も ▪ Zero-shotで頑丈性を評価 6
Whisperが遂行できるタスク ▪ 公式ブログによると、以下のタスクが遂行できる • 言語認識 ▪ 与えれた音声の言語を答える • フレーズのタイムスタンプ ▪
音声にある各フレーズのタイムスタンプを答える • 多言語スピーチ文字起こし ▪ 音声にある言語そのままの文字起こし • スピーチの英語翻訳 ▪ 音声にある言語を英語に翻訳した文字起こし ▪ ほとんどの音声・文字に関わるアプリケーションをカバー 7
内容 ▪ Whisperとは ▪ 誰でも試せるデモ ▪ Whisperを使ったアプリケーション 8
Webページとコマンドラインツール ▪ https://huggingface.co/spaces/openai/whisper ▪ pip install git+https://github.com/openai/whisper.git でイン ストールすれば、whisper audio.mp3
--model medium のよう に推論できる ▪ HuggingFaceの一つのモデルとしても使える 9
内容 ▪ Whisperとは ▪ 誰でも試せるデモ ▪ Whisperを使ったアプリケーション 10
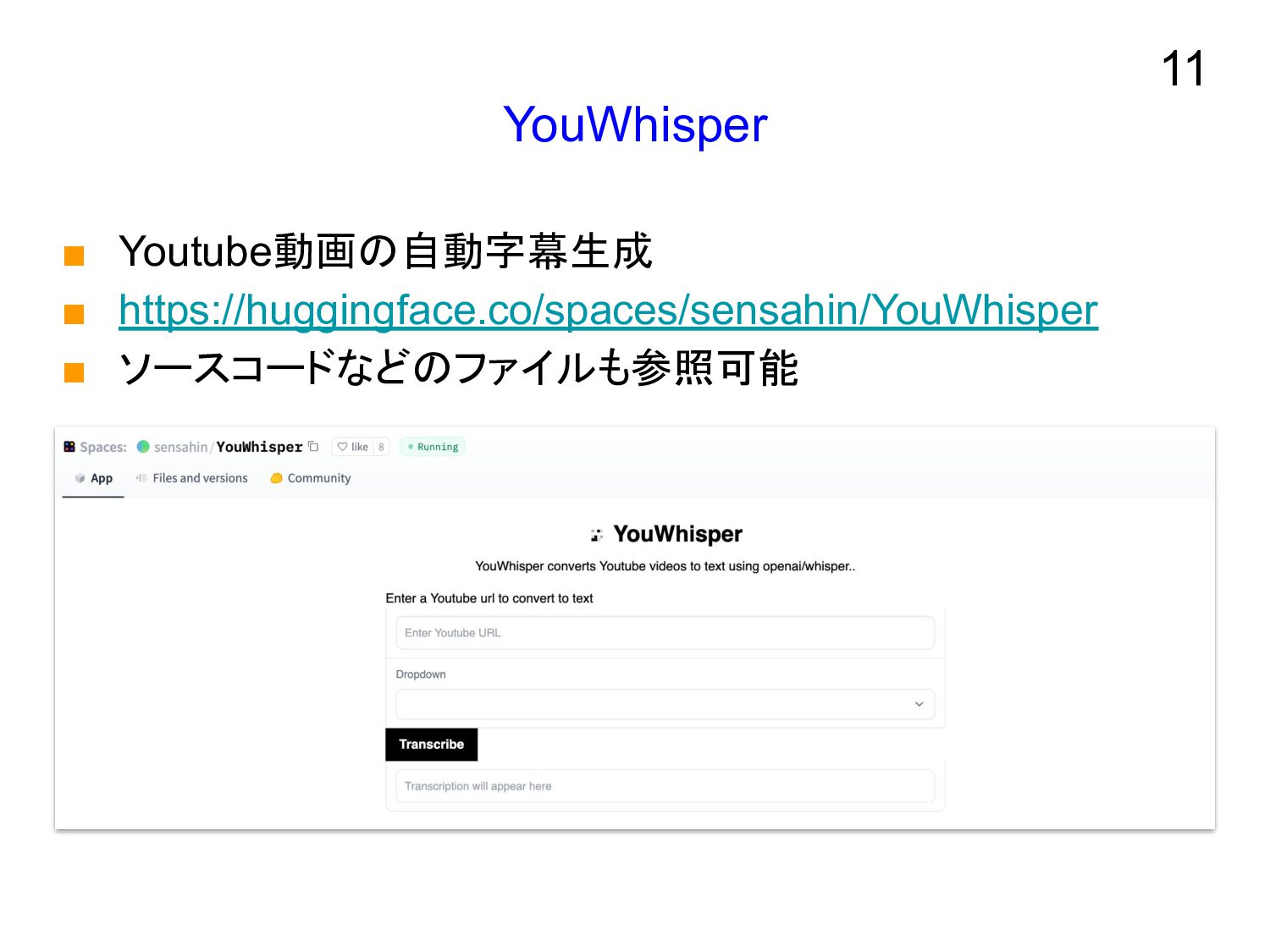
YouWhisper ▪ Youtube動画の自動字幕生成 ▪ https://huggingface.co/spaces/sensahin/YouWhisper ▪ ソースコードなどのファイルも参照可能 11
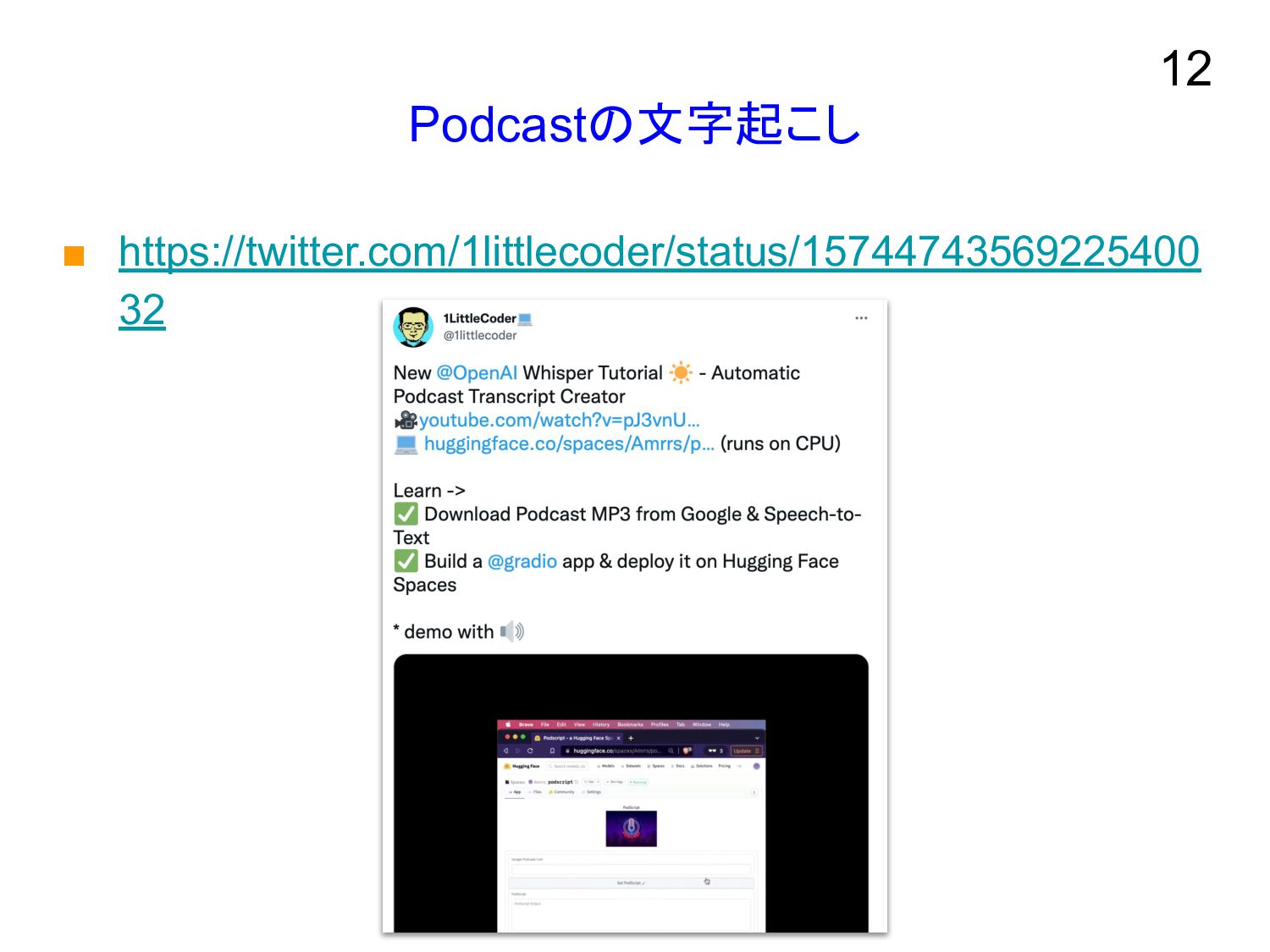
Podcastの文字起こし ▪ https://twitter.com/1littlecoder/status/15744743569225400 32 12
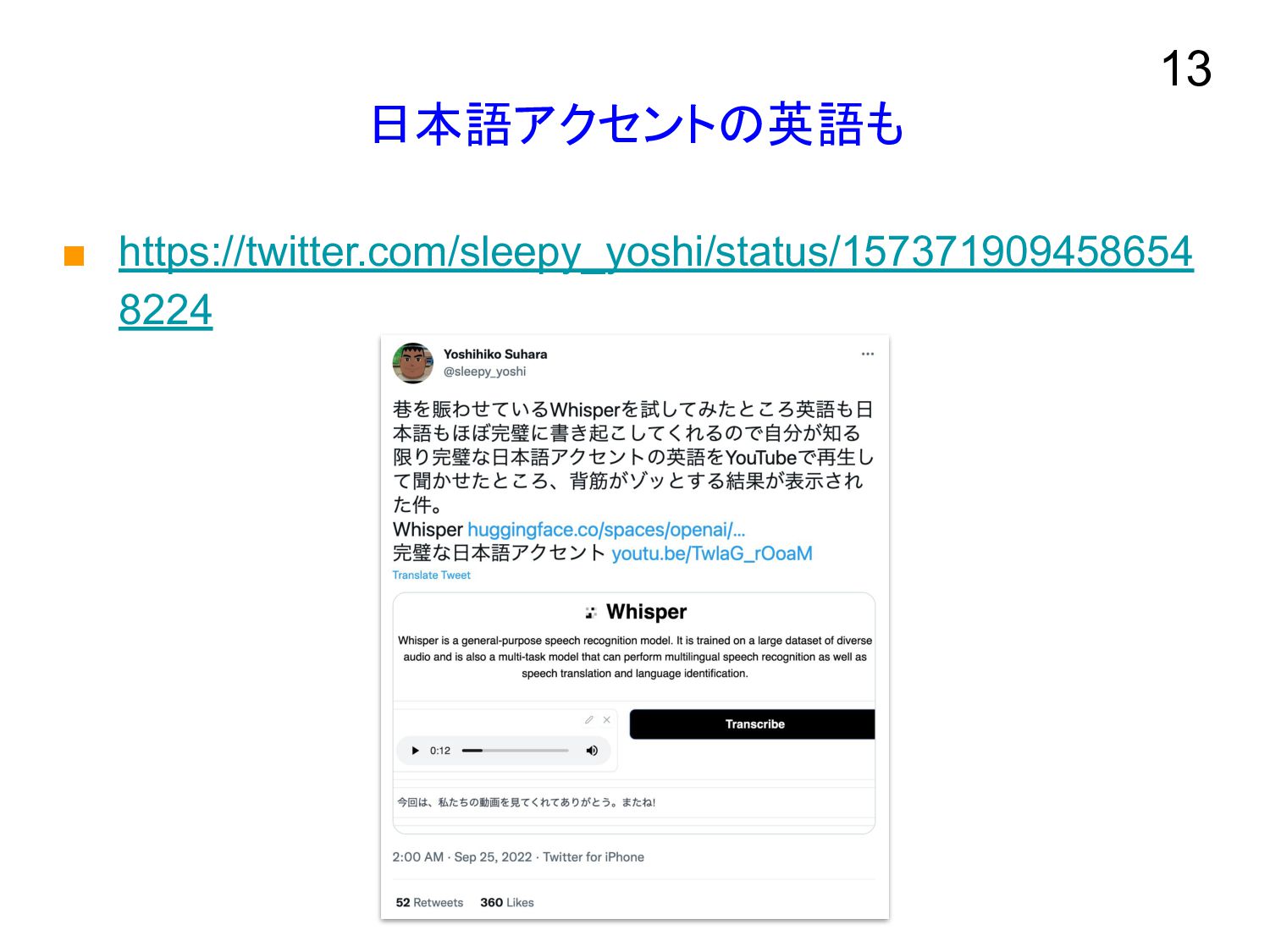
