against aggregate tables • fast to acceptable ‣ Queries against base fact table • generally unacceptable I. RDBMS - THE RESULTS Monday, September 9, 13
rows / second / core 1 day of summarized aggregates 60M+ rows 1 query over 1 week, 16 cores ~5 seconds Page load with 20 queries over a week of data long time Monday, September 9, 13
a NoSQL store II. NOSQL - THE SETUP ts gender age revenue 1 M 18 $0.15 1 F 25 $1.03 1 F 18 $0.01 Key Value 1 revenue=$1.19 1,M revenue=$0.15 1,F revenue=$1.04 1,18 revenue=$0.16 1,25 revenue=$1.03 1,M,18 revenue=$0.15 1,F,18 revenue=$0.01 1,F,25 revenue=$1.03 Monday, September 9, 13
key ‣ Inflexible • not aggregated, not available ‣ Not continuously updated • aggregate first, then display ‣ Processing scales exponentially II. NOSQL - THE RESULTS Monday, September 9, 13
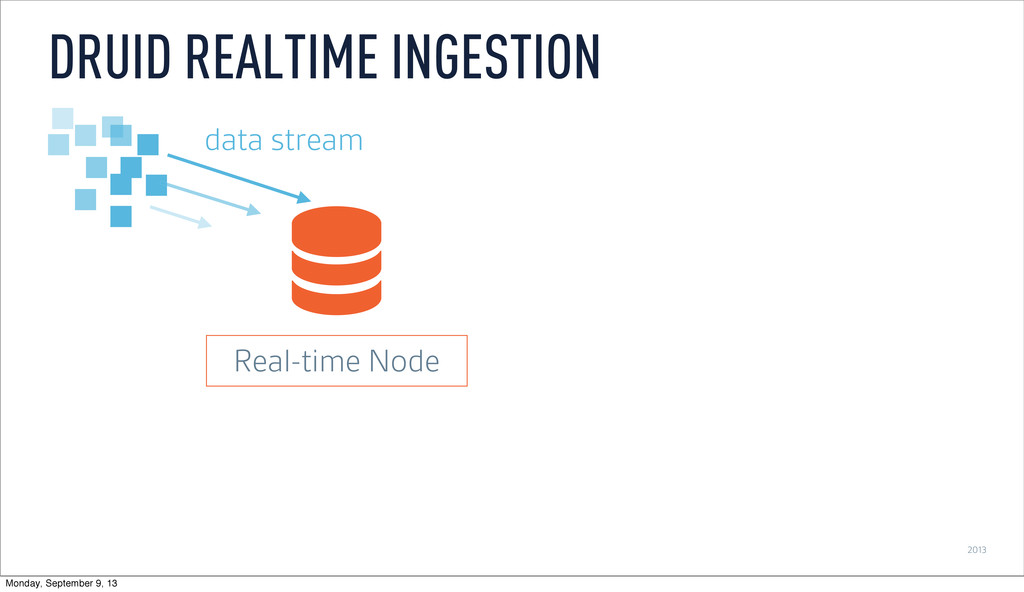
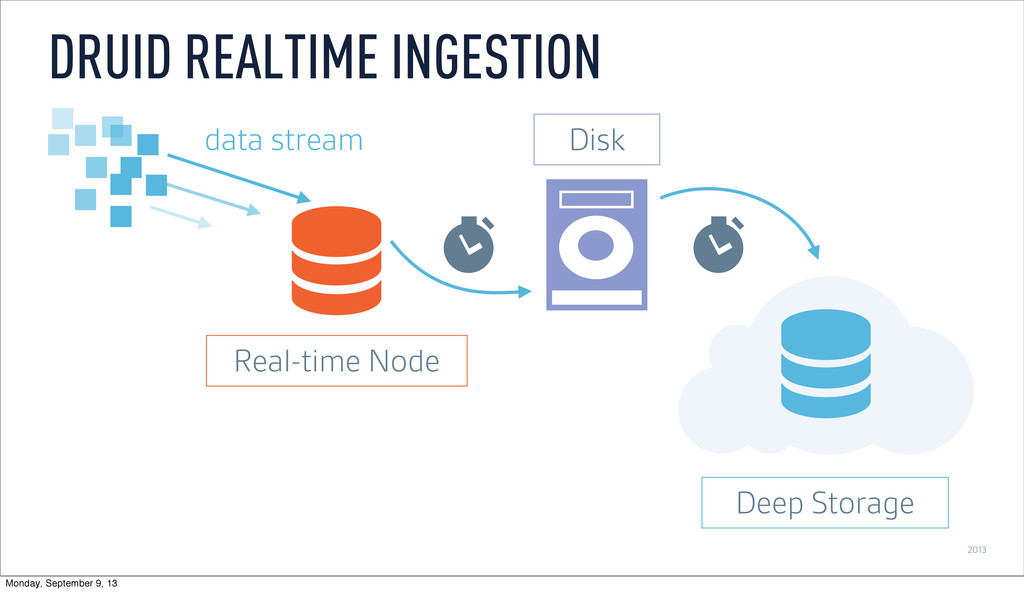
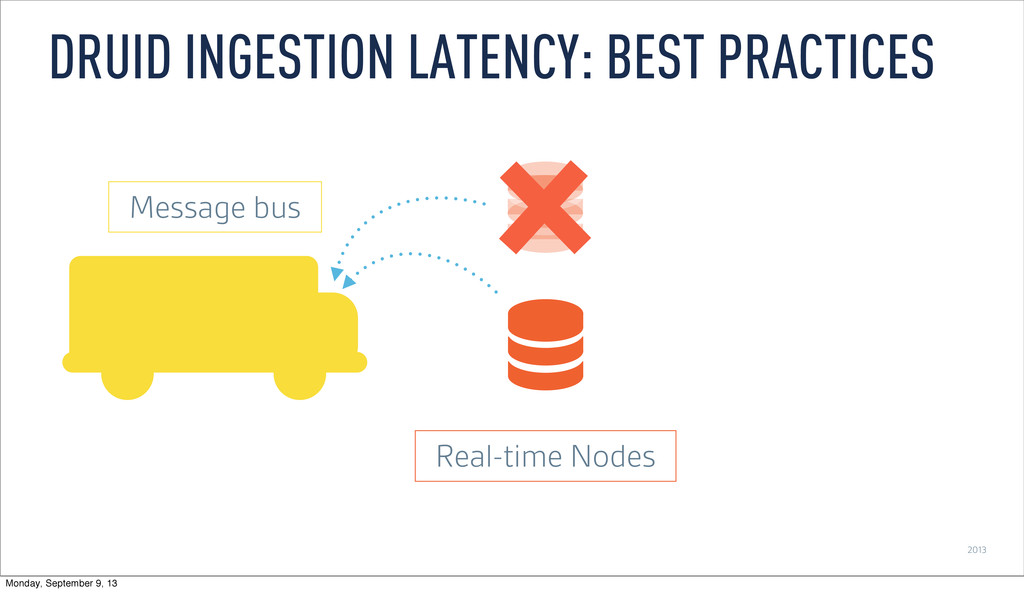
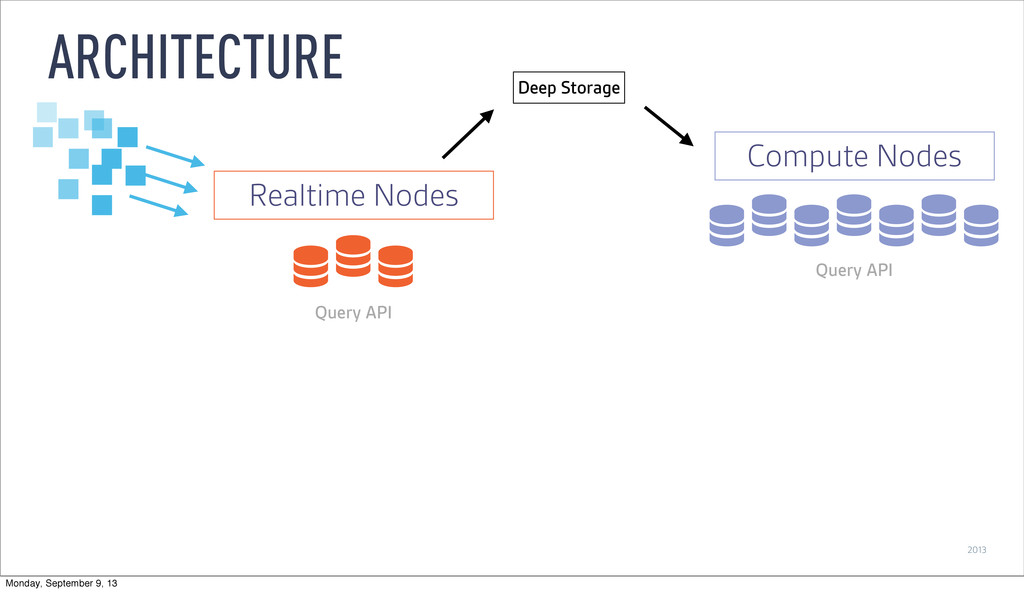
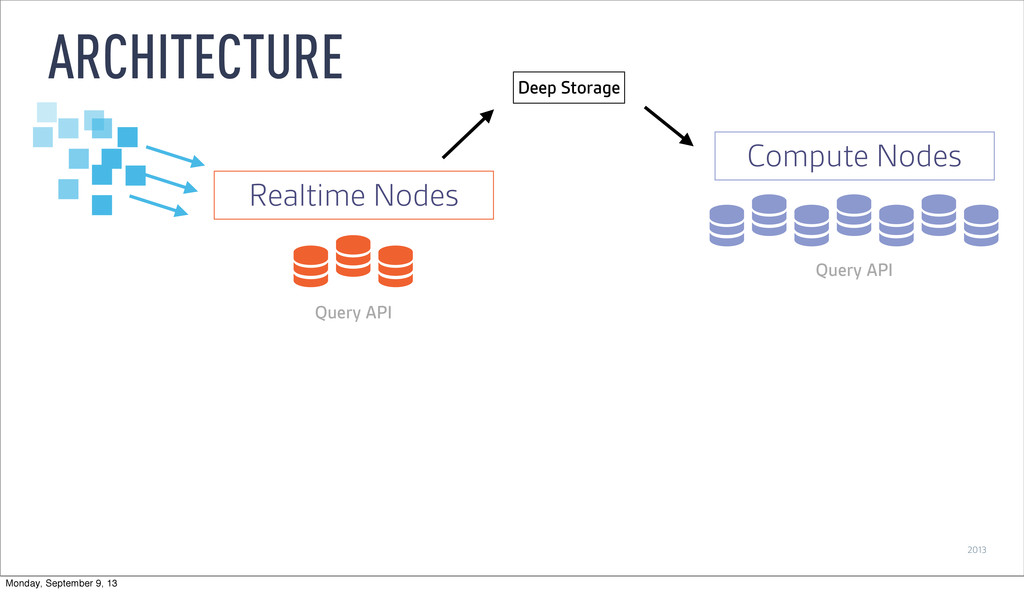
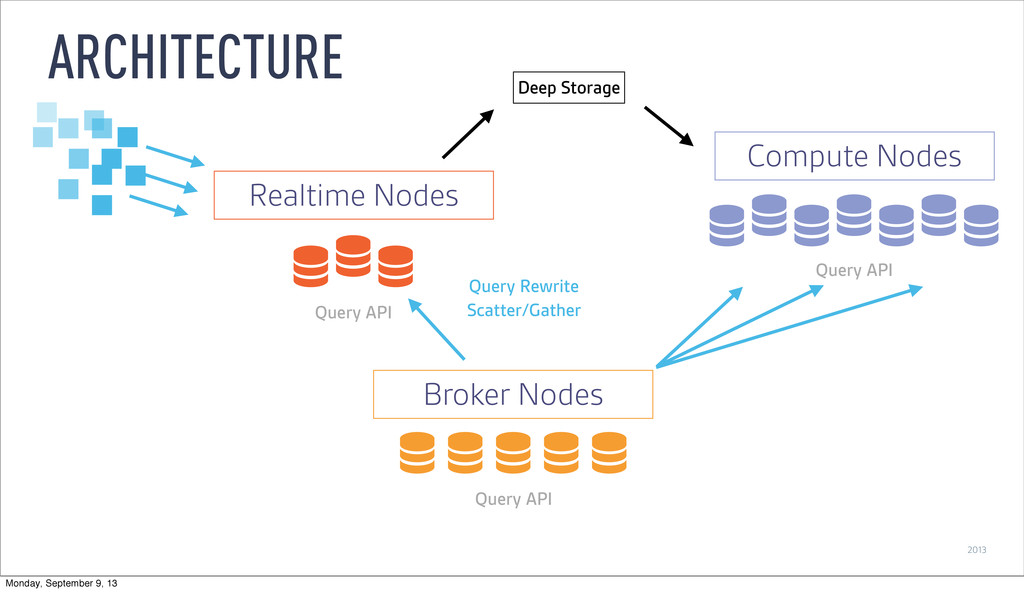
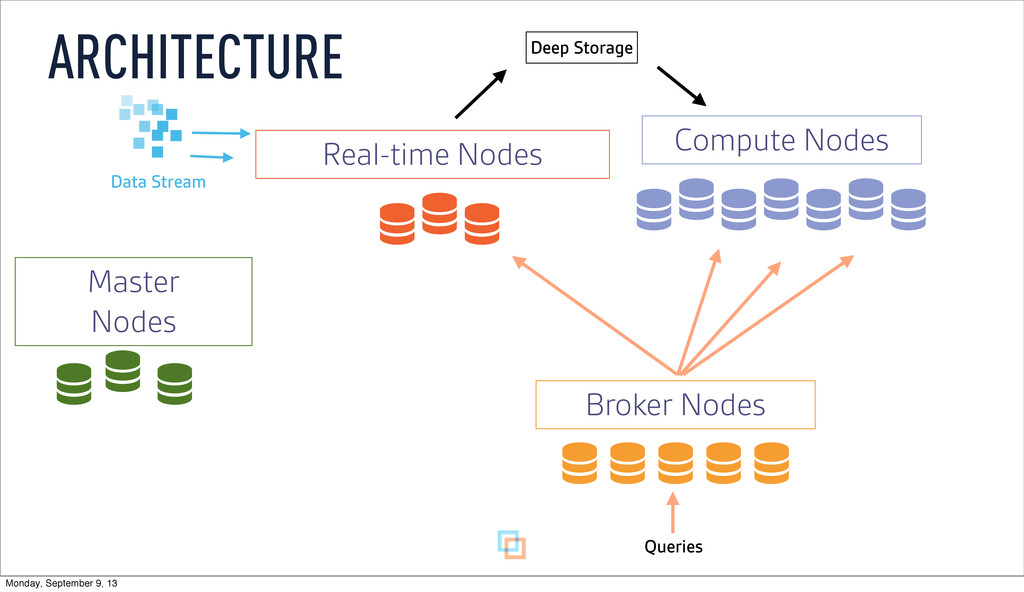
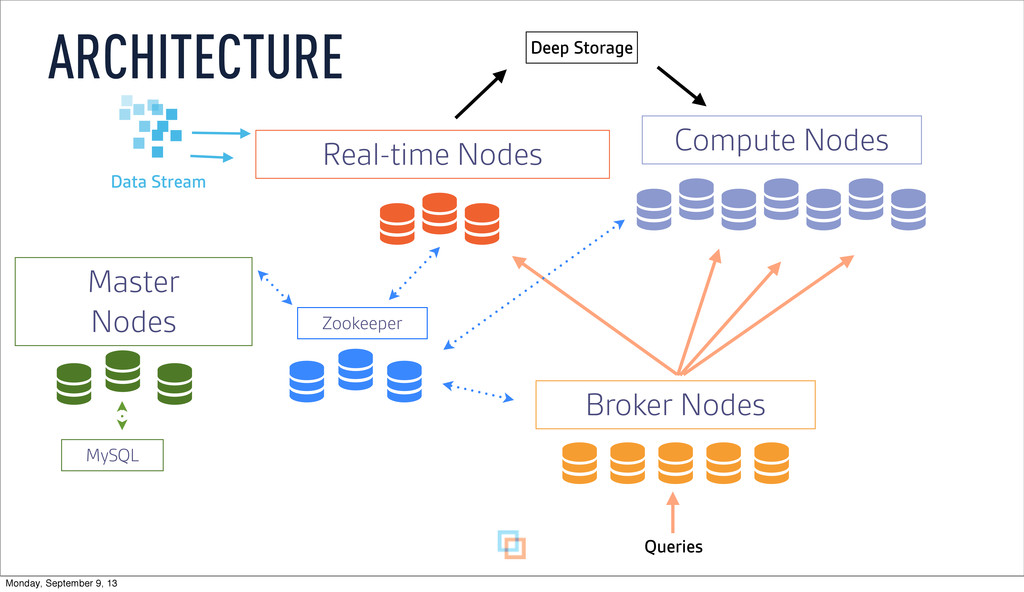
