Craig Stuntz Improving Enterprises [email protected] Abstract— When you leave Lambda Jam and return to work, do you expect to apply what you’ve learned here to hard problems, or is there just never time or permission to venture outside of fixing “undefined is not a function" in JavaScript? Many of us do use functional languages, machine learning, proof assistants, parsing, and formal methods in our day jobs, and employment by a CS research department is not a prerequisite. As a consultant who wants to choose the most effective tool for the job and keep my customers happy in the process, I’ve developed a structured approach to finding ways to use the tools of the future (plus a few from the 70s!) in the enterprises of today. I’ll share that with you and examine research into the use of formal methods in other companies. I hope you will leave the talk This talk combines general techniques for finding freedom to use the best tool for the job with my real-world experience using F#, machine learning, parsing, and constructive logic in an organization with conservative architectural guidelines which forbid most of this explicitly. I’ll expand on this in the presentation, but the elevator pitch is: “Look for unpopular but potentially costly problems; find the looming technical debt that other developers are afraid to touch and use formal methods to break it wide open.” The running example is a smoldering tire fire of 3.5 GB of XML, custom-not-quite-XPath, multiple ad- hoc DSLs, and VB6 services used to configure a single web site in an otherwise successful business. I like to hack on compilers. People often say, “I studied [compilers, FP, etc.] in college, never touched it again.”
any time at end for questions. I’m going to describe the last year and a half of my work, and I have 30 minutes to do it. Please come talk with me later! I’d love to talk with you and hear your own experiences.
work 2. Distinguish production code from metacode 3. Don’t wait to be asked to do the work you want to do 2. Legacy code migration example 3. Related work How to use real computer science in the job you already have, today. Will start with “the conclusion,” the key ideas on the slide. Work through an example, Talk about some other helpful ideas for finding and doing interesting work.
this work, people often say, “I studied [compilers, FP, data structures, etc.] in college, never touched it again." I use it all the time. Am I doing something wrong? People say they want to do this work, so Take what I do and formalize it. How do you find the opportunities? How do you convince your employer/coworkers it’s a good plan?
Here’s some things which won’t work: 1. Don’t turn this into class struggle. Don’t sneer. No one wants to be told they’re doing it wrong. 2. Don’t wait for anyone to ask you to use formal methods. May never happen. Finally, If you take work other people want to do (rails new) and try to use Haskell, etc., they’ll complain. Maybe for good reason? You don’t need a rocket engine to power a skateboard; it’s fun, but hard to find good rocket mechanics.
into them almost every day. “ http://steve-yegge.blogspot.ca/2007/06/rich-programmer-food.html Fortunately, Opportunities abound! Parsing is fundamental! Some problems which don’t look like compilers on the surface end up being compilers all the way down.
use CS in your day job that I won’t cover. Most of them involve changing your job. I want to show you how to use CS in the job you already have. Work for MSR. You don’t need to be in this audience. Start a company. Hard! College prof/research assistant. Most of us don’t get handed this sort of work on a silver platter. Have to find opportunities ourselves.
and everyone else is afraid to touch?” https://www.flickr.com/photos/motleye/306334293/ So here’s a question to ask your manager/client/teammates, which might lead you to a good place: (slide) Has anyone here ever worked in a place which had some skeletons in its closet before? Is that the kind of work you want to take on? Maybe: Total freedom of tooling with unpopular / scary tasks
on hard enough problems. And that is a big mistake.” For sufficiently difficult tasks, formal methods might be the only viable solution. Similar to machine learning: Maybe not everyone’s first choice, doesn’t give precise answers, but literally the only thing which works well. If there appears to be an alternative to formal methods, look for harder problems!
essential material to be addressed by a subject at this level is not the syntax of particular programming-language constructs, nor clever algorithms for computing particular functions efficiently, nor even the mathematical analysis of algorithms and the foundations of computing, but rather the techniques used to control the intellectual complexity of large software systems.” https://mitpress.mit.edu/sicp/full-text/book/book-Z-H-7.html#%25_chap_Temp_4 What is computer science, really? (pause to read?) I lured you here by promising to talk about ML, parsing, formal methods, etc., and I will, but if we're going to talk about woodworking we wouldn't start by introducing hammers and chisels. Step back: We need to think about the act of computing, as performed by ‘computers’ such as actuaries and programmers. We compute to solve business problems. You must first understand the problems.
I’m a consultant, here’s a problem I solved for a client. “What’s the worst problem you have? What’s the unfixable boat anchor which holds you back?” Anonymizing client. Let’s call them a health insurance company. Sells insurance contracts to employers.
