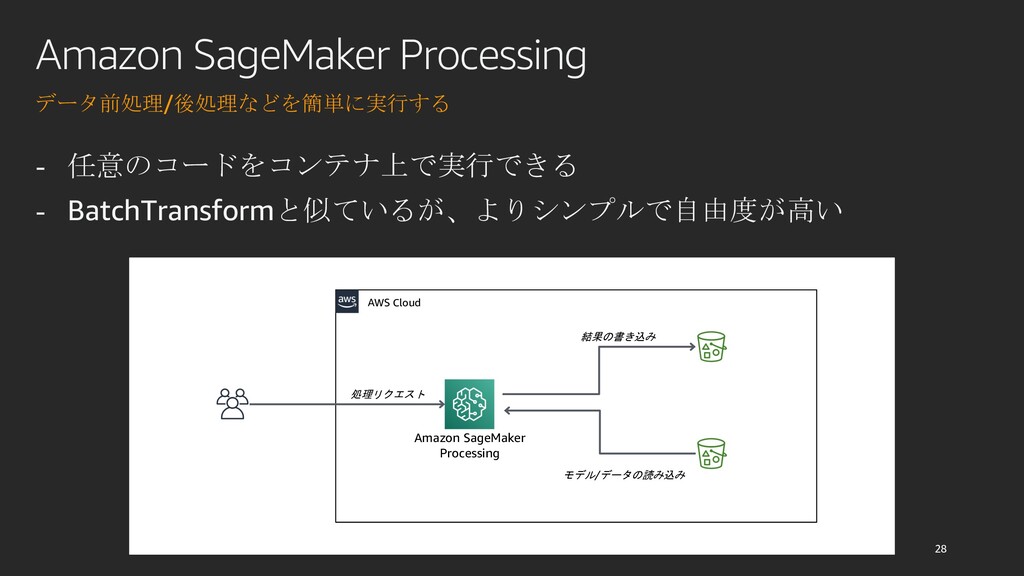
DeNA では、Amazon SageMaker をフル活用して実際のプロダクトの実装に取り入れています。本セッションでは、バッチ推論と Processing を Airflow と組み合わせてスケーラブルなバッチ推論パイプラインを構築した事例と、Amazon SageMaker 上にデプロイした推論エンドポイントで完全サーバレスな推論アプリケーションを構築した事例を紹介します。 