This intermediate level talk will focus on introducing the three pillars of Observability (1: structured logging 2: metrics 3: tracing) to your Python application. The learning objective is to introduce existing Python developers to each area as well as best practices (RED/four golden signals) and the specific Python libraries they can use in their applications. It aim is that by the end people will know how to add specific tools plus related best practices to their existing applications to provide greater insight into their systems. The closest example is that this talk will pragmatically present the content of "Distributed Systems Observability" O'Reilly into concrete actions and libraries to use. Some anecdotes and examples of how these have gone for the speaker in his production systems will also be noted.
{kind=link}
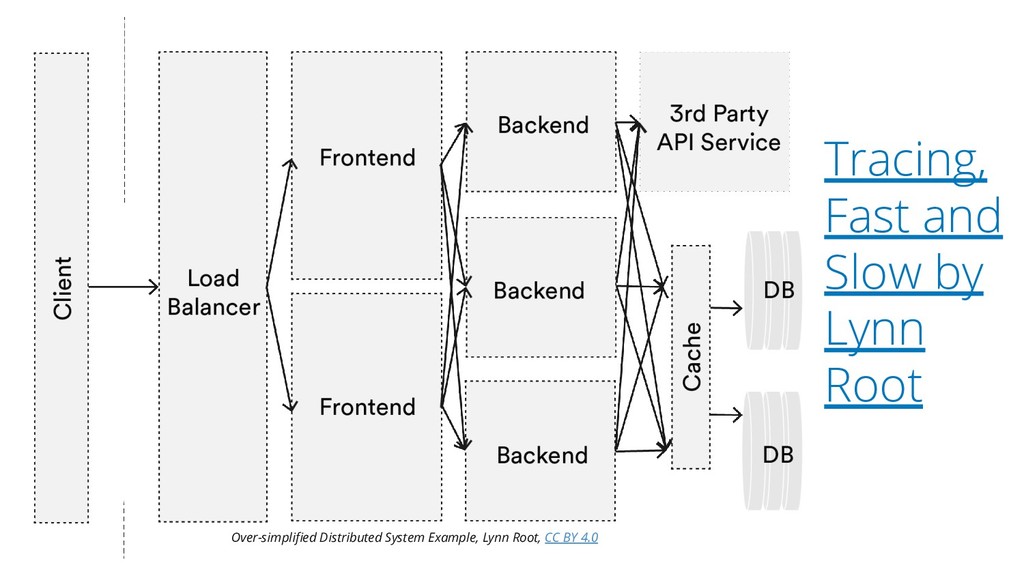{kind=link}
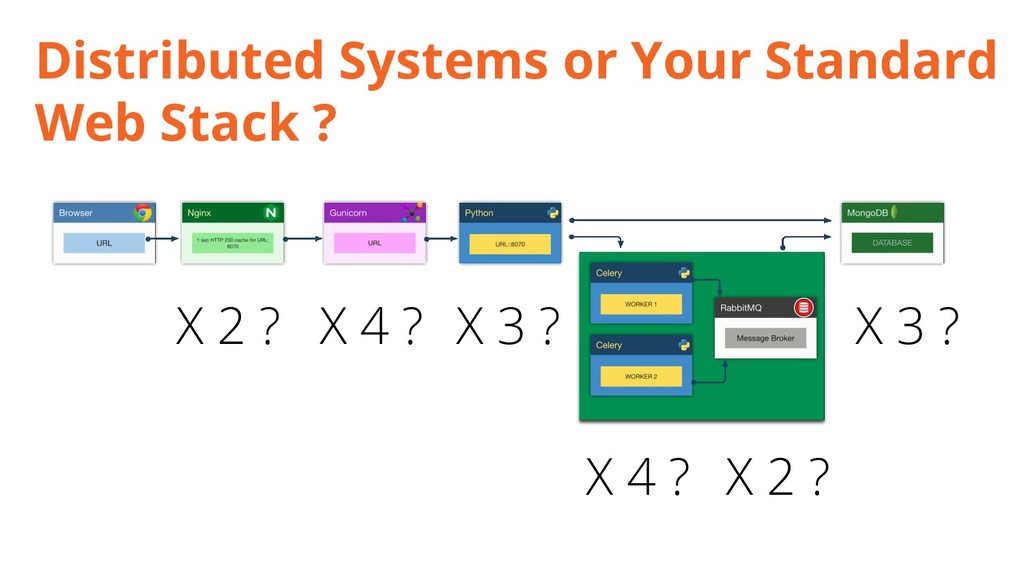{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[2018-10-17 20:00:17 +0100] [33353] [INFO] Goin' Fast @ http://0.0.0.0:8006 [2018-10-17](https://files.speakerdeck.com/presentations/9daaf609dc0548139dff46c8b9ab1c33/slide_11.jpg){kind=link}
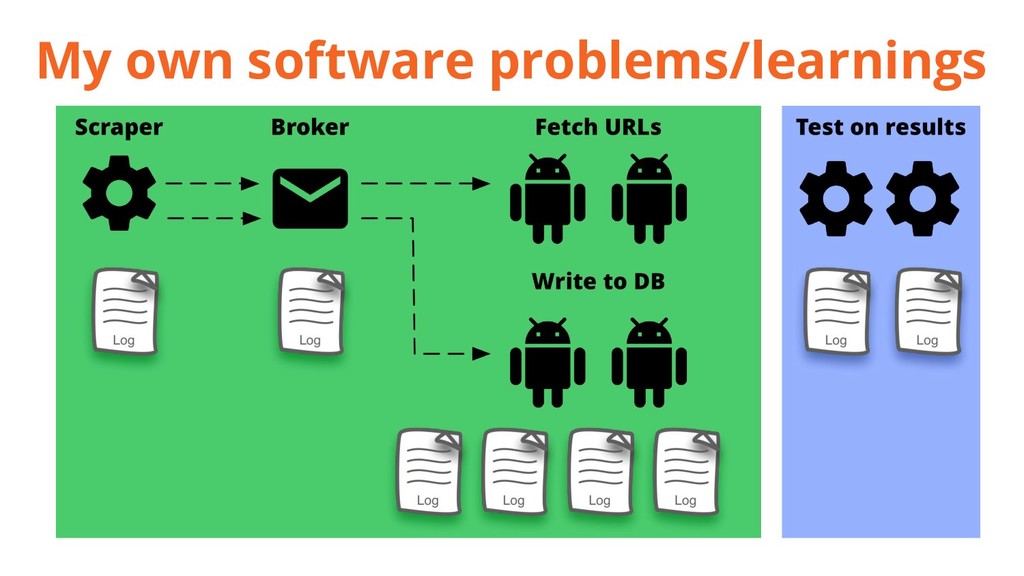{kind=link}
{kind=link}
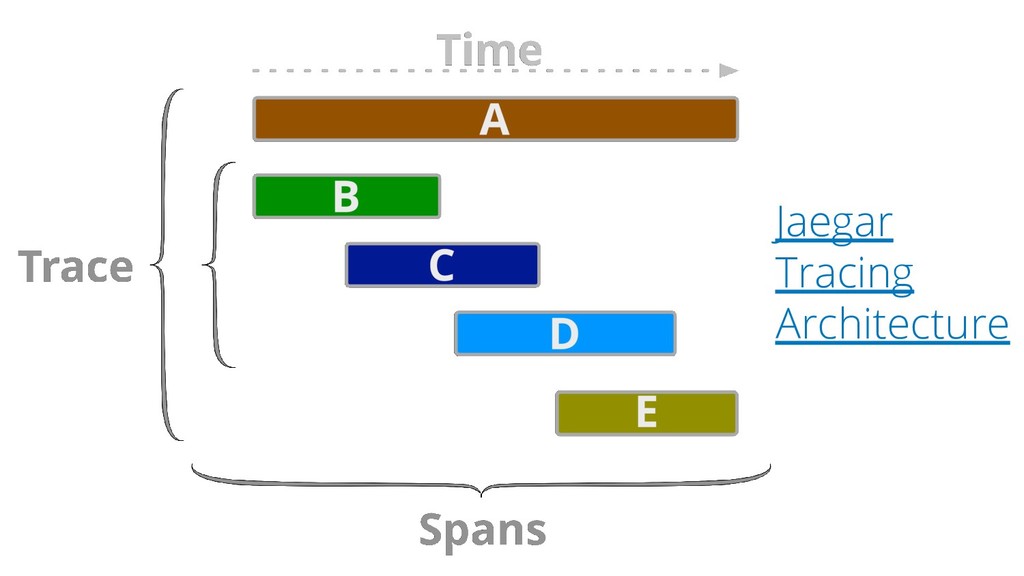{kind=link}
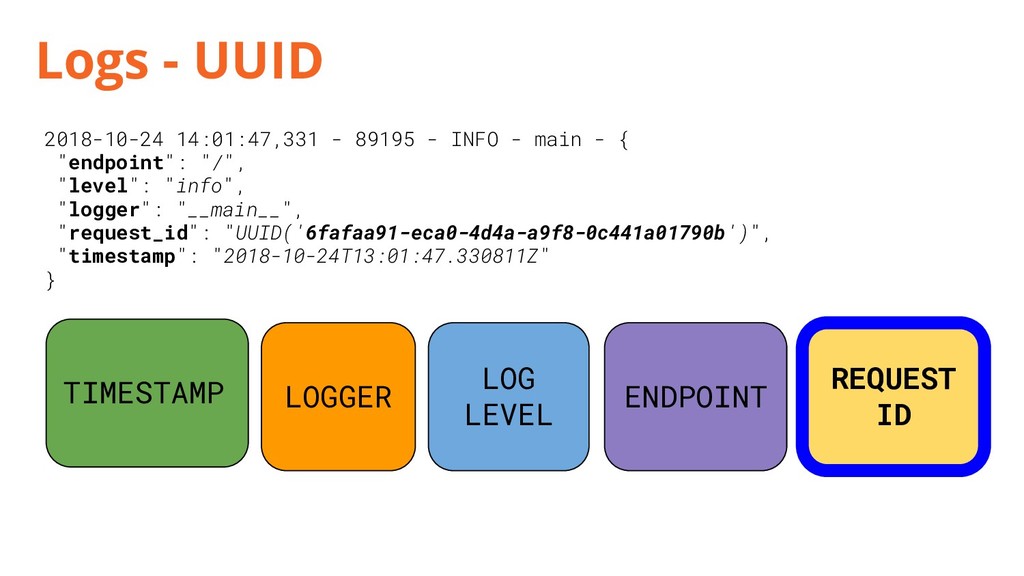{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
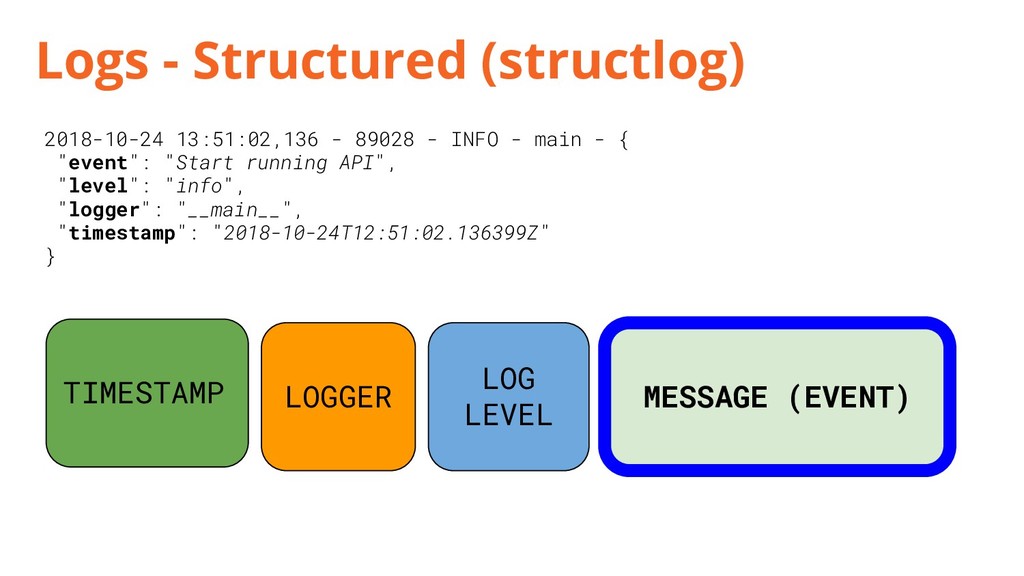{kind=link}
{kind=link}
{kind=link}
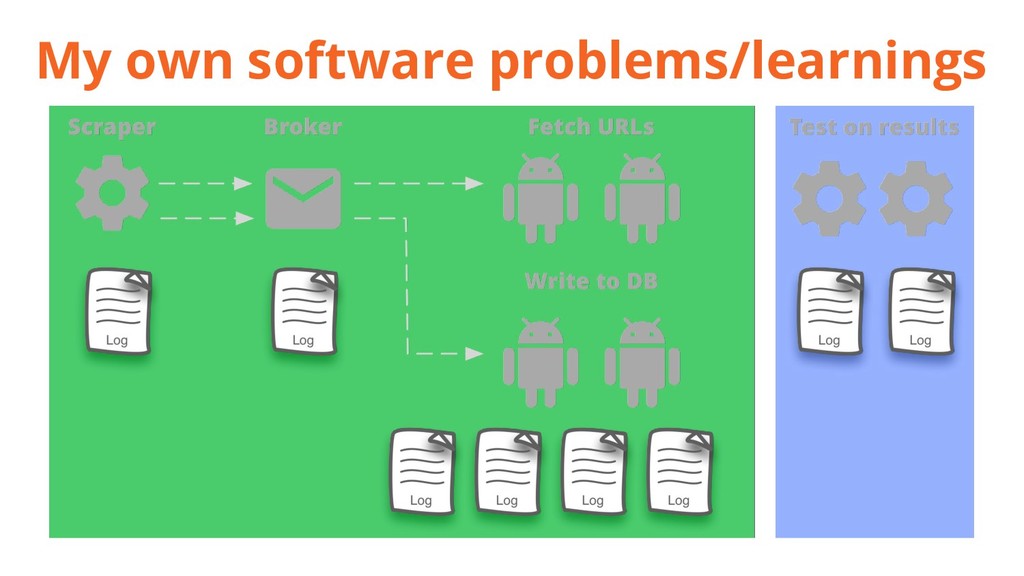{kind=link}
{kind=link}
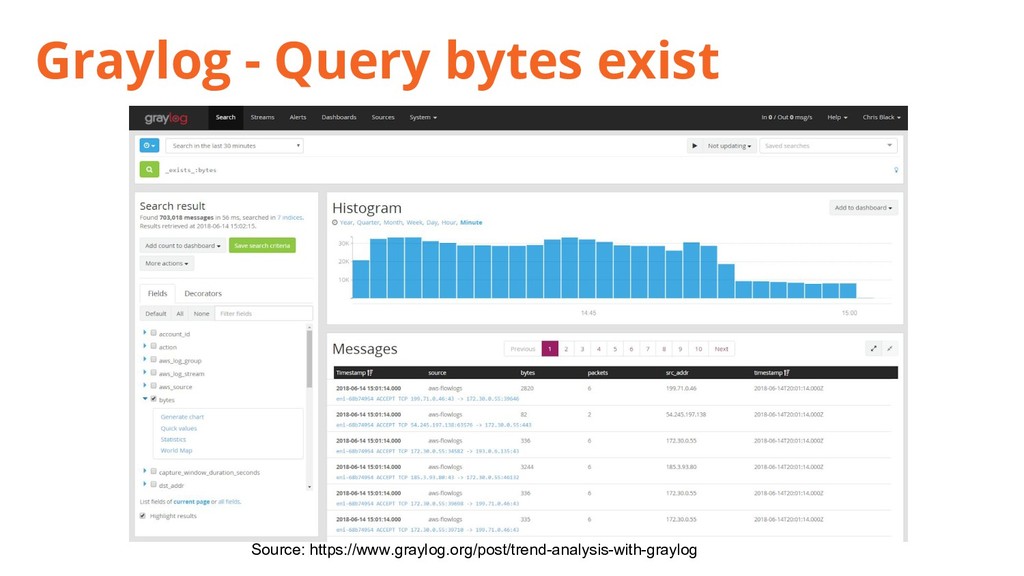{kind=link}
{kind=link}
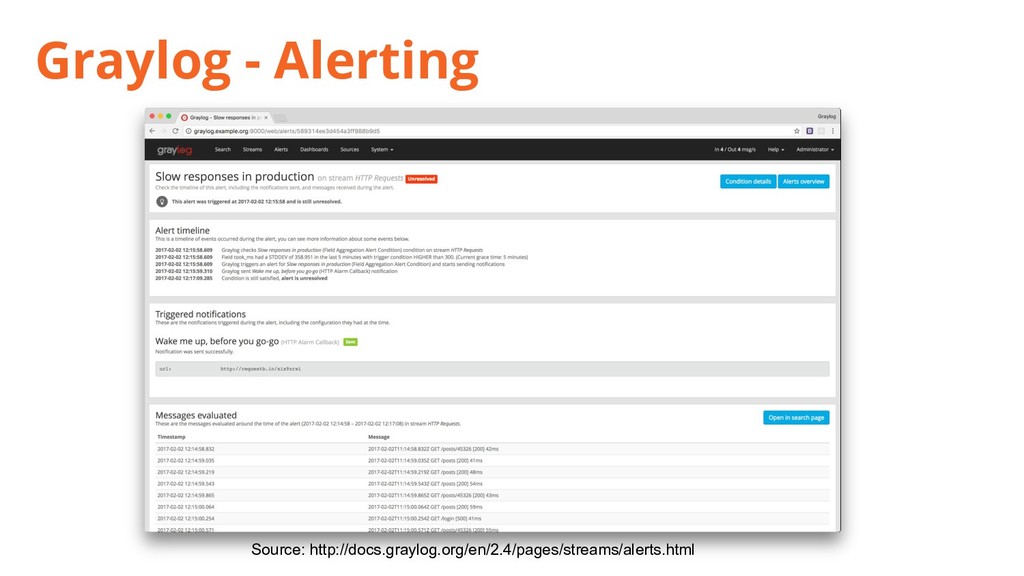{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}