DeNAの様々な事業を横断的に見るインフラチームでは、各サービスを統一的に運用できるような仕組みを IaaS で作ってきました。
監視、OSやミドルウエアの設定、クラウドリソース管理、コスト最適化、KPI管理、オーケストレーション、と様々な仕組みの自動化を整備してきましたが、そういった中で今もなお一定の工数がかかっているのがデータベースの運用です。
今回はそのデータベースの運用について、大規模ゲームを題材にしながら、どのように最適化を目指してきたのかについてご紹介します。
また、日々アップデートされるデータベースの新技術を、今後どのように取り入れていきたいかについてもお話していきます。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
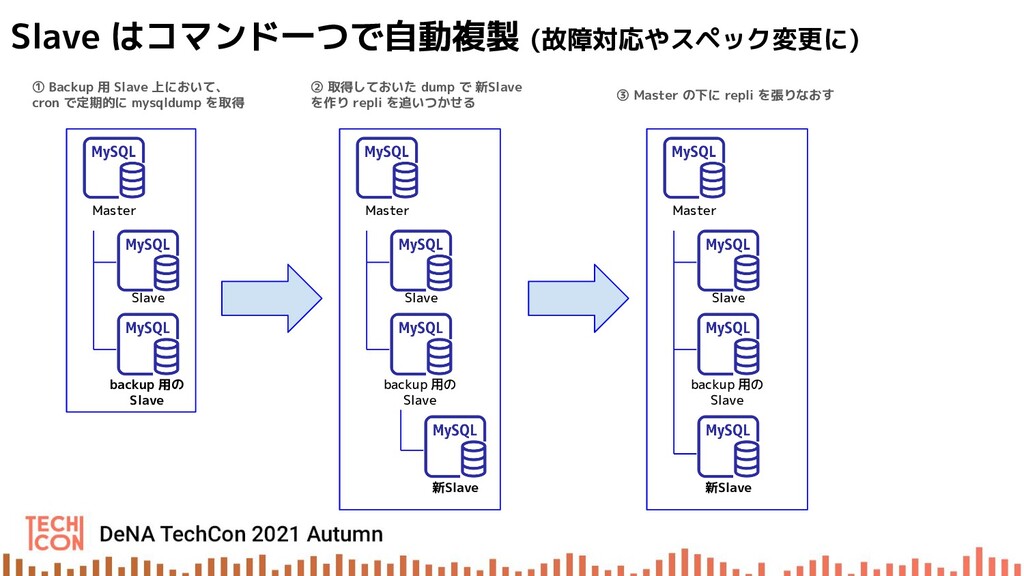{kind=link}
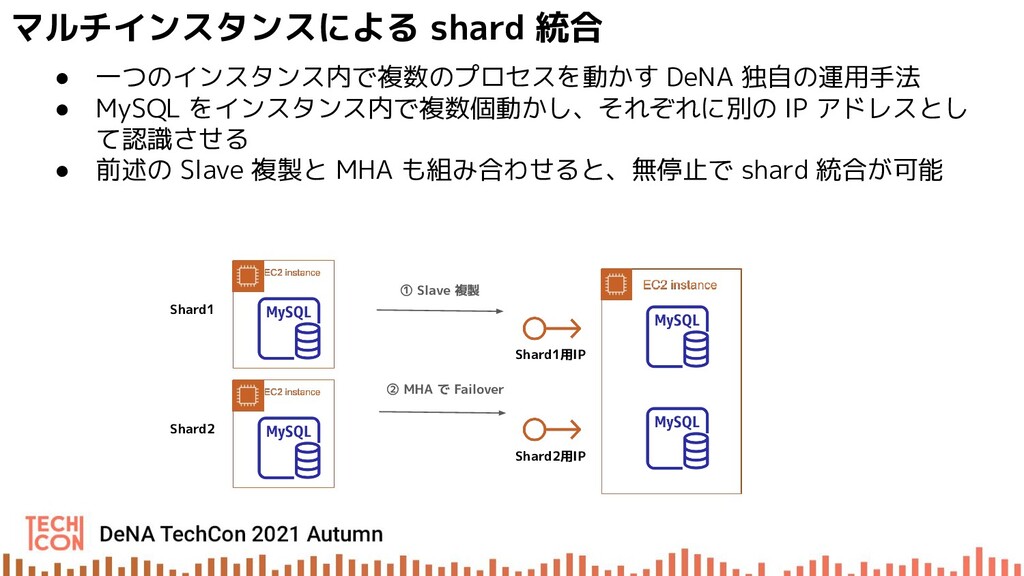{kind=link}
{kind=link}
{kind=link}
{kind=link}
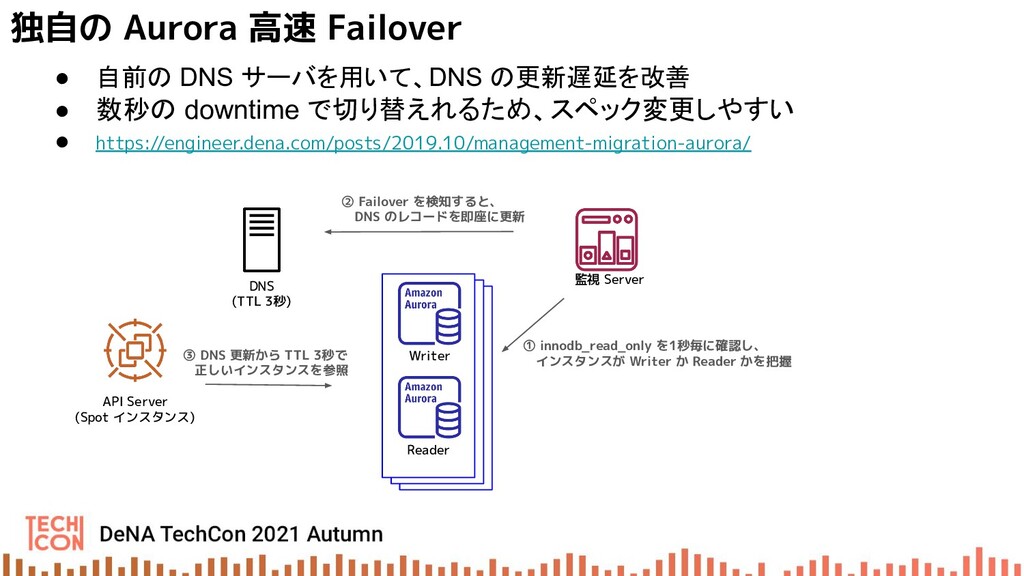{kind=link}
{kind=link}
{kind=link}
{kind=link}
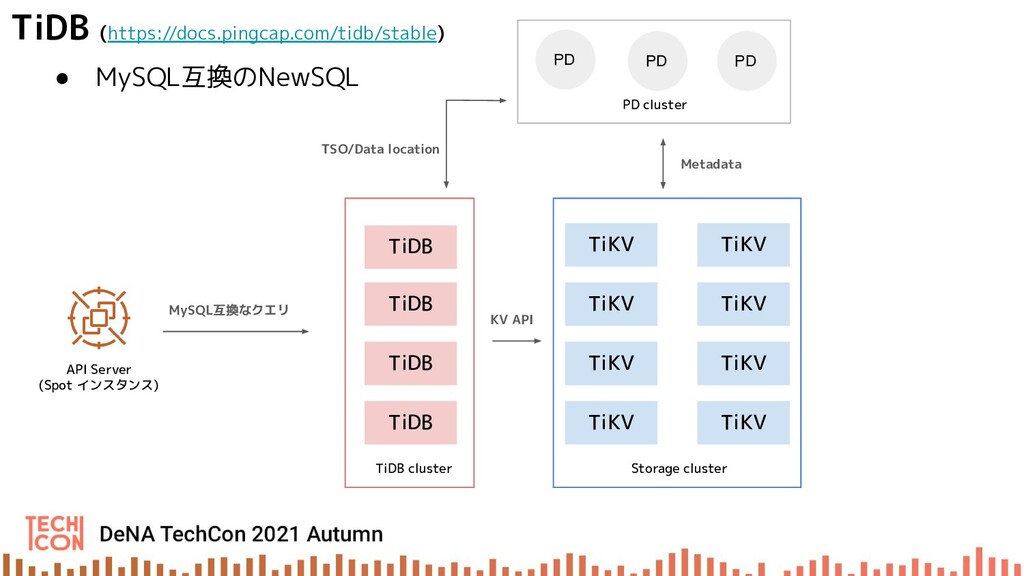{kind=link}
{kind=link}
{kind=link}
{kind=link}