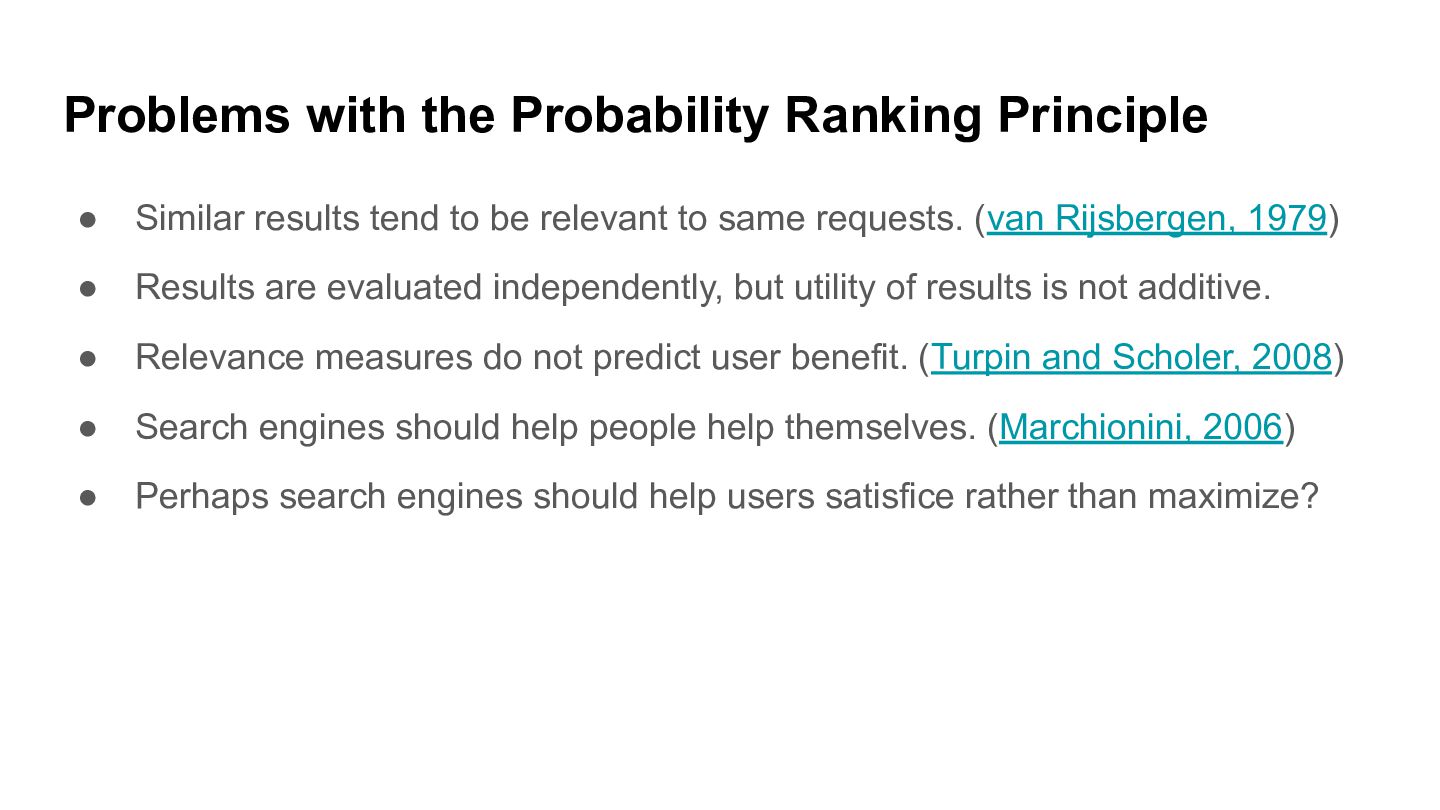
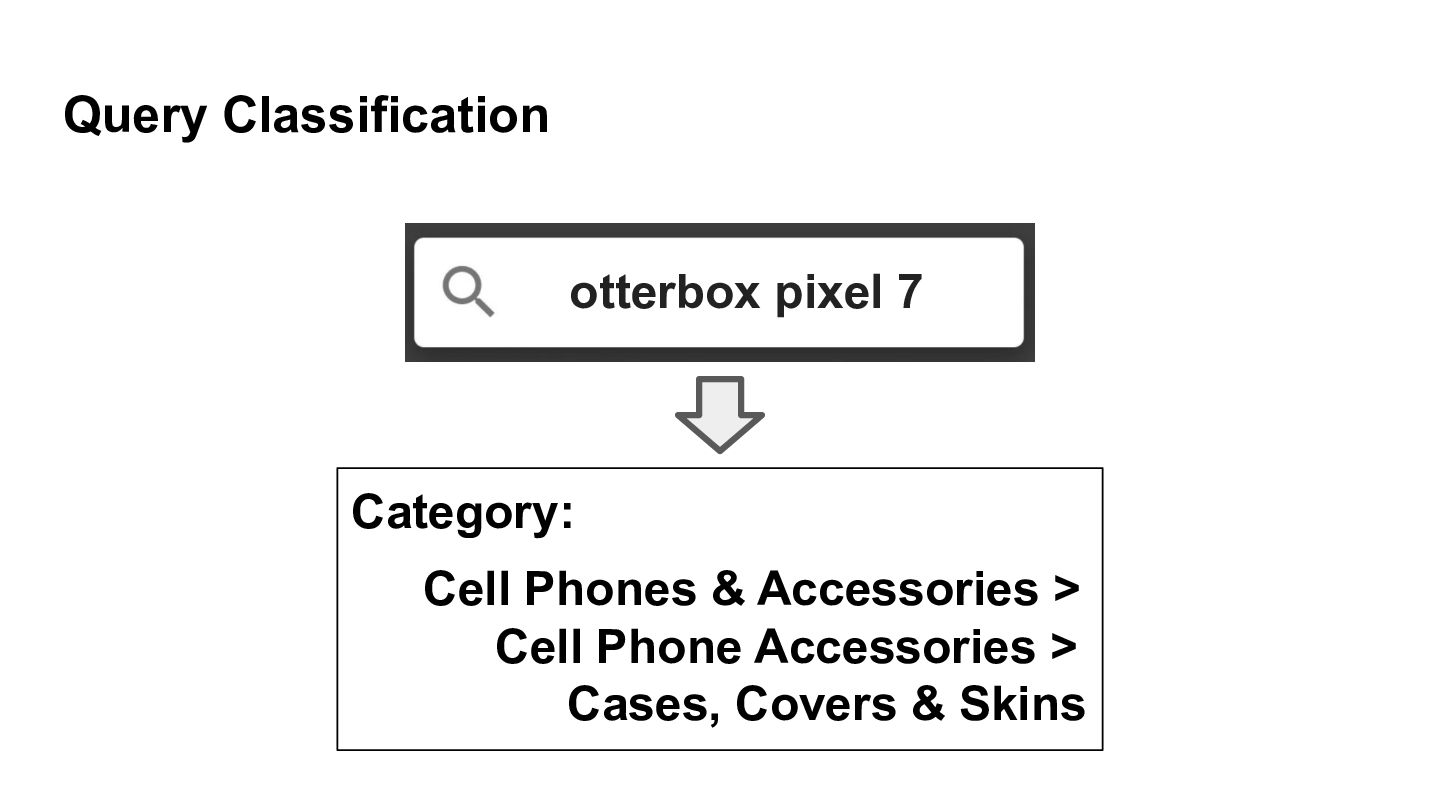
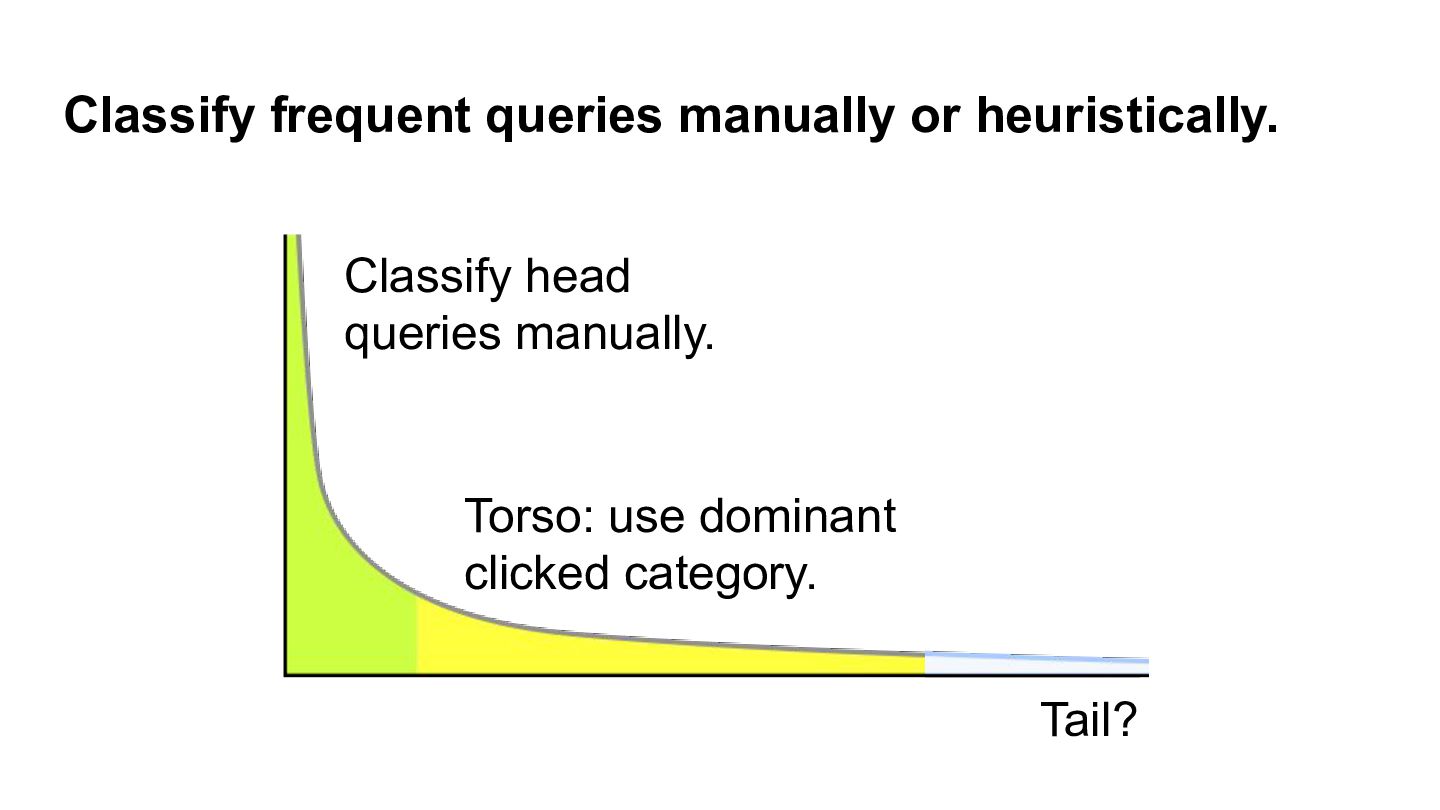
