Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NextGen Sequencing data intro.
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
David Rio Deiros
March 26, 2012
Research
230
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
NextGen Sequencing data intro.
Brief introduction to nextgen sequencing data.
David Rio Deiros
March 26, 2012
Other Decks in Research
See All in Research
Data Visualization Tools in the Age of AI
flekschas
0
160
typst の使い方:言語学を研究する学生のために
gitomochang
0
460
Claude Code × autoresearch 実践
mathbullet
0
170
The mathematics of transformers
gpeyre
0
340
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
310
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
10
7.7k
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
520
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
110
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.7k
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
370
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
820
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
480
Featured
See All Featured
Scaling GitHub
holman
464
140k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.3k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
Practical Orchestrator
shlominoach
191
11k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
140
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
330
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
The World Runs on Bad Software
bkeepers
PRO
72
12k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
450
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
370
Documentation Writing (for coders)
carmenintech
77
5.4k
Transcript
Next-Gen Sequencing Data
@shiondev
@drio
None
Σ Bases DNA == “The Genome”
Σ Bases DNA == “The Genome” 3Gbp
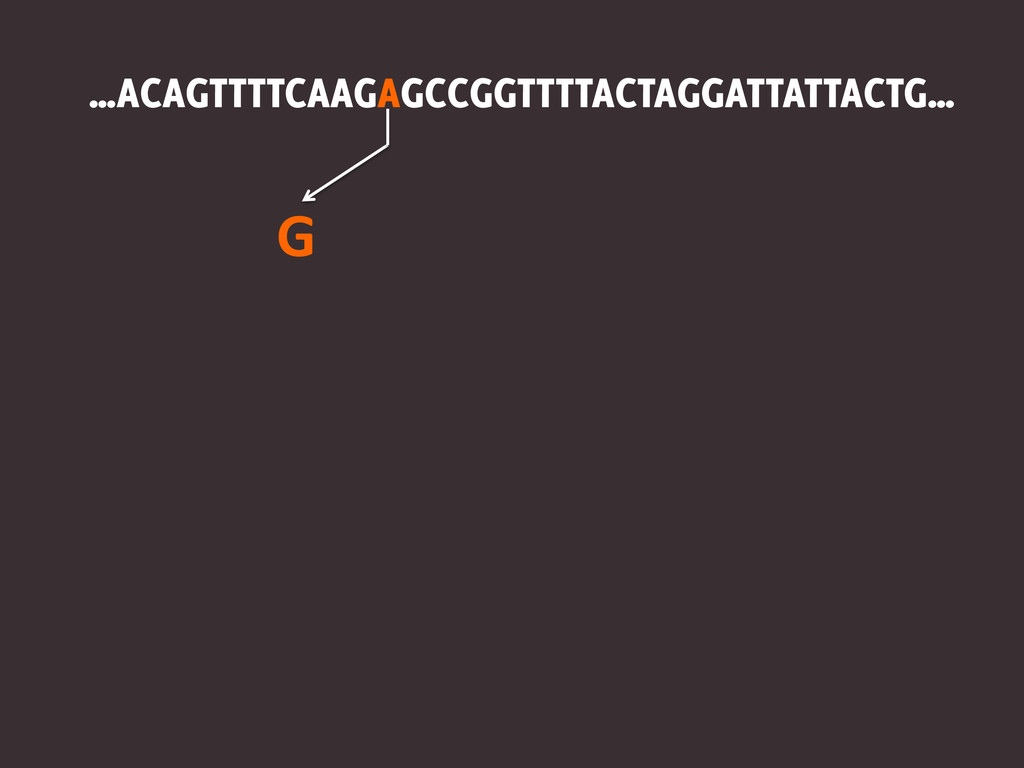
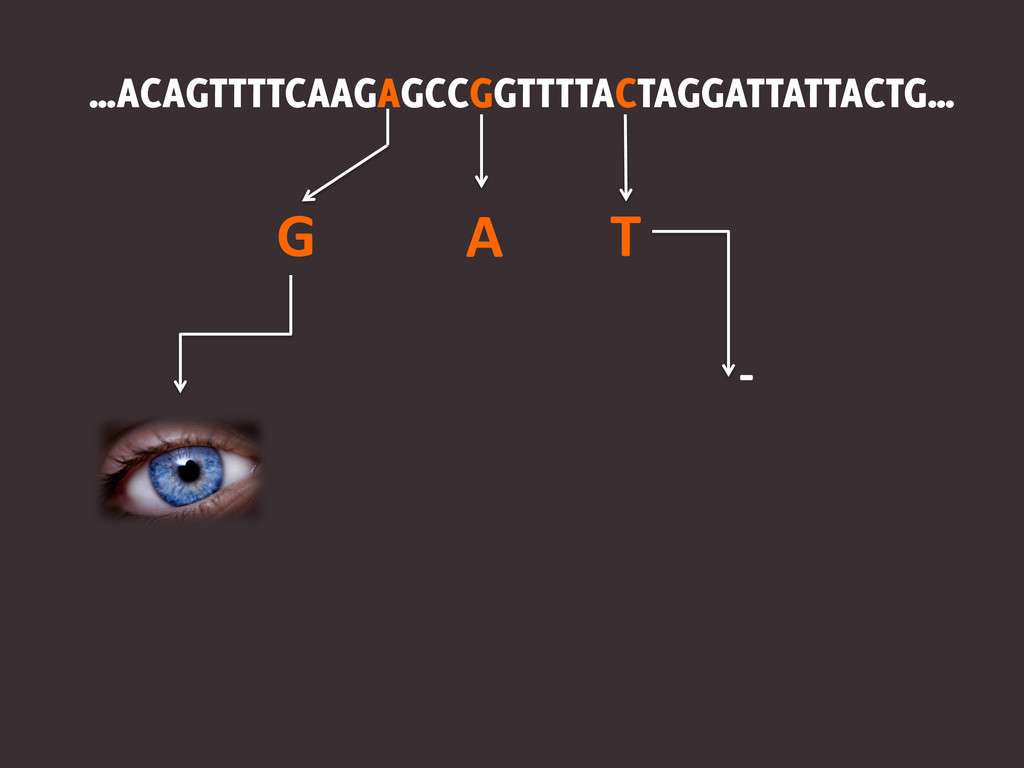