日本語アクセントの英語も ▪ https://twitter.com/sleepy_yoshi/status/157371909458654 8224 13
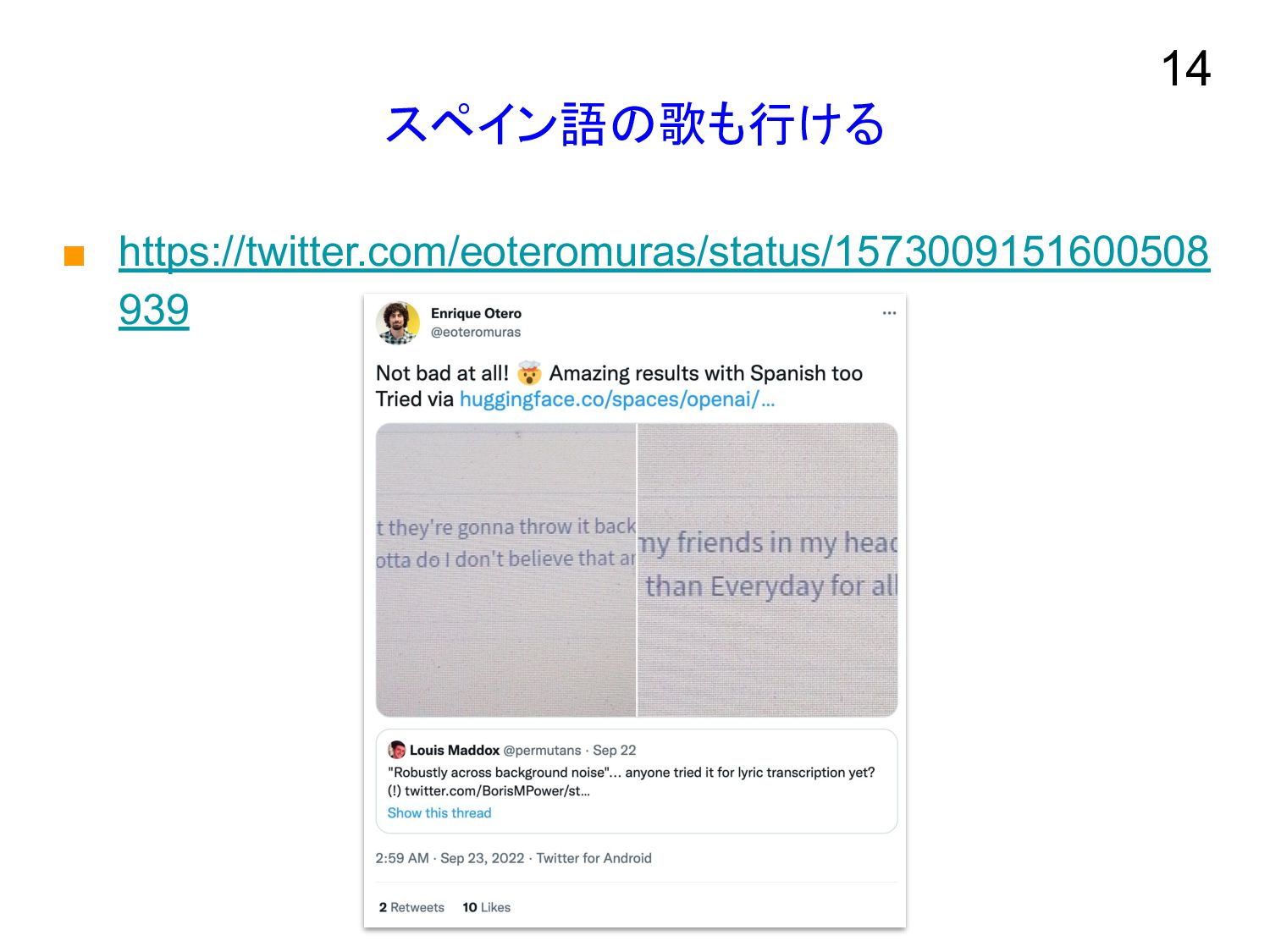
スペイン語の歌も行ける ▪ https://twitter.com/eoteromuras/status/1573009151600508 939 14
