Павел Бахтин. ВШЭ. Использование state-of-the-art эмбеддинговых моделей для анализа научно-технических текстов
О проблемах использования эмбеддинговых моделей (в т.ч. BERT, XLNet) для анализа научно-технических текстов. Рассмотрены способы оценки их эффективности и кейс расширения базы знаний на примере одного научно-технологического направления.
заведующий отделом информационно- аналитических систем [email protected] Центр стратегической аналитики и больших данных Института статистических исследований и экономики знаний НИУ ВШЭ Big Data and AI Conference 2019, Москва, 2019 Илья Кузьминов, директор центра стратегической аналитики и больших данных [email protected]
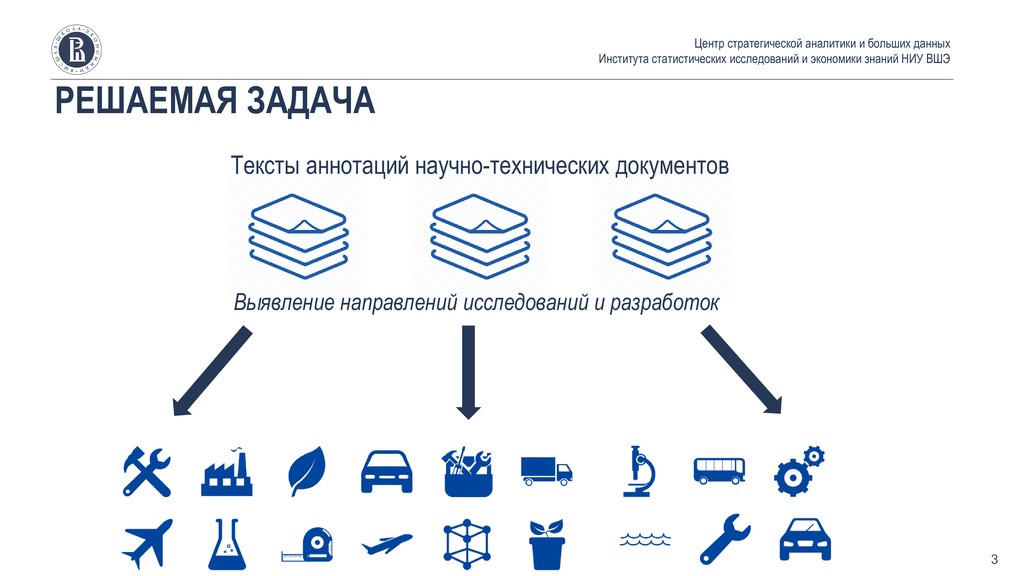
▪ Эволюция векторных моделей ▪ Разработка бенчмарка: исследовательские фронты ▪ Семантическая близость между документами и основная гипотеза ▪ Оценка эффективности векторных моделей ▪ Оптимальная конфигурация BERT ▪ Кейс по выявлению направлений в сфере ИИ, машинного обучения и других тематиках ИКТ ▪ Основные выводы Центр стратегической аналитики и больших данных Института статистических исследований и экономики знаний НИУ ВШЭ 2
модели: LSI/LSA, LDA, PLSA ▪ Word embeddings: Word2Vec, GloVe ▪ ELMo, BERT, GPT2, ERNIE 2.0, RoBERTA, XLNet Центр стратегической аналитики и больших данных Института статистических исследований и экономики знаний НИУ ВШЭ 5 Основная задача векторных моделей: превратить текст в числа
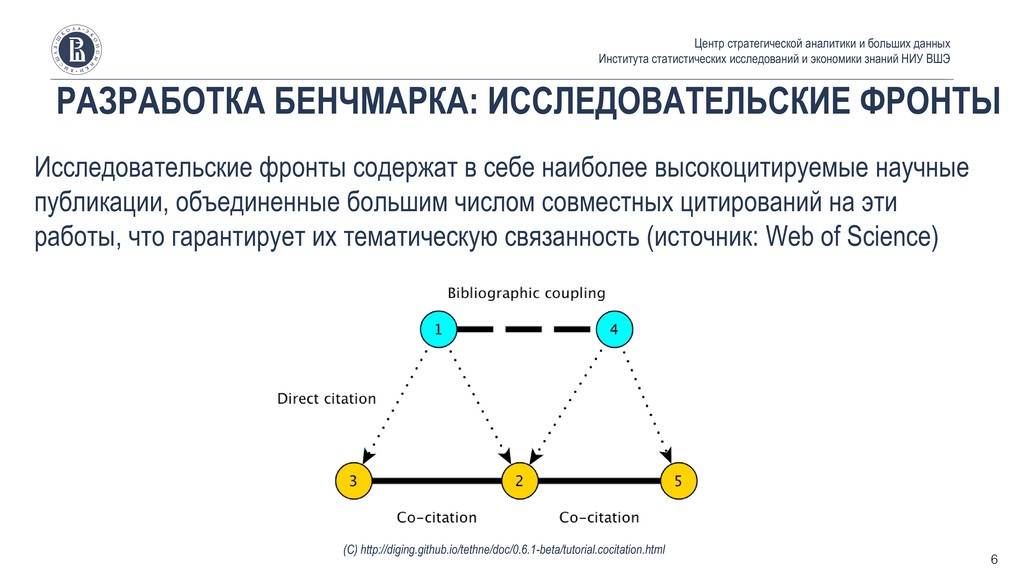
Института статистических исследований и экономики знаний НИУ ВШЭ 6 (С) http://diging.github.io/tethne/doc/0.6.1-beta/tutorial.cocitation.html Исследовательские фронты содержат в себе наиболее высокоцитируемые научные публикации, объединенные большим числом совместных цитирований на эти работы, что гарантирует их тематическую связанность (источник: Web of Science)
и больших данных Института статистических исследований и экономики знаний НИУ ВШЭ 7 Косинусная мера [cosine similarity] векторов: , = ∙ = σ σ 2 σ 2 Гипотеза: научные публикации, находящиеся в одном исследовательском фронте, должны иметь высокую семантическую близость.
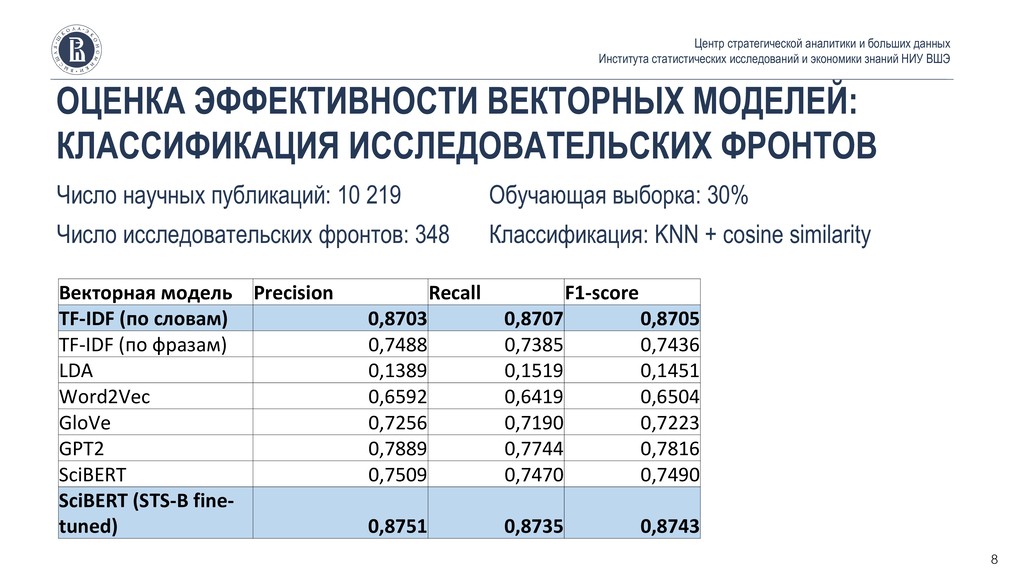
статистических исследований и экономики знаний НИУ ВШЭ ▪ Эмбеддинговые модели достигли уровня, приемлемого для анализа научно-технических документов. Следовательно, ретроспективный анализ-со-цитируемости может быть дополнен / заменен real-time анализом семантической близости между документами. ▪ Для решения задачи подходят как простые методы (TF-IDF), так и state-of-the-art (BERT), однако BERT позволяет уменьшить сложность вычислений за счет снижения размерности представления текстов ▪ Разработанный бенчмарк поможет оценивать новые эмбеддинговые модели, а также выбрать их оптимальную конфигурацию
систем Центр стратегической аналитики и больших данных Института статистических исследований и экономики знаний НИУ ВШЭ Big Data and AI Conference 2019, Москва, 2019 Илья Кузьминов, директор центра стратегической аналитики и больших данных
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![СПАСИБО ЗА ВНИМАНИЕ [email protected] Павел Бахтин, заведующий отделом информационно- аналитических](https://files.speakerdeck.com/presentations/454fbf1f66004adca65a2a783a3cf4cf/slide_11.jpg){kind=link}