In this Knowledge Ketchup Session, Pujan gave an insightful session on how modern AI models are made smaller and faster by storing their numbers with fewer bits, so they can run on everyday hardware instead of only in the data center.
made smaller and faster by storing their numbers with fewer bits, so they can run on everyday hardware instead of only in the data center. Presented By: Pujan Nepal
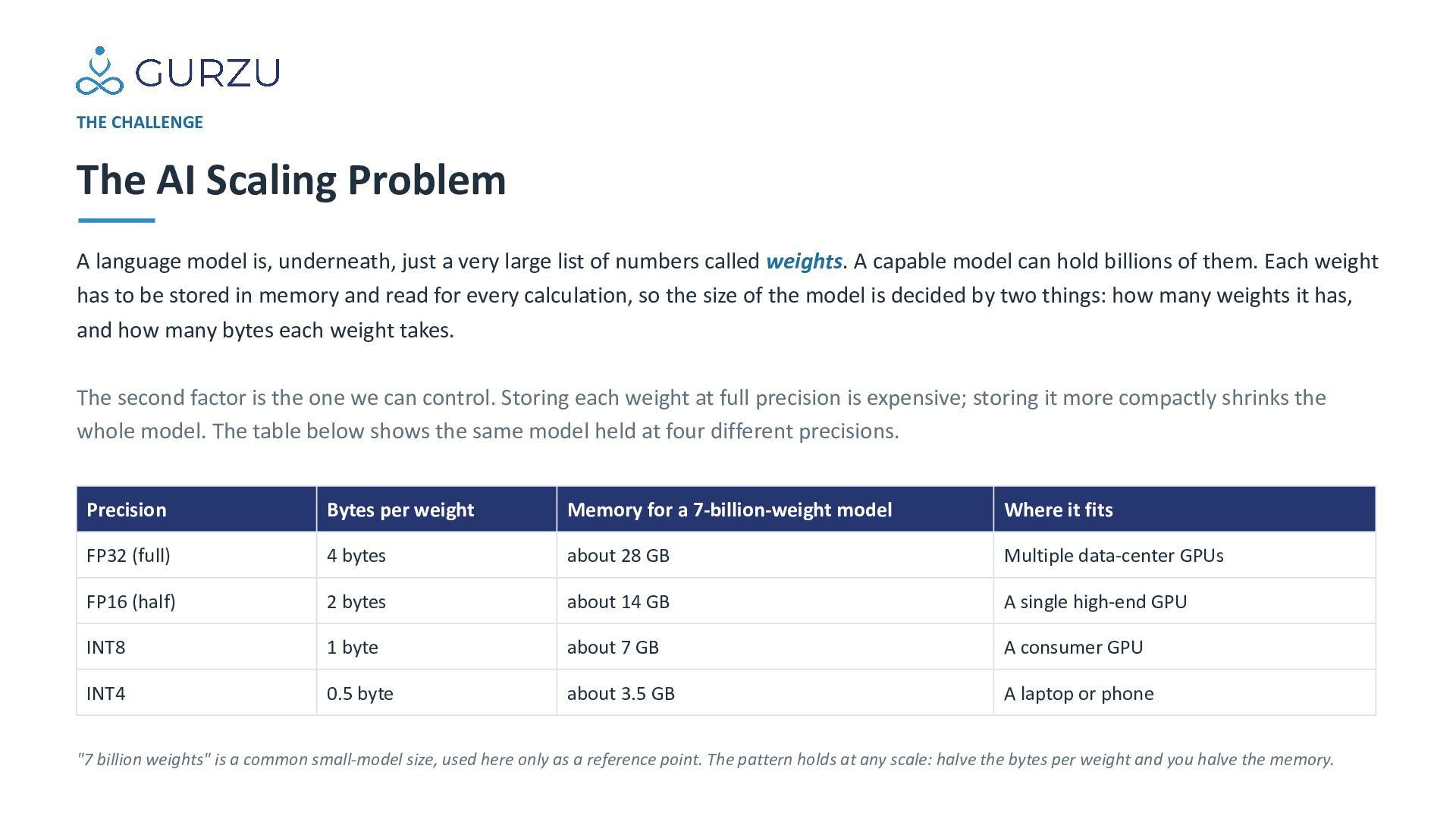
underneath, just a very large list of numbers called weights. A capable model can hold billions of them. Each weight has to be stored in memory and read for every calculation, so the size of the model is decided by two things: how many weights it has, and how many bytes each weight takes. The second factor is the one we can control. Storing each weight at full precision is expensive; storing it more compactly shrinks the whole model. The table below shows the same model held at four different precisions. Precision Bytes per weight Memory for a 7-billion-weight model Where it fits FP32 (full) 4 bytes about 28 GB Multiple data-center GPUs FP16 (half) 2 bytes about 14 GB A single high-end GPU INT8 1 byte about 7 GB A consumer GPU INT4 0.5 byte about 3.5 GB A laptop or phone "7 billion weights" is a common small-model size, used here only as a reference point. The pattern holds at any scale: halve the bytes per weight and you halve the memory.
