) E(CatchRate) = μ ij Log(μ ij ) = GearType ij + Temperature ij + FleetDeployment i FleetDeployment i ~ N(0, σ2) Using lme4: m <- glmer(CatchRate ~ GearType + Temperature + (1 | FleetDeployment), family = poisson) FISH 6003 FISH 6003: Statistics and Study Design for Fisheries Brett Favaro 2017 This work is licensed under a Creative Commons Attribution 4.0 International License
in which we gather as the ancestral homelands of the Beothuk, and the island of Newfoundland as the ancestral homelands of the Mi’kmaq and Beothuk. We would also like to recognize the Inuit of Nunatsiavut and NunatuKavut and the Innu of Nitassinan, and their ancestors, as the original people of Labrador. We strive for respectful partnerships with all the peoples of this province as we search for collective healing and true reconciliation and honour this beautiful land together. http://www.mun.ca/aboriginal_affairs/
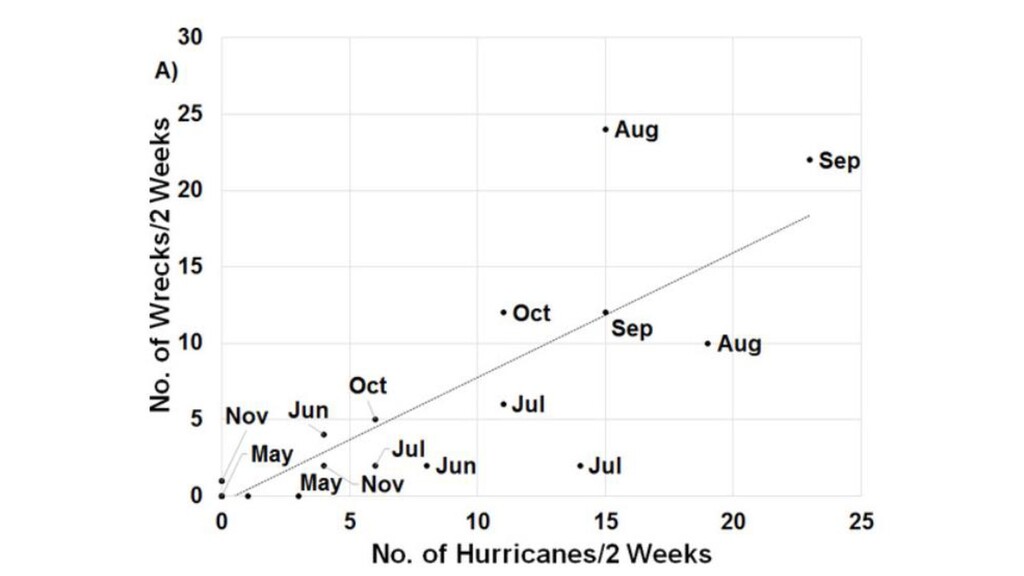
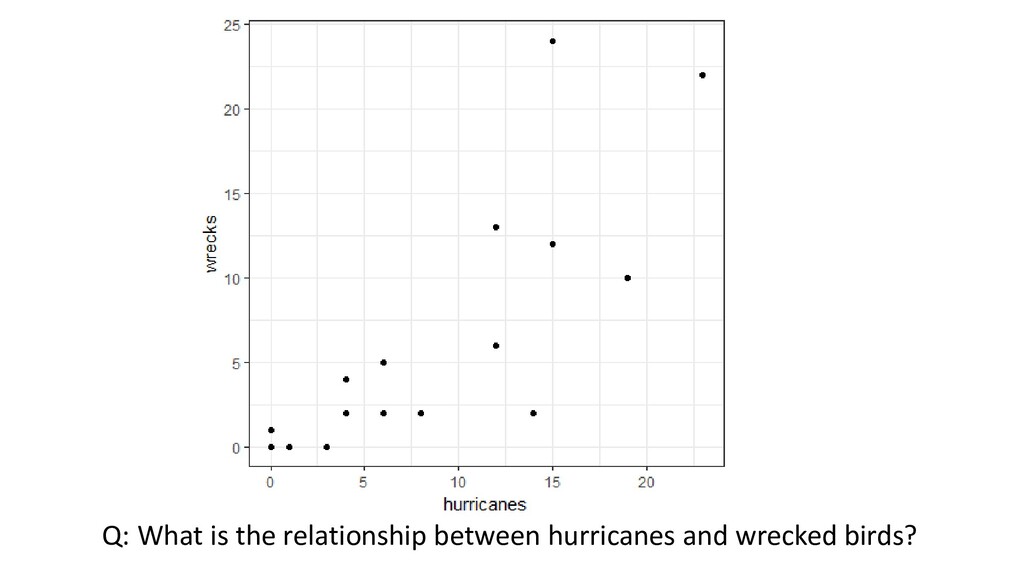
