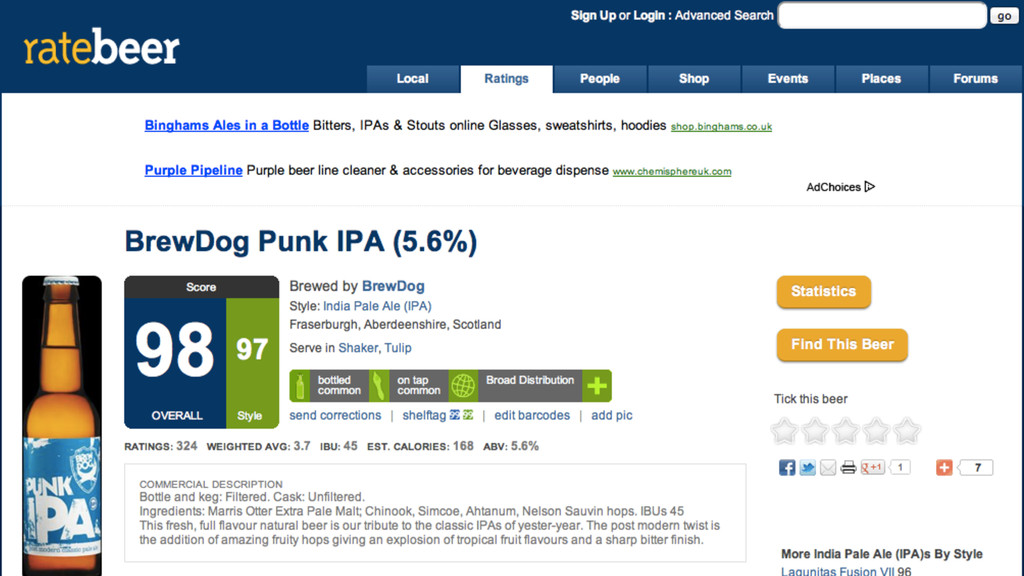
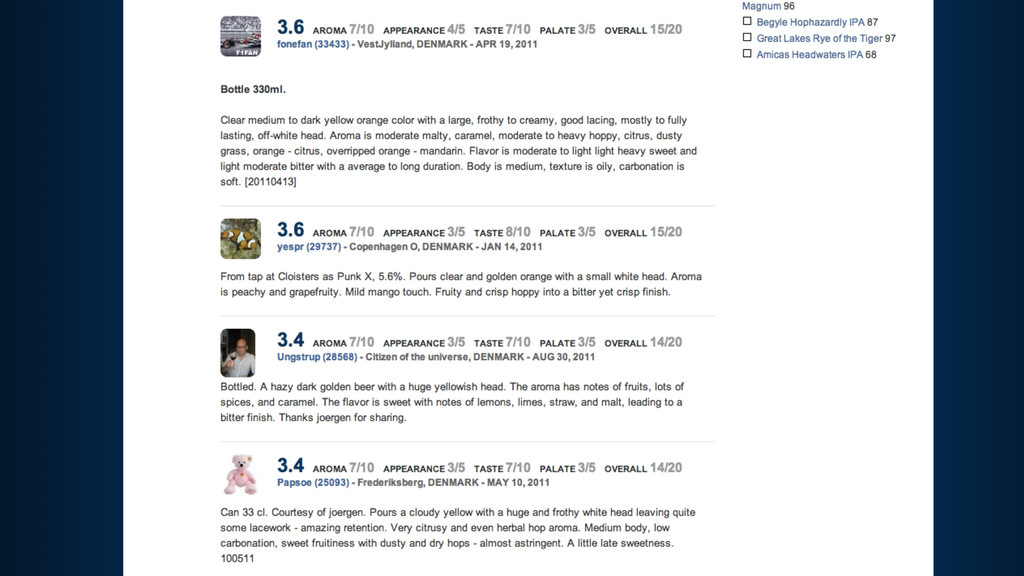
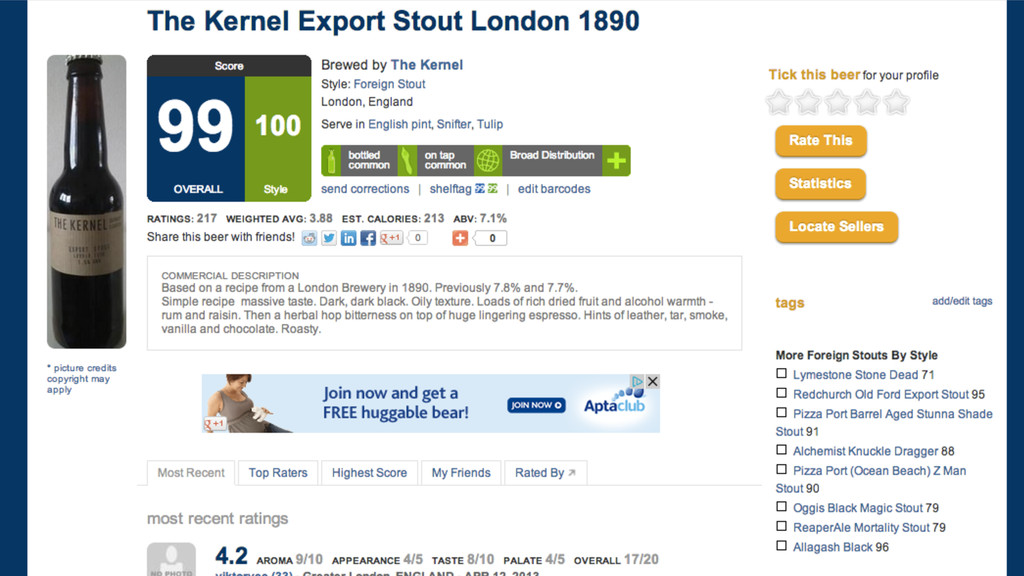
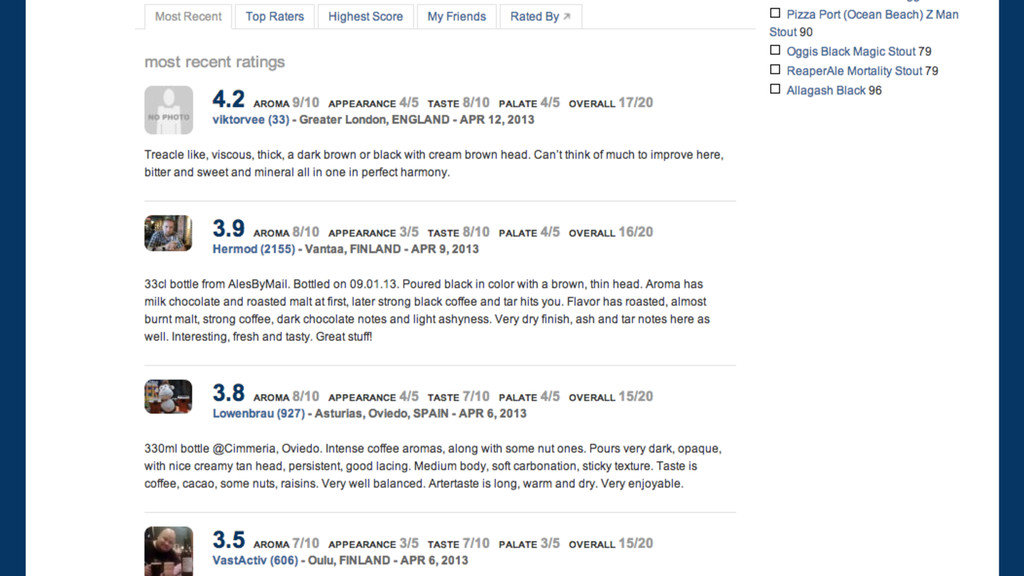
taste like coffee, chocolade and dried fruits in an great way, this one is 7,5% strong. But the label is rather dull, beer is great.Kleur is zwart, ruikt naar koffiebonen en ruikt naar een koffiepak, Smaakt naar mokka, pure chocolade. Ik vind het veel te sterk, ook al lijkt het begin waterig daarna komt pas de smaakexplosie. Ik kreeg er kippenvel van, de smaak bleef ook nog eens heel lang hangen.Bottle:Small light brown tan ish bubbly head which changes into a lacing on the side as an open ring. Black beer with a deep dark brown edge.Smell lots of coffee, roasted malts and roasted coffee.Taste coffee, roasted coffee, espresso, roasted espresso, roasted nice good bitter, hint of vanilla and slight hints of pencil and dark bitter chocolate.Deep, lots and loads of coffee and roasts in the taste. Good!Good bitter roasted coffee herby aftertaste.Low carbo, soft mouthfeel, full body and a watery texture.Damn this is some good stuff!Bottle in London. Black beer with a creamy beige head. Cocoa aroma, chocolate, coffee notes, rosted, earthy, milky notes. Cocoa and coffee flavor, rather bitter, soot, roasted, some tar, licorice, vinous notes.Bottle at the brewery. Jet black with small golden head. Aroma is coffee, vanilla, touch of dark fruitiness. Taste is roasted malt, bitter finish, bit of booze, touch of liquorice along with the expected coffee, and vanilla. Very nice!Bottle. Black, foamy tan head. Herbal, coffee nose with mocha hints. Vanilla malt flavours and vegetal hops combine with an almost coconut edge. Damn lovely beer.Bottle from the brewery. Black color with a small tan head. The aromas of dried fruit, smoke, some brown sugar. The taste is actually quite hoppy, some espresso, bitter chocolate. The bodys medium, oily. Dry. Overall, a very drinkable stout indeed. Straightforward and tasty.nice coffee flavour,also like good espresso .hints of raisin . poor head retention ,but good carbonation .Bottle at home, 13th January 2012. This followed a Kernel IPA Citra, so a good Beer Friday. Aroma is dark chocolate and coffee, pours to reveal a nice black drink, taste is hoppy with bitter chocolate, and coffee, palate is perfect oily and smooth. I would choose the Kernel Imperial Brown Stout over this, but it is closeBottle @ Brewdog Glasgow. Black colour, beige head. Nose is full chocolate, roasted malts, maybe bit of mocha, bit salty. Flavour is roasted malts, chocolate, liquorice. Quite odd. Medium bodied.Bottle @ BrewDog Glasgow. Dark brown almost black colour, no head. Unusual flowery biscuit flavour. Strong spicy fruity flavour. Quite smooth. Needs to be drunk slowly. Not a big stout fan but I like this one.Bottle conditioned @ 7.1%. Lively, with a tan head with zero retention. Jet black body. Chocolate, roast, washing up liquid, fruity, nutty. Bittersweet. Long bitter finish. Fizzy, Quite soft, refreshing, rejuvenating.Wow first sip packs a hoppy punch. Very dark roasty oily chocolaty syrup. Has an intense brown head which lingers. Taste is very heavy and filling with a bitter clean finish. However little disappointed with aroma for such an amazing beer I expected more intense aromas, but smell isnt very strong. But overall an absolutely beautiful beer.33cl bottle from DeMolen biershop. Brune foncée, col crémeux moka.Arôme a une pointe aigre lactique le tout suivi par une note café malt chocolat.En bouche, une bière aux notes chocolat amer et encore je note ce profile lactique et aigre, le tout sur un malt épais grillé et un pointe fruité noire. Retrouve ce style de stout anglais ayant une touche de cuire avec une once de malt