You have heard the hype about Apache Spark using Python, and would like to learn more?
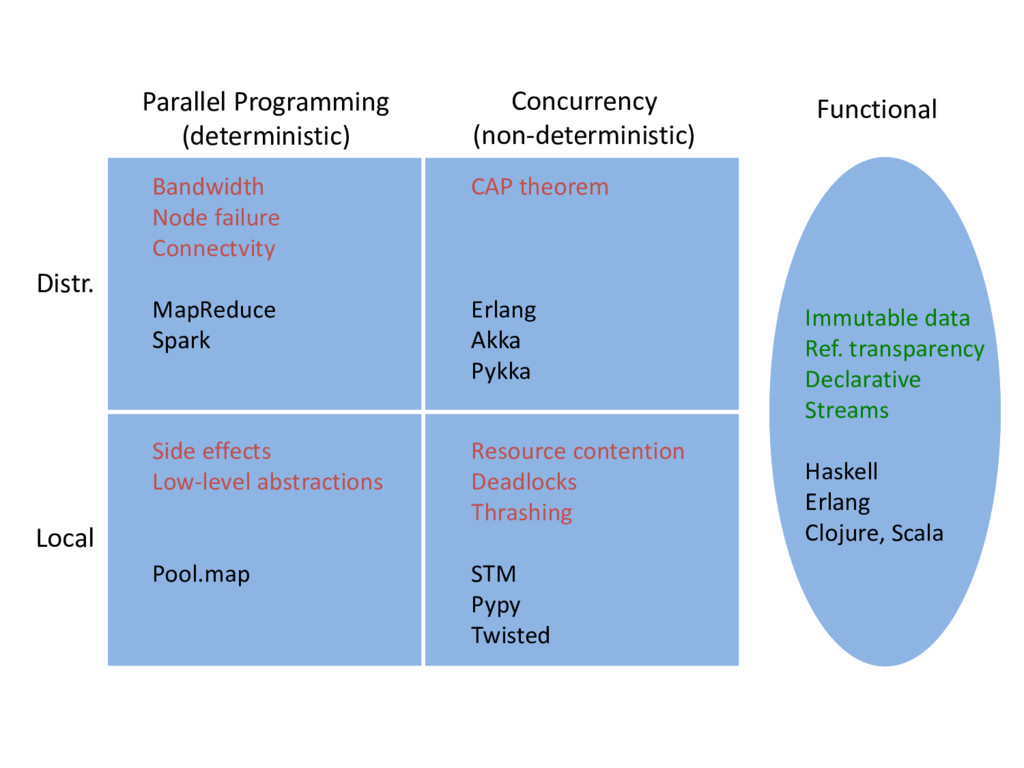
Distributed Computing is becoming more and more prevalent with the rise of big data, multicore processors and scale-out architecture.
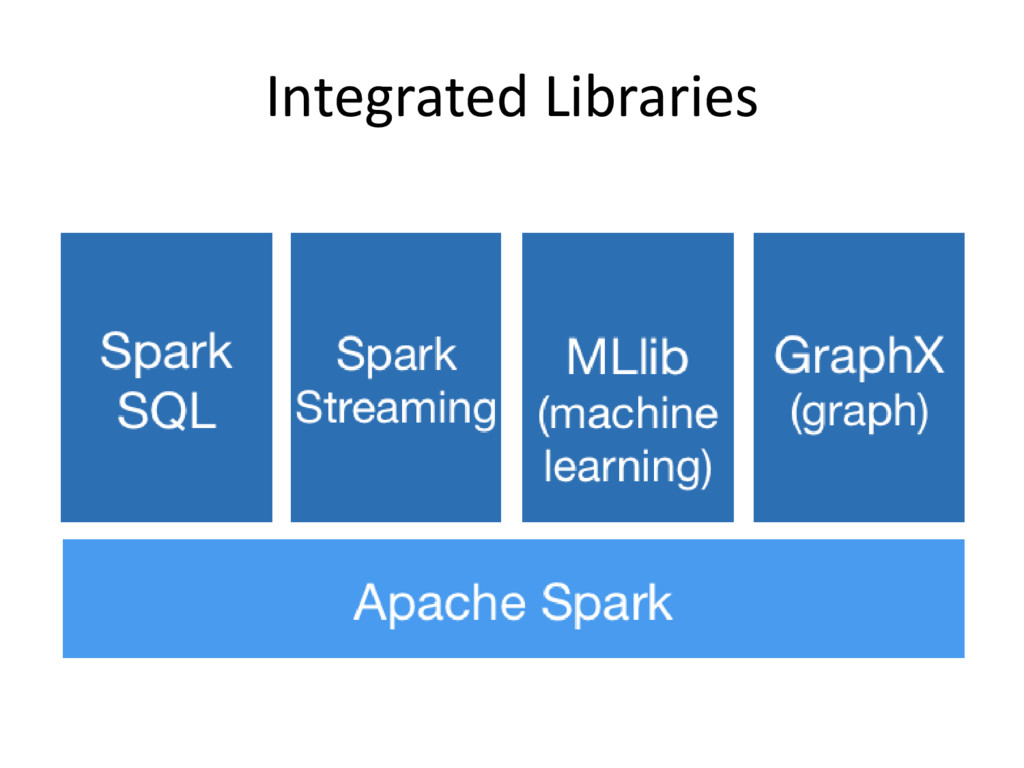
This talk will give an introduction to Parallel Programming using Apache Spark and Python, how you can leverage it in you day-to-day programming, and the core Functional Principles that are making it scale.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Immutable State append([1, 2, 3], 4) => [1, 2, 3,](https://files.speakerdeck.com/presentations/9e03043fb8ba4478b347ac361e7dfb82/slide_14.jpg){kind=link}
![Streams (Generators, Iterators) xs = [1, 2, 3]; return xs.map(x](https://files.speakerdeck.com/presentations/9e03043fb8ba4478b347ac361e7dfb82/slide_15.jpg){kind=link}
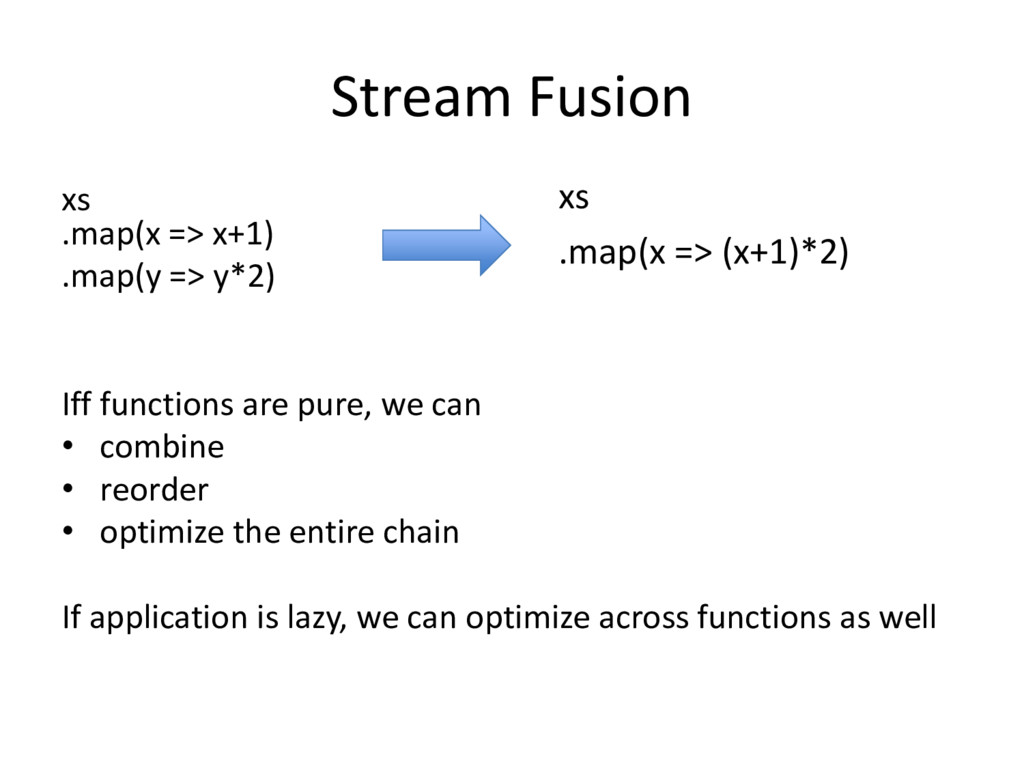{kind=link}