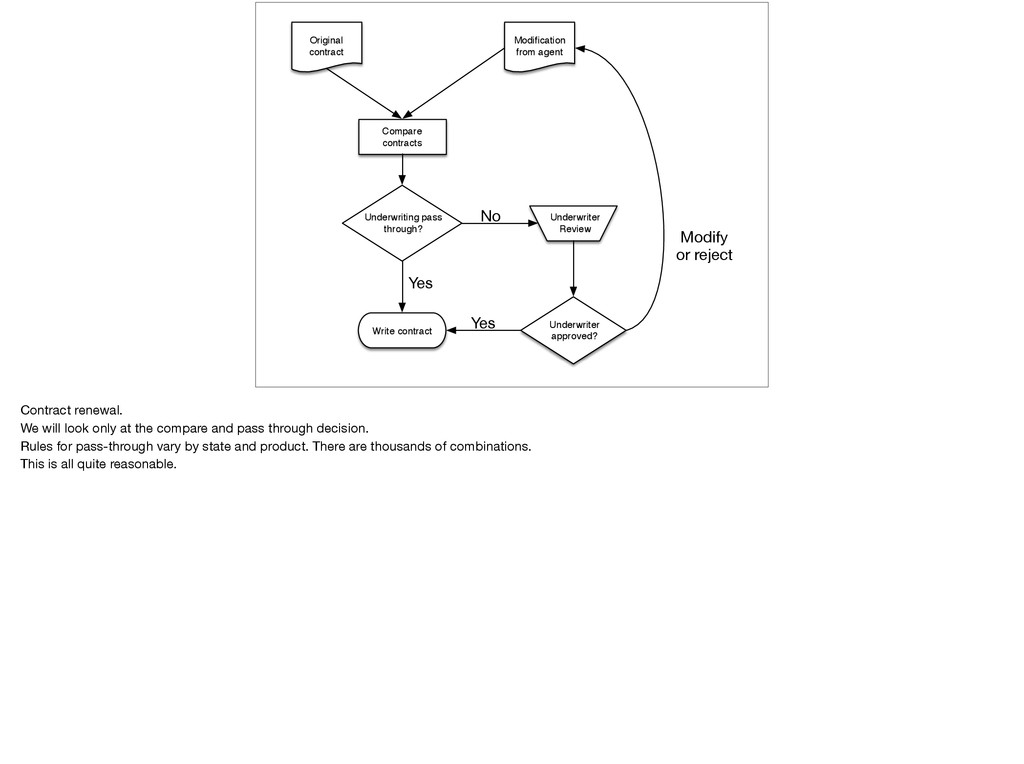
contract Modification from agent Compare contracts No Yes Yes Modify or reject Contract renewal. We will look only at the compare and pass through decision. Rules for pass-through vary by state and product. There are thousands of combinations. This is all quite reasonable.
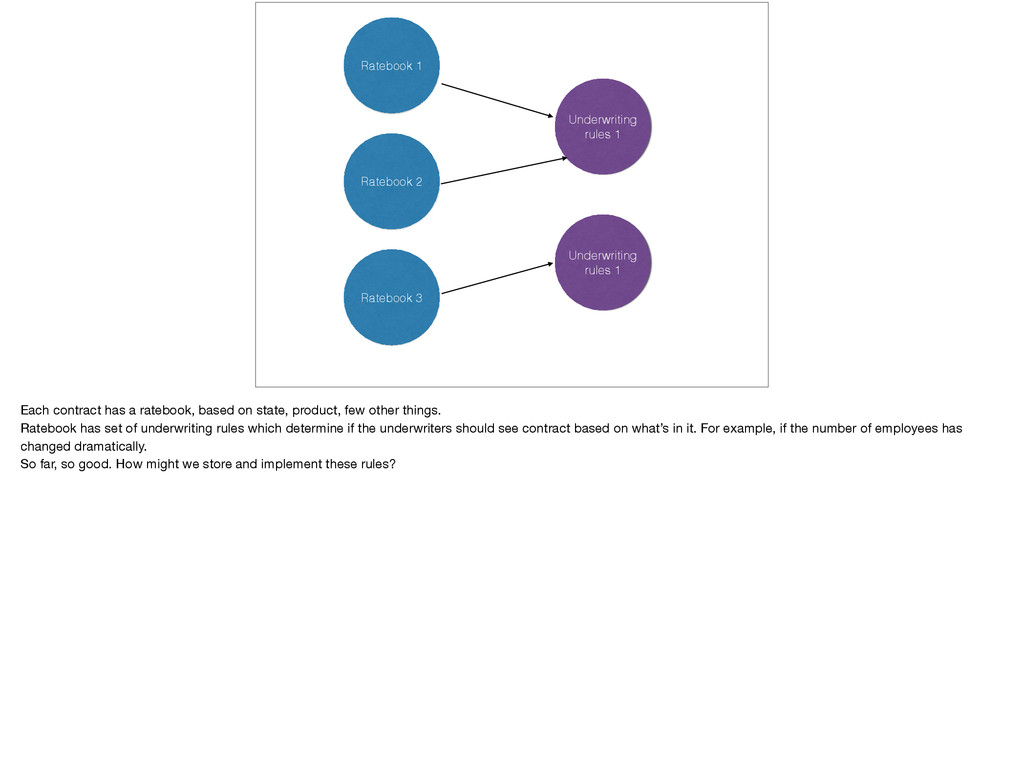
rules 1 Each contract has a ratebook, based on state, product, few other things. Ratebook has set of underwriting rules which determine if the underwriters should see contract based on what’s in it. For example, if the number of employees has changed dramatically. So far, so good. How might we store and implement these rules?
