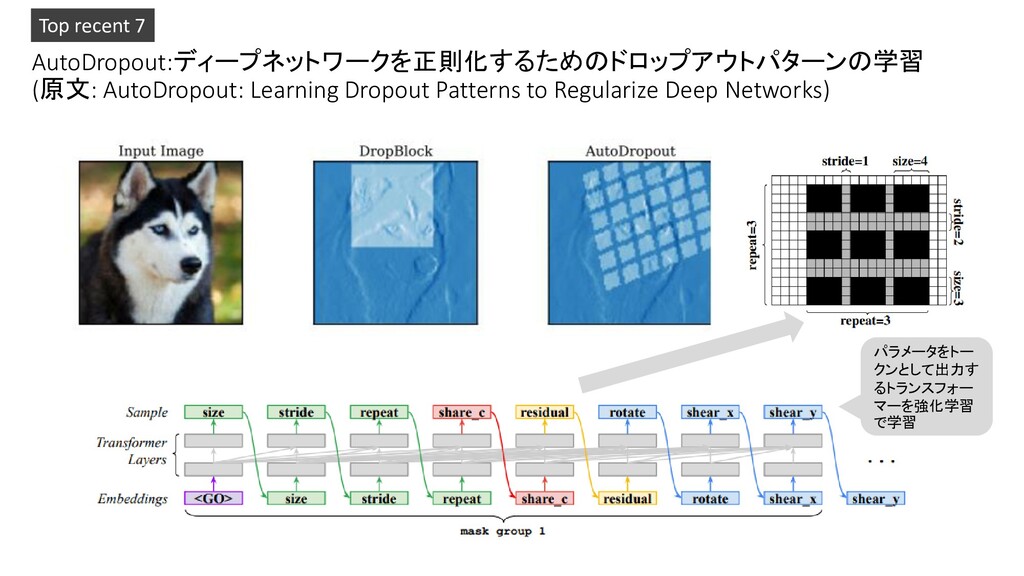
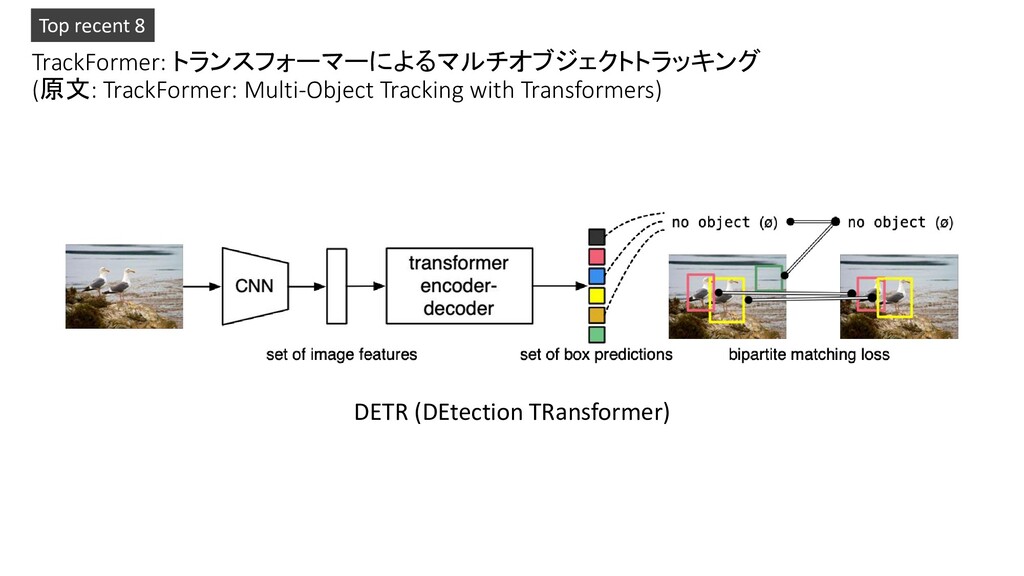
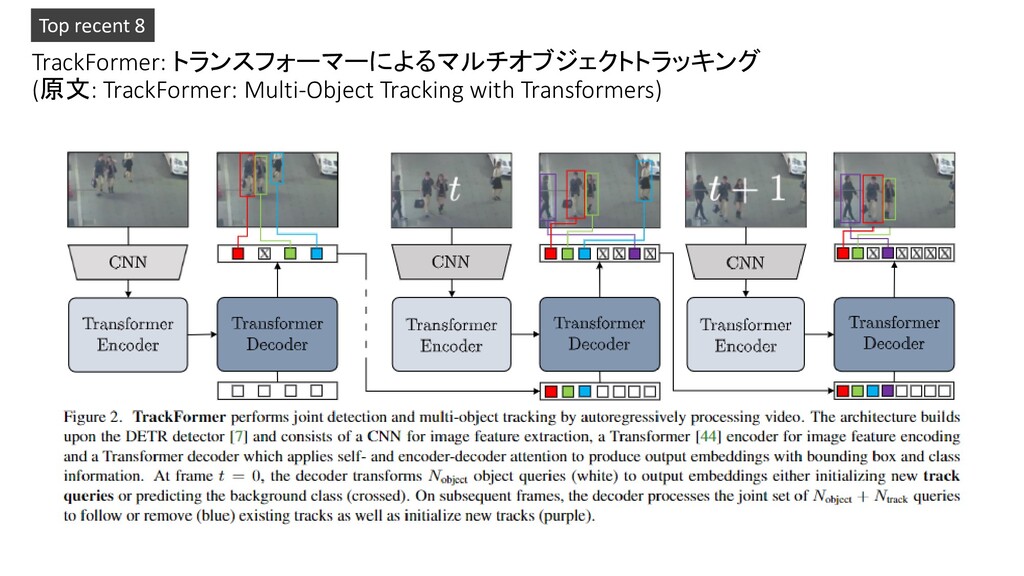
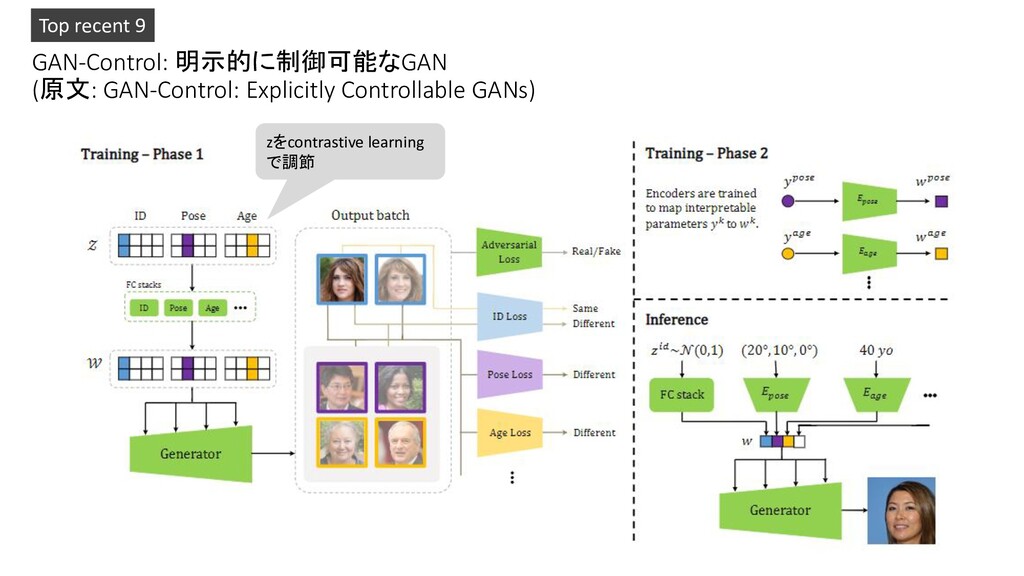
Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity 3. Deep Learning-Based Human Pose Estimation: A Survey 4. RepVGG: Making VGG-style ConvNets Great Again 5. A Survey on Neural Network Interpretability 6. Global Context Networks 7. AutoDropout: Learning Dropout Patterns to Regularize Deep Networks 8. TrackFormer: Multi-Object Tracking with Transformers 9. GAN-Control: Explicitly Controllable GANs 10. GAN Inversion: A Survey Pickup!
