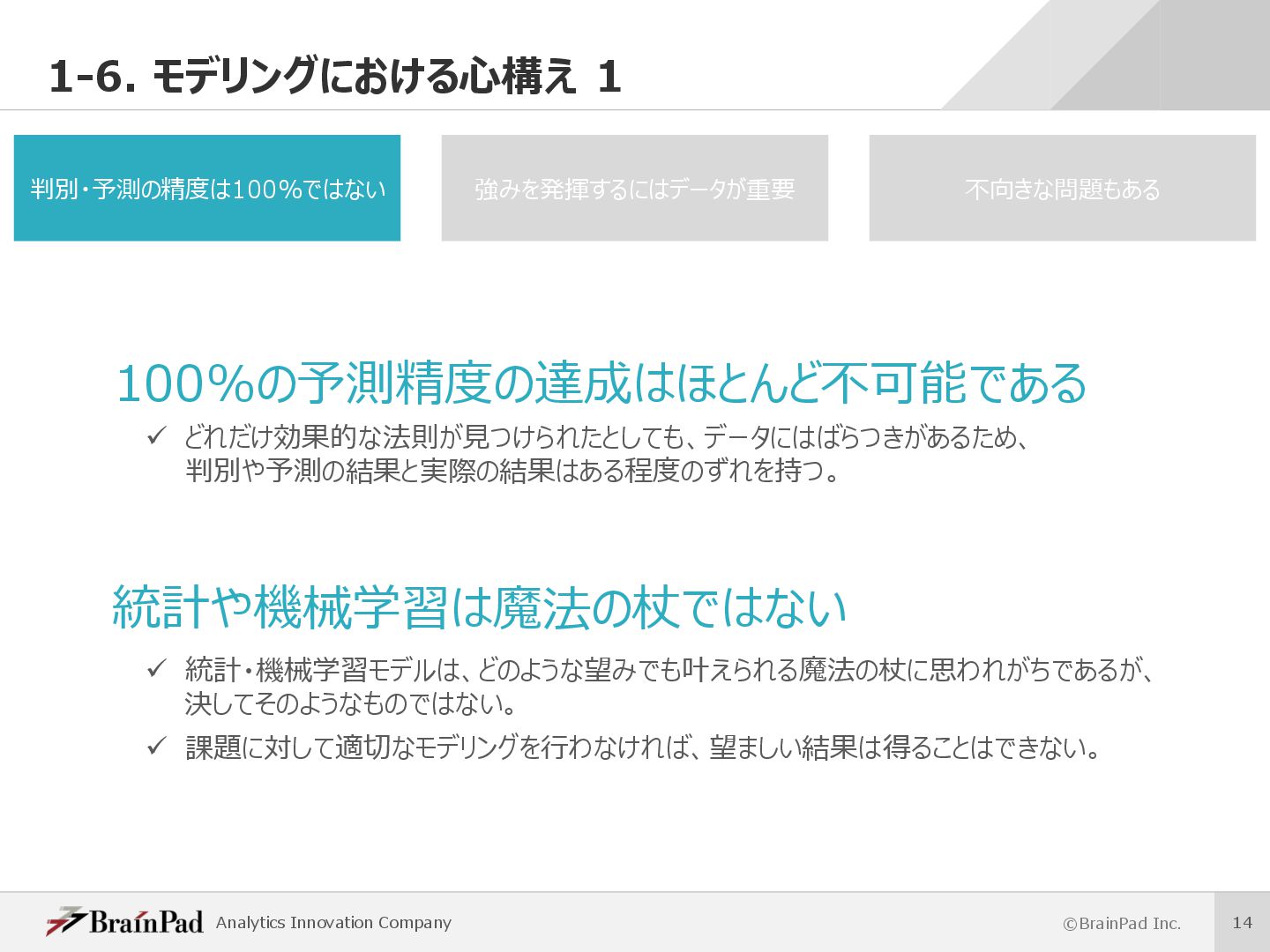
強みを発揮するにはデータが重要 不向きな問題もある 100%の予測精度の達成はほとんど不可能である ü どれだけ効果的な法則が⾒つけられたとしても、データにはばらつきがあるため、 判別や予測の結果と実際の結果はある程度のずれを持つ。 統計や機械学習は魔法の杖ではない ü 統計・機械学習モデルは、どのような望みでも叶えられる魔法の杖に思われがちであるが、 決してそのようなものではない。 ü 課題に対して適切なモデリングを⾏わなければ、望ましい結果は得ることはできない。
判別・予測の精度は100%ではない 強みを発揮するにはデータが重要 不向きな問題もある ü そもそも判別や予測のできない問題や、現在は適応の難しい問題もある。 • 偶発的に起こるもの o サイコロの出⽬、ルーレットの出⽬、コイントスの表裏 • 現象が起こるメカニズムが⾼度に複雑であるもの o 地震の発⽣の予測、メガヒット商品の発⽣の予測、超⾼額購⼊顧客の発⽣の予測 • 過去にデータが無いもの o 全く新しい施策の効果の予測、全くの新商品の販売数の予測
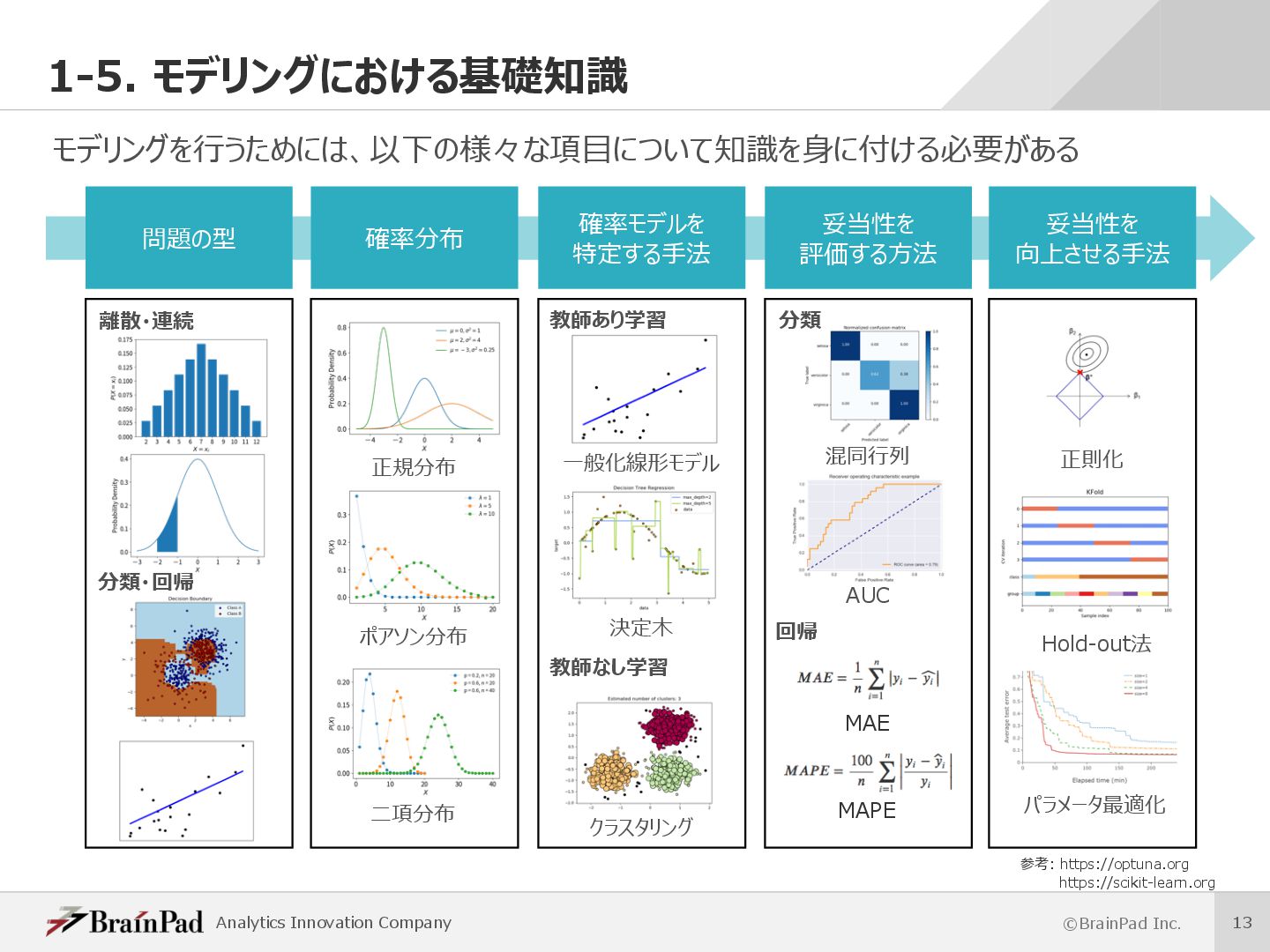
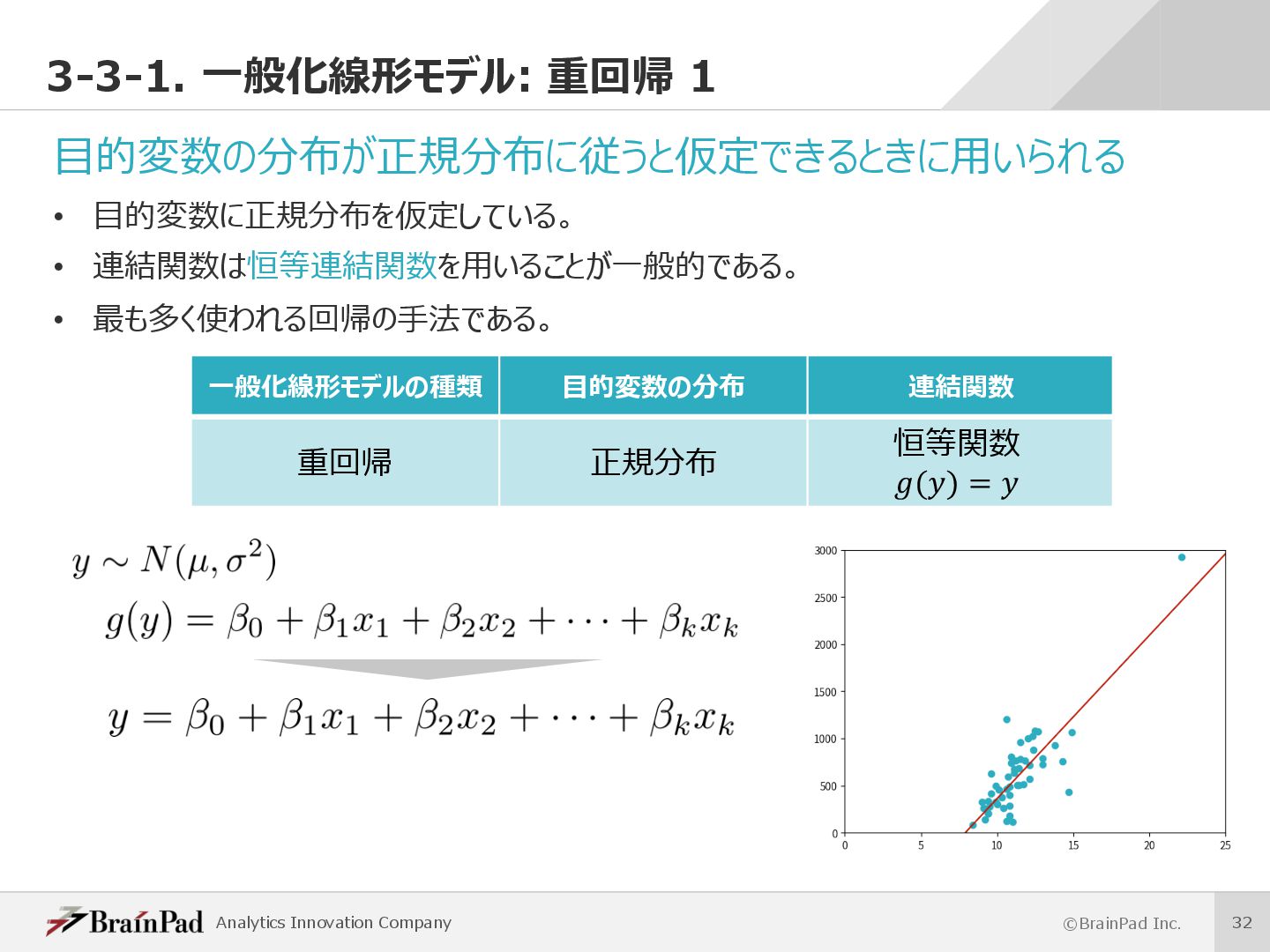
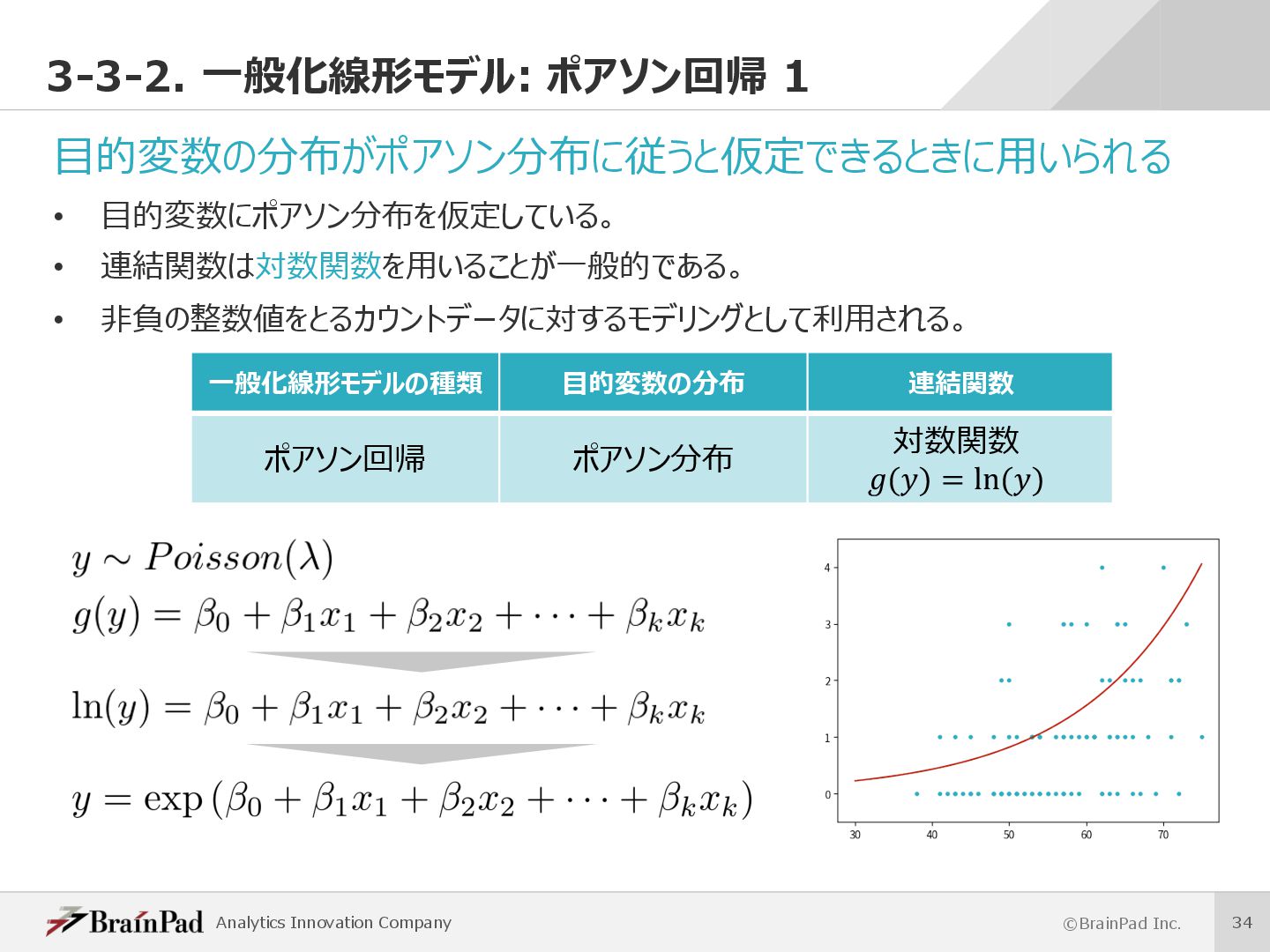
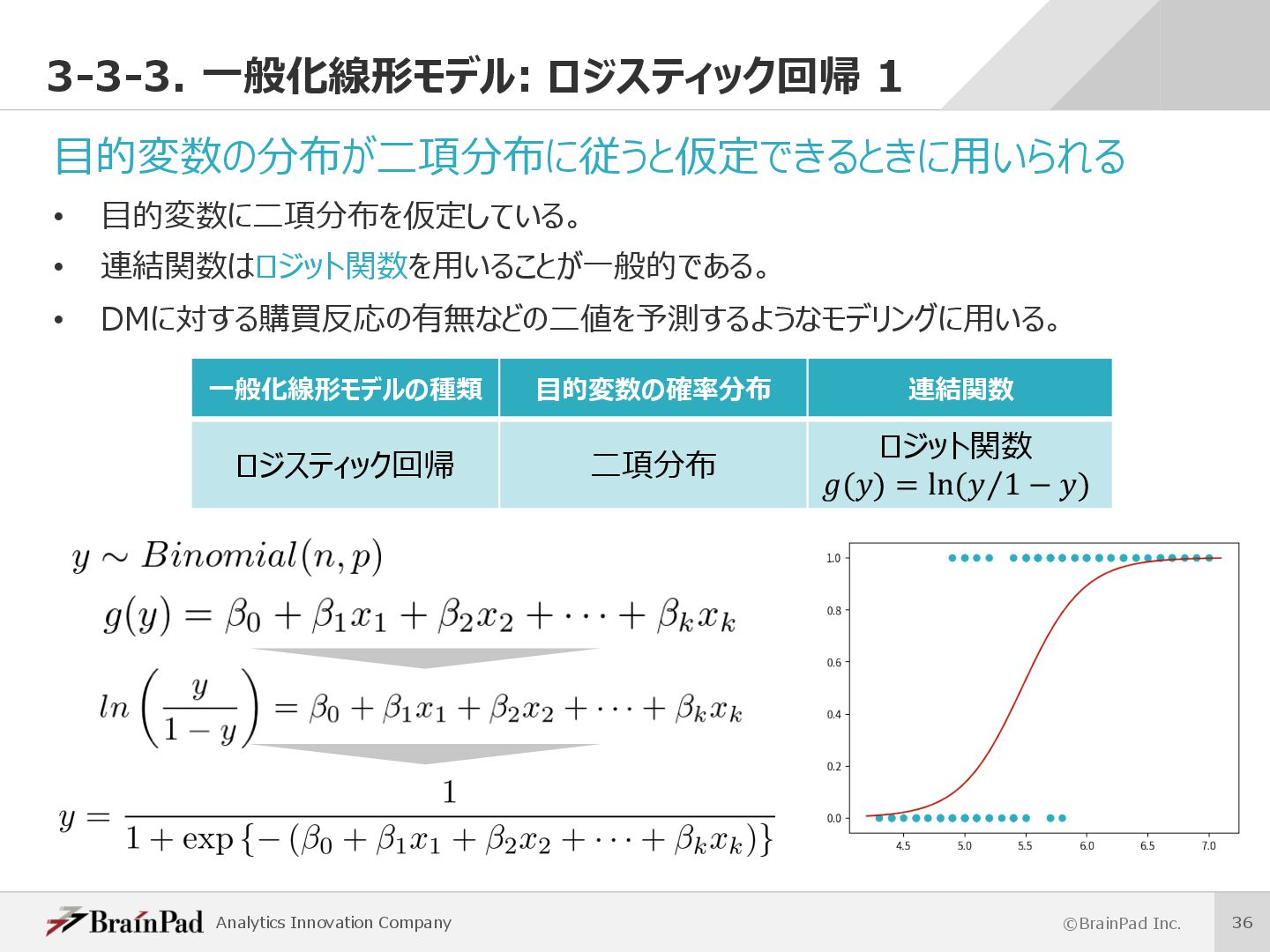
Generalized Linear Model (GLM)とも呼ばれる。 • よく⽤いられるものに線形回帰・ポアソン回帰・ロジスティック回帰がある。 • ⽬的変数が特定の確率分布に従うことが仮定されるときに⽤いられる。 • ⽬的変数と線形予測⼦の関係を、⽬的変数の確率分布に対応した連結関数(リンク関数)を⽤いて表現する。 • 既に述べた線形モデルは、⼀般化線形モデルの1つとして捉えられる。 ü 線形モデル ü ⼀般化線形モデル • 線形モデルでは⽬的変数と線形予測⼦の関係が恒等連結関数で表現されている。 連結関数 線形予測⼦
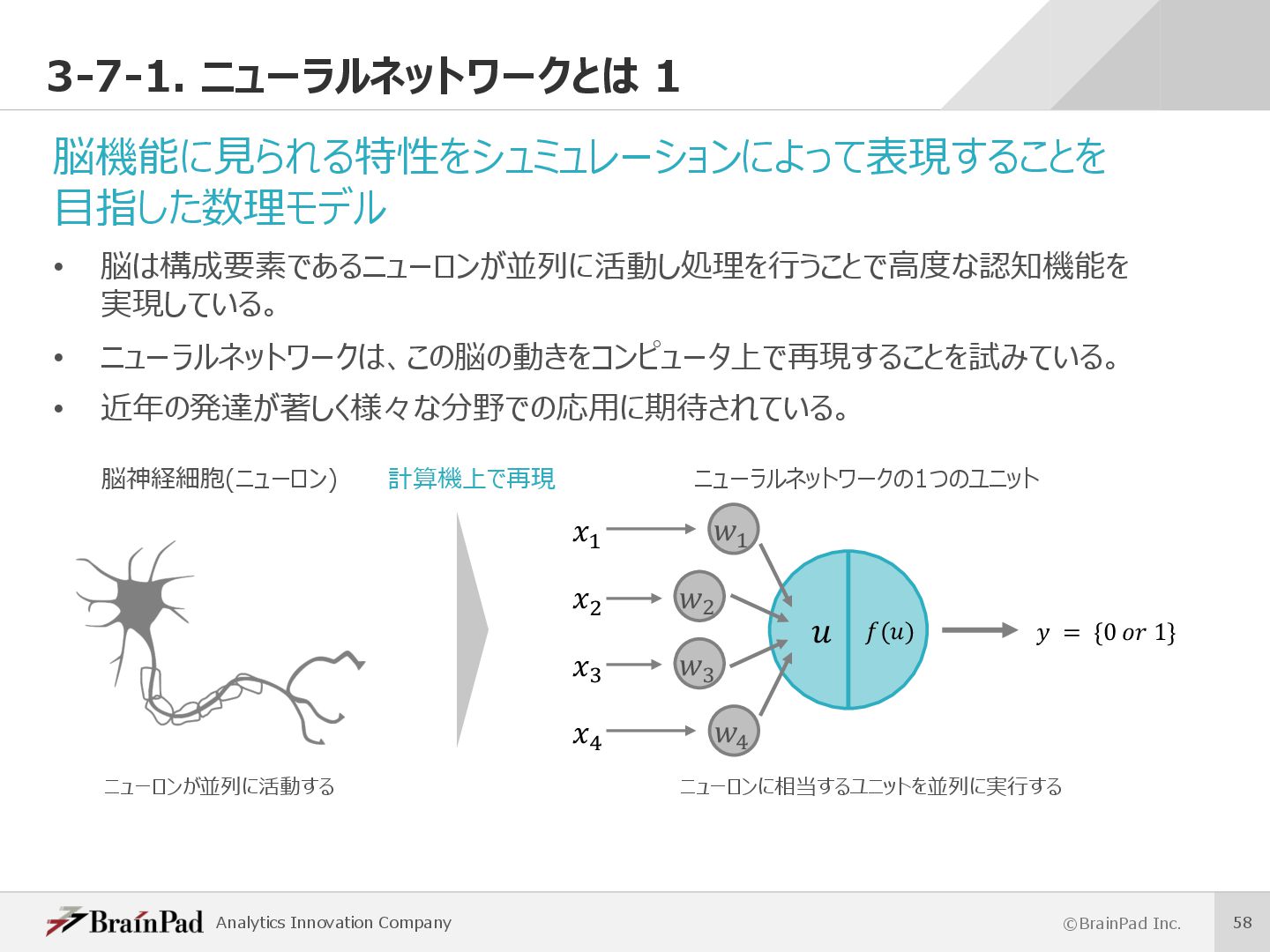
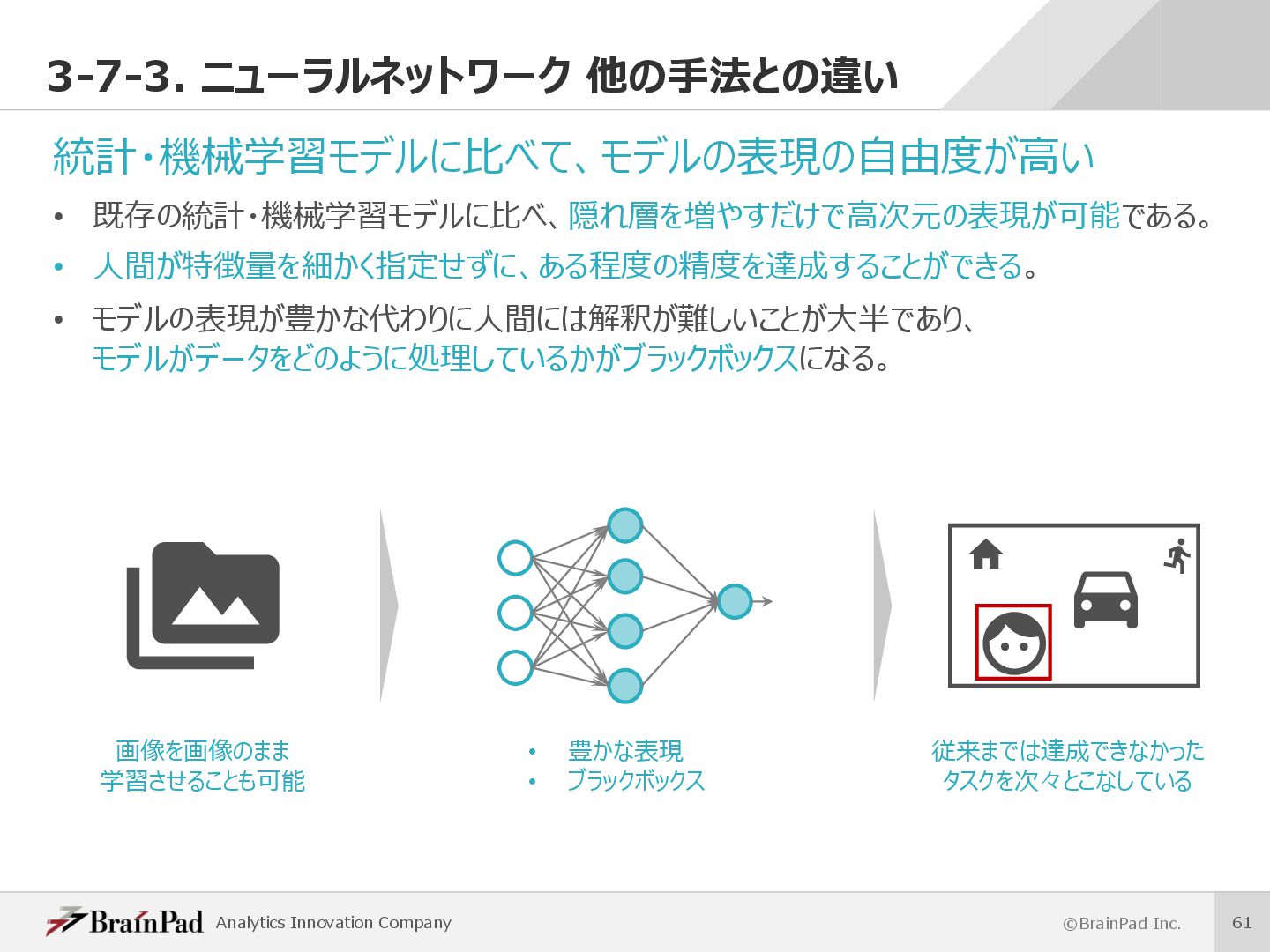
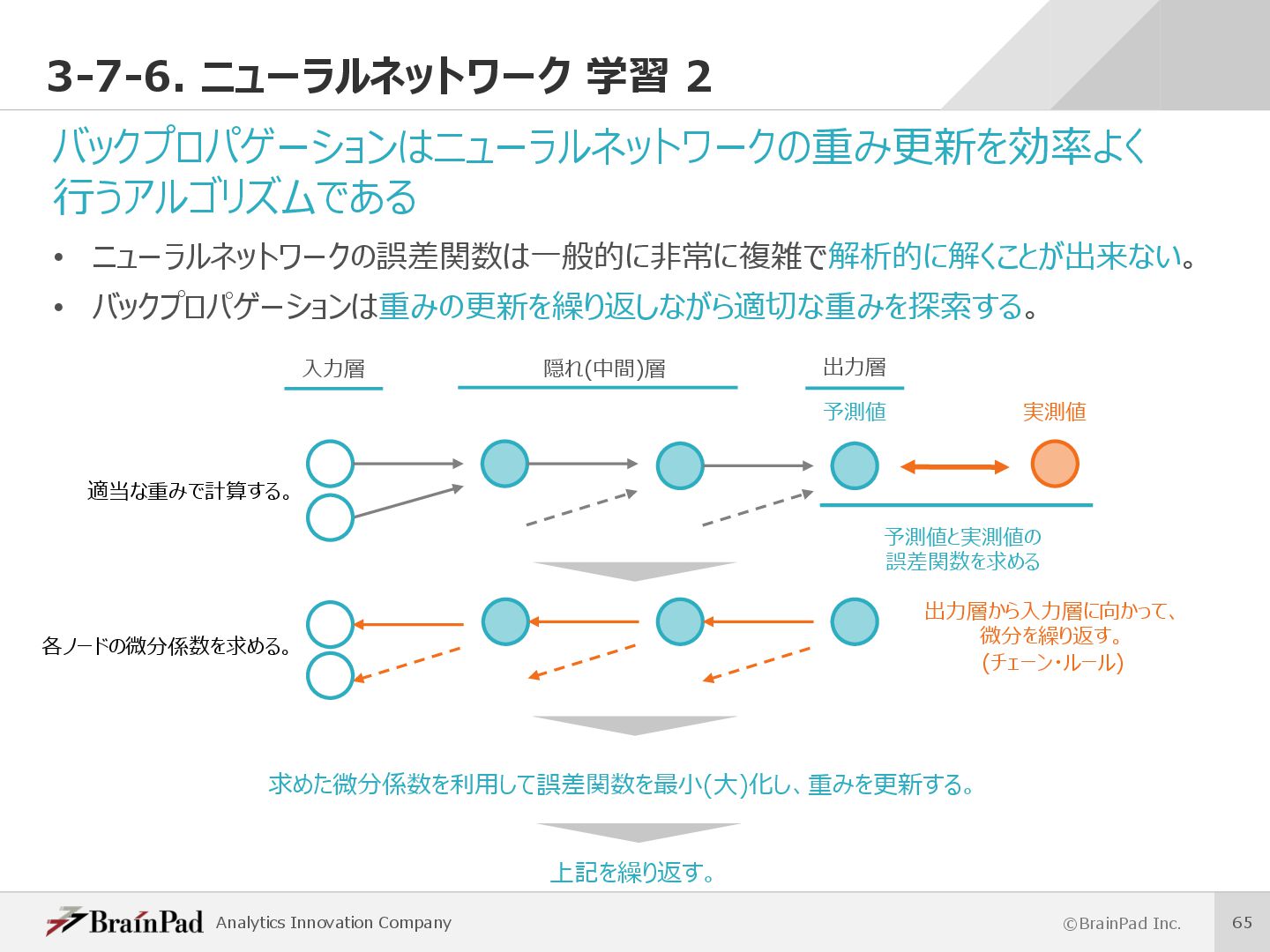
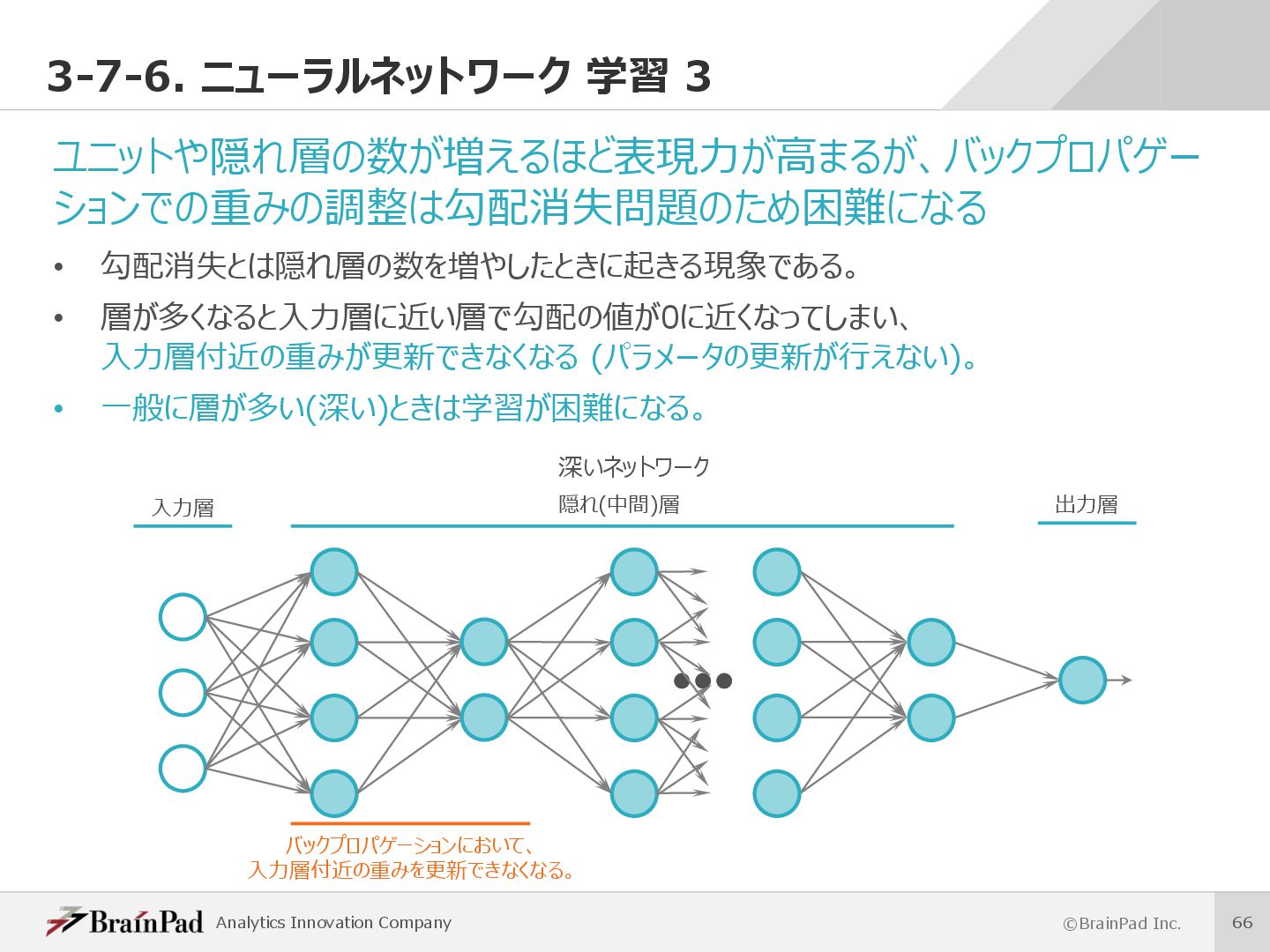