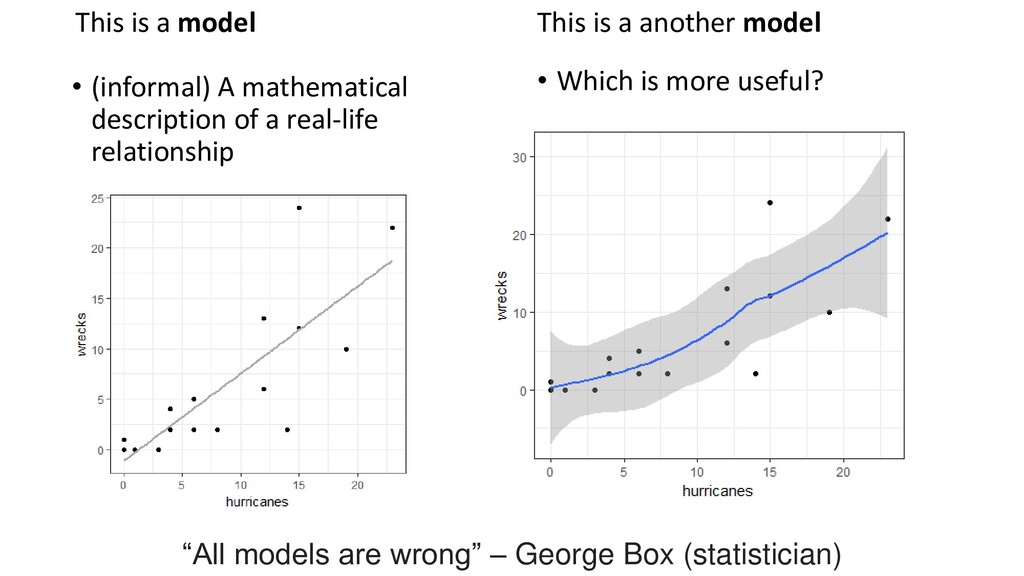
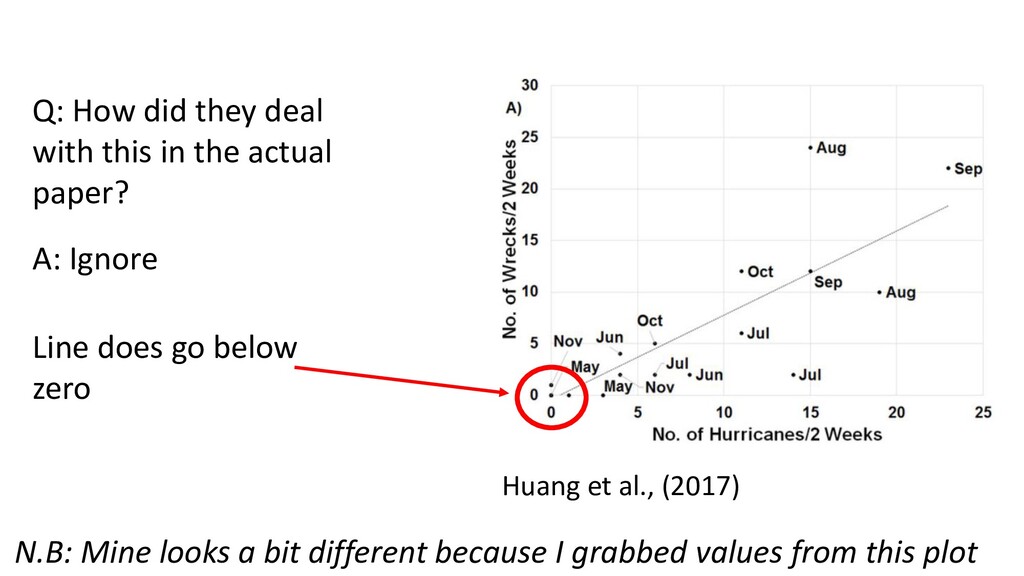
with a long-term capture- mark-recapture dataset from the Dry Tortugas National Park to map the movements at sea for this species, calculate estimates of mortality, and investigate the impact of hurricanes on a migratory seabird. … Indices of hurricane strength and occurrence are positively correlated with annual mortality and indices of numbers of wrecked birds.
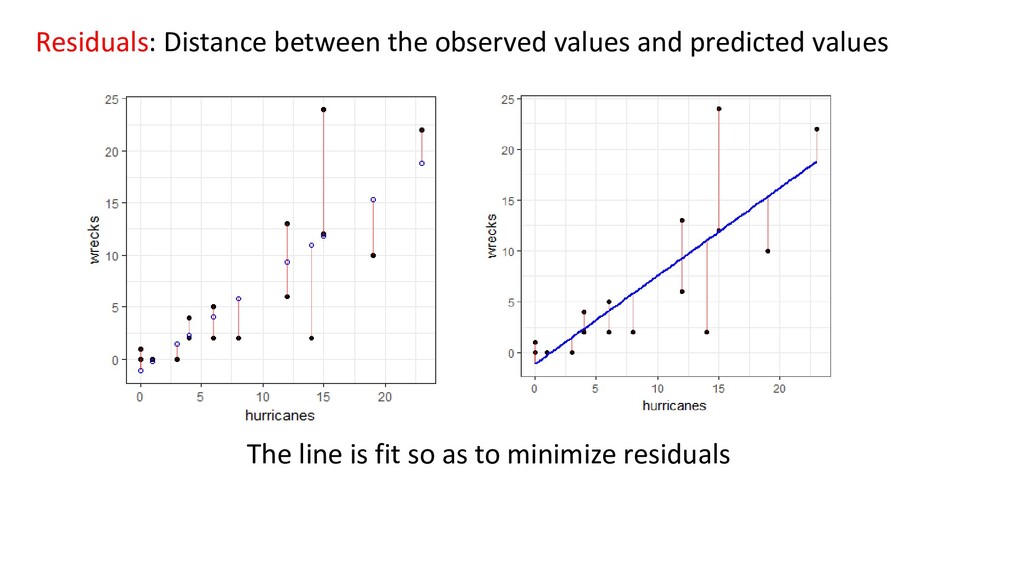
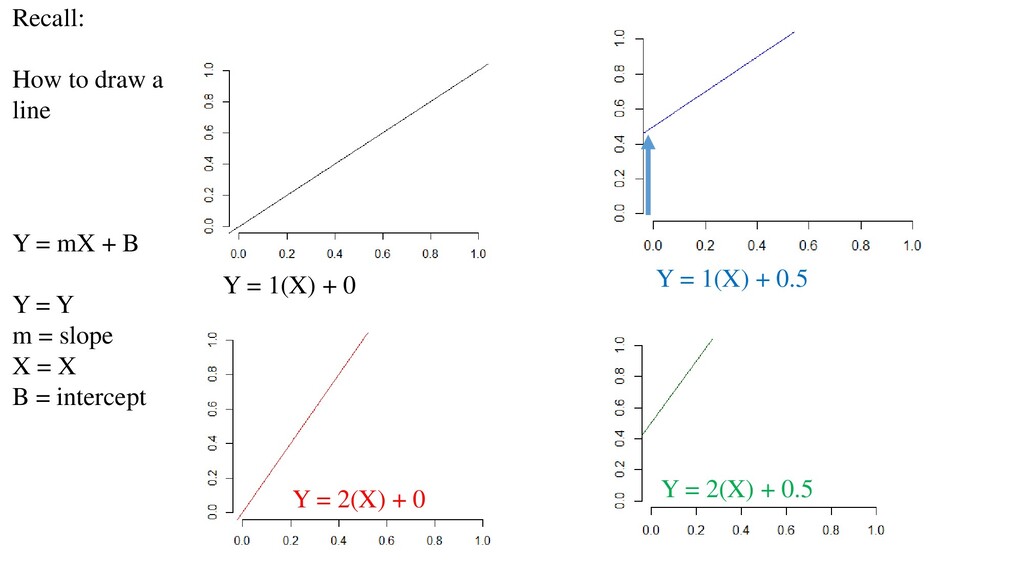
εi Yi = Response at position i Xi = Explanatory variable at i βo = Intercept (sometimes denoted α) β = Population slope ε = residual error – information not explained by model AKA “Bivariate linear regression” εi ~ N(0, σ2) Error is normally distributed with mean of zero, variance σ2 Same form as: Y = mX + B
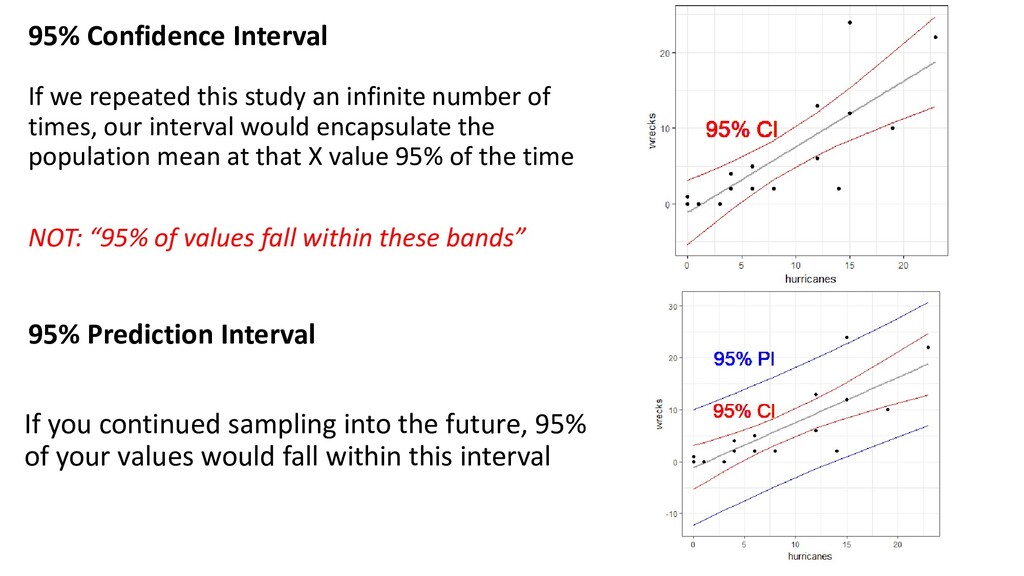
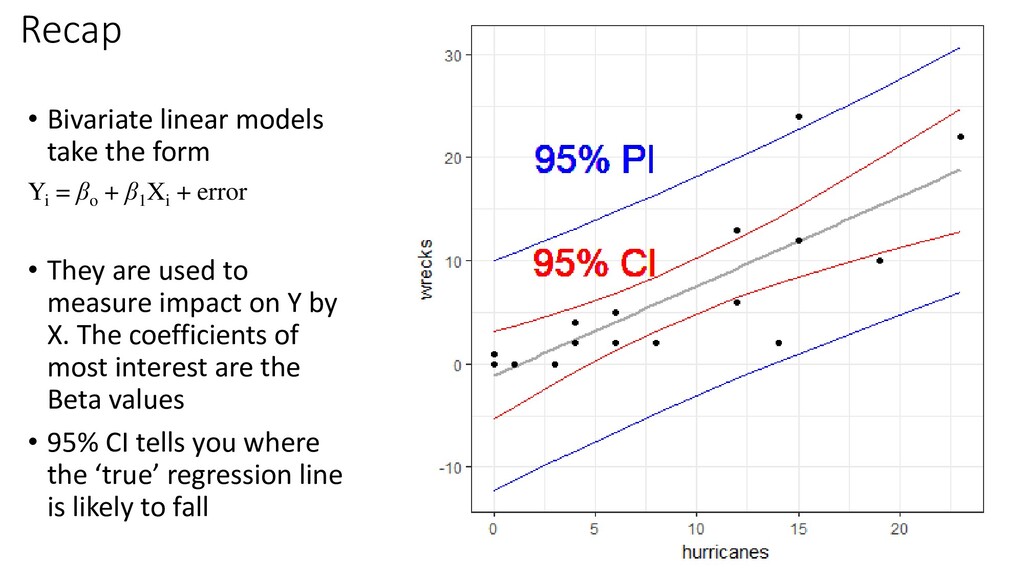