not only an engineering convenience. It changes where AI can run, how much it costs, and who is able to use it at all. Six reasons it matters in practice: 01 Lower cost Less memory means cheaper hardware and lower cloud bills. A provider can serve far more users on the same machine. 02 Faster responses Smaller numbers mean less data to move and compute, which cuts the delay before a model replies. 03 Runs on real devices A compact model can fit on a phone or laptop, rather than requiring a rack of specialised servers. 04 Wider access Lower hardware requirements let smaller teams, schools, and businesses adopt AI without large budgets. 05 Energy savings Fewer and simpler calculations draw less power, reducing both operating cost and environmental impact. 06 Data privacy When a model runs locally, sensitive information can stay on the device instead of being sent to the cloud.
number in a model using fewer bits. Instead of recording every weight with many decimal places, we round each one to the nearest value in a small, fixed set of levels. The model keeps behaving almost the same, because the rounding is tiny relative to what each number does. What changes is the storage: far fewer bits per weight, and so a much smaller model overall. An everyday analogy. Saving a photo as a smaller file keeps the picture looking almost identical while using a fraction of the space. Quantization does the same to a model: a small loss of precision in exchange for a large saving in size. Rounding one weight Stored precisely Stored compactly 0.8124971 → 0.81 -1.4093388 → -1.41 0.0027461 → 0.00 2.7188043 → 2.72 Fewer digits to keep means fewer bits to store.
bits into roles. A wider row means more bits, which means more storage per number. Floating-point formats spend bits on a sign, an exponent (range) and a mantissa (precision); integer formats use plain whole numbers. FP32 S E E E E E E E E M M M M M M M M M M M M M M M M M M M M M M M 32 bits FP16 S E E E E E M M M M M M M M M M 16 bits BF16 S E E E E E E E E M M M M M M M 16 bits FP8 (E4M3) S E E E E M M M 8 bits INT8 I I I I I I I I 8 bits INT4 I I I I 4 bits NF4 N N N N 4 bits Binary B 1 bit S sign E exponent (range) M mantissa (precision) I integer N non-uniform B binary Takeaway: choosing a format is choosing how many bits to spend per number. INT8 and INT4 are the compact workhorses for running models; FP16 and BF16 are common during training.
weight into a small integer, using two saved values: a scale (the size of one step) and a zero-point (where real zero sits on the integer grid). It runs in four named stages: 1. Calibration Measure the actual range of the weights, their minimum and maximum. (For activations, a small sample of data is used here.) 2. Compute scale and zero-point The scale is the range divided by the number of levels available; the zero-point aligns real zero with the integer grid. 3. Quantize Map each weight to its nearest integer with the formula below. This is the stage that reduces storage. 4. Dequantize When the model computes, the integer is converted back to an approximate real value using the same scale. THE FORMULA quantize: q = round( x / scale ) + zero dequantize: x ≈ scale × ( q − zero ) WORKED EXAMPLE (INT8, symmetric) range ±2.0, zero = 0 scale = 2.0 / 127 ≈ 0.0157 weight x = 0.74 q = round( 0.74 / 0.0157 ) = 47 back = 47 × 0.0157 ≈ 0.7403 The gap between 0.74 and 0.7403 is the rounding error. Averaged across the whole model it stays small, which is why a quantized model still works well.
