'db_coninfo':[{'db_ip':'192.168.1.50','db_port':3306,'db_user':'jobs','db_passwd':'hhxxttxs','db_db':'test'}], 'db_path':'test.a2', 'pre_sql':[], 'post_sql':[], 'data_save_type':'SimpleOutput', "sql_assemble":'SimpleAssemble', 'sql':'select * from test.a2 limit 30', },], "transform":[{'etl_class_name':'TransformEtl', 'step_name':'transform1', 'data_source':[{"job_name":"job1","step_name":'mysql_e_1','data_field':''},], 'data_transform_type':'SimpleTransform', },], "loading":[{'etl_class_name':'LoadingEtl', 'step_name':'load1', 'data_source':{"job_name":"job1","step_name":'transform1'}, 'db_type':'mysql', 'db_coninfo':[{'db_ip':'192.168.1.50','db_port':3306,'db_user':'jobs','db_passwd':'hhxxttxs','db_db':'test'}], 'db_path':'test.a2', 'pre_sql':[], 'post_sql':[], 'data_load_type':'SplitLoad', 'data_field':'a|b'},]} }
![Python&Hadoop构建数据仓库 从开源中来,到开源中去 EasyHadoop 童小军 [email protected] 2012年10年20日](https://files.speakerdeck.com/presentations/2532764070f701303b9822000a9f3a59/slide_0.jpg){kind=link}