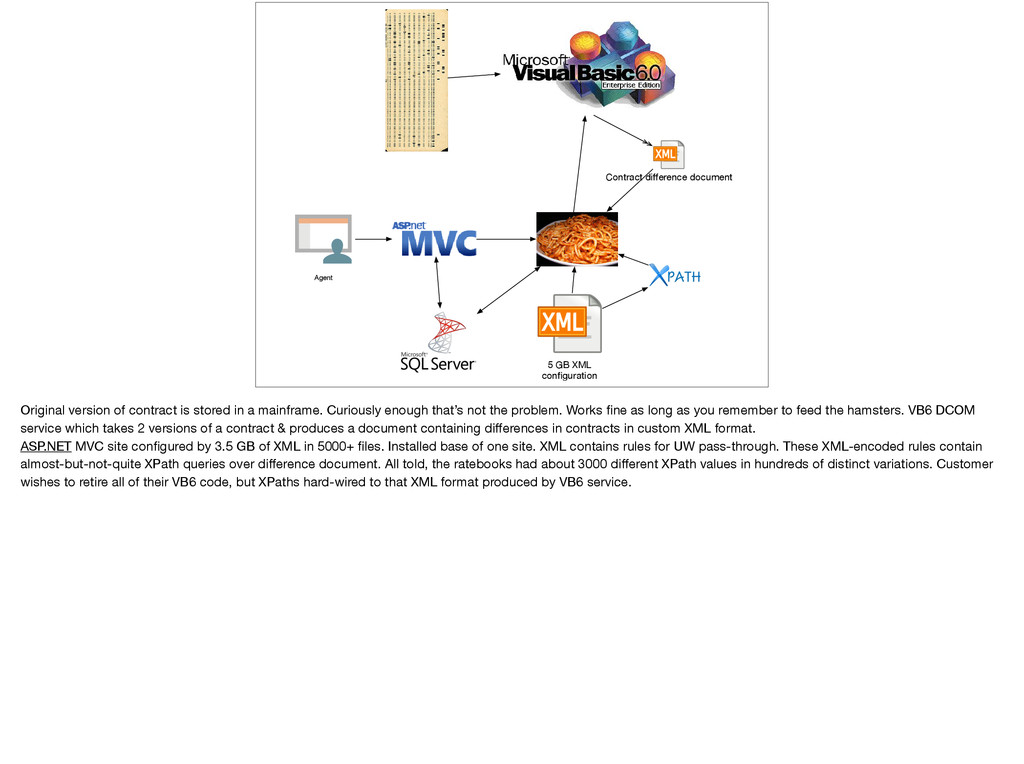
of contract is stored in a mainframe. Curiously enough that’s not the problem. Works fine as long as you remember to feed the hamsters. VB6 DCOM service which takes 2 versions of a contract & produces a document containing differences in contracts in custom XML format. ASP.NET MVC site configured by 3.5 GB of XML in 5000+ files. Installed base of one site. XML contains rules for UW pass-through. These XML-encoded rules contain almost-but-not-quite XPath queries over difference document. All told, the ratebooks had about 3000 different XPath values in hundreds of distinct variations. Customer wishes to retire all of their VB6 code, but XPaths hard-wired to that XML format produced by VB6 service.
files • ~10000 lines C# production code generated in ~100 files • ~15000 lines C# test code generated • “Some” hand-written C# • Affects ~1500 product offerings • ~300 manual test cases generated LOC not good for much, but it does measure maintenance impact Existing behavior of system generally assumed to be correct; there is no other comprehensive documentation. This has to work the first time, or there’s no hope. Can’t write imperfect implementation and find bugs with manual testing. “Bug for bug” compatibility b/c production system is only specification in existence.
incredibly fertile ground for data mining. (There’s gold in that brownfield!) Real domain knowledge captured in bad format. Source format is crap, but works 95%? of the time in production. Not well structured, but beaten into submission with 10 years of bug fixes.