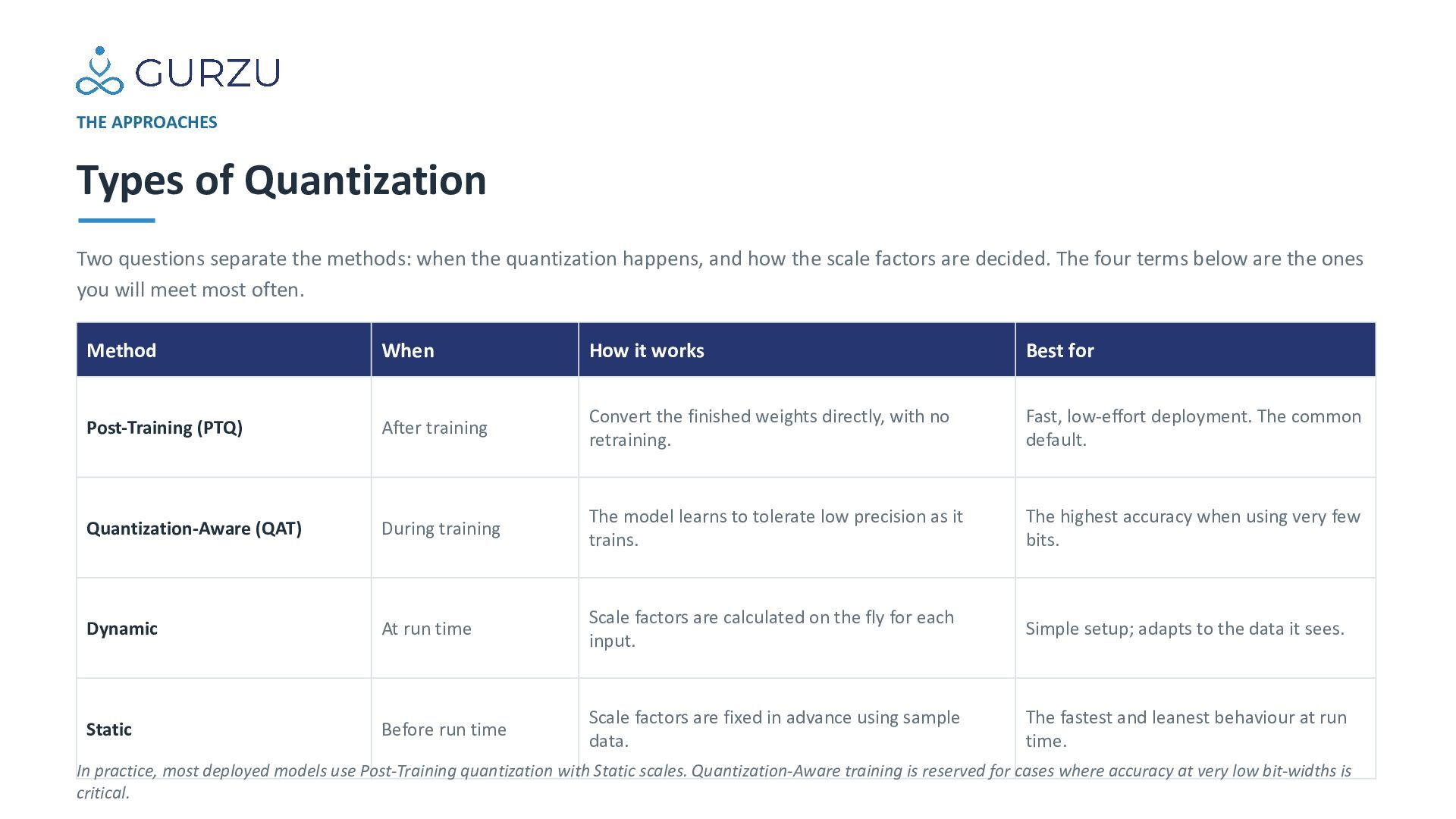
when the quantization happens, and how the scale factors are decided. The four terms below are the ones you will meet most often. Method When How it works Best for Post-Training (PTQ) After training Convert the finished weights directly, with no retraining. Fast, low-effort deployment. The common default. Quantization-Aware (QAT) During training The model learns to tolerate low precision as it trains. The highest accuracy when using very few bits. Dynamic At run time Scale factors are calculated on the fly for each input. Simple setup; adapts to the data it sees. Static Before run time Scale factors are fixed in advance using sample data. The fastest and leanest behaviour at run time. In practice, most deployed models use Post-Training quantization with Static scales. Quantization-Aware training is reserved for cases where accuracy at very low bit-widths is critical.
same number of bits. Mixed-precision quantization does something smarter: it assigns more bits to the parts of the model that are sensitive to error, and fewer bits to the parts that are not. The total size drops while accuracy is largely preserved. Model component What it does How it is quantized Attention projections (Q, K, V) Decide which earlier tokens each token pays attention to. Higher precision (sensitive) Output / prediction layer Turns the model's internal state into the next-word scores. Higher precision (sensitive) Embedding table Maps each token to its starting vector of numbers. Often kept higher precision Feed-forward (MLP) weights The largest block of parameters in the model. Lower precision (tolerant)
worth it for running models, but it is a dial rather than a free lunch. The right setting depends on the model, the task, and the hardware. Benefits Much smaller models. Commonly a 4x to 8x reduction in storage and memory. Faster inference. Less data to move and process means quicker replies. Runs on modest hardware. Phones, laptops and single GPUs become viable hosts. Lower cost and energy. Cheaper to run and greener to operate at scale. Trade-offs Some accuracy is lost. Aggressive levels can dull reasoning, nuance or rare knowledge. Not always plug-and-play. Some hardware and tools support only certain formats. Quality varies by model. Smaller models tolerate heavy compression less gracefully. Extra engineering effort. Choosing and validating the right level takes testing.
enabler behind AI that feels instant, local, and affordable. On-device assistants Voice and text helpers that run on a phone, so replies are fast and personal data can stay on the device. Local language models Tools such as Ollama and llama.cpp let people run capable models on a laptop, fully offline if they wish. Edge and IoT devices Smart cameras and sensors run AI directly on small, low-power chips where sending data to the cloud is impractical. Cost-efficient cloud serving Providers fit many more users onto each GPU by serving quantized models, lowering the price per request. Regulated industries Healthcare and finance can keep analysis on local hardware, helping meet privacy and data-residency requirements. Real-time systems Applications with strict latency limits, such as live transcription, rely on the speed that compact models give.