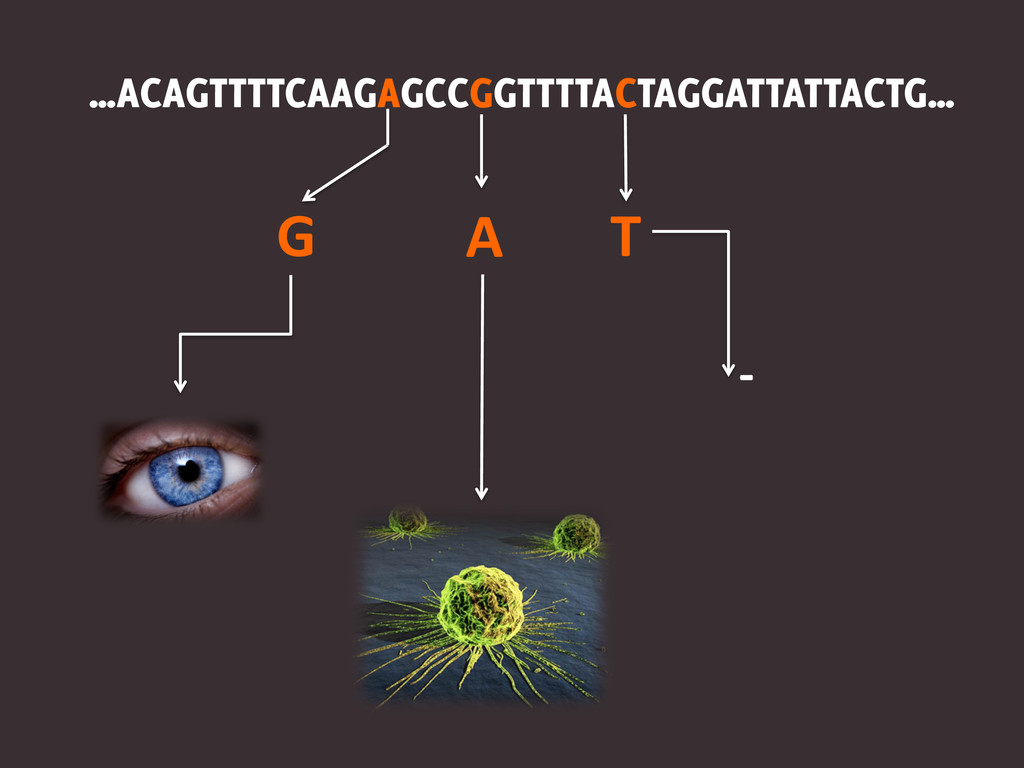
…ACAGTTTTCAAGAGCCGGTTTTACTAGGATTATTACTG…
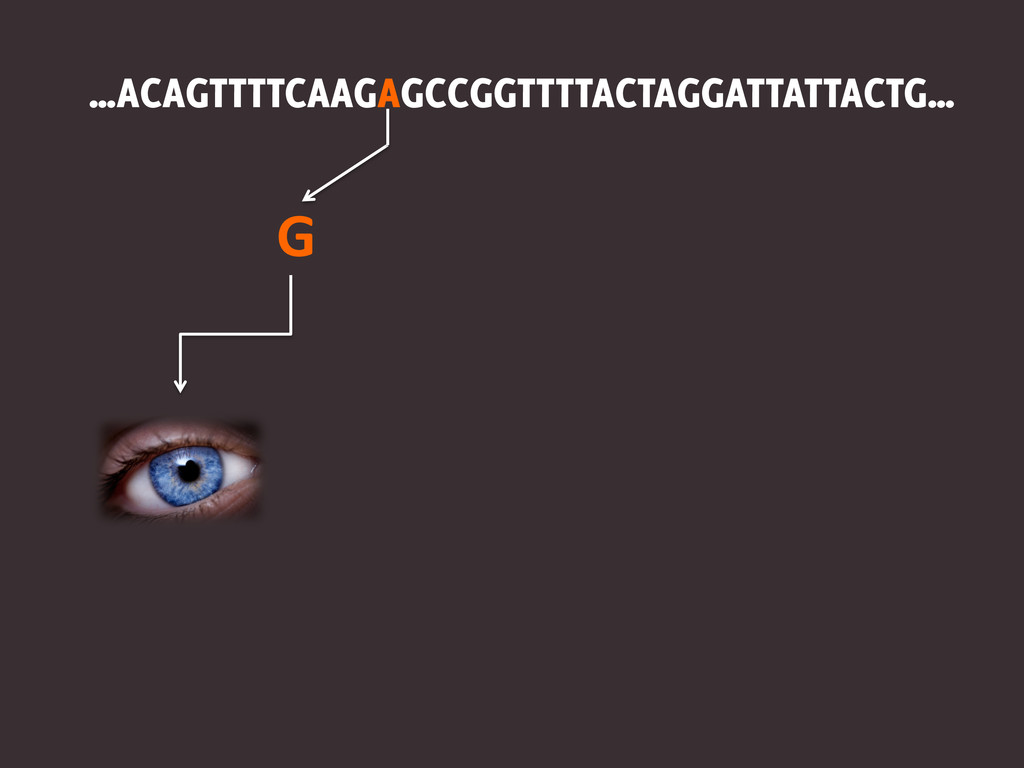
…ACAGTTTTCAAGAGCCGGTTTTACTAGGATTATTACTG… G
…ACAGTTTTCAAGAGCCGGTTTTACTAGGATTATTACTG… G
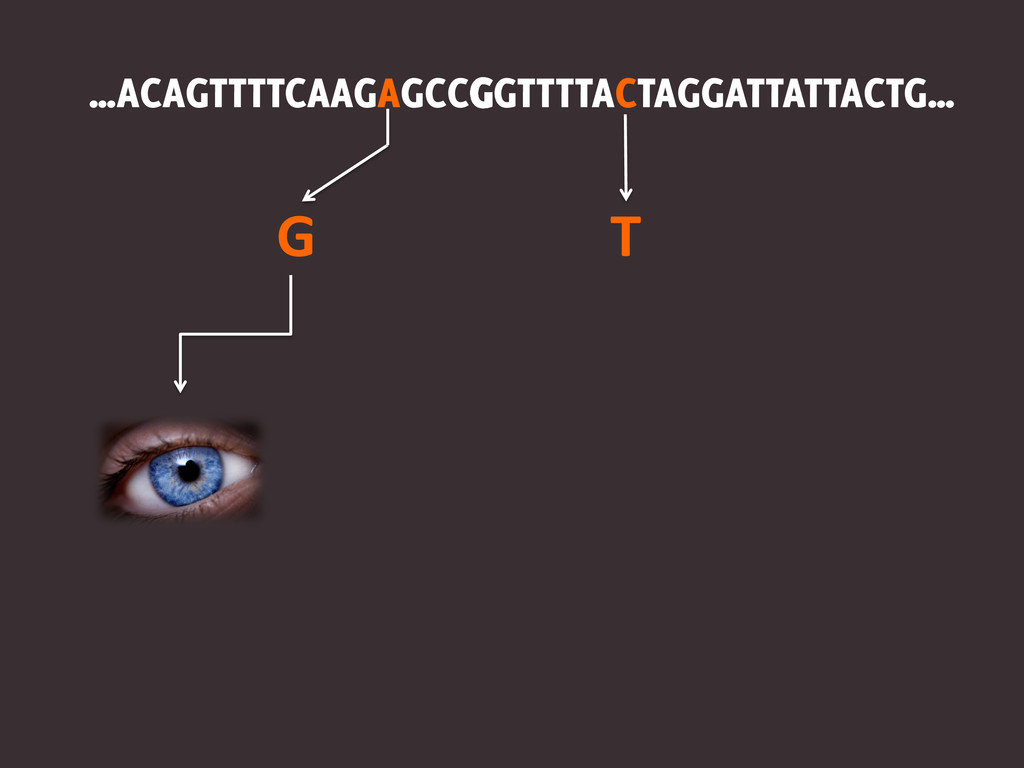
…ACAGTTTTCAAGAGCCGGTTTTACTAGGATTATTACTG… G T
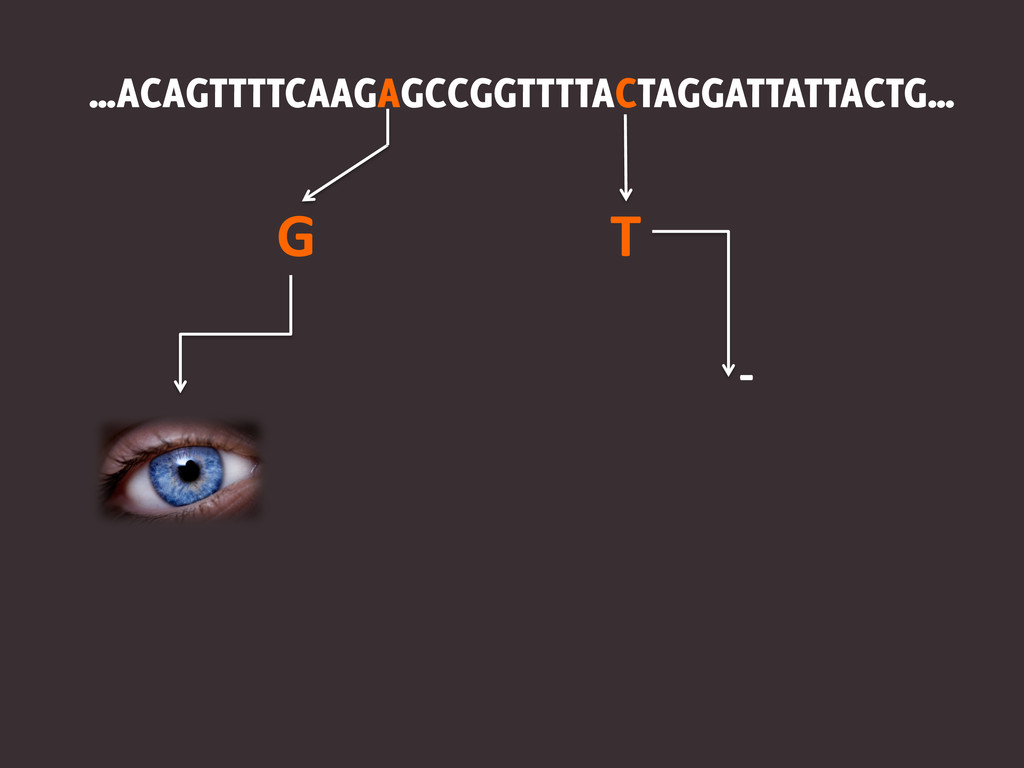
…ACAGTTTTCAAGAGCCGGTTTTACTAGGATTATTACTG… G T -‐
…ACAGTTTTCAAGAGCCGGTTTTACTAGGATTATTACTG… G T -‐ A
…ACAGTTTTCAAGAGCCGGTTTTACTAGGATTATTACTG… G T -‐ A
SEQUENCING
None
# of Bases per day per machine
200kbp 2000
1Mbp 2003
200 Mbp 2005
3Gbp 2009
60Gbp 2012
what can we do with NGS data?