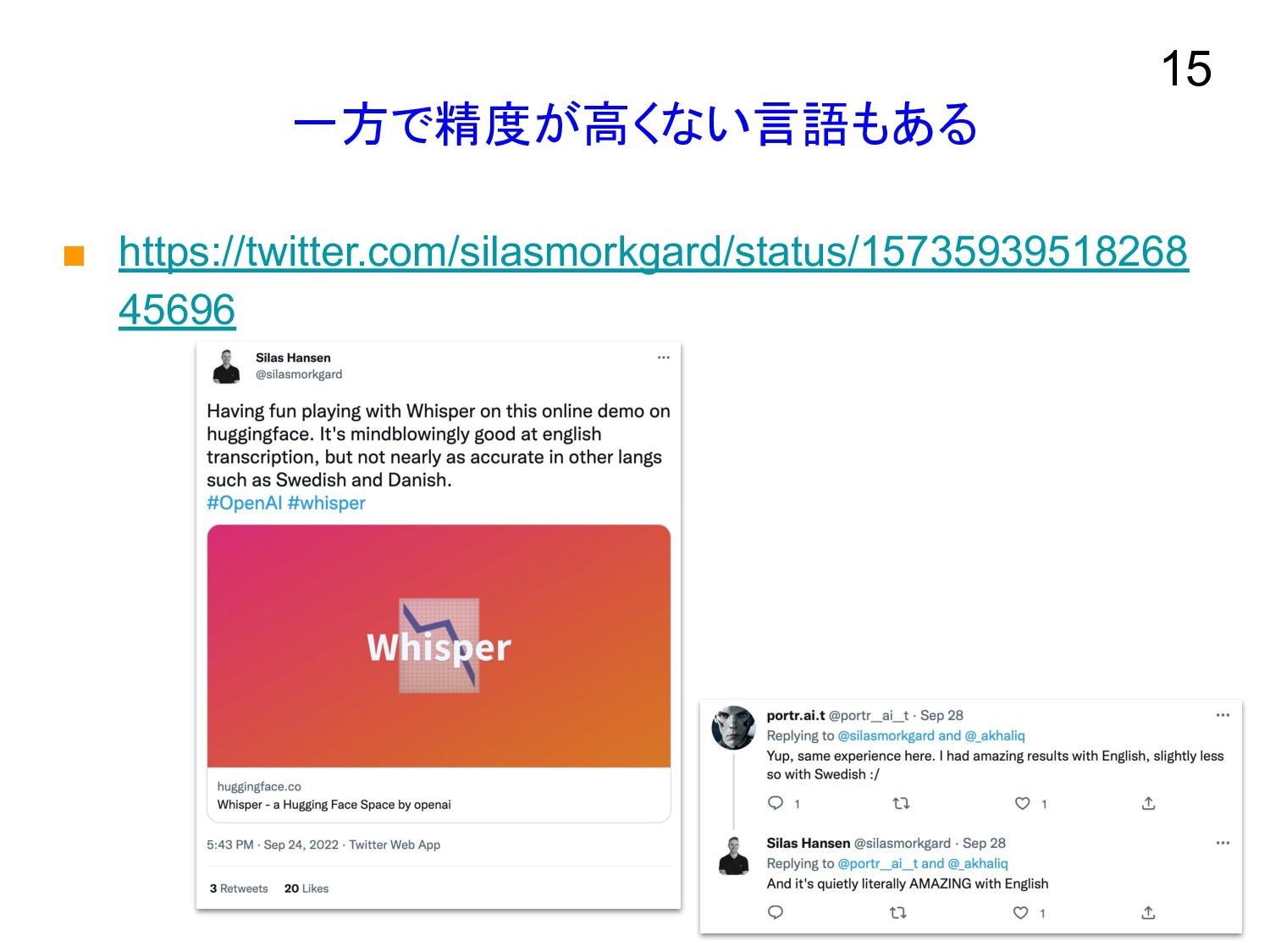
一方で精度が高くない言語もある ▪ https://twitter.com/silasmorkgard/status/15735939518268 45696 15
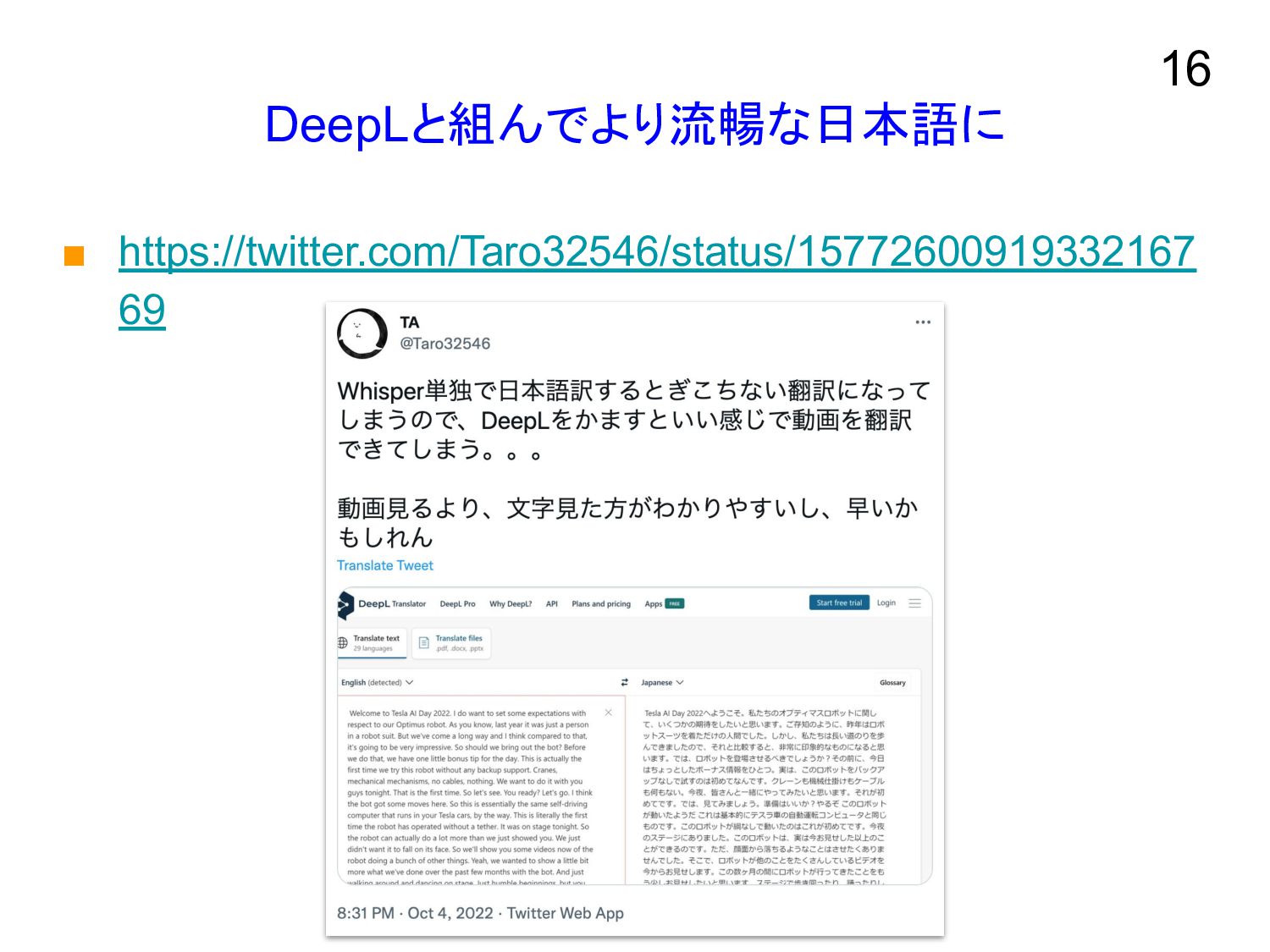
DeepLと組んでより流暢な日本語に ▪ https://twitter.com/Taro32546/status/15772600919332167 69 16