{kind=link}
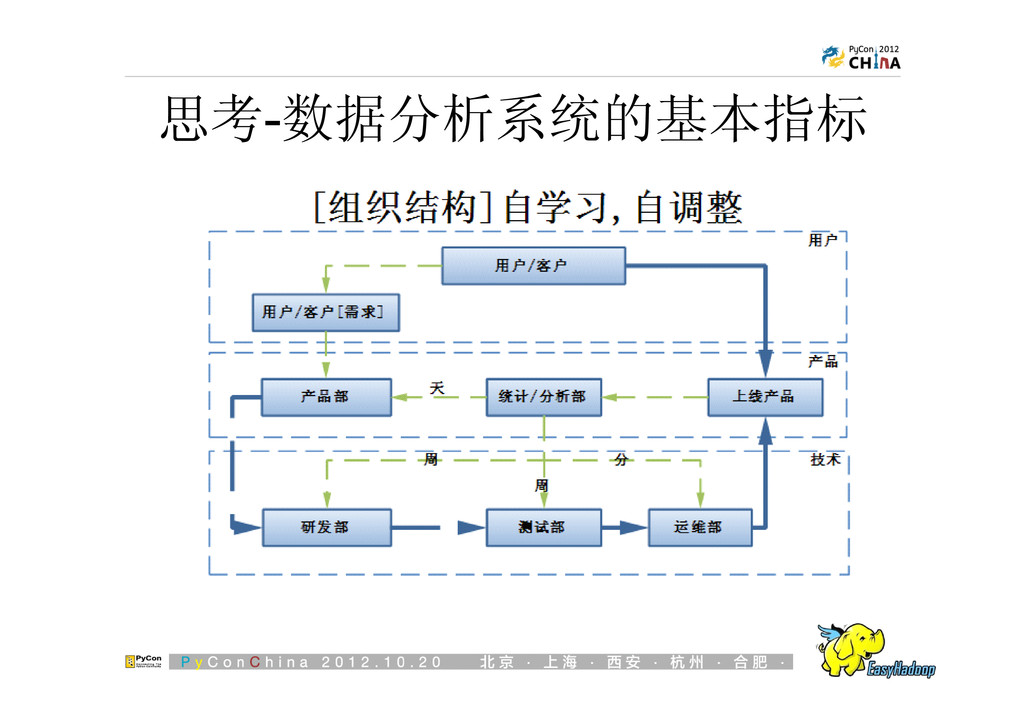{kind=link}
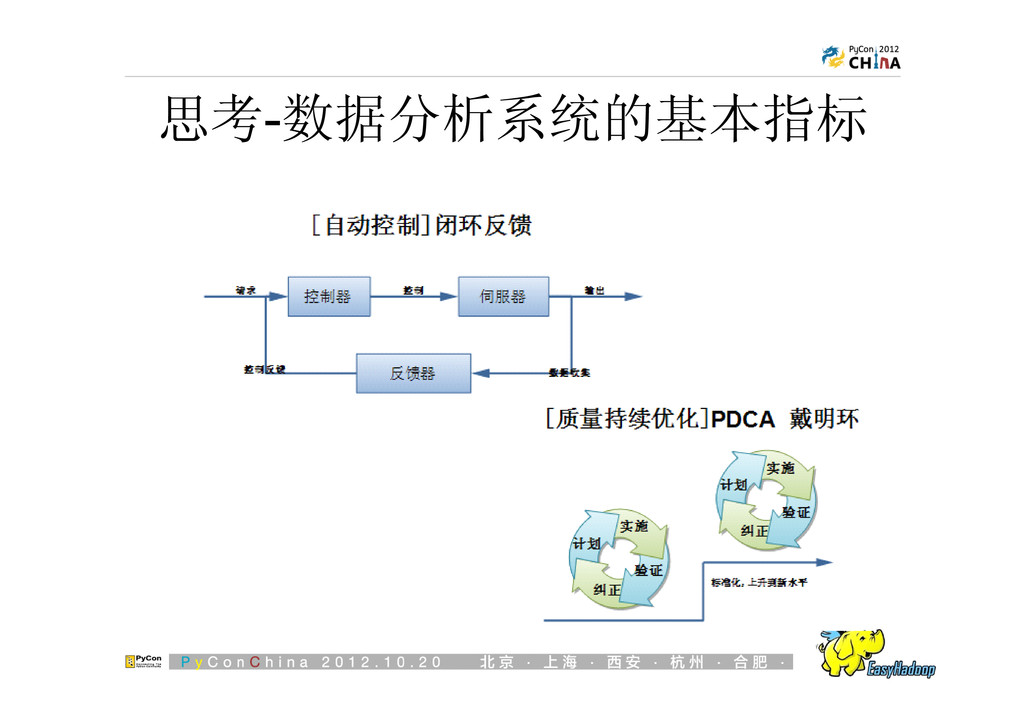{kind=link}
{kind=link}
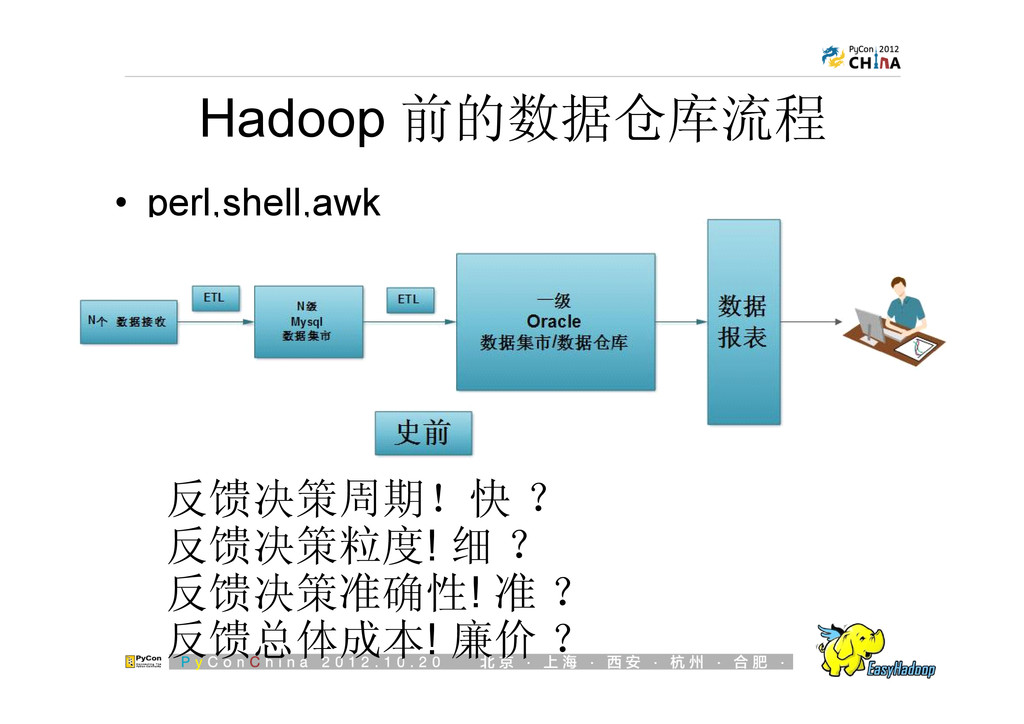{kind=link}
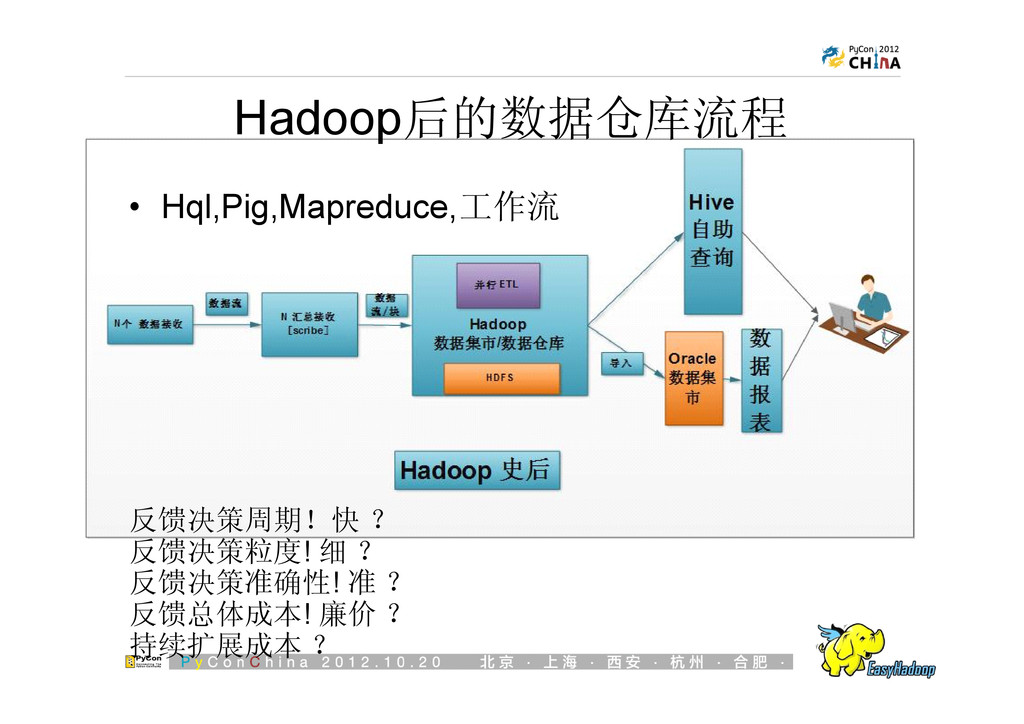{kind=link}