GLU Variants Improve Transformer 3. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity 4. The Problem with Metrics is a Fundamental Problem for AI 5. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 6. A Survey on Neural Network Interpretability 7. Soft-DTW: a Differentiable Loss Function for Time-Series 8. RepVGG: Making VGG-style ConvNets Great Again 9. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 10. A Modern Introduction to Online Learning gray: [dup]
GLU Variants Improve Transformer 3. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity 4. The Problem with Metrics is a Fundamental Problem for AI 5. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 6. A Survey on Neural Network Interpretability 7. Soft-DTW: a Differentiable Loss Function for Time-Series 8. RepVGG: Making VGG-style ConvNets Great Again 9. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 10. A Modern Introduction to Online Learning gray: [dup]
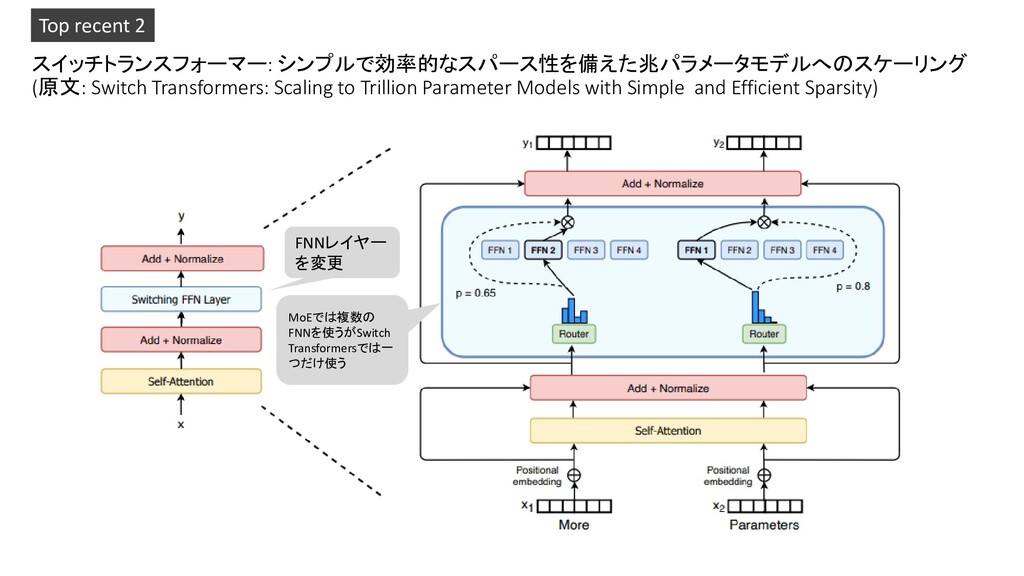
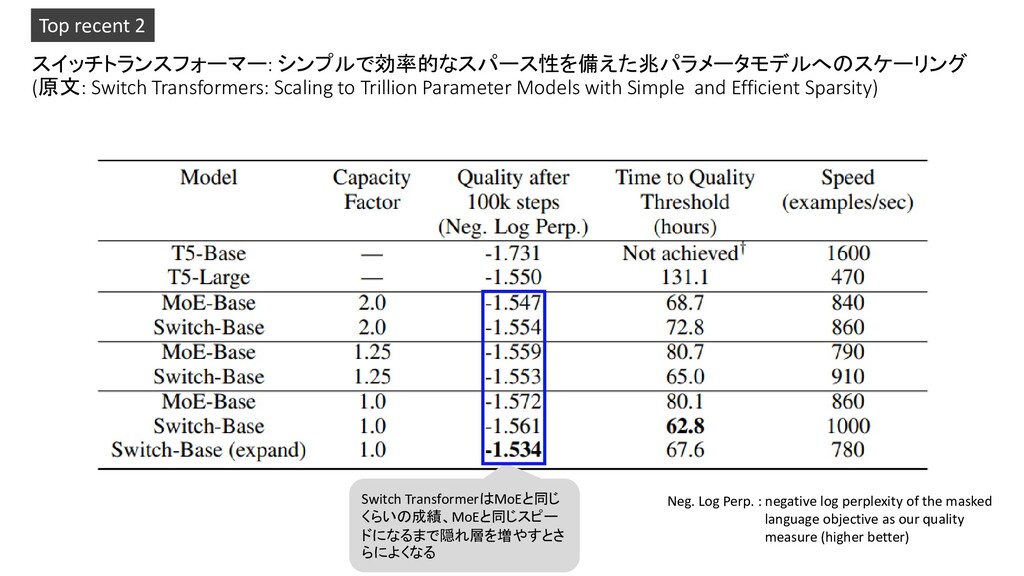
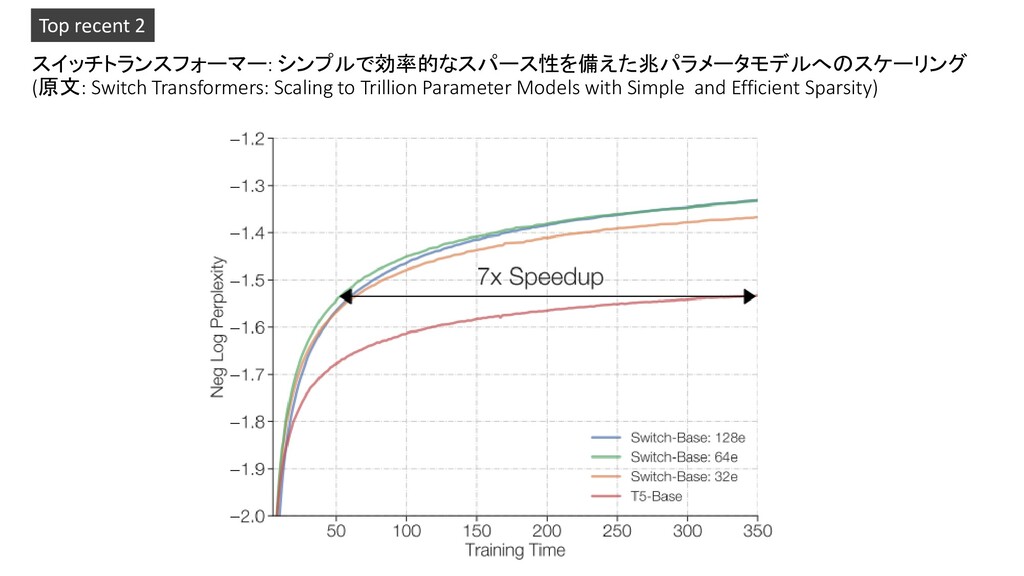
with Simple and Efficient Sparsity) Top recent 2 Switch TransformerはMoEと同じ くらいの成績、MoEと同じスピー ドになるまで隠れ層を増やすとさ らによくなる Neg. Log Perp. : negative log perplexity of the masked language objective as our quality measure (higher better)
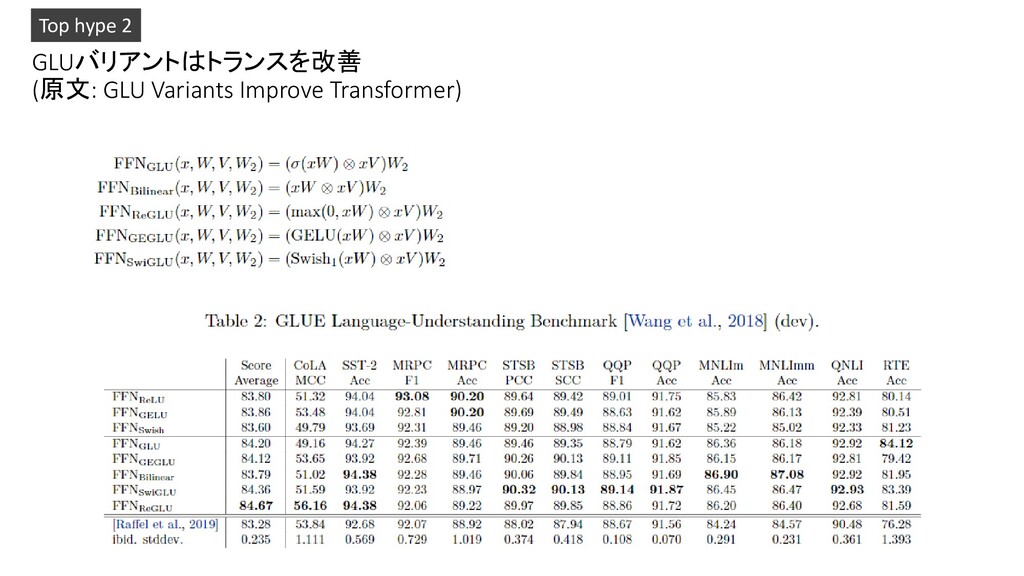
(arXiv:1612.08083)は、2つの線形射影の成分積で構成され、そのうちの1つは最初にシグモイド関数を通過させる。 GLUのバリエーションは,シグモイドの代わりに異なる非線形(あるいは線形)関数を用いることで可能である.Transformer (arXiv:1706.03762)のシーケンスツーシーケンスモデルのフィードフォワードサブレイヤーでこれらのバリエーションをテストし、それらのい くつかが一般的に使用されているReLUやGELU活性化よりも品質の向上をもたらすことを発見した。 Top hype 2 目的:トランスフォーマで使われるGated Linear Unit (GLU)にシグモイド以外を使用した場合の調査 成果:データセットごとで最も精度のよい関数が異なる 方法:複数のデータセットで、複数の関数を調べる 著者所属:Google
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}