fumé et de café froid. Fini est sec et grains. Fini conserve un brin damertume houblonnée.Bottle at 7.1%. Black with a beige head. Aromas are coffee, dark chocolate and liquorice with mellow blackberry. Floral with grapefruit and leather. Oily with hints of marzipan and peppery notes. Flavours are rich coffee with dark winter fruit and gritty, bitter dark chocolate. Dark rum with cola. Pithy bittersweet grapefruit with a yeasty, dry, woody finish. Very good.In bottle. Pours a dark brown colour with a ruby tinge and a thin tan head. Aroma of chocolate milk, some grassy hops, caramel and alcohol. Big roasty malt and chocolate flavours with pine and grassy hops to finish, Alcohol is well balanced and roasty malt lingers. Moderate carbonation and light CO2 prickle.Bottle @ BrewDog Aberdeen,<br />Black, dark tan head dissipates to thin layer, good lacing.<br />Aroma - roasted malt, sweet chocolate, espresso, dark fruit berries, sweet malts, molasses.<br />Taste - coffee, roasted malts, sweet sweet dark malts, chocolate, tasty, well blended but not too complex. Alcohol quite well hidden.<br />Palate - soft carb, full body, sweet syrupy sticky texture, smooth.<br />Overall - Good stout, good flavour, but a bit too sweet.Bottle: Literally black, stable brownish foamy layer, roasty-bitter aroma, vanilla, dried fruits and wood in the nose; moderate to solid bitter-sweet flavour, a slight acidity is present as well, medium bodied, very smooth; roasty-bitter and coffeeish finish, warming alcohol detectable. Gorgeous british brewBottle from Bierkoning. Dark black body with thin tan head. Nose of licorice, anice and oils. Taste is also oily malts and espresso. Texture is smooth and sticky. Quite enjoyable.About as good as a beer can be. Powerful liquourice/coffee taste. Long mouthfeel. The brewer should be given a medal!33cl Bottle from De Bierkoning, ABV 7.5%. Black, brown head. Aroma of lovely fresh coffee, moccha, bitter chocolate, rum. Flavour is hard hard roasted malts, tar, coffee, rum, espresso, coffee, light dark fruits, herbal (all like in the descreption indeed) bitterness, very hard roasted bitter finish. Medium bodied. Aroma promises more than flavour delivers, but nice nevertheless.For late celebration of Thursday, which was International Stout day, and the day when my first Linux Kernel patch was accepted to mainline. This beer should be the most accurate celebration drink to me what comes to the Nov 3rd, 2011.The drink seems to be very stout like; black, short light brown thick head, roast smell of smoke and coffee. First taste is sweet, and very malty. Bit later there is plenty of aromas. Mostly heavy malts, some basement/leather/earth and soy sauce with cooked vegetables. Finish is unsurprisingly long. The creamy texture and flat carbonation makes the feel of this drink very good. Overall a good, good stout.Bottle from Stirchley Wines, Birmingham. Smells good, looks fantastic. Taste is, ooh, wow, so smooth, rich and mocha-y. Deep, long, vibrato balance of sweet, dry and power. Really fine.Bottle: Black with a small head. Aroma is coffee and roasted malt. Flavor is inetnsive and full bodied, notes of roasted/burnt malt, dark coffee and molasse. Roast bitter finish. Lovely.Cask at CASK Pub & Kitchen Pre-GBBF Meet the brewer event, London. Opaque black color. Sweet and roasty with chocolate, licorice, coffee, toffee and nuts. Fairly coffeish, more sweet than bitter. Nice to have this on cask, I think it gives this an extra kick.From bottle. Black with tan head. Big aroma, smoke, toast, char, lots of roast malt. Taste is similar. Quite hard to drink, not very smooth. Tastes burntCask. Black with a small off-white head. Malty aroma with licorice, molasses and dark chocolate. Sweetish roasted