Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ビジネス要件から逆算するマイクロサービスアーキテクチャ選定の「思考プロセス」
Search
akira345
March 27, 2026
Technology
82
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ビジネス要件から逆算するマイクロサービスアーキテクチャ選定の「思考プロセス」
おもにクラウドの話してます - 広島 #6 発表スライドです。
akira345
March 27, 2026
More Decks by akira345
See All by akira345
回路設計のバイブコーディング
akira345
0
83
インシデント対応
akira345
0
530
えれくら!〜電気電子工作系制作・交流会〜#29
akira345
0
55
脱・同期処理!マイクロサービスにおける負荷分散の勘所
akira345
0
160
AWSデプロイツール紹介
akira345
0
89
40歳でやったこと
akira345
0
70
回路を読むために必要なこと
akira345
0
57
おれのAWSが こんなに辛い訳がない!!
akira345
0
63
Dockerを触ってみよう
akira345
0
130
Other Decks in Technology
See All in Technology
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
410
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
280
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
260
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
620
Network Firewallやっていき!
news_it_enj
0
260
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
300
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
480
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.2k
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
260
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
520
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
160
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
450
Featured
See All Featured
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
How to Talk to Developers About Accessibility
jct
2
420
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
The Limits of Empathy - UXLibs8
cassininazir
1
530
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Transcript
2026/03/27 Akira345 おもにクラウドの話してます - 広島 #6 ビジネス要件から逆算する マイクロサービスアーキテクチャ選定の 「思考プロセス」
自己紹介 • 金田 晃(HN) • 所属:某社 • I like Cloud.
I like AWS. • 自宅サーバ(Docker、Proxmox、Hyper-V) • 電子工作(分解・破壊・修理) 個人検証を地味にやっていたりします・・・
題材: IP電話サービスの録音データ蓄積システム構築 • 背景 • トラブル防止のため通話録音とトランスクリプトを証跡として残したい • 利用中のIP電話サービスの録音保存期間が短い(保存期間1ヶ月 or 300時間/月)
• 録音ファイル永続化オプションが高額なので、自前で蓄積・管理をしたい • 使用中のIP電話サービスは外部API連携が可能
ふむふむ 色々気になるけど とりあえず王道パターンを想定するか
要件整理
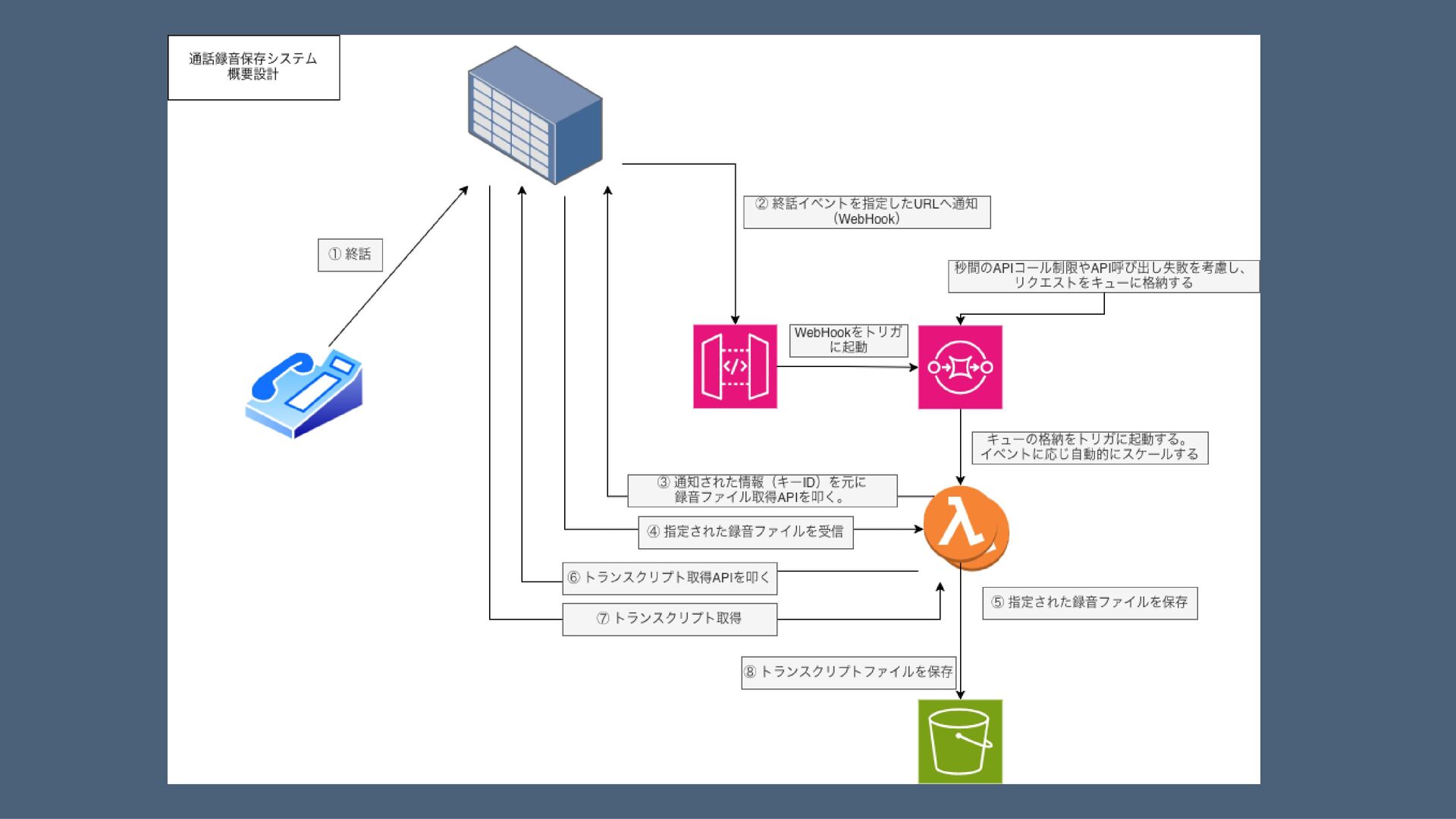
王道パターンで仮置き トリガとデータ取得方式。データ保存戦略 • 終話をトリガにWebHookを呼び出せるなら、イベント駆動でデータ取得が可能 • API Gateway or HTTP API
+ Lambda or ECS が候補。EC2やk8sは不要 • 取得対象は音声ファイルとトランスクリプトの2種類 • WAV/MP3いずれにしてもファイルサイズは問題にならない • 永続保管が目的なので、保存先はS3が最適 • ライフサイクルポリシーで費用面も有利 • ファイル名の命名規則やパスの設計が重要。通話頻度やユースケースの確認が必要
ここでの視点 お客様の言葉を「非機能要件」に翻訳する 「証跡を残したい」 • 可用性・完全性が最優先 • 欠損は極力避ける • 証跡を残す事が主目的→検索性は優先度 が低い
「費用を抑えたい」 • AWSマネージドサービス活用 • 運用コスト最小化 • インフラ費用の削減 「1ヶ月/300hで消える」 • 取得時間は十分にある • リアルタイム性は不要 • 非同期処理で十分可能
技術検証
技術面での深掘り 連携先APIの仕様把握と制約の可視化 • APIレート制限の確認 • 秒間10回の制約あり → バースト時のリトライ戦略が必要 • データ取得におけるAPIの依存関係
• WebHookのリクエストは識別子のみ(音声・トランスクリプトファイルは含まれない) • 音声ファイルは架電・受電側で分かれている トランスクリプト取得も合わせると1トリガに対し3つのAPIコールが必要 • トランザクション管理の視点が必要 • 3つのAPIコールの部分成功時にどう扱うか?冪等性をどう持たせるか? • 開発環境の制約 • 開発環境用のサンドボックスAPIや環境提供はあるか?要確認
選定の分岐点 単一Lambdaかステートマシン(StepFunctions)か 複数のAPIを組み合わせて呼び出す必要がある。どう設計するか? 単一Lambda構成 1つのLambda内で3つのAPIを叩く ✓ シンプル構成 ✗ 処理時間増大に伴う ラムダのタイムアウト