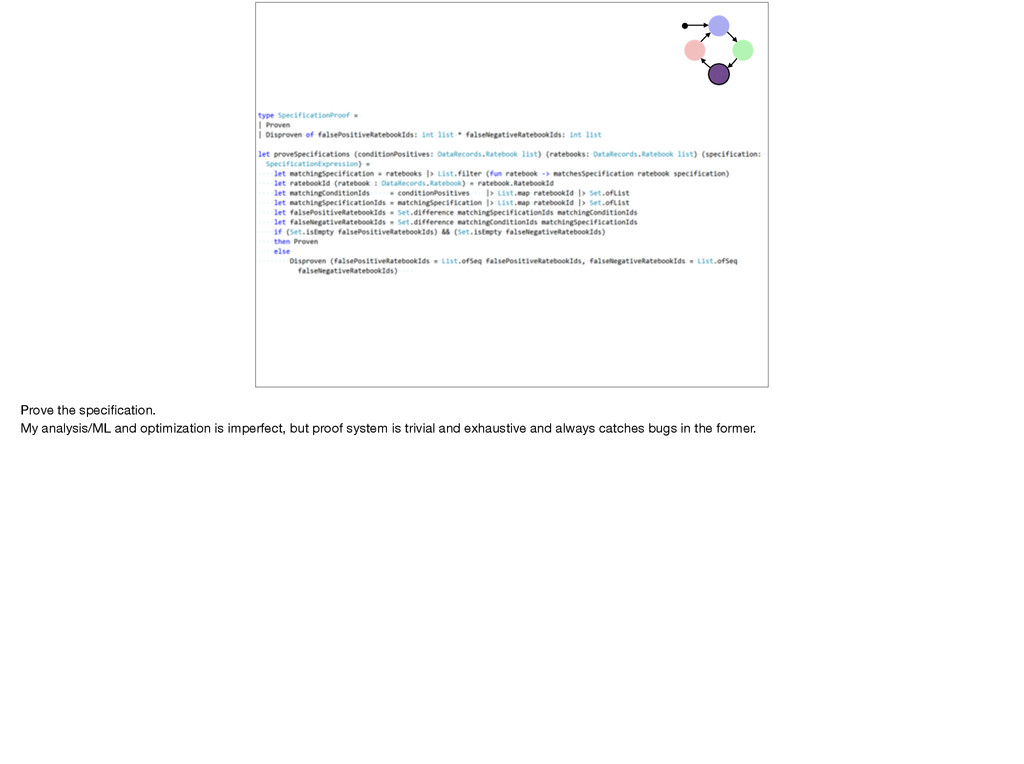
models from thousands of files? 1. Make sweeping overgeneralization 2. Write lightweight test to show where you are wrong 1. Wrote down what I thought was in XML files at first glance. F# forces me to be really precise in my notation. 2. Then wrote a deserializer. Proven correct by construction. XML changing under my feet; this is living code!
permission.” Grace Hopper Chips Ahoy, July, 1986 One more wrinkle: Company (application) architecture team opposed to F# code. This is inconsequential! As long as I check in C# production code they don’t care how I “wrote” it. Nobody else was offering a solution to this problem at all.
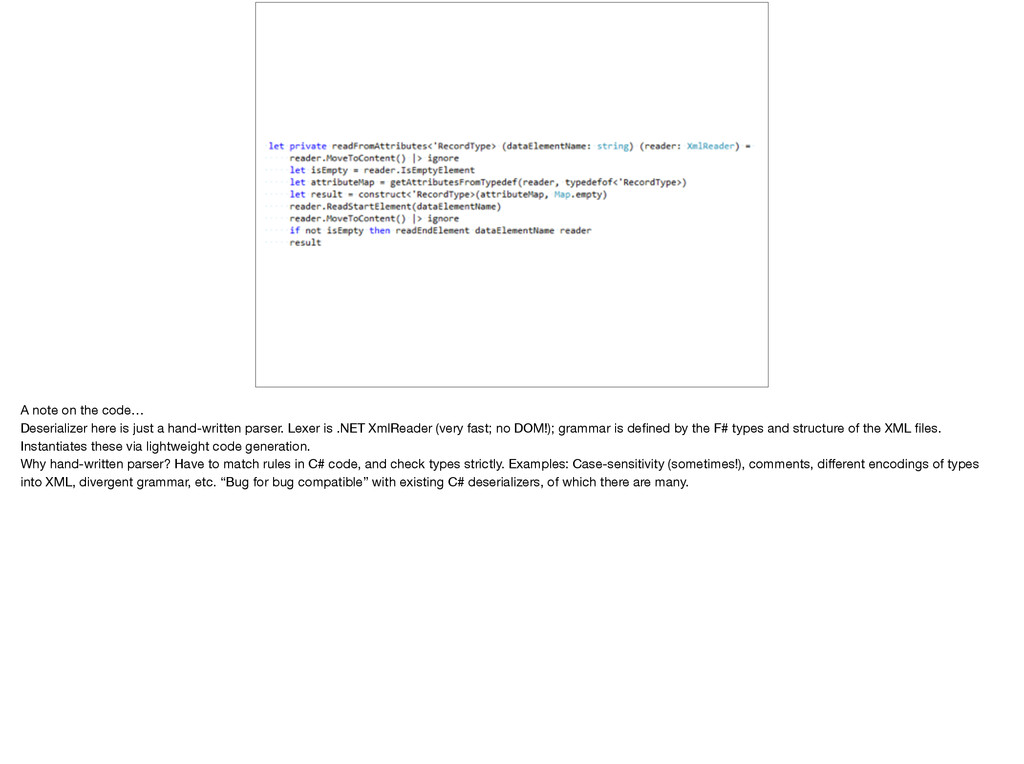
hand-written parser. Lexer is .NET XmlReader (very fast; no DOM!); grammar is defined by the F# types and structure of the XML files. Instantiates these via lightweight code generation. Why hand-written parser? Have to match rules in C# code, and check types strictly. Examples: Case-sensitivity (sometimes!), comments, different encodings of types into XML, divergent grammar, etc. “Bug for bug compatible” with existing C# deserializers, of which there are many.