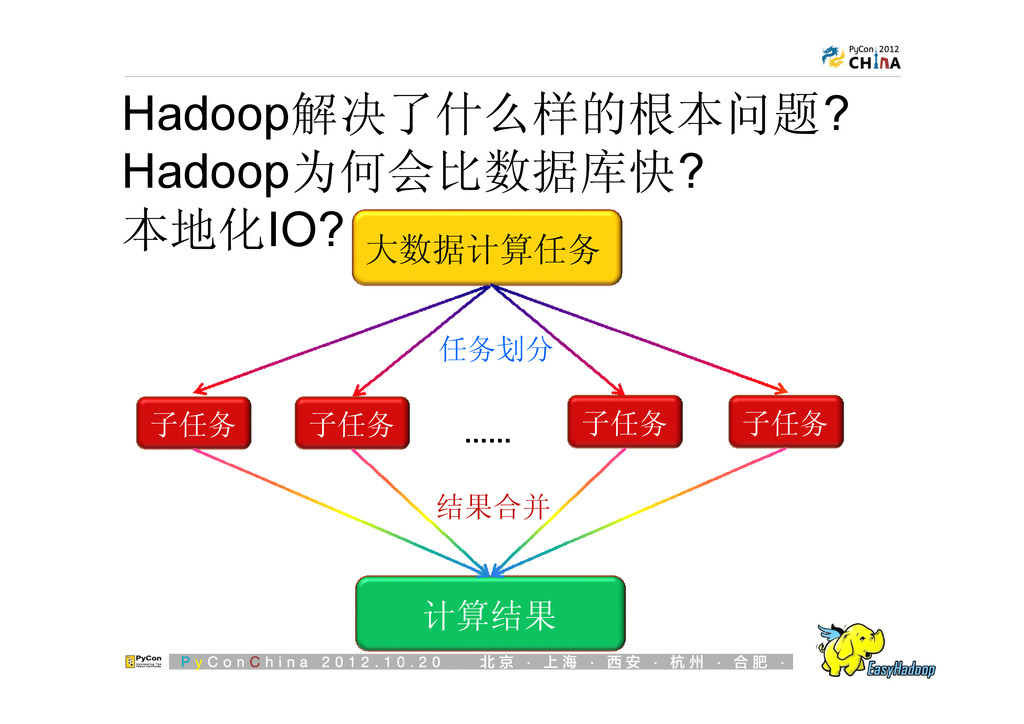{kind=link}
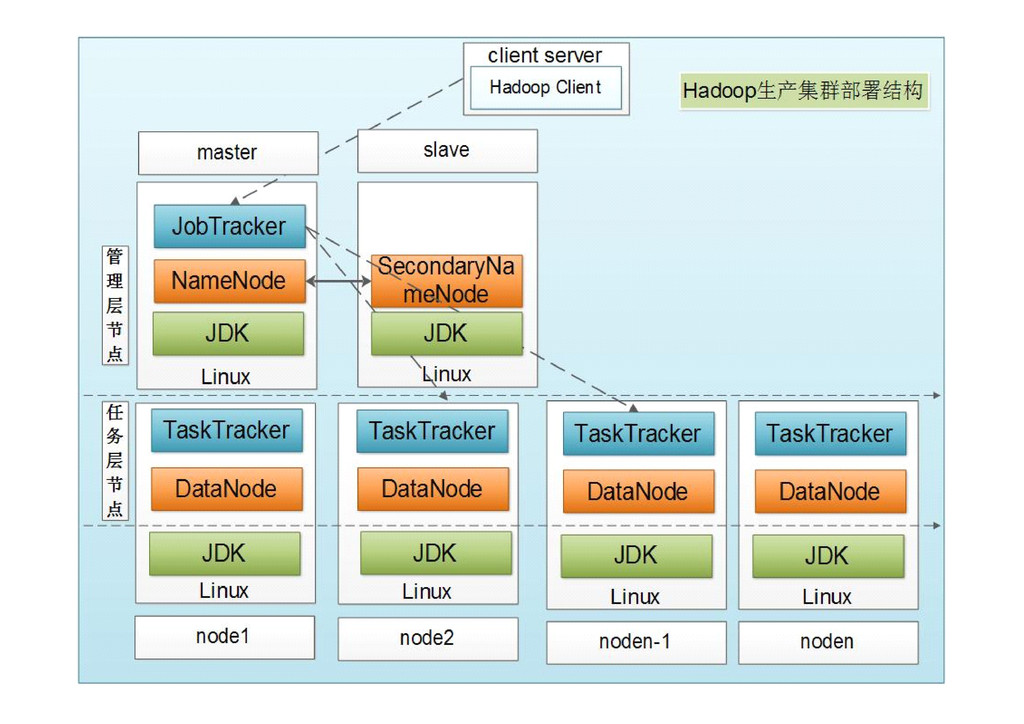{kind=link}
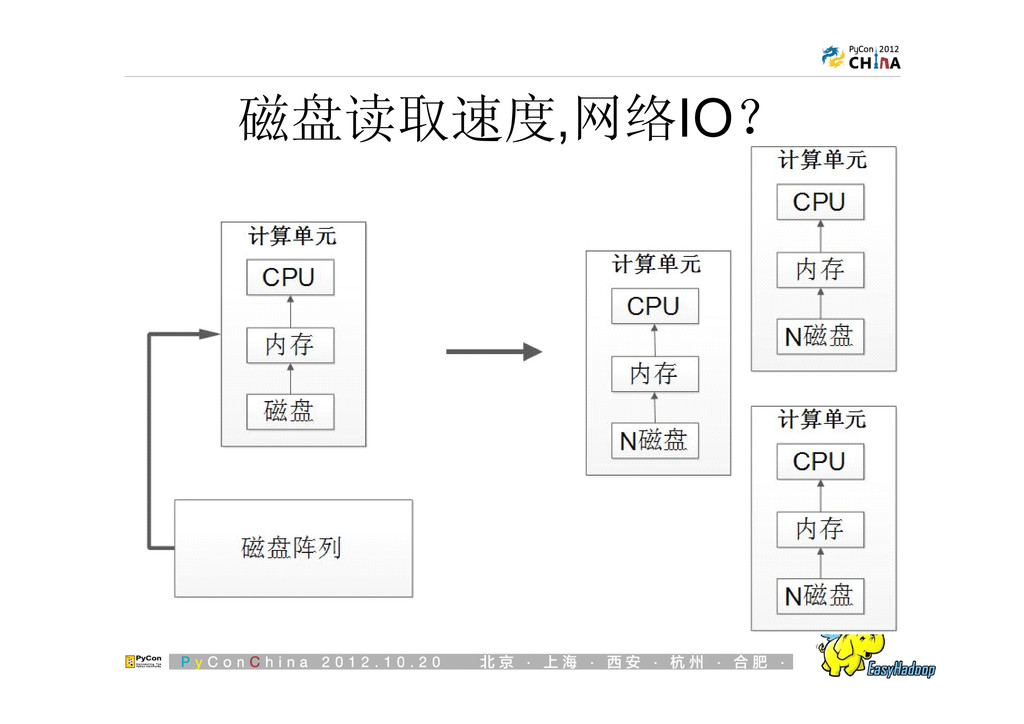{kind=link}
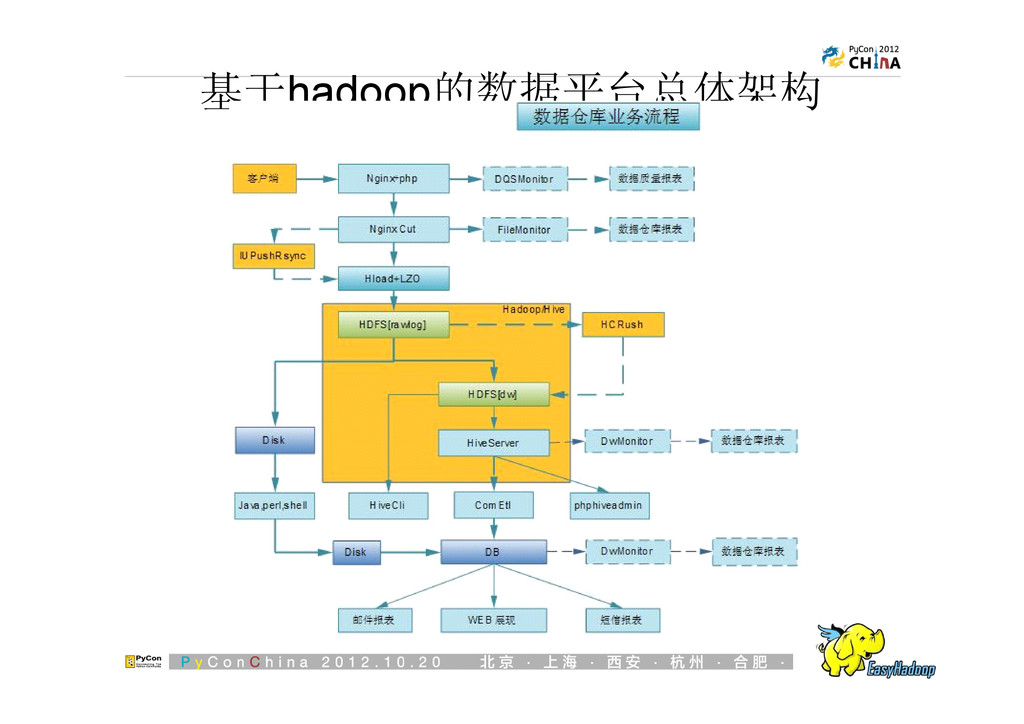{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