これらの事例を通して、プロダクション環境で Amazon SageMaker を利用する方法と、それによってどのような利点があったのかを考えます。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
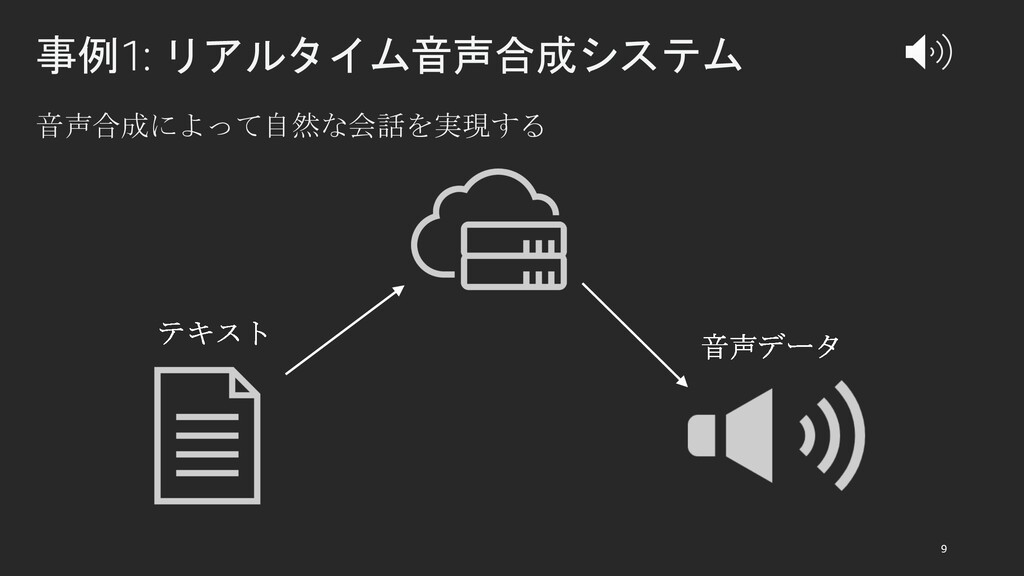{kind=link}
{kind=link}
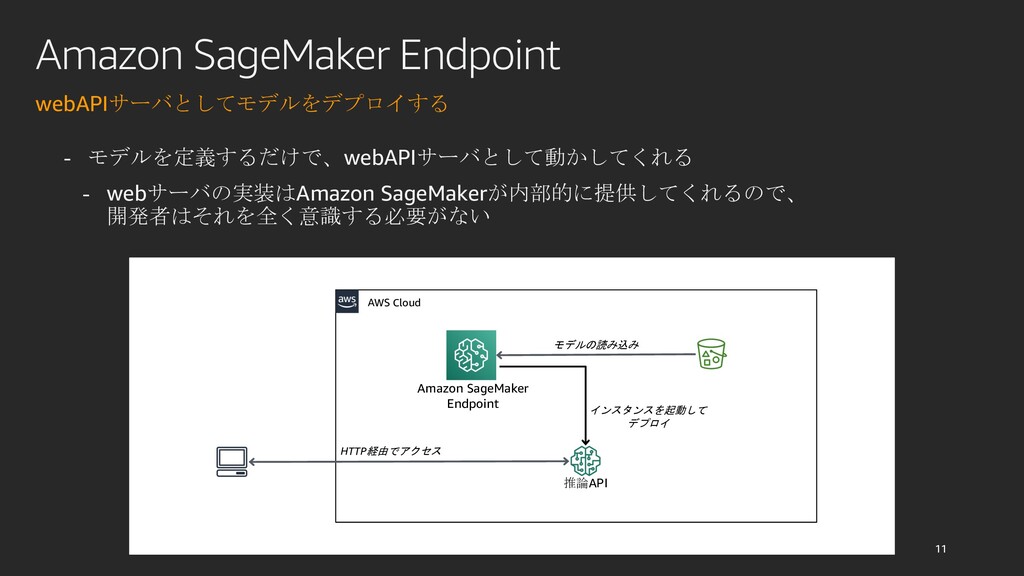{kind=link}