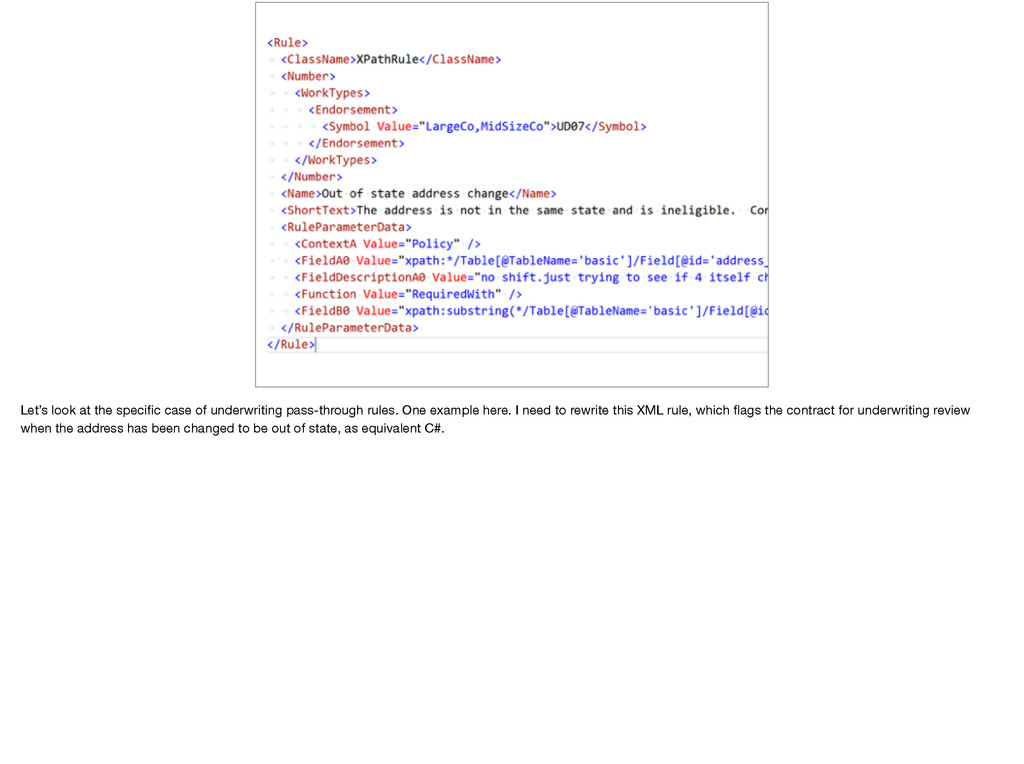
One example here. I need to rewrite this XML rule, which flags the contract for underwriting review when the address has been changed to be out of state, as equivalent C#.