number of times, our interval would encapsulate the population mean at that X value 95% of the time NOT: “95% of values fall within these bands” 95% Prediction Interval If you continued sampling into the future, 95% of your values would fall within this interval
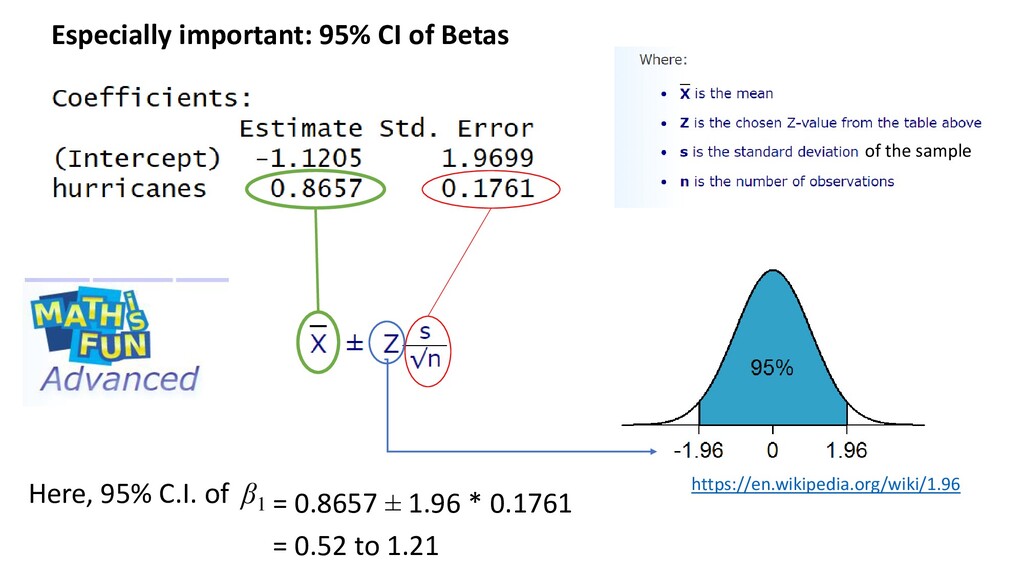
Beta spans zero? Y= βo + β1 *X + error Definition of 95% CI: If you did this experiment an infinite number of times, the population Beta would be encapsulated by the interval 95% of the time In other words, we can’t rule out that the ‘true’ beta value is zero In OTHER words… This variable has no statistically significant effect on Y Y= βo + 0*X + error Y= βo + error
βo + β1 Xi + error • They are used to measure impact on Y by X. The coefficients of most interest are the Beta values • 95% CI tells you where the ‘true’ regression line is likely to fall
from zero?” Larger absolute value of T → Further to the tails on the distribution -> Lower P value This is compared against the T-distribution https://financetrain.com/students-t-distribution/ P < 0.05 = “Reject hypothesis that this parameter’s value is zero”