{kind=link}
{kind=link}
{kind=link}
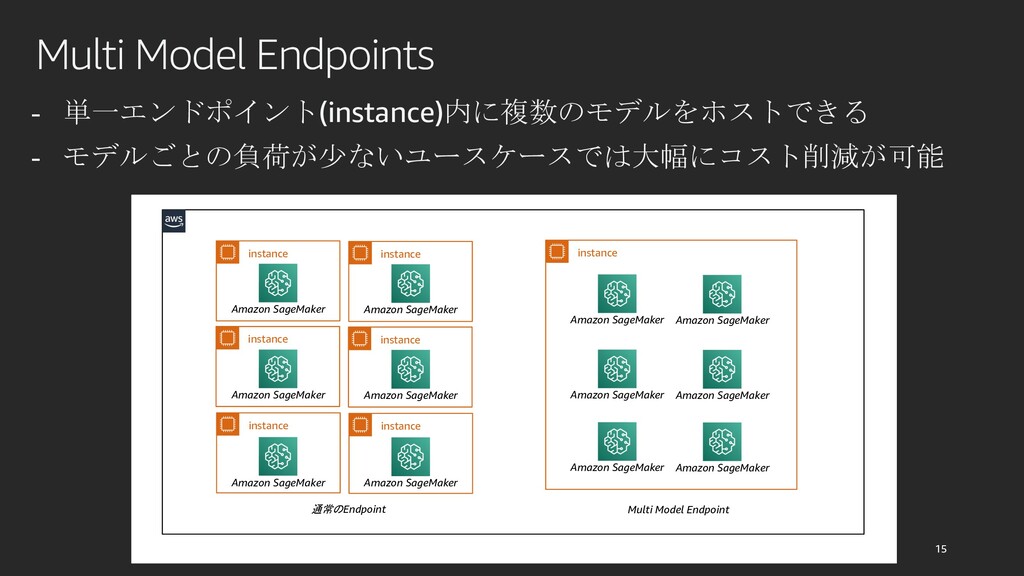{kind=link}
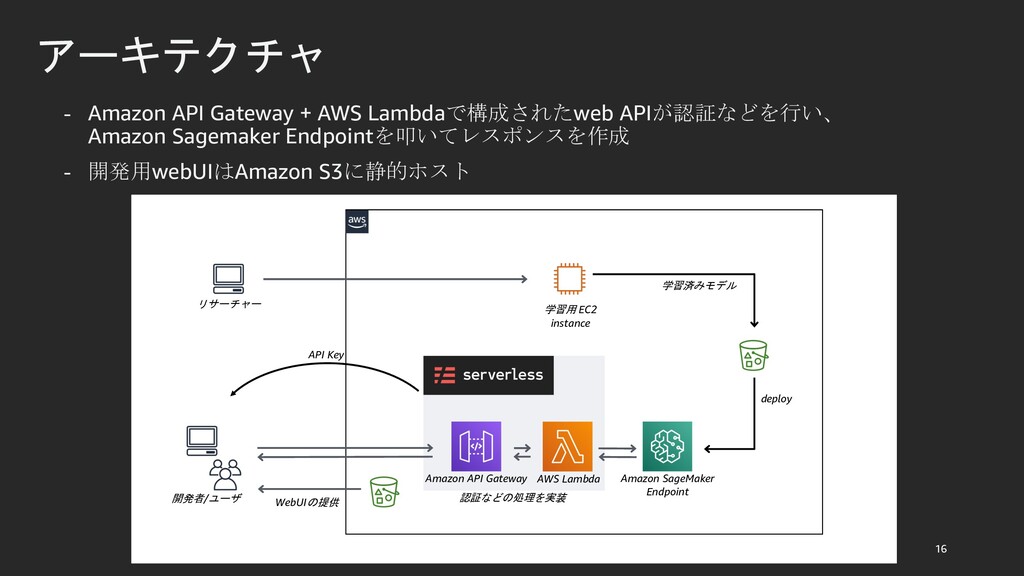{kind=link}
{kind=link}
{kind=link}
{kind=link}
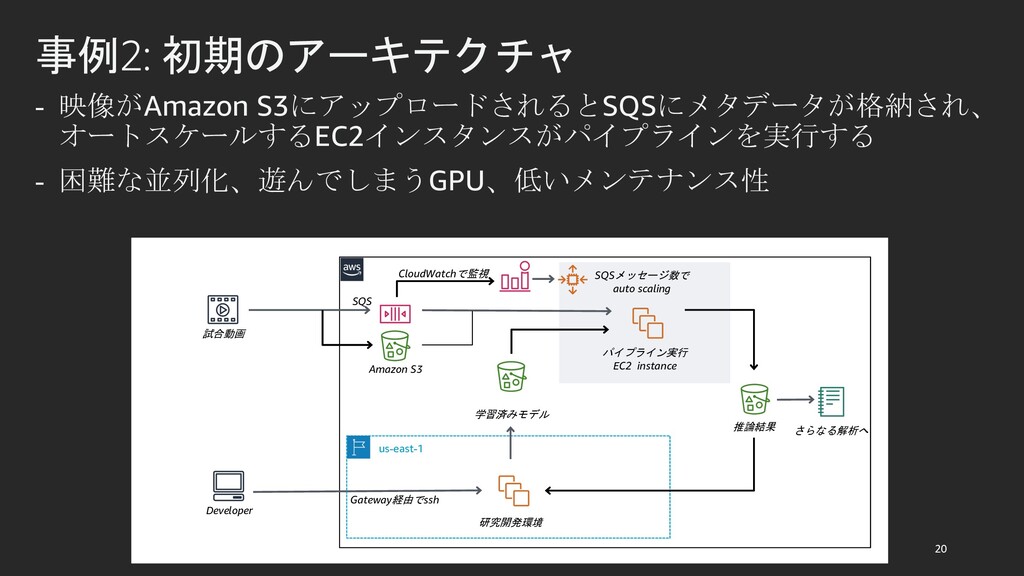{kind=link}