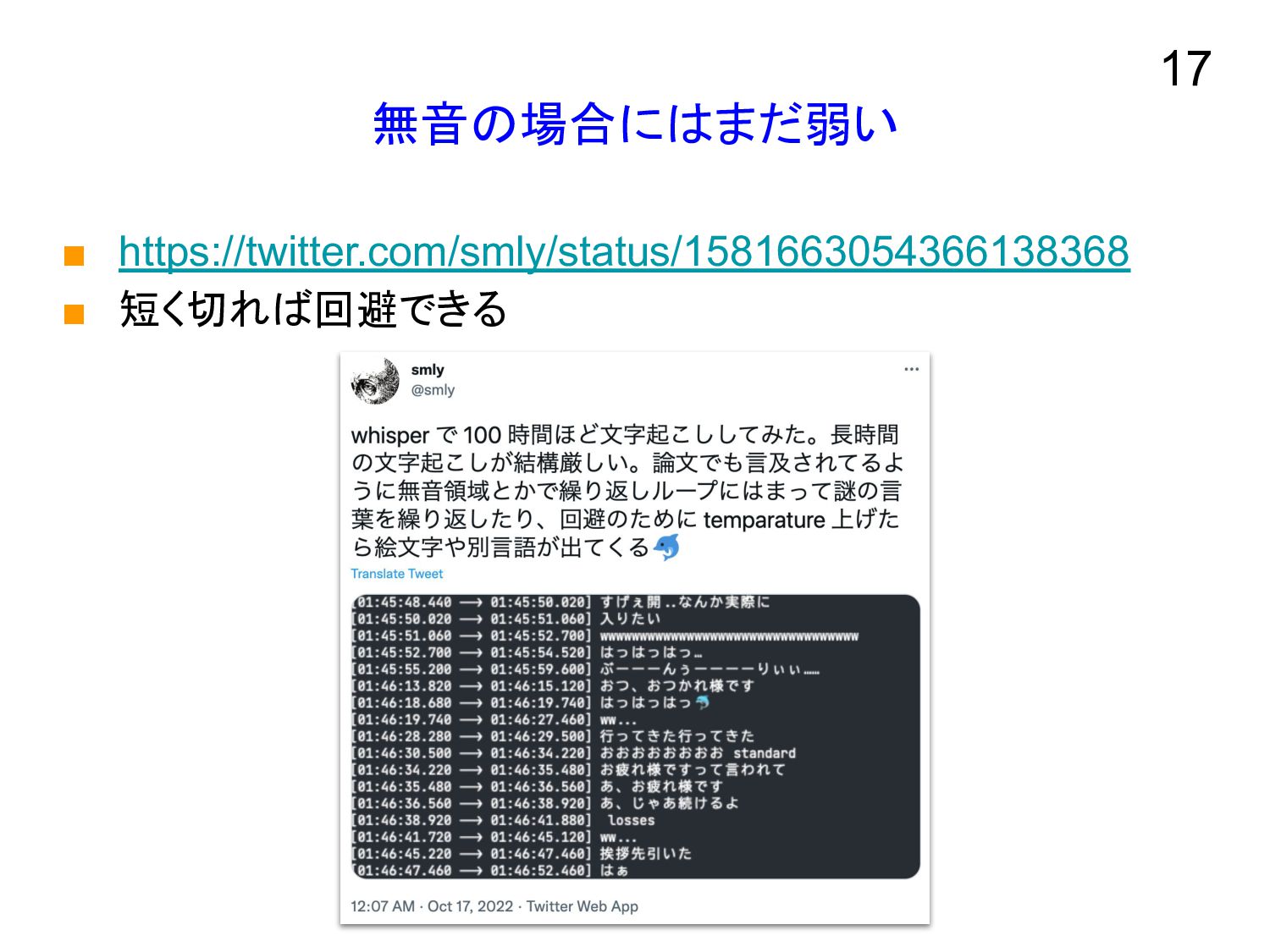
無音の場合にはまだ弱い ▪ https://twitter.com/smly/status/1581663054366138368 ▪ 短く切れば回避できる 17
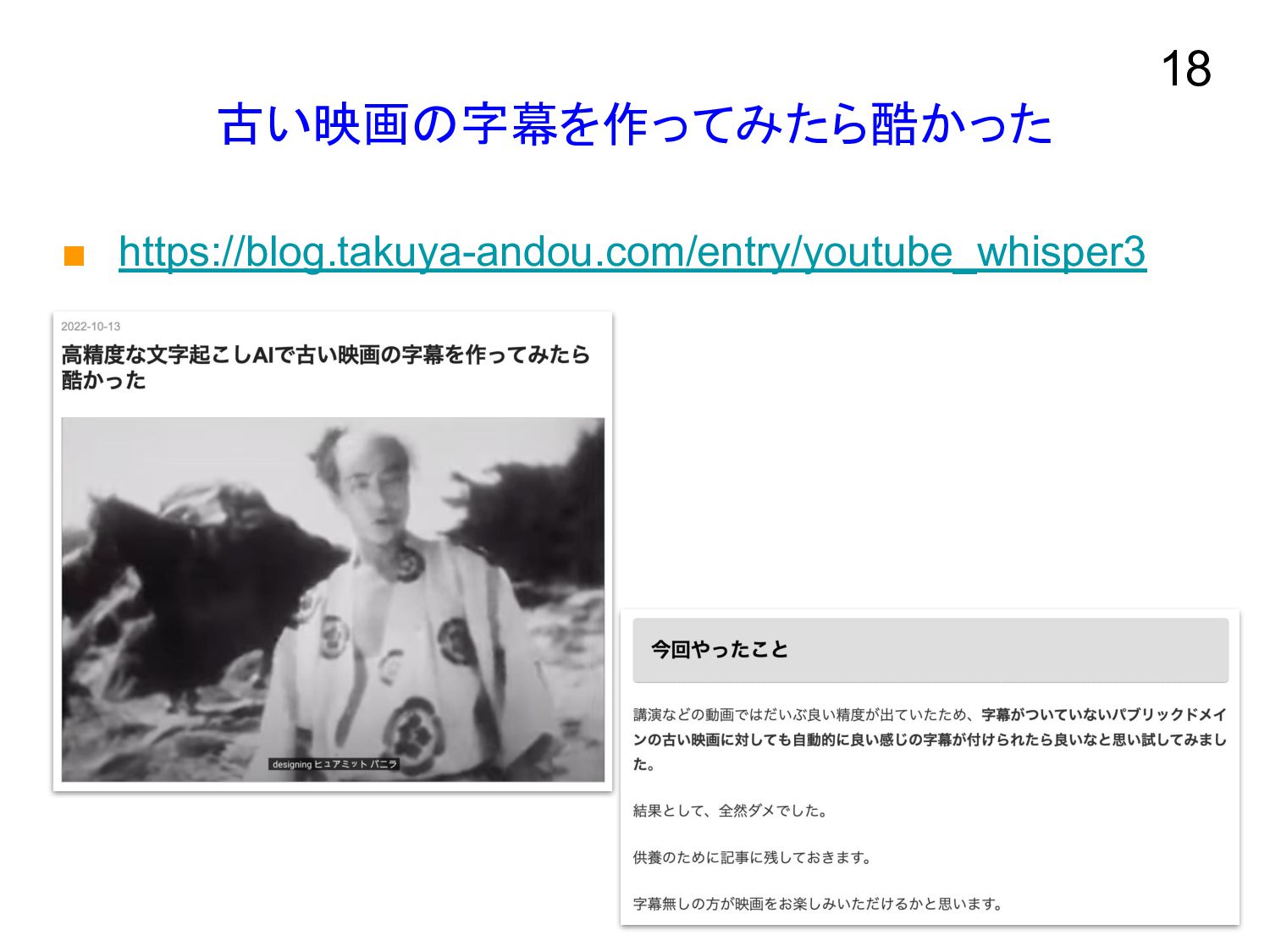
古い映画の字幕を作ってみたら酷かった ▪ https://blog.takuya-andou.com/entry/youtube_whisper3 18
まとめ ▪ OpenAIのWhisperモデルは膨大な学習データのおかげで、 多数のタスクで高性能を達成した ▪ 無音やマイナー言語などの場合にはまだ弱い時がある ▪ アプリケーションが多く展望される 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}