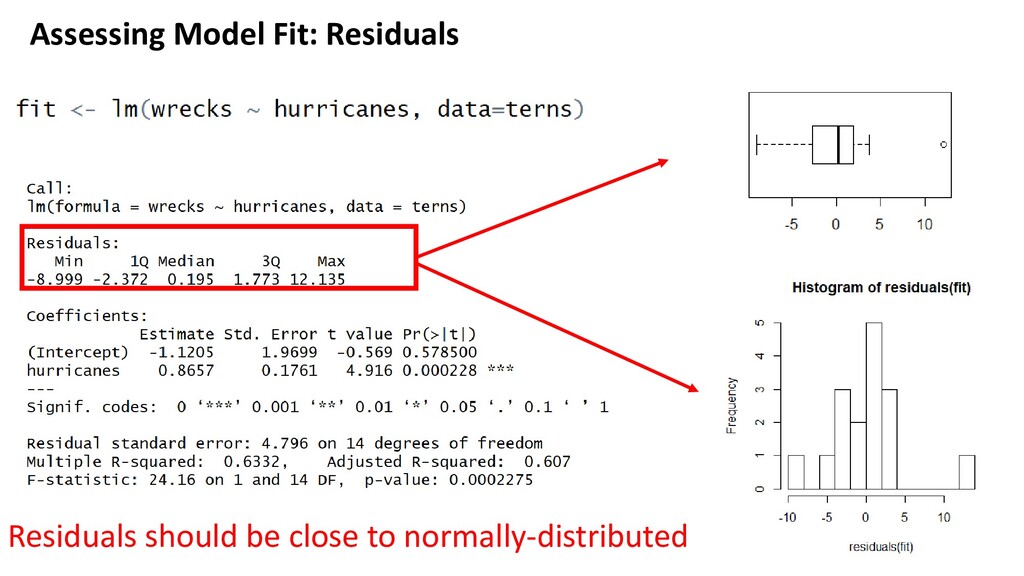
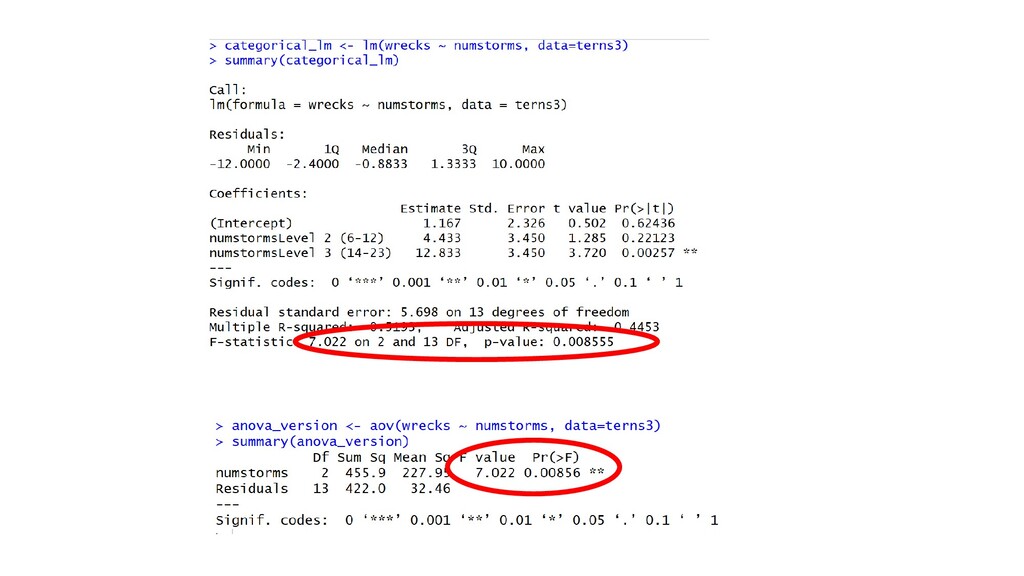
of freedom (df) because... 16 data points 2 coefficients (intercept and slope) So… 16 – 2 = 14 - When R fits a linear regression model, the sum of all residuals adds to zero (intuitively: because there should be as many points “above” line as below, at roughly same overall distance) - Therefore, calculate ‘spread’ of residuals by the following formula:
is same as R2 • A correlation is the strength of a linear association between two variables r r2 Important: r vs. R2 r = 0: no association r = 1: perfect association
X vs Y – correlation is 0.8. Can you say, “X is driving Y?” • Can you infer causality from a regression? • E.g. X vs Y – Beta1 is 0.8, R2 is high. Can you say “X is driving Y?” Key point: Regression doesn’t magically allow you to infer causality on its own. You still have to understand mechanism, design an experiment, rule out other explanations, etc.