flavour with licorice and chocolate. Rich and full-flavoured, but a bit too one-dimensional licorice/roast for my taste<small style="color: #666666">UPDATED: NOV 18, 2011</i></small> Bottle from Great Grog. Very dark brown, almost black, thin tan lacing. Dirt, coffee, some herbal notes on the nose. Hint of rum and raisin warmth. Palate is largely dry and bitter but with some sweet raisin, sort of tastes like dirt in a very good way! Bitter herbal finish. Velvety mouthfeel, really tasty stuff! Also sampled off keg at BrewDog - slightly more sweetness, slightly better mouthfeel. Extra point.Draught @ Stone vs Moeder Lambic event in Brussels. Again, thank you Jean for letting me and my friends have a bottle of this. Opague, pitch black colour with a light brown head. Smells mocca, coffee, bitter, chocolate, bourbon - in a quite overwhelming fashion. So full of flavours.. Tastes mocca, sweet, icecream, vanilla, coffee, roasty. Its almost a dessert. This beer is crazy. Very full body, bit thick, tasty. 330ml bottle. Pours near pitch black with a small head. Aroma is coffee with a little smoked ham. Taste has roast and yeast to start. Bitter coffee and meaty Fonish. Very oily in the mouth.33cl, at 7.8%Vol, new exclusive English brew Anno 2010, from The Bottle Shop Canterbury, complex Stout, roasted and slightly smoked/alcoholic, heavy, yet balanced, cloudy, small head, good brew, yet expensive!33 cL bottle into a Westmalle glass. Very little head, disappears quickly, over a black beer. The aroma is fantastic, chocolate and coffee, dark malt, delicious. Tastes lovely, chocolate, sweet with body and a hint of coffee and a bit of bitterness, nice and complex. One of the best of British. Really good beer, proud its UK.Bottle at Chez Moeder Lambic Fontainas. Gift from Jean, huge thanks! Almost pitch black opaque color, but some dark red comes though when held into a light. No head, just a small light brown lacing. Smell so much coffee, mocca and caramel, but mostly its mocca. Taste malts, bitter, coffee, mocca and chocolate. Bitter aftertaste, slightly oily texture. Very round velvety taste. Soft carbo, medium body.Black beer with fluffy tan-cream head. Peanuts, coffee, Indonesian satesauce and moccha. Vinous, stout-like acidity, other grains, roasted barley, grapeskins in the aftertaste. Very well-bodied, thick, viscous. Now theres some stout. If this is from a historic recipe, it beats most of those recreations hands-down. <i> Grand merci à Jean H.! </i>shared at Max & Jesss - dark brown pour, toasted and smoked malts and bready. Milk chocolate and nuts. Dark fruits and dries out into woody finish.Half pint, cask, 7.8% abv, at <i>Meet the Brewer event at Cask Pub & Kitchen</i>, Pimlico. Oily dark pour. Bright naked surface. Aroma of sweet cocoa with a hint of lactose to it. Milk chocolate in flavour supported by notes dried fruits and rum offset by a moderate tart and bitter ending. Enjoyable (London, 01.08.2011).August 13, 2011 - draught at The Kernel (south and east of Tower Bridge). Opaque brown-black with a creamy, lasting, slightly green-tinged light brown head with thick lacing. Aroma is lush - fresh non-acidic coffee roast, a little cream and mint tossed in, very light chocolate and "dark" fruit (7+). Taste follows, also has a hint of mineral grittiness which knocks down the incipient sweetness from the coffee/chocolate roast - alcohol is incredibly restrained, really nicely balanced all-round when you start to detect light peat, herbal/floral bitterness and even some random oak tannin as it warms. Creamy and thick mouthfeel, a bit airy, the alcohol emerges slightly in the bitter, slightly earthy roast coffee bean finish. Really, reallly good stuff, these guys make the real deal from what