Re-sequencing
Re-sequencing Looking for changes in a Genome
Re-sequencing Looking for changes in a Genome (Given that we
have a HIGH quality reference)
Re-sequencing Looking for changes in a Genome (Given that we
have a HIGH quality reference) Consequences?
Reliably finding those changes is not easy
(1%-3%) of your bases may be errors.
30x
What’s the typical workflow in a re-sequencing project ?
Library preparation
Library preparation Sequencing
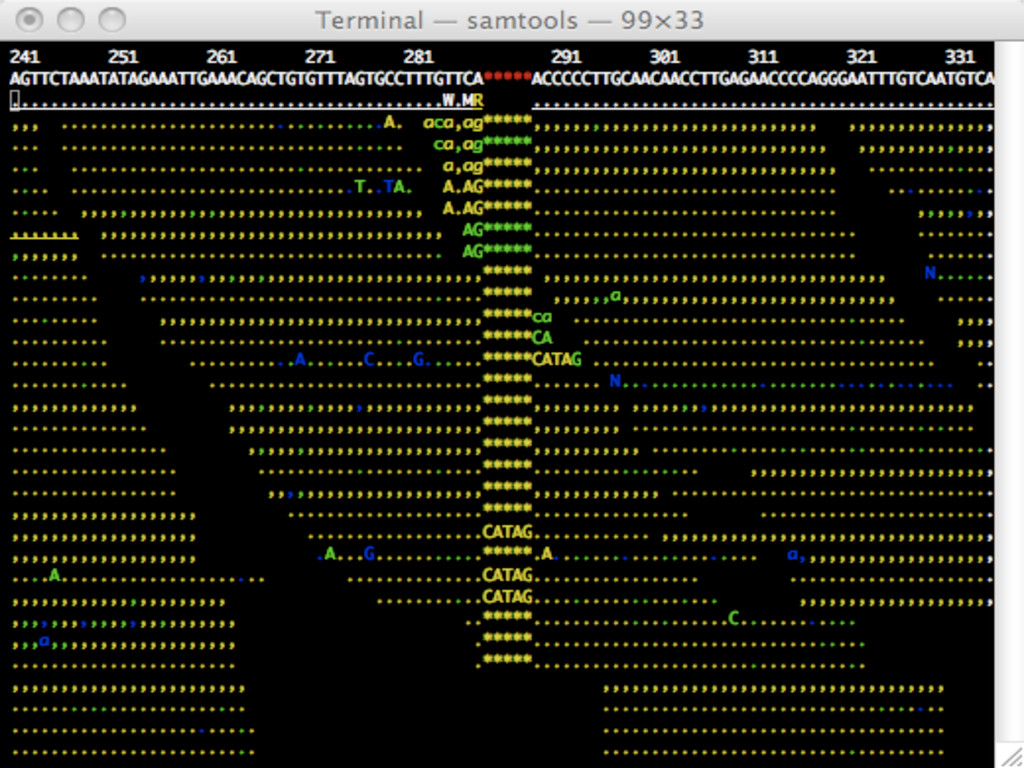
Library preparation Sequencing Analysis I (images -> reads)
.fastq ... >HWI-ST821_0129:5:1101:1927:2089#GATCAG/1 TGGACAACGGCCAGGTTAATGATGGGCAGGTAGAAGATGATCACT +HWI-ST821_0129:5:1101:1927:2089#GATCAG/1 ___ccccccYc[eff`]X`a^ef][RHP^_cXIYSXcXcfSWXcd ...