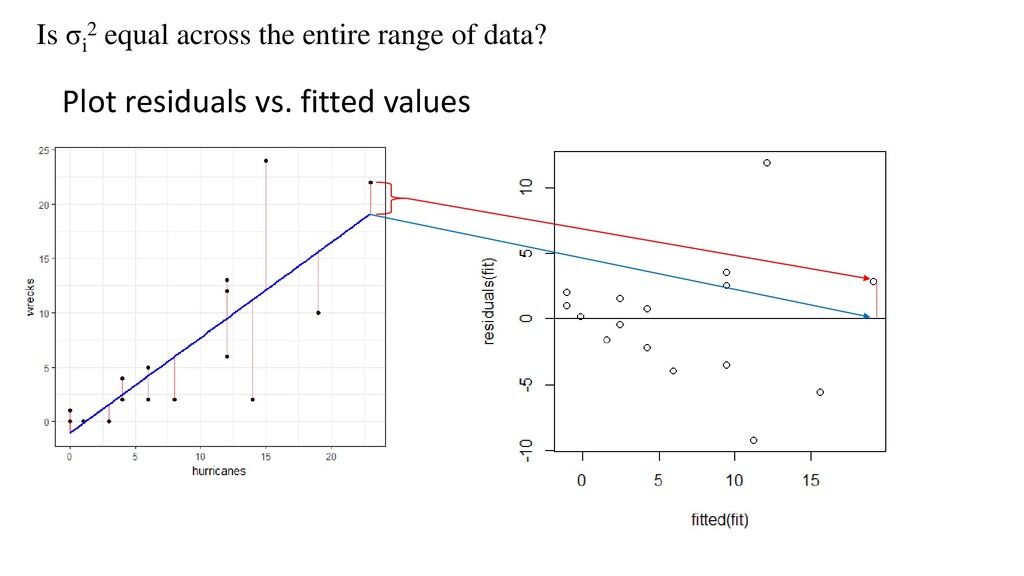
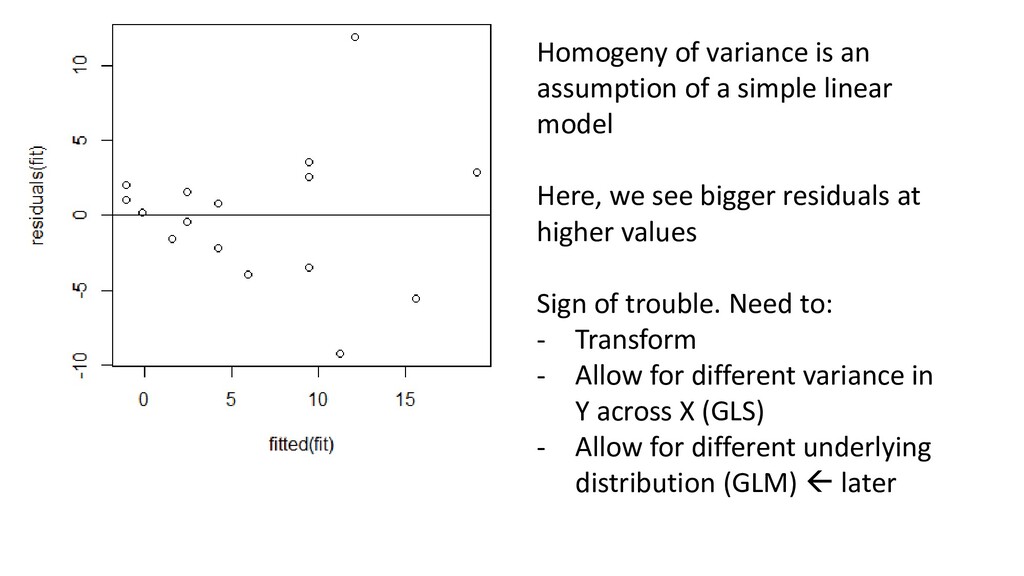
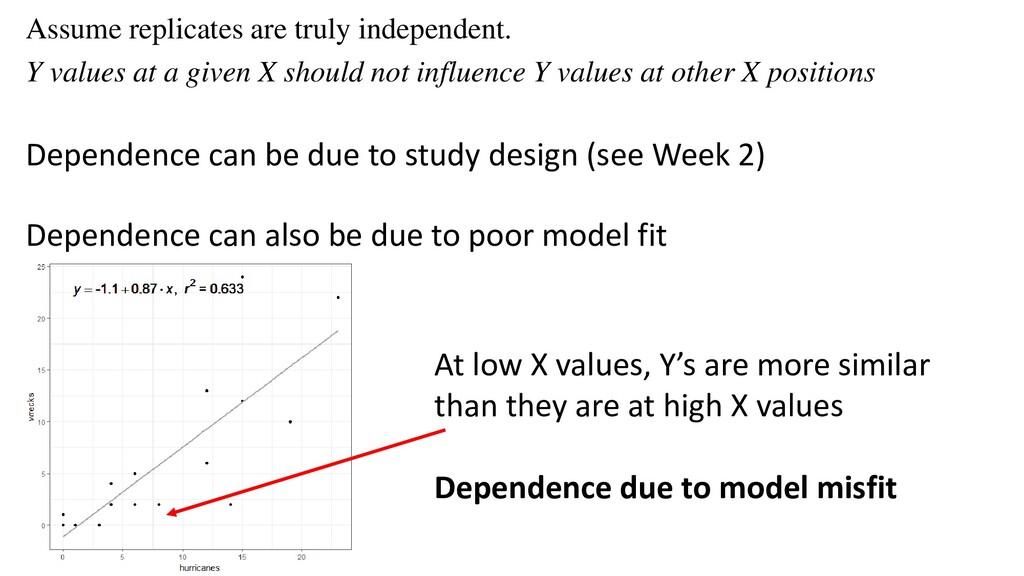
εi Yi = Response Xi = Explanatory variable β0 = Intercept (sometimes denoted α) β = Population slope ε = residual error – information not explained by model AKA “Bivariate linear regression” Assumptions: Assume error (i.e. residuals) is/are normally distributed with mean of zero, variance σi 2 Assume σi 2 is equal across the entire range of data Assume replicates are truly independent. Y values at a given X should not influence Y values at other X positions Assume fixed X εi ~ N(0, σi 2)
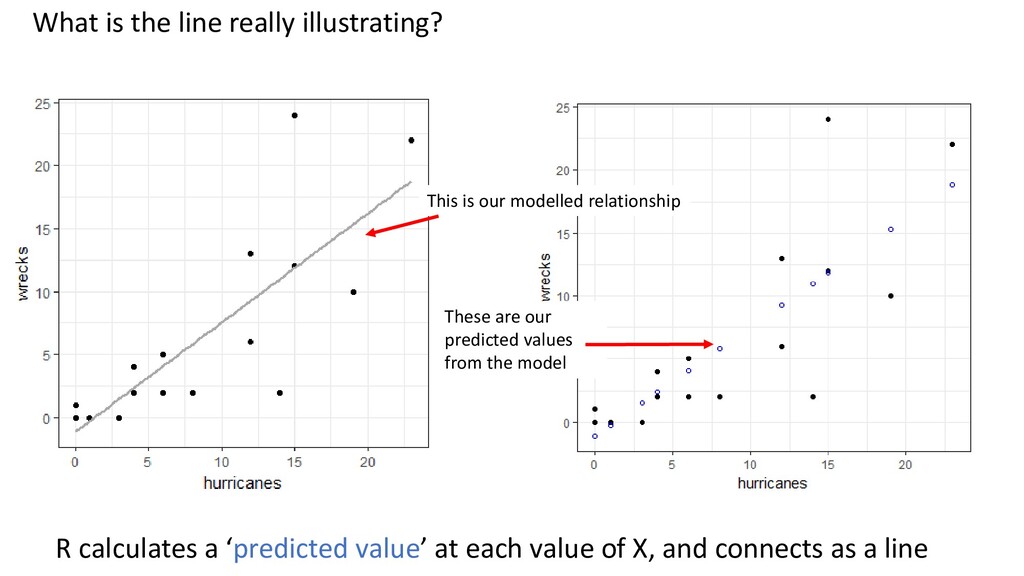
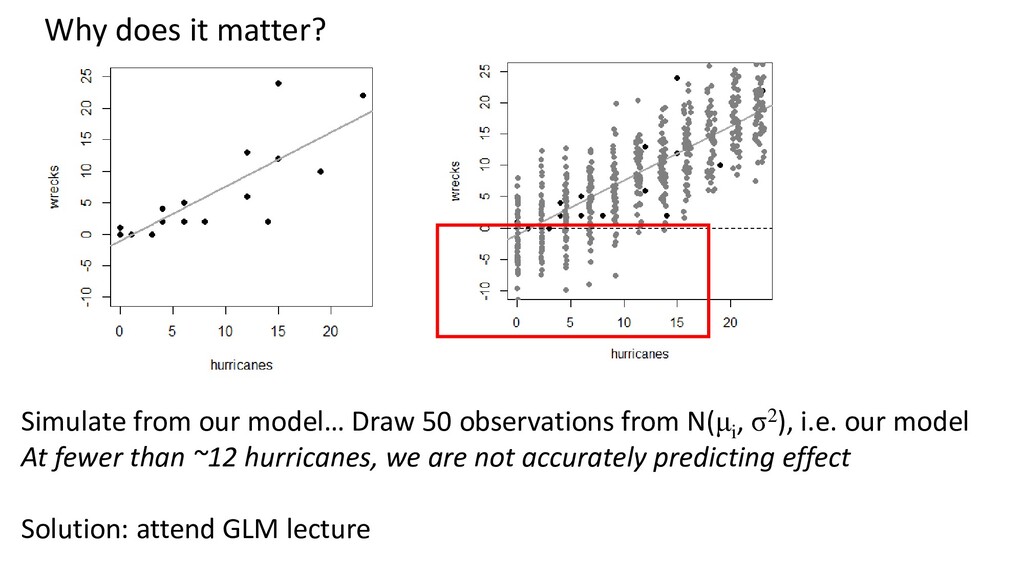