I have tried so far!At a tasting, thanks Oren, pour black to brown with a brownish head, aroma of smoke, milk chocolate, milk, brandy and nuts, flavor is dry with some bitterness (not from hops), malt acids, lactic acids, coffee and tender smokiness, medium to full bodied, greatBottle at a tasting. Thanks Oren. Black-colored with a big of brown foam. Aroma of coffee, chocolate and some liqueur notes. Flavor of bitter chocolate, roasted malt, light acidic notes, a bit of fruitiness and a slightly drier finish. Medium to full-bodied with a flat but silky mouthfeel.Cask at Cask Pub & Kitchen @ Pre-GBBF Kernel night. Pitch black - offwhite head. Nice sticky body, fruity, coffee, ok hoppy, exotic fruits, fullbodied, sweetness, herbal, light flowery, dried fruits, alcoholic, raisins, light smokey. Lovely.330 ml bottle. dark brown with mini mocha head. intense aroma of chocolate and roasted coffee. rich flavor of highly roasted malts (with its acidity), and dark dried fruits (carobs). very long after taste, light to medium body. very good beer.Kernel Event @ Cask Pub and Kitchen, 1 August, 2011. Cask. Pours brown with a small head and lacings. Roast, caramel, smoke and liquorice. Smooth and full bodied. Velvetly soft. Dry roasted end. Lovely!330ml bottle from Utobeer, 7.8%, drunk at home, 27th Dec 2010. Black with a small beige head. Perfumed roasty nose. Tar, shoe polish, leather on the tongue. Great mouthfeel - strength without heaviness, smooth without excessive oiliness. A very drinkable strong stout. Lovely balance of good hops and good malts.Cask @ pre GBBF 2011. A black colored beer, with a small beige head. The aroma of coffee malt, bitter with hints of chocolate. The taste of coffee with dark fruits, some sweet with notes of bitter. Aftertaste some sweet with bitter.<small style="color: #666666">UPDATED: AUG 2, 2011</i></small> From the cask at CPK, Kernal event. Sweet, choco, tangy and hoppy too. Tingy, peppery finish nice.Nice body, fruity, berries, rather sweet.Bottled 500ml (PBF, BBE 2012)<br />Opaque black color, small beige head. Strong aroma of licorice, coffee, coffee beans. Medium-bodied. Quite easy to drink for this ABV. Licorice, coffee beans, roasted malty. Pleasant stout. Not too burned!Bottled (from the Kernel, London). Black colour, small brown head. Aroma is coffee, roasted malts, mild toast as well as some liquorice. Flavour is roasted malts, coffee, some ashes as well as mild liquorice and mild grassyness. Also some quite vanillaish notes.Bottle at the Rake in London. Pours a black creamy, bubbly lacing. Aroma is cappucino, and strong dark chocolate. Mouthfeel is creamy with notes of bitter malts, coffee, roast, smoke, tobacco, espresso.From bottle on 26 April 2011. Very dark brown. Slightly oily consistency. Extremely roasty, verging on burnt, with lots of chocolate and hints of pruney fruit. Plenty of tangy hops too. Firm, rich mouthfeel. Excellent stuff.<i>Bottled. </i> Very black, beige head. Aroma of licorice and tobacco. Dryish with meaty full body, clean, rounded mouthfeel. Plenty of dark chocolate, notes of smoke. Salty salmiak finish. Quite intense.<small style="color: #666666">UPDATED: AUG 29, 2011</i></small> Bottle from the Kernel Brewery. Lovely liquid black in the glass with a chocolate tan head that dissolves after a minute or so. Rainbow bubbles in the foam. Nose is deep beautiful chocolate syrup and then black coffee notes. Bit soapy. Flavour is silky chocolate syrup sauce. Fairly light in texture for a stout although body is robust and full. Bit of roasted bitterness on the finish. This is a very fine beer.330 ml bottle in England. Pours black with a dark tan head. Loads of coffee and chocolate on the aroma and some raspberry. taste is much the