This 2023 Walmart AI Summit keynote describes how behavioral economics transformed how we think about human decision making, rejecting expected utility maximization for the real world of heuristics, biases, and satisficing. It argues that our thinking about search engines needs a similar transformation. It compares the Probability Ranking Principle to expected utility maximization and offer ways that AI can help searchers satisfice through query understanding.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
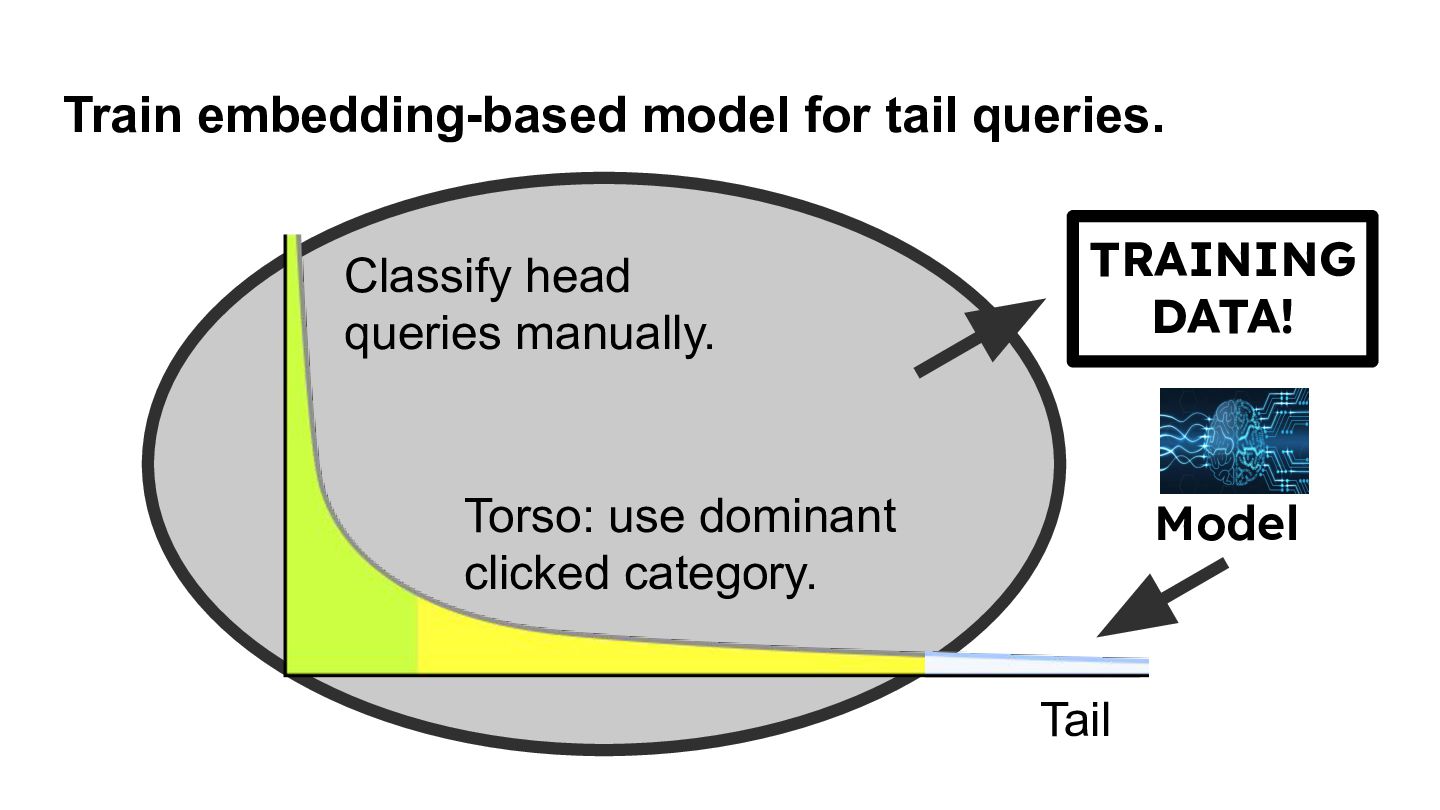{kind=link}
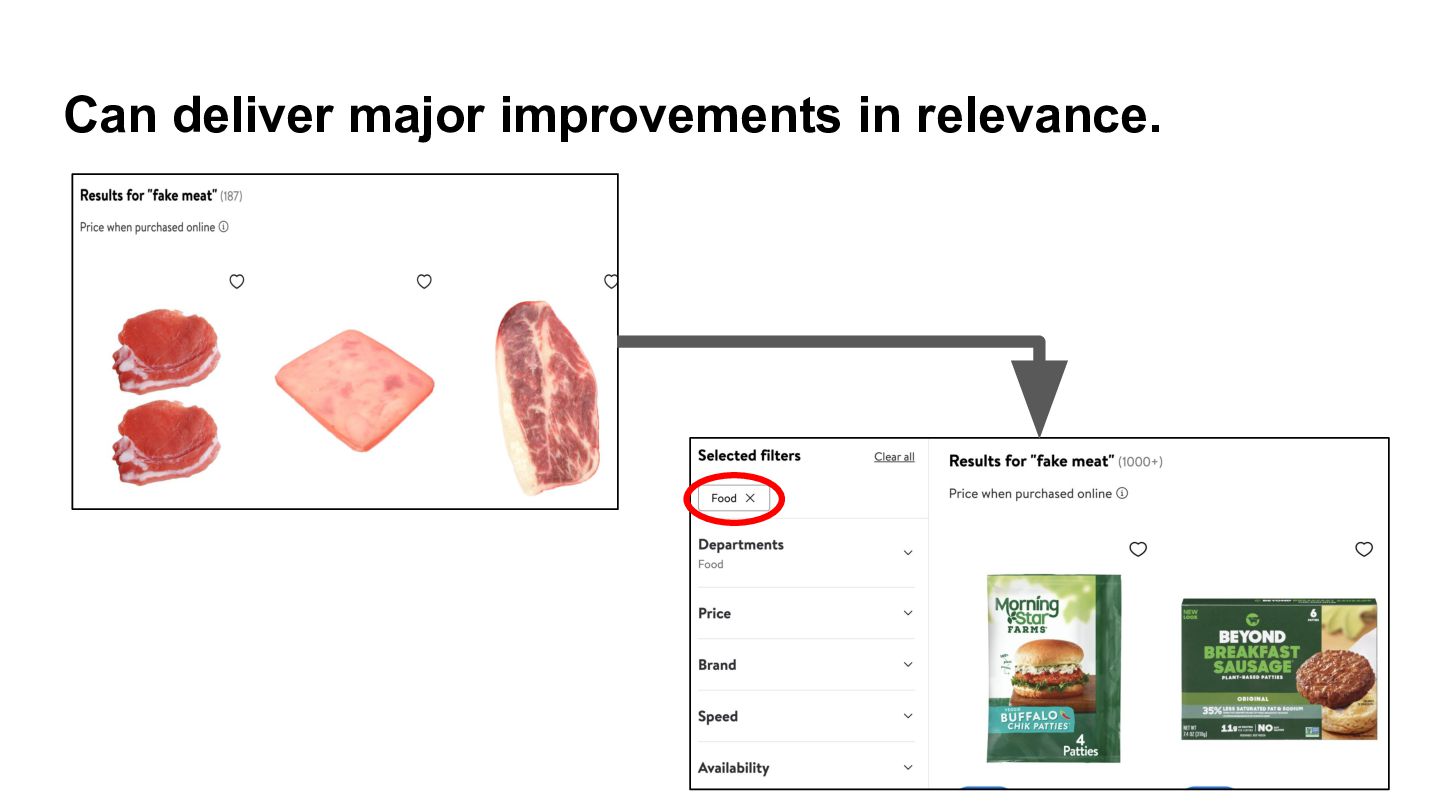{kind=link}
{kind=link}
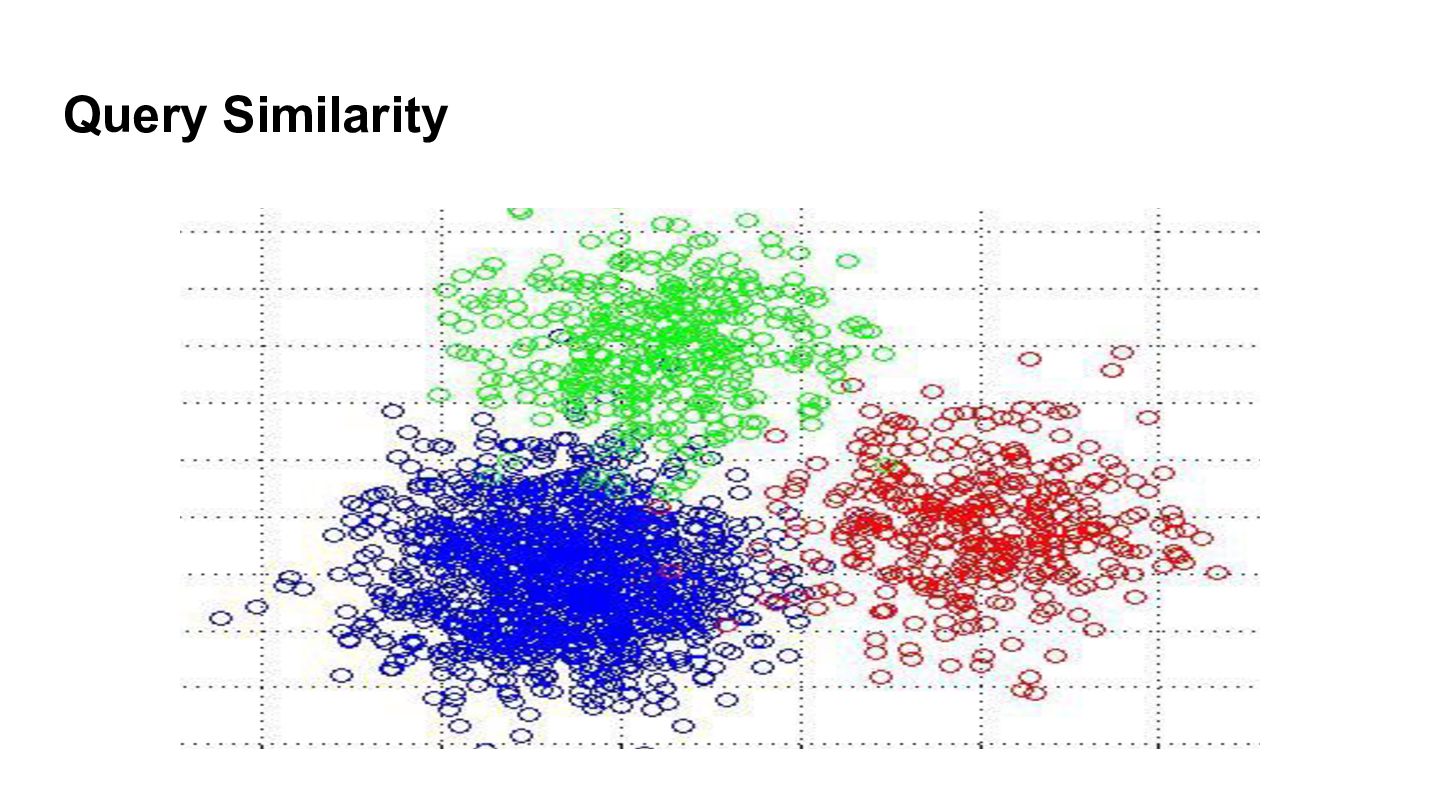