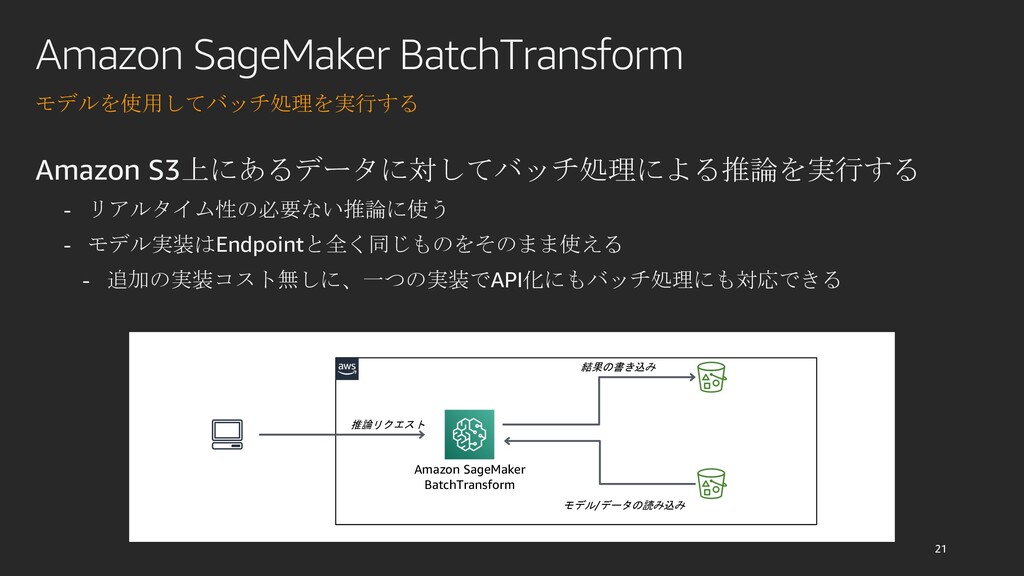{kind=link}
{kind=link}
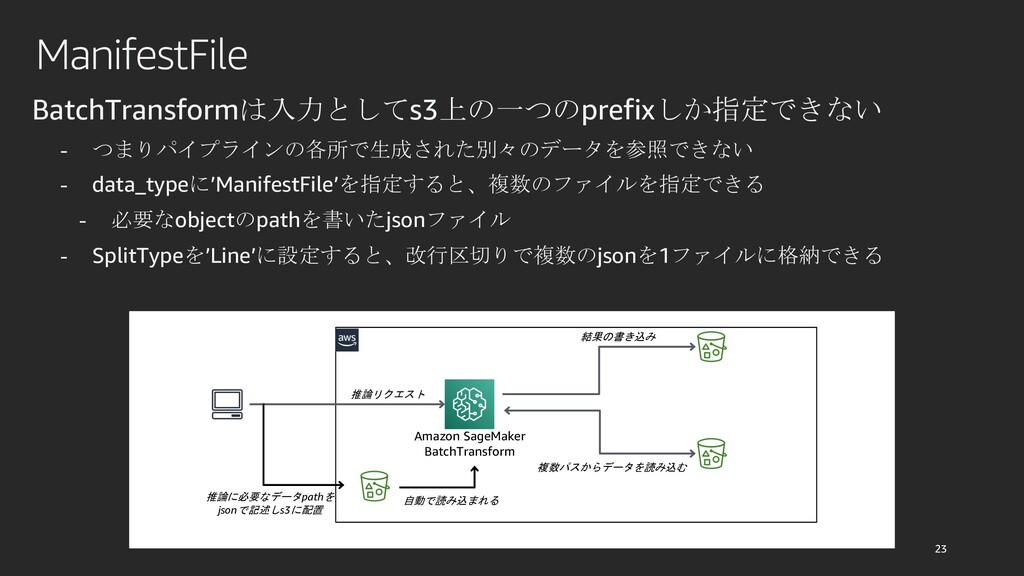{kind=link}
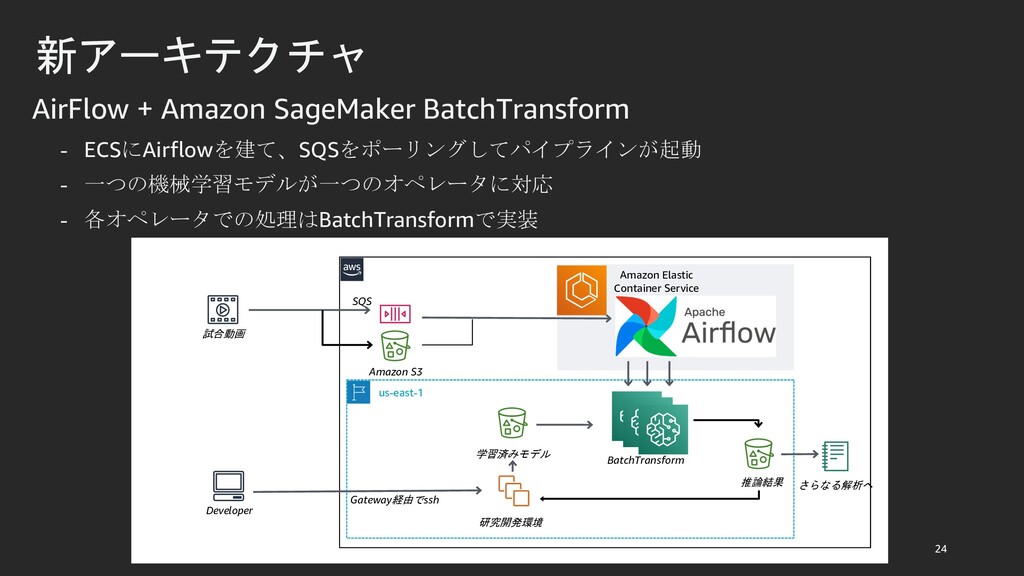{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}