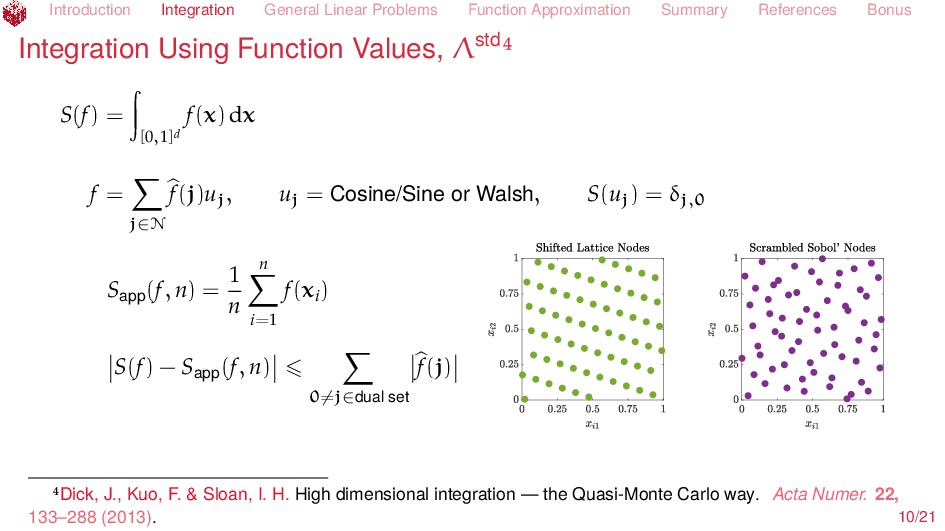
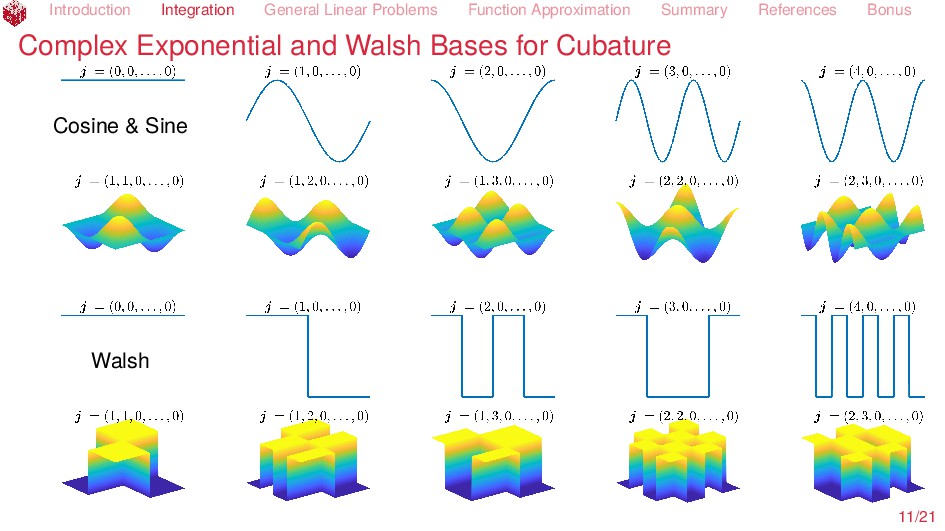
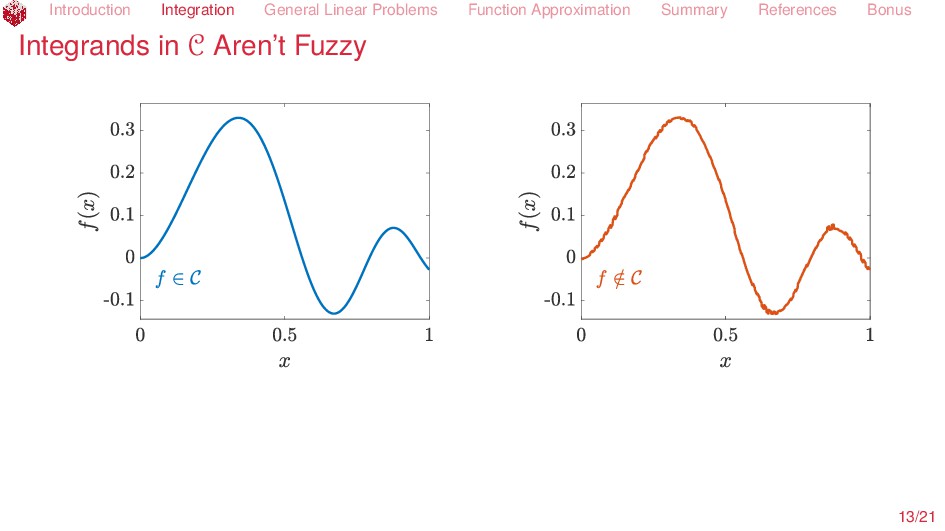
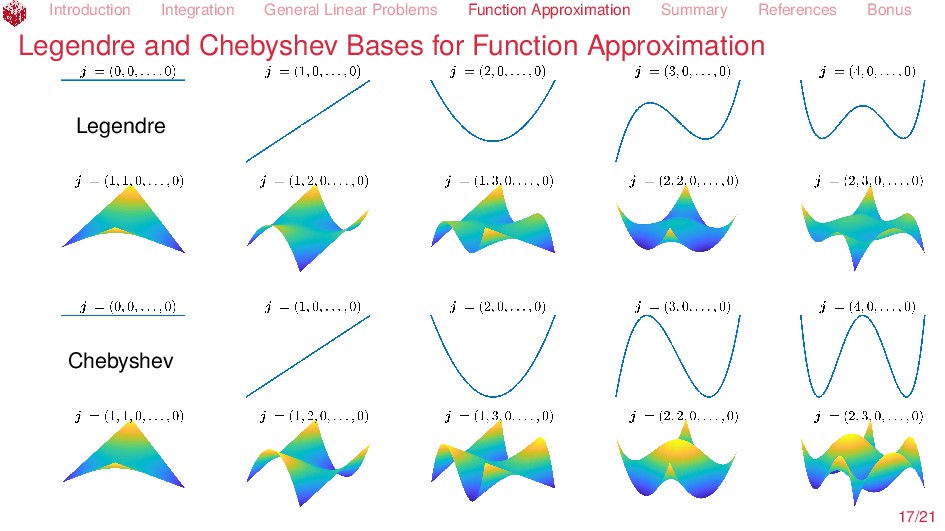
Issues Given f ∈ F find S(f) ∈ G, where S : F → G is linear Successful algorithms A(C, Λ) := {A : C×(0, ∞) → G such that S(f) − A(f, ε) G ε ∀f ∈ C ⊆ F, ε > 0} where A(f, ε) depends on function values, Λstd, Fourier coefficients, Λser, or any linear functionals, Λall Solvability : A(C, Λ) = ∅ Construction: Find A ∈ A(C, Λ) Cost: cost(A, f, ε) = # of function data cost(A, C, ε, ρ) = max f∈C∩Bρ cost(A, f, ε) Bρ := {f ∈ F : f F ρ} Complexity : comp(A(C, Λ), ε, ρ) = min A∈A(C,Λ) cost(A, C, ε, ρ) Optimality: cost(A, C, ε, ρ) comp(A(C, Λ), ωε, ρ) Tractability : comp(A(C, Λ), ε, ρ) Cρpε−pdq Implementation in open source software Kunsch, R. J., Novak, E. & Rudolf, D. Solvable Integration Problems and Optimal Sample Size Selection. Journal of Complexity. To appear (2018). Traub, J. F., Wasilkowski, G. W. & Woźniakowski, H. Information-Based Complexity. (Academic Press, Boston, 1988). Novak, E. & Woźniakowski, H. Tractability of Multivariate Problems Volume I: Linear Information. EMS Tracts in Mathematics 6 (European Mathematical Society, Zürich, 2008). 5/21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}