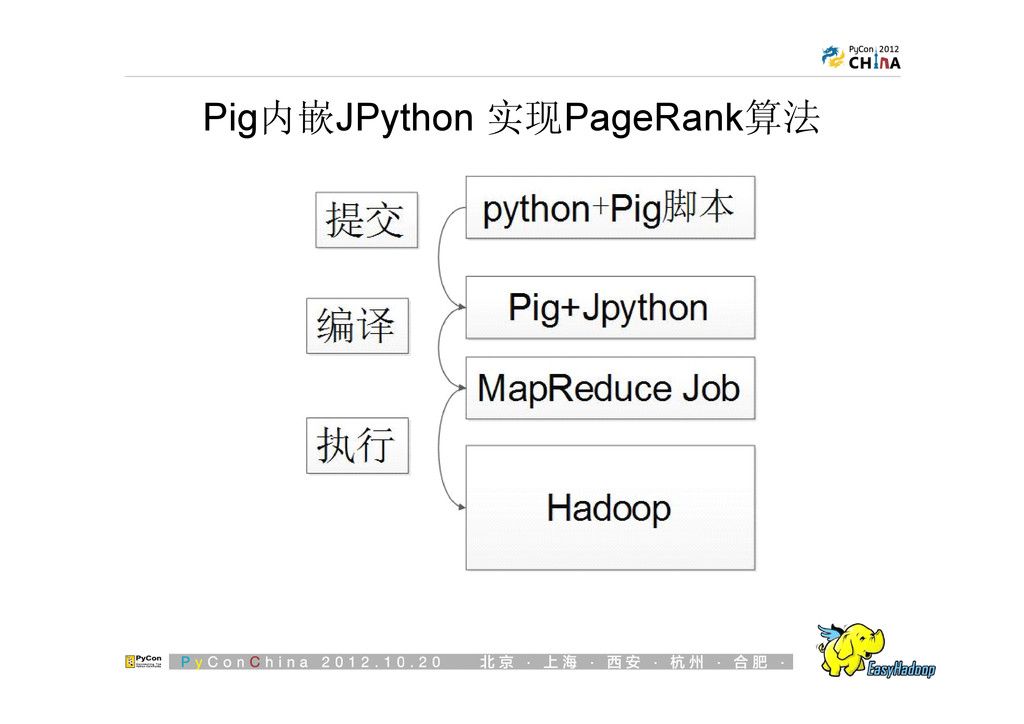{kind=link}
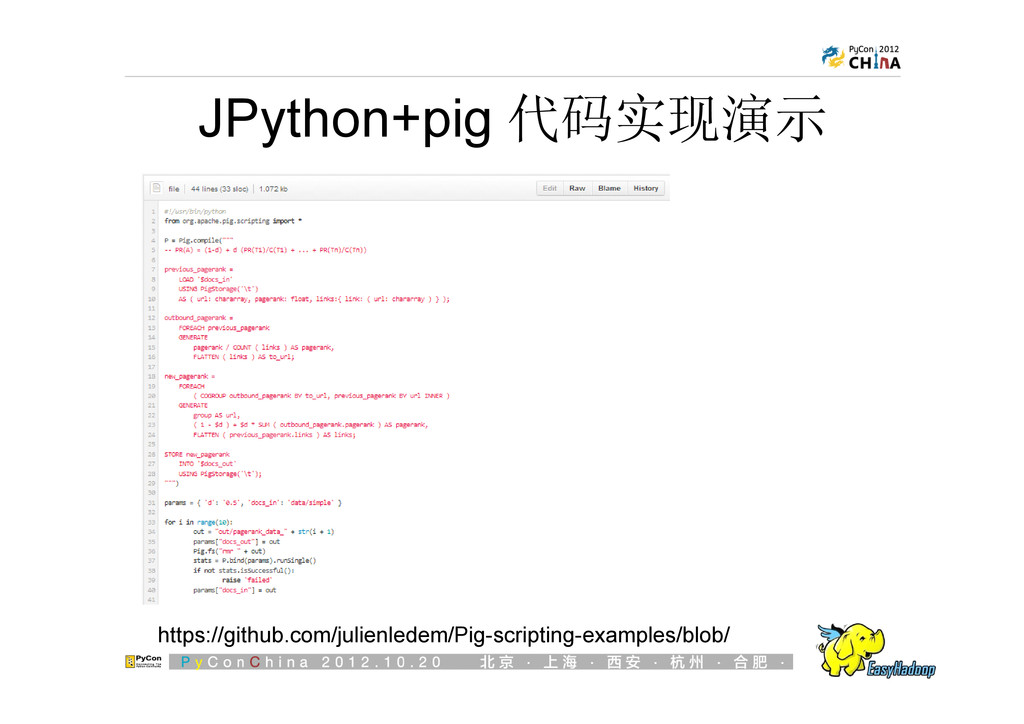{kind=link}
{kind=link}
{kind=link}
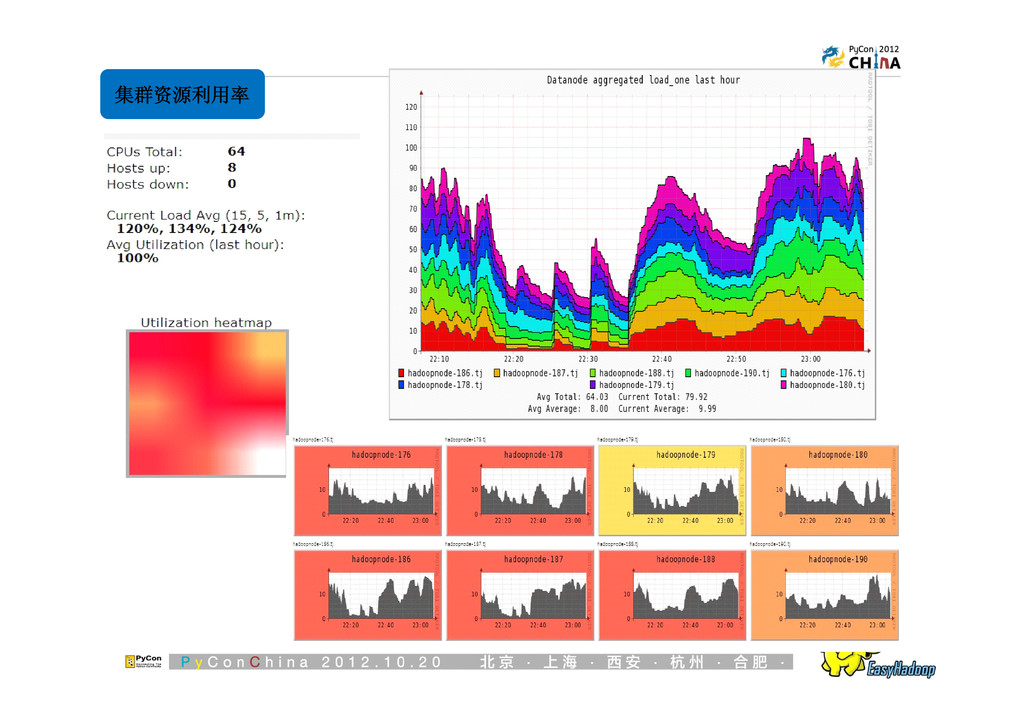{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}