as it is ingested ‣ Buffer data in memory ‣ Persist to local disk at configurable time window ‣ Merge and persist to deep storage at (wider) time window REAL-TIME NODES Monday, September 9, 13
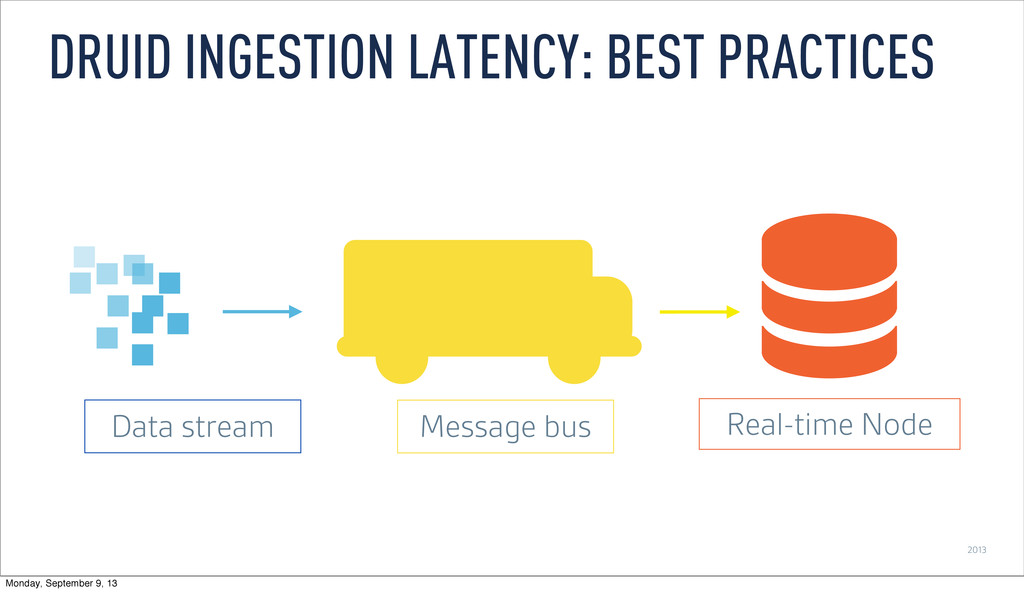
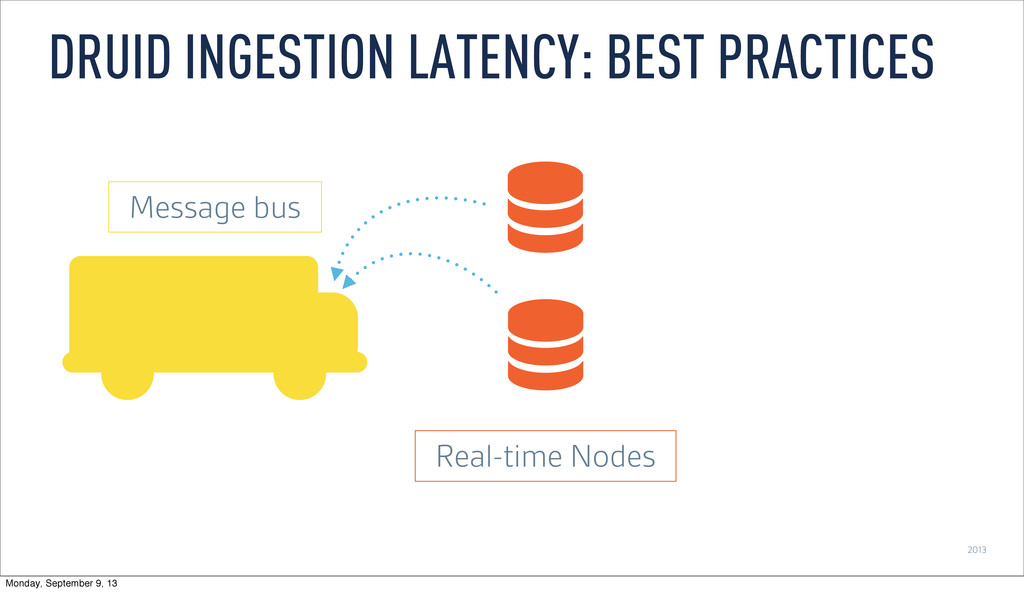
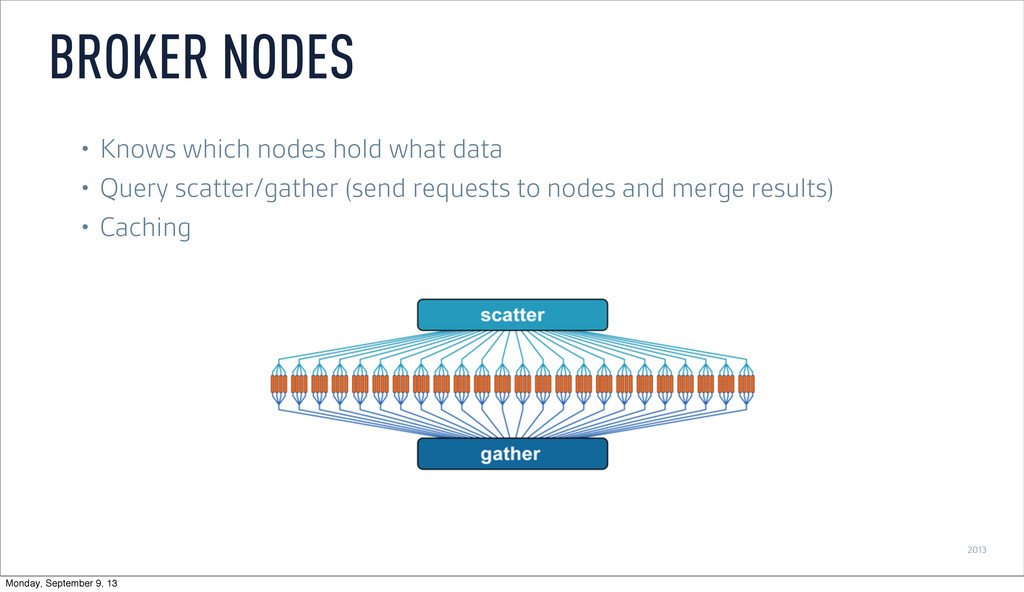
Persist events and update message stream offsets • Replay events • Recover from lost process by replaying events that haven’t persisted • Consume same feed multiple times • Replicate by having multiple real-time nodes process the same stream DRUID INGESTION LATENCY: BEST PRACTICES Monday, September 9, 13
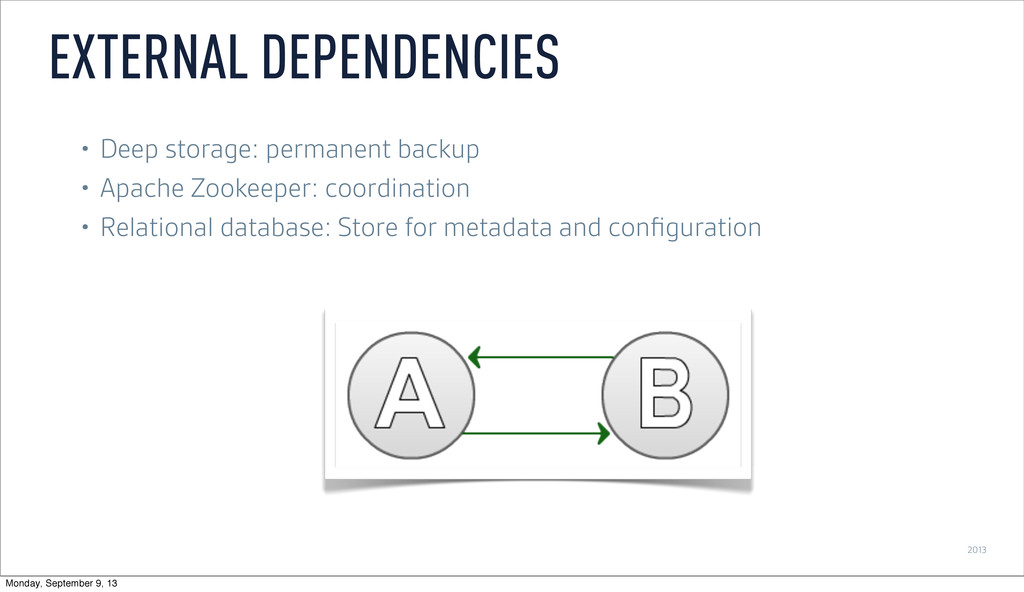
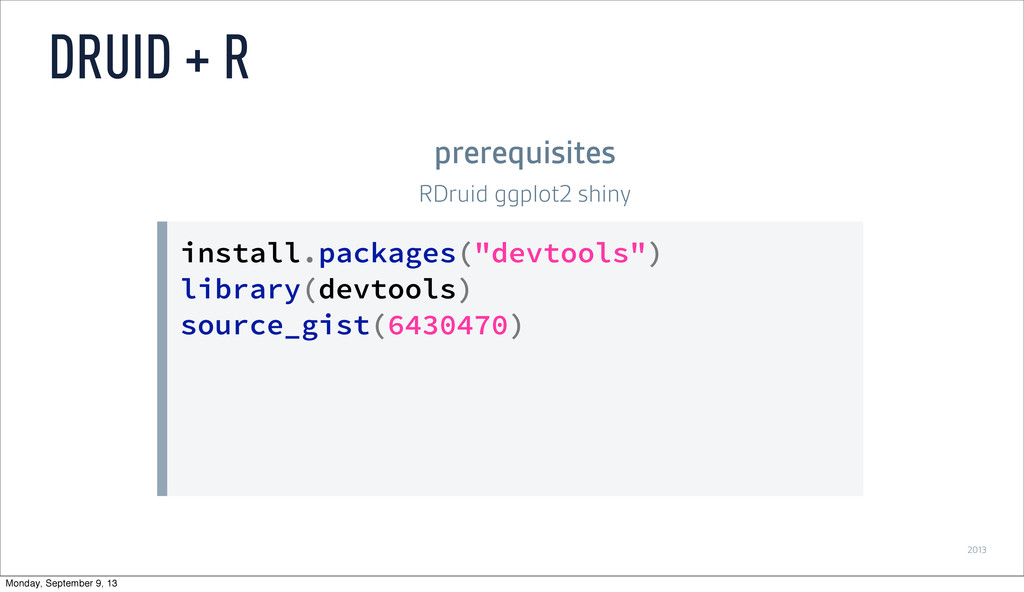
brew install mysql mysql -u root GRANT ALL ON druid.* TO 'druid'@'localhost' IDENTIFIED BY 'diurd'; CREATE database druid; INSTALLING EXTENSIONS MySQL Monday, September 9, 13
2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T01:00:00Z Ke$ha en Calgary CA 17 87 2011-01-01T02:00:00Z Ke$ha en Calgary CA 43 99 2011-01-01T02:00:00Z Ke$ha en Calgary CA 12 53 ... Monday, September 9, 13
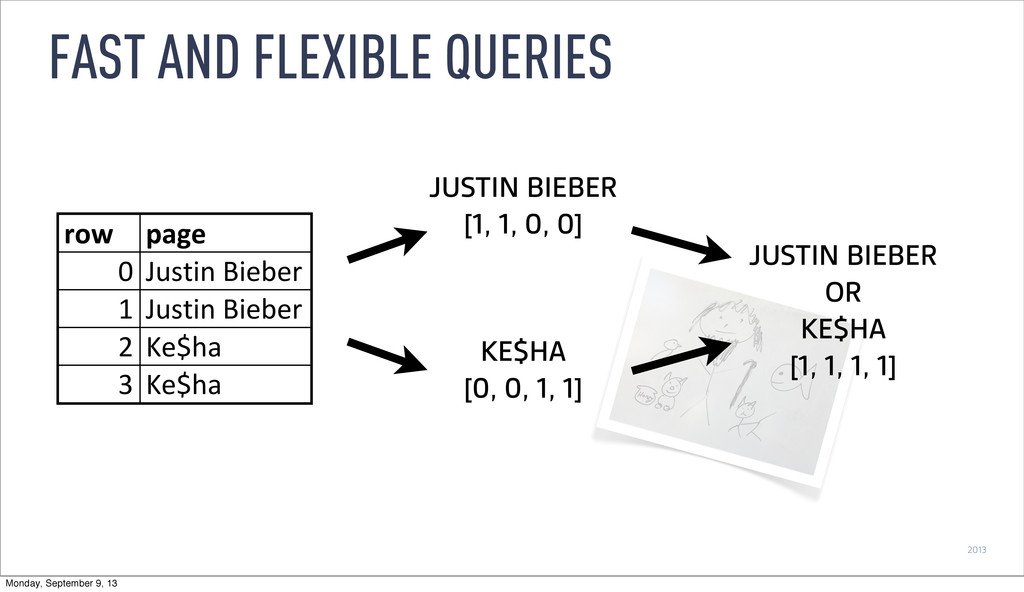
Bieber -> 0, Ke$ha -> 1 ‣ Store • page -> [0 0 0 1 1 1] • language -> [0 0 0 0 0 0] timestamp page language city country ... added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T01:00:00Z Ke$ha en Calgary CA 17 87 2011-01-01T02:00:00Z Ke$ha en Calgary CA 43 99 2011-01-01T02:00:00Z Ke$ha en Calgary CA 12 53 ... Monday, September 9, 13
-> [111000] ‣ Ke$ha -> [3, 4, 5] -> [000111] timestamp page language city country ... added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T01:00:00Z Ke$ha en Calgary CA 17 87 2011-01-01T02:00:00Z Ke$ha en Calgary CA 43 99 2011-01-01T02:00:00Z Ke$ha en Calgary CA 12 53 ... Monday, September 9, 13
directly on compressed indices • Less memory => faster scan rates ‣ More details • http://ricerca.mat.uniroma3.it/users/colanton/concise.html Monday, September 9, 13
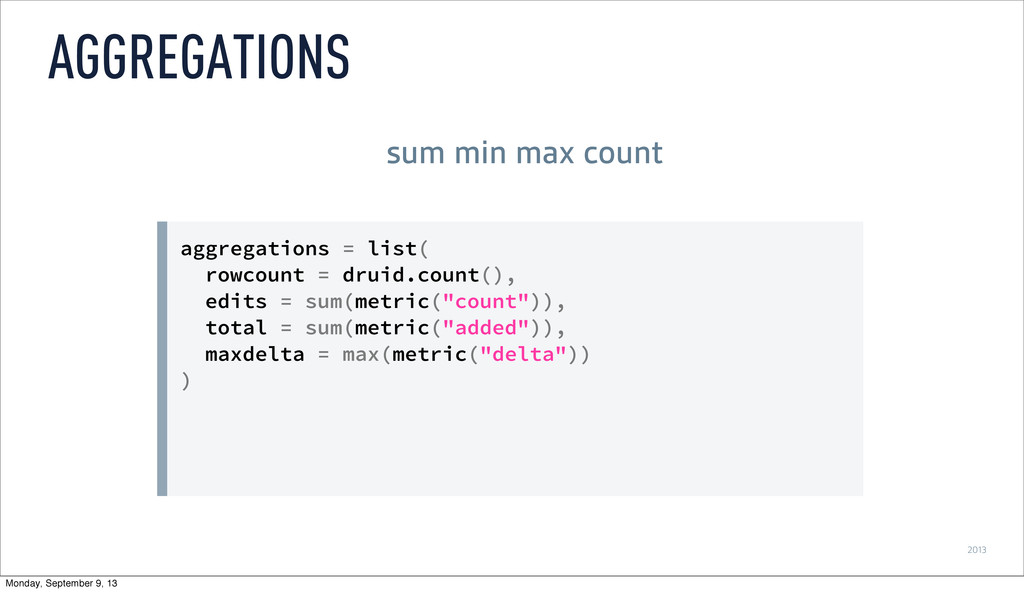
dimension("namespace") == "article" & ( dimension("language") == "en" | dimension("language") == "fr" ) ) FILTERS what if I’m only interested in articles in English or French Monday, September 9, 13
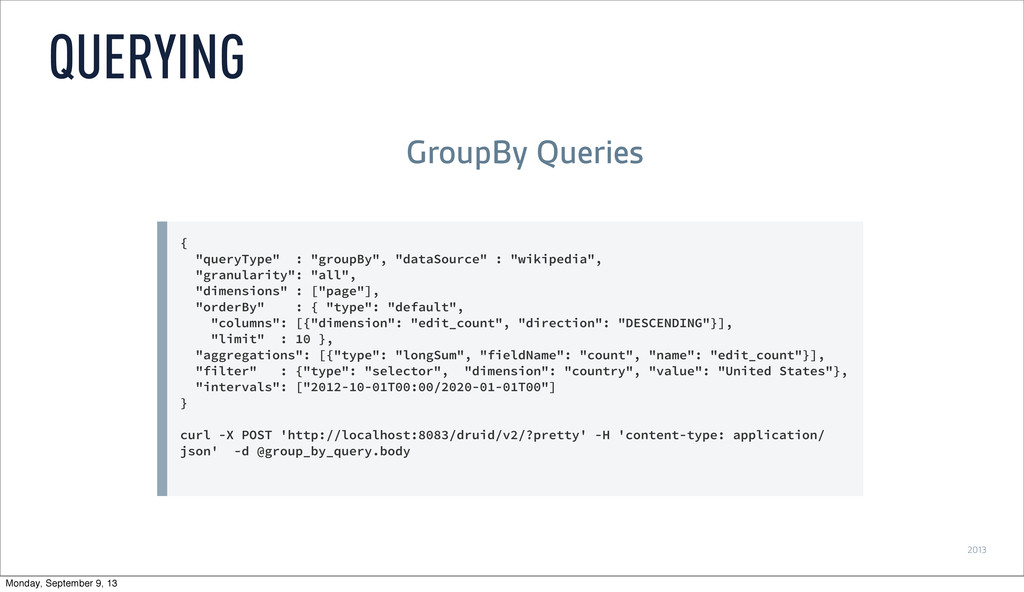
& ( dimension("language") == "en" | dimension("language") == "fr" ), dimensions = list("language") ) qplot(data = enfr, x = timestamp, y = count, geom = "line", color = language) GROUP BY break it out by language Monday, September 9, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2013 { "queryType": "timeseries", "dataSource": "wikipedia", "intervals": ["2010-01-01/2020-01-01"], "granularity": "minute",](https://files.speakerdeck.com/presentations/50c52830fc7301302f630ada113e7e19/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2013 BITMAP INDICES ‣ Justin Bieber -> [0, 1, 2]](https://files.speakerdeck.com/presentations/50c52830fc7301302f630ada113e7e19/slide_65.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2013 enfr <- druid.query.timeseries( [...] granularity = granularity("PT1M"), filter =](https://files.speakerdeck.com/presentations/50c52830fc7301302f630ada113e7e19/slide_81.jpg){kind=link}
![2013 enfr <- druid.query.groupBy( [...] filter = dimension("namespace") == "article"](https://files.speakerdeck.com/presentations/50c52830fc7301302f630ada113e7e19/slide_82.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}