Gregory Ditzler The University of Arizona Department of Electrical & Computer Engineering [email protected] http://www2.engr.arizona.edu/˜ditzler 25 August 2016 IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
multiple experts 2 Using SML to estimate voting weights 3 Simulations & real-world data streams 4 Conclusions & discussion Dow Jones Industrial Average index with the 30 companies associated with the index 1993 1998 2004 2009 0 50 100 150 200 250 IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
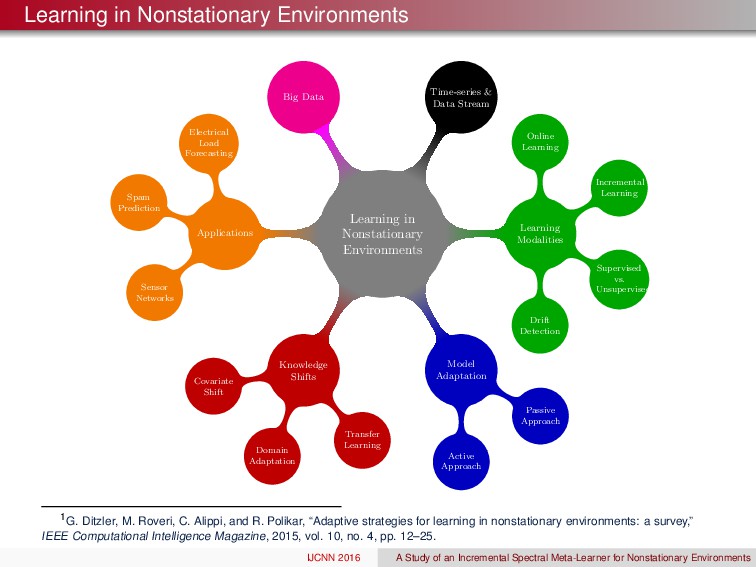
Online Learning Incremental Learning Supervised vs. Unsupervised Drift Detection Model Adaptation Passive Approach Active Approach Knowledge Shifts Transfer Learning Domain Adaptation Covariate Shift Applications Sensor Networks Spam Prediction Electrical Load Forecasting Big Data Time-series & Data Stream 1G. Ditzler, M. Roveri, C. Alippi, and R. Polikar, “Adaptive strategies for learning in nonstationary environments: a survey,” IEEE Computational Intelligence Magazine , 2015, vol. 10, no. 4, pp. 12–25. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
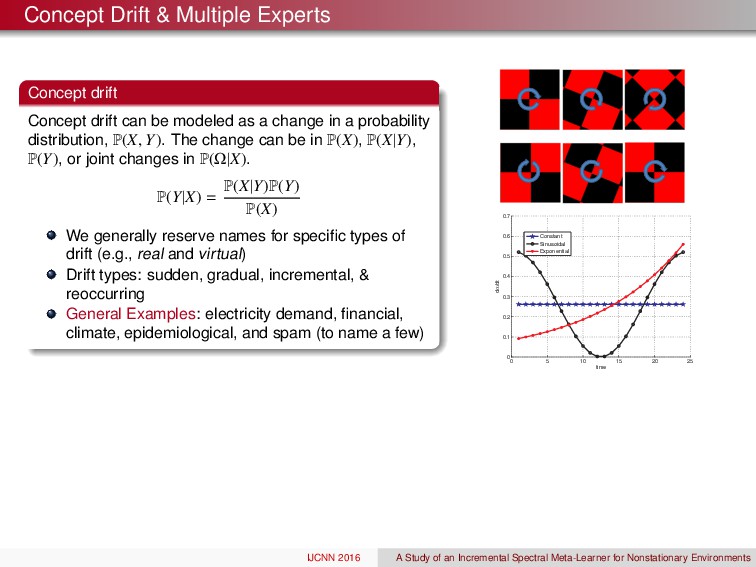
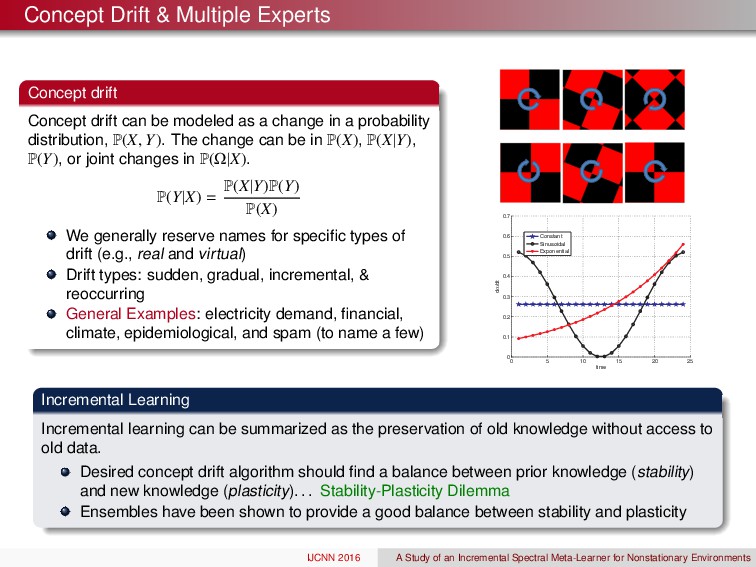
be modeled as a change in a probability distribution, P ( X, Y ) . The change can be in P ( X ) , P ( X|Y ) , P ( Y ) , or joint changes in P ( ⌦|X ) . P ( Y|X ) = P ( X|Y ) P ( Y ) P ( X ) We generally reserve names for specific types of drift (e.g., real and virtual ) Drift types: sudden, gradual, incremental, & reoccurring General Examples: electricity demand, financial, climate, epidemiological, and spam (to name a few) 0 5 10 15 20 25 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 dα/dt time Constant Sinusoidal Exponential IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
be modeled as a change in a probability distribution, P ( X, Y ) . The change can be in P ( X ) , P ( X|Y ) , P ( Y ) , or joint changes in P ( ⌦|X ) . P ( Y|X ) = P ( X|Y ) P ( Y ) P ( X ) We generally reserve names for specific types of drift (e.g., real and virtual ) Drift types: sudden, gradual, incremental, & reoccurring General Examples: electricity demand, financial, climate, epidemiological, and spam (to name a few) 0 5 10 15 20 25 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 dα/dt time Constant Sinusoidal Exponential Incremental Learning Incremental learning can be summarized as the preservation of old knowledge without access to old data. Desired concept drift algorithm should find a balance between prior knowledge ( stability ) and new knowledge ( plasticity ). . . Stability-Plasticity Dilemma Ensembles have been shown to provide a good balance between stability and plasticity IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
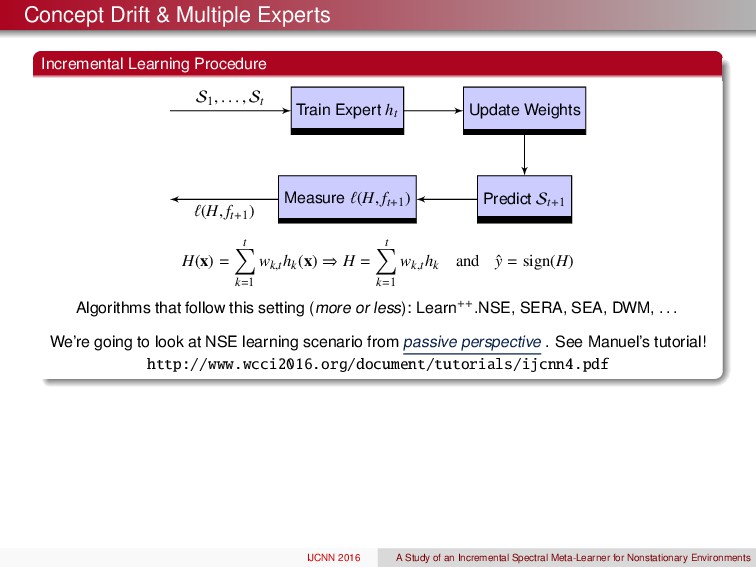
ht Update Weights Predict St+ 1 Measure ` ( H, ft+ 1) S 1 , . . . , St ` ( H, ft+ 1) H ( x ) = t X k= 1 wk,t hk ( x ) ) H = t X k= 1 wk,t hk and ˆ y = sign( H ) Algorithms that follow this setting ( more or less ): Learn++.NSE, SERA, SEA, DWM, . . . We’re going to look at NSE learning scenario from passive perspective . See Manuel’s tutorial! http://www.wcci2016.org/document/tutorials/ijcnn4.pdf IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
ht Update Weights Predict St+ 1 Measure ` ( H, ft+ 1) S 1 , . . . , St ` ( H, ft+ 1) H ( x ) = t X k= 1 wk,t hk ( x ) ) H = t X k= 1 wk,t hk and ˆ y = sign( H ) Algorithms that follow this setting ( more or less ): Learn++.NSE, SERA, SEA, DWM, . . . We’re going to look at NSE learning scenario from passive perspective . See Manuel’s tutorial! http://www.wcci2016.org/document/tutorials/ijcnn4.pdf The twist!: Concept Drift Concept drift is characterized by changes in ft (i.e., the oracle) or change in the distribution on x Old experts/classifiers/hypotheses have varying degrees of relevancy at time t. How should we combine the experts? Loss t+ 1( H ) some interpretable quantity IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
for a classifier in an ensemble is typically of the form wk = log 1 ✏k ✏k where ✏k is some expected measure of loss for the kth classifier. How do the expert weights affect the loss when being tested on an unknown distribution? 1G. Ditzler, G. Rosen, and R. Polikar, “Domain adaptation bounds for multiple expert systems under concept drift,” in International Joint Conference on Neural Networks, 2014. (Best Student Paper). IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
for a classifier in an ensemble is typically of the form wk = log 1 ✏k ✏k where ✏k is some expected measure of loss for the kth classifier. How do the expert weights affect the loss when being tested on an unknown distribution? Using Domain Adaptation to Clarify the Bound Combining the works by Ben-David et al. (2010) and Ditzler et al. (2014) gives us: ET ⇥` ( H, fT ) ⇤ t X k= 1 wk,t ✓Ek ⇥` ( hk, fk ) ⇤ + T,k + 1 2 ˆ d H H ( UT , Uk ) + O 0 B B B B B @ r⌫ log m m 1 C C C C C A ◆ where T,k is a measure of disagreement between fk and fT ( a bit unfortunate) 1G. Ditzler, G. Rosen, and R. Polikar, “Domain adaptation bounds for multiple expert systems under concept drift,” in International Joint Conference on Neural Networks, 2014. (Best Student Paper). IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
for a classifier in an ensemble is typically of the form wk = log 1 ✏k ✏k where ✏k is some expected measure of loss for the kth classifier. How do the expert weights affect the loss when being tested on an unknown distribution? Using Domain Adaptation to Clarify the Bound Combining the works by Ben-David et al. (2010) and Ditzler et al. (2014) gives us: ET ⇥` ( H, fT ) ⇤ t X k= 1 wk,t ✓Ek ⇥` ( hk, fk ) ⇤ + T,k + 1 2 ˆ d H H ( UT , Uk ) + O 0 B B B B B @ r⌫ log m m 1 C C C C C A ◆ where T,k is a measure of disagreement between fk and fT ( a bit unfortunate) Weighted sum of: training loss + disagreement of fk and fT + divergence of Dk and DT T,k encapsulates real-drift , where are as ˆ d H H is virtual drift. More over, existing algorithms using the loss on the most recent labelled distribution are missing out on the other changes that could occur. 1G. Ditzler, G. Rosen, and R. Polikar, “Domain adaptation bounds for multiple expert systems under concept drift,” in International Joint Conference on Neural Networks, 2014. (Best Student Paper). IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
weights if we do not assume something about the nature of the drift is a very difficult problem. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
weights if we do not assume something about the nature of the drift is a very difficult problem. The limited drift assumption! IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
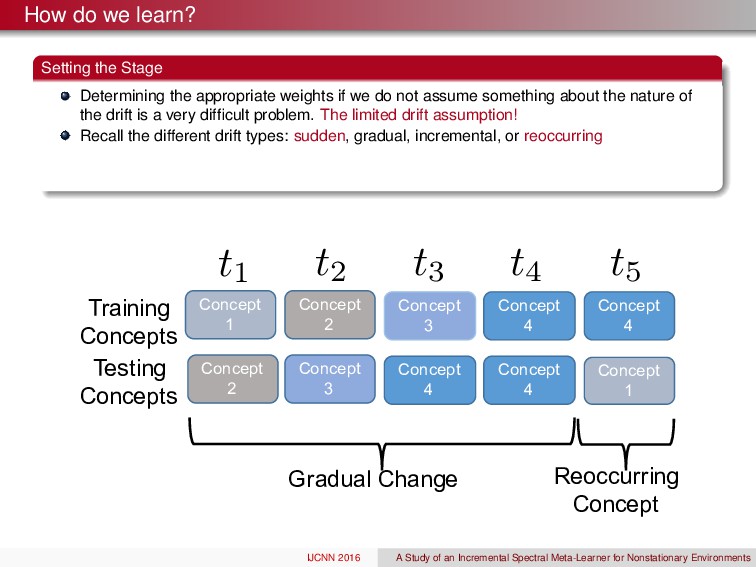
weights if we do not assume something about the nature of the drift is a very difficult problem. The limited drift assumption! Recall the different drift types: sudden, gradual, incremental, or reoccurring IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
weights if we do not assume something about the nature of the drift is a very difficult problem. The limited drift assumption! Recall the different drift types: sudden, gradual, incremental, or reoccurring IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
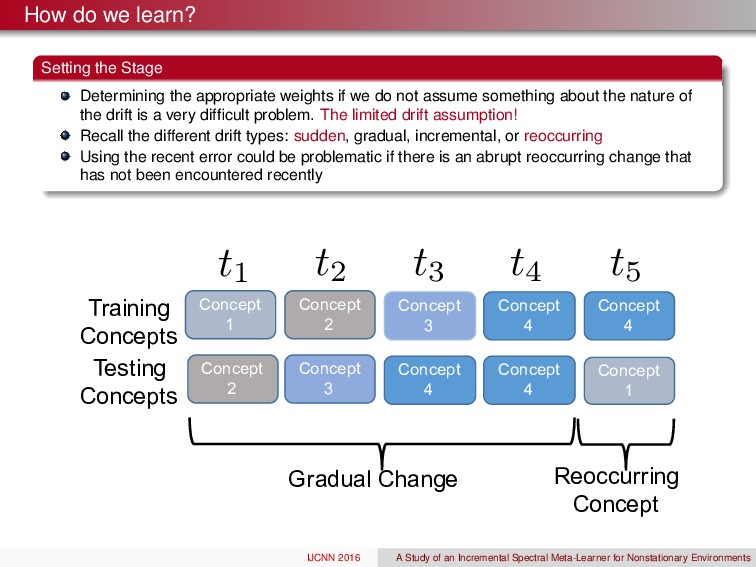
weights if we do not assume something about the nature of the drift is a very difficult problem. The limited drift assumption! Recall the different drift types: sudden, gradual, incremental, or reoccurring Concept 1 Concept 2 Concept 3 Concept 4 Concept 2 Concept 3 Concept 4 Concept 4 Training Concepts Testing Concepts Concept 1 Concept 4 Gradual6Change Reoccurring Concept t1 t2 t3 t4 t5 IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
weights if we do not assume something about the nature of the drift is a very difficult problem. The limited drift assumption! Recall the different drift types: sudden, gradual, incremental, or reoccurring Using the recent error could be problematic if there is an abrupt reoccurring change that has not been encountered recently Concept 1 Concept 2 Concept 3 Concept 4 Concept 2 Concept 3 Concept 4 Concept 4 Training Concepts Testing Concepts Concept 1 Concept 4 Gradual6Change Reoccurring Concept t1 t2 t3 t4 t5 IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
provides an approach to rank classifiers on data. 1F. Parisi, F. Strino, B. Nadler, and Y. Kluger, “Ranking and combining multiple predictors without labeled data,” Proceedings of the National Academy of Sciences, vol. 111, no. 4, pp. 1253?1258, 2014. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
provides an approach to rank classifiers on data. SML assumes there are k binary classifiers of unknown reliability (but, better than chance), each providing predicted class labels on unlabeled data. SML can rank the the classifiers based on their accuracy if: 1F. Parisi, F. Strino, B. Nadler, and Y. Kluger, “Ranking and combining multiple predictors without labeled data,” Proceedings of the National Academy of Sciences, vol. 111, no. 4, pp. 1253?1258, 2014. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
provides an approach to rank classifiers on data. SML assumes there are k binary classifiers of unknown reliability (but, better than chance), each providing predicted class labels on unlabeled data. SML can rank the the classifiers based on their accuracy if: The evaluation set are sampled i.i.d. from DT . 1F. Parisi, F. Strino, B. Nadler, and Y. Kluger, “Ranking and combining multiple predictors without labeled data,” Proceedings of the National Academy of Sciences, vol. 111, no. 4, pp. 1253?1258, 2014. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
provides an approach to rank classifiers on data. SML assumes there are k binary classifiers of unknown reliability (but, better than chance), each providing predicted class labels on unlabeled data. SML can rank the the classifiers based on their accuracy if: The evaluation set are sampled i.i.d. from DT . The classifiers are conditionally independent 1F. Parisi, F. Strino, B. Nadler, and Y. Kluger, “Ranking and combining multiple predictors without labeled data,” Proceedings of the National Academy of Sciences, vol. 111, no. 4, pp. 1253?1258, 2014. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
provides an approach to rank classifiers on data. SML assumes there are k binary classifiers of unknown reliability (but, better than chance), each providing predicted class labels on unlabeled data. SML can rank the the classifiers based on their accuracy if: The evaluation set are sampled i.i.d. from DT . Tough to prove in NSE :( The classifiers are conditionally independent 1F. Parisi, F. Strino, B. Nadler, and Y. Kluger, “Ranking and combining multiple predictors without labeled data,” Proceedings of the National Academy of Sciences, vol. 111, no. 4, pp. 1253?1258, 2014. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
provides an approach to rank classifiers on data. SML assumes there are k binary classifiers of unknown reliability (but, better than chance), each providing predicted class labels on unlabeled data. SML can rank the the classifiers based on their accuracy if: The evaluation set are sampled i.i.d. from DT . Tough to prove in NSE :( The classifiers are conditionally independent Let us assume the evaluation data are i.i.d. 1F. Parisi, F. Strino, B. Nadler, and Y. Kluger, “Ranking and combining multiple predictors without labeled data,” Proceedings of the National Academy of Sciences, vol. 111, no. 4, pp. 1253?1258, 2014. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
provides an approach to rank classifiers on data. SML assumes there are k binary classifiers of unknown reliability (but, better than chance), each providing predicted class labels on unlabeled data. SML can rank the the classifiers based on their accuracy if: The evaluation set are sampled i.i.d. from DT . Tough to prove in NSE :( The classifiers are conditionally independent Let us assume the evaluation data are i.i.d. A Couple of Notes SML does not estimate the 0-1 error, rather it estimates a balanced error The combinations are determined in an unsupervised fashion 1F. Parisi, F. Strino, B. Nadler, and Y. Kluger, “Ranking and combining multiple predictors without labeled data,” Proceedings of the National Academy of Sciences, vol. 111, no. 4, pp. 1253?1258, 2014. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
provides an approach to rank classifiers on data. SML assumes there are k binary classifiers of unknown reliability (but, better than chance), each providing predicted class labels on unlabeled data. SML can rank the the classifiers based on their accuracy if: The evaluation set are sampled i.i.d. from DT . Tough to prove in NSE :( The classifiers are conditionally independent Let us assume the evaluation data are i.i.d. A Couple of Notes SML does not estimate the 0-1 error, rather it estimates a balanced error The combinations are determined in an unsupervised fashion Evaluating SML in NSE Build diverse classifiers on a stream of data Estimate the classifier voting weights solely from SML’s error estimates on unlabeled data 1F. Parisi, F. Strino, B. Nadler, and Y. Kluger, “Ranking and combining multiple predictors without labeled data,” Proceedings of the National Academy of Sciences, vol. 111, no. 4, pp. 1253?1258, 2014. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
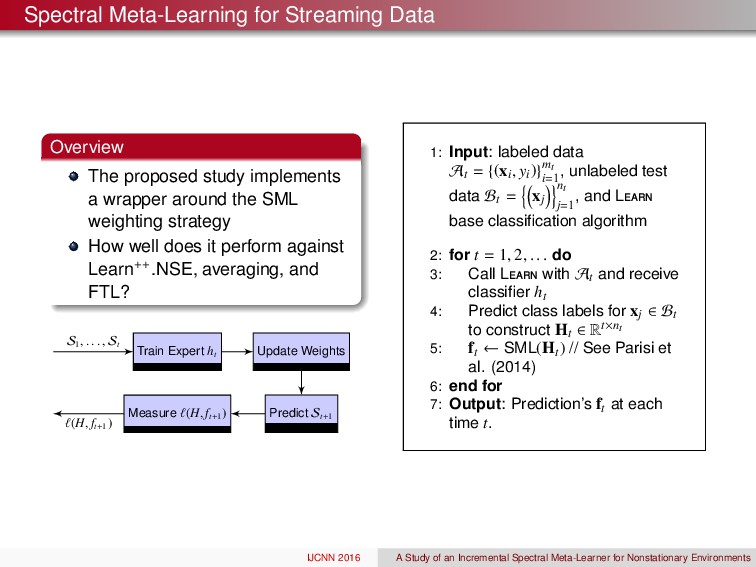
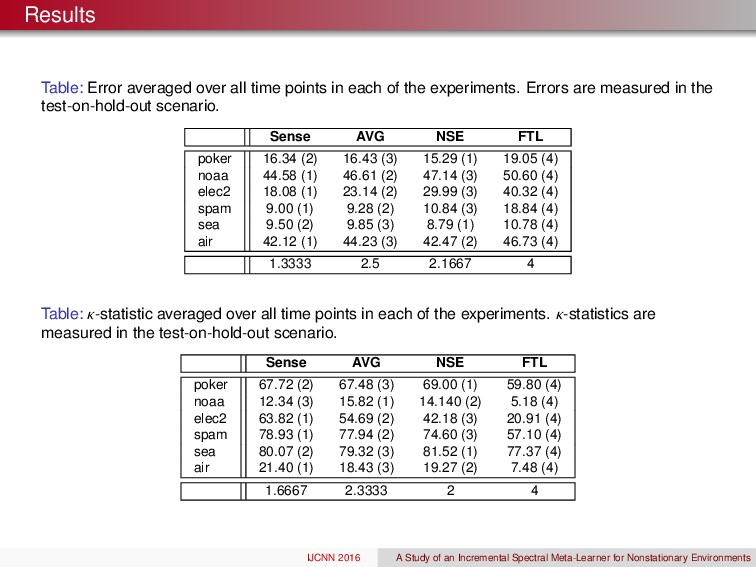
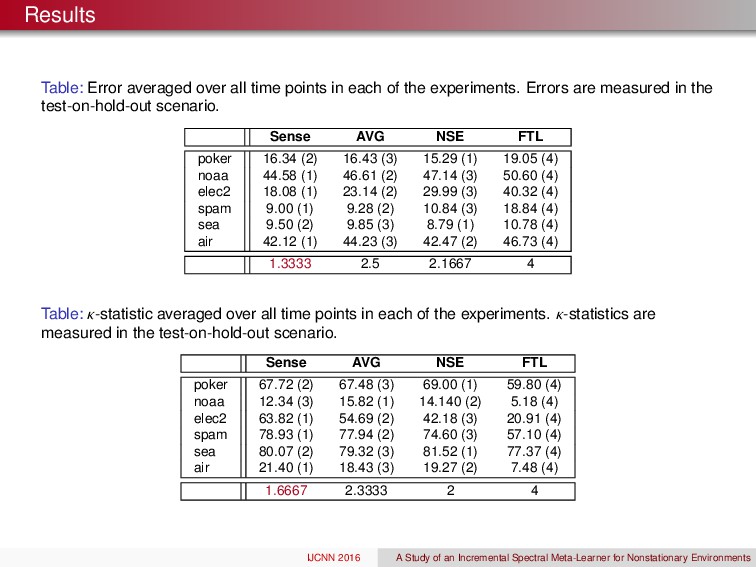
a wrapper around the SML weighting strategy How well does it perform against Learn++.NSE, averaging, and FTL? Train Expert ht Update Weights Predict St+ 1 Measure ` ( H, ft+ 1) S 1 , . . . , St ` ( H, ft+ 1) 1: Input: labeled data At = { ( xi, yi ) }mt i= 1 , unlabeled test data Bt = n⇣xj ⌘ont j= 1 , and Learn base classification algorithm 2: for t = 1 , 2 , . . . do 3: Call Learn with At and receive classifier ht 4: Predict class labels for xj 2 Bt to construct Ht 2 Rt⇥nt 5: ft SML ( Ht ) // See Parisi et al. (2014) 6: end for 7: Output: Prediction’s ft at each time t. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
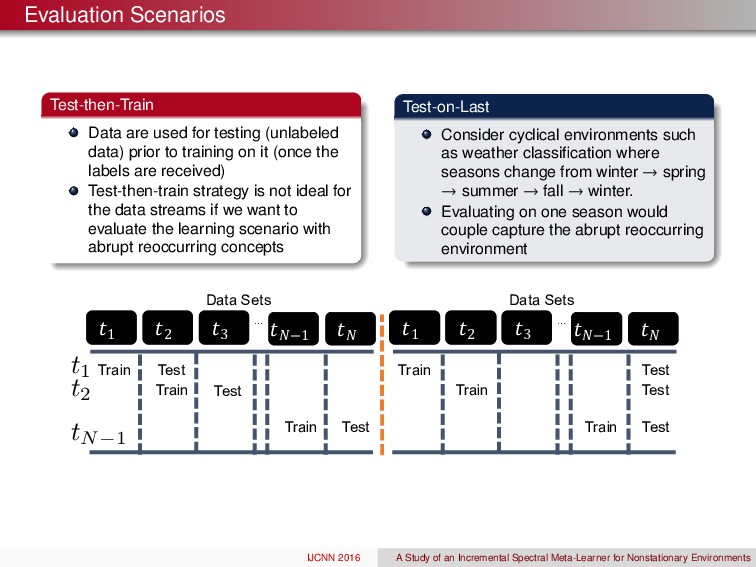
prior to training on it (once the labels are received) Test-then-train strategy is not ideal for the data streams if we want to evaluate the learning scenario with abrupt reoccurring concepts Test-on-Last Consider cyclical environments such as weather classification where seasons change from winter ! spring ! summer ! fall ! winter. Evaluating on one season would couple capture the abrupt reoccurring environment !1 !2 !3 !%−1 … !% Data%Sets Train Train Train Test Test Test !1 !2 !3 !%−1 … !% Data%Sets Train Train Train Test Test Test t1 t2 tN 1 IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
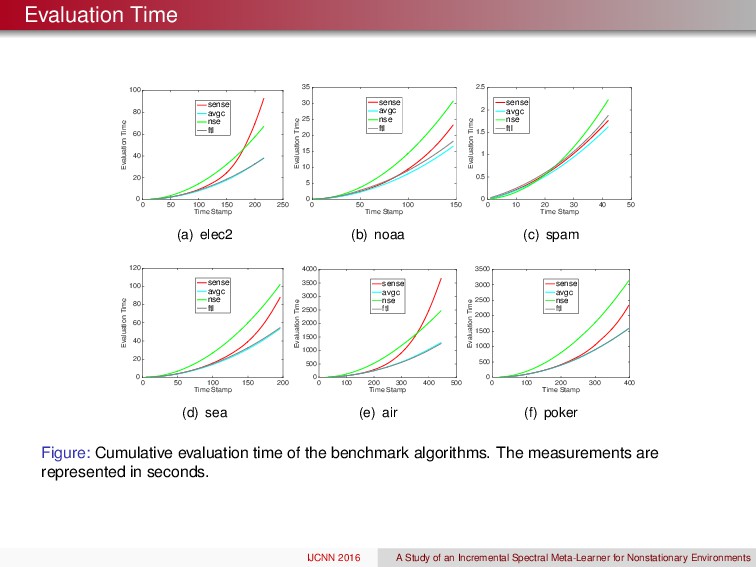
algorithm worked well, and provided promising results, yet more diverse data sets will be required to fully benchmark its efficacy. Furthermore, combine SML with a supervised strategy could be quite beneficial. Are we violating some of the assumptions in the original SML, yes! Do the preliminary results for the SML look promising for passive strategies in NSE, yes! IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
algorithm worked well, and provided promising results, yet more diverse data sets will be required to fully benchmark its efficacy. Furthermore, combine SML with a supervised strategy could be quite beneficial. Are we violating some of the assumptions in the original SML, yes! Do the preliminary results for the SML look promising for passive strategies in NSE, yes! Future Work: Data Dependent Regularizers Idea: use labeled and unlabeled data to optimize the weights ✓⇤ = arg min ✓2⇥ Loss( H, ✓, St ) + ⌦ ( H, ✓, Ut+ 1) What does ⌦ look like if we do not have labeled data from ˆ t = t + 1 ? H should generalize on St and St+ 1 Let SML estimate ⌦ and the Loss come from traditional passive NSE approaches. IJCNN 2016 A Study of an Incremental Spectral Meta-Learner for Nonstationary Environments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}