same. On the palate there is lots of roast malt, giving flavours of coffee and milk chocolate, then a smoky, chared and very soft dry finish. Excellent.330 ml bottle conditioned, bought at The Cheese & Wine Shop, Darlington. ABV is 7.7%. Pitch black colour, big to moderate brown head. Roasty aroma with strong notes of coffee, hints of liquorice and ashes. The flavour is roasty and quite dry, again strong notes of coffee, hints of liquorice and dark bitter chocolate. Good stuff.Didnt get a big sample of this but it was pretty good. Poured dark brown, aromas of toasted malt, chocolate, smoke, wood. Very smooth with lots of chocolate on the palate. Finish is roasted malt and chocolate. Quite enjoyable.Bottle at Max and Jesss place. Pours a hazy and murky brown with a thin beige head. Roast, chocolate and cocoa, vanilla and malt, roast and chocolate. Smooth and sweet, roast, and chocolate. Lots of roast and chocolate on the finish.Tasting at MaxxDaddys house. The aroma is chocolate, vanilla, roasted malt. Very nice. The flavor is the exact same. The appearance is the usual deep black, light tan head. Medium in body, light for this style. Really good.Bottle from beermerchants.com A black coloured pour with a medium beige head on top. Good roasty, malty aroma. Tastes malty, chocolate, coffee, dry, slight bitterness. A superb stout from London. Kernel are currently knocking out some of the best beers in England.Bottle at Maxs tasting. Pours near black with a beige head. Dry roasted malt aroma with a hint of coffee. The flavor has dry roasted malts and a light sweetness. Really good.Bottle shared by Mario at Maxs tasting. Pours black. Tan head. Nose and taste of dry chocolate malts, roasted coffee and vanilla. Dryish finish.Bottle, bought @ Beermerchants.com.<br / >Deep black with a smallish, creamy, light-brown head. Fizzes slowly away. Aroma is lovely, overall sweet, with some good chocolate, light cocoa, mildly roasted, light liqourice. Medium carbonation, good creamy and light dry mouthfeel. Flavour is very lovely, good chocolate and liqourice as base with some good grassy hops, mild coffee, well roasted. Light vinious with some fair hoppy bitterness. Very nice.Bottle from the brewery. Near black in colour with no head. Plain chocolate aroma with some roasted, slightly creamy malts. Flavour had black coffee and more chocolate. Slightly oily mouth feel, coating the mouth and leading to a bitter finish with a touch of warming alcohol.Bottle from Beermerchants.com. Pours black with a 1 inch dark brown headAroma of strong dark bitter and sweet chocolate, also some coffee and liquorice. Taste is medium sweet, smooth and light roasted malts, slightly burnt, with liquorice playing in the background. Ends with a moderate spicy bitterness, quite good this one.Bottle from Beermerchants. Poured virtually black with a good sized beige head and some lace action. Nose was enticingly laden with malt, dark chocolate and coffee. Quite fullish mouthfeel, slid down soft and smooth Top notch flavour jam packed with roasty goodness and coffee aplenty. Alcohol nicely smothered. Bitterness levels started to pick up towards the finish. Superbly well executed stout.330ml bottle (Utobeer, London)<br />6+ Very rich roasty aroma, touch of chocolate. Anna thought she got some banana (poured without any sediment, for reference).<br />5- Beautiful black body, tight tan head.<br />7 Moderately full roasty taste, some sour stale coffee notes, and a good dry bitterness too. But perhaps a little sludgy and cocoa-powdery.<br />4 Full smooth rich palate, not slick, carbonation low. Slightly chocolatey finish, some nice bitter hops too. Doesnt completely cover the alcohol, but it doesnt exactly feel strong either.