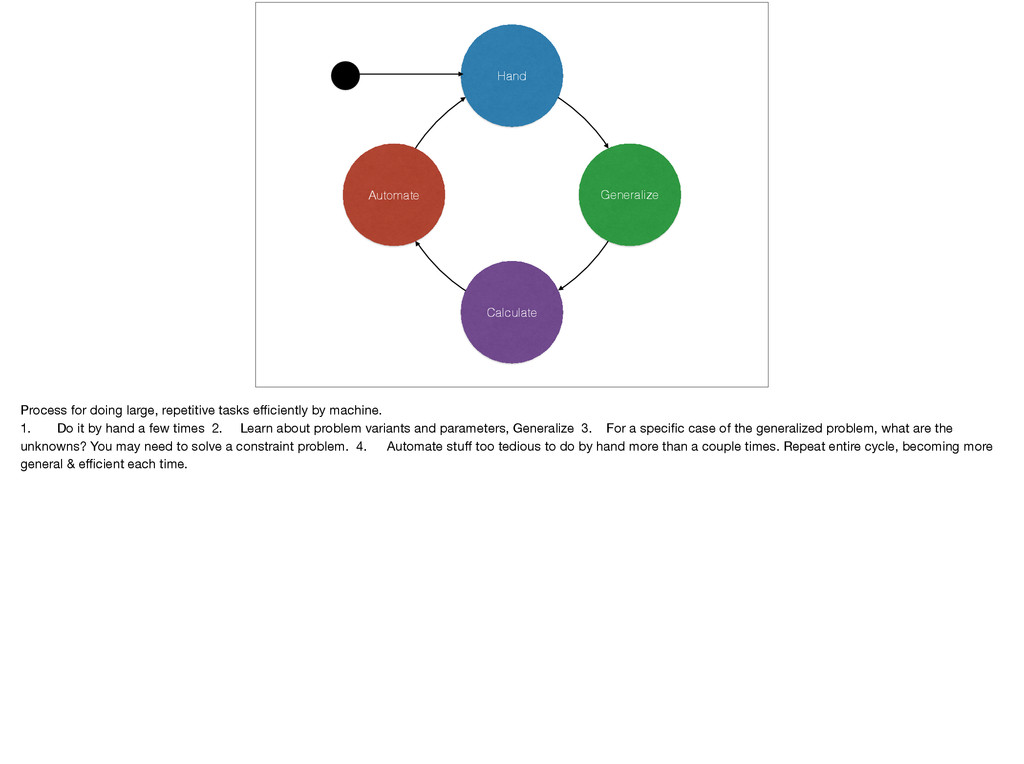
efficiently by machine. 1. Do it by hand a few times 2. Learn about problem variants and parameters, Generalize 3. For a specific case of the generalized problem, what are the unknowns? You may need to solve a constraint problem. 4. Automate stuff too tedious to do by hand more than a couple times. Repeat entire cycle, becoming more general & efficient each time.
here: OnApplies and OnValidate. With sufficient effort or tools, they can both be inferred from the XML files. Handle individually. Creating code like this isn’t hard, but we need to do it hundreds of times, perfectly.
PPO 35 Michigan HDHP 50 Ohio HMO 1 Ohio HMO 24 Ohio PPO 36 Ohio PPO 90 Ohio HDHP 203 Ohio HDHP 305 Texas HMO 56 Texas PPO 67 Texas HDHP 304 Utah HMO 57 Utah PPO 89 Utah PPO 92 (but hundreds of other products it doesn’t apply to) ⇒ state ∈{ MI, OH, TX, UT } ∧ Plan ∈ { HMO, PPO, HDHP } One thing I learned is analyzing when the rule applies is really hard to do by hand. For any XPath, find duplicate/similar rule definitions, then produce an comprehensive list of products it applies to by examining XML and fixing up references between files. Ratebook files reference multiple underwriting rules files. Collect all ratebooks which reference a given rule, then analyze their common properties. Then infer a specification for that when that rule applies at all. Some specification are simple (state or contract type), some are quite complicated. How?