{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
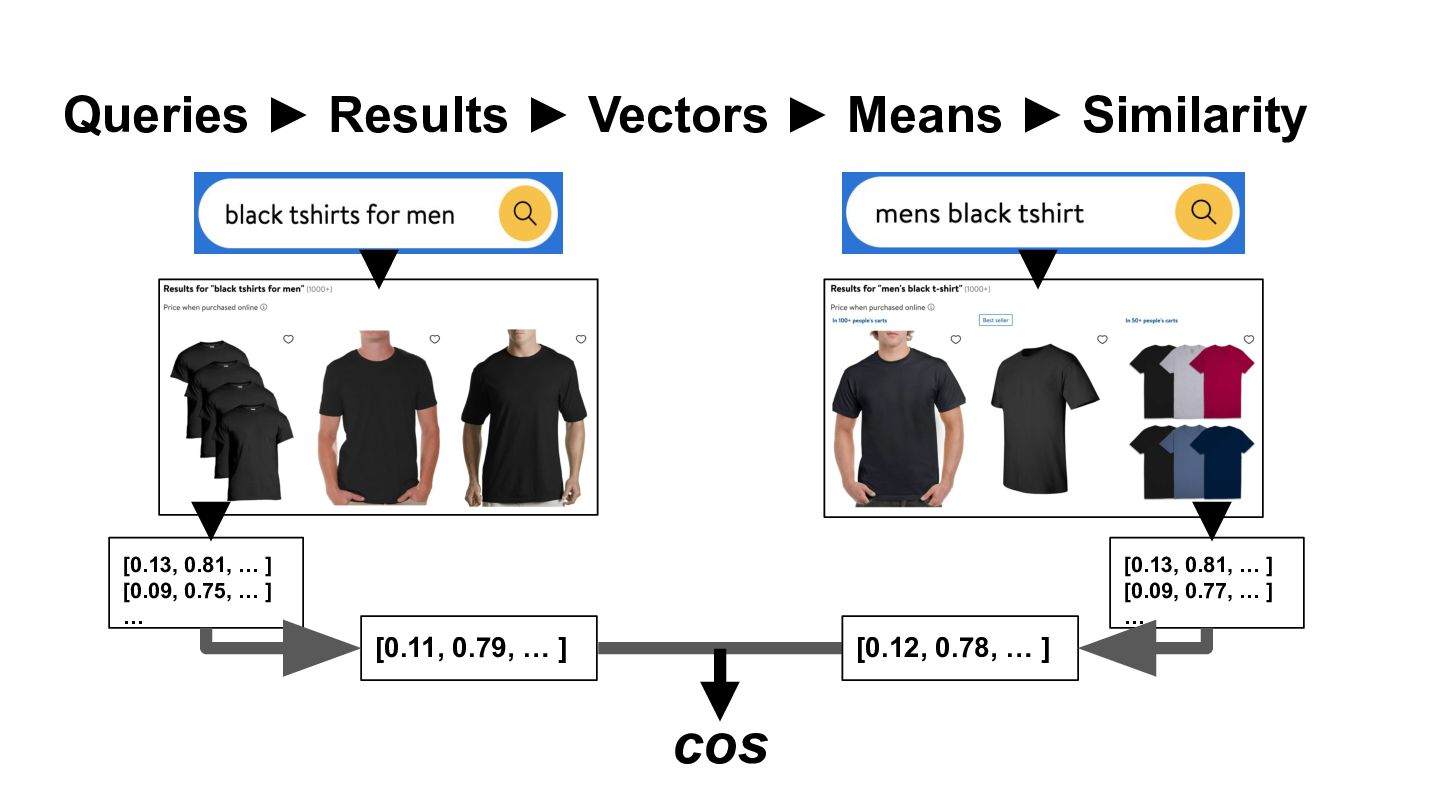{kind=link}
{kind=link}
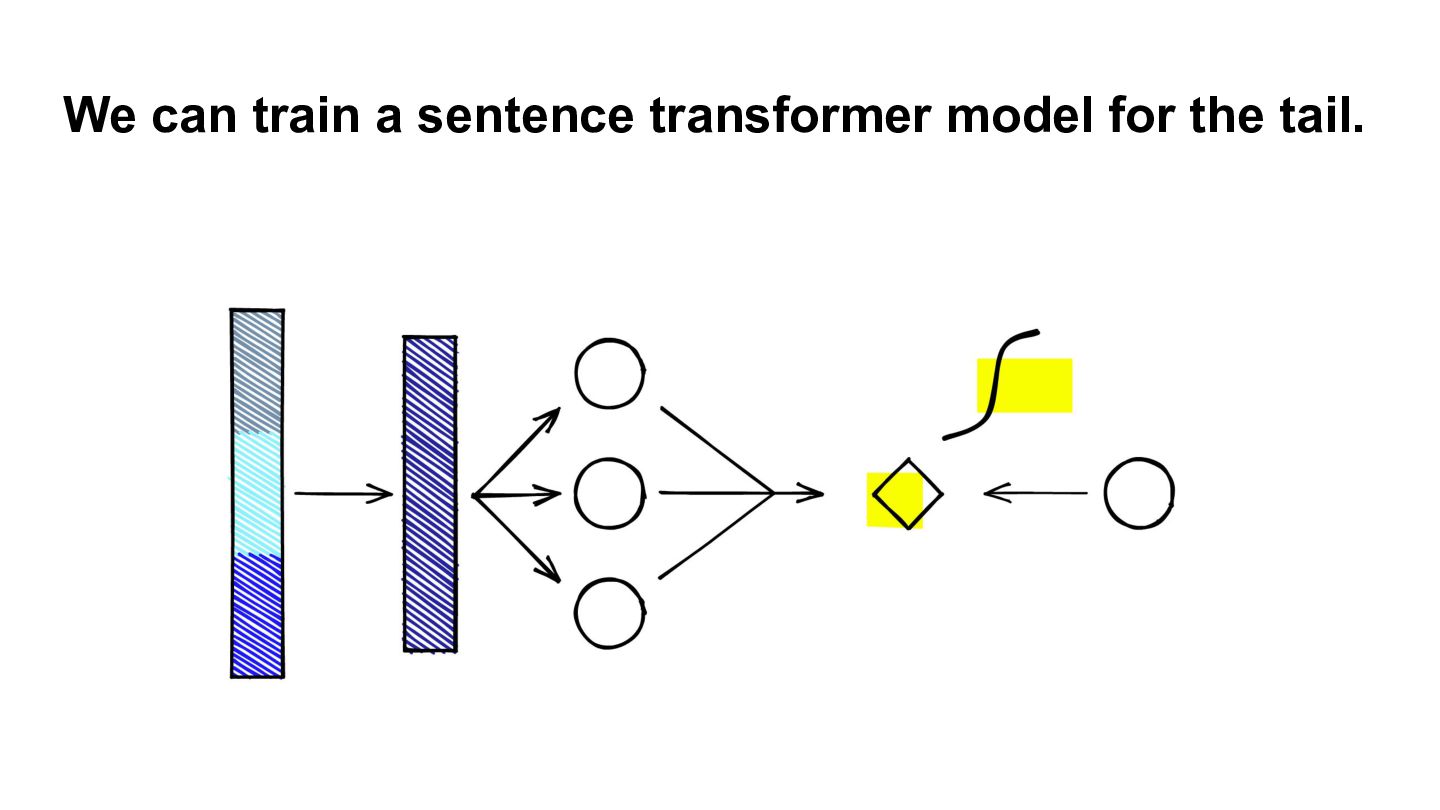{kind=link}
{kind=link}
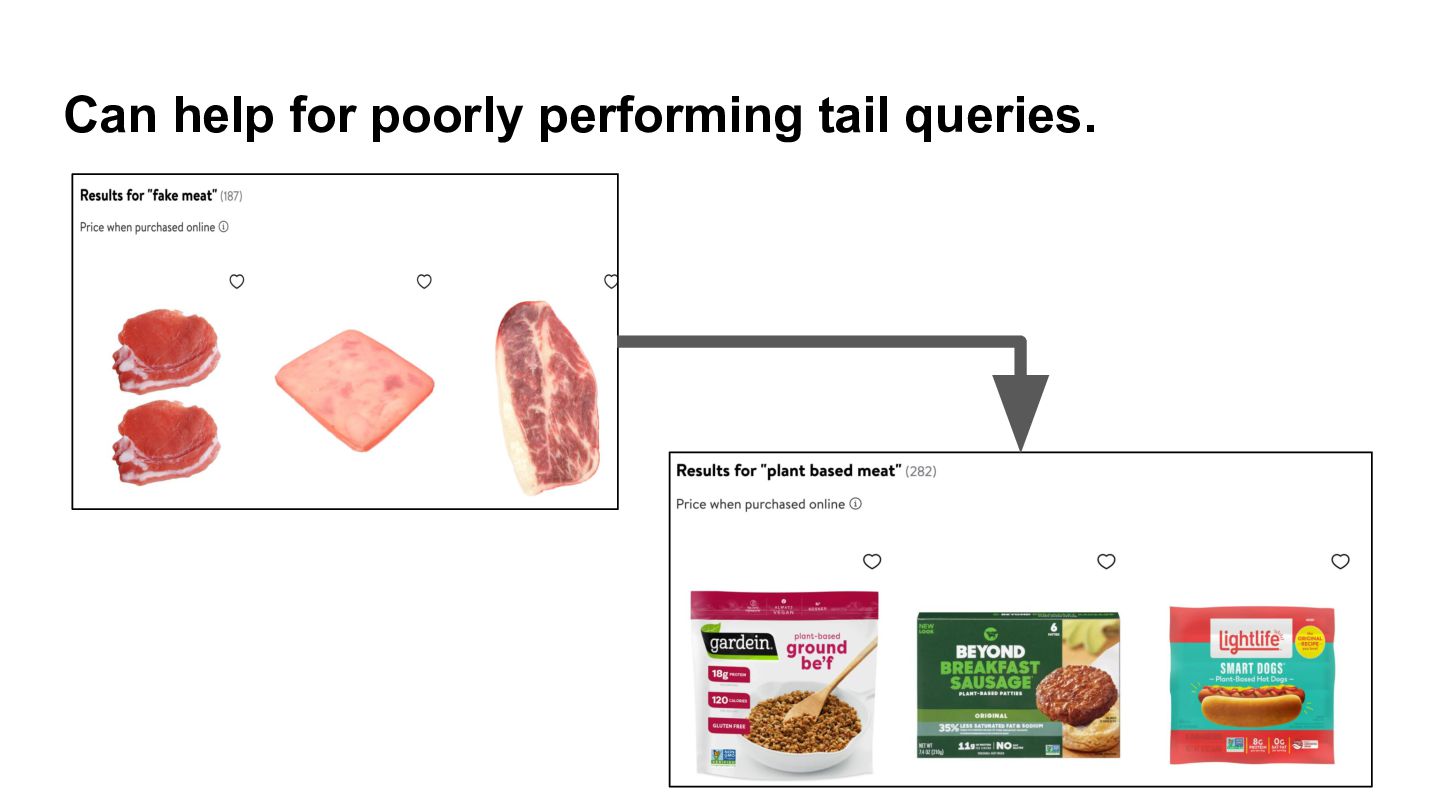{kind=link}
{kind=link}