<br />13 I liked it more than Anna, who would have given it a little bit less everywhere. She should get her own account. If they could rein in the cocoa-powder sludginess, I think it would be great.Pours thick and slick and oily with a depleting tan head. I found the aroma rather unleasent, a sort of damp feet woody smell. Good carbonation. The flavour is full dry coffee with plenty of chocolate.Bottle from Beermerchants. Deep oily pour with a fine, dissipating tan collar. Aroma: apples rolled in ash, mouldering leaves, cranberry, Crunchie, toast. Drinks a bit like a concentrate of the London Porter; thick and mellow with Twiglet and dark chocolate praline notes; mouldering leaves, coal smoke, dabs of brine, black cherry. Nice powdery cocoa, cigar linger. Solidly roasted stout that carries the alcohol with some finesse.(Bottle, purchased at the brewery outlet, Druid Street, London) Pitch black colour with frothy, pale brown head. Malty, roasted nose with chocolate, black coffee, cocoa, ashes and hints of liquorice and tobacco. Malty, roasted taste with notes of chocolate, cocoa, coffee, hints of tobacco and dark berries. A touch of cream. Well pronounced but rather gentle cocoa bitterness in the finish. Lots of chocolate truffles with cocoa powder. More than medium body, with a touch of sweetness. Smooth and velvety mouthfeel. Exceptionally well balanced and very tasty. Lovely beer.Bottle (conditioned). Smells of coffee beans and liquorish. Black with a hint of cherry colouring. Strong coffee flavours with liquorish finish. Hint of tangy cooking apple, hint of bitter cherry. Warming alcoholic burn on finish along with bitter liquorish.<small style="color: #666666">UPDATED: NOV 17, 2011</i></small> bottle at home ... deep black ... thin tan head ... soft chocolate ... light meaty ... nose ... light bitter chocolate ... soft burnt tone in background ... nice 3.7tap at brewdog ... deep black ... thin lacing ... soft dry dark roast malt nose ... dark malts ... light bitter charcoal roast ... litle chocolate ... quite dry ... nice if a little dry and little bitter for me 3.8Bottle. Pours a black color with a small tan head. Has a roasted malty chocolate and licorice aroma. Roasted malty chocolate flavor with hints of licorice and caramel. Has a roasted malty chocolate finish with hints of licorice in the aftertaste.Bottle at The Rake. Pitch black. Lasting thin beige head. I like Export stouts. Lovely tar and cocoa really rich. Outstanding aroma. Rich full in mouth. Like thick liquid chocolate. Bit of grainyness on finish adds some dryness to the dry feel. Touch of tar liquorice. Amazing really. Just stunned me.Pours black black with a brown thick head leaving nice lacing. Aroma is smokey and salty, heavy of roasted malts, some hints of coffee and chocolate and dark fruits. Nice body; not too heavy nor too thin. Good stouty mouthfeel. Flavor is slightly acidy, fresh yet heavy stouty with some smokey saltiness and tones of fresh fruits. Lean, bready and heavy palate. Finishes with a longlived smokey, tartbitter hoppy aftertaste. Excellent.Bottle in a hotel room in London.Black coloured with a small beige head.Roasted aroma of liquorice and dark chocolate with notes of dried fruits.Roasted flavour of liquorice and caramel with notes of dried fruits.Roasted finish.20th November 2010. <br /> Opaque black stout, good tan head. Crispish dry palate. Minerally dark malt and bitter coffee. Trace of cream and a whisper of orangey hop fruit. Dry crisp fresh finish. The fresh crisp palate elevates this stout out of the odinary.<small style="color: #666666">UPDATED: AUG 5, 2011</i></small> 33 cl bottle from Mennos place. Nearly black, thin brown head that settles quickly to an edge. Aroma of burnt espresso and dark cocoa. Taste is dark roasted coffee, bitter cocoa. Finish is very bitter. Decent body. Could use a slight throttle back of the bittering hops, but otherwise a very nice stout.