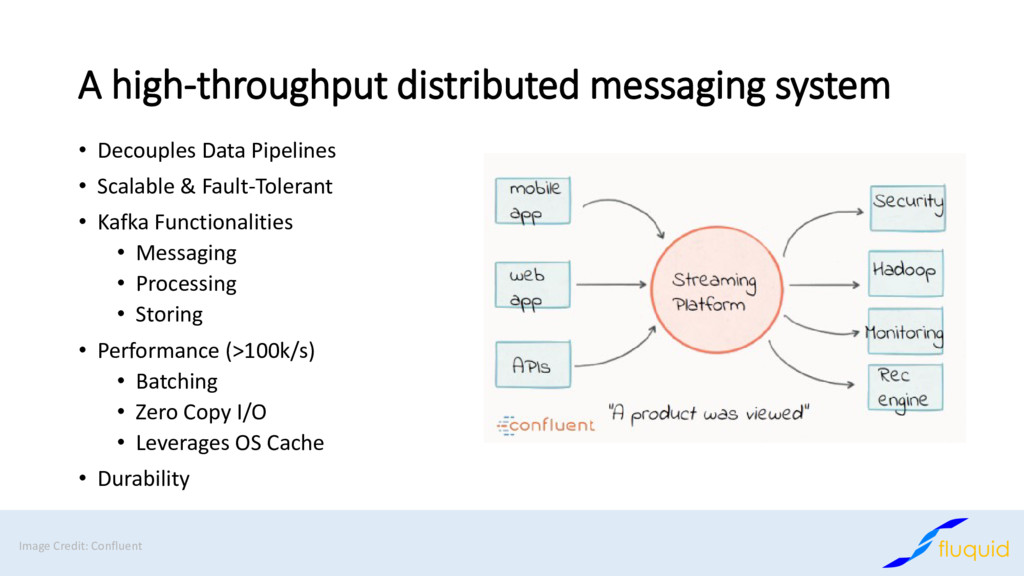
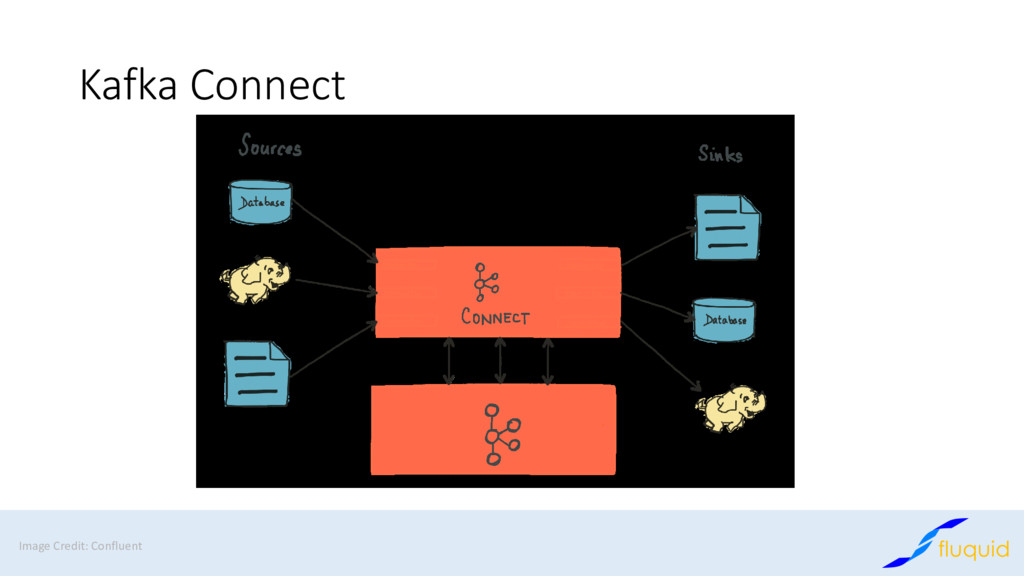
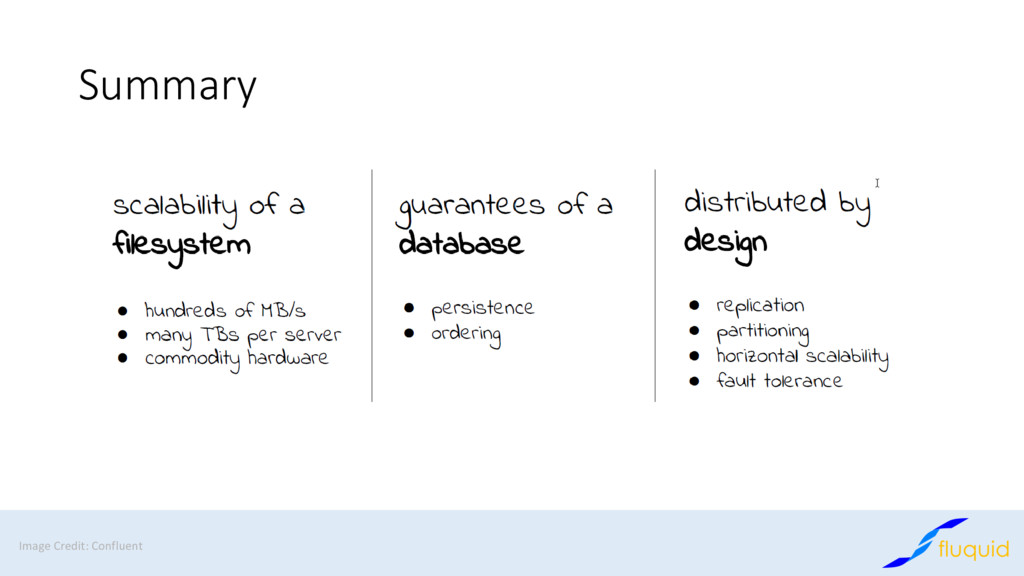
Apache Kafka has become the de-facto standard for distributed message passing, processing and storage of data. At Fluquid we are using Kafka for decoupling and connecting multiple applications asynchronously and for storing data in the context of web crawling and big data processing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}