model Here, we see bigger residuals at higher values Sign of trouble. Need to: - Transform - Allow for different variance in Y across X (GLS) - Allow for different underlying distribution (GLM) later
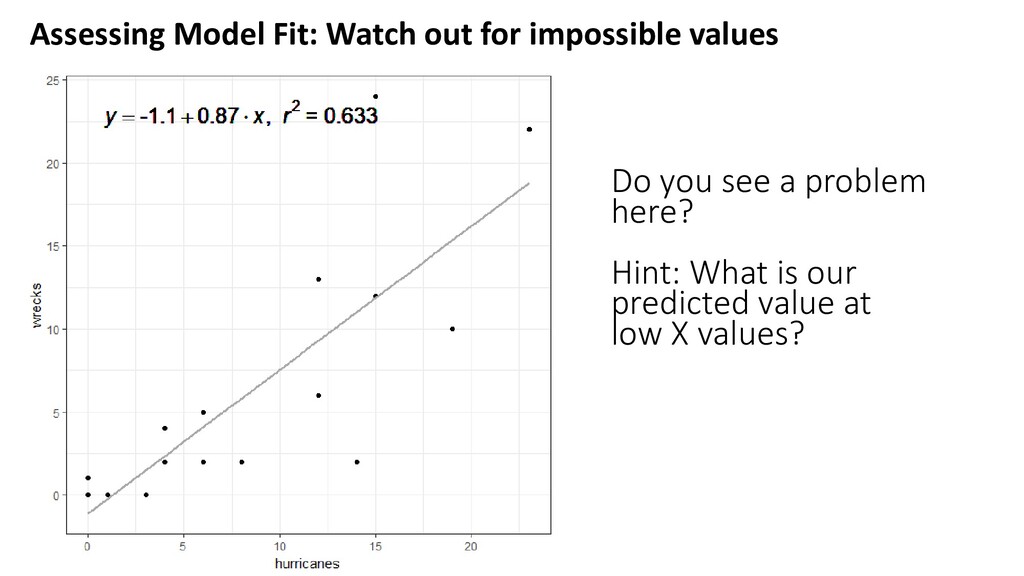
X should not influence Y values at other X positions Dependence can be due to study design (see Week 2) Dependence can also be due to poor model fit At low X values, Y’s are more similar than they are at high X values Dependence due to model misfit
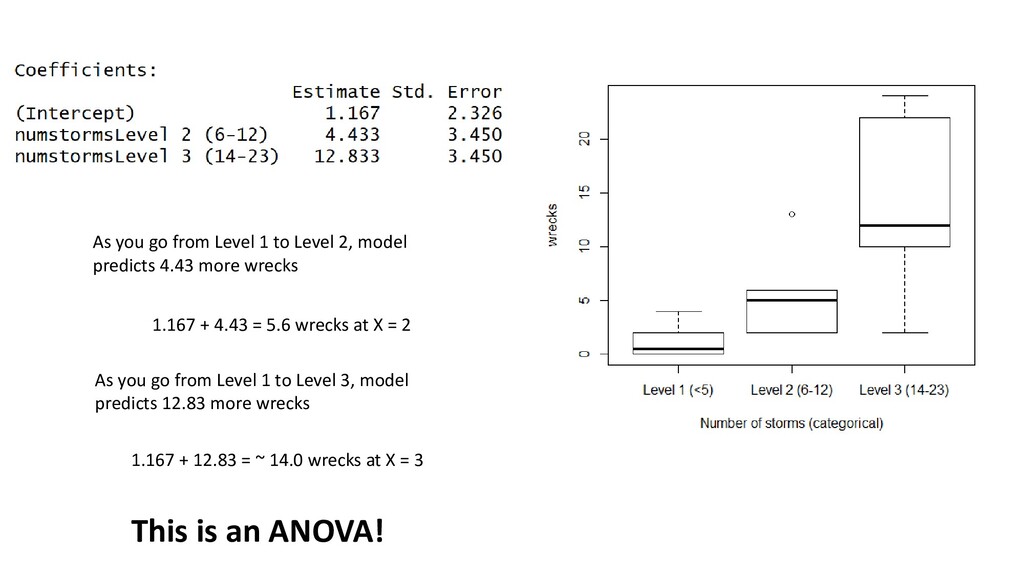
predicts 4.43 more wrecks 1.167 + 4.43 = 5.6 wrecks at X = 2 As you go from Level 1 to Level 3, model predicts 12.83 more wrecks 1.167 + 12.83 = ~ 14.0 wrecks at X = 3 This is an ANOVA!