<i> <b> Bottle that I picked up at the Kernel Brewery, Bermondsey, London, consumed at home on Lozs birthday 14.11.10 </i> </b> Pours black with a light beige head. This is lovely in the mouth, soft, velvety and smooth. Light creamy coffee, touch dry but also with a good roasty sweetness. Quite lovely. <b> A7 A4 T8 P4 Ov15 3.8 </b>Milk chocolate and coffee in the nose, a hint of smoke and some cherries. Very dark with beige head.Lovely flavour of roasted grain, campfire sourness and a clean crisp finish. Lingering cigarette ash in the aftertaste.A very welcome beer from a new brewery, hope you keep up the standard!(Bottle from beermerchants)[330ml bottle, Kernel Brewery, London] Much darker pour than the London porter as youd expect thick, treacle-like consistency. Touch of coffee on the aroma, but mostly heavy bitter alcohol and stewed fruit. An exceptionally well-crafted strong stout bitter coffee with a warming alcohol aftertaste and more bitterness on the finish. However, it never oversteps the mark its not too bitter at the end, its not too punchy with the alcohol, and the smooth sweetness yields just at the right time. Rivals the best US imperials in every way [06102010]Bottle at the London Brewers Showcase. Pours opaque brown with a strong, tan head. Holds a sharp malt aroma with some roast and dark cocoa. Lightly sweet with some unique flavors and notes of earth, tobacco, licorice and some chocolate. Medium to full in body with average carbonation and light warmth. Finishes with lingering roast and some nice bitterness.Pours black as squid ink with only the very edges finding any colour. The head is medium tan with a layer of creamy white on top - I love these two tier heads. The lacing is lasting and easily reinvigorated. The nose is of roasted malts, aged hops, dark chocolate and fortified red wine. The mouth brings a orange edge to the chocolate. Then come coffee, leather, tobacco and a mild yeast presence. It finishes on the roasted characters, with the hops growing progressively bitter towards its final dry end. A well done stout and highly enjoyable.330 ml bottle at home: pours black with tall somewhat tight tan head. Fades to a thick film. Roast barley, toast and a good underlying malt nose. Green herbal notes come up as the beer sits. Sweet alcohol and a touch of toffee mix with a light mixed nut aroma. In the mouth you first get green herbal hops and then the roast. Roast goes nice and deep but not astringent. Sweet alcohol comes in with a touch of treacle. At first I actually think there is too much hop but the extra hop comes in handy as you get further into the beer. Medium body which ends just dry enough to be very drinkable.Bottle@The Rake, courtesy of reakt. Thanks! Opaque black body, topped by mediumsized, creamy tan head. Big chocolatey malt aroma. Some fruitiness, and notes of licorice and freshly crushed coffee beans. Initial taste is gently sweet with a strong malt body. More chocolate, roastedness and licorice. Also a tone of light acidulous fruitiness. Noticable hop bitterness in the backbone. Mouthfeel is slick. Roast, peppery bitterness and a fine dryness in the ending. A very good Stout.