Acquiring large datasets is quite simple these days on the internet, but data is often noisy and most of the value often lies in combining, connecting and merging multiple datasets from different sources.
This talk gives an overview of Probabilistic Record Matching, i.e. the challenges posed when dealing with noisy data, how to normalize data and how to match noisy records to each other.
The goal of the presentation is to give participants an understanding of the possibilities and challenges of merging datasets, as well as mention some of the amazing python libraries available.
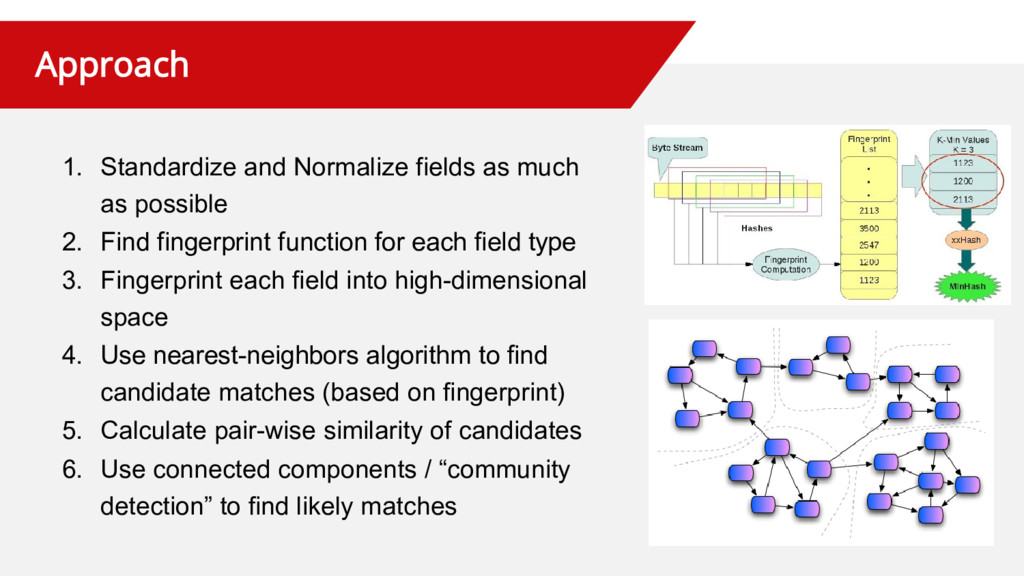
Topics discussed: normalization of attributes, approximate string matching, performance, similarity clustering
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You [email protected]](https://files.speakerdeck.com/presentations/274bd56875ca444d8e4ea25166b5ddf6/slide_11.jpg){kind=link}