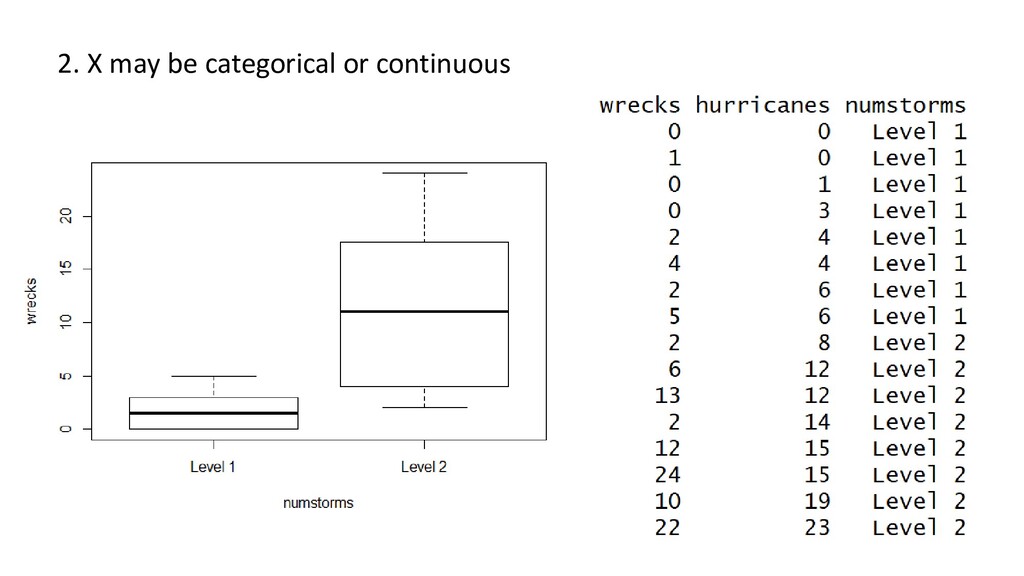
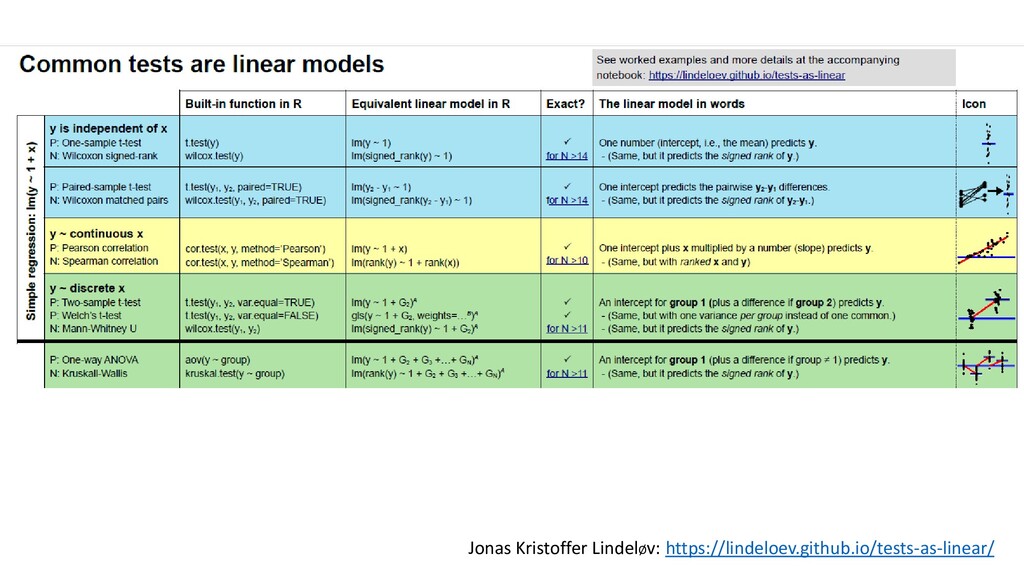
= mx + B • …but expressed as: • X can be continuous or categorical • Models approximate reality. Simple linear models only do that when: • X is fixed • When error is normally distributed with mean of zero, variance sigma squared • When sigma squared is equal across entire range of data • When replicates are truly independent • We outlined graphical tools to look at these. There will be more. • Now: What do you write in a paper? Y= βo + β1 *X + error
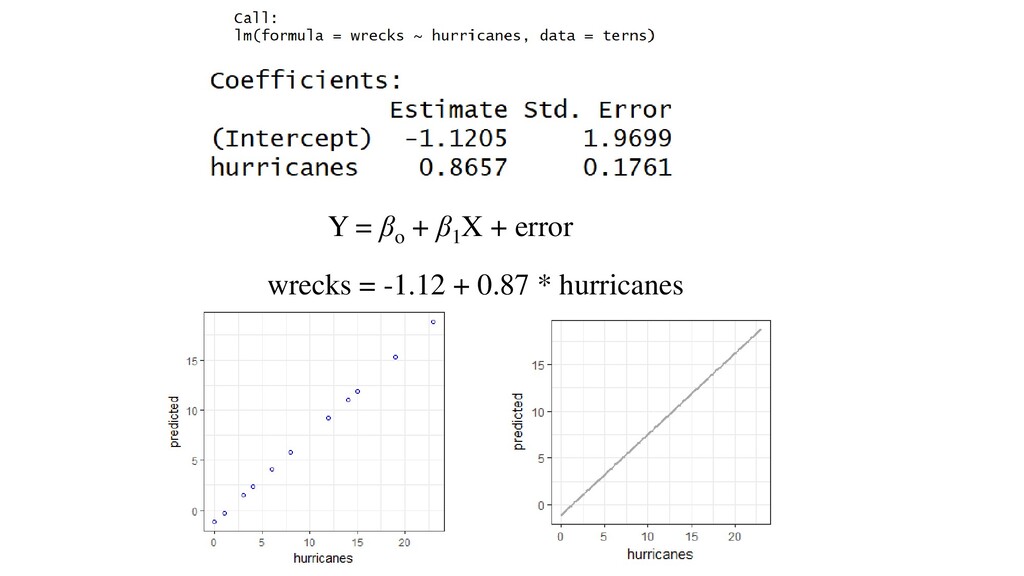
given X position (denoted by i), we expect wrecksi to be Normally Distribution with a mean of μ (the population mean – the “true value” at that X position), and variance σ2 wrecksi ~ N(μi , σ2) E(wrecksi ) = μi Var(wrecksi ) = σ2 wrecksi = β0 + β1 hurricanesi Write out the model For this to work it must be true that: σ1 2 = σ2 2 = σ3 2 = … σi 2 When error is zero, it is equal to μi – the unknowable population mean We specify that the error is normally distributed with variance σ2
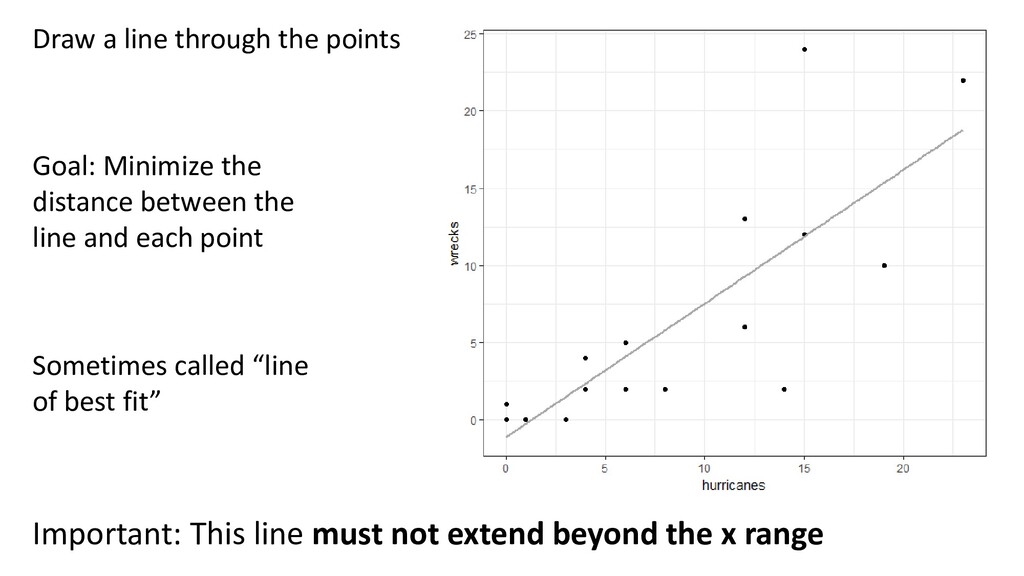