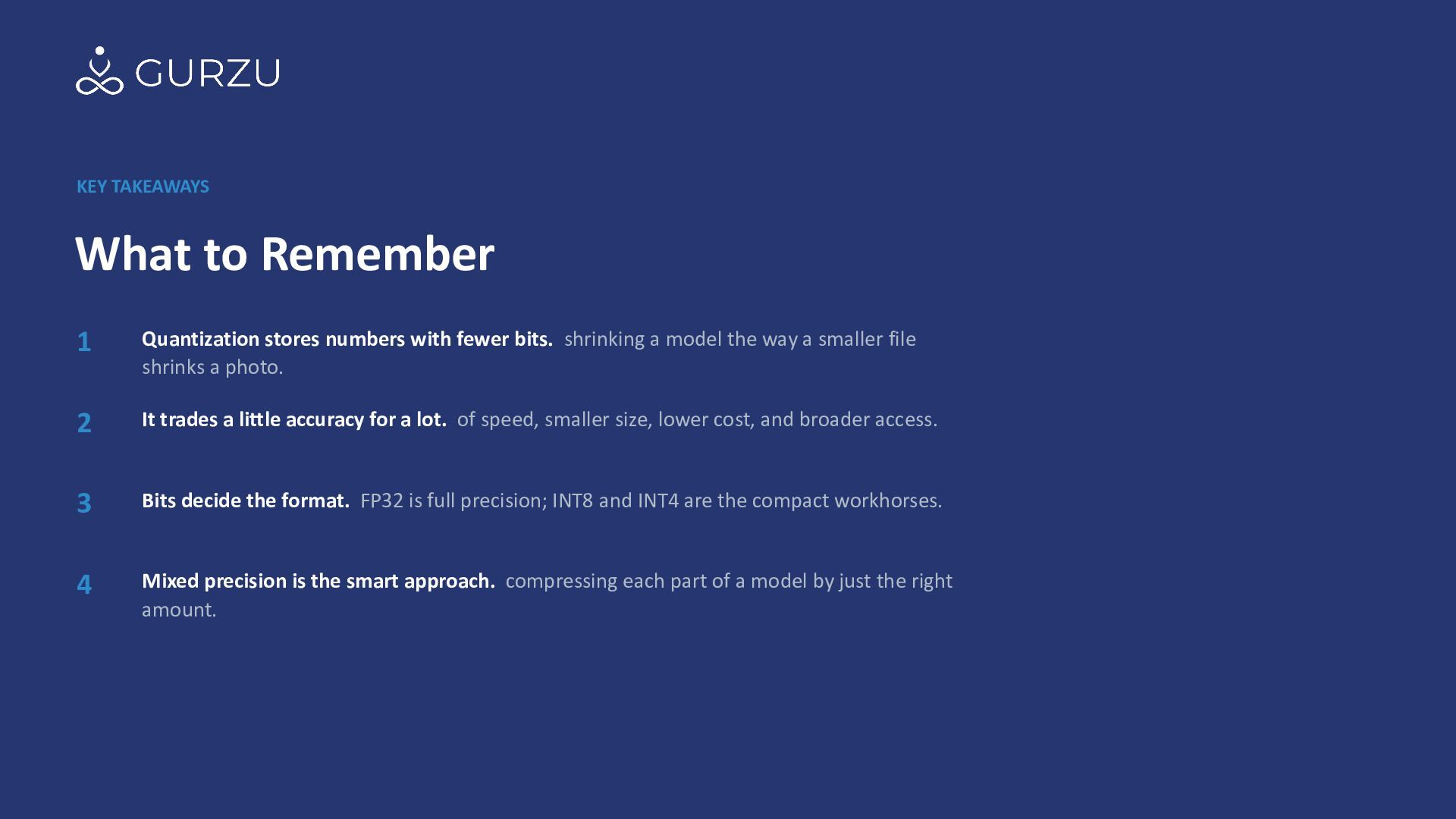
fewer bits. shrinking a model the way a smaller file shrinks a photo. 2 It trades a little accuracy for a lot. of speed, smaller size, lower cost, and broader access. 3 Bits decide the format. FP32 is full precision; INT8 and INT4 are the compact workhorses. 4 Mixed precision is the smart approach. compressing each part of a model by just the right amount.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}