Library preparation Sequencing Analysis I (images -> reads) Analysis II
(alignments)
None
Library preparation Sequencing Analysis I (images -> reads) Analysis II
(alignments) Analysis III (Variant calling)
.vcf
Library preparation Sequencing Analysis I (images -> reads) Analysis II
(alignments) Analysis III (Variant calling) Annotation
Library preparation Sequencing Analysis I (images -> reads) Analysis II
(alignments) Analysis III (Variant calling) Annotation Science starts here …
None
Library preparation Sequencing Analysis I (images -> reads) Analysis II
(alignments) Analysis III (SNP calling) Annotation 5/15 Tb 150Gb 80G 16 8G 1G 1 400Mb 1
1 Genome (3-6 days) ~ 230Gb
1 Genome
Let’s do it again for N genomes
Let’s do it again for N genomes
None
None
None
None
None
None
None
personalize medicine
personalize medicine Tailor physician decisions and practices to individual patients
Let’s do it again for N genomes
None
None
Thanks!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
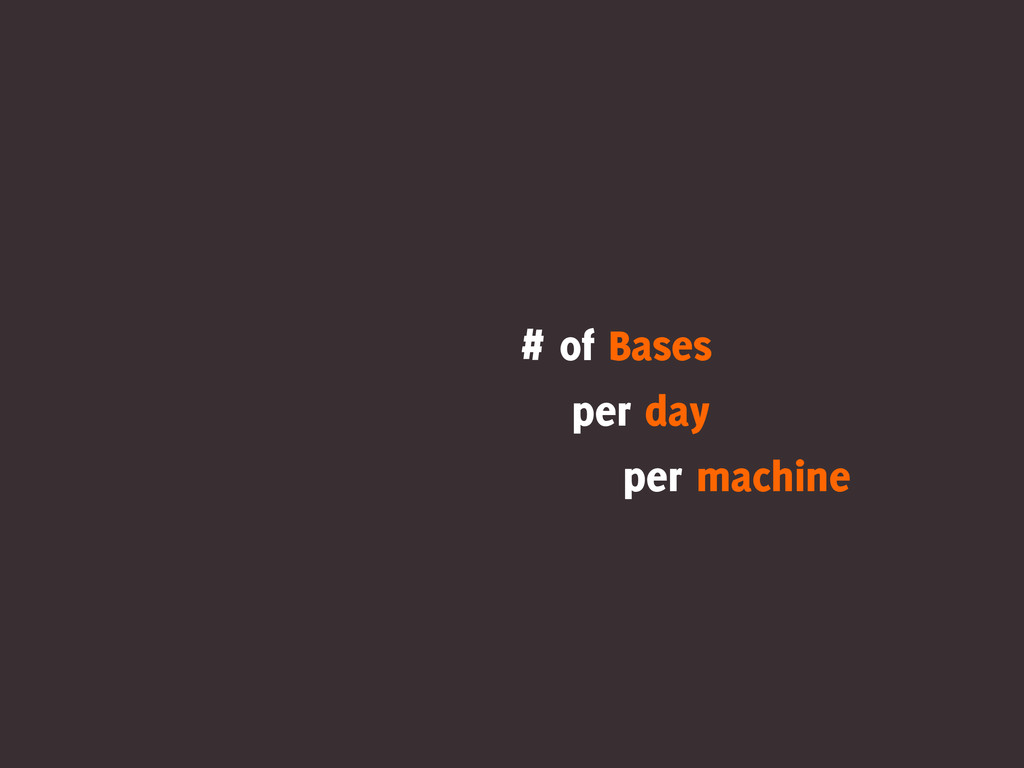{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![.fastq ... >HWI-ST821_0129:5:1101:1927:2089#GATCAG/1 TGGACAACGGCCAGGTTAATGATGGGCAGGTAGAAGATGATCACT +HWI-ST821_0129:5:1101:1927:2089#GATCAG/1 ___ccccccYc[eff`]X`a^ef][RHP^_cXIYSXcXcfSWXcd ...](https://files.speakerdeck.com/presentations/4f712475ca692c001f00e960/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}