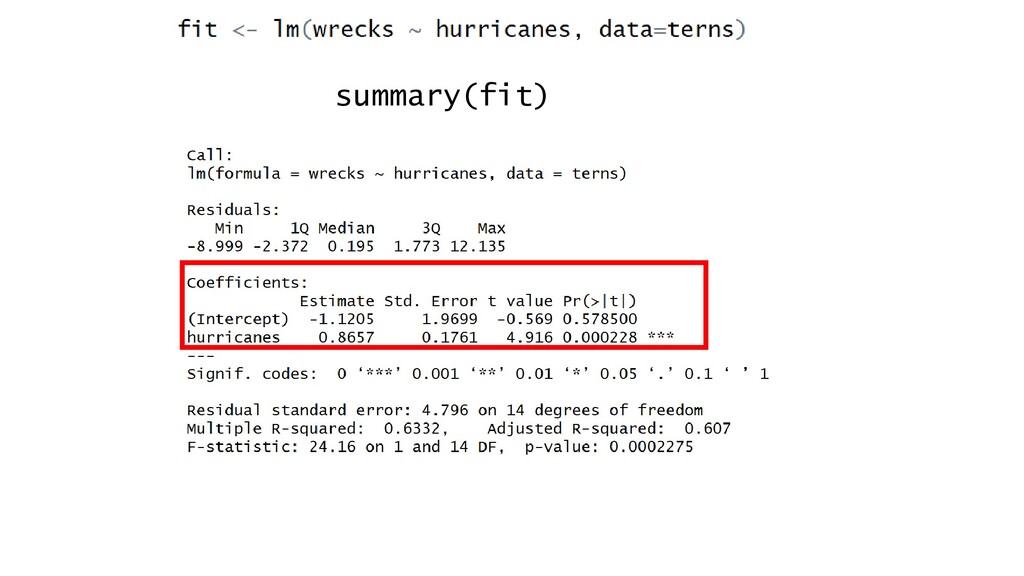
+ εi wrecksi ~ N(μi , σ2) E(wrecksi ) = μi Var(wrecksi ) = σ2 wrecksi = β0 + β1 hurricanesi Two ways to say the same thing: From: Zuur et al (2016) Methods: “We performed a bivariate linear regression of the number of wrecks in a two-week period against the number of hurricanes in a given two-week period (eqn 1).” “We verified model assumptions by plotting residuals versus fitted values” (Eqn 1)
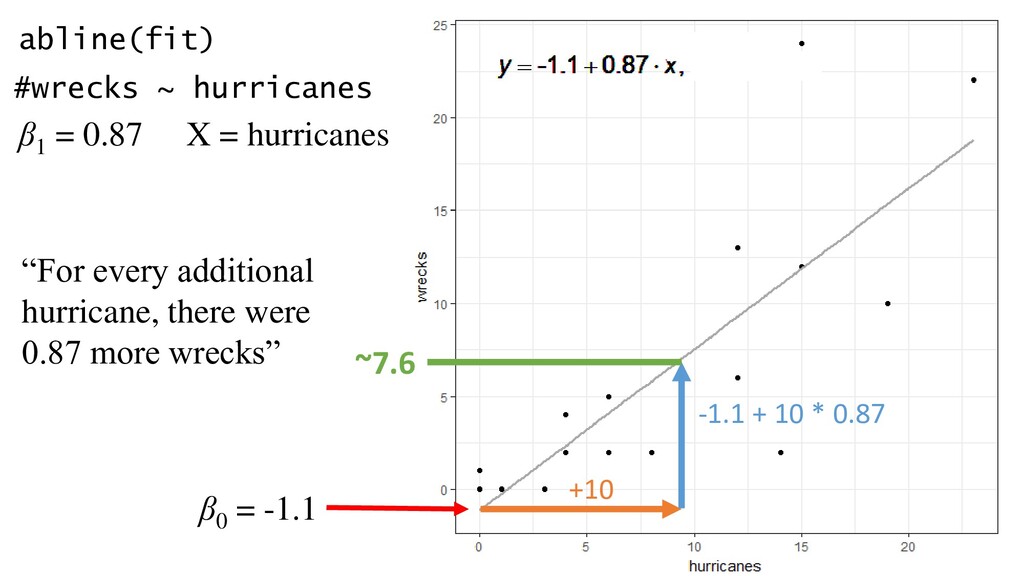
model presented in eqn 1 Estimate Std. error T-value P-value Intercept -1.12 1.97 -0.569 0.579 Hurricanes 0.866 0.176 0.492 <0.001 And say it in words, in Results: “For every additional hurricane, there were between 0.52 and 1.21 additional wrecked birds (95% C.I. = 0.87)” Note P-values are not necessary in text. If CI spans zero, no effect (Halsey et al. 2015) Then… β1
regression model of wrecks versus hurricanes (eqn 1). Black dots are independent observations, and the blue line indicates predicted model. The grey shading indicates 95% C.I.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}