✗API呼び出しの部分失敗の考慮 StepFunctions構成 各API取得Lambdaを並列実行 ✓ 監視・リトライ制御が容易 ✗ 構成要素が増える ✗構築が職人芸になりがち SQS/SNS + 複数Lambda キュー経由で分散実行 ✓ 疎結合 ✗ メリット少なく複雑化
現実的なアプローチ 技術自慢に囚われていないか? • 個人的にはステートマシンを組みたい! • しかし現実的にはどうか? • 音声ファイルは多くても100MB程度。ほとんどは数MBでダウンロード時間は問題にならない • 失敗しても再取得の時間的猶予は十分にある
• Lambda内リトライ不要 → SQSキュー制御でOK • API部分成功時は再実行で上書きすればよく、ゴミファイル掃除の考慮も不要 • 取得済みファイルの再取得もダウンロード時間は問題にならない • 取得済みファイルについて、API側で自動消去されることもないため再取得で問題なし • → 単一Lambda構成で十分可能
設計と実装
None
設計の勘所 失敗を前提としたシステム構成 API Gateway → SQS 直接接続 • WebHookに即座にステータス200を応答 •
バースト時の取りこぼし防止にキューイング (API Gatewayのスループット注意!) • 非同期処理でLambdaタイムアウト回避 (API Gateway 30秒制約回避) • DLQ通知による手動リトライ構成 • 冪等性はファイル上書きで担保 不正アクセス対策 • WebHookには不正リクエストの可能性あり • 無効IDは処理スキップ+成功応答 • 無駄なリトライを回避する設計
運用を見据えたデータ設計 人間系処理からシステム化まで • S3ディレクトリ構成は YYYYMM/DD で人間の探索性+将来のDynamoDBパス格納を両立 • 現在のS3はPrefixのランダム性が不要なため、ハッシュ値より視認性を優先 • ファイル名は
[開始時刻]_[通話ID(電話番号+識別子)].[拡張子] を想定 • 証跡検索時の情報は「いつ」「だれ」→ 並び替え・人間による探索を容易にする設計 • 将来的にライフサイクルポリシーによる自動アーカイブにも対応可能 • S3 Standard → S3 Glacier へ自動移行でストレージコストを削減
まとめ
思考のポイント 外部連携は「失敗前提」で設計する • APIのリクエスト耐性を確認 • 回復可能エラーの判別が可能か?リトライ戦略 • 代替手段・リカバリプランの確保 将来性・拡張性を想定する •
システムの制約を把握した上で拡張性を確保 • 将来の検索要件や拠点追加に対応可能か 運用監視のコスト判断 • 運用監視にかけるコストの見極め • あえて作らない選択肢もある(RPA/AI等) 開発・検証はセット • 本番と同じ挙動を再現できるか? • 本番環境でしか検証できない場合どうする?
アーキテクチャ選定の本質 ビジネス要件を技術で実現する • フワッとした要件を制約に基づき現実的 なアーキテクチャに落とし込む 最善の選択をする • 「俺が考えた最強のシステム」ではなく 業務要件を満たす運用可能な最善を選ぶ •
「機能要件を満たすこと」が最低限。 頼まれてもいない最強のシステムは蛇足 外部連携が入ると警戒すべし • 外部連携の境界は責任分解点 • 失敗前提の設計 • 思い込みを排除し「常識」のすり合わせ を怠らない
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}