<small style="color: #666666">UPDATED: SEP 9, 2010</i></small> Bottle at the Rake. Pours black with a dark tan head. Loads of coffee and chocolate on the nose, plus notes of sour apple, pepper and raspberry. On the palate there is lots of roast malt, giving flavours of coffee and milk chocolate, then a smoky, dry and very bitter finish. Excellent.Dark brown with a medium beige head. Sweet aroma with hard roasted malt, coffee and dark chocolate. Sweet flavor with hard roasted malt, coffee, dark chocolate and hops. Finished dry and bitter.33 cL bottle. Pours dark brown to black with a small tan head. Aroma is dark roasted malt and liqourice. Mild smoked like touch. Dark roasted malt and liqourice. Lingering dark malty and vague overripe fruity. Lasting roasted to smoked note into the far finish.Bottled. A black beer with a thick brown head. The aroma has notes of roasted malt, dark chocolate, and a bit of alcohol. The flavor is sweet with notes of roasted malt, dark chocolate, alcohol, and sugar, leading to a dry and quite roasted finish.Bottle 33 cl. Courtesy of fonefan. Pours an opaque black with a dense light brown head. Lots of fat burned malts and licorice. Solid body, hard roasted oily malts and licorice - lots of licorice. Very malt bitter finish. Very well crafted. 010910Bottle from Kris Wines. Almost black underneath a huge, light brown head. The nose promises a decent chocolate and espresso attack, like a good caffe mocca. Flavours start very chocolatey, moves on to include, is there even a mildening (original or strange) perfumey touch towards the end? Body can easily be fuller, but that does not ruin the overall impression: The Kernel goes from strength to strength.<br /><b>Bottle 330ml.</b><br /><br />Clear dark black brown color with a average to large, frothy to creamy, good lacing, fully lasting, beige head. Aroma is light heavy malty, chocolate, coffee, dark malt. Flavor is light heavy sweet and bitter with a long duration, hoppy, dark roasted. Body is medium full, texture is oily and sticky, carbonation is soft. [20100731]Dark brown, with a thick tan head. Smells like a pretty standard stout, with a hint of coffee mixed in there. Taste has a hint of coffee as well. Smooth, with a slightly bitter finish.330ml bottle from Kernel Brewery. Pours dark brown with a thin caramel head. Nose; fresh roasted coffee, caramel, soy sauce and sesame oil. Taste; coffee, bitter-sweet, caramel, over-powering soy sauce and sesame oil with a very long finish. Like the smell, but found the taste too rich and difficult to drink much. I couldnt really get over the strong soy-sauce taste to enjoy it. Bottle from Mr Lawrence Wine Merchants, Brockley. Pours black with a tan head. Very nice coffee and dark chocolate aromas. A little bit of vanilla in there too. Severe coffee attack on the palate. Smoother than Raymond Delorney (School for Scoundrels). Roasty, malty finish. The Kernels Mustard!! Damn fine brew!<i>A Mes rate. Bottle thanks muchly to Nate.</i><br />Woo hoo, another bloody good Kernel beer. Almost opaque black red with a really impressive beige head and lace. Stunning coffee and malt aroma with a surprising amount of roasty and toasty character. Flavour wise, my god, this is really good. Massively roasty and gloriously rich. Superb malt, some leather and tar, faint rubber, and erm... Coffee. Loads of it. Utterly brilliant stuff. English in style through and through but just ramped up a little. Really good length, the coffee just will not shift, it just hangs around making you want more. Stellar stuff.<small style="color: #666666">UPDATED: AUG 12, 2010</i></small> What a stonker from Evin! Fantastic job mate. Awesome head which calms down to fill out half the top surface. Lacing is good. The creamy guey dark brown head matches the label exceptionally well. Roasted malts; espresso and faint grains on aroma. Taste is nutty chocolate, roasted mals, burnt toast, espresso, vanilla, oak and an injection of cream. A stunning authentic English ale. Thanks a lot Evin. Based on a recipee from 1890. Edit - Fresh at the brewery and its even better! 4.3.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}