⽬指した数理モデル • 脳は構成要素であるニューロンが並列に活動し処理を⾏うことで⾼度な認知機能を 実現している。 • ニューラルネットワークは、この脳の動きをコンピュータ上で再現することを試みている。 • 近年の発達が著しく様々な分野での応⽤に期待されている。 計算機上で再現 脳神経細胞(ニューロン) () h h i i r r s s = {0 1} ニューラルネットワークの1つのユニット ニューロンが並列に活動する ニューロンに相当するユニットを並列に実⾏する
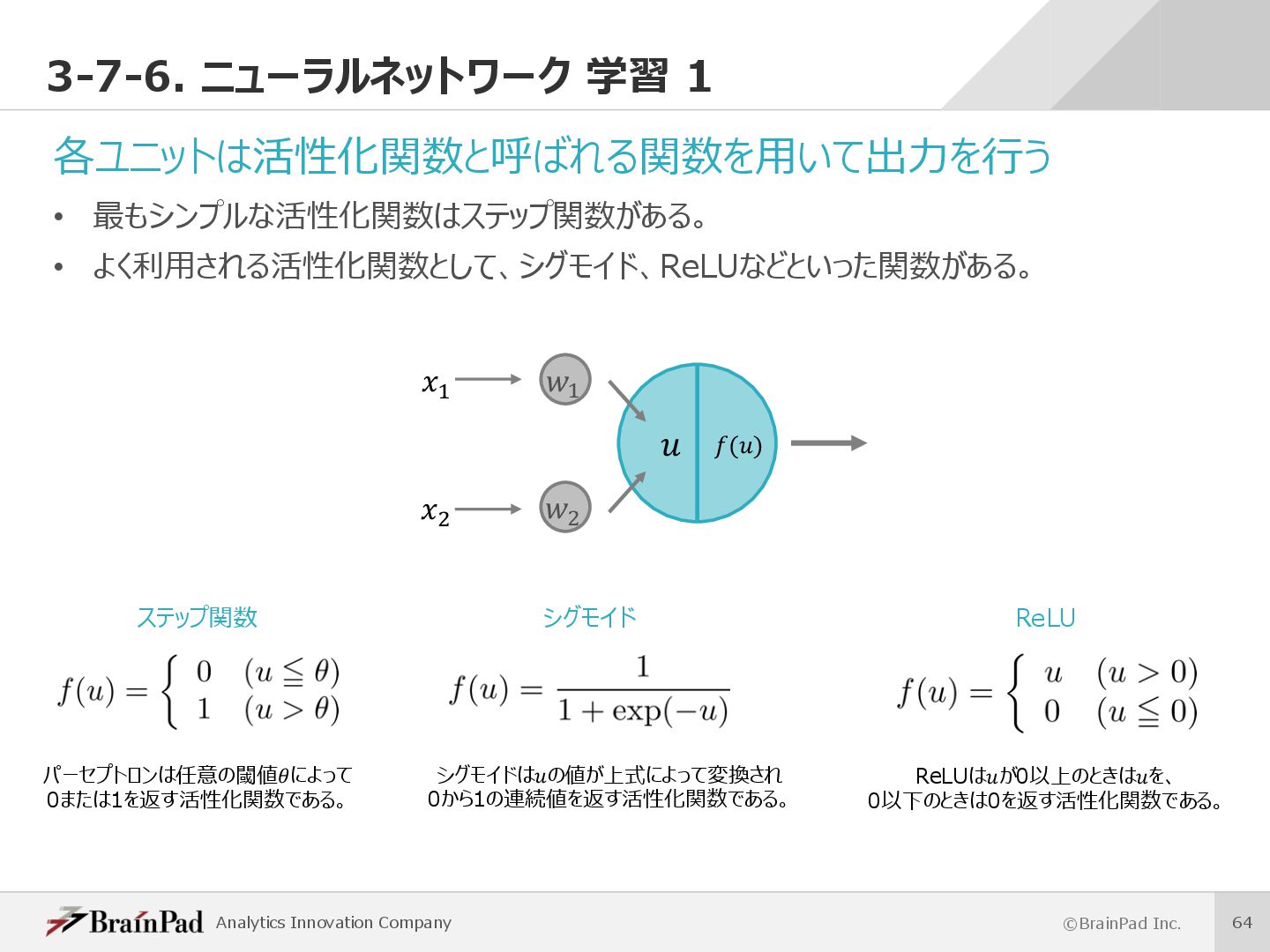
各ユニットは活性化関数と呼ばれる関数を⽤いて出⼒を⾏う • 最もシンプルな活性化関数はステップ関数がある。 • よく利⽤される活性化関数として、シグモイド、ReLUなどといった関数がある。 () h h i i シグモイドはの値が上式によって変換され 0から1の連続値を返す活性化関数である。 パーセプトロンは任意の閾値によって 0または1を返す活性化関数である。 ReLUはが0以上のときはを、 0以下のときは0を返す活性化関数である。 ステップ関数 シグモイド ReLU
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
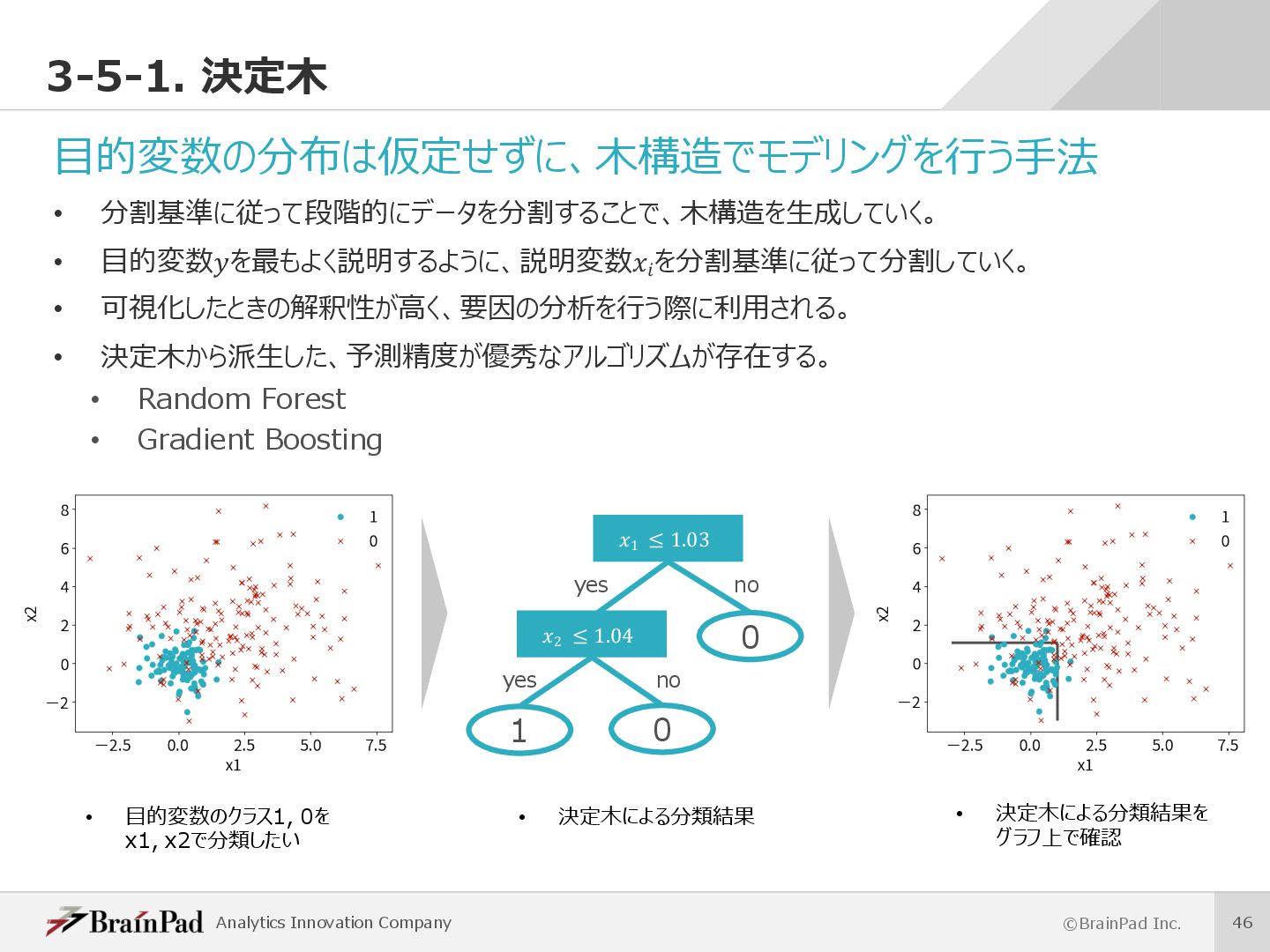{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
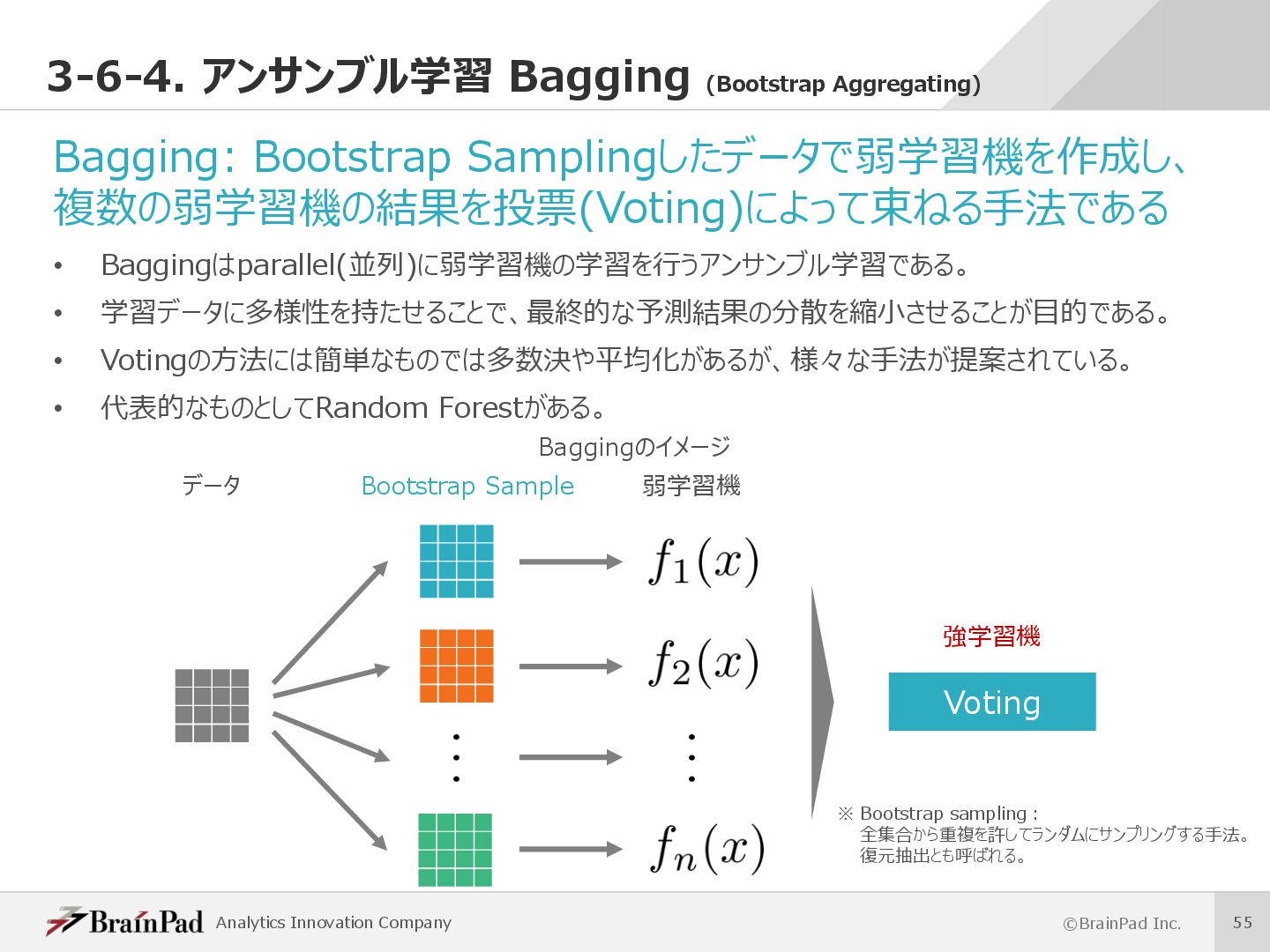{kind=link}
{kind=link}
{kind=link}
{kind=link}
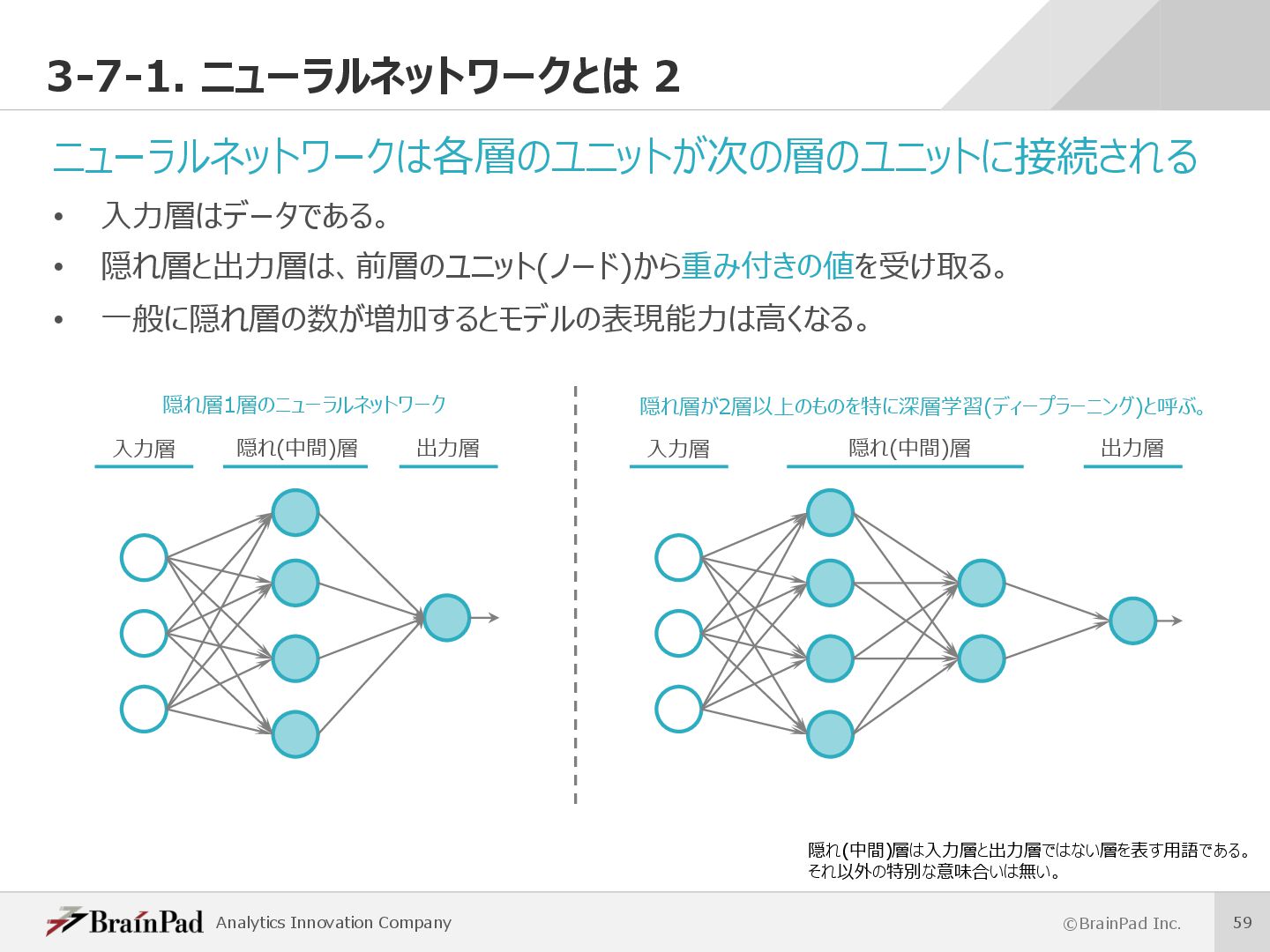{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
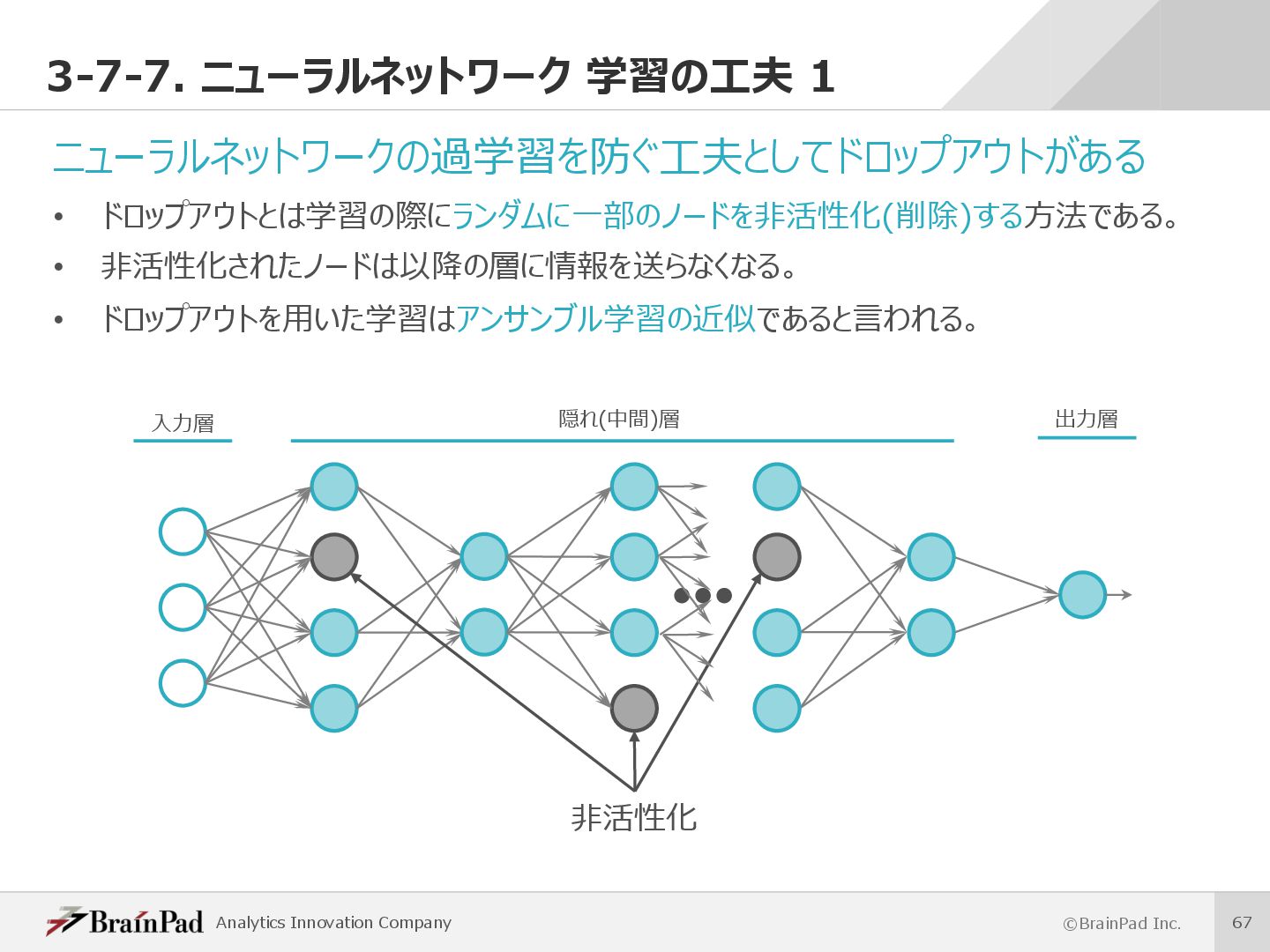{kind=link}
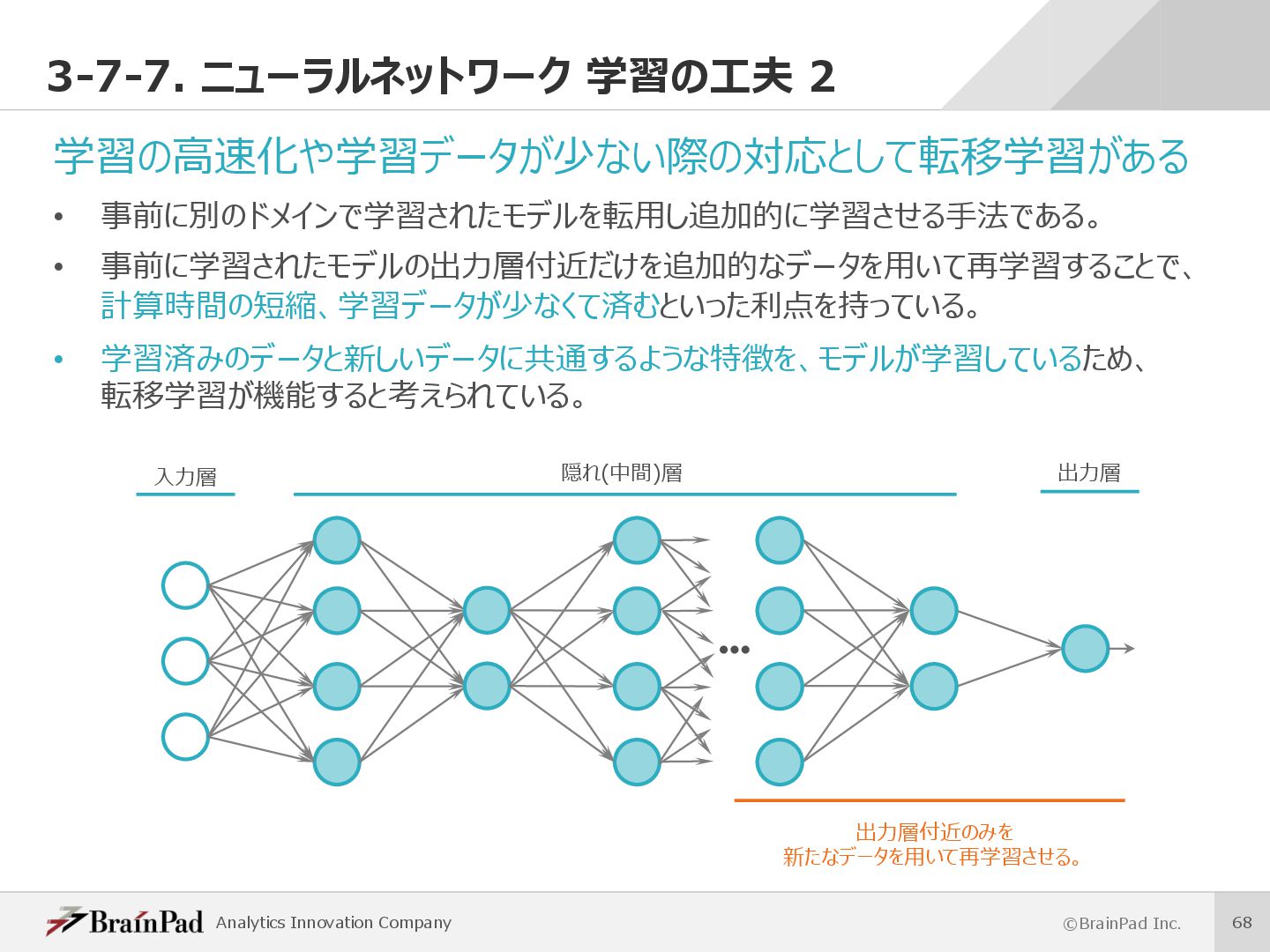{kind=link}
{kind=link}
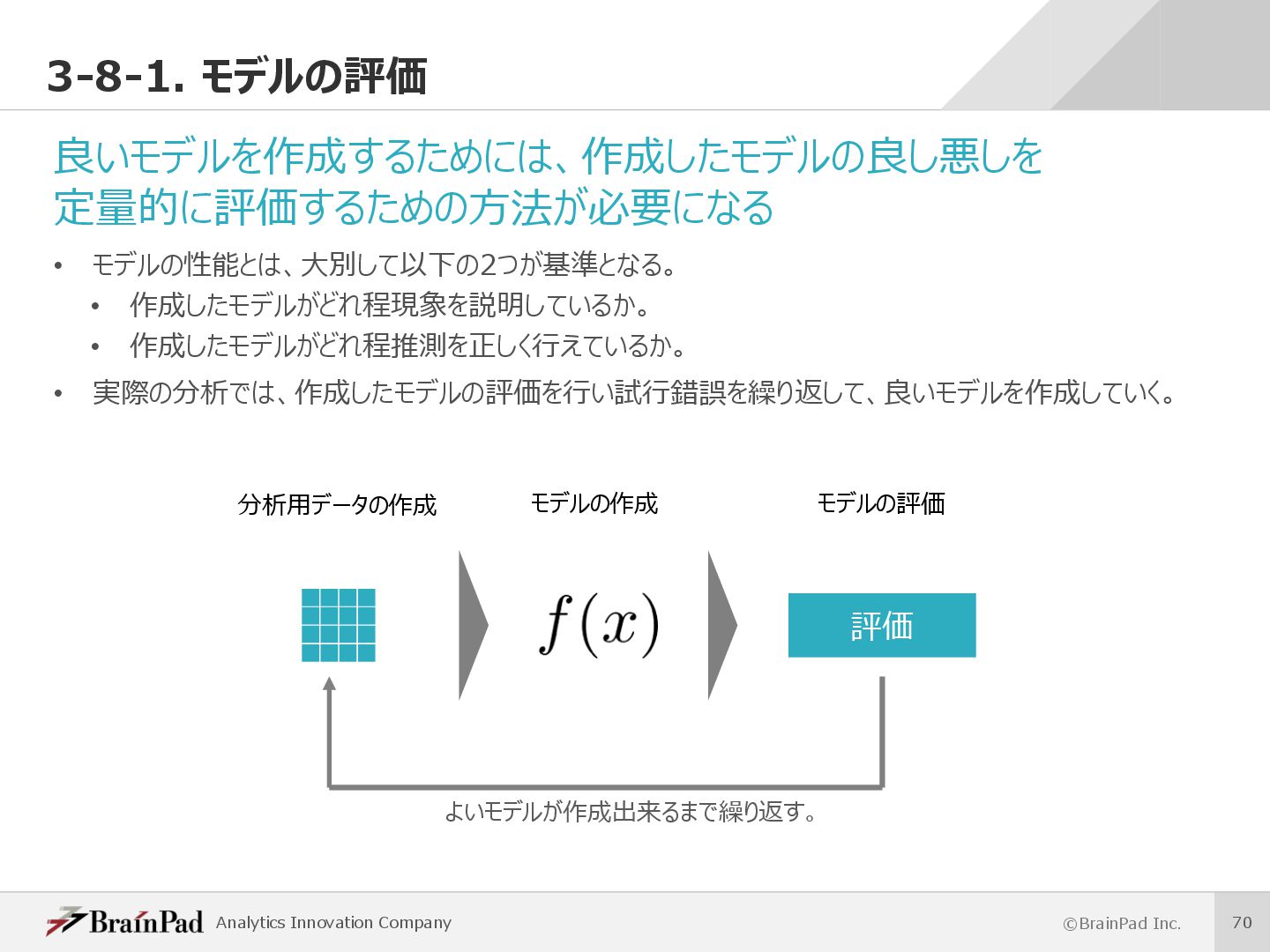{kind=link}
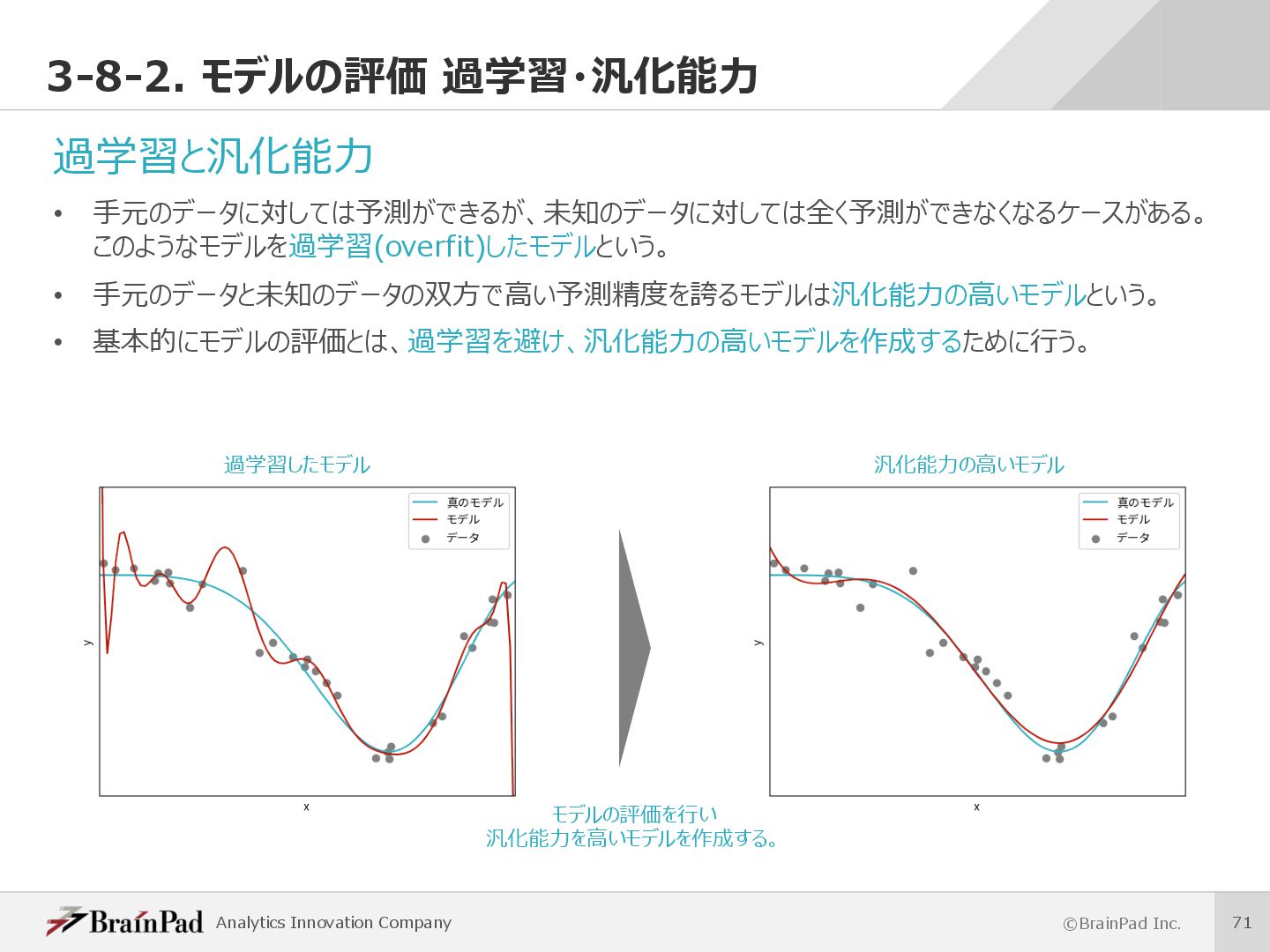{kind=link}
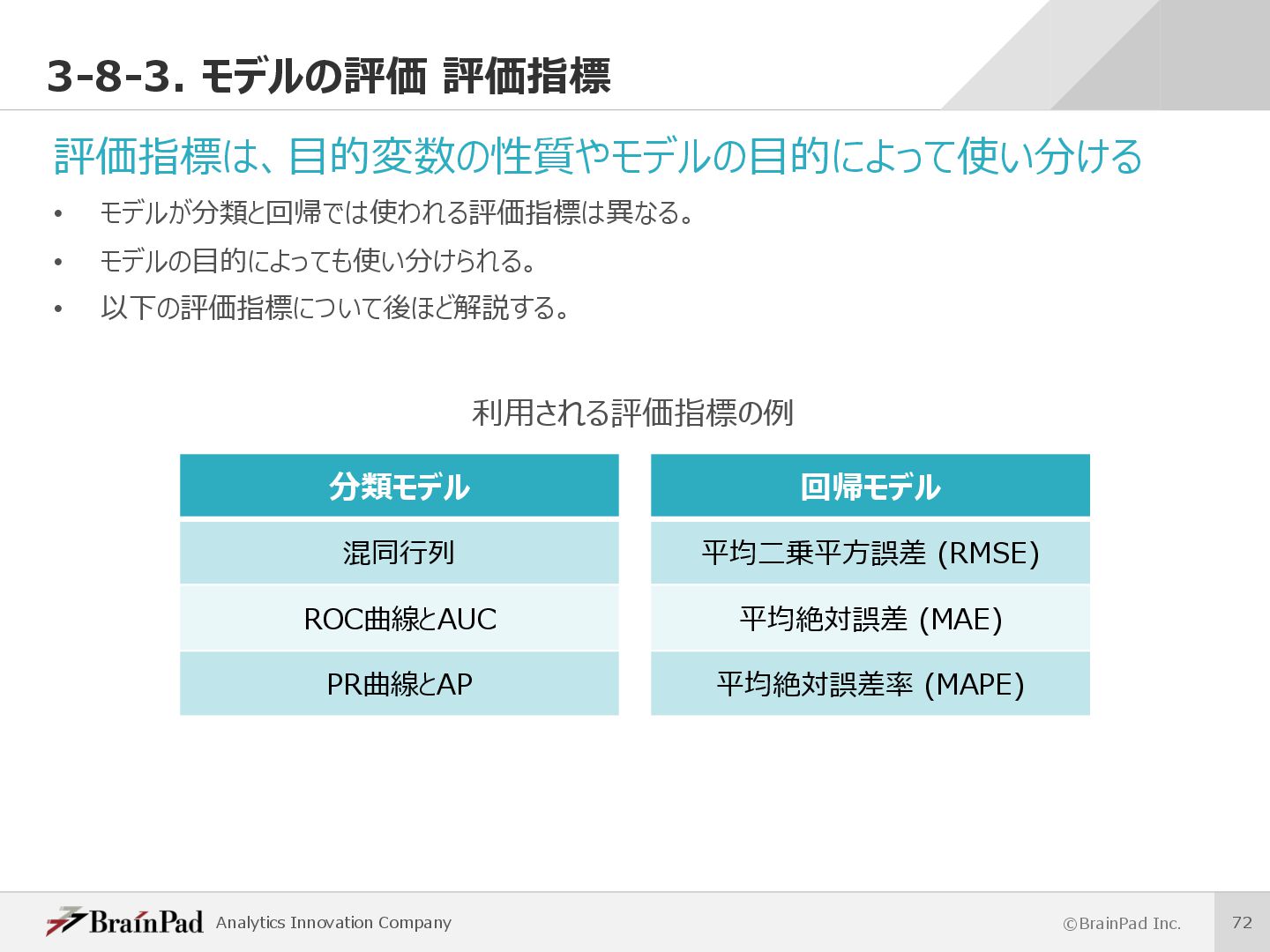{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
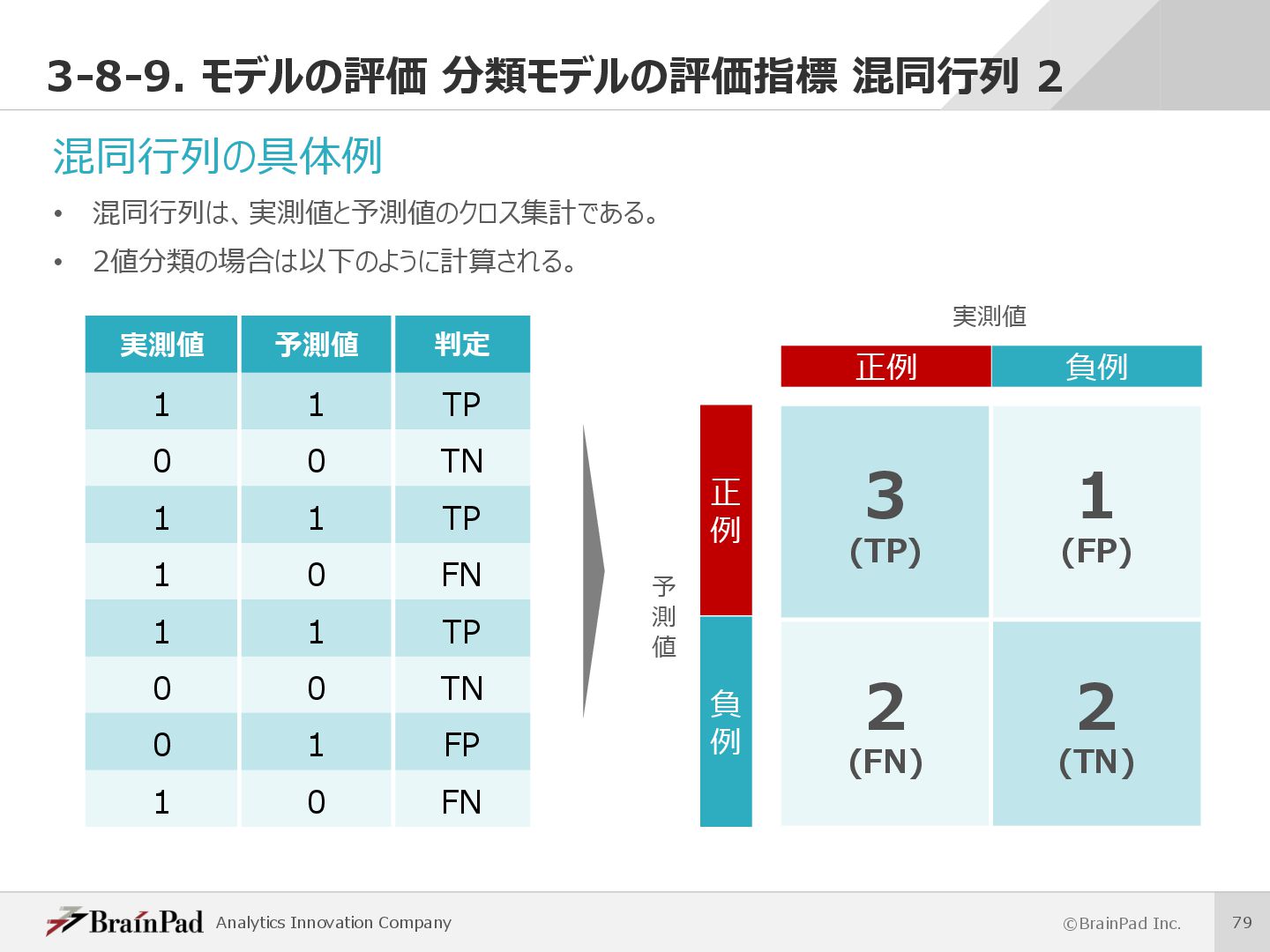{kind=link}
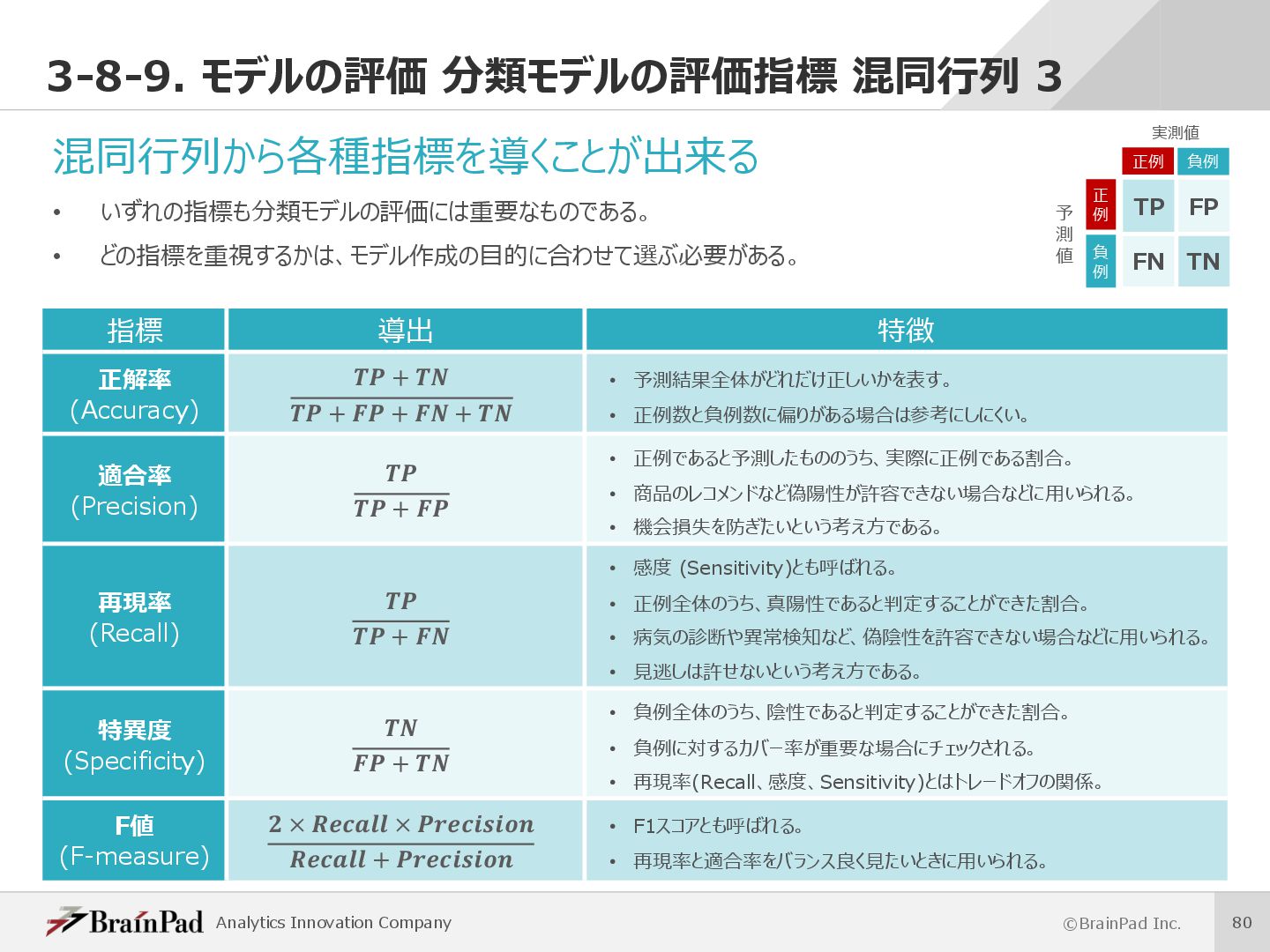{kind=link}
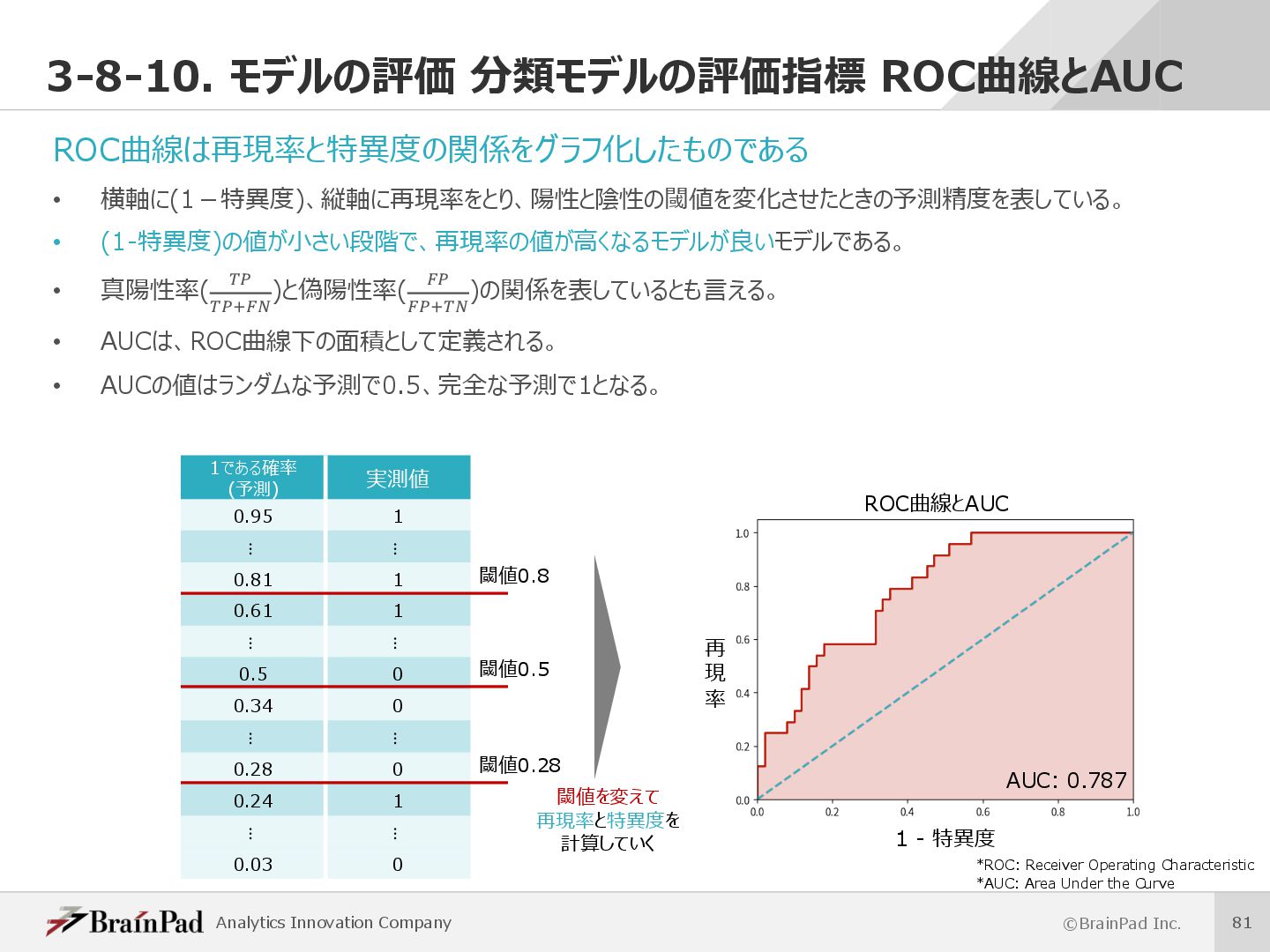{kind=link}
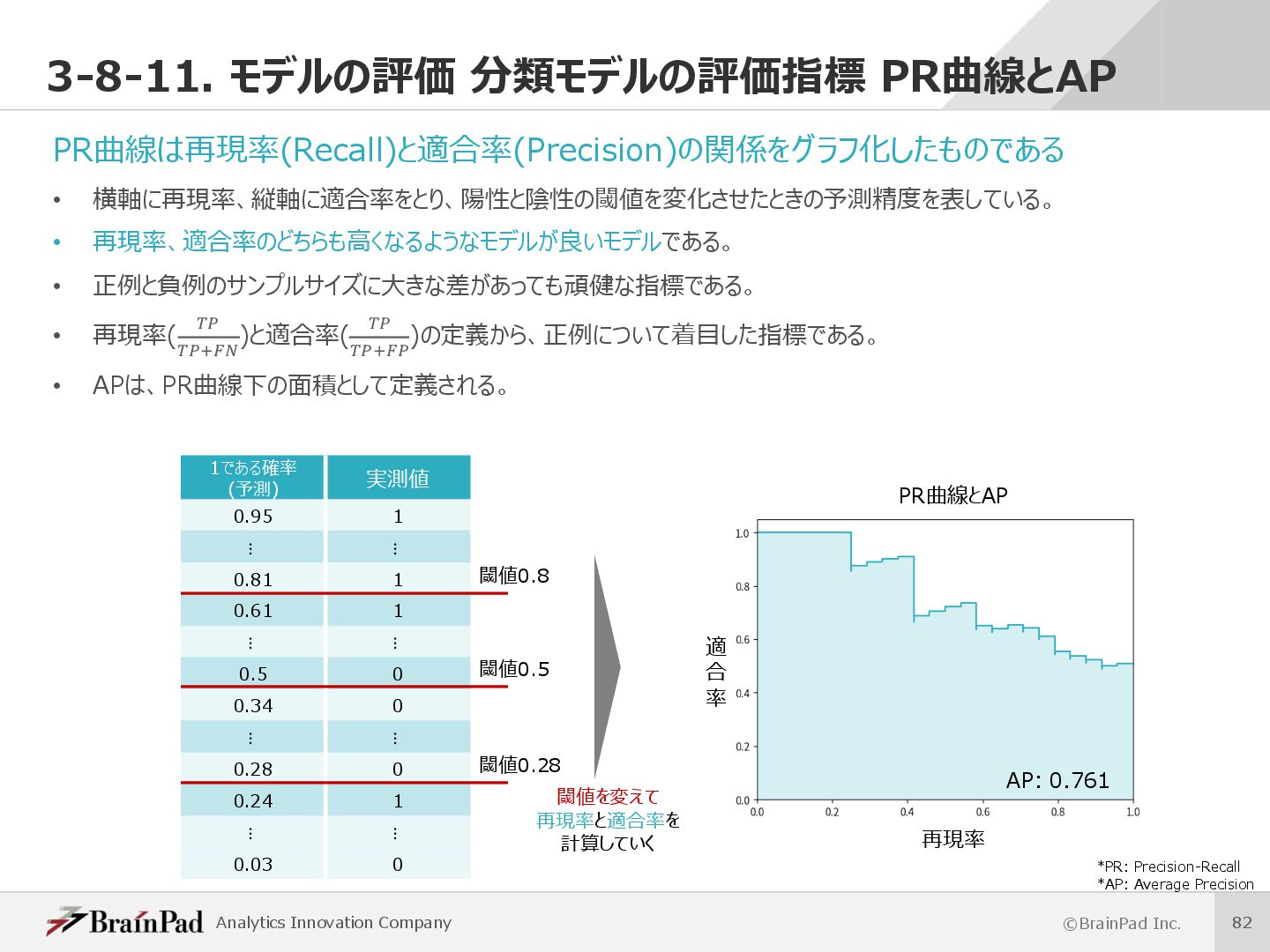{kind=link}
{kind=link}
{kind=link}
{kind=link}
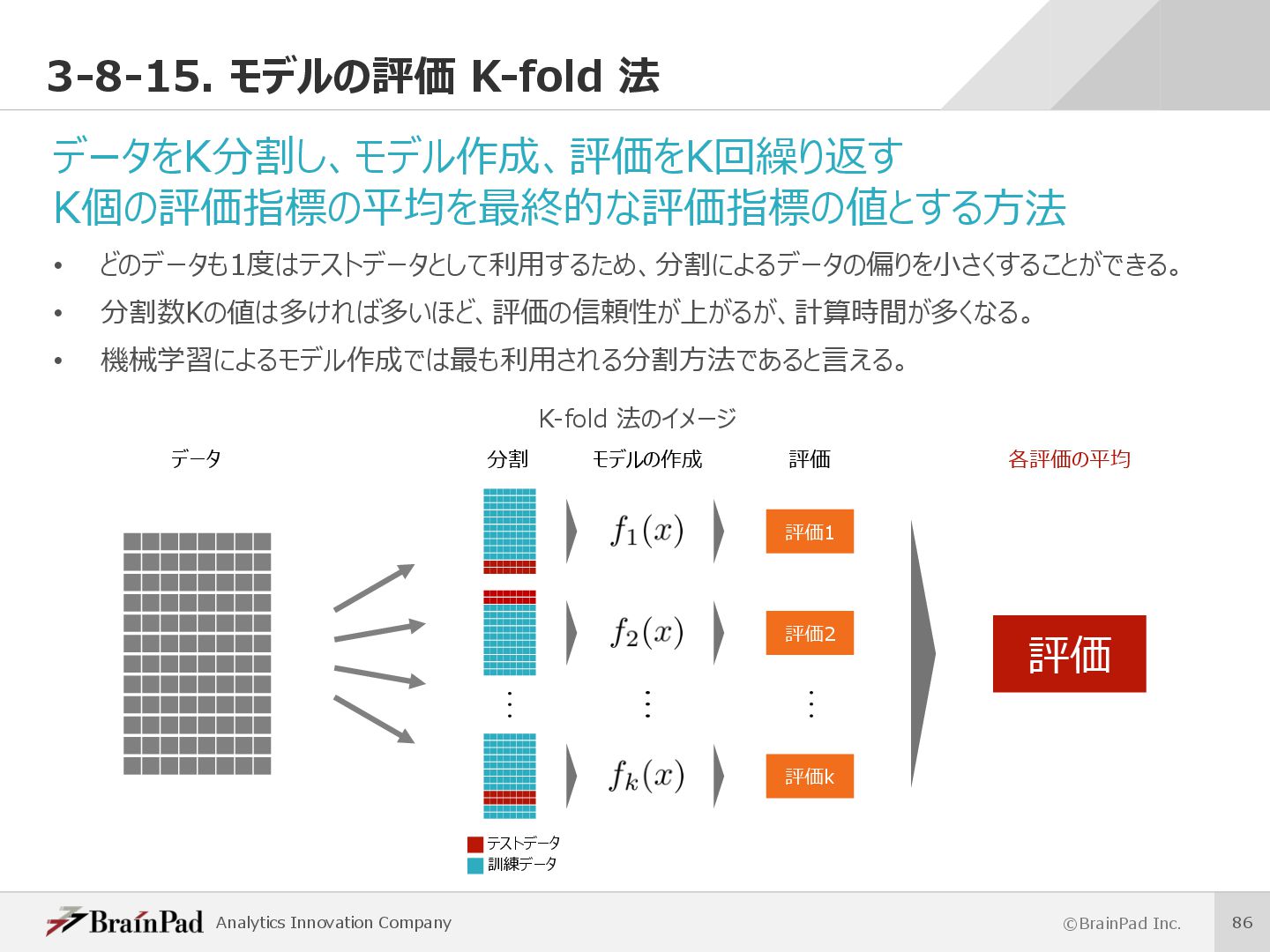{kind=link}
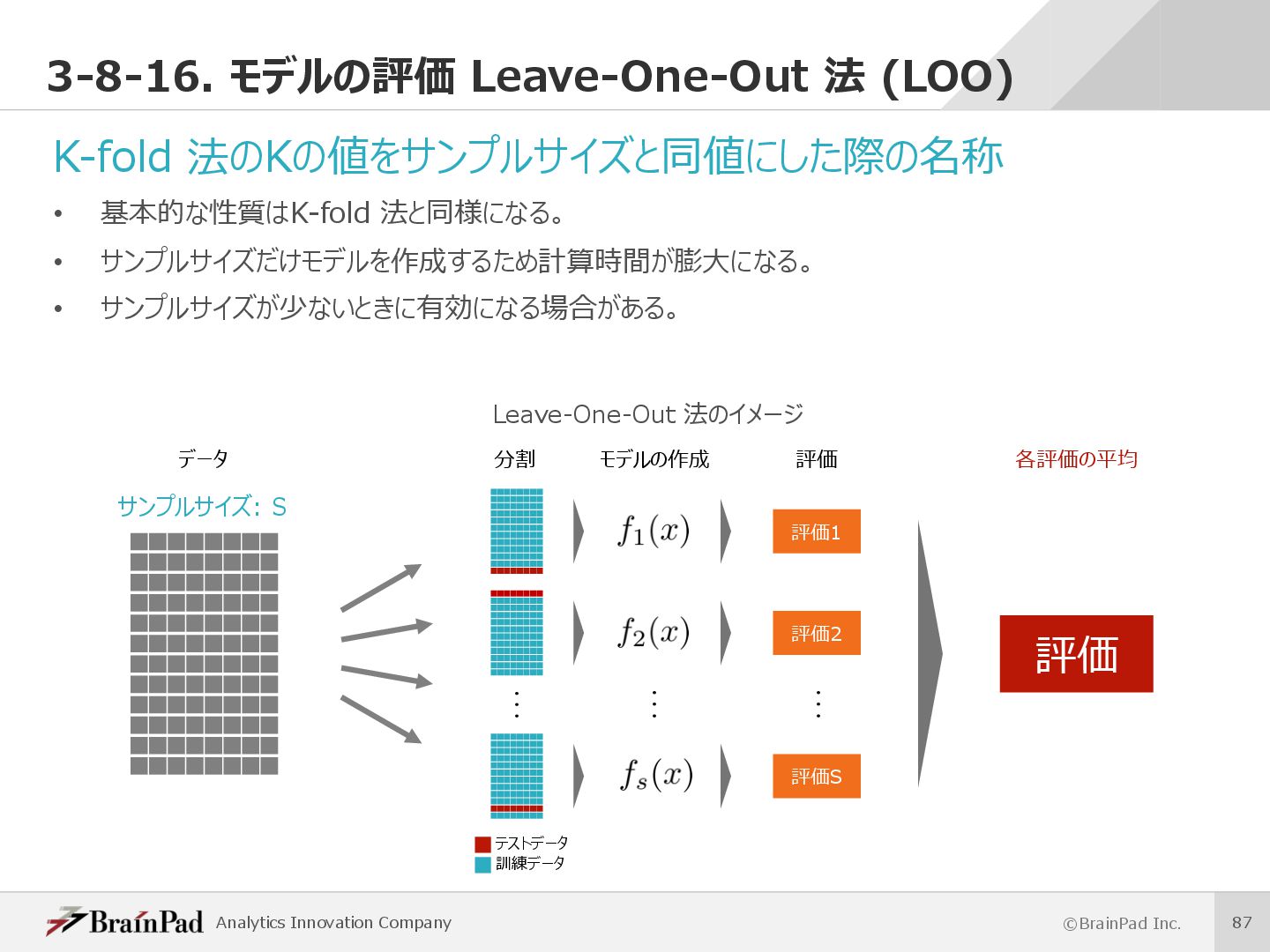{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
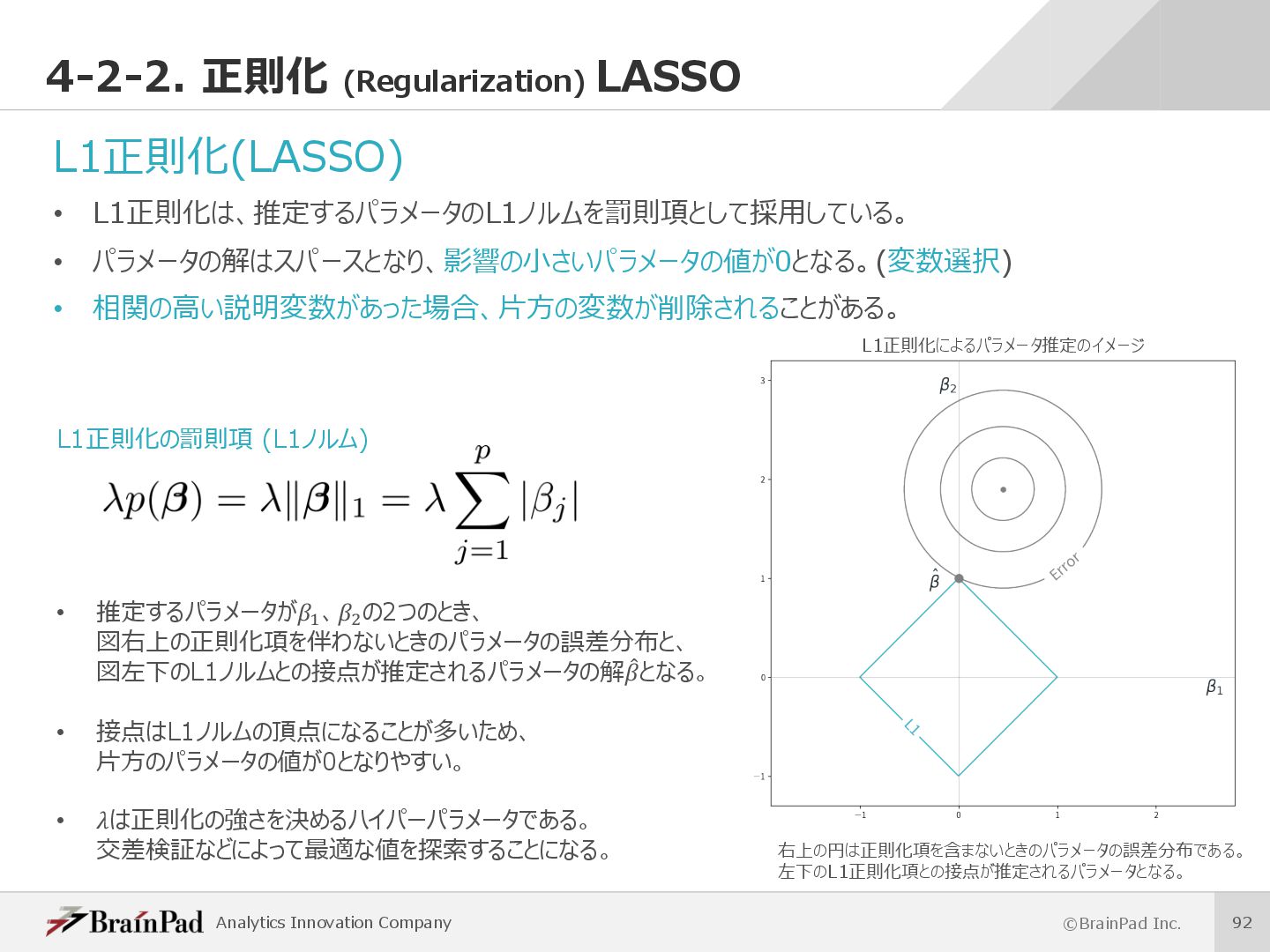{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
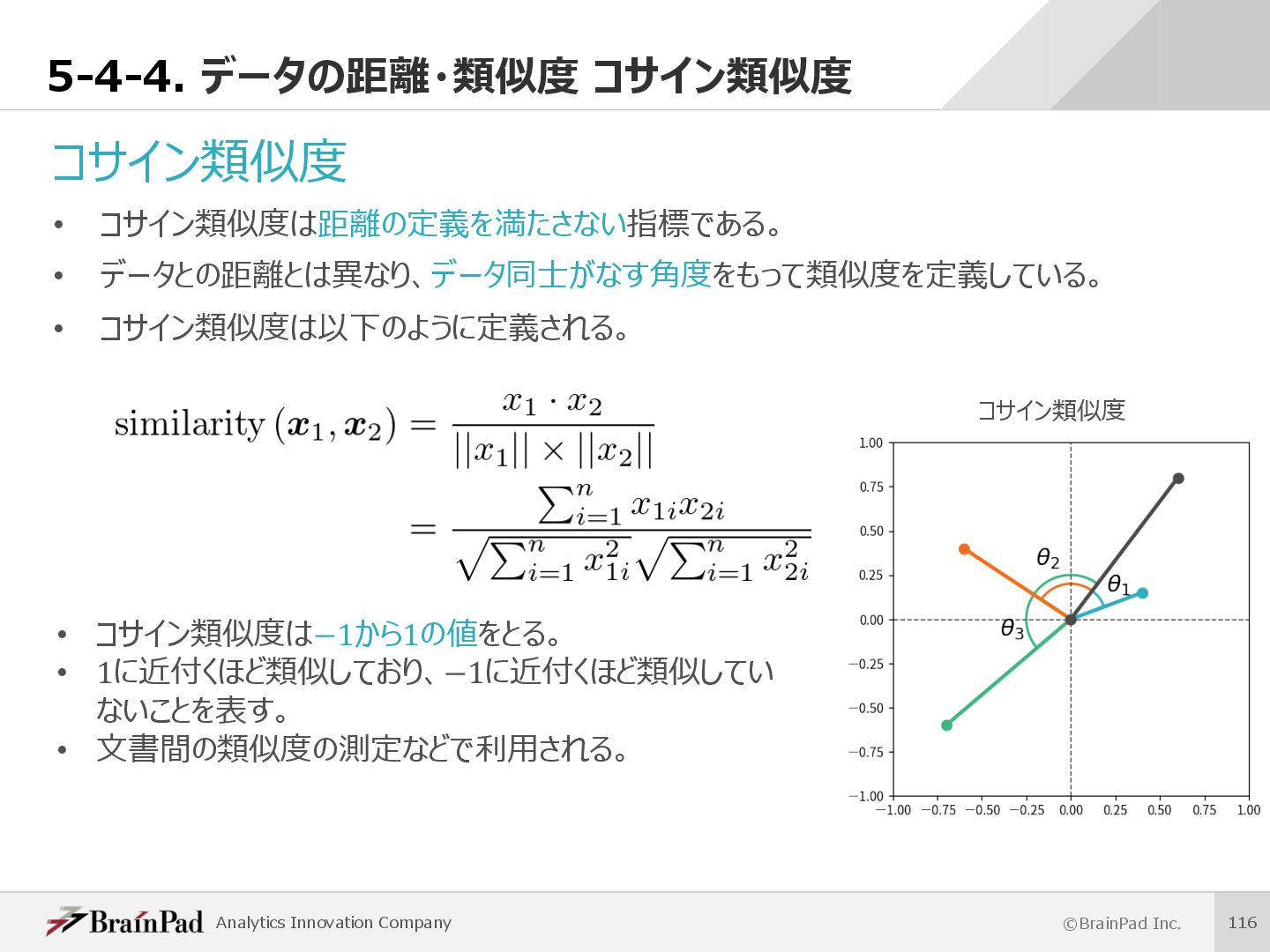{kind=link}
{kind=link}
{kind=link}
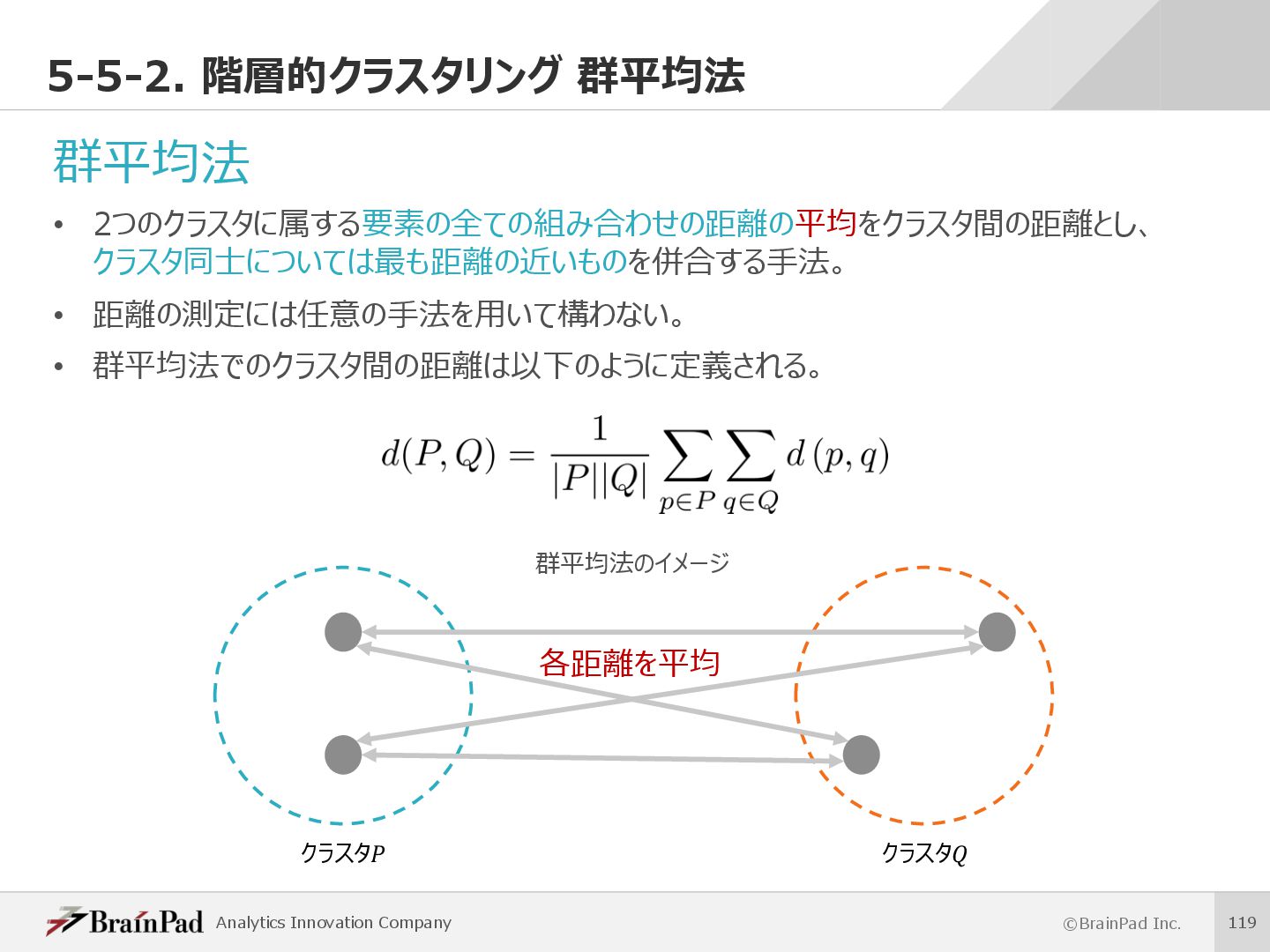{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
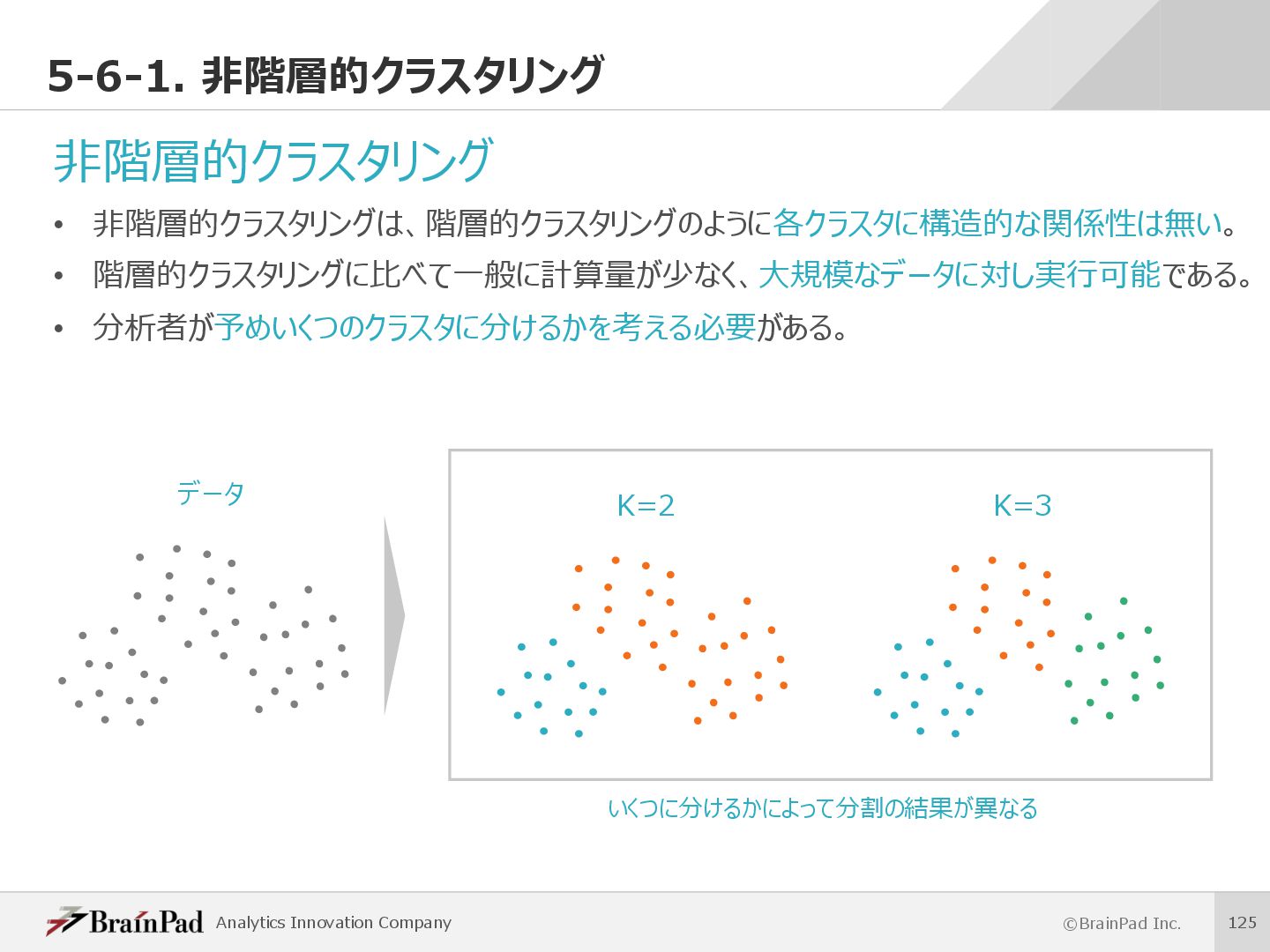{kind=link}
{kind=link}
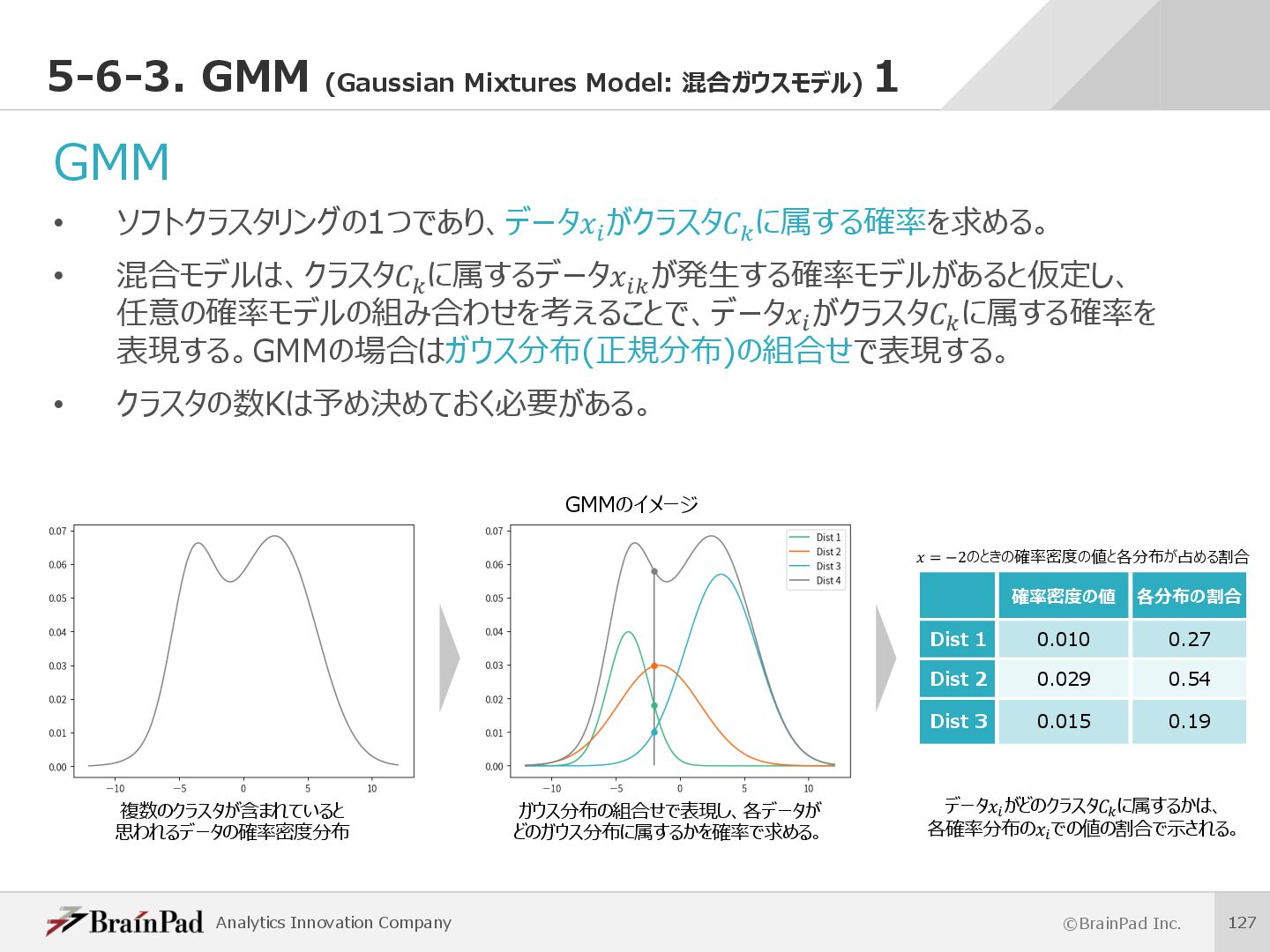{kind=link}
{kind=link}
{kind=link}