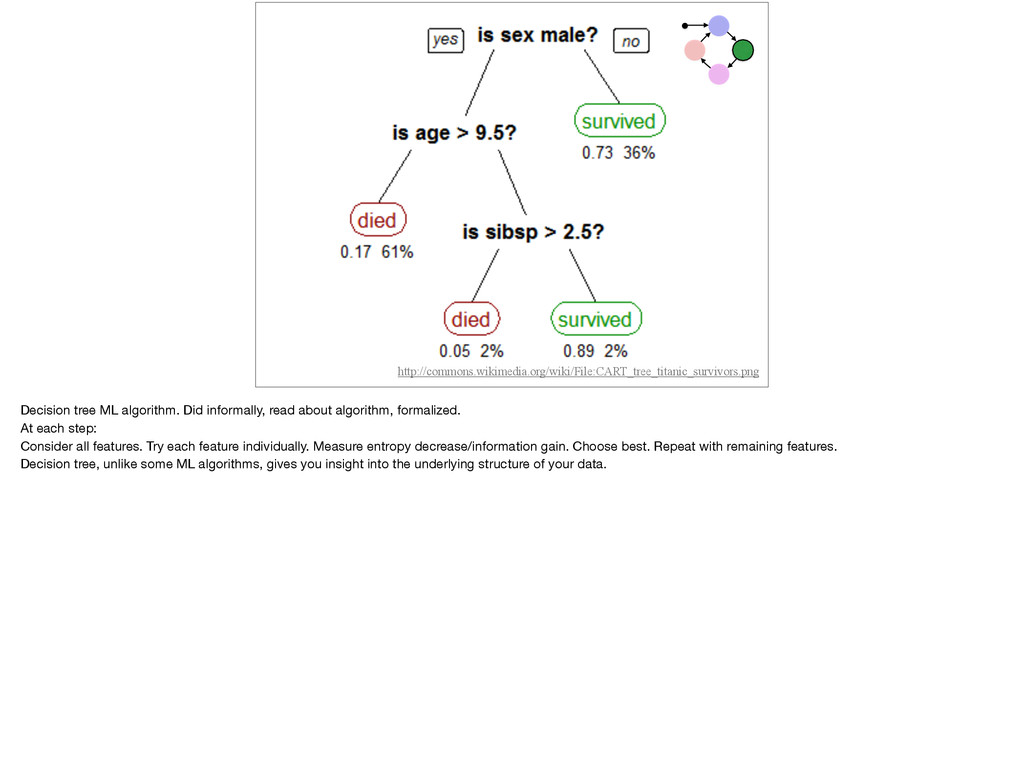
formalized. At each step: Consider all features. Try each feature individually. Measure entropy decrease/information gain. Choose best. Repeat with remaining features. Decision tree, unlike some ML algorithms, gives you insight into the underlying structure of your data.
Ohio ∧ Plan = HMO) ∨ (State = Texas ∧ Plan = HMO) ————————————————————— (Plan = HMO) ∧ (State ∈ { Michigan, Ohio, Texas } ) Optimization. Want to do more with this. Whatever the optimizer changes must be shown to be equivalent. This probably captures the original intent of the BA who wrote the rule better than a list of ratebooks.
programming.” Nada Amin Programming Should Eat Itself Really important. 1/2 my F# code is just to make sure my sweeping assumptions about the business motivation for tens of thousands of lines of code are correct. And that my analysis and optimization is correct. Other half generates shipping/test C#.
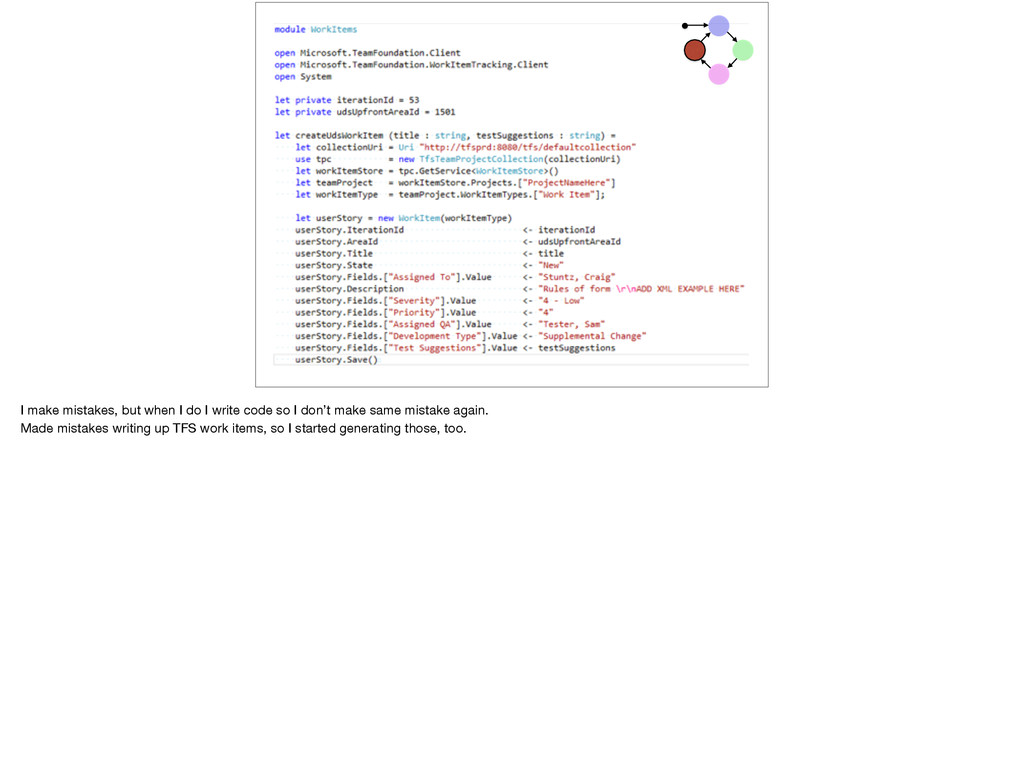
C# a few Incorrect TFS work items a few, until I automated that, too QA Again, my code generation code isn’t perfect, but my verification code is trivial.
