The internet contains many open and openly-available datasets that can be used to gather intelligence on people and organizations. This talk will outline possible approaches to gathering such intelligence:…
- what is a company working on through employee's github accounts
- track when a company's website or web stack changes
- build a profile of target persons from public activity (blog posts, forum posts, etc.) for targeted communication like for spear fishing
{kind=link}
{kind=link}
{kind=link}
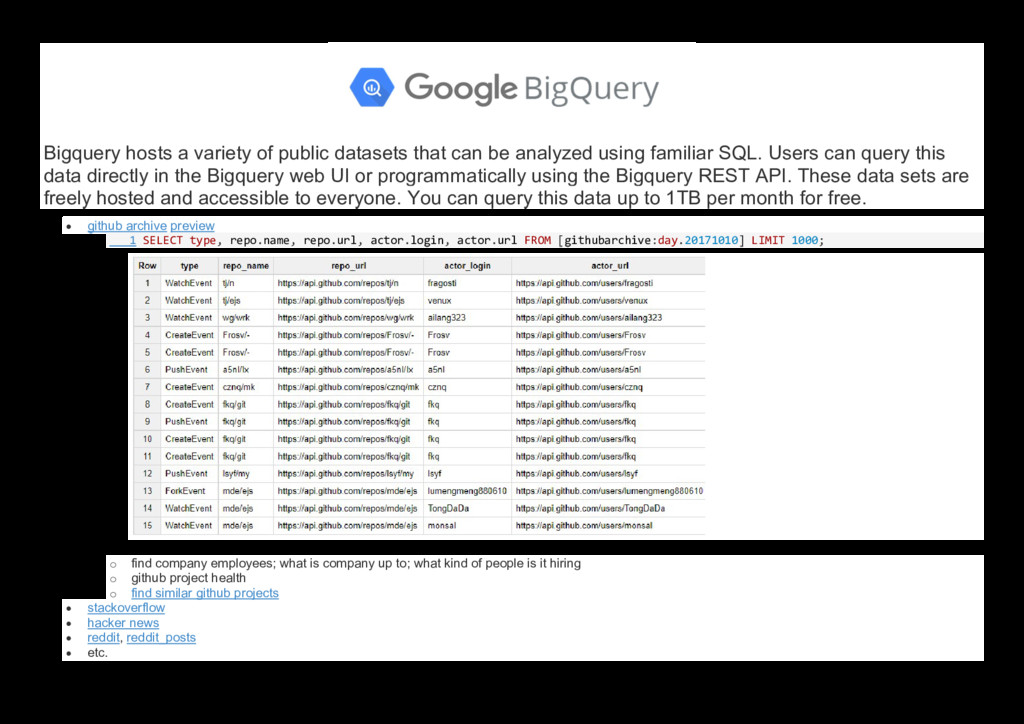{kind=link}
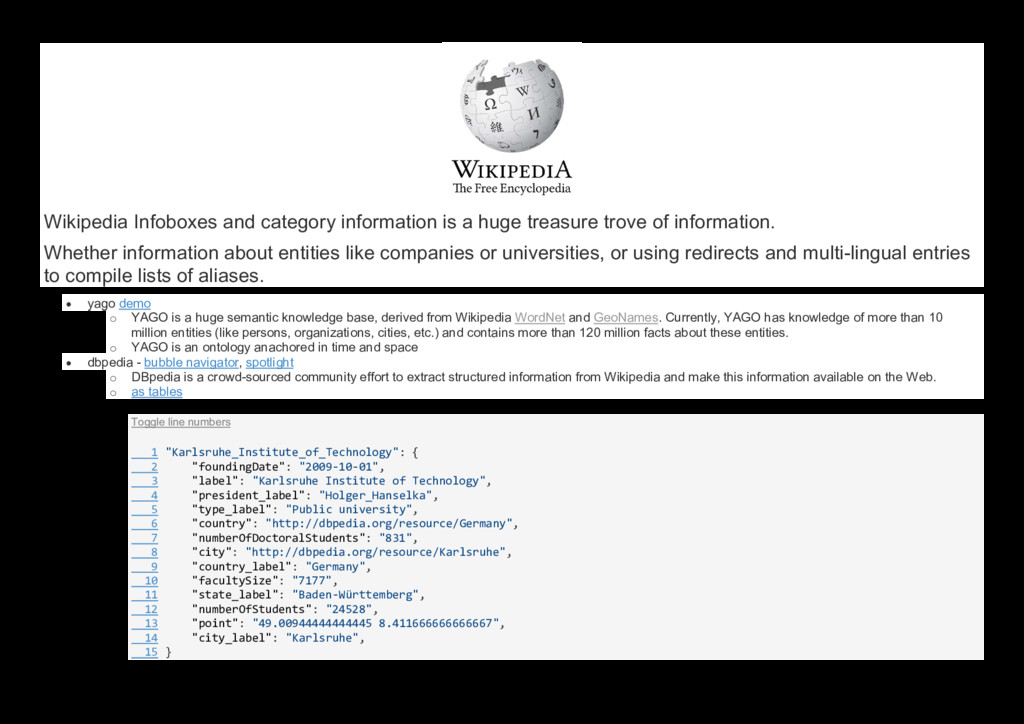{kind=link}
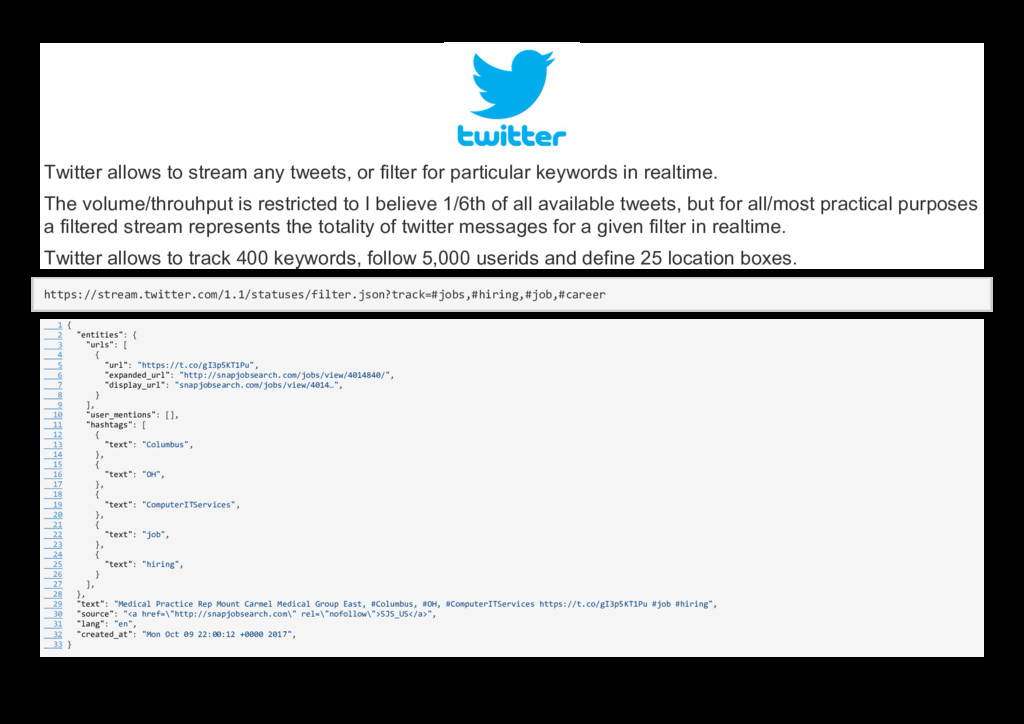{kind=link}
{kind=link}
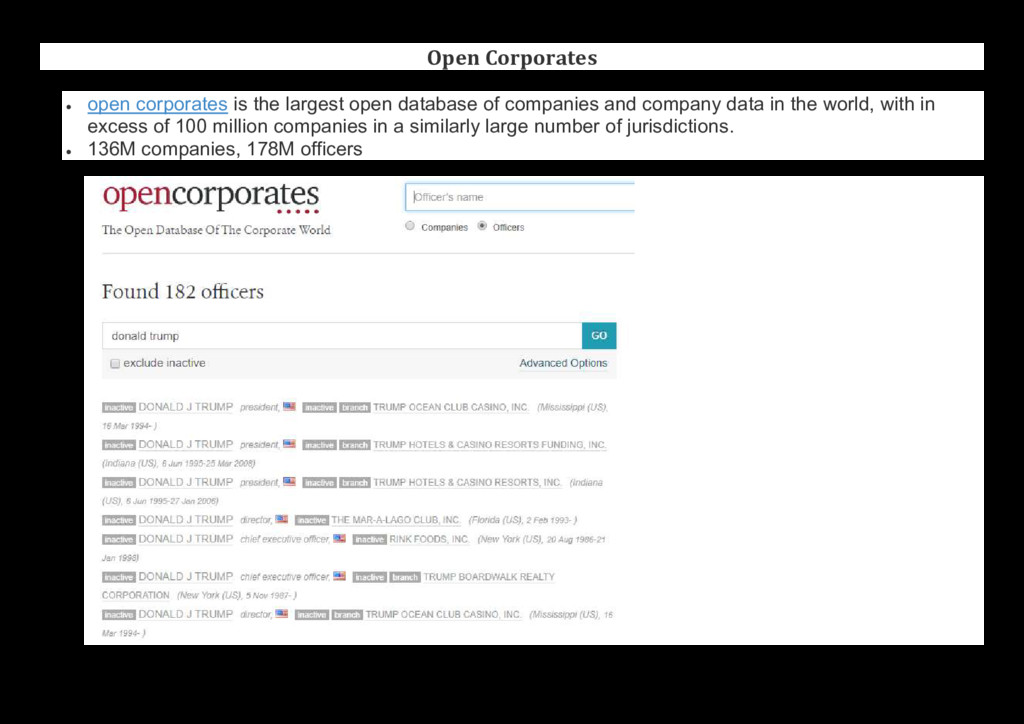{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}