Strong static typing as domain modeling • Wrote two parsers and a lexer • AST optimizer • Machine learning/decision tree • Code generator In summary…. This is exactly the kind of code I like to write!
Had only model of underwriting rules and could provide data to BAs on what current system actually does • Other developers could analyze XML • Foundation for removing XML altogether => more agility Business value — customer very happy!
I want to learn • Hard problems at my employer Obviously, step 0 in using computer science is learning computer science. Understand how your employer's business work, and to what degree software contributes to that. Look for gaps between technical implementations and strategy. Maintain mental map between “day job” problems and formal methods Large scope / "Too hard" / fragile When faced with old, brittle code: Exhaustively analyze behavior of legacy code and use statistics / ML to derive better solution. Computers are really fast. Use this!
• Code which exists to understand other code • Domain Model Recovery • Compilers • Tests • Proofs • Code Generators These have totally different rules. Cut and paste bad in prod code, maybe OK in tests?
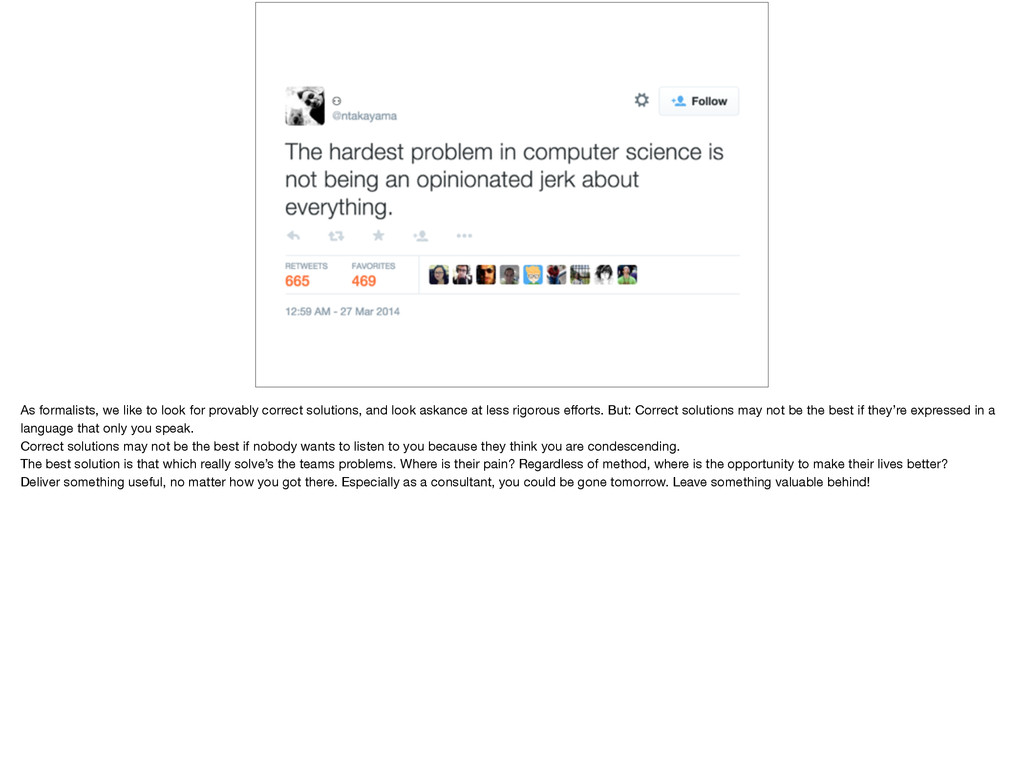
and look askance at less rigorous efforts. But: Correct solutions may not be the best if they’re expressed in a language that only you speak. Correct solutions may not be the best if nobody wants to listen to you because they think you are condescending. The best solution is that which really solve’s the teams problems. Where is their pain? Regardless of method, where is the opportunity to make their lives better? Deliver something useful, no matter how you got there. Especially as a consultant, you could be gone tomorrow. Leave something valuable behind!
example: Some of the code I wrote was quite abstract; I kept this to the code generator (thrown away at end of project), not the generated code. Generated code/tests should be understandable to anyone.
unpopular problems * Look for impossible problems * When it’s hard to solve a problem with code, use code to write code and more code to make sure that code is correct. Look for power tools!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Craig Stuntz @craigstuntz [email protected] http://blogs.teamb.com/craigstuntz http://www.meetup.com/Papers-We-Love-Columbus/ Thanks so much for](https://files.speakerdeck.com/presentations/dd4b7b8caed7457daca904d06